数据库内核那些事|PolarDB X-Engine:如何构建1/10成本的事务存储引擎?
1. 技术背景
云原生数据库PolarDB MySQL版是阿里云自研产品,100%兼容MySQL。产品具有多主多写、多活容灾、HTAP等特性。交易和分析性能最高分别是开源数据库的6倍和400倍,TCO低于自建数据库50%。
X-Engine引擎是PolarDB为用户提供的低成本,高性价比的解决方案,LSM-tree分层存储结合标准zstd压缩,在性能和成本做到了很好的平衡。在标准sysbench场景下,存储空间相比InnoDB引擎减少60%,读写性能降低10-20%。X-Engine引擎通过压缩减少了存储空间,但由于PolarStore这种分布式块存储面向高吞吐,低延迟的场景而设计,介质全部采用的是高端SSD和昂贵的RDMA网络,对于归档性和冷数据场景,压缩后存储成本依然较高。
1.1 对象存储的特性
云上的对象存储面向海量数据、低成本、高可靠的场景设计,可以很好的解决低成本存储诉求,产品包括AWS S3、Azure Blob storage、Alibaba OSS……这些存储系统的特点类似:
1. Key-Value的数据组织方式,key是数据的path,value是data object(file);
2. 超低成本,以OSS对比PolarStore为例,成本下降10倍;
3. 超高扩展性,可以认为是近乎无限的存储容量;
4. 超高持久性,写入后不用担心数据的丢失;
5. 单次读取的延迟较大;
6. Data object(file)支持按字节偏移量的范围读,但写只能是追加写或者覆盖写,也就是partial read + overwrite。
以阿里云的对象存储产品OSS为例:

1.2 X-Engine为什么适合使用OSS
对象存储是基于对象的,每个对象都有一个唯一的标识符,并且不支持修改,因为文件的修改会产生多个版本,需要引入更为复杂的一致性管理并占用更多的存储空间。因此,对象存储只支持覆盖写。这种特性使对象存储并不适合用于就地更新的存储结构,写放大问题会比较严重,随机更新性能较弱。例如MariaDB提供的支持S3对象存储的低成本引擎,数据归档后并不支持修改,而且InnoDB到S3引擎的转换需要非常长的时间。
X-Engine是LSM-tree结构,使用Copy-on-Write(CoW)方式来写入新增数据至Memtable,等后续刷到磁盘上再由后台线程进行新旧数据的合并。相较于就地更新的存储结构,对象存储只支持覆盖写的特性对LSM-tree的影响并不大,LSM-tree能够很自然的支持对存储在对象存储上的归档数据进行更新。而且LSM-tree天然具有冷热分层的特性,上层的数据热,下层的数据冷,底层的数据量大于上层所有数据量之和。这种特性适合结合多种存储介质做分层存储,大部分数据存储在对象存储上,小部分数据存储在性能更高的介质上,同时兼顾性能和成本。
为此,X-Engine考虑结合OSS对象存储,进一步降低冷数据成本,同时保留MySQL生态特征。

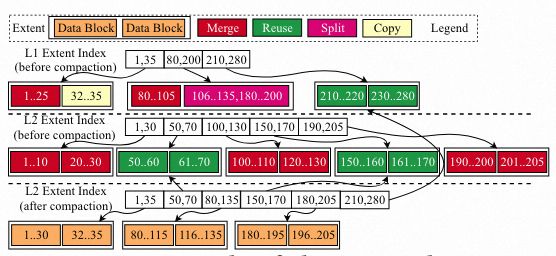
1. 支持OSS介质的X-Engine表,将SST的内容都存储在OSS上。
2. L2数据存储在OSS上,增量部分仍然先写入到memtable,慢慢流转到OSS。
3. X-Engine内部的存储格式不变,仍然是extent->block组织方式。
4. RW和RO节点共享一份OSS数据。
5. Standby有单独的checkpoint+slog,有单独的一份PolarStore+OSS数据。
核心优势:
1. 归档表支持实时更新,无需来回转换引擎;
2. DDL变更支持归档OSS特性秒级完成,后台异步转换到OSS。
2. X-Engine适配OSS的挑战
X-Engine为了尽可能重用数据,以减少相邻两级(即Leveli和Leveli+1)之间合并所需的I/O次数,将合并的粒度划分为2 MB大小的Extent级别,并可进一步将粒度细化为16 KB的数据块。如果Compaction中涉及的某一范围的键与其他范围的键不重叠,只需更新Extent相应的元数据索引,而无需在磁盘上实际移动数据。但X-Engine使用OSS作为底层存储介质后,基于对象存储只支持追加写、覆盖写,不支持偏移写的特点,原先将一个物理文件逻辑上划分为多个Extent的文件管理方式将不再适用。
此外,对象存储在拥有超低成本、超高扩展性优势的同时,也牺牲了一定的读写性能。对象存储的网络时延较大,KB级别的小IO因网络时延会显得代价高昂,且不能充分利用对象存储的大带宽。因此,对象存储对大IO更为友好,更多用于湖仓的大数据分析。以下是OSS和本地Nvme SSD,不同大小IO的读取和写入速度对比。可以看到随着IO的增大,平均读取和写入速度均有所提升,但依然与本地Nvme SSD有数量级的差距。因此,X-Engine在使用OSS作为底层存储介质时,应尽可能的利用好介质本身的特点,尽量隐藏OSS与昂贵的PolarStore之间的性能差距。

