rime中州韵小狼毫 生字注音滤镜 汉字注音滤镜
在中文环境下,多音字是比较常见的现象。对于一些不常见的生僻字,或者一些用于地名,人名中的常见字的冷门读音,如果不能正确的阅读,例如把 荥阳 读成了 miāo yáng,则会怡笑大方。
今天我们在rime中州韵小狼毫输入法中配置一个注音滤镜,以便我们在日常的文字输入时,可以经常的,实时的学习、复习、强化这些文字的读音,不做白字先生。
先睹为快
本文所分离的在rime中州韵小狼毫须鼠管输入法中的生字注音效果如下:
![]()
pinyinAdding.txt
首先,我们需要一个文档来记录和管理汉字与注音的信息。pinyinAdding.txt 文档的内容截取部分展示如下:
冔 冔(xǔ)
玏 玏(lè)
鹯 鹯(zhān)
亶 亶(dǎn)
荥 荥(yíng)
荥阳 荥(xíng)阳
以上,pinyinAdding.txt 文档中的内容主要有两列,以 tag 制表符分隔。第一列是汉字或者词组,第二列是带有注音的词组。顺序无先后。但在后续的lua滤镜中,会被处理成优先匹配词组的逻辑。例如词组荥阳会优先匹配荥(xíng)阳,而不是匹配成 荥(yíng)阳。
pinyinAddingModule.lua
我们有了字典文档 pinyinAdding.txt,但这并没有办法在输入引擎中直接使用。我们还需要一个lua脚本,将 pinyinAdding.txt 文档内的词组加载到lua程序中。pinyinAddingModule.lua 脚本文档中的脚本如下:
-- pinyinAddingModule.lua
-- Copyright (C) 2023 yaoyuan.dou 以上脚本中,我们将指定的 pinyinAdding.txt 文档中的词组加载为一个 dict 的字典对象,然后给出了一个检索字典的方法 pinyinAdding。我们通过方法pinyinAdding可以方便的检索出指定关键字的注音版本词组。
pinyinAdding_Filter.lua
在脚本文档 pinyinAddingModule.lua 中,我们加载并定义了词组的检索方法。现在我们需要在脚本文档 pinyinAdding_Filter.lua 内将词组检索方法整理成rime引擎的滤镜方法,pinyinAdding_Filter.lua文档内的脚本如下:
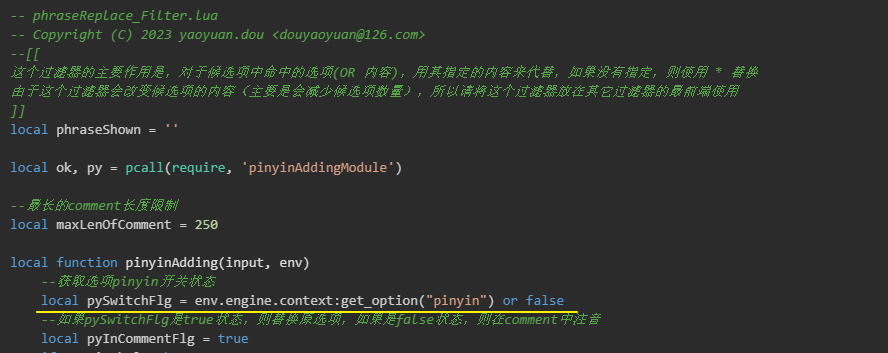
-- phraseReplace_Filter.lua
-- Copyright (C) 2023 yaoyuan.dou 以上脚本中, 我们定义了滤镜方法 pinyinAdding 并返回/抛出了该方法。
注意:
以上所述文档 pinyinAdding.txt,pinyinAddingModule.lua,pinyinAdding_Filter.lua 三个文档,应该位于 用户文件夹 下的 lua 文件夹内。如下:

rime.lua
以上我们完成了 pinyinAdding 滤镜方法的定义,现在我们需要在文档 rime.lua 中将该 pinyinAdding 滤镜方法映射成 pinyinAdding_Filter 滤镜接口。我们在 rime.lua 中增加以下脚本:
help_translator = require("help")
inputShow_translator = require("inputShow")
inputShow_Filter = require("inputShow_Filter")
Upper_Filter = require("Upper_Filter")
dic_4w_Filter = require("dic_4w_Filter")
phraseReplace_Filter = require("phraseReplace_Filter")
pinyinAdding_Filter = require("pinyinAdding_Filter")
以上脚本中,注音最后一行的 pinyinAdding_Filter 的定义。
wubi_pinyin.custom.yaml
以上步骤中,我们完成了pinyinAdding_Filter滤镜的定义。现在万事俱备,只欠东风了。我们只需要在我们的输入方案中配置引用该 pinyinAdding_Filter 滤镜,即可看到文字注音的效果了。
现在我们以 五笔・拼音 输入方案为例来配置生字注音滤镜。我们在 五笔・拼音输入方案的方案文档 wubi_pinyin.schema.yaml 的补丁文档 wubi_pinyin.custom.yaml 加入以下配置:
patch:
switches/+: #增加以下开关
- name: pinyin # 这个开关用于标记是否打开拼音滤镜
reset: 0
states: [Off, pīnyīn]
engine/filters: # 设置以下filter
- simplifier
# 下面的滤镜是comment滤镜,不会改变候选项列表
- lua_filter@pinyinAdding_Filter # pinyin滤镜,用于对候选项中的字添加拼音
以上的配置中,我们增加了两项内容,一个是switch开关pinyin, 一个是lua_filter 滤镜 pinyinAdding_Filter。这是因为我们在 pinyinAdding_Filter.lua 脚本中会检测开关pinyin的状态以决定是否启用滤镜功能。如下:
注意:
文档 rime.lua 和 wubi_pinyin.custom.yaml 都应该位于 用户文件夹下,这不需要再多说什么了。
pinyinAdding.txt/pinyinAddingModule.lua/pinyinAdding_Filter.lua/rime.lua/wubi_pinyin.custom.yaml 文档
以上所述 pinyinAdding.txt、pinyinAddingModule.lua、pinyinAdding_Filter.lua、rime.lua、wubi_pinyin.custom.yaml 五个文档,你也可以在 rime中州韵小狼毫 生字注音滤镜.zip 下载取用。
效果欣赏
做完了以上的配置工作,不要忘了 重新部署 你的 rime。然后你就应该能够观察到文字注音效果了。如下:
![]()
小结
本文分享了一种在rime中州韵小狼毫须鼠管输入法中配置生字注音滤镜的方法,并以五笔・拼音 输入方案为例,配置并演示了生字注音滤镜的功能效果。本文所配置文档共5个,其中 pinyinAdding.txt 文档为词组管理文档,通过这个文档可以非常方便的增删管理生字及其注音信息;pinyinAddingModule.lua 脚本文档提供了 pinyinAdding.txt 词组的加载和解析功能,并提提供了检索方法的接口;pinyinAdding_Filter.lua 文档定义了基于rime引擎接口的滤镜方法;最后我们在 rime.lua 脚本和 wubi_pinyin.custom.yaml 文档中配置和使用了该滤镜。并在最终的功能效果中观察到了预期的功能效果。