MySQL分区操作详解
什么是分区表
分区表是一个独立的逻辑表,但是底层由多个物理子表组成。对分区表的请求,都会通过句柄对象转化成对存储引擎的接口调用。所以分区对于 SOL 层来说是一个完全封装底层实现的黑盒子,对应用是透明的,但是从底层的文件系统来看就很容易发现,每个分区表都有一个使用#分隔命名的表文件。
分区表的用途
如果有一张非常大的表,我们查询这张表时,无法将其全部放到内存中,由于数据量巨大,所以不能使用全表扫描,而索引在数据量巨大的时候会产生大量的碎片导致随机IO,所以也无法使用索引来优化(除非是覆盖索引),这个时候就可以考虑使用分区了
分区以代价非常小的方式定位到需要的数据在哪一片“区域”。在这片“区域”中,你可以做顺序扫描,可以建索引,还可以将数据都缓存到内存等等操作
分区表的操作
SELECT操作
当查询一个分区表的时候,分区层先打开并锁住所有的底层表,优化器先判断查询中是否有条件可以过滤部分分区,然后再调用底层代码访问表
INSERT操作
当写入一条记录时,分区层先打开并锁住所有的底层表,然后确定这条记录该写入哪个分区,再将记录写入对应底层表
DELETE操作
当删除一条记录时,分区层先打开并锁住所有的底层表,然后确定要删除的数据所对应的分区,最后对相应底层表进行删除操作。
UPDATE操作
当更新一条记录时,分区层先打开并锁住所有的底层表,MySOL 先确定需要更新的记录在哪个分区,然后取出数据并更新,再判断更新后的数据应该放在哪个分区最后对底层表进行写入操作,并对原数据所在的底层表进行删除操作。
判断mysql是否支持分区
调用SHOW PLUGINS;
如果出现了下列信息,则说明支持分区
![]()
5.4版本前可以使用
SHOW VARIABLES LIKES '%PARTITION%'
如果出现了
| have_partition_engine | YES |则说明支持分区
创建分区表
Range分区
RANGE分区是一种MySQL数据库分区策略,用于根据指定的列的范围值将数据分割成不同的分区。
使用RANGE分区时,需要先选择一个列作为分区的基准列,然后定义每个分区的范围值。
创建一个Range分区的分区表
PARTITION BY RANGE(将值作为基准列的列名)(
PARTITION 分区1 VALUES LESS THAN (值),
PARTITION 分区2 VALUE LESS THAN (值),
...
)示例代码:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (YEAR(hired))(
PARTITION p1 VALUES LESS THAN (2015),
PARTITION p2 VALUES LESS THAN (2020),
PARTITION p3 VALUES LESS THAN (2022),
PARTITION p4 VALUES LESS THAN (2030)
)添加一些数据
INSERT INTO employees (id, fname, lname, hired, separated, job_code, store_id) VALUES
(1, 'John', 'Doe', '2010-01-01', '9999-12-31', 1, 1),
(2, 'Jane', 'Smith', '2011-02-02', '9999-12-31', 2, 1),
(3, 'Michael', 'Johnson', '2012-03-03', '2020-01-01', 3, 2),
(4, 'Emily', 'Williams', '2013-04-04', '9999-12-31', 1, 2),
(5, 'William', 'Brown', '2014-05-05', '2021-01-01', 2, 1),
(6, 'Olivia', 'Jones', '2015-06-06', '9999-12-31', 3, 3),
(7, 'Liam', 'Garcia', '2016-07-07', '2022-01-01', 1, 2),
(8, 'Sophia', 'Martinez', '2017-08-08', '9999-12-31', 2, 1),
(9, 'James', 'Rodriguez', '2018-09-09', '2023-01-01', 3, 3),
(10, 'Ava', 'Hernandez', '2019-10-10', '9999-12-31', 1, 2),
(11, 'Logan', 'Gonzalez', '2020-11-11', '2024-01-01', 2, 1),
(12, 'Mia', 'Lopez', '2021-12-12', '9999-12-31', 3, 3),
(13, 'Benjamin', 'Perez', '2012-01-01', '2025-01-01', 1, 1),
(14, 'Charlotte', 'Torres', '2013-02-02', '9999-12-31', 2, 2),
(15, 'Elijah', 'Rivera', '2014-03-03', '2026-01-01', 3, 3),
(16, 'Amelia', 'Turner', '2015-04-04', '9999-12-31', 1, 1),
(17, 'Lucas', 'Collins', '2016-05-05', '2027-01-01', 2, 2),
(18, 'Harper', 'Wood', '2017-06-06', '9999-12-31', 3, 3),
(19, 'Mason', 'Ward', '2018-07-07', '2028-01-01', 1, 1),
(20, 'Evelyn', 'Cooper', '2019-08-08', '9999-12-31', 2, 2),
(21, 'Ethan', 'Harris', '2020-09-09', '2029-01-01', 3, 3),
(22, 'Lily', 'Peterson', '2021-10-10', '9999-12-31', 1, 1),
(23, 'Daniel', 'Gomez', '2022-11-11', '2030-01-01', 2, 2),
(24, 'Grace', 'Cruz', '2023-12-12', '9999-12-31', 3, 3),
(25, 'Alexander', 'Edwards', '2014-01-01', '2031-01-01', 1, 1),
(26, 'Lillian', 'Morales', '2015-02-02', '9999-12-31', 2, 2),
(27, 'Henry', 'Bennett', '2016-03-03', '2032-01-01', 3, 3),
(28, 'Addison', 'Richardson', '2017-04-04', '9999-12-31', 1, 1),