3. X-Engine适配OSS
SIGMOD 2023《Disaggregating RocksDB A Production Experience》一文中,Meta将RocksDB架构于类对象存储的文件系统Tectonic(高延迟,追加写,适合大IO)的做法与本文类似。文章中提到,RocksDB需要弥补远程IO带来的延迟差距,通过两方面进行:Tectonic的优化,以及RocksDB的具体优化。Tectonic的优化例如缓存文件元数据,优化尾部延迟等,对标OSS内部的优化,不详细展开。而RocksDB的具体优化则包括:
1. 更改读写的IO size。比如将compaction read size设置为4-8MB,将SST文件大小设置在32MB到256MB。
2. 使用并行I/O。例如用户用MultiGet()读取太多键的场景,可以通过对同一SST文件中的键发出多个数据块的并行读取来减少延迟。
3. 使用预读,例如一个迭代器读取太多连续数据块的场景。
X-Engine的做法和上述优化在核心思路上是一样的,如尽量减少读取过程中的IO次数,将多次小IO优化成一次大IO;实现并行读和预读,为扫描提速等。下面将详细介绍。
3.1 文件管理
将数据存储在PolarStore上时,每一个物理文件文件内部按2M的Extent划分,每个Extent由若干个16k的变长Block组成。将数据存储在OSS上后,每一个Extent对应一个Object,也就是OSS上的一个文件,分配Extent时,通过OSS服务分配创建文件;回收Extent时,通过OSS服务删除文件。

➠ 空间回收
当某一个版本的静态数据被回收后,其包含的Extent就可能被释放掉用于接下来的再次写入。回收时需要拿元数据锁,如果调用OSS接口将Extent文件物理删除,会因为网络时延花费较多时间,阻塞Flush的进行。因此,对OSS上的文件进行空间回收需要先打标,实际删除物理文件交由后台线程进行。
3.2 读路径优化
➠ 点查
当选择将某张表转储到OSS上时,此时数据大概率是冷数据,不在row_cache中。当cache miss时,一次点查(主键)需要:
1. 打开table_reader。如果table_reader未在table_cache中,需要依次读取footer、index、properties等部分,并将filter block和index block缓存在block cache。对于多次Open过程中的多次小IO,优化成一次IO。
2. 根据索引读取data block,第二次IO。
此时最好的情况,是table_reader在table_cache中,在OSS上仅进行一次IO即可。最坏的情况,是table_reader不在table_cache中,此时需要进行两次IO。
➠ 范围查

一次范围查需要:
1. BlockPrefetchHelper和TablePrefetchHelper根据元数据进行预取优化,打开相应的table_reader并加入队列。
2. 根据范围,由DataBlockIter依次读取data block。
此时,如果range较大,那么依次读取data block会造成很多次小IO。OSS上,读取一个Extent的Block三次,所耗费的时间已经超过读取一整个Extent。因此对于OSS上的数据,需要一次缓存整个Extent,并对相应的缓存进行管理,做到查完即释放,不过度占用内存资源。优化后范围查询某个Extent,如果table_reader在cache里面只需访问一次,最多访问两次OSS,读性能有大幅提升。
3.3 宕机恢复
X-Engine的故障恢复是通过Checkpoint+Slog来恢复元数据,决定当前系统中哪些Extent在被使用,每个table的LSM-tree形状是怎样的,每个Level包含了多少Extent。对于OSS上的Extent,直接去标记已经使用的Extent,无需在OSS上读取任何数据。因此,将数据存储在OSS上对宕机恢复的速率没有任何影响。
3.4 一写多读支持
X-Engine的现有逻辑是通过回放redo-log同步增量写入,通过回放slog回放磁盘数据变化。数据放在OSS上后,RW和RO共享一份数据,且数据的高可用性由OSS服务保证。对于Standby,因为本身磁盘上的数据和RW是异构的,所以Standby独享一份数据。当用户发起建立OSS表的DDL时,只需要将元数据的属性同步给Standby即可,同步走原有的物理复制机制。
1. RW写表的OSS属性到redo;
2. Standby回放redo,修改元信息;
3. Standby感知到元数据属性发生变化;
4. Standby后续的Compaction动作在合并L2时写OSS。
3.5 后台任务管理
➠ Flush
不直接与OSS交互,L0到L1仍然写到PolarStore,合并到L2时,写到OSS。
➠ Compaction
Compaction过程中,需要读取OSS上的Extent。Xengine中将OSS上的compaction read size从Block(16KB)调整成Extent(2MB),且后续还可以实现不同介质上不同大小的Extent,优化了OSS上数据Compaction的速率。经测试,数据在OSS上的Compaction性能比在SSD上约慢25%。因此,还需要根据不同介质上Compaction任务速度不同,相应的调整调度策略。

