啤酒和尿不湿?购物篮分析、商品关联分析和关联规则算法都给你搞清楚(上—理论篇)

不管是不是搞数据分析的,相信应该都听过啤酒尿不湿的故事,说的是美国的沃尔玛超市管理人员分析销售数据时发现了一个令人难以理解的现象:“啤酒”与“尿布湿”这两件看上去毫无关系的商品会经常出现在同一个购物篮中。经过后续调查他们发现,这种现象大多出现在年轻的父亲身上。
原来在有婴儿的美国家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布湿。父亲在购买尿布湿的同时,往往会顺便为自己购买啤酒,这就出现了啤酒与尿布湿这两件看上去不相干的商品经常被放入同一个购物篮的现象。沃尔玛超市发现了这一独特的现象,开始在卖场尝试将啤酒与尿布湿摆放在相同的区域,让年轻的父亲可以同时找到这两件商品,并很快地完成购物,销售效果很明显。1993 年美国学者 Agrawal 通过分析购物篮中的商品集合,从而找出商品之间关联关系的算法,并根据商品之间的关系,找出客户的购买行为。从数学及计算机算法角度他提出了商品关联关系的计算方法,也就是接下来要讲的Aprior 算法。
沃尔玛尝到了甜头,后来又发现一个现象,每当季节性飓风来临之前,蛋挞销量也增加了,于是每当季节性飓风来临时,沃尔玛就会把蛋挞与飓风用品摆放在一起,从而增加销量。
无独有偶,美国第二大超市塔吉特百货(Target)被一位父亲抗议投诉,说他的女儿还是高中生,超市却给她邮寄孕妇产品。超市经理赶忙道歉才平息了这位父亲的怒火。谁知一个月后这位父亲来给超市道歉,说他的女儿的确怀孕了。一家超市怎么会比父亲先知道女儿的怀孕呢?原来塔吉特从公司订单数据仓库中挖掘出25项与怀孕高度相关的商品,制作“怀孕预测”指数。比如他们发现女性会在怀孕四个月左右,大量购买无香味乳液。以此为依据推算出预产期后,抢先一步将孕妇装,婴儿床等折扣劵寄给客户来吸引客户购买。
这就是大数据的威力,当数据量足够大,就具有了统计学意义,群体行为的规律性就被发掘出来。其实不是你的隐私被窥探了,而是你恰好是目标群体的一份子,不是你还会是别人。
现在小视频很火,不知道大家有没有意识到,抖音很懂你,总是给你推你喜欢的东西。这就是推荐算法在背后起作用。如果是你,让你给你的朋友推荐购买商品,你会怎么办?第一种办法,你观察他喜欢买什么东西,这些东西有什么共同特性,那你就推荐你有的同类产品,这叫基于物品的协同过滤(Collaborative Filtering);第二种办法你看他玩得好的几个朋友买的东西都是什么,找出同类产品推荐给他,这叫基于用户的协调过滤。那还有什么方法呢?就是接下来要讲的关联规则。通过关联规则,可以找到不一定是同类或功能关联产品的关系的商品组合,从而提升销量。这是一种简单好理解,但是实施起来却很复杂的算法。我一说你就懂,但是你一做就不一定会。
一、什么是关联规则
关联规则算法源于对购物小票(也叫购物篮)数据记录的挖掘,因此现在往往叫做购物篮分析,又因为研究的是商品之间关联关系,又叫做商品关联分析。这三者其实是一个意思。但是有很多BI分析师要么故意把它简化,要么用错了。比如用法一:算出同时购买商品A和商品B的订单数占总订单数比例,叫支持度;算出同时购买商品A和商品B的订单数占单独购买商品A的订单数的比例,叫置信度;算出“支持度/((购买A次数/总购买订单数)*(购买B次数/总购买订单数))”,叫提升度。概念和算法是正确的,但也不是完全正确。因为这只是关联规则里频繁一项集的情况,而且提升度并不是一个稳定的指标,实用会出问题。用法二:找出购买商品A的订单数m、购买商品B的订单数n和同时购买商品A商品B的订单数o,算出o/(m+n),将商品A的所有B组合,找出排序最大的就是最佳组合。这种用法也有他的道理,但是跟关联规则没啥关系。
究竟什么是关联规则呢?还是用一个例子来详细解释。
下面是十张购物小票(Receipt,缩写R),每个RID代表一张小票,后面是小票上记录的顾客购买的商品。我们的目的是怎么找出商品与商品之间最好的搭配方式能让两者销量都提高。
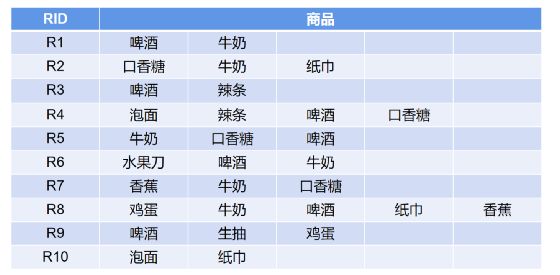
关联规则算法怎么解决的呢?
第一步,找出上面所有订单里出现的商品,它们的所有组合。
第二步,计算这些组合的支持度和置信度,这叫支持度-置信度框架,也就是关联规则。
第三步,对算出的每个组合支持度和置信度进行衡量,也就是计算提升度,按照支持度、置信度、提升度排序,都比较高的就是好的商品组合。
过程是不是很简单?其实还没完。
在第一步中,我们真的需要所有商品组合吗?不是的。有些商品组合几乎没出现或很少,我们就需要把它排除。这里排除的方式就是最小支持度。(还有一个是最小置信度,但是它对商品组合没有影响,影响的是规则,也就是最后算出关联规则的结果,我们决定要不要它。而最小支持度影响商品组合。这句话先放在这里,最后你会明白)。而这两个最小,不是固定的,而是业务专家根据业务观测经验来定的。
在第二步中,衡量组合的好坏这里讲的是提升度,你百度搜索看到几乎所有回答都用提升度,但实际忽略这个度量的缺陷,合理的衡量标准实际是KULC 度量 + 不平衡比(IR)两个指标搭配使用。
在第三步中,笼统的说三者都比较高就是好的,实际上这是很笼统的说法,我们人可以判断比较好,但是机器怎么判断比较好呢?得有个标准吧!很遗憾,这就是这个算法的缺陷。它是无监督机器学习方法,用于知识发现,而不是预测或者验证,没有办法对其结果进行评估,只能通过业务观测来判断它是否合理。不过这个算法实际使用效果很好,它总比你什么都不做好的多吧?
接下来我用这个例子一步步解释算法实际计算过程。这个算法是被Agrawal,Imielinski and Swami在1993年的SIGMOD会议上提出的,有很多晦涩的术语,这里尽量用通俗的说法来介绍。
二、关联规则相关概念
1.事务:每张小票叫一个事务;
2.事务集:所有小票叫事务集;
3.事务的个数叫S,这里S=10;
4.项:每个商品叫做项目(item),简称项;
5.项集:每个商品组合(它自身也是一个组合)叫做项集(itemset);
6.项集的支持度:该项集出现的次数除以总的事务数,比如{牛奶,啤酒}项集的支持度为:
Support({牛奶,啤酒}) = 4/10
(牛奶和啤酒共同出现的次数是4次)
由定义也可以看出,某项集的支持度实际是该项集出现的概率,牛奶和啤酒共同出现的概率是 4/10。
7.关联规则:人为定义项集内部存在一个关联规则R:A>B,也就是说从A到B存在某条规则R;
8.规则R的支持度:事务集中同时包含A和B的事务数与所有事务数S之比,比如从啤酒到牛奶之间规则的支持度为:
Support(啤酒=>牛奶)=4/10
(牛奶和啤酒共同出现的次数是4次,总事务数是S)
如果规则的支持度越高,说明这个规则出现的概率越大,可能是有用的规则。
9.规则R的置信度:项集{A,B}的支持度与项集{A}的支持度之比,比如从啤酒到牛奶之间规则的置信度为:
Confidence(啤酒=>牛奶)=4/7
(牛奶和啤酒共同出现的次数是4次,项集{A,B}的支持度为4/10 ;啤酒出现的次数是7次,啤酒的支持度为7/10)
置信度的意义在于项集{A,B}同时出现的次数占项集{A}出现次数的比例,即发生A的条件下,又发生B的概率(条件概率),它是衡量规则R的可信程度。如果比较高,说明买了A又买B的可能性很大。
10.规则R的提升度:项集{A,B}的规则R的置信度与项集{B}的支持度之比,比如从啤酒到牛奶之间规则的提升度为:
Lift(啤酒=>牛奶) = (4/7)/(6/10)=4/42
(这里为方便看没化简。项集{A,B}的规则R的置信度为4/7,项集{B}的支持度为6/10)
规则的提升度的意义在于度量项集{A}和项集{B}的独立性。具体的含义稍后再讲,这是核心。
有了这些概念就可以理解过程了。
三、关联规则实施步骤
第一步,找出经过最小支持度过滤的商品组合(也就是低于最小支持度的都不要),这里我把最小支持度定位0.1,只要小于等于0.1的都排除。
这里10张小票所包含的产品是啤酒、口香糖、泡面、牛奶、水果刀、香蕉、鸡蛋、辣条、生抽、纸巾这十种(都是10是偶然哈)。
包含1个项的叫频繁1项集,它们的支持度很好算,一个一个数事务数就好了:
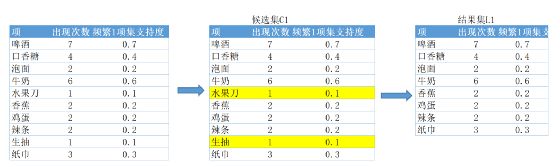
上图表示的是,把所有事务扫描一遍(这是第一次扫描全部数据),里含频繁1项集的计数,再算支持度,低于0.1的排除掉,得到结果集1
包含2个项的叫频繁2项集,它们的支持度也很好算,继续数数:

还是把所有事务扫描一遍(这是第二次扫描全部数据,里含频繁2项集的计数,再算支持度,低于0.1的排除掉,得到结果集2。但是这里你发现每两个商品组合就10*10=100种,如果找频繁3项集、频繁4项集…频繁10项集,总数就会有2025条。这还只是10个商品,如果上千个商品,计算量会非常大。虽然最后经过筛选每个结果集都很小。但是这个过程的计算量很大。怎么办呢?
