【LeetCode周赛】第373场周赛
LeetCode第373场周赛
- 2946. 循环移位后的矩阵相似检查 简单
- 2947. 统计美丽子字符串 I 中等
- 2948. 交换得到字典序最小的数组 中等
- 2949. 统计美丽子字符串 II 困难
2946. 循环移位后的矩阵相似检查 简单
2946. 循环移位后的矩阵相似检查
分析:
对于循环位移k,当 k = 1 k =1 k=1,此时是向左或者向右循环移动、当 k = n + 1 k = n+1 k=n+1,此时与 k = 1 k=1 k=1情况类似,最终也是想左或向右循环移动。因此我们可以先将 k 对 n 取模。
此时我们可以尝试暴力的方式进行循环左右平移。
但对于奇数与偶数的不同方向循环移动,其实有点麻烦。
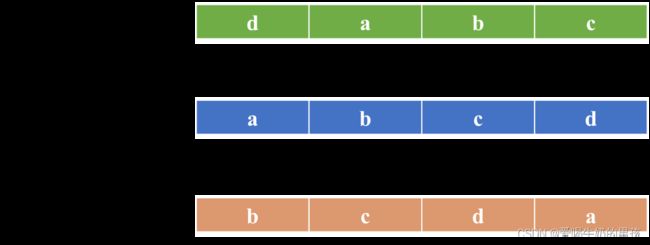
假设矩阵某行元素为 [a, b, c, d],其循环左移一位与循环右移一位的结果如图:
循环右移 1 位与原数组的映射:
{a=b、b=c、c=d、d=a }
循环左移 1 位与原数组的映射:{a=d、b=a、c=b、d=c }
由映射关系可以得到:如果循环右移一位与原数组相等,那么循环左移一位也肯定是相等的。
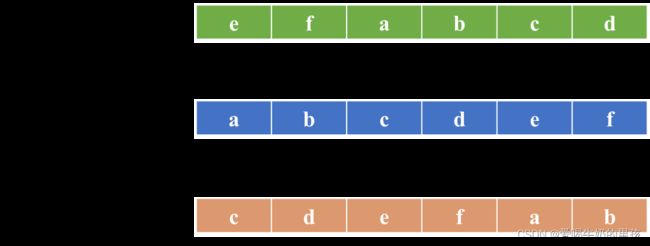
假设矩阵某行元素为 [a, b, c, d, e, f],其循环左移一位与循环右移一位的结果如图:
循环右移 2 位与原数组的映射:
{a=e、b=f、c=a、d=b、e=c、f=d }
循环左移 2 位与原数组的映射:{a=c、b=d、c=e、d=f、e=a、f=b }
循环左移两位中的a=c,可以由循环右移中a=e与e=c推导得出,其余的类似。最终可以得出两组映射是完全相等的。
因此循环左移k位后数组与原数组相同,则循环右移k位后数组也与原数组相同!