调度策略
Major Compaction的分数计算
原公式:
![]()
原公式l2numv/l1numv/10 将作为一个减分项,减弱大major合并的频率。对于L2层放到OSS上的情况,compaction的负担更重,这个减分项的权重理应占比更大。
Major Compaction时,生成的Compaction job的大小
在Major Compaction中,会先划分L1参与合并的Extent范围,再根据这个范围选择L2参与合并的Extent。随后,将参与Compaction的level1和level2的数据切分为不相交的batch,加入到生成的compaction task中。每个Compaction job对应多个compaction task,每个task有最大的extent数量限制,生成的Compaction job会进入队列循环执行。这样设计可以保证多个表之间的Compaction能够一起进行,且table之间的并发粒度已经能够利用好后台的Compaction线程,所以不支持表内不同层级的Compaction并发。
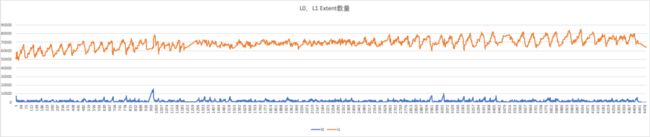
但是这样的设计,在持续写入且原表数据量已经很大的情况下存在问题。数据量很大时,一次Major Compaction任务可能涉及几万个extent的合并,在这个时间内L0->L1的compaction是被阻塞的,因此可能造成L0数据的堆压。如下图所示,蓝线为L0 extent数量,黄线为L1 extent数量,随着持续写入抖动变得越来越剧烈。

原策略划分L1参与合并的extent范围,是将以下范围内的extent进行合并。L1_extent是L1实际的extent数量,L1_trigger是L1触发合并的extent数量。
![]()
当写入压力很大且持续写入较长时间以后(例如写24h以上),0.4 * L1_extent的数量可能远大于L1_trigger,此时生成的compaction job会非常的大。我们希望调整策略,减小L1_merge_range的范围,从而减小生成的compaction job,避免L0发生数据堆积。
新策略:
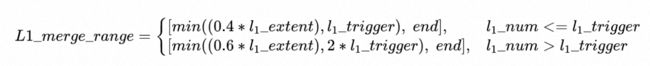
新策略减小了当l1_extent > l1_trigger时(此时一般L2数据量较大,影响合并数量的主要因素是L2),进行合并的L1 extent数量。以默认参数l1_trigger = 1000,l1Max = 5000,compaction_task_extents_limit = 1000为例,原策略当L1=3000时,参加合并的L1 extent = 2000,加上L2参与合并的extent可能会被拆分成十几个task,在队列中循环十几次。新策略参加合并的L1 extent = 1200,在L2数量是影响合并的主因素的时候,可以让合并数量大约减少40%,避免一次compaction时间过久。修改后l0、l1数量稳定,避免了数据堆积。
4. 性能测试
本小节测试了相同配置下,X-Engine在不同介质上的性能表现。测试使用sysbench脚本,主要测试了几种典型的场景,包括插入、点查、范围查等。
4.1 插入
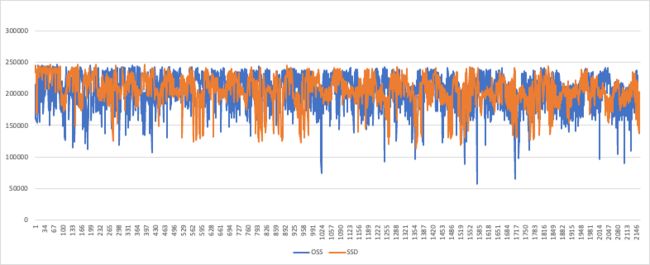
使用oltp_insert.lua脚本持续写入数据6h,其中黄线为SSD上数据写入QPS随时间变化图,蓝线为OSS上数据写入QPS随时间变化图。可以看到,因为前台写入还是先写到PolarStore介质上,随着Compaction任务再转储到OSS上,对写入性能影响不大。这与SIGMOD 2023《Disaggregating RocksDB A Production Experience》一文中的结果也是符合的。
4.2 点查
注:这里为了更好比较在不同介质上的速度差距,将所有数据都刷到了L2,这牺牲了本架构热数据在L0、L1,冷数据在L2的优势。同时,测试将row_cache、block_cache设置的很小以方便比较,而真实场景下查询有cache,介质的性能差距在命中cache时不会那么明显。
oltp_point_select.lua
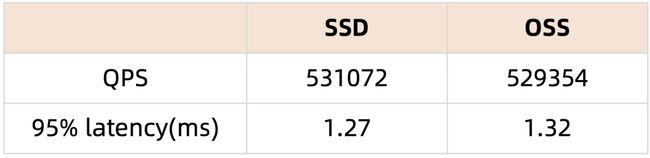
SQL:SELECT c FROM sbtest%u WHERE id=?
该脚本中,一个事务包含的多条主键点查的SQL,id是连续增长的,因此多条查询会命中同一个block。访问OSS的时间开销被均摊,且压测并发线程数较多,能够把OSS带宽打上去,QPS和延时无明显下降。
select_random_points.lua
SQL:SELECT id, k, c, pad FROM sbtest1 WHERE k IN (?,?,?,...?)
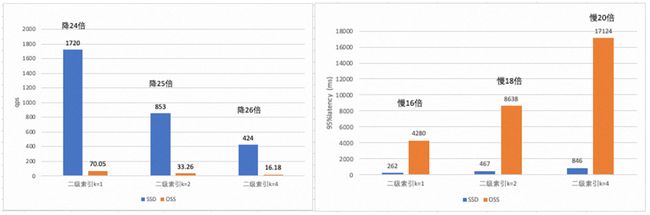
select_random_points.lua中的SQL在当前数据量下,IN中1个k值对应约150个id,而这些id均匀分布在各个extent。此时需要先访问二级索引,再逐条数据回表访问主索引,过程中多次访问OSS。查询数据量/访问OSS次数比值较大时,OSS的网络时延成为查询耗时主要因素,和SSD的速度差距会凸显出来。
以下是k IN(?, ?),IN中的值=1,2,4时候的QPS对比,每个k值差不多对应约150个均匀分布的id。可以看到,随着查询的数据量成倍增加,QPS成倍下降,latency也成倍上升,这是符合预期的。而对于OSS和SDD的对比,随着查询的数据量成倍增加,访问OSS的次数变多,QPS从下降24倍变成26倍,95% latency从慢16倍变成慢20倍。
4.3 范围查
select_random_ranges.lua
SQL: SELECT count(k) FROM sbtest.sbtest1 WHERE k BETWEEN ? AND ? OR BETWEEN ? AND ? ……;
该查询语句只获取二级索引的字段和主键字段,属于covering index,只需要访问二级索引本身。在range=50或500时,一个range都只读1-2个extent,一次查询访问OSS的次数不变,因此在OSS上的性能差距并不大。而对于SSD,是根据block进行读取,要读的block数量差了10倍,所以QPS下降,latency上升。当range = 50000时,一个range对应20个左右的extent,能更好的利用并行扫描和OSS的带宽,两种介质上测得的QPS和latency并无差距。

从结果来看,X-Engine使用OSS作为底层存储介质后,最适合大范围数据查询的场景,对于多次点查且数据分布较分散的场景则性能不佳。
5. 总结
从以上测试场景可以看到,将L2层放在OSS上后,对写入性能影响不大。对于读取性能,单次点查性能下降较小,而且单次点查本身耗时很短,变慢了也不明显。多次点查(Mutiget,例如使用二级索引且需要回表的场景)因为多次访问OSS,性能下降较为明显,而Mutiget同样也是论文《Disaggregating RocksDB A Production Experience》中性能下降较明显的场景,开启row_cache和block_cache后能有所缓解。范围查下性能下降最多30%,且后续还可以通过预读来进一步优化。
总而言之,将数据放到L2后,存储成本变为原来的1/10,性能的适度下降也是可以容忍的。