迁移学习的简要介绍
迁移学习概述
迁移学习是什么?
来源
迁移学习的概念最初来自教育心理学。根据心理学家C.H.Judd提出的经验泛化理论:学习迁移是经验泛化的结果。只要⼀个⼈概括他的经验,可以实现从⼀种情境到另⼀种情境的转移。根据这⼀理论,迁移的前提是两个学习活动之间需要有联系。

定义
迁移学习的定义:给定源域 D s D_s Ds和学习任务 T s T_s Ts、目标域 D t D_t Dt和学习任务 T t T_t Tt,迁移学习的目的是获取源域 D s D_s Ds和学习任务 T s T_s Ts中的知识以帮助提升目标域中的预测函数 f t ( . ) f_t(.) ft(.)的学习,其中 D s ≠ D t D_s \neq D_t Ds=Dt或者 T s ≠ T t T_s \neq T_t Ts=Tt。
领域(Domain) 是学习的主体,主要由两部分构成:源领域和目标领域。
源领域(Source domain,源域):有知识、有大量数据标注的领域,是我们要迁移的对象。
目标领域(Target domain,目标域):待学习的领域,我们要赋予知识、赋予标注的对象。
任务(Task):学习的目标,由标签 和 标签对应的函数 组成。

领域不同( D s ≠ D t D_s \neq D_t Ds=Dt)或者任务不同( T s ≠ T t T_s \neq T_t Ts=Tt)

下图中为整个迁移学习过程。图中左侧是传统的机器学习过程,右侧为迁移学习过程。迁移学习不仅利用目标任务中的数据作为学习算法的输入,还利用源域中的所有学习过程(包括训练数据、模型和任务)作为输入。通过源域获得更多知识来解决目标域中缺少训练数据的问题。

迁移学习的核心思想(Transfer Learning,TL)
利用数据和领域之间存在的相似性关系,把之前学习到的知识,应用于新的未知领域。
迁移学习的核心思想是,
1. 寻找源领域和目标领域之间的相似性/不变量
2. 度量和利用相似性(度量相似程度, 增大相似性)。
负迁移(Negative Transfer)——失败的迁移
在源域上学习到的知识,对于目标域上的学习产生负面作用。(迁移学习取得了比不迁移还要差的结果)
产生负迁移的主要原因
数据问题:源域和目标域压根不相似。
经验问题:源域和目标域是相似的,但是,学习者跨领域寻找可迁移和有益的知识部分的能力不足。
传递迁移学习(Transitive transfer learning,TTL)——解决负迁移
使得迁移学习可以在两个领域存在弱相似性的情况下进行,进一步扩展了迁移学习的边界。

为什么要用迁移学习?

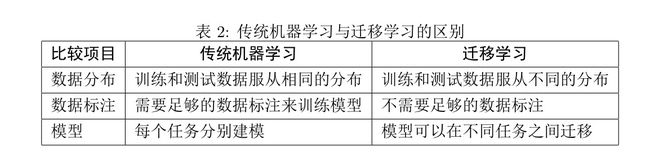
传统机器学习与迁移学习的区别
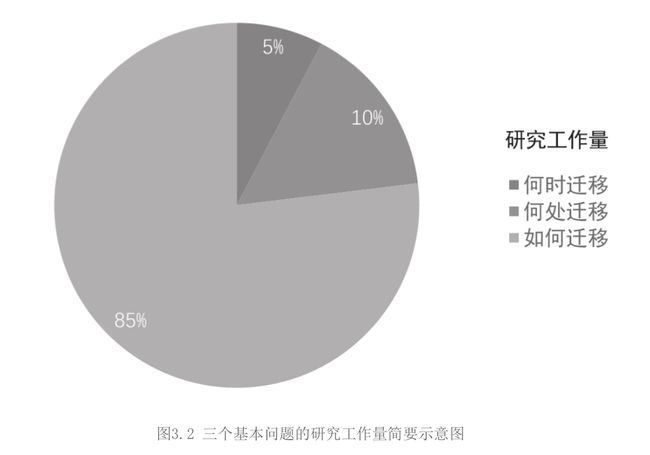
迁移学习三个基本问题
何时迁移?(能否迁移)—— when to transfer
此步骤应该发生在迁移学习的第一步. 给定待学习的目标,我们首先要做的便是判断当时的任务是否适合进行迁移学习。(该部分的主要工作均属于理论分析范畴,对应于一些理论、边界条件的证明,即学习得到的模型满足某个范式时,便可以进行迁移学习。从理论上决定了迁移学习的成功与否)
MMD度量(最大均值差异):求源领域和目标领域的数据在RKHS(再生核希尔伯特空间)中的均值距离。
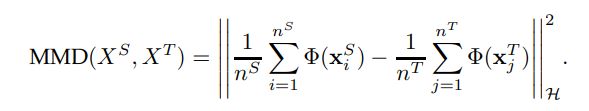
何处迁移?(要迁移的对象)—— what/where to transfer
what, 指的是要迁移什么知识,这些知识可以是神经网络权值,特征变化矩阵某些参数等;而where指的是要从哪个地方进行迁移,这些地方可以是某个源域,某个神经元等。
如何迁移?(迁移学习方法)—— how to transfer
这一步是绝大多数迁移学习方法的着力点。给定待学习的源域和目标域, 这一步则是要学习最优的迁移学习方法以达到最好的性能。
如何进行迁移?——迁移学习的基本方法
基于样本的迁移学习——数据层面
基于实例的迁移学习方法主要基于实例加权策略,也就是权重重用,源域和目标域的样例进行迁移。对样本赋予不同权重,相似的样本权重更高。
源领域中存在不同种类的动物,而目标领域只有猫这一种类别。在迁移时,为了最大限度地和目标领域相似,我们可以人为地提高源领域中猫这个类别的样本权重。

