3.ElasticSearch分词器,包括默认分词器、英文分词器、中文分词器
注:测试环境:CentOS Linux release 7.6.1810 (Core)
jdk:1.8
elasticsearch:6.8.2 单节点
es 安装:1.ElasticSearch安装教程与注意事项 以及集群环境搭建_名猿陈大浏的博客-CSDN博客
es添加索引:2.ElasticSearch添加、查询、修改、删除索引入门教程_名猿陈大浏的博客-CSDN博客
导图(用于总结和复习)

注:使用 GET _analyze 可以使用分词器查看分词结果,例:

以上用例是使用 analyzer 指定英文分词器查看分词结果,如果field是索引里的字段,会使用字段指定的分词器进行分词。

接下来进入测试。
默认分词器
默认使用standard分词器
在不标明的时候都是使用默认的standard分词
在建索引的时候,使用 analyzer 指定字段分词器
测试数据:
#1.删除 /test下的测试数据
DELETE /test/
#2.给字段添加限制类型,使用analyzer添加分词方式,不标明的时候默认使用standard分词器,也可以标明english使用英文分词器
PUT /test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"_doc":{
"properties":{
"name":{"type":"text"},
"age":{"type":"integer"},
"introduce":{"type":"text","analyzer":"english"}
}
}
}
}
#3.添加测试数据:李雷
PUT /test/_doc/1
{
"name":"李雷",
"age":12,
"engname":"Lilei",
"introduce":"My name is Lilei, I like eating apples and running"
}
#4.使用“李小雷”测试查询
GET /test/_search
{
"query": {
"match": {
"name": "李小雷"
}
}
}
分别执行以上的测试脚本,最后发现使用“李小雷”也能搜索出 name 为“李雷”的文档。这是因为 name 默认使用了 standard 分词器。可以通过以下方法查看分词器的分词结果。例:

这里field使用name,就会使用name的默认分词器standard
可以看到 standard 分词器会把中文拆分成一个一个的汉字,搜索条件只需要满足一个汉字就能搜索出结果,所以“李小雷”能搜索到“李雷”。中文一般不建议直接使用这种分词器,否则没有效果了,后面会介绍中文分词器。
英文分词器

这里field使用introduce,就会使用introduce的分词器english。
英文分词器会把单词的 词干 提取出来。当我们使用条件搜索的时候,也会提取查询单词的 词干 与分词结果匹配,所以搜索的时候只要有满足分词结果的 词干 就会有搜索结果。
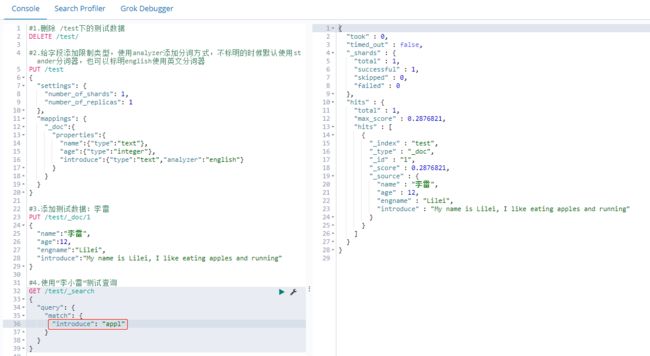
使用 "appl" 和 "apples" 可以搜索到结果,因为搜索的时候都会解析成"appl"。但是如果使用app就不能搜索到结果,因为app跟english分词器的分词结果appl不匹配。
中文分词器
中文分词需要安装插件:analysis-ik
网址:GitHub - medcl/elasticsearch-analysis-ik: The IK Analysis plugin integrates Lucene IK analyzer into elasticsearch, support customized dictionary.
安装命令:
1.进入es主目录:cd /usr/lib/elasticsearch/elasticsearch-0/
2.执行安装命令:./bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v6.8.2/elasticsearch-analysis-ik-6.8.2.zip
注意版本号一定要对应
安装完成后
cd plugins

说明已经安装好了
安装好后可以进词库文件查看词库,命令:
cd /usr/lib/elasticsearch/elasticsearch-0/config/analysis-ik/
vi main.dic

词库量很大不做展示。接下来做测试。
测试脚本(需要删除历史数据重新创建):
#1.删除 /test下的测试数据
DELETE /test/
#2.给字段添加限制类型,使用analyzer添加分词方式,不标明的时候默认使用standard分词器,也可以标明english使用英文分词器
PUT /test
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 1
},
"mappings": {
"_doc":{
"properties":{
"name":{"type":"text"},
"age":{"type":"integer"},
"introduce":{"type":"text","analyzer":"english"},
"address":{"type":"text","analyzer":"ik_max_word"},
"address2":{"type":"text","analyzer":"ik_smart"}
}
}
}
}
#3.添加测试数据:李雷
PUT /test/_doc/1
{
"name":"李雷",
"age":12,
"engname":"Lilei",
"introduce":"My name is Lilei, I like eating apples and running",
"address":"我家住在南京市长江大桥",
"address2":"我家住在南京市长江大桥"
}
#4.测试中文分词
GET /test/_search
{
"query": {
"match": {
"address": "南京市"
}
}
}
#测试中文分词器ik_max_word
GET /test/_analyze
{
"field": "address",
"text" : "我家住在南京市长江大桥"
}
#测试中文分词器ik_smart
GET /test/_analyze
{
"field": "address2",
"text" : "我家住在南京市长江大桥"
}analysis-ik 插件支持两种分词器:
第一种是 ik_max_word 分词器
这种分词器几乎会把所有词汇进行分词。例:
注意:使用GET方法测试分词结果。"field": "address"的时候,就会使用address指定的分词器 ik_max_word

在进行搜索的时候,只用满足其中的一个词汇就能搜索到结果,例:

关键词“南京”可以在分词结果里找到,所以可以搜索到结果。其他像“我”、“我家”、“住在”这些包含在分词结果里的词汇都可以搜索到结果,但是用“住”就不能找到,因为“住”不在分词结果里。使用“我家住”能找到,因为满足了“我”或者“我家”。
第二种是 ik_smart 分词器
注意:使用GET方法测试分词结果。"field": "address2"的时候,就会使用 address2 指定的分词器 ik_smart

ik_smart 分词的粒度就粗很多。搜索的时候满足其中的词汇就能搜索出结果。例:

这两种分词器该怎么配合使用呢?
在建索引的时候使用 ik_max_word 分词器,这样分的词可以更细。
在搜索的时候使用 ik_smart 分词器,这样在搜索的时候分的词粒度更粗,只用查更少的词,能提高效率。
例:

这么配置就可以在搜索的时候使用 ik_smart 分词器,建索引的时候使用 ik_max_word 分词器了。