yolov1, yolo v2 和yolo v3系列分析
目标检测模型主要分为two-stage和one-stage, one-stage的代表主要是yolo系列和ssd。简单记录下学习yolo系列的笔记。
1 yolo V1
yolo v1是2015年的论文 you only look once:unified,real-time object detection 中提出,为one-stage目标检测的开山之作。其网络架构如下:(24个卷积层和两个全连接层,注意最后一个全连接层可以理解为14096到11470(7730)的线性变换)

yolo v1的理解主要在于三点:
1.1 网格划分: 输入图片为448448,yolo将其划为为49(77)个cell, 每个cell只负责预测一个物体框, 如果这个物体的中心点落在了这个cell中,这个cell就负责预测这个物体

1.2 预测结果:最后网络的输出为7730, 也可以看做49个1*30的向量,每个向量的组成如下: (x, y, w, h, confidence) *2 + 20; 即每一个向量预测两个bounding box及对应的置信度,还有物体属于20个分类(VOC数据集包括20分类)的概率。
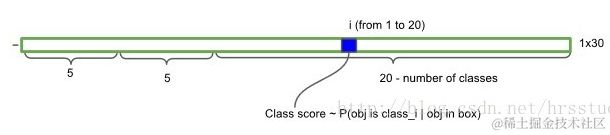
1.3 Loss 函数理解:loss函数如下图所示,下面几个概念需要理清楚
s2:最后网络的输出为7730, 因此49个cell;
B: 每个cell(1*30)预测了两个bbox,因此B=2,只有和ground truth具有最大IOU的bbox才参与计算
7*7的正掩膜obj:最开始进行网络划分时,ground truth的中心点落在了该cell中,则该cell出值为1;只有为1出的cell才参与计算
7*7的反掩膜noobj:正掩膜取反。

(1) 坐标预测损失(coordinate loss) : 上面损失函数的第一部分是对预测bbox的坐标损失,如下图所示,有两个注意点:一是对宽高取平方根,抑制大物体的loss值,平衡小物体和大物体预测的loss差异;二是采用了权重系数5,因为参与计算正样本太少(如上面7*7掩膜中只有三个cell的坐标参与计算),增加权重

(2)置信度损失(Confidence loss) :第二部分是正负样本bbox的置信度损失,如下图所示;注意下ground truth的置信度: 对于正样本其置信度为预测框和ground truth之间的IOU1, 对于负样本,置信度为IOU0;另外由于负样本多余正样本,取负样本的权重系数为0.5

(3)分类损失(Classification Loss) : 第三部分是预测所属分类的损失,如下图所示,预测值为网络中softmax计算出,真实值为标注类别的one-hot编码(可以理解为20分类任务,若为第五类,则编码为00001000000000000000)

yolo v1的主要特点
(1) 优点: one-stage,速度快
缺点:
(1) 不支持拥挤物体的检测(划分网格时一个cell只预测一个物体)
(2) 对小物体的检测效果差, 且对新的宽高比物体检测效果不好
(3)网络中没有使用batch normalization
下面是pytorch的实现的Yolo V1 network 和 loss计算方式:(未经实验,仅供理解用)
![]() Yolo_loss
Yolo_loss
![]() Yolo V1 network
Yolo V1 network
2. Yolo V2
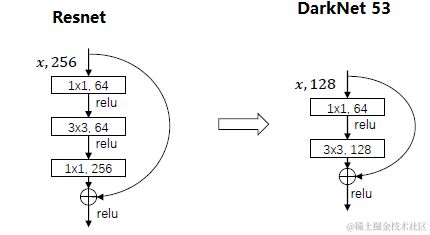
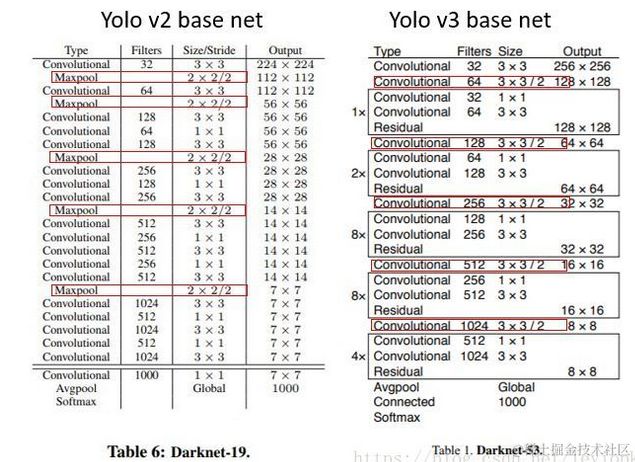
Yolo V2是在2016年的Yolo9000: Better, Faster, Stronger 中提出的, 采用了新的网络模型,称为Darknet-19, 包括19个卷积层和5个maxpooling层,相比Yolo V1的计算量减小了33%左右。其结构如下:
在ImageNet上预训练的结构:

进行检测任务训练时模型结构:(引入了不同尺度特征融合)

Yolo V2 主要对Yolo V1进行了五处改进:
(1) 加入Batch Normalization, 去掉dropout
(2) High resolution classifier (高分辨率图片分类器)
(3) 引入 Anchors
(4) Fine-grained Features (低层和高层特征融合)
(5) Multi-scale Training (不同尺度图片的训练)
2.1 High resolution classifier (4% mAP)
yolo v1中分类器在ImageNet数据集(224224)上预训练,而检测时图片的大小为448448,网络需要适应新的尺寸,因此yolo V2中又加入了一步finetune,步骤如下:
a, 在ImageNet上预训练分类器(224*224),大概160个epoch
b,将ImageNet的图片resize到448*448,再finetune 10个epoch, 让模型适应大图片
c, 采用上述预训练的权重,在实际数据集上finetune(416416),最终输出为1313
2.2 Anchors
借鉴Faster RCNN中Anchor的思想,通过kmeans方法在VOC数据集(COCO数据集)上对检测物体的宽高进行了聚类分析,得出了5个聚类中心,因此选取5个anchor的宽高: (聚类时衡量指标distance = 1-IOU(bbox, cluster))
COCO: (0.57273, 0.677385), (1.87446, 2.06253), (3.33843, 5.47434), (7.88282, 3.52778), (9.77052, 9.16828)
VOC: (1.3221, 1.73145), (3.19275, 4.00944), (5.05587, 8.09892), (9.47112, 4.84053), (11.2364, 10.0071)
这样每个grid cell将对应5个不同宽高的anchor, 如下图所示:(上面给出的宽高是相对于grid cell,对应的实际宽高还需要乘以32)

关于预测的bbox的计算:(416416-------1313 为例)
(1) 输入图片尺寸为416416, 最后输出结果为1313125,这里的125指5(5 + 20),5表示5个anchor,25表示[x, y, w, h, confidence ] + 20 class ),即每一个anchor预测一组值。
(2) 对于每一anchor预测的25个值, x, y是相对于该grid cell左上角的偏移值,需要通过sigmoid函数将其处理到0-1之间。如13*13大小的grid,对于index为(6, 6)的cell,预测的x, y通过sigmoid计算为xoffset, yoffset, 则对应的实际x = 6 + xoffset, y = 6+yoffset, 由于0 (3) 由于上述尺度是在13*13下的,需要还原为实际的图片对应大小,还需乘以缩放倍数32 实际计算代码如下: 2.3 Fine-Grained Features 由上面网络架构中,可以看到一条shortcut,将低层的的feature map(2626512)和最后输出的feature map(13131024)进行concat,从而将低层的位置信息特征和高层的语义特征进行融合。另外由于2626尺度较大,网络采用Reorg层对其进行了reshape,使其转变为1313,如下图所示: 2.4 Multi-scale Training 上述网络架构中,最后一层的(Conv22)为11125的卷积层代替全连接函数,可以处理任何大小的图片输入,因此在训练时,每10个epoch,作者从320×320, 352×352, … 608×608选一个尺度作为输入图片的尺寸进行训练,增加模型的鲁棒性。(当尺度为416416时,输出为1313125;输入为320320,则输出为1010125) Yolo V2的特点: (1)采用Darknet19网络结构,层数比Yolo V1更少,且没有全连接层,计算量更少;模型运行更快; (2) 使用卷积代替全链接:解除了输入大小的限制, 多尺度的训练使得模型对不同尺度的图片的检测更加鲁棒 (3) 每个cell采用5个anchor box进行预测,对拥挤和小物体检测更有效 3. Yolo 9000 Yolo 9000是和yolo v2在同一篇文章中提出,是在YOLOv2的基础上提出的一种可以检测超过9000个类别的模型,其主要贡献点在于提出了一种分类和检测的联合训练策略, 具体细节参考:https://zhuanlan.zhihu.com/p/35325884 4. Yolo V3 Yolo V3是在2018年的文章YOLO V3: An Incremental Improvement 中提出,Yolo V3网络结构为DarkNet53, 如下图所示:(有ResNet, FPN的思想)。Yolo V3每个网格单元预测3个anchor box,每个box需要有(x, y, w, h, confidence)五个基本参数,然后有80个类别(COCO数据集) 的概率,所以3*(5 + 80) = 255。(y1, y2,y3的深度都是255) 相比于Resnet,Darknet中的残差结构如下: 采用FPN的思想,将不同尺度的Feature map进行融合,并在每个尺度上进行预测,如下图所示: yolo_v3也和v2一样,backbone都会将输出特征图缩小到输入的1/32,通常都要求输入图片是32的倍数,Yolo v3中的DarkNet 53 和yolo v2 的DarkNet 19对比如下图所示: