图像融合论文阅读:A Deep Learning Framework for Infrared and Visible Image Fusion Without Strict Registration
@article{li2023deep,
title={A Deep Learning Framework for Infrared and Visible Image Fusion Without Strict Registration},
author={Li, Huafeng and Liu, Junyu and Zhang, Yafei and Liu, Yu},
journal={International Journal of Computer Vision},
pages={1–20},
year={2023},
publisher={Springer}
}
论文级别:SCIA2/Q1
影响因子:19.5
[论文下载地址]
文章目录
- 【如侵权请私信我删除】
- 论文解读
-
- 关键词
- 核心思想
- 网络结构
-
- CTHIE
- DRFR
- FPFF
- 损失函数
- 数据集
- 训练设置
- 实验
-
- 评价指标
- Baseline
- 实验结果
- 传送门
-
- 图像融合相关论文阅读笔记
- 图像融合论文baseline总结
- 其他论文
- 其他总结
- ✨精品文章总结
【如侵权请私信我删除】
论文解读
以往的融合算法需要在配准的图像上进行,为了解决这个问题,作者提出了一种融合不需要严格配准可见光和红外图像的算法,该算法利用CNN和Transformer分层交互嵌入模块(CNN-Transformer Hierarchical Interactive Embedding , CTHIE)提取特征,设计了一个动态聚合特征表示(Dynamic Re-aggregation Feature Representation , DRFR)模块用来配准。再使用完全感知前向融合(Fully Perceptual Forward Fusion , FPFF)生成融合图像。
关键词
Infrared and visible image fusion · Misalignment · Convolutional neural network · Transformer
红外与可见光图像融合,非配准,卷积神经网络,Transformer
核心思想
参考链接
[什么是图像融合?(一看就通,通俗易懂)]
网络结构
作者提出的网络结构如下图1所示。

看起来很复杂是不是,别担心,继续往下看。
我们先关注一路数据流,理解后另外一路也就明白了。

作者首先使用FEB-CL对配准图像对 ( x i r , x v i ) (x_{ir},x_{vi}) (xir,xvi)和未配准图像对 ( x ^ i r , x v i ) (\hat x_{ir},x_{vi}) (x^ir,xvi)进行特征提取,然后将特征图输入CTHIE,即上图中灰色块标记的地方,内部结构先不管。
注意,这里和普通的ViT不同,作者没有将源图像变成patches输入,而是提取其特征图作为输入。特征图为不同通道的特征组成的特征向量
我们梳理一下结构
- FEB-CL
Feature Extraction Block based on Conv layers ,基于卷积层的特征提取模块,用来获取多通道的特征图,便于后续使用Transformer继续进行特征提取。如下图

CTHIE
CNN和Transformer分层交互嵌入模块(CNN-Transformer Hierarchical Interactive Embedding),里面主要是由CETB(CNN Embedded Transformer Block),即嵌入Transformer块的CNN,以及普通的卷积层组成,对应图1里用灰色块标记的区域。在CETB和卷积层多层之间交互传递信息,即卷积层提取的特征输入CETB,CETB提取的特征再输入下一层的卷积层。同时在CTHIE里还加入了跳跃链接,借鉴了DenseNet的思想。如下图
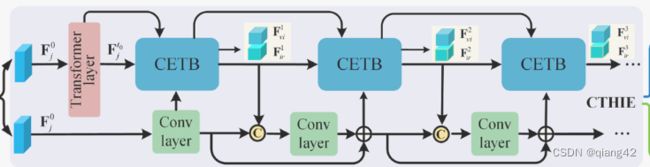
其中,蓝色CETB的内部结构如下图所示