(29, 'Andrew', 'Wood', '2018-05-05', '2033-01-01', 2, 2),
(30, 'Aubrey', 'Sullivan', '2019-06-06', '9999-12-31', 3, 3),
(31, 'Joseph', 'Clark', '2020-07-07', '2034-01-01', 1, 1),
(32, 'Natalie', 'Mitchell', '2021-08-08', '9999-12-31', 2, 2),
(33, 'David', 'Perez', '2022-09-09', '2035-01-01', 3, 3),
(34, 'Zoe', 'Morgan', '2023-10-10', '9999-12-31', 1, 1),
(35, 'Noah', 'Ruiz', '2024-11-11', '2036-01-01', 2, 2),
(36, 'Riley', 'Campbell', '2025-12-12', '9999-12-31', 3, 3),
(37, 'Samuel', 'Flores', '2016-01-01', '2037-01-01', 1, 1),
(38, 'Chloe', 'Gutierrez', '2017-02-02', '9999-12-31', 2, 2),
(39, 'Penelope', 'Lee', '2018-03-03', '2038-01-01', 3, 3),
(40, 'Isaac', 'Gonzales', '2019-04-04', '9999-12-31', 1, 1),
(41, 'Aria', 'Nelson', '2020-05-05', '2039-01-01', 2, 2),
(42, 'Xavier', 'Carter', '2021-06-06', '9999-12-31', 3, 3),
(43, 'Hannah', 'Parker', '2022-07-07', '2040-01-01', 1, 1),
(44, 'Gabriel', 'Mendoza', '2023-08-08', '9999-12-31', 2, 2),
(45, 'Avery', 'Rivera', '2024-09-09', '2041-01-01', 3, 3),
(46, 'Levi', 'Gomez', '2025-10-10', '9999-12-31', 1, 1),
(47, 'Grace', 'Diaz', '2026-11-11', '2042-01-01', 2, 2),
(48, 'Mila', 'Brown', '2027-12-12', '9999-12-31', 3, 3),
(49, 'Luke', 'Hayes', '2018-01-01', '2043-01-01', 1, 1),
(50, 'Aurora', 'Russell', '2019-02-02', '9999-12-31', 2, 2),
(51, 'Owen', 'Ortiz', '2020-03-03', '2044-01-01', 3, 3),
(52, 'Layla', 'Simpson', '2021-04-04', '9999-12-31', 1, 1),
(53, 'Carter', 'Fuller', '2022-05-05', '2045-01-01', 2, 2),
(54, 'Skylar', 'Ruiz', '2023-06-06', '9999-12-31', 3, 3),
(55, 'Wyatt', 'McDonald', '2024-07-07', '2046-01-01', 1, 1),
(56, 'Claire', 'Santiago', '2025-08-08', '9999-12-31', 2, 2),
(57, 'Bentley', 'Gregory', '2026-09-09', '2047-01-01', 3, 3),
(58, 'Stella', 'Ramirez', '2027-10-10', '9999-12-31', 1, 1),
(59, 'Cameron', 'Schmidt', '2028-11-11', '2048-01-01', 2, 2),
(60, 'Brooklyn', 'Weber', '2029-12-12', '9999-12-31', 3, 3);查看分区以及分区信息
SELECT
PARTITION_NAME AS 分区名,
PARTITION_EXPRESSION AS 分区列,
TABLE_ROWS AS 分区表所含列数,
PARTITION_DESCRIPTION AS 分区范围,
PARTITION_METHOD AS 分区类型
FROM
information_schema.PARTITIONS
WHERE
table_name = "employees"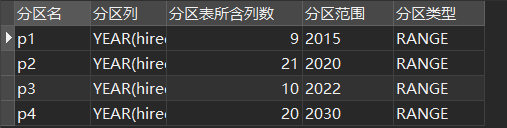
如果想要查看分区的全部消息,可以使用
SELECT
*
FROM
information_schema.PARTITIONS
WHERE
table_name = "employees"其他分区都可以使用上面这种方式来查看
使用指南
- RANGE分区可以使用任意各种函数,但是要求必须是一个整数值,且不能是一个常量值
- RANGE分区是使用频率最高的分区方法
List分区
List分区类似于Range分区,LIST分区中定义分区和选择分区是依据某列的值属于一个列表集中的一个值
可以用下面的格式创建一个分区表。
PARTITION BY LIST (列名)(
PARTITION 分区名 VALUES IN (值1,值2,...),
PARTITION 分区名1 VALUES IN (值3,值4,...)
)创建一个List分区的分区表
示例代码
CREATE TABLE factory(
factory_name VARCHAR(30),
factory_code INT,
factory_id INT
)
PARTITION BY LIST(factory_id)(
PARTITION list1 VALUES IN (1,3,5,7,9),
PARTITION list2 VALUES IN (2,4,6,8,10)
)插入示例数据
INSERT INTO factory (factory_name, factory_code, factory_id) VALUES
('Factory A', 1001, 1),
('Factory B', 1002, 2),
('Factory C', 1003, 3),
('Factory D', 1004, 4),
('Factory E', 1005, 5),
('Factory F', 1006, 6),
('Factory G', 1007, 7),
('Factory H', 1008, 8),
('Factory I', 1009, 9),
('Factory J', 1010, 10);
Hash分区
Hash分区主要用来确保数据在预先确定数目的分区中平均分布,在RANGE和LIST分区中,必须明确指定一个给定的列值或集合,而在HASH分区中,MySQL 自动完成确定存储到哪个分区的工作,我们只需要指定一个用于分区的列或者一个表达式(不是所有数据类型都能被使用),以及指定被分区的表将要被分割成的分区数量即可
创建分区
PARTITION BY HASH(列)
PARTITIONS n;示例代码
CREATE TABLE student (
id INT NOT NULL,
birthday DATE NOT NULL DEFAULT '1970-01-01',
name VARCHAR(30) NOT NULL
)
PARTITION BY HASH(id)
PARTITIONS 4;下面的查询会创建60行id随机分布的数据
INSERT INTO student (id, birthday, name)
SELECT
seq.id,
DATE_ADD('1970-01-01', INTERVAL FLOOR(RAND() * 365*20) DAY),
CONCAT('Student', seq.id)
FROM
(SELECT 1 AS id UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5) AS seq
CROSS JOIN
(SELECT 1 AS a UNION SELECT 2 UNION SELECT 3 UNION SELECT 4 UNION SELECT 5) AS seq2;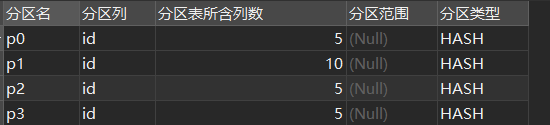
Linear Hash分区
MySQL还支持线性哈希功能,它与常规哈希的区别在于,线性哈希功能使用的一个线性的2的幂(powers-of-two)hash算法,而常规 哈希使用的是求哈希函数值的模数。
线性哈希分区的优点在于增加、删除、合并和拆分分区将变得更加快捷,有利于处理含有极其大量数据的表。它的缺点在于,与使用常规HASH分区得到的数据分布相比,各个分区间数据的分布不大可能均衡。
定义线性hash分区
PARTITION BY LINEAR HASH(列)
PARTITIONS n;CREATE TABLE student (
id INT NOT NULL,
birthday DATE NOT NULL DEFAULT '1970-01-01',
name VARCHAR(30) NOT NULL
)
PARTITION BY LINEAR HASH(id)
PARTITIONS 4;Key分区
使用KEY进行分区类似于HASH分区, KEY分区的 哈希函数是由MySQL 服务器提供, MySQL Cluster使用函数MD5()来实现KEY分区;对于使用其他存储引擎的表,服务器使用其自己内部的 哈希函数,这些函数与PASSWORD()是一样的运算法则
定义n个Key分区
PARTITION BY KEY (列名)
PARTITIONS n示例代码
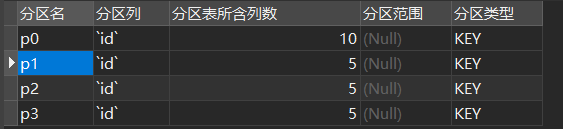
CREATE TABLE `student` (
`id` int(11) NOT NULL,
`birthday` date NOT NULL DEFAULT '1970-01-01',
`name` varchar(30) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1
PARTITION BY KEY(id)
PARTITIONS 4 运行截图
子分区
如果在一张表中数据量过大,可以考虑使用在原有的分区上建立子分区。子分区就是分区表中每个分区的再次分割。注意:原有的分区需要为RANGE分区和LIST分区,子分区既可以使用HASH希分区,也可以使用KEY分区
设置子分区
PARTITION BY RANGE/List (列1)
SUBPARTITION BY HASH/KEY (列2)
SUBPARTITIONS nCREATE TABLE ts (
id INT,
purchased DATE )
PARTITION BY RANGE (YEAR ( purchased ))
SUBPARTITION BY HASH (TO_DAYS( purchased ))
SUBPARTITIONS 2
( PARTITION p0 VALUES LESS THAN ( 1990 ),
PARTITION p1 VALUES LESS THAN ( 2050),
PARTITION p2 VALUES LESS THAN MAXVALUE );插入60条示例数据:
INSERT INTO ts (id, purchased) VALUES
(1, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(2, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(3, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(4, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(5, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(6, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(7, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(8, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(9, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(10, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(11, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(12, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(13, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(14, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(15, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(16, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(17, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