分布式批处理框架在大促场景下的设计与实现
在本次双十一之前,我们上线了新版的批处理框架,完整支撑了大促的招商。通过SDK接入,可以直接在业务应用中实现任务逻辑,接入便捷;通过中心化调度与任务分发,处理过程提效明显。

背景
在B端系统中,批处理能力是不可或缺的,它可以帮助用户批量完成一系列动作,降低重复操作的成本。在大促招商系统中,我们也需要一套在线批处理框架,来支持商家的批量商品报名、批量主图打标、一键发布、导出已报商品等操作,让商家可以批量上传数据、管理操作记录、查看批量操作的结果明细。这些任务输入数据的来源五花八门,有Excel、DB、OpenSearch等,框架需要能支持各种类型输入数据的解析。同时,招商系统的应用数量较多,需要能同时支持各个域的应用便捷接入,最好是只需要引包,然后实现任务逻辑即可。在大数据量的场景下,框架需要能支持对不同类型的任务实例精细化调度,同时保证系统的吞吐量和稳定性。

整体方案
▐ 架构设计
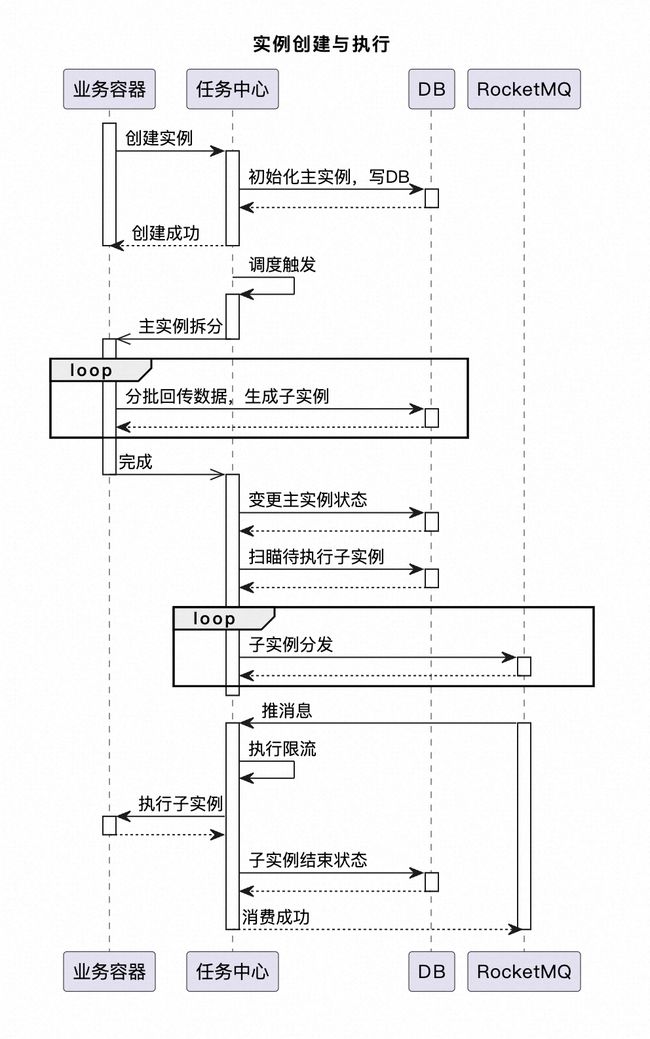
业务容器为接入框架的应用,任务中心是批处理框架的中心应用。实例的调度、状态变更在任务中心完成,方便做中心化管理;实例的执行逻辑在业务容器中实现,所以在执行时需要回调业务容器。

▐ 模型设计
要在单条数据项维度调度任务实例,除了任务注册信息、任务实例外,还需要引入子任务实例的模型。任务注册信息对象含有某个任务的任务类型、执行限流值等信息。用户每次批量上传数据都会生成一个主任务实例,单条数据项对应一个子任务实例。
▐ 主要流程
核心流程借鉴了MapReduce的思想,将一个大任务拆分后分发到多机去执行,最后再进行结果汇总。业务容器在接入时需要实现一个任务的主实例拆分、子实例执行和结果合并逻辑。主实例拆分时会将用户输入数据解析为子实例,落DB存储;子实例执行是单条数据项的执行逻辑;结果合并是将子实例的处理结果统计后展示(如生成任务明细Excel)。
实例被调度触发后任务中心会调用业务容器中实现的主实例拆分方法,主实例被拆分后需要分批回传数据。任务中心执行实例时会将子实例扫出来,通过rocketmq自发自收将子实例分发到任务中心的整个集群,接到消息后调用业务容器执行子实例,拿到结果后更新子实例状态,消费成功。通过ScheduleX任务定时扫描执行中主实例的子实例状态,当子实例全部执行完成后回调业务容器执行结果合并逻辑,最终将任务归档。

▐ 状态机
主任务

子任务


关键技术点
▐ 调度执行
限流组件
限流组件使用的是guava包中的实现,任务注册时需要分别配置主实例和子实例执行的限流值,限流也在任务类型维度来做,调度时根据任务的key取到对应的限流器。限流器缓存在机器本地,过期后重新查询任务注册信息,新建限流器。目前只在单机维度做了限流,用集群限流数除以任务中心的集群机器数,得到单机限流值。

主实例调度
任务实例创建后,会尝试获取一次令牌,如果能获取到,那主实例会直接被触发,执行后续流程。如果没有获取到令牌,任务会停留在待触发状态,等待ScheduleX任务定时捞起重新尝试执行。