F ^ j c , i \hat F_j^{c,i} F^jc,i表示第i个卷积层的输出。对于每个CETB来说都有多个输入。
第一个CETB较为特殊,因为其之前没有卷积层,所以将两个 F ^ j t 0 \hat F_j^{t_0} F^jt0作为其输入,一个输入到LN层,另一个作为 F ^ j f , 0 \hat F_j^{f, 0} F^jf,0输入到FIB处。
对于之后的CETB, F ^ j i − 1 \hat F_j^{i-1} F^ji−1是第(i-1)个CETB的输出,
卷积层的内部结构如下图,加入了密集连接。
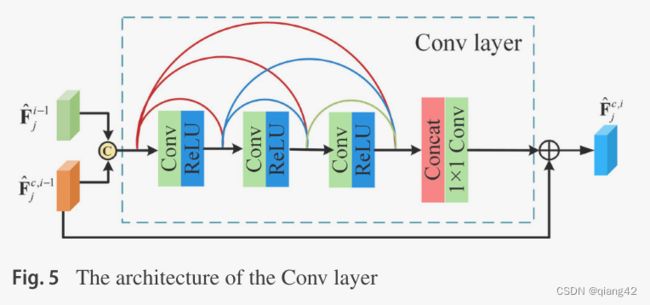
DRFR
动态聚合特征表示(Dynamic Re-aggregation Feature Representation , DRFR)模块用来配准,其核心思想是将红外图像(x,y)处的特征向量,视为其邻域的特征向量的线性组合,对红外图像(x,y)处的特征向量赋予更大的权重,以此来减轻非严格配准对图像融合的影响。如下图
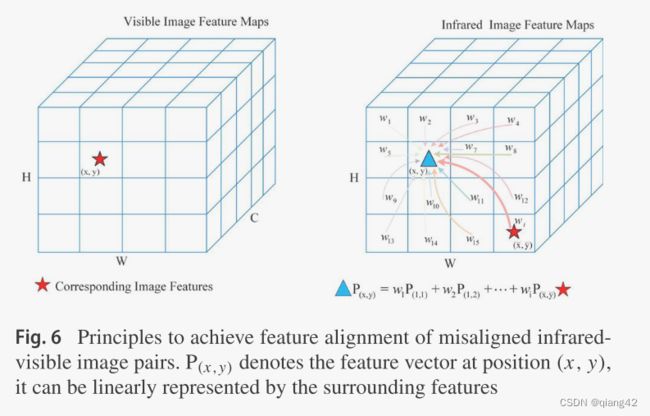
网络里的DRFR结构如下图,由特征调整模块和重配准模块构成。
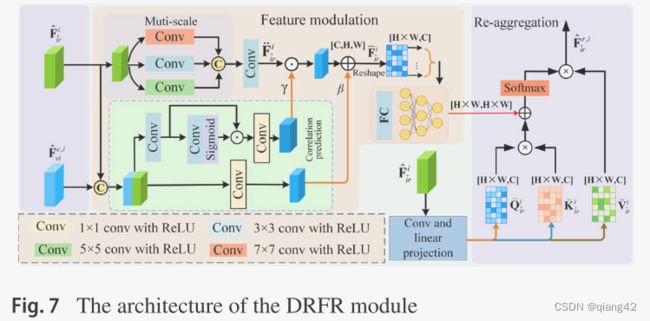
FPFF
完全感知前向融合(Fully Perceptual Forward Fusion , FPFF)生成融合图像,其网络结构如下

总的来说,该文网络结构过于复杂,在运行效率上肯定存在一定的不足。大家主要体会学习其核心思想即可
损失函数
阶段1:
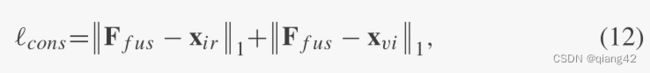
阶段2:
损失=像素损失+梯度损失+感知损失
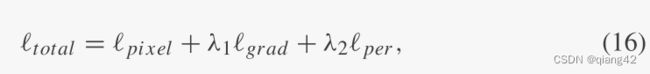

