数据库系统原理(五)
课程三:数据建模与数据库设计
5.1为什么要数据建模与数据库设计?
对用户需求的理解,包括数据需求和处理规则需求的理解。
5.1.1 数据模型与概念模型
数据模型: 表达计算机世界的模型
概念模型: 表达信息世界的模型(概念数据模型)
信息世界是对现实世界的理解与抽象
数据建模是抽象,抽象是理解-区分-命名-表达
现实世界需要理解:现实中的卡片,单据,表格。。。
理解的标志是区分:表与表的区分,表内数据项的区分,数据项之间关系的区分,表之间关系的区分
区分的标志是命名:命名表,命名数据项,命名表之间的联系
抽象的最终结果是正确的表达:用其他人能理解的表达方式来表达(E-R图/Crow‘ Foot/IDEF1X)
5.2 E-R模型
E-R模型: 实体关系模型;世界是由一组称作实体的基本对象和这些对象之间的联系构成的
5.2.1 E-R模型基本概念
E-R模型给出了一组基本概念,用这组概念可以刻画信息世界
————实体;属性;联系;关键字/码
示例:给抽象概念赋予一定语义的新的概念
实体——学生,课程,教师
属性——学号,学生姓名,课程号,课程名…
联系——任课
关键字——学号,课程号,教师编号,教师编号
5.2.2 实体
实体: 客观存在并可相互区分的事物
实体有类(实体的型)和个体(实体的实例,值)的概念;
一类实体具有相同的特性
如何刻画实体?
实体用属性来刻画;
属性: 实体所具有的某一方面特性
属性还有很多类型:
1.单一属性与复合属性
复合属性:家庭住址-省份和详细地址;
在关系模型中,复合属性一定要转化为单一属性
2.单值属性和多值属性
多值属性:电话号码-一人可能有多个电话号码
在关系模型中,多值属性一定要转化为单值属性
3.可空值属性和非空值属性
4.导出属性(由其他属性计算得到)
关键字/码: 实体中能够用其值唯一区分开每一实例的属性或属性组合
联系: 指一个实体的实例与其他实体实例之间所可能发生的联系
参与发生联系的实体的数目,称为联系的度或元。
实体是相对稳定的,而联系是可能变化的。
角色: 实体在联系中的作用称为实体的角色。
当同一实体的不同实例参与一个联系时,为区分各实例参与联系的方式,需要显式指明其角色。
二元联系:一对一,一对多,多对多联系
1:1——实体A的实例只能和实体B的一个实例发生联系,反之,实体B的实例只能和实体A的一个实例发生联系
1:m——实体A的实例能和实体B的多个实例发生联系,反之,实体B的实例只能和实体A的一个实例发生联系
m:m——实体A的实例能和实体B的多个实例发生联系,反之,实体B的实例能和实体A的多个实例发生联系
联系的基数: 实体实例之间的联系数量,一个实体的实例通过一个联系能与另一实体中相关联的实例的数目
联系的基数还要区分时0个,1个,不定数目的多个,固定数目的多个;
通常以实体参与联系的最小基数和最大基数来标记
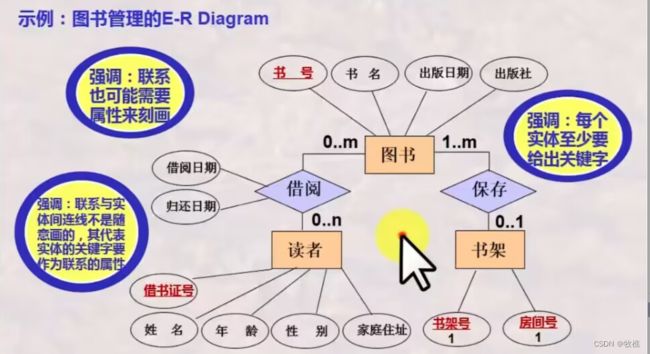
例如:
书架参与存放图书联系的基数为(0…m)-表示:一个书架最少放0个图书,最多放m个图书。
图书参与此联系的基数为(1…1)-表示:一本图书只能存放在一个书架
完全参与联系: 即该端实例至少有一个参与到联系中,最小基数为1