(18, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(19, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(20, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(21, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(22, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(23, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(24, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(25, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(26, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(27, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(28, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(29, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(30, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(31, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(32, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(33, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(34, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(35, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(36, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(37, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(38, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(39, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(40, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(41, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(42, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(43, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(44, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(45, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(46, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(47, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(48, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(49, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(50, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(51, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(52, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(53, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(54, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(55, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(56, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(57, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(58, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(59, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY)),
(60, DATE_ADD('1900-01-01', INTERVAL ROUND(RAND() * 73000) DAY));查看子分区就不能通过访问PARTITION_xxx来获取分区信息了,需要使用SUBPARTITION_xxx来获取子分区的信息
SELECT
SUBPARTITION_NAME AS 子分区名,
SUBPARTITION_EXPRESSION AS 子分区列,
TABLE_ROWS AS 分区表所含列数,
PARTITION_DESCRIPTION AS 分区范围,
SUBPARTITION_METHOD AS 子分区类型
FROM
information_schema.PARTITIONS
WHERE
table_name = "ts"
定义每一个子分区
上面的子分区的名称都是按照分区名默认生成的,我们也可为每一个子分区定义具体的分区名和分区路径
PARTITION BY RANGE/LIST(列名)
SUBPARTITION BY HASH/KEY(列名)
SUBPARTITION n
(
PARTITION 分区名 VALUES ...(
SUBPARTITION 子分区名1,
SUBPARTITION 子分区名2,
...
SUBPARTITION 子分区名n
)
PARTITION 分区名 VALUES ...(
SUBPARTITION 子分区名1,
SUBPARTITION 子分区名2,
...