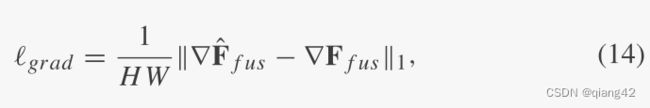

数据集
- 训练:KAIST, FLIR
- 测试:TNO, VOT2020-RGBT, CVC-14
图像融合数据集链接
[图像融合常用数据集整理]
训练设置

实验
随机将图像裁剪为140×140的图像块,在实验中,分别对配准图像和未对齐图像的融合分支进行训练。前者训练共10个epoch,后者训练42个epoch。
评价指标
- CE
- EN
- Qabf
- Qcb
- Qcv
- SSIM
参考资料
[图像融合定量指标分析]
Baseline
- FusionGAN, DeepFuse, IFCNN, NestFuse, U2Fusion, RFN , SDNet, PMGI , LRRNet , DATFuse
✨✨✨参考资料
✨✨✨强烈推荐必看博客[图像融合论文baseline及其网络模型]✨✨✨
实验结果
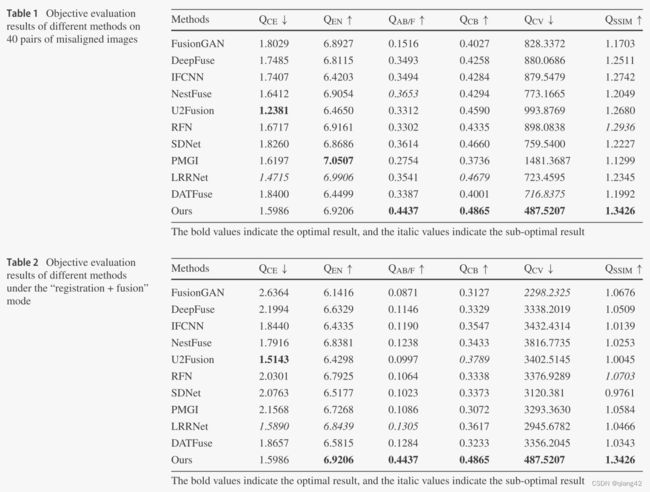
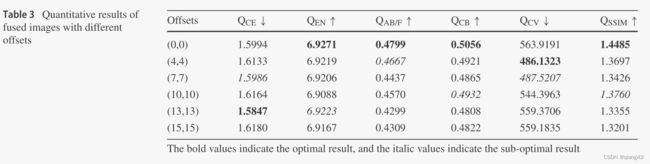

更多实验结果及分析可以查看原文:
[论文下载地址]
传送门
图像融合相关论文阅读笔记
[(APWNet)Real-time infrared and visible image fusion network using adaptive pixel weighting strategy]
[Dif-fusion: Towards high color fidelity in infrared and visible image fusion with diffusion models]
[Coconet: Coupled contrastive learning network with multi-level feature ensemble for multi-modality image fusion]
[LRRNet: A Novel Representation Learning Guided Fusion Network for Infrared and Visible Images]
[(DeFusion)Fusion from decomposition: A self-supervised decomposition approach for image fusion]
[ReCoNet: Recurrent Correction Network for Fast and Efficient Multi-modality Image Fusion]
[RFN-Nest: An end-to-end resid- ual fusion network for infrared and visible images]
[SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images]
[SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer]
[(MFEIF)Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion]
[DenseFuse: A fusion approach to infrared and visible images]
[DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pair]
[GANMcC: A Generative Adversarial Network With Multiclassification Constraints for IVIF]
[DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion]
[IFCNN: A general image fusion framework based on convolutional neural network]
[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
[FusionGAN: A generative adversarial network for infrared and visible image fusion]
[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
[U2Fusion: A Unified Unsupervised Image Fusion Network]
综述[Visible and Infrared Image Fusion Using Deep Learning]
图像融合论文baseline总结
[图像融合论文baseline及其网络模型]
其他论文
[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
其他总结
[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]
如有疑问可联系:[email protected];
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~