PV-RAFT:用于点云场景流估计的点体素相关场(CVPR2021)
在2019和2020年的CVPR上均有关于点云场景流的相关工作,今天介绍的是2021年CVPR上最新的关于点云场景流的工作。机器人和人机交互中的许多应用都可以从理解动态环境中点的三维运动中获益,这种运动被广泛称为场景流。相较于静态的点云,点云场景流估计更侧重于计算两个连续帧之间的3D运动场,这为场景提供了重要的动态信息。以往的方法大多以立体图像和RGB-D图像作为输入,很少有直接从点云估计场景流的方法。随着3D数据变得更容易获得,许多工作最近开始关注点云的场景流估计。
在本文中,作者提出了一种Point-Voxel Recurrent All-Pairs Field Transforms (PV-RAFT)方法来估计来自点云的场景流。由于点云是不规则且无序的,因此从3D空间中的所有对(all-pairs)场中有效提取特征十分具有挑战性,其中所有对相关性在场景流估计中起着重要作用。
为了解决这个问题,作者提出了点体素相关场(PV-RAFT),其核心有以下2点:
1)PV-RAFT通过学习点对的局部和全局的依赖关系,从而实现捕获基于点的相关性,同时采用K-Nearest Neighbors搜索来保留局部区域中的细节信息。
2)通过以多尺度方式对点云进行体素化,作者构建了金字塔相关体素来模拟大尺度上的对应关系。然后利用PV-RAFT融合处理这两种类型的相关性。
作者最后在FlyingThings3D和KITTI Scene Flow 2015数据集上取得了不错的结果。
作者的出发点是认为与从粗到细的策略相比,all-pairs场同时保留了局部相关性和远距离的全局关系。但考虑到点云的不规则性,在3D空间构建结构化的all-pairs相关场仍然十分困难,为了解决这些问题,作者提出了点体素相关性场,以多尺度方式对目标点云进行体素化以构建金字塔相关体素,这些场融合了基于点和基于体素的相关性的优点(如图1所示)。同时,为了节省内存,作者还提出了一种截断机制来选择性的放弃计算分数较低的相关场。
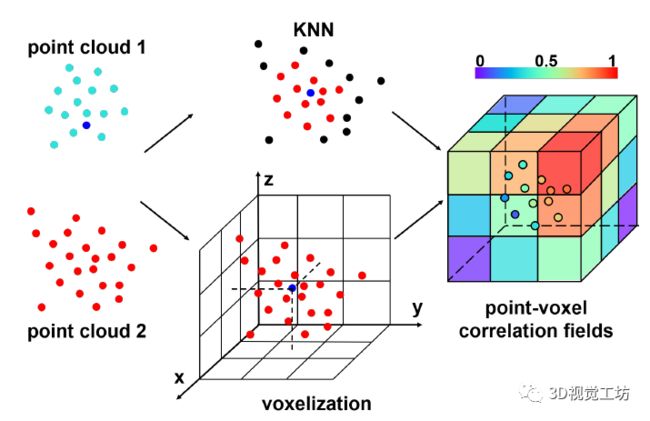
图1 点体素相关场的图示。对于源点云中的一个点,作者通过在目标点云中找到它的k近邻点来提取基于点的相关性。此外,作者还通过构建以该源点为中心的体素来模拟全局的远程交互。
核心方法:
为了构建所有点对场,设计一个可以同时捕获局部和全局关系的相关量是很重要的。这里主要解释如何在点云上构建点体素相关场。
作者首先基于所有对之间的特征相似性构建一个完整的相关卷积。给定点云特征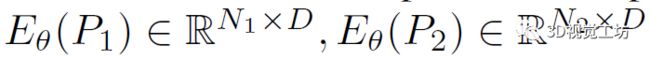 ,其中D是特征维度,相关域C∈ RN1×N2 可以通过矩阵点积计算,即:
,其中D是特征维度,相关域C∈ RN1×N2 可以通过矩阵点积计算,即:

点分支:作者使用 KNN近邻搜索定义:假设P2中Q的top-k个最近邻为Nk = N(Q)k,它们对应的相关值为CM(Nk),则Q与P2的相关特征可以定义为:
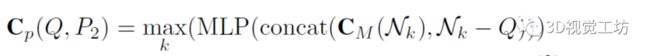
其中concat代表串联,max表示k维上的最大池化操作。因为最近邻点一般靠近查询点,所以点分支可以用来提取估计流的细粒度相关特征,如图1的上支所示。但作者也提到,虽然点分支能够捕获局部相关性,但全局关系在KNN场景中通常不考虑。现有的方法试图通过由粗到细的策略来解决这个问题,但是如果粗阶段的估计不准确,误差往往会累积。
体素分支:为了解决上述问题,作者又提出了一个体素分支来捕获远程的全局相关特征。作者没有直接对Q进行体素化,而是构建以Q为中心的体素相邻立方体,并检测P2中的哪些点位于这些立方体中。此外,还需要知道每个点与Q的相对方向。如果用r表示子立方体边长,用a表示立方体分辨率,那么Q的相邻立方体表示为a×a×a:

其中每个r×r×r子立方体N(i)r表示相邻点的一个特定的方向。然后我们识别子立方体中的所有邻域点N(i)r并对他们的相关值求平均值获得子立方体特征。Q和P2之间的相关特征可以定义为:

