PyTorch|构建自己的卷积神经网络--池化操作
在卷积神经网络中,一般在卷积层后,我们往往进行池化操作。实现池化操作很简单,pytorch中早已有相应的实现。
nn.MaxPool2d(kernel_size= ,stride= )
这种池化叫做最大池化。
最大池化原理很简单,就是一个filter以一定的stride在原数据上进行操作,就像这样:
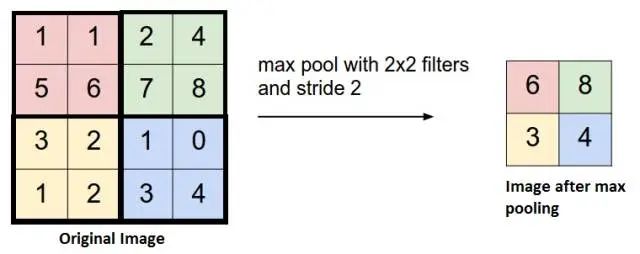
这里是一个2x2的filter,同时stride为2,在原始数据上扫描,最终的到新的数据。
通过代码来实现:
>>> import torch>>> import torch.nn as nn>>> data=torch.tensor([[1,1,2,4],[5,6,7,8],[3,2,1,0],[1,2,3,4]],dtype=torch.float32)>>> data.size()torch.Size([4, 4])>>> data=data.unsqueeze(0)>>> data.size()torch.Size([1, 4, 4])>>> data=data.unsqueeze(0)>>> data.size()torch.Size([1, 1, 4, 4])
之所以这样操作,是为了模仿实际训练网络时的场景。这样data的尺寸变为了1x1x4x4
可以理解为Batch为1,Channel为1,Height为4,Width为4
>>> net=nn.MaxPool2d(kernel_size=2,stride=2)>>> end=net(data)>>> endtensor([[[[6., 8.],[3., 4.]]]])
结果符合预期
当然,nn.MaxPool2d()的可接受参数很多,完整如下:
nn.MaxPool2d(kernel_size,stride=None,padding=0,dilation=1,return_indices=False,ceil_mode=False)
-
kernel_size:设置filter大小
-
stride:控制移动步长,默认为kernel_size的尺寸
-
padding:对原始数据周围进行填充
-
dilation:给原始数据之间添加0
-
return_indices :如果为True,会返回输出最大值对应的序号序列。
-
ceil_mode:控制当卷积核超过原始图像时,是否对max进行保留
这里参数很多,但很多时候我们并不需要一些参数,就像这样:
nn.MaxPool2d(kernel_size=,stride=,padding=)
或者这样:
nn.MaxPool2d(kernel_size,stride)
当然,进行池化操作后,我们很可能再来连接一个卷积层或者全连接层,所以对数据进行池化后,数据的尺寸如何变化是必须要知道的。
公式(假设输入的数据H和W相同):
输入:N,C,H,W
输出:N,C,H',W'
-
H'=(H+2*padding-kernel_size)/stride+1
-
W'=(W'+2*padding-kernel_size)/stride+1
再次回到最初的代码:
>>> import torch>>> import torch.nn as nn>>> data=torch.tensor([[1,1,2,4],[5,6,7,8],[3,2,1,0],[1,2,3,4]],dtype=torch.float32)>>> data.size()torch.Size([4, 4])>>> data=data.unsqueeze(0)>>> data.size()torch.Size([1, 4, 4])>>> data=data.unsqueeze(0)>>> data.size()torch.Size([1, 1, 4, 4])>>> net=nn.MaxPool2d(kernel_size=2,stride=2)>>> end=net(data)>>> endtensor([[[[6., 8.],[3., 4.]]]])
输入:1x1x4x4
输出:1x1x2x2
2=(4+2*0-2)/2+1
当然池化种类也有很多,但理解起来都不难,同时,kernel_size,dilation,stride,padding的尺寸也不一定为正方形。