【YOLO系列】 YOLOv4思想详解
前言
以下内容仅为个人在学习人工智能中所记录的笔记,先将目标识别算法yolo系列的整理出来分享给大家,供大家学习参考。
本文未对论文逐句逐段翻译,而是阅读全文后,总结出的YOLO V4论文的思路与实现路径。
若文中内容有误,希望大家批评指正。
资料下载
YOLO V4论文下载地址:YOLOv4: Optimal Speed and Accuracy of Object Detection
项目地址:YOLO V4
回顾:
YOLO V1:【YOLO系列】YOLO V1论文思想详解
YOLO V2:【YOLO系列】YOLO V2论文思想详解
YOLO V3:【YOLO系列】 YOLOv3论文思想详解
大家可以发现YOLO V4论文的作者变成Alexey Bochkovskiy了,YOLO V1-3的作者都是Joseph Redmon, Ali Farhadi,不过不影响,YOLO V4作者提出了一大堆措施来提高YOLO的性能,我们这就来看看。
一、YOLO V4思想
1、在训练阶段,YOLO V4使用Mosaic数据增强来提升模型的训练速度和网络精度。它利用CmBN和SAT自对抗训练来提升网络的泛化性能。
2、在Backbone网络中,YOLO V4使用了CSPDarkNet53作为基准网络,并利用Mish激活函数代替原始RELU激活函数,同时增加Dropblock模块来进一步提升模型的泛化能力。
3、在Neck网络中,YOLO V4利用SPP模块融合不同尺度大小的特征图。同时,利用自底向上的PAN特征金字塔提升网络的特征提取能力。
4、作者将YOLO V4分成了Two-Stage 检测器,即在Head部分使用了两级Prediction方法,一级目标检测器为Dense Prediction,用于生成密集的bbox,二级目标检测器为Sparse Prediction,用于对一级检测器生成的bbox进行精细调整;还利用CIOU_Loss来代替Smooth L1 Loss函数,并利用DIOU_nms来代替传统的NMS操作,从而进一步提升算法的检测精度。

二、YOLO V4详解
1、Bag of freebies(BOF)
(1)BOF介绍
作者将只改变训练策略或只增加训练成本的方法称为“bag of freebies”,而在目标检测方法中经常采用的bag of freebies包括数据增强、标签分布、损失函数。
1)Data augmentation
数据增强的目的是增加输入图像的可变性,使所设计的目标检测模型对来自不同环境的图像具有更高的鲁棒性。常用的方法包括光度失真和几何失真处理两方面,处理光度失真时,可以调整图像的亮度、对比度、色调、饱和度和噪点。处理几何失真,可以采用随机缩放、裁剪、翻转和旋转等方法(以上一些方法在YOLO V3中已经使用了)。
作者也介绍了其他数据增强的方法,包括:random erase、CutOut、hide-and-seek、grid mask、DropOut、DropConnect、DropBlock、Mixup、CutMix、GAN
2)Data balance(label distribution)
对于不同类别之间存在数据不平衡的问题的解决方法,作者认为也属于bag of freebies。
对于这类问题,作者介绍了hard negative example mining、online hard example mining、focal loss等解决办法。
3)Objective function of bbox regression
关于这个问题,作者介绍了GIOU loss、DIOU loss、CIOU loss等方法。
2、Bag of specials(BOS)
(1)BOS介绍
作者将只增加少量推理成本,却能显著提高目标检测精度的plugin 模块和post-processing方法称为“bag of specials”。plugin模块是为了增强模型中的某些属性,比如扩大感受野(enlarging receptive field)、引入注意机制(attention mechanism)或者增强特征集成能力(feature integration capability)等,post-processing主要用于对模型预测结果进行筛选。
