pulsar原来是这样操作topic的
本篇主要讲述pulsar topic部分,主要从设计以及源码的视角进行讲述。在pulsar中,一个Topic的新建、扩容以及删除操作都是由Broker来处理的,而Topic相关的数据是存储在zookeeper上的。本篇文章模拟一个高效的学习流程进行展开
- 介绍使用方式(Topic操作指令)
- 从高纬度俯视调用流程(从服务层面看Topic的调用流程)
- 逐步切入某个具体的操作进一步展开内部的调用流程(从代码层面看具体的调用流程)
- 看具体的实现(看代码具体的实现)
Topic操作指令
在日常对pulsar Topic操作时,咱们常常会用到以下指令
//1. Topic创建
pulsar-admin topics create-partitioned-topic \
persistent://my-tenant/my-namespace/my-topic \
--partitions 4
//2. Topic扩容
pulsar-admin topics update-partitioned-topic \
persistent://my-tenant/my-namespace/my-topic \
--partitions 8
//3. Topic删除
pulsar-admin topics delete persistent://test-tenant/ns1/tp1
//4. Topic unload
pulsar-admin topics unload persistent://test-tenant/ns1/tp1
更多的操作可以参考 https://pulsar.apache.org/docs/3.0.x/admin-api-topics/
在这里列举了针对分区并存储Topic的四个操作指令
- Topic创建,通过指令可以在指定的租户以及命名空间下创建Topic并指定分区数
- Topic扩容,这是业务场景为了提升性能时通常会用到的操作,增加指定Topic的分区数
- Topic删除,删除不用的Topic,在删之前一定要在监控上确保此Topic的上下游都没有被使用
- Topic unload,重制Topic状态
以上就是使用方式,打个比方就是猪可以用来烹饪,猪脑可以用来烤脑花等等
服务层面调用流程
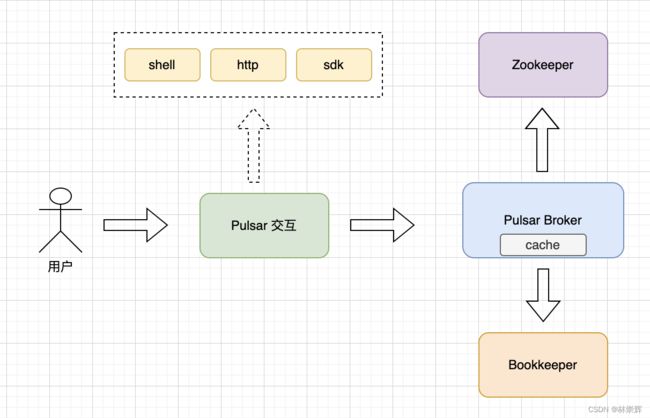
Pulsar用户(管理员) 跟Pulsar集群的交互流程可以提炼成上面这张表,从左往右看
- 用户是集群管理员或者Pulsar的用户,在跟Pulsar集群交互时,可以通过Pulsar提供的上面三种方式。上面提供的操作指令就是第一种shell命令的方式,还可以直接通过http访问rest接口方式以及使用Pulsar针对各个编程语言提供的sdk包进行操作
- Pulsar集群Topic相关的元数据全部存储在Zookeeper中,同时为了避免高频访问Zookeeper导致的性能瓶颈,Pulsar在自身服务增加了Cache,在本地内存进行元数据的存储。同时在Pulsar Broker启动时会在Zookeeper添加Watcher来感知元数据的变动,如果有变动会同步更新本地Cache。在有Topic元数据相关的查操作时,会优先查询本地Cache
- Pulsar Topic里的数据会存在Bookkeeper中,在对Topic新增/删除时,会调用Bookkeeper来创建/删除 Bookkeeper中相关的数据
以上就是高纬度俯视调用流程,打个比方就是猪的骨架以及神经脉络的构成,这个设计/调用流程在大的方向上已经将Pulsar定型了。在学习的过程中切忌一下子就钻入细节(除非是急着解决问题),一定要有一个清晰的全貌认识,在根据需要逐步切入具体的细节
代码层调用流程
在对全貌有了解后,咱们开始从代码实现层面来看调用流程
首先先看通用的,无论是新增、扩容、卸载还是删除,Pulsar都需要让所有Broker节点感知到元数据的变化。通过下图来看看Pulsar是怎么做的

如上图所示,Pulsar Broker在启动的时候,会通过ZooKeeperCache对象的构造函数中创建一个ZookeeperClient对象,其通过watcher方式来监听 Zookeeper中 /brokers/topics 路径下数据的变动;在Topic新建时,本质上就是在 /brokers/topics目录下新建一个 Topic名称的子目录,Topic删除本质就是删除此目录,而扩容的本质就是变更 /brokers/topics/topic名称 中分区的信息。因此Pulsar中Topic的变更感知其实就是通过Zookeeper提供的一致性写入以及watcher来实现的,这也是大部分组件元数据变更的实现方案。通过上述可以看到Pulsar在感知到Topic元数据的变动后只做了一件事,就是同步刷新本地的缓存。
在知道Pulsar是怎么实现的Topic变更感知后,接下来看看它的Topic新建流程
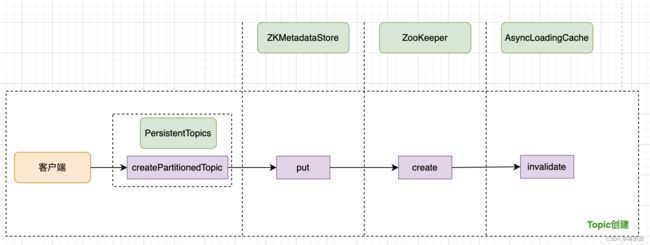
如上图所示,在我们通过指令调用Pulsar创建Topic后,Pulsar Broker会调用ZKMetadataStore的put方法进行处理,其内部罪关键的操作就是调用Zookeeper的客户端在 Zookeeper的服务端 /brokers/topics目录下创建Topic名称的新目录,同时更新本地缓存AsyncLoadingCache。至此Topic创建的流程就结束了,可以负责消息的读写操作。其他扩容、删除等操作也类似,在这里就不一一例举了。
以上就是代码的调用流程,打个比方就是猪的心脏、猪蹄的构成,在深入细节时要不断的在头脑或者笔记中梳理细节的脉络,否则很容易迷失在这里。
代码实现
在对各个操作的调用流程了解了之后,咱们的脑海中已经有一副Pulsar Topic相关操作的地图了,现在就让咱们根据地图去探索具体的“宝藏”吧。
咱们先来看看Topic创建的代码实现,为了避免迷路,博主在下面先整理调用栈,之后再针对具体的核心代码进行讲解
PersistentTopics#createPartitionedTopic //Topic创建 服务端代码入口,仅做了Topic相关的格式、权限的校验
AdminResource#internalCreatePartitionedTopic //异步检查Topic是否存在以及异步调用创建Topic
AdminResource#tryCreatePartitionsAsync //根据分区数循环调用异步方法tryCreatePartitionAsync
AdminResource#tryCreatePartitionAsync //调用zk服务端来创建Topic具体的某个分区
ZKMetadataStore#put
ZKMetadataStore#storePut
ZKMetadataStore#storePutInternal
ZooKeeper#setData //这里就是创建Topic最关键的地方,也就是在Zookeeper服务端创建新Topic目录下的分区信息
整个调用链路还是非常清晰的,因为相比kafka而言,Pulsar是无主架构,不需要做选主、一致性相关的操作,所以代码难度整体并不算高。不过pulsar为了性能大量使用了异步处理搭配lambda操作,对于不熟悉的读者会有点难度。
下面让咱们深入看下实现细节,首先是入口 PersistentTopics#createPartitionedTopic
public void createPartitionedTopic(...) {
try {
validateGlobalNamespaceOwnership(tenant, namespace); //校验当前Topic的租户-namespace二级目录是否有效
validatePartitionedTopicName(tenant, namespace, encodedTopic); //未知校验什么
//判断当前操作是否允许
validateTopicPolicyOperation(topicName, PolicyName.PARTITION, PolicyOperation.WRITE);
validateCreateTopic(topicName); //校验Topic命名,避免跟服务内部Topic冲突
//真正调用创建Topic的方法
internalCreatePartitionedTopic(asyncResponse, numPartitions, createLocalTopicOnly);
} catch (Exception e) {
//
}
}
因此我们可以看到主要就是做相关的校验,主要的逻辑交给下一层AdminResource#internalCreatePartitionedTopic,进一步看实现
protected void internalCreatePartitionedTopic(AsyncResponse asyncResponse, int numPartitions,
boolean createLocalTopicOnly) {
Integer maxTopicsPerNamespace = null;
try {
//获取当前Namespace的策略,用于校验
Policies policies = getNamespacePolicies(namespaceName);
maxTopicsPerNamespace = policies.max_topics_per_namespace;
} catch (RestException e) {
//....
}
try {
if (maxTopicsPerNamespace > 0) {
List<String> partitionedTopics = getTopicPartitionList(TopicDomain.persistent);
//校验当前namespace下的Topic数量已经达到限额,到的话则创建新Topic失败
if (partitionedTopics.size() + numPartitions > maxTopicsPerNamespace) {
log.error("[{}] Failed to create partitioned topic {}, "
+ "exceed maximum number of topics in namespace", clientAppId(), topicName);
resumeAsyncResponseExceptionally(asyncResponse, new RestException(Status.PRECONDITION_FAILED,
"Exceed maximum number of topics in namespace."));
return;
}
}
} catch (Exception e) {
//....
}
final int maxPartitions = pulsar().getConfig().getMaxNumPartitionsPerPartitionedTopic();
try {
//对namespace的操作进行校验
validateNamespaceOperation(topicName.getNamespaceObject(), NamespaceOperation.CREATE_TOPIC);
} catch (Exception e) {
//....
}
//对分区数进行下界校验
if (numPartitions <= 0) {
asyncResponse.resume(new RestException(Status.NOT_ACCEPTABLE,
"Number of partitions should be more than 0"));
return;
}
//对分区数进行上界校验
if (maxPartitions > 0 && numPartitions > maxPartitions) {
asyncResponse.resume(new RestException(Status.NOT_ACCEPTABLE,
"Number of partitions should be less than or equal to " + maxPartitions));
return;
}
List<CompletableFuture<Void>> createFutureList = new ArrayList<>();
CompletableFuture<Void> createLocalFuture = new CompletableFuture<>();
createFutureList.add(createLocalFuture);
//异步调用检查Topic是否已存在
checkTopicExistsAsync(topicName).thenAccept(exists -> {
if (exists) {
log.warn("[{}] Failed to create already existing topic {}", clientAppId(), topicName);
asyncResponse.resume(new RestException(Status.CONFLICT, "This topic already exists"));
return;
}
//核心操作,异步调用创建Topic操作
provisionPartitionedTopicPath(asyncResponse, numPartitions, createLocalTopicOnly)
.thenCompose(ignored -> tryCreatePartitionsAsync(numPartitions))
.whenComplete((ignored, ex) -> {
if (ex != null) {
createLocalFuture.completeExceptionally(ex);
return;
}
createLocalFuture.complete(null);
});
}).exceptionally(ex -> {
//....
});
//如果这个Topic是全局的,那么还会调用其他pulsar集群异步创建这个Topic
//这里控制多个并发请求结束处理的设计值得借鉴,通过轮训异步对象容器进行结果处理
if (!createLocalTopicOnly && topicName.isGlobal() && isNamespaceReplicated(namespaceName)) {
getNamespaceReplicatedClusters(namespaceName)
.stream()
.filter(cluster -> !cluster.equals(pulsar().getConfiguration().getClusterName()))
.forEach(cluster -> createFutureList.add(
((TopicsImpl) pulsar().getBrokerService().getClusterPulsarAdmin(cluster).topics())
.createPartitionedTopicAsync(
topicName.getPartitionedTopicName(), numPartitions, true)));
}
FutureUtil.waitForAll(createFutureList).whenComplete((ignored, ex) -> {
if (ex != null) {
log.error("[{}] Failed to create partitions for topic {}", clientAppId(), topicName, ex.getCause());
if (ex.getCause() instanceof RestException) {
asyncResponse.resume(ex.getCause());
} else {
resumeAsyncResponseExceptionally(asyncResponse, ex.getCause());
}
return;
}
log.info("[{}] Successfully created partitions for topic {} in cluster {}",
clientAppId(), topicName, pulsar().getConfiguration().getClusterName());
asyncResponse.resume(Response.noContent().build());
});
}
这个方法的逻辑有些多,但整体也是比较清晰的,接下来进一步看看AdminResource#tryCreatePartitionsAsync的代码
protected CompletableFuture tryCreatePartitionsAsync(int numPartitions) {
//如果Topic不需要持久化,直接结束
if (!topicName.isPersistent()) {
return CompletableFuture.completedFuture(null);
}
List> futures = new ArrayList<>(numPartitions);
//针对Topic的每个分区单独发起各自的创建请求
for (int i = 0; i < numPartitions; i++) {
futures.add(tryCreatePartitionAsync(i, null));
}
//等待多个异步任务处理好
return FutureUtil.waitForAll(futures);
}
继续看AdminResource#tryCreatePartitionAsync的实现
private CompletableFuture tryCreatePartitionAsync(final int partition, CompletableFuture reuseFuture) {
CompletableFuture result = reuseFuture == null ? new CompletableFuture<>() : reuseFuture;
//获取元数据存储对象,pulsar默认都是zookeeper的实现,没有其他选项,但支持自定义拓展
Optional localStore = getPulsarResources().getLocalMetadataStore();
if (!localStore.isPresent()) {
result.completeExceptionally(new IllegalStateException("metadata store not initialized"));
return result;
}
//核心代码,往元数据对象中新增这个分区的信息
localStore.get()
.put(ZkAdminPaths.managedLedgerPath(topicName.getPartition(partition)), new byte[0], Optional.of(-1L))
.thenAccept(r -> {
if (log.isDebugEnabled()) {
log.debug("[{}] Topic partition {} created.", clientAppId(), topicName.getPartition(partition));
}
result.complete(null);
}).exceptionally(ex -> {
//....
});
return result;
}
继续跟踪,进入到ZKMetadataStore#put
public CompletableFuture put(String path, byte[] value, Optional optExpectedVersion) {
return put(path, value, optExpectedVersion, EnumSet.noneOf(CreateOption.class));
}
public final CompletableFuture put(String path, byte[] data, Optional optExpectedVersion,
EnumSet options) {
// Ensure caches are invalidated before the operation is confirmed
return storePut(path, data, optExpectedVersion, options)
.thenApply(stat -> {
NotificationType type = stat.getVersion() == 0 ? NotificationType.Created
: NotificationType.Modified;
if (type == NotificationType.Created) {
existsCache.synchronous().invalidate(path);
String parent = parent(path);
if (parent != null) {
childrenCache.synchronous().invalidate(parent);
}
}
metadataCaches.forEach(c -> c.invalidate(path));
return stat;
});
}
继续看ZKMetadataStore#storePut操作
public CompletableFuture storePut(String path, byte[] value, Optional optExpectedVersion,
EnumSet options) {
CompletableFuture future = new CompletableFuture<>();
//核心方法
storePutInternal(path, value, optExpectedVersion, options, future);
return future;
}
进去看ZKMetadataStore#storePutInternal实现
private void storePutInternal(String path, byte[] value, Optional optExpectedVersion,
EnumSet options, CompletableFuture future) {
boolean hasVersion = optExpectedVersion.isPresent();
int expectedVersion = optExpectedVersion.orElse(-1L).intValue();
try {
if (hasVersion && expectedVersion == -1) {
CreateMode createMode = getCreateMode(options);
ZkUtils.asyncCreateFullPathOptimistic(zkc, path, value, ZooDefs.Ids.OPEN_ACL_UNSAFE,
createMode, (rc, path1, ctx, name) -> {
execute(() -> {
Code code = Code.get(rc);
if (code == Code.OK) {
future.complete(new Stat(name, 0, 0, 0, createMode.isEphemeral(), true));
} else if (code == Code.NODEEXISTS) {
// We're emulating a request to create node, so the version is invalid
future.completeExceptionally(getException(Code.BADVERSION, path));
} else if (code == Code.CONNECTIONLOSS) {
// There is the chance that we caused a connection reset by sending or requesting a batch
// that passed the max ZK limit. Retry with the individual operations
log.warn("Zookeeper connection loss, storePut {}, retry after 100ms", path);
executor.schedule(() ->
storePutInternal(path, value, optExpectedVersion, options, future),
100, TimeUnit.MILLISECONDS);
} else {
future.completeExceptionally(getException(code, path));
}
}, future);
}, null);
} else {
//核心操作
zkc.setData(path, value, expectedVersion, (rc, path1, ctx, stat) -> {
execute(() -> {
Code code = Code.get(rc);
if (code == Code.OK) {
future.complete(getStat(path1, stat));
} else if (code == Code.NONODE) {
if (hasVersion) {
// We're emulating here a request to update or create the znode, depending on
// the version
future.completeExceptionally(getException(Code.BADVERSION, path));
} else {
// The z-node does not exist, let's create it first
put(path, value, Optional.of(-1L)).thenAccept(s -> future.complete(s))
.exceptionally(ex -> {
future.completeExceptionally(ex.getCause());
return null;
});
}
} else if (code == Code.CONNECTIONLOSS) {
// There is the chance that we caused a connection reset by sending or requesting a batch
// that passed the max ZK limit. Retry with the individual operations
log.warn("Zookeeper connection loss, storePut {}, retry after 100ms", path);
executor.schedule(() -> storePutInternal(path, value, optExpectedVersion, options, future),
100, TimeUnit.MILLISECONDS);
} else {
future.completeExceptionally(getException(code, path));
}
}, future);
}, null);
}
} catch (Throwable t) {
future.completeExceptionally(new MetadataStoreException(t));
}
}
继续进入看ZooKeeper#setData的逻辑
public void setData(String path, byte[] data, int version, StatCallback cb, Object ctx) {
PathUtils.validatePath(path);
String serverPath = this.prependChroot(path);
RequestHeader h = new RequestHeader();
h.setType(5);
SetDataRequest request = new SetDataRequest();
request.setPath(serverPath);
request.setData(data);
request.setVersion(version);
SetDataResponse response = new SetDataResponse();
this.cnxn.queuePacket(h, new ReplyHeader(), request, response, cb, path, serverPath, ctx, (ZooKeeper.WatchRegistration)null);
}
走到这里基本就差不多结束了,就是调用zookeeper创建
接下来看看Topic删除的代码实现,为了避免迷路,一样先看看调用栈
删除
校验
删除Topic相关策略
调用BK删除schema数据
调用BK删除Topic数据
删副本
删producers
删subscriptions
没找到删zk数据的地方,是否有定时任务一起删?
PersistentTopics#deleteTopic
PersistentTopic#delete
疑问以及答案
在学习的过程中咱们的脑海中会诞生很多宝贵的疑问,以下是博主的想法也当作是留给读者的一份“考核”,可以尝试解答以及深入思考
Topic存在zk如何避免 zk成为性能瓶颈
对Topic进行变更后,如何同步给其他的Broker,分区分配给Broker的策略是
创建Topic的模型(包含创建流程、同步给其他服务流程、选定owner流程)
zk和 MetadataCache的关系是什么
bk是以什么样的数据模型存的Topic数据,删的时候是如何删的
如果是跨集群多副本的Topic,删除过程如何回收其他集群的副本?
pulsar的Topic可以被close吗,什么场景下会被使用?
pulsar如何避免大量删Topic时对线上稳定性有影响
pulsar可否像kafka一样指定分区分配方案,可以的话应该如何操作
没找到删zk数据的地方,是否有定时任务一起删?
Topic存在zk如何避免 zk成为性能瓶颈
答:加Cache
对Topic进行变更后,如何同步给其他的Broker,分区分配给Broker的策略是
创建Topic的模型(包含创建流程、同步给其他服务流程、选定owner流程)
zk和 MetadataCache的关系是什么
答:MetadataCache是为了避免高频访问zk导致的性能瓶颈从而增加的一层本地缓存
bk是以什么样的数据模型存的Topic数据,删的时候是如何删的
如果是跨集群多副本的Topic,删除过程如何回收其他集群的副本?
pulsar的Topic可以被close吗,什么场景下会被使用?
pulsar如何避免大量删Topic时对线上稳定性有影响
写在最后
参考资料
- http://matt33.com/2018/06/18/topic-create-alter-delete/