此时,我们就可以不用管是左移还是右移,直接统一一个方向即可。
代码:
暴力模拟每一个数字每一位移动的情况(容易超时):
class Solution {
public:
bool areSimilar(vector<vector<int>>& mat, int k) {
vector<vector<int>> map(mat);
int n=mat.size(), m=mat[0].size();
for(int i=0;i<n;i++){
int l=k%m;
while(l--){
if(i%2==0){
int tmp=map[i][0];
for(int j=1;j<m;j++) map[i][j-1]=map[i][j];
map[i][m-1]=tmp;
}else{
int tmp=map[i][m-1];
for(int j=m-2;j>=0;j--) map[i][j+1]=map[i][j];
map[i][0]=tmp;
}
}
}
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
if(map[i][j]!=mat[i][j]) return false;
}
}
return true;
}
};
优化每一次的循环位移,直接一步到位进行对比。进行了奇偶的判断,对奇偶进行了不同的操作。
class Solution {
public:
bool areSimilar(vector<vector<int>>& mat, int k) {
int n=mat.size(), m=mat[0].size(), l=k%m;;
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
if(i%2==0){
if(mat[i][j]!=mat[i][(m-l+j)%m]) return false;
}else{
if(mat[i][j]!=mat[i][(j+l)%m]) return false;
}
}
}
return true;
}
};
利用推导结论:循环左移k位满足要求,则循环右移k位也满足要求。
class Solution {
public:
bool areSimilar(vector<vector<int>>& mat, int k) {
int n=mat.size(), m=mat[0].size(), l=k%m;;
for(int i=0;i<n;i++){
for(int j=0;j<m;j++){
if(mat[i][j]!=mat[i][(j+k)%m]) return false;
}
}
return true;
}
};
优化之后的python代码:
class Solution:
def areSimilar(self, mat: List[List[int]], k: int) -> bool:
k=k%len(mat[0])
for r in mat:
t = r.copy()
r = r[k:] + r[:k]
if r!=t:
return False
return True
时间复杂度 :
- 暴力: T ( n ) = O ( m n ( k % m ) ) T(n) = O(mn(k\%m)) T(n)=O(mn(k%m))
- 优化位移: T ( n ) = O ( m n ) T(n) = O(mn) T(n)=O(mn)
- 优化奇偶左右位移的不同操作: T ( n ) = O ( m n ) T(n) = O(mn) T(n)=O(mn)
空间复杂度:
- 暴力:创建了一个二维数组存储原数组 S ( n ) = O ( m n ) S(n) = O(mn) S(n)=O(mn)
- 优化位移: S ( n ) = O ( m n ) S(n) = O(mn) S(n)=O(mn)
- 优化奇偶左右位移的不同操作: S ( n ) = O ( m n ) S(n) = O(mn) S(n)=O(mn)
2947. 统计美丽子字符串 I 中等
2947. 统计美丽子字符串 I
分析:
个人思考:美丽子字符串:元音字符数量 = 辅音字符数量,同时二者乘积可以被 k 整除。
定义 i 和 j , O [ i ] [ j ] O[i][j] O[i][j] 代表 i ~ j 这一段子字符串中 元音字符数量 - 辅音字符数量。 P [ i ] [ j ] P[i][j] P[i][j] 代表 i ~ j 这一段子字符串中 元音字符数量。
获得转移方程:
O [ i ] [ j ] = { O [ i ] [ j − 1 ] − 1 s [ j ] 不为元音字符 O [ i ] [ j − 1 ] + 1 s [ j ] 为元音字符 P [ i ] [ j ] = { P [ i ] [ j − 1 ] s [ j ] 不为元音字符 O [ i ] [ j − 1 ] + 1 s [ j ] 为元音字符 \begin{equation} O[i][j]=\begin{cases} O[i][j-1]-1 & s[j]不为元音字符 \\ O[i][j-1]+1 & s[j]为元音字符 \end{cases} \end{equation} \\ \\ \begin{equation} P[i][j]=\begin{cases} P[i][j-1] & s[j]不为元音字符 \\ O[i][j-1]+1 & s[j]为元音字符 \end{cases} \end{equation} O[i][j]={O[i][j−1]−1O[i][j−1]+1s[j]不为元音字符s[j]为元音字符P[i][j]={P[i][j−1]O[i][j−1]+1s[j]不为元音字符s[j]为元音字符