1)Enhance receptive field
SPP、ASPP、RFB
2)Attention mechanism
Squeeze-and-Excitation(SE)、Spatial attention module(SAM)
3)Feature integration
SFAM、ASFF、BiFPN
4)Activation function
ReLU、LReLU、PReLU、ReLU、SELU、Swish、hard-Swish、Mish
5)Post-processing
DIOU-NMS
3、YOLO V4 方法论
(1)基本目标
基于神经网络在生产系统中的快速运行和并行计算的优化,而不是以低计算量为理论指标(BFLOP)。
于是,作者提出了两种Real-time的神经网络:
For GPU:在卷积层中使用少量的(1-8)的CSPResNeXt50/CSPDarknet53
For VPU:使用分组卷积,但是避免使用SE模块,包括EfficientNet-lite / MixNet / GhostNet / MobileNetV3
(2)模型的选择
这里的模型(architecture)可以理解为作者在为搭建YOLO V4时所选择的backbone、neck、head。
目标一:在输入网络分辨率、卷积层数、参数数量(filter_size²* filters * channel/groups)和输出层数之间找到最佳平衡;
目标二:选择额外的blocks来增加感受野,并从不同的backbone为不同的检测级别选择参数聚合的最佳方法。
由于一个最佳的分类器不一定是一个最佳的detector,因此在文中作者提出了对detector的要求如下:
1)更高的输入网络尺寸(分辨率)-用于检测多个小尺寸的对象
2)更多的层-用于更高的接受域以覆盖增加的输入网络尺寸
3)更多的参数-用于更大的模型能力,以检测单个图像中不用尺寸的多个对象
而不同大小感受野的影响主要如下:
1)直到目标大小——允许看到整个对象
2)直到网络大小——允许查看对象周围的环境
3)超过网络大小——增加图像点和最终激活函数之间的连接数量
基于以上内容,最后作者通过实验选择了CSPDarknet53(Backbone)+SPP block+PANet作为在backbone与detector的参数聚合方法(Neck)+YOLO V3的head搭建了YOLO V4模型(Head)。
(3)额外的提升
为了使所设计的detector更适合在单GPU上进行训练,作者进行了额外的设计和改进,具体如下:
数据增强:Mosaic、Self-Adversarial Training(SAT)
应用遗传算法选择最优的超参数
修改过的SAM、PAN和Cross mini-Batch Normalization(CmBN)
(4)YOLO V4
1)Backbone、Neck、Head
Backbone: CSPDarknet53
Neck: SPP、PAN
Head: YOLO V3
2)YOLO V4中的BOF
a. BOF for backbone
CutMix and Mosaic data augmentation,DropBlock regularization, Class label smoothing
b. BOF for detector
CIOU-loss, CmBN, DropBlock regularization, Mosaic data augmentation, Self-Adversarial Training(SAT), Eliminate grid sensitivity, Using multiple anchors for a single ground truth, Cosine annealing scheduler, Optimal hyperparameters, Random training shapes
3)YOLO V4中的BOS
a. BOS for backbone
Mish activation, Cross-stage partial connections (CSP), Multiinput weighted residual connections (MiWRC)
b. BOS for detector
Mish activation, SPP-block, SAM-block, PAN path-aggregation block, DIOU-NMS
三、YOLO V4中策略详解
1、Backbone
CSPDarknet53是借鉴了CSPNet(Cross stage partial networks,跨阶段局部网络)的思想,再加上YOLO V3中的Darknet53网络进行改进而形成的全新的主干网络结构。
(1)CSPNet
CSPNet的提出主要是为了解决以下三个问题:
1、加强CNN的学习能力
2、消除计算瓶颈
3、减少内存成本
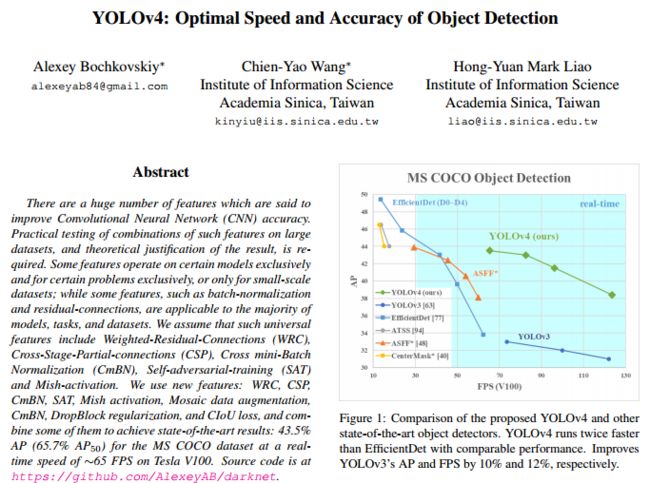
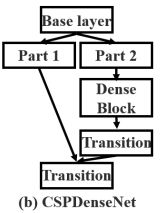
CSPNet的思想就是将基础层的特征图分成两部分,一部分经过密集块和过渡层,然后将另一部分与传输的特征映射结合到下一阶段。它可以与ResNet、ResNeXt、DenseNet等网络结合形成新的网络。下图为CSPNet与DenseNet结合后的网络结构图。
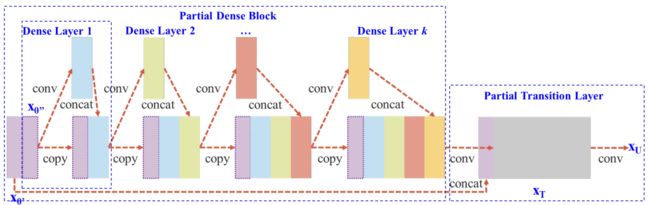
关于CSPNet的其他内容,大家可以下载论文CSPNet: A New Backbone that can Enhance Learning Capability of CNN 自行阅读,也是YOLO V4的作者写的(自产自销啦~)。
(2)CSPDarknet53
在这里给大家推荐一个网络可视化软件:Netron,大家可以自行下载安装后,导入模型配置文件就可以。
网页版:Netron
桌面版:Netron
CSPDarknet53主要有5个DownSample结构组成,每个DownSample结构包含ConvBNMish和ResBlock,最后3个DownSample结构负责输出特征图进行下一阶段的处理。
在CSPDarknet的卷积网络中所使用的激活函数为Mish函数(什么是Mish函数,请看【YOLO系列】 YOLOv4之Mish函数)
下图为 CSPDarknet53网络

2、Neck
(1)SPP
SPP(Spatial Pyramid Pooling,空间金字塔池化)是何凯明大神提出用于解决R-CNN中速度慢问题的方法。主要思想是将同一个特征图进行不同的池化,然后将池化后的特征图拼接在一起,这样解决不同尺寸的特征图如何连接全连接层。

在YOLO V4中,通过DownSample3后的特征图经过3个卷积后,分别使用了池化核为13 * 13 , 9 * 9, 5 * 5的最大池化,padding模式为‘same', 然后将原来的特征图与池化后的三个特征图拼接在一起。
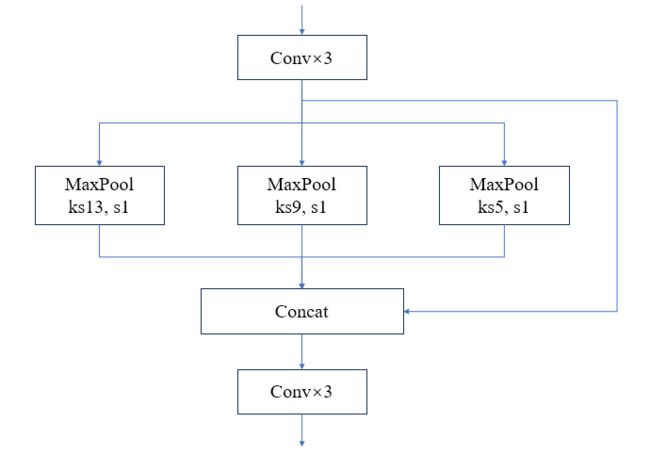
(2)PAN
PAN(Path Aggregation Network)结构其实就是在FPN(Feature Pyramid Networks,特征金字塔网络)的基础上进行改进得到的。
原来多数的object detection算法都是只采用顶层特征做预测,但是我们知道低层的特征语义比较少,但是目标位置准确;高层的特征语义信息比较丰富,但目标位置比较粗略。
另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而不一样的地方在与预测试在不同特征层独立进行的。

PAN主要分为3个模块也是3点贡献:
1)改进的FPN: Bottom-up Path Augmentation