Apriori算法
这就引出了Apriori算法。Apriori算法利用了一条重要的性质,叫先验性质。这玩意儿没有为什么,就跟定理似的,我们拿来用就可以了。
这条性质的内容是:频繁项集的所有非空子集也一定是频繁的。反过来,如果这个频繁项集被排除,那它的子集就需要被排除。
所以在使用Apriori算法进行第二次扫描数据时结合第一次扫描排除掉的频繁1项集的信息,直接排除它们的子集。如下图。这样就大大减少了过程的计算量。黄色表示在第一次扫描时排除的项。
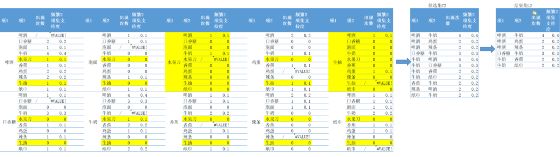
它的巧妙之处在于第二次扫描的过程就进行排除,而不是全部组合好再排除。这里效果还不算明显,当你第三次扫描计算频繁3项集的时候,把2中排除的直接排除,你就会发现比你用之前的办法硬算的计算量少太多了。实际上,这还不是最好的办法,FP-growth算法不用产生候选集,直接构造可用频繁项集,更加快捷。如果感兴趣,可以自己去搜索一下。
在继续寻找频繁3项集的时候发现没有符合条件的结果。因此我们对这个数据集找到的所有频繁项集如下(就只有所有频繁2项集):
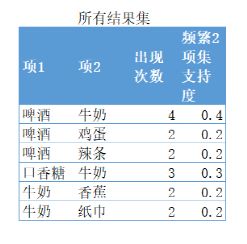
第二步,计算支持度、置信度、提升度,在这里我还同时引入了KULC度量和IR不平衡比例两种度量方式。

很清晰的看到每个指标计算的结果。虽然从啤酒到牛奶的支持度和置信度都比较高,但是它的提升度却小于1。前面讲到提升度的算法是项集{A,B}的规则R的置信度与项集{B}的支持度之比,实际就是:
Lift(啤酒=>牛奶) = (P(A∩B)/P(A))/P(B)
= P(A∩B)/P(A)P(B)
这不就是条件概率嘛,如果P(A∩B)/P(A)P(B)=1,说明A事件发生和B事件发生是具有独立性的。如果Lift<1,说明a和b之间是负相关,a的出现可能导致b不容易出现。因为我们看到牛奶的出现概率是0.6,已经很高了。再加入啤酒的话反而会降低顾客购买牛奶的概率(变成0.571428)。这说明这条规则并不好。好的规则是口香糖和牛奶组合,虽然它们的支持度比较低,但是置信度和提升度都很高,说明关联规则很强。通过关联销售,就可以增加销售机会。
既然提升度已经很有用了,为什么还推荐使用KULC度量和IR不平衡比例两种度量方式呢?因为这里只是10个商品10个单号,当在真实商业环境时,会有大量的顾客既没有购买上面的A,也没有购买B,这叫零事务,零事务的个数很容易引起提升度计算的变动,而且A项集的支持度与B项集的支持度悬殊过大也会造成提升度不能很好衡量关联规则强度。那引入的两个是怎么定义和计算的呢?
KULC度量:
0.5\ *(P(B|A)+P(A|B))
它可以看作是两个置信度的平均值。
IR不平衡比例:

KULC度量越大越好,IR不平衡比例越小越好,两者组合使用比单独使用Lift能更好的的发现强关联规则。
以上就是关联规则的全部内容了。本篇讲的是关联规则的理论,下部分将通过PowerBI和Python进行实际应用和展示。
最后欢迎大家关注我,我是拾陆,搜索公众号“二八Data”,更多技术干货持续奉献。