SUBPARTITION 子分区名n
)
)```
CREATE TABLE ts (id INT, purchased DATE)
PARTITION BY RANGE(YEAR(purchased))
SUBPARTITION BY HASH(TO_DAYS(purchased))
SUBPARTITIONS 2
(
PARTITION p0 VALUES LESS THAN (1990)(
SUBPARTITION sp1,
SUBPARTITION sp2
),
PARTITION p1 VALUES LESS THAN (2050)(
SUBPARTITION sp3,
SUBPARTITION sp4
),
PARTITION p2 VALUES LESS THAN MAXVALUE(
SUBPARTITION sp5,
SUBPARTITION sp6
)
);这种写法中, SUBPARTITIONS 2可以去掉
还是按照上面的方式插入60个数据:查看运行结果

注意:如果真的定义每个子分区,那么每个分区都需要拥有相同数量的子分区,不然会报错
,且子分区名称不能重复。
管理分区
管理LIST和RANGE分区
RANGE和LIST分区非常相似,所以这两个分区的管理介绍放到一起
删除分区
示例分区
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (YEAR(hired))(
PARTITION p1 VALUES LESS THAN (2015),
PARTITION p2 VALUES LESS THAN (2020),
PARTITION p3 VALUES LESS THAN (2022),
PARTITION p4 VALUES LESS THAN (2030)
)
删除分区又分为了三种方式
1. 删除分区包括分区中的数据
语法:
ALTER TABLE 表名
DROP PARTITION 分区名示例程序
- 首先查看还有p2分区中还是有数据的
SELECT COUNT(*) from employees
WHERE YEAR(hired) BETWEEN 2015 AND 2020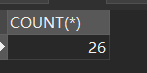
- 删除分区
ALTER TABLE employees
DROP PARTITION p2- 检查数据
SELECT
*
FROM
employees
WHERE
YEAR ( hired ) BETWEEN 2015 AND 2020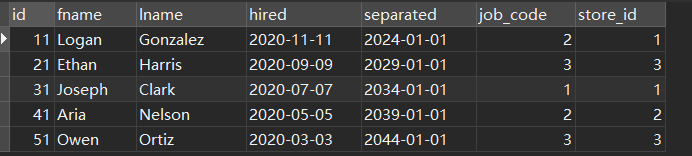

可以看到所有p2 分区(2015~2020)的数据都已经被删除了
2. 删除分区数据,但是保留该分区配置信息
删除特定分区数据
DELETE FROM 表名 PARTITION (分区名);示例程序:
DELETE FROM employees PARTITION (p3)运行结果:

SELECT * FROM `employees` WHERE YEAR(hired) BETWEEN 2015 AND 2022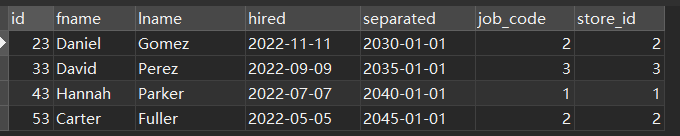
删除所有分区数据
TRUNCATE TABLE 表名这种方法实际上直接完全重构了表,比一行行的删除速度快很多
示例程序:
TRUNCATE TABLE employees
3. 删除分区,分区数据将重新放入其他分区
ALTER TABLE 表名 REORGANIZE PARTITION 要删除的分区,该分区后一个分区 INTO (
PARTITION 该分区后一个分区 VALUES LESS THAN (2030)
)这样的操作实际上相当于将分区重新组织了一遍,这样之后虽然数据没有被删除,但是没有放入该放入的分区,需要重新组织一下分区表才能将数据放入分区中
ALTER TABLE 表名 ENGINE=存储引擎名;示例程序:
ALTER TABLE employees REORGANIZE PARTITION p3,p4 INTO (
PARTITION p4 VALUES LESS THAN (2030)
)
运行结果

添加分区
RANGE分区添加分区
ALTER TABLE 表名
ADD PARTITION (
PARTITION 分区名 VALUES LESS THAN (整数)
)示例代码:

RANGE添加分区只能在所有分区的后面添加,不能在分区中间或者前面添加,下面这种代码会报错
ALTER TABLE employees
ADD PARTITION (
PARTITION p5 VALUES LESS THAN (2020)
)
> 1493 - VALUES LESS THAN value must be strictly increasing for each partition添加在所有分区之后
ALTER TABLE employees
ADD PARTITION (
PARTITION p5 VALUES LESS THAN (2040)
)
基于RANGE的这种限制,我们要谨慎在RANGE分区中创建VALUES LESS THAN ()
LIST分区添加分区