2)改进之前的pool策略: Adaptive Feature Pooling
3)改进mask分支: Full-connected Fusion
1)Bottom-up Path Augmentation
FPN已经证明了加入一条top-down的旁路连接,能给feature增加high-level的语义有利于分类。
但是low-levle中的feature是很有利于定位的,虽然FPN中P5也间接得有了low-level的特征,但是信息流动路线太长了如上图红色虚线所示(其中有很多卷积层)。在PAN思想中,FPN的P2-P5又加了low-level的特征,最底层的特征流动到N2-N5只需要经过很少的层。
具体如下图所示,在PAN原文中采用的addition,在YOLO V4中修改为concatenation。P2直接copy在N2,然后N2通过步长为2的3 * 3卷积后分辨率缩小2倍,和P3尺寸一致,然后concatenation。
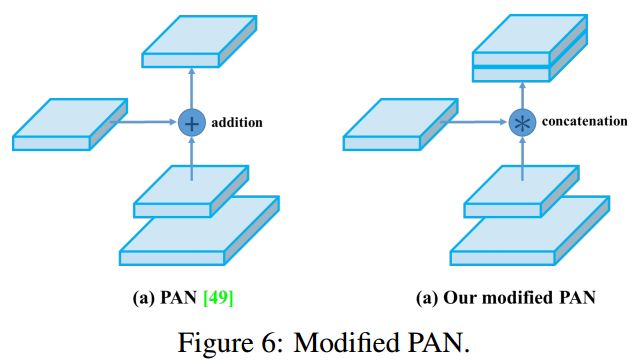
这样构建的优势在于缩短了底层尺寸的特征到高层尺寸小的特征之间的距离,让特征融合更加有效。
2)Adaptive Feature Pooling
在FPN的论文中可以知道FPN从P2-P6(P6仅用作生成proposal,不用作ROIPooling时提取特征)多尺度地生成proposal,然后做ROIPooling时会根据proposal的大小将它分配到不同的level去crop特征,小的proposal去low-level的层,大的proposal去high-level的层。
这样做虽然简单也有效,但是不是最好的处理方式,尽管P2-P5(N2-N5)已经融合了low-level和high-level的特征,然后他们的主要特征还是以 它本有的level为主, 这时如果小的proposal能从high-level层获取到更多的上下文语义信息是有利于分类的,而大的proposal能从low-level层获取到更好的细节是有利于它定位的。
PAN认为高低层特征各有其优势,高层特征的视野域更大,小的ROI可以在这些特征上获取更丰富的上下文信息。底层特征可以帮助大的proposal更好得定位。这里提出的池化方法则是在所有尺度的特征上操作,之后进行融合。

3)Full-connected Fusion
全连接FC是全图视野域对位置更敏感,看得更大,因此PAN多加一条用全连接层预测的支路来做mask预测,然后和FCN融合,具体如下:
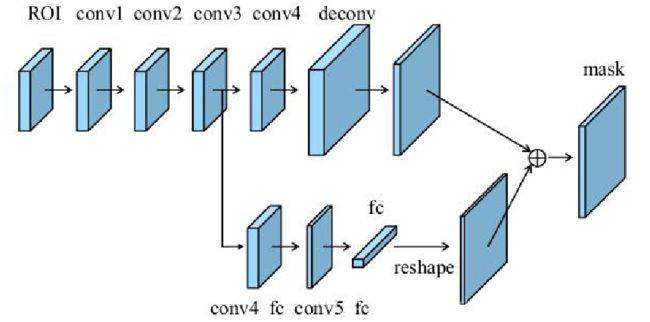
四、YOLO V4网络模型

五、YOLO系列对比
| Type |
YOLO V1 |
YOLO V2 |
YOLO V3 |
YOLO V4 |
| 网络结构 Backbone |
借鉴了GoogleNet的思想,24个卷积层+2层全连接层 |
Darknet-19 |
Darknet-53 |
CSPDarknet53 |
| 损失函数 |
均方差损失(sum-squared error loss) |
Softmax loss |
Logistic loss |
CIOU |
| Anchor Box |
无Anchor Box |
提出聚类的方法生成Anchor Box,但未使用,还是采用了预设的方式确定先验框的尺寸 |
聚类生成Anchor Box |
聚类生成Anchor Box |
| 特征提取 Neck |
-- |
Passthrough layer |
采用了类似FPN的结构,进行多尺度特征提取 |
SPP、PAN |
| FPS |
45 FPS |
-- |
在Titan X GPU上的速度是45 fps,加速版的YOLO差不多是150fps。 |
65 FPS on Tesla V100 |
| mAP |
63.4 |
在VOC2007数据集上,以67FPS的速度可达到76.8mAP; 以40FPS的速度可达到78.6mAP。 |
55左右 |
AP为43.5% (AP50为65.7%) |
下篇YOLO V5再见!