部分参与联系: 即该端实例可以不参与联系,最小基数为0
5.2.3 E-R模型表达方法之chen方法
E-R模型的几种图示化表达方法——chen方法
1.Chen方法的基本图元及其含义
实体:矩形框
属性:椭圆
————多值属性:双线椭圆
————导出属性:虚线椭圆
关键字/码:下划线
连接实体和属性:直线
联系:菱形框
连接实体与联系:直线
连接联系和属性:直线
复合关键字:标有相同数字
多组关键字:标有不同数字
1:1联系:箭头直线,由联系指向实体
1:m联系:指向1端为箭头直线,指向多端为无箭头直线
m:m联系:无箭头直线
也可以如下区分:都用直线,在直线旁标注1,m,n
完全/部分参与联系也可以标注最小基数…最大基数进行区分
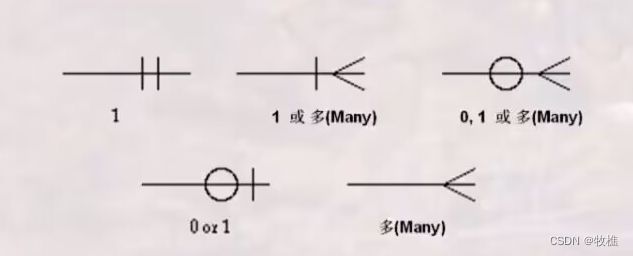
5.2.4 E-R模型表达方法之Crow’s foot方法
1.基本图元及其含义
实体:矩形框,实体的名称写在横线上面
属性:实体框横线的下面
关键字:属性下加下划线
联系:菱形框表示,也可省略,直接以联系名称
联系的基数表示方法:
5.2.5 数据库设计中的抽象
数据模型: 一组相互关联且已严格定义的概念集合,是用于刻画或描述现实世界,信息世界或计算机世界的模型
概念模型: 表达信息世界的模型
不同层面的抽象:现实世界-信息世界-计算机世界逻辑世界(语义关系)-物理世界(存储)
建模的不同层次:模型与元模型,模型与实例
5.3 IDEF1X方法
5.3.1 IDEF1X两种实体的区分
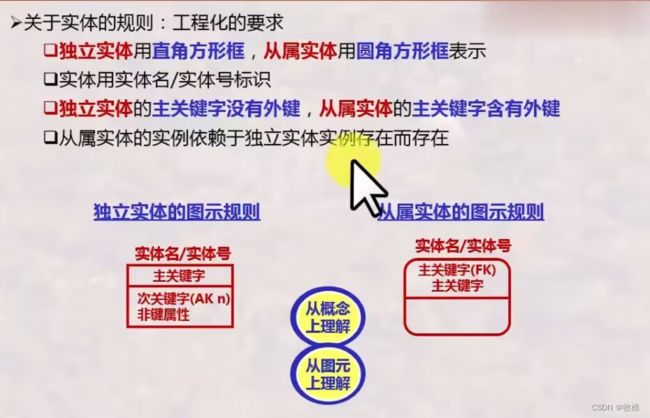
实体被区分为独立实体和从属实体
在扩展E-R图中,独立实体又称为强实体,从属实体又称弱实体。
独立实体: 一个实体的实例都被唯一的标识而不决定于它与其他实体的联系(独立实体的关键字属性是自身属性)【方框标识,参照Crow法】
从属实体: 一个实体的实例的唯一标识需要依赖该实体与其他实体的联系【圆方框标识】
- 从属实体需要从其他实体继承属性作为关键字的一部分
- 主关键字包含了外来属性的实体为从属实体
5.3.2 IDEF1X的标定联系与非标定联系
联系有连接联系,分类联系,不确定联系
连接联系: 又称父子联系或依存联系,又可进一步区分为标定联系和非标定联系
标定联系: 子实体的实例都是由它与父实体的联系而确定的,父实体主关键字是子实体主关键字的一部分(实线)
非标定联系: 子实体的实例能够被唯一标识而无需依赖于其他实体的联系。父实体的主关键字不是子实体的主关键字(虚线)
非确定联系: 实体之间的多对多联系
(非确定联系必须分解为若干个一对多的联系来表达)
相交实体/相关实体: 非确定联系通过引入相交实体来分解为若干个一对多的联系来表达
- 确定性联系通过属性继承实现两实体之间的联系
- 非确定性联系通过引入相交实体实现两实体的联系
分类联系: 一个实体实例是由一个一般实体实例及多个分类实体实例构成的
- 一个一般实体是若干具体实体的类
- 分类实体与一般实体具有相同的主关键字
- 不同分类实体除具有一般实体特征外,各自还可能具有不同的属性特征