ALTER TABLE 表名
ADD PARTITION (
PARTITION 分区名 VALUES IN (数值1,数值2)
)
示例代码
LIST分区中,不允许新建的LIST分区中的数值与前面所建立分区有重复,下面的代码会报错
ALTER TABLE factory
ADD PARTITION (
PARTITION list3 VALUES IN (9)
)
> 1517 - Duplicate partition name list3每个LIST分区不重复
ALTER TABLE factory
ADD PARTITION (
PARTITION list3 VALUES IN (11,12,14)
)

拆解合并分区
前面的章节中我们已经接触过了REORGANIZE TABLE指令,其实这个指令是用于拆解,合并分区的指令
完整指令如下:
ALTER TABLE tbl_name REORGANIZE PARTITION partition_list INTO (partition_definitions);其中,tbl_name 是分区表的名称,partition_list 是通过逗号分开的、一个或多个要被合并或拆解的现有分区的列表。partition_definitions 是一个是通过逗号分开的、新分区定义的列表,在把多少个分区合并到一个分区或把一个分区拆分成多少个分区方面,没有限制
合并分区示例代码

ALTER TABLE employees
REORGANIZE PARTITION p4,p5 INTO(
PARTITION p3 VALUES LESS THAN (2040)
)
一定要记得重新组织表
ALTER TABLE employees ENGINE = INNODB
拆解分区示例代码
下面这行代码会把p6拆解为p4和p5
ALTER TABLE employees
REORGANIZE PARTITION p6 INTO(
PARTITION p4 VALUES LESS THAN (2045),
PARTITION p5 VALUES LESS THAN (2060)
)
也需要重新组织一下表
拆解和合并一定要遵循以下原则:
- 拆解时,一定要让拆解后的各个分区能够覆盖掉原分区的区间,下面这种拆分会报错

ALTER TABLE employees
REORGANIZE PARTITION p6 INTO
(
PARTITION p4 VALUES LESS THAN(2050),
PARTITION p5 VALUES LESS THAN(2060)
)
> 1520 - Reorganize of range partitions cannot change total ranges except for last partition where it can extend the range
- 拆解时,一定要保证不能越过原分区的区间
ALTER TABLE employees
REORGANIZE PARTITION p6 INTO(
PARTITION p4 VALUES LESS THAN (2030),
PARTITION p5 VALUES LESS THAN (2070)
)
> 1493 - VALUES LESS THAN value must be strictly increasing for each partition
> 时间: 0.003s
KEY和HASH分区
添加分区
下面的代码会把分区增加为n个分区
ALTER TABLE 表名 ADD PARTITION PARTITIONS n;减少分区
下面的代码会把分区减少为n个分区
ALTER TABLE 表名 COALESCE PARTITION n;分区查询不能进行的SELECT优化
用于测试的emplyees分区表的分区信息

可以查看查询语句使用的分区信息
EXPLAIN PARTITIONS 查询语句示例程序:
EXPLAIN PARTITIONS
SELECT fname FROM employees ![]()
这段查询无法使用分区来优化,所以partitions显示为所有分区都使用了
EXPLAIN PARTITIONS
SELECT fname FROM employees WHERE hired>'2021-01-01'![]()
在其中加入了判断条件之后可以看到优化器确实按照分区来优化了这段查询
无法执行优化的示例:
- 查询条件没有直接使用列名
EXPLAIN PARTITIONS
SELECT fname FROM employees WHERE YEAR(hired)>2021![]()
上面的查询并没有使用分区来优化。
从这里也可以看出无法使用分区来优化查询的情形为:
查询条件中带入的不是列,而是分区列的表达式,就算是创造分区表时传入的用于分区的表达式也不能通过分区优化
- 表中有NULL值
分区表没有禁止插入NULL值,一般而言,MySQL 把NULL视为0。如果你希望回避这种情况,你应该在设计表时不允许空值;最可能的方法是,通过声明列“NOT NULL”
PDF下载地址
如果决定csdn默认文章样式看的不舒服,可以下载这个pdf
链接:百度网盘 请输入提取码
提取码:a1a5