仅当 O [ i ] [ j ] = = 0 O[i][j] == 0 O[i][j]==0 且 ( P [ i ] [ j ] ∗ P [ i ] [ j ] ) % k = = 0 (P[i][j] * P[i][j])\%k==0 (P[i][j]∗P[i][j])%k==0 时,该子字符串才满足要求。
可以利用 前缀和 优化成一维的矩阵,可以降低空间消耗。
更优思路: 见第四题
代码:
二维数组记录中间值:
class Solution {
public:
int beautifulSubstrings(string s, int k) {
int n=s.length(), ans=0;
vector<vector<int>> o(n, vector<int>(n,0));
vector<vector<int>> p(n, vector<int>(n,0));
for(int i=0;i<n;i++){
if(s[i]=='a'||s[i]=='e'||s[i]=='i'||s[i]=='o'||s[i]=='u') o[i][i]=p[i][i]=1;
else o[i][i]=-1;
for(int j=i+1;j<n;j++){
if(s[j]=='a'||s[j]=='e'||s[j]=='i'||s[j]=='o'||s[j]=='u'){
o[i][j]=o[i][j-1]+1;
p[i][j]=p[i][j-1]+1;
}
else{
o[i][j]=o[i][j-1]-1;
p[i][j]=p[i][j-1];
}
if(o[i][j]==0&&p[i][j]*p[i][j]%k==0) ans++;
}
}
return ans;
}
};
优化空间,利用前缀和优化成一维数组:
class Solution {
public:
int beautifulSubstrings(string s, int k) {
int n=s.length(), ans=0;
int o[n+1];
int p[n+1];
memset(o,0,sizeof(o));
memset(p,0,sizeof(p));
// 进行前缀和计算,o[i]表示0~i所有的元音字符数量-辅音字符数量
// p[i]表示0~i所有元音字符的数量之和
for(int i=0;i<n;i++){
if(s[i]=='a'||s[i]=='e'||s[i]=='i'||s[i]=='o'||s[i]=='u'){
if(i==0) o[i]=1,p[i]=1;
else o[i]=o[i-1]+1,p[i]=p[i-1]+1;
}
else{
if(i==0) o[i]=-1,p[i]=0;
else o[i]=o[i-1]-1,p[i]=p[i-1];
}
}
for(int i=0;i<n;i++){
for(int j=i;j<n;j++){
int oo,pp;
if(i==0) oo=o[j],pp=p[j];
else oo=o[j]-o[i-1],pp=p[j]-p[i-1];
if(oo==0&&pp*pp%k==0) ans++;
}
}
return ans;
}
};
时间复杂度:
- 二维数组:枚举了每一个子串,因此总时间复杂度 : T ( n ) = O ( n 2 ) T(n) = O(n^2) T(n)=O(n2)
- 前缀和优化为一维数组:也枚举了每一个子串,因此总时间复杂度: T ( n ) = O ( n 2 ) T(n) = O(n^2) T(n)=O(n2)
空间复杂度:
- 二维数组:创建了两个二维数组,因此总的空间复杂度为: S ( n ) = O ( n 2 ) S(n) = O(n^2) S(n)=O(n2)
- 前缀和优化为一维数组:利用前缀和方式将二维数组优化成了一维数组,因此只创建了两个一维数组,总空间复杂度: S ( n ) = O ( n ) S(n) = O(n) S(n)=O(n)
2948. 交换得到字典序最小的数组 中等
2948. 交换得到字典序最小的数组
分析:
对于任意两个下标 i 和 j ,只有满足 ∣ n u m s [ i ] − n u m s [ j ] ∣ < = l i m i t | nums[i] - nums[j] | <= limit ∣nums[i]−nums[j]∣<=limit ,才能进行位置的交换。
基于此条件,我们可以先进行升序排序,再从头遍历,将数分为若干组(至少一个组),组内存在两个数a与b(b>=a),满足 b − a < = l i m i t b - a <= limit b−a<=limit。
假设某个分组的情况如下,第一行为对应的下标,第二行为对应的值。可以看到所有的值都有至少一个对应的另外一个值,满足 ∣ a − b ∣ < = l i m i t | a - b | <= limit ∣a−b∣<=limit。

短暂思考与计算之后,我们可以得出同一组的数,如果要得到最小的字典序,那就要将最小的数对应到最小的下标。而同一组数,经过有限次的交换,即可完成最小数对应最小下标。
最终我们只需要将坐标数组与数值数组升序排序,再一一对应即可。

最终对应的结果:

将每一组的所有数,插入其对应下标位置即可得到交换后能得到的字典序最小的序列。
代码:
C++代码:
class Solution {
public:
vector<int> lexicographicallySmallestArray(vector<int>& nums, int limit) {
vector<pair<int, int>> nu; // 需要同时记录数和对应的下标
int n=nums.size();
for(int i=0;i<n;i++){
nu.push_back(make_pair(i, nums[i]));
}
sort(nu.begin(), nu.end(), [&](auto a, auto b){return a.second<b.second;});// 按照数进行升序排序
for(int i=0;i<n;){
int j=i;i++;
vector<int> tmp,index;
tmp.push_back(nu[j].second);index.push_back(nu[j].first);
for(;i<n && (nu[i].second-nu[i-1].second<=limit);i++) tmp.push_back(nu[i].second),index.push_back(nu[i].first);
// 下标要进行升序排序,来达到对应的情况。数已经进行了升序排序了,因此直接使用即可
sort(index.begin(), index.end());
for(int k=j,o=0;k<n&&k<i;k++,o++){
nums[index[o]]=tmp[o];
}
}
return nums;
}
};
python代码:
class Solution:
def lexicographicallySmallestArray(self, nums: List[int], limit: int) -> List[int]:
n = len(nums)
t = sorted(zip(nums, range(n))) # 将 nums 与对应的下标相结合排序,排序规则还是按照nums中的值进行排序的
ans = [0] * n
i=0
while i < n:
j = i
i+=1
while i<n and t[i][0] - t[i-1][0] <= limit:
i+=1
ids = sorted([id for _,id in t[j:i]])
for k in range(j,i):
ans[ids[k-j]]=t[k][0]
return ans
时间复杂度: 代码中存在循环中嵌套快排,设想中最坏的情况:即外层循环进行 O ( n ) O(n) O(n)次,内层排序 O ( n l o g n ) O(nlogn) O(nlogn)。
但代码中当 外层循环 进行n次的话, 内层快排 仅仅只会进行常数的排序、当 内层排序 达到 O ( n l o g n ) O(nlogn) O(nlogn)时, 外层循环 只会进行一次。
因此总的时间复杂度: T ( n ) = O ( n l o g n ) T(n) = O(nlogn) T(n)=O(nlogn)
空间复杂度: 创建一个一维数组,因此为: S ( n ) = O ( n ) S(n) = O(n) S(n)=O(n)
2949. 统计美丽子字符串 II 困难
2949. 统计美丽子字符串 II
分析:
观察美丽子字符串的条件:
1、元音字母的数量 a 和 辅音字母的数量 b的相等,即 a = = b a==b a==b。假设美丽子字符串的长度为 L L L,那么满足条件 a = b = L / 2 a = b = L/2 a=b=L/2。
2、元音字母的数量 a 和 辅音字母的数量 b 乘积能被 k 整除,根据第一点条件得: ( L / 2 ) 2 % k = 0 (L/2)^2\ \%\ k = 0 (L/2)2 % k=0。整理得出 L 2 L^2 L2 包含 4 k 4k 4k 这一因子。
第一个条件很容易满足,遇到元音字母 sum+1 ,遇到辅音字母sum-1,只需要不断地记录 j 时sum的值。如果i+1 到 j 中元音与辅音字母数量相等,则 s u m i = = s u m j sum_i == sum_j sumi==sumj ,使用 hash表映射即可满足。
第二个条件则必须记录 i+1 到 j 中元音字母出现的次数(或整个长度),这样又需要枚举 i 与 j ,会超时。所以我们必须简化该式子,找到更简便的方法。
对于 L 2 L^2 L2 包含 4 k 4k 4k 这个因子,那 L L L 需要满足什么要求呢?