实例加权策略
P S ( X ) ≠ P T ( X ) P^S(X)\neq P^T(X) PS(X)=PT(X) and P S ( Y ∣ X ) = P T ( Y ∣ X ) P^S(Y|X) = P^T(Y|X) PS(Y∣X)=PT(Y∣X) ,两个领域只在边缘分布上不同,在这种情况下考虑调整边缘分布。⼀个简单的想法是为损失函数中的源领域实例分配权重。加权策略基于以下等式:

将比值用 β i \beta_i βi表示,学习任务的目标函数可以写为:

权重的值如何确定?——KMM
KMM核均值匹配,通过最小化领域之间的MMD距离来产生实例的权重。

基于特征的迁移学习(研究热点)——特征层面
基于特征的方法将原始特征转换为新的特征表示。基于特征,对特征进行变换,假设源域和目标域的特征原来不在一个空间,或者说它们在原来那个空间上不相似,那就想办法把它们变换到另一个空间里,使得该空间中源域数据与目标域数据具有相同的数据分布,于是这些特征的相似性便会大大增加。

特征变换策略
将每个原始特征转换为新的特征表示以进行知识迁移。构建新的特征表示的目标包括最小化边缘和条件分布差异,保留数据的属性或潜在结构,以及找到特征之间的对应关系。
基于映射的特征提取方法
主成分分析(PCA)
PCA是一种常见的降维算法,它可以通过线性变换将数据投影到主成分上,从而找到数据中的主要变化方向。通过保留最重要的主成分,可以实现特征的降维和提取共同特征。
迁移成分分析(TCA)
源域和目标域处于不同数据分布时[ P ( X S ) ≠ P ( X T ) P(X_S) \neq P(X_T) P(XS)=P(XT)],将两个领域的数据一起映射[ Φ \Phi Φ]到一个高维的再生核希尔伯特空间。在此空间中,最小化源和目标的数据距离【使得映射后数据的分布相似[ P ( Φ ( X S ) ) ≈ P ( Φ ( X T ) ) P(\Phi (X_S))\approx P(\Phi (X_T)) P(Φ(XS))≈P(Φ(XT))]】,同时最大程度地保留它们各自的内部属性【保留数据中最重要的共享特征,实现降维的效果】。
基于模型的迁移学习——参数层面
即构建参数共享的模型,模型参数迁移。
Pre-training and fine-tuning:预训练—微调
它指的是我们在源领域预训练好一个网络,直接将其用于目标域的数据,并在目标域数据上进行微调,以适应新任务。通常会调整模型的最后一层或几层。

微调
方法一:将已经训练好的模型参数权重直接拿过来作为初始化权重值。
方法二:固定住某些层的参数,只更新其他层的参数。
