Rust 常用集合(上)
目录
1、使用 Vector 储存列表
1.1 新建 vector
1.2 更新 vector
1.3 读取 vector 的元素
1.4 遍历 vector 中的元素
1.5 使用枚举来储存多种类型
1.6 丢弃 vector 时也会丢弃其所有元素
2、使用字符串储存 UTF-8 编码的文本
2.1 什么是字符串?
2.2 新建字符串
2.3 更新字符串
2.3.1 使用 push_str 和 push 附加字符串
2.3.2 使用 + 运算符或 format! 宏拼接字符串
2.3.3 索引字符串
2.3.4 字符串 slice
2.3.5 遍历字符串的方法
2.3.6 字符串并不简单
Rust 标准库中包含一系列被称为 集合(collections)的非常有用的数据结构。大部分其他数据类型都代表一个特定的值,不过集合可以包含多个值。不同于内建的数组和元组类型,这些集合指向的数据是储存在堆上的,这意味着数据的数量不必在编译时就已知,并且还可以随着程序的运行增长或缩小。每种集合都有着不同功能和成本,而根据当前情况选择合适的集合,以下三种是在 Rust 程序中被广泛使用的集合;
- vector 允许我们一个挨着一个地储存一系列数量可变的值
- 字符串(string)是字符的集合。我们之前见过
String类型,不过在本章我们将深入了解。 - 哈希 map(hash map)允许我们将值与一个特定的键(key)相关联。这是一个叫做 map 的更通用的数据结构的特定实现。
1、使用 Vector 储存列表
我们要讲到的第一个类型是 Vec,也被称为 vector。vector 允许我们在一个单独的数据结构中储存多于一个的值,它在内存中彼此相邻地排列所有的值。vector 只能储存相同类型的值。
1.1 新建 vector
为了创建一个新的空 vector,可以调用 Vec::new 函数,如下所示:
let v: Vec = Vec::new();
这里,定义了一个变量v,是vector类型,类型后面使用一对尖括号来表示Vector类型的泛型,在这里指定的是i32类型,所以变量v存储的是一组i32组成的集合。
通常,我们会用初始值来创建一个 Vec 而 Rust 会推断出储存值的类型,所以很少会需要这些类型注解。为了方便 Rust 提供了 vec! 宏,这个宏会根据我们提供的值来创建一个新的 vector。
fn main() {
let v = vec![1, 2, 3, 4, 5, 6];
println!("{:?}", v.len()) // 6
}因为我们提供了 i32 类型的初始值,Rust 可以推断出 v 的类型是 Vec,因此类型声明就不是必须的。
1.2 更新 vector
对于新建一个 vector 并向其增加元素,可以使用 push 方法
fn main() {
let mut v = Vec::new();
v.push(1);
v.push(2);
v.push(3);
println!("{:?}", v.len()) // 3
}1.3 读取 vector 的元素
fn main() {
let mut v = Vec::new();
v.push(1);
v.push(2);
v.push(3);
let first = &v[0];
println!("{:?}", first); // 3
println!("{:?}", &v[100]); // index out of bounds:
println!("{:?}", v.get(1)); // Some(2)
}这里有几个细节需要注意。我们使用索引值 2 来获取第三个元素,因为索引是从数字 0 开始的。使用 & 和 [] 会得到一个索引位置元素的引用。当使用索引作为参数调用 get 方法时,会得到一个可以用于 match 的 Option<&T>。
当我们获取了 vector 的第一个元素的不可变引用并尝试在 vector 末尾增加一个元素的时候,如果尝试在函数的后面引用这个元素是行不通的:
fn main() {
let mut v = Vec::new();
v.push(1);
v.push(2);
v.push(3);
let first = &v[0];
v.push(100); // 报错......