假设要判断某个质数 r r r 是否为 L 2 L^2 L2 的因子,那 L L L 的因子必须要包含 r r r。因为如果 L L L 的因子不包含 r r r,就算 L 2 L^2 L2 也一定不会包含。
假设要判断某个质数 r r r 的 e e e 次幂是否为 L 2 L^2 L2 的因子:
- 若 e e e 为偶数,显然只需要 r e / 2 r^{e/2} re/2 为 L L L 的因子即可。
- 若 e e e 为奇数,显然需要 r e / 2 + 1 r^{e/2+1} re/2+1 为 L L L 的因子即可。例如 r 5 r^5 r5,那么必须 r 3 r^3 r3 为 L L L 的因子,即 r 6 r^6 r6 为 L 2 L^2 L2的因子,此时 r 5 r^5 r5 也一定是 L 2 L^2 L2的因子。
假设 r r r 是由两个质数 r 1 r_1 r1 和 r 2 r_2 r2 的 e 1 e_1 e1 和 e 2 e_2 e2 次幂的乘积组成, r r r 是 L 2 L^2 L2 的因子,满足条件: r 1 ( e 1 + 1 ) / 2 ∗ r 2 ( e 2 + 1 ) / 2 r_1^{(e_1+1)/2} * r_2^{(e_2+1)/2} r1(e1+1)/2∗r2(e2+1)/2 是 L L L 的因子, r r r 是 L 2 L^2 L2 的因子。
PS: ( e 1 + 1 / 2 ) (e_1+1/2) (e1+1/2) 利用了C++中的整形自动去除小数的功能,如果 e 1 e_1 e1为奇数,则次数增加了1,如果为偶数则不影响。
基于上述推论,对 4 k 4k 4k 进行质因数分解,得到 k ′ k' k′,此时只需要 L L L 的因子包含 k ′ k' k′ 即可,即 ( j − i ) % k ′ = = 0 (j - i ) \% k' == 0 (j−i)%k′==0,当 i % k ′ = = j % k ′ i \% k' == j \% k' i%k′==j%k′ 即可满足上述条件。
最终将 i % k ′ i \% k' i%k′ 与 s u m i sum_i sumi 结合作为hash表的key,当key相同时,根据value值来增加美丽子字符串的数量。
对于元音字母 a 、 e 、 i 、 o 、 u a、e、i、o、u a、e、i、o、u ,利用其与 a a a 的相对位置构成二进制数,元音字母对应位置置 1 。只需要左移对应位置,然后与 1 按位相与就可判断是否为元音字母。
代码:
C++代码:
class Solution {
public:
int prime_factor(int k){
int res=1;
for(int i=2;i*i<=k;i++){
int t = i*i;
while(k%t==0){
res*=i;
k/=t;
}
if(k%i==0){
res*=i;
k/=i;
}
}
if(k>1) res*=k;
return res;
}
const int MASK = 1065233;
int beautifulSubstrings(string s, int k) {
k=prime_factor(4*k);
map<pair<int, int>, int> cnt;
int n=s.length(), sum=0, ans=0;
cnt[{k-1, 0}]++;
for(int i=0;i<n;i++){
int b=((MASK >> (s[i] - 'a')) & 1);
sum+=(2*b-1);
ans+=cnt[{i%k, sum}]++;
}
return ans;
}
};
python代码:
class Solution:
def prime_factor(self, k: int) -> int:
res = 1
i=2
while i * i <= k:
t = i*i
while k%t==0:
res *= i
k //= t
if k%i==0:
res *= i
k //= i
i+=1
if k>1:
res *= k
return res
def beautifulSubstrings(self, s: str, k: int) -> int:
k = self.prime_factor(4*k)
cnt = Counter()
cnt[(k-1, 0)]+=1
p_sum = 0
ans = 0
for i,c in enumerate(s):
p_sum += 1 if c in "aeiou" else -1
p = (i %k, p_sum)
ans += cnt[p]
cnt[p]+=1
return ans
时间复杂度: 一维循环,总时间复杂度: T ( n ) = O ( n ) T(n) = O(n) T(n)=O(n)
空间复杂度: 创建了一个map作为hash表,总空间复杂度: S ( n ) = O ( n ) S(n) = O(n) S(n)=O(n)