子实例调度
主实例在执行时会先在任务中心通过rocketmq将所有子实例分发到整个集群,然后同步调用业务容器执行并获取到子实例的结果。子实例的限流是通过控制消息消费速率实现的。在任务中心消费rocketmq时阻塞获取令牌。因为所有任务类型共用一个topic,消息分发速率也做了上限控制,否则大实例会导致消息积压从而阻塞其他类型任务的执行。

如果在更新子实例状态前机器重启,利用mq的重试机制,对于幂等的任务类型,可直接重新执行,不支持幂等的任务类型在消息重试时子实例直接更新为失败即可。
▐ 中心与客户端通信
执行任务的实现逻辑时,需要回调业务容器,SDK中需要有支持供任务中心主动发起的通信方式。具体实现为:
客户端侧:提供Dubbo接口,业务应用启动时注册服务,用Dubbo的group区分不同应用(group不能重复,所以直接使用应用名称作为group)
任务中心侧:注册为所有业务应用服务的消费者,在需要回调业务容器时,先根据任务注册的应用找到对应消费者,通过消费者向业务应用发起调用
主实例的拆分和结果合并采用异步调用,子实例考虑到已经是拆分后的结果,目前只支持同步调用。
▐ 实例探活
考虑到主实例的拆分和结果合并执行时间较长,极端场景下有几十万条数据的读写,所以主实例的拆分和结果合并对客户端的调用都是异步的。在异步场景下需要考虑如何对业务应用进行探活并重试,否则一旦机器重启,正在执行的任务实例便会停留在中间状态,产生大量脏数据。
探活采用的方案是客户端侧上报心跳结合任务中心侧定时任务检测心跳。客户端接收到请求后会在本地定时上报任务实例的心跳,即更新DB中实例的心跳时间,执行结束后不再上报。任务中心通过ScheduleX任务扫表检测心跳超时的任务实例,重新向客户端发起请求。

以上解决的是业务应用重启时实例执行中断的问题,如果任务中心应用重启,也会导致对实例的部分操作中断(如子实例分发),同样也用心跳时间探活来解决,对超时的实例,重新执行当前状态的操作,防止实例永久停留在中间状态。
▐ 客户端实现
业务容器接入时,只需要实现SDK中的MapReduceTask类并实现主任务实例拆分、子任务实例执行和结果合并的方法,其余逻辑在SDK中内置,无需关心。定义类时还需要声明任务类型的唯一标识key,用于在客户端匹配任务类型和具体实现。具体demo如下:
@BatchTask(key = "myDemo")
public class MyDemo implements MapReduceTask {
/**
* 主任务实例拆分
*
* @param context context
* @return {@link TaskResult}
*/
@Override
public TaskResult processInstance(ExecuteContext executeContext) {
while (true) {
// 分批读取输入数据
...
// 生成子实例
List subInstances = ...;
// 提交数据
executeContext.commit(subInstances);
}
return TaskResult.success();
}
/**
* 子任务实例执行
*
* @param context context
* @return {@link TaskResult}
*/
@Override
public TaskResult map(SubExecuteContext subExecuteContext) {
// do something
...
return TaskResult.success();
}
/**
* 结果合并
*
* @param context 上下文
* @return {@link TaskResult}
*/
@Override
public TaskResult reduce(ExecuteContext executeContext) {
do {
// 读取子实例
List subInstanceList = executeContext.read(pageSize);
if (CollectionUtils.isEmpty(subInstanceList)) {
break;
}
// 构建结果明细
...
} while (subInstanceList.size() == pageSize);
// 生成结果数据
Map resultInfoMap = ...;
return TaskResult.success(resultInfoMap);
}
} 在主任务的拆分与结果合并逻辑中,分别会需要对子实例进行读与写操作,所以在任务执行上下文ExecuteContext中,提供了commit()和read()方法供客户端调用,其中写逻辑需要在业务容器中构建好子实例对象并提交。
考虑到子实例的读写如果每次通过Dubbo调用任务中心,高频次读写下会增加网络超时等异常的数量,所以采用了直连DB的方案,SDK中内置了与DB的交互层。为了提高写DB的效率,commit后的数据会存在任务执行上下文的缓冲区中,超过阈值后会向DB批量插入一次数据,最后清空缓冲区,插入剩余数据。

效果与展望
新版批处理框架上线后目前完成了批量报名、一键报名、导出已报商品、批量撤销等多个商家关键操作的迁移与接入,完整、稳定支撑了本次双十一大促的招商,处理了130W+的任务实例。目前系统整体较稳定,任务支持灵活配置,系统整体可监控。
关于未来优化的方向:因为子实例是通过mq分发的,导致如果大量子实例执行被限流,可能会阻塞后面其他任务没有被限流的子实例的消息。目前消息做了业务身份的隔离,发送速率上限也做了粗略地控制,未来会尝试通过匹配消息单机发送与集群消费的速率、不同类型任务的分组消费,提高整个系统的在极端场景下的吞吐量。

团队介绍
淘天核心技术团队,持续建设全网比价、用增、交易、招商、选品、搭建、投放等能力,支撑大促(双11、618等)和日销业务。简单、高效、纯粹的技术文化,在使命与责任中互相成就,共同成长。
Base杭州职位热招中:Java开发工程师、前端工程师、测试开发工程师、数据分析师。详情联系:[email protected]
¤ 拓展阅读 ¤
3DXR技术 | 终端技术 | 音视频技术
服务端技术 | 技术质量 | 数据算法