println!("{:?}", first); // 3
println!("{:?}", &v[100]); // index out of bounds:
println!("{:?}", v.get(1)); // Some(2)
}会抛出如下错误:
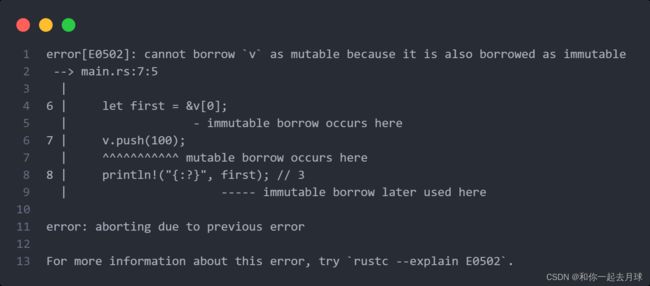
所以在 vector 的结尾增加新元素时,在没有足够空间将所有元素依次相邻存放的情况下,可能会要求分配新内存并将老的元素拷贝到新的空间中。这时,第一个元素的引用就指向了被释放的内存。借用规则阻止程序陷入这种状况。
1.4 遍历 vector 中的元素
如果想要依次访问 vector 中的每一个元素,我们可以遍历其所有的元素而无需通过索引一次一个的访问。如下所示:
fn main() {
let mut v = Vec::new();
v.push(1);
v.push(2);
v.push(3);
for i in &v {
println!("{}", i)
}
}我们也可以遍历可变 vector 的每一个元素的可变引用以便能改变它们。如下所示:
fn main() {
let mut v = Vec::new();
v.push(1);
v.push(2);
v.push(3);
for i in &mut v {
*i *= 10;
}
println!("{:?}", v) // [10, 20, 30]
}修改可变引用所指向的值,在使用 *= 运算符之前必须使用解引用运算符(*)获取 i 中的值。
1.5 使用枚举来储存多种类型
vector 只能储存相同类型的值。这是很不方便的;绝对会有需要储存一系列不同类型的值的用例。幸运的是,枚举的成员都被定义为相同的枚举类型,所以当需要在 vector 中储存不同类型值时,我们可以定义并使用一个枚举!看一下下面这个示例:
fn main() {
#[derive(Debug)]
enum Value {
Int(i32),
Float(f32),
Text(String),
Valid(bool),
}
let mut v = Vec::new();
v.push(Value::Int(1));
v.push(Value::Float(1.1));
v.push(Value::Text(String::from("wangwu")));
v.push(Value::Valid(true));
println!("{:?}", v) // [Int(1), Float(1.1), Text("wangwu"), Valid(true)]
}Rust 在编译时就必须准确的知道 vector 中类型的原因在于它需要知道储存每个元素到底需要多少内存。第二个好处是可以准确的知道这个 vector 中允许什么类型。如果 Rust 允许 vector 存放任意类型,那么当对 vector 元素执行操作时一个或多个类型的值就有可能会造成错误。
1.6 丢弃 vector 时也会丢弃其所有元素
类似于任何其他的 struct,vector 在其离开作用域时会被释放,如下所示:
{
let v = vec![1, 2, 3, 4];
// todo
} // 超出作用域,v被丢弃,对应的元素值也会被丢弃2、使用字符串储存 UTF-8 编码的文本
2.1 什么是字符串?
在开始深入这些方面之前,我们需要讨论一下术语 字符串 的具体意义。Rust 的核心语言中只有一种字符串类型:字符串 slice str,它通常以被借用的形式出现,&str。第四章讲到了 字符串 slices:它们是一些对储存在别处的 UTF-8 编码字符串数据的引用。举例来说,由于字符串字面值被储存在程序的二进制输出中,因此字符串字面值也是字符串 slices。
字符串(String)类型由 Rust 标准库提供,而不是编入核心语言,它是一种可增长、可变、可拥有、UTF-8 编码的字符串类型。当 Rustaceans 提及 Rust 中的 "字符串 "时,他们可能指的是 String 或 string slice &str 类型,而不仅仅是其中一种类型。虽然本节主要讨论 String,但这两种类型在 Rust 的标准库中都有大量使用,而且 String 和 字符串 slices 都是 UTF-8 编码的。
2.2 新建字符串
很多 Vec 可用的操作在 String 中同样可用,事实上 String 被实现为一个带有一些额外保证、限制和功能的字节 vector 的封装。其中一个同样作用于 Vec 和 String 函数的例子是用来新建一个实例的 new 函数,如下所示:
let mut s = String::new();
上面创建了一个叫做 s 的空的字符串,接着我们可以向其中装载数据。通常字符串会有初始数据,因为我们希望一开始就有这个字符串。为此,可以使用 to_string 方法,它能用于任何实现了 Display trait 的类型,比如字符串字面值。如下所示:
fn main() {
let data = "test string";
let s = data.to_string();
// 该方法也可直接用于字符串字面值:
let s = "test string".to_string();
println!("{:?}", s) // test string
}也可以使用 String::from 函数来从字符串字面值创建 String。如下所示:
let data = String::from("test string");
2.3 更新字符串
String 的大小可以增加,其内容也可以改变,就像可以放入更多数据来改变 Vec 的内容一样。另外,可以方便的使用 + 运算符或 format! 宏来拼接 String 值。
2.3.1 使用 push_str 和 push 附加字符串
可以通过 push_str 方法来附加字符串 slice,从而使 String 变长,如下所示:
fn main() {
let mut s = String::from("hello ");
s.push_str("world");
println!("{}", s) // hello world
}push 方法被定义为获取一个单独的字符作为参数,并附加到 String 中。如下所示:
fn main() {
let mut s = String::from("hell");
s.push('o');
println!("{s}");
}2.3.2 使用 + 运算符或 format! 宏拼接字符串
通常你会希望将两个已知的字符串合并在一起。一种办法是像这样使用 + 运算符,如下所示:
fn main() {
let h = String::from("hello ");
let w = String::from("world");
let res = h + &w;
println!("{res}"); // hello world
}执行完代码之后,h在相加之后不再有效,+运算符调用时跟函数签名有关,+运算符使用了add函数,这个函数看起来像这样:
fn add(mut self, other: &str) -> String {
self.push_str(other);
self
}首先,w 使用了 &,意味着我们使用第二个字符串的 引用 与第一个字符串相加。这是因为 add 函数的 s 参数:只能将 &str 和 String 相加,不能将两个 String 值相加。不过等一下 —— &w的类型是 &String, 而不是 add 第二个参数所指定的 &str。那么为什么还能编译呢?
之所以能够在 add 调用中使用 &w 是因为 &String 可以被 强转(coerced)成 &str。当add函数被调用时,Rust 使用了一个被称为 Deref 强制转换(deref coercion)的技术,你可以将其理解为它把 &w 变成了 &w[..]。因为 add 没有获取参数的所有权,所以 w 在这个操作后仍然是有效的 String。
其次,可以发现签名中 add 获取了 self 的所有权,因为 self 没有 使用 &。这意味着示例 8-18 中的 h 的所有权将被移动到 add 调用中,之后就不再有效。所以虽然 let res = h + &w; 看起来就像它会复制两个字符串并创建一个新的字符串,而实际上这个语句会获取 h 的所有权,附加上从 w 中拷贝的内容,并返回结果的所有权。换句话说,它看起来好像生成了很多拷贝,不过实际上并没有:这个实现比拷贝要更高效。
如果想要级联多个字符串,+ 的行为就显得笨重了:
fn main() {
let h = String::from("hello ");
let w = String::from("world");
let t = String::from(", 123");
let res = h + &w + &t;
println!("{res}"); // hello world, 123
}对于更为复杂的字符串链接,我们可以使用 format! 宏:
fn main() {
let h = String::from("hello ");
let w = String::from("world");
let t = String::from(", 123");
println!("{h}{w}{t}"); // hello world, 123
}2.3.3 索引字符串
在很多语言中,通过索引来引用字符串中的单独字符是有效且常见的操作。然而在 Rust 中,如果你尝试使用索引语法访问 String 的一部分,会出现一个错误。
fn main() {
let h = String::from("hello ");
let res = h[0];
}
我们可以看下字符串的实现。
pub struct String {
vec: Vec,
} 所以在获取索引的时候,并不会返回我们所期望的第一个字母,而在Rust在编译过程就会阻止,并报错。
2.3.4 字符串 slice
字符串索引应该返回的类型是不明确的:字节值、字符、字形簇或者字符串 slice。因此,如果你真的希望使用索引创建字符串 slice 时,Rust 会要求你更明确一些。为了更明确索引并表明你需要一个字符串 slice,相比使用 [] 和单个值的索引,可以使用 [] 和一个 range 来创建含特定字节的字符串 slice:
fn main() {
let h = "Здравствуйте";
let res = &h[0..4];
println!("{res}") // Зд
}如果获取 &h[0..1] 会发生什么呢?答案是:Rust 在运行时会 panic,就跟访问 vector 中的无效索引时一样:

2.3.5 遍历字符串的方法
操作字符串每一部分的最好的方法是明确表示需要字符还是字节。对于单独的 Unicode 标量值使用 chars 方法。对 “Зд” 调用 chars 方法会将其分开并返回两个 char 类型的值,接着就可以遍历其结果来访问每一个元素了:
fn main() {
let str = "Здравствуйте";
for i in str.chars() {
println!("{i}") // З д р ...
}
}另外 bytes 方法返回每一个原始字节,这可能会适合你的使用场景:
fn main() {
let str = "Здравствуйте";
for i in str.bytes() {
println!("{i}") // 208 151 ...
}
}2.3.6 字符串并不简单
总而言之,字符串还是很复杂的。不同的语言选择了不同的向程序员展示其复杂性的方式。Rust 选择了以准确的方式处理 String 数据作为所有 Rust 程序的默认行为,这意味着程序员们必须更多的思考如何预先处理 UTF-8 数据。这种权衡取舍相比其他语言更多的暴露出了字符串的复杂性,不过也使你在开发周期后期免于处理涉及非 ASCII 字符的错误。
好消息是标准库提供了很多围绕 String 和 &str 构建的功能,来帮助我们正确处理这些复杂场景。请务必查看这些使用方法的文档,例如 contains 来搜索一个字符串,和 replace 将字符串的一部分替换为另一个字符串。
称作 String 的类型是由标准库提供的,而没有写进核心语言部分,它是可增长的、可变的、有所有权的、UTF-8 编码的字符串类型。当 Rustacean 们谈到 Rust 的 “字符串”时,它们通常指的是 String 或字符串 slice &str 类型,而不特指其中某一个。虽然本部分内容大多是关于 String 的,不过这两个类型在 Rust 标准库中都被广泛使用,String 和字符串 slices 都是 UTF-8 编码的。