具体化: 实体的实例集中,某些实例子集具有区别于该实例集内其他实例的特性,可以根据这些差异特性对该实例集进行分组,这一分组过程称为具体化
泛化: 若干个实体根据共有的性质,可以合成一个较高层的实体。泛化是一个高层实体与若干个低层实体之间的包含关系。
- 泛化与具体化是个互逆过程
- 具体化强调同一实体不同实例之间的差异属性,泛化强调不同实体之间的相似属性
- 自底向上或者自顶向下
具体化和泛化在E-R图中用标记为ISA的三角形来表示。
5.4 数据库设计过程
5.4.1 过程概述
1.需求分析:收集需求和理解需求,“源”
2.概念数据库设计:建立概念模型,E-R图/IDEF1X图
3.逻辑数据库设计:建立逻辑模型,“关系模型”包括全局模式和用户模式
4.物理数据库设计:建立物理模型
5.4.2 需求分析
目标:理解企业业务过程与数据处理流程。
提交物:需求分析报告
——包含以下内容:部门岗位划分;基础数据表;表之间关系;业务处理关系;未来可能实施的需求。
5.4.3 概念数据库设计
目标:进一步深入理解企业,对信息源进行抽象,发现信息之间的本质联系,这些本质联系可能隐藏于需求分析得到的信息源中
提交物:概念数据库设计报告
——包含以下内容:实体,实体属性和实体联系的发现,分析和定义;外部视图和概念视图的定义
用E-R图或IDEF1X模型描述;
1.依据需求分析报告
2.识别实体与联系
3.绘制E-R图,表达业务规则
4.定义实体,联系及实体的属性构成(消除冲突)
5.形成并提交概念数据库设计报告
5.4.4 逻辑数据库设计
目标:用指定DBMS要求的模式描述方法,给出概念数据库的逻辑模式描述
提交物:逻辑数据库设计报告
——包括以下内容:将E-R图转换成逻辑模式,遵循关系范式的设计原则;外模式和概念模式的定义。
基本转换规则:实体-属性-关键字的转换
E-R图的实体转换为关系
E-R图的属性转换为关系的属性
E-R图的关键字转换为关系的关键字
将每个分量属性作为复合属性所在实体的属性,或将复合属性本身作为所在实体的属性
将多值属性与所在实体的关键字一起组成一个新的关系
1.依据概念数据库设计报告
2.E-R图向关系模型的转换
3.检查逻辑数据库设计的正确性
4.定义全局模式和外模式
5.形成并提交逻辑数据库设计报告
5.4.5 物理数据库设计
目的:结合指定DBMS物理数据库管理方法,给出概念数据库的物理模式描述。
提交物:物理数据库设计报告
包括以下内容:DBMS选型,数据库的存储结构,完整性控制约束,确定高效的访问形式
5.5 函数依赖
函数依赖: 设R(U)是属性集合U={A1,A2,…An}上的一个关系模式,X,Y是U上的两个子集,若对R(U)的任意一个可能的关系r,r中不可能有两个元组满足在X中的属性值相等而在Y中的属性值不等。即“X函数决定Y”
候选键: 设K为R(U)中的属性或属性组合,若k全部决定该元组,则称k为候选键
- 可任选一候选键作为R的主键
- 包含在任一候选键中的属性称为主属性,其他属性称为非主属性
- 若k是R的一个候选键,s包含k,则称s为r的一个超键
外来键: 某属性或属性组合不是一关系的候选键,但却是另一关系的候选键
逻辑蕴含: 设F是关系模式R(U)中的一个函数依赖集合,X,Y是R的属性子集,如果从F中的函数依赖能够推导出X决定Y,则称F逻辑蕴含X决定Y。
