[阅读记录]《数据分析师求职面试指南》-1
写在最前面的一些碎碎念:对于《数据分析师求职面试指南》的阅读记录,大概会按照个人的阅读进度来更,所以每篇结束的地方可能不是章节结束的地方(●'◡'●)
目录
第一章 面试前的准备
第二章 直面数据分析师面试
第三章 基础知识考察
统计及数据分析知识
基础概念:随机变量、分布函数、概率密度函数
随机变量的常用特征
正态分布与大数定理、中心极限定理
假设检验
第一章 面试前的准备
第一章首先介绍了常见的数据类岗位,具体分为算法工程师、数据挖掘工程师、数据分析师、数据产品经理和数据仓库工程师,算法工程师侧重技术支持,数据产品经理侧重业务落地。具体的岗位选择则需要根据自己的能力及偏好筛选。而通用的要求具备以下几点:
1.具备扎实的基础知识/编程能力
2.拥有丰富的项目经验
3.具有积极的学习态度
接着作者针对数据类岗位的简历提出建议,包括如何描述数据类项目:以数据为导向、流程明确、突出技术点;最后作者给出了求职可用的一些软件:猎聘、拉勾、BOSS直聘等。
第二章 直面数据分析师面试
首先介绍了通用的面试流程:笔试→部门内部成员面试→部门负责人面试→总监面试→HR面试
- 笔记侧重基础知识,包括概率论、数理统计、数据挖掘等内容
- 部门内部成员面试侧重理论知识及实践技能、业务尝试、编程技能、沟通能力
- 部门负责人面试侧重”潜力“,需要表现出创造力
- 总监面试侧重大局观,给出未来职业规划、对公司发展、行业格局的理解
- HR面试侧重稳定性,体现对公司的认同
接着作者给出了一些常见的数据分析师面试问题,涉及概率论与数理统计、数据挖掘方面
第三章 基础知识考察
统计及数据分析知识
基础概念:随机变量、分布函数、概率密度函数
什么是随机变量?
随机变量是用来描述随机试验结果的,而随机试验指的是在同等条件下能够对某随机现象进行重复观测,具备三个条件:结果的不可预见性,但可以列出全部可能结果;同等条件下可重复实验;实验结果以随即方式出现。
举例:例如某个APP发放优惠券,用户是否使用则是一个随机试验,而对于优惠券转换率X而言,就是一个随机变量
如何区分不同的随机变量?
可以根据随机变量的分布来区分不同的随机变量
什么是样本?样本和随机变量之间有什么关系?
样本是每次随机试验的结果,也称”观测值“
举例:例如,优惠券转化率为X,而每张优惠券是否被使用可以记为x1,x2,……,X就是这些样本的均值
随机变量是怎么进行分类的?分类依据是什么?
随机变量可以分为离散型和连续型,二者区别是是否可数,例如网站点击率可以计数为0,1,2,3,则是可数的离散型变量,而转化率可以是【0,1】之间任意数,不可以枚举出来,则为不可数的连续型变量
常见的离散型随机变量有哪些?各自有什么样的分布律?
对于离散型随机变量,通常用Pr来描述某个试验结果发生概率,不同的分布律对应不同分布
- 伯努利分布:也称0-1分布,“非A即B”,Pr(X=0)=1-Pr(X=1)
- 二项分布:n个重复独立的伯努利分布(每个伯努利分布事件发生概率均为p,且各试验相互独立互不干扰)
- 泊松分布:适合描述在单位时间内随机事件发生的次数,对于一些没有提前了解过的试验,都可以用泊松分布进行初步描述
常见的连续型随机变量有哪些?各自有什么样的概率密度?
首先需要定义分布函数,通常用F(x)表示,F(x)=Pr(X≤x),因此也称累积分布函数(CDF),如果存在f(x)为F(x)的导数,则称f(x)为概率密度函数(PDF)
- 均匀分布:即概率密度函数在结果区间内为固定数值的分布
- 正态分布:概率密度函数满足
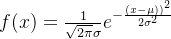
- 指数分布:有一个很大的特点是无记忆性
随机变量的常用特征
用来描述随机变量的数字特征有哪些?
- 期望:随着试验次数增加,X的均值会愈发趋于E(X)
- 方差和标准差:标准差是方差的平方根,有了期望和标准差之后就可以通过公式
 得到对应标准化变量
得到对应标准化变量 - 分位数
- 协方差及相关系数:关注两个或多个随机变量之间的关系,当XY相互独立时,协方差和相关系数均为0,当相关系数绝对值接近于1时,表示二者之间线性关系较强。
随机变量X+Y、XY的期望与X、Y期望的关系?
E(X+Y)=E(X)+E(Y):对于XY无约束;E(XY)=E(X)E(Y):XY一定是独立变量,反之不一定成立,只能证明XY不相关,不能证明独立(不相关与独立的区别之后会讲到)
分布的期望和中位数的大小关系?
二者大小关系根据分布的不同而变化,正态分布下二者相等,正偏态情况下中位数小于期望,负偏态情况下中位数大于期望。
简述变量独立与变量不相关的区别?
不相关指的是二者没有线性关系,但不排除其他关系的存在,独立则是二者毫无关系
常见分布的期望和方差是什么?
离散型
- 伯努利:期望p,方差p(1-p)
- 二项:期望np,方差np(1-p)
- 泊松:期望和方差都是

连续型
- 均匀分布:期望(a+b)/2,方差(b-a)²/12
- 正态分布:期望
 ,方差
,方差 ²
² - 指数分布:期望
 ,方差
,方差
正态分布与大数定理、中心极限定理
正态分布又称高斯分布
正态分布的基本特性是什么?
概率密度函数以期望为中心左右对称,期望=中位数,呈现“中间高、两边低”的情形
3σ方法与正态分布之间存在怎样的关联?
样本落在3σ之外的概率仅有0.27%,因此这部分误差不再属于随机误差,而是粗大误差,应将这部分数据予以剔除
大数定律:核心在于随着试验次数增加,X均值会愈发趋近于期望
简述常见的大数定律,以及它们之间的区别
辛钦大数定律、伯努利大数定理、切比雪夫大数定律,涉及到中心极限定理(对于一组足够大的样本,无论其原本服从什么分布,最终都能转换为正态分布)
假设检验
通常需要对一些项目或产品的效果进行分析,判断新功能上线后是否会带来负面影响,因此需要假设检验
假设检验中,原假设和备择假设常用的划分方法是什么?
原假设即为H0,备择假设记为H1,二者选择是基于实际需要。检验统计量是用于接受或拒绝原假设的,常用的有t统计量和z统计量
假设检验的基本思想?
通过证明该样本对应的p-value小于α,以此推翻原假设,接受备择假设