其中ni是P2中位于Q和Cv(Q, P2)∈RN1×a3的第i个子立方体中的点数。如图1的下部分支。Voxel分支有助于捕获远程的全局相关特征r,a可以足够大以覆盖远处的点。此外,作者建议立方体分辨率为固定值。
PV-RAFT框架:
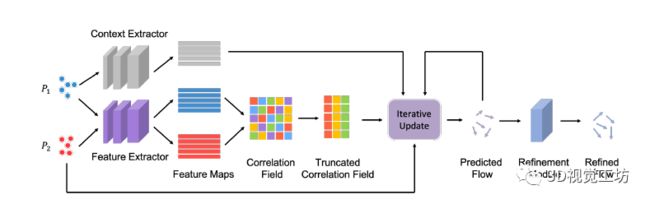
图2 PV-RAFT架构的图示。特征提取器对P1和P2的高维特征进行编码,而上下文提取器仅对P1的上下文特征进行编码。然后通过计算两个特征图的矩阵点积以构建所有对相关场。
鉴于所提出的结合细粒度和全局远程特征的相关场,作者构建了一个用于场景流估计的深度神经网络。pipeline由四个阶段组成,其中前三个阶段以端到端的方式进行,而第四个阶段是单独训练的。:
(1)特征提取:分层点云特征学习。
(2)相关场构建:我们基于主特征E (P1)、E (P2) 构建全对相关场C。用于后续迭代更新。
(3)迭代场景流估计:迭代流估计从初始化状态f0 = 0开始。随着每次迭代,场景流估计根据当前状态更新:ft+1 = ft + ∆f。最终,序列收敛fT → f。每次迭代都将以下变量作为输入:(a)相关特征,(b)当前流估计,(c)前一次迭代的隐藏状态,(d)上下文特征。
(4)流细化。设计这个流程细化模块的目的是使场景流预测f在3D空间中更加平滑。
实验环节:
实验环节作者在 FlyingThings3D 和 KITTI 数据集上进行了测试。作为一个大规模的合成数据集,FlyingThings3D是场景流估计的第一个基准。其包含ShapeNet对象,FlyingThings3D 由渲染过的立体图像和 RGB-D 图像组成。训练集中共有19,640对样本,测试集中共有3,824对样本。此外,训练集中保留了 2000个样本用于实验验证。同时将深度图像提升到点云,将光流提升到场景流,而不是对 RGB 图像进行操作。另一个基准KITTI Scene Flow 2015 是一个用于真实扫描场景流估计的数据集。它是通过利用 KITTI 原始数据进行动态运动标注构建的。
评价标准:端点误差(End-point-error, EPE)和流量估计精度(Acc)
表 1:FlyingThings3D和KITTI数据集的性能比较。所有方法都以受监督的方式在FlyingThings3D上进行训练。每个数据集的最佳结果以粗体标记。


图3 FlyingThings3D(上)和 KITTI(下)的定性结果。蓝点和红点分别表示P1和 P2。平移点P1 + f为绿色。PV-RAFT可以处理小位移和大位移的情况。
表 2:PV-RAFT 在 FlyingThings3D 数据集上的消融研究。作者依次将基于点的相关性、基于体素的相关性和细化模块应用于所提框架。

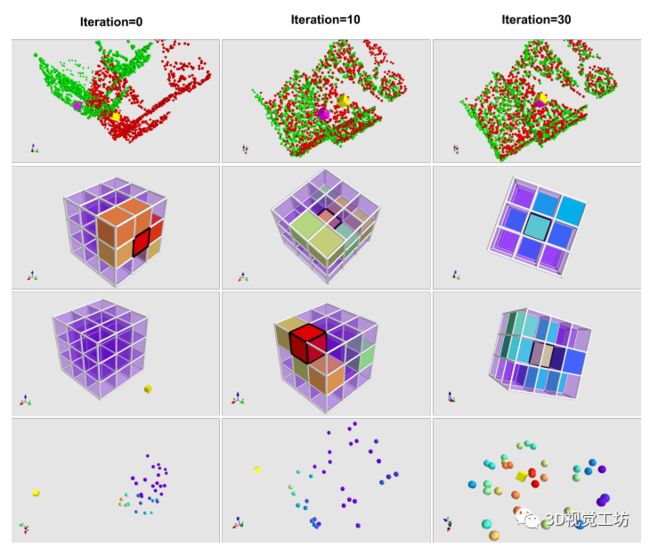
作者最后还对点体素相关场进行了可视化。第一行,绿点代表平移的点云P1+f,而红点代表目标点云P2。粉色立方体是平移后的点云中的一个点,它在P2中的对应关系是黄色立方体。体素分支的相关场在第二行和第三行。体素分支仅提供目标点的粗略位置(在中心子立方体处),而点分支可以通过计算局部区域内所有相邻点的相关分数从而实现目标点的准确定位。
备注:作者也是我们「3D视觉从入门到精通」特邀嘉宾:一个超干货的3D视觉学习社区
原创征稿
初衷
3D视觉工坊是基于优质原创文章的自媒体平台,创始人和合伙人致力于发布3D视觉领域最干货的文章,然而少数人的力量毕竟有限,知识盲区和领域漏洞依然存在。为了能够更好地展示领域知识,现向全体粉丝以及阅读者征稿,如果您的文章是3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、硬件选型、求职分享等方向,欢迎砸稿过来~文章内容可以为paper reading、资源总结、项目实战总结等形式,公众号将会对每一个投稿者提供相应的稿费,我们支持知识有价!
投稿方式
邮箱:[email protected] 或者加下方的小助理微信,另请注明原创投稿。

▲长按加微信联系

▲长按关注公众号