闭包: 被F逻辑蕴含的所有函数依赖集合称为F的闭包
5.5.1 函数依赖的公理和定理
1.函数依赖的Armstrong公理
设R(U)是属性集U上的一个关系模式,F为该关系模式的一组函数依赖,记为R(U,F),由如下规则:
- A1自反律:若Y包含于X包含于U,则X决定F被F逻辑蕴含
- A2增广律:若X决定Y,且Z包含U,则XZ决定YZ被F逻辑蕴含
- A3传递率:若X决定Y,Y决定Z,则X决定Z被F逻辑蕴含
- 合并律:若X决定Y且X决定Z,则X决定YZ
- 为传递律:若X决定Y且WY决定Z,则XW决定Z
- 分解律:若X决定Y且Z包含于Y,则X决定Z
属性闭包: 由Armstrong公理的A1,A2,A3推导出的单一属性的集合称为F的属性闭包。
5.5.2 函数依赖的最小覆盖
覆盖: 对R(U)上的两个函数依赖集合F,G,如果F的闭包=G的闭包,则称F和G是等价的,也称F覆盖G或者G覆盖F
最小覆盖: 若F满足以下条件,则称F为最小覆盖
- F中每个函数依赖的右部都是单个属性
- 对任何X-A属于F,有F-{X决定A}不等价于F(每个函数依赖都不可或缺)
- X决定A中,X没有多于属性
5.6 关系模式设计之规范形式
5.6.1 1NF和2NF
第一范式: 若关系模式中的关系的每个分量都是不可分的数据项(原子),则称R(U)属于第一范式
不符合1NF的处理:转换为1NF;引入新的数据模型处理;
第二范式: 若关系模式满足第一范式,且U中的每一非主属性完全函数依赖于候选键,则称关系模式属于第二范式。
(第二范式消除了非主属性对候选键的部份依赖。)
5.6.2 3NF和Boyce-Codd范式
第三范式: 若关系模式满足第二范式,但不存在传递函数依赖。
Boyce-Codd: 若关系模式中,任何函数依赖都依赖于候选键,如果依赖于属性组合,该组合包含候选键。
(若满足BCNF,则一定满足3NF)
5.6.3 多值依赖与关系的4NF
多值依赖:

第四范式: 如果有多值依赖,则一定依赖于候选键
(第四范式消除了非主属性对候选键以外属性的多值依赖)
5.7 模式分解存在的问题
模式分解: 关系模式的分解是指用R的一组子集来代替它,满足所以子集的并集等于R。
关于模式分解的特性:
1.数据内容的等价性—— 模式分解后的若干关系,再次连接,得到一个新的总关系,其元组数目多于原关系。(多于元组为错误信息)
2.数据约束的等价性——
5.7.1 无损连接分解
无损连接分解: 对于关系模式R(U,F),U是属性全集,F是函数依赖集合,p是一个分解,如果对于R的任何满足函数依赖集F的关系r,有r=m®,称p是R相对于F的一个无损连接分解。
无损连接性检验算法:


无损连接分解的性质:
- 对于关系模式进行一次无损连接分解,对得到的结果再进行一次无损连接分解,最终得到的结果也是对原关系模式的无损连接分解。
- 对于无损连接分解的结果增加新的模式,新的结果仍是无损连接分解。
5.7.2 保持依赖分解
保持依赖分解:

保持依赖分解的检验算法:

5.7.3 关系模式分解成3NF或BCNF
无损连接分解成BCNF得算法:

关系模式保持依赖分解成3NF算法:
