元数据管理平台对比预研 Atlas VS Datahub VS Openmetadata
大家好,我是独孤风。元数据管理平台层出不穷,但目前主流的还是Atlas、Datahub、Openmetadata三家,那么我们该如何选择呢?
本文就带大家对比一下,这三个平台优势劣势。要了解元数据管理平台,先要从架构说起。
正文共: 4394字 13图
预计阅读时间: 11分钟
元数据管理的架构与开源方案
下面介绍元数据管理的架构实现,不同的架构都对应了不同的开源实现。
下图描述了第一代元数据架构。它通常是一个经典的单体前端(可能是一个 Flask 应用程序),连接到主要存储进行查询(通常是 MySQL/Postgres),一个用于提供搜索查询的搜索索引(通常是 Elasticsearch),并且对于这种架构的第 1.5 代,也许一旦达到关系数据库的“递归查询”限制,就使用了处理谱系(通常是 Neo4j)图形查询的图形索引。
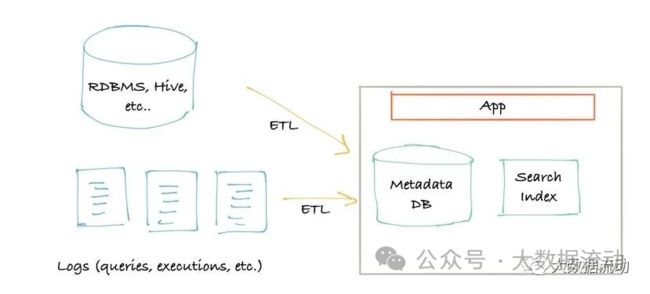
很快,第二代的架构出现了。单体应用程序已拆分为位于元数据存储数据库前面的服务。该服务提供了一个 API,允许使用推送机制将元数据写入系统。

第三代架构是基于事件的元数据管理架构,客户可以根据他们的需要以不同的方式与元数据数据库交互。
元数据的低延迟查找、对元数据属性进行全文和排名搜索的能力、对元数据关系的图形查询以及全扫描和分析能力。

Datahub 就是采用的这种架构。
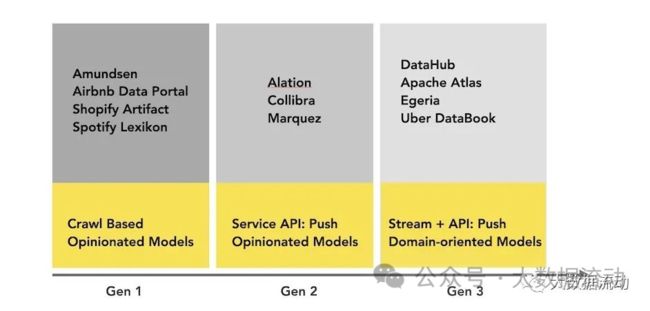
下图是当今元数据格局的简单直观表示:
(包含部分非开源方案)
Apache Atlas
Atlas是Hadoop的数据治理和元数据框架。Atlas于2015年7月开始在Hortonworks进行孵化。
官网地址为:https://atlas.apache.org/
源码地址为:https://github.com/apache/atlas
目前标星1.7K,最新稳定版本2.3.0。
开发语言后端主要为Java,前端功能主要为JS实现。

特性
Atlas支持各种Hadoop和非Hadoop元数据类型
提供了丰富的REST API进行集成
对数据血缘的追溯达到了字段级别,这种技术还没有其实类似框架可以实现
对权限也有很好的控制
Atlas包括以下组件:
采用Hbase存储元数据
采用Solr实现索引
Ingest/Export 采集导出组件 Type System类型系统 Graph Engine图形引擎 共同构成Atlas的核心机制
所有功能通过API向用户提供,也可以通过Kafka消息系统进行集成
Atlas支持各种源获取元数据:Hive,Sqoop,Storm。。。
还有优秀的UI支持
Atlas是Hadoop生态的嫡系,并且天然的集成在Ambari中(不过版本较低,建议自己安装)。

Atlas对Hive的支持极好,对Spark也有一定的支持。
如果熟悉Atlas的API,也可以很好的扩展。
但由于社群活跃度一般,Atlas后期更新乏力。
页面也还是老样子,新版本的页面并不完善,所以还有有很大的局限性。
DataHub (LinkedIn)
LinkedIn开源出来的,原来叫做WhereHows 。经过一段时间的发展datahub于2020年2月在Github开源。
官网地址为:https://datahubproject.io/
源码地址为:https://github.com/linkedin/datahub
目前标星8.8K,最新稳定版本0.12.0。
开发语言为Java和Python。

DataHub是由LinkedIn的数据团队开源的一款提供元数据搜索与发现的工具。
提到LinkedIn,不得不想到大名鼎鼎的Kafka,Kafka就是LinkedIn开源的。LinkedIn开源的Kafka直接影响了整个实时计算领域的发展,而LinkedIn的数据团队也一直在探索数据治理的问题,不断努力扩展其基础架构,以满足不断增长的大数据生态系统的需求。随着数据的数量和丰富性的增长,数据科学家和工程师要发现可用的数据资产,了解其出处并根据见解采取适当的行动变得越来越具有挑战性。为了帮助增长的同时继续扩大生产力和数据创新,创建了通用的元数据搜索和发现工具DataHub。
由于背后有商业化的规划,并且社区活跃,近两年Datahub的更新异常活跃。也将自己的定位为基于现代数据栈的元数据平台。DataHub实现了端到端的数据发现,数据可观察性和数据治理。并且为开发人员提供了丰富的扩展接口,其目的就是应对不断变化的数据生态。事实证明,元数据管理就应该这样去建设。DataHub提供了跨数据库、数据仓库、数据湖、数据可视化工具的搜索与发现功能。实现端到端的全流程数据血缘的构建。DataHub是实时的元数据捕捉框架,可以实时感应元数据的变化。同时支持标签,术语表,业务域等元数据的管理。DataHub还提供了丰富的权限支持。在最新的DataHub版本中,可以在页面上去进行元数据的获取操作。DataHub支持的数据源非常丰富,如Tableai、PowerBI、Superset等数据可视化工具。也支持Airflow、Spark、ES、Kafka、Hive、Mysql、Oracle等大数据组件的元数据的获取。

Datahub的页面经过最新的改版,规划也较为合理,美观。
Openmatadata
OpenMetadata是一个用于数据治理的一体化平台,可以帮助我们发现,协作,并正确的获取数据。
OpenMetadata提供了数据发现、数据血缘、数据质量、数据探查、数据治理和团队协作的一体化平台。它是发展最快的开源项目之一,拥有充满活力的社区,并被各行业垂直领域的众多公司采用。OpenMetadata 由基于开放元数据标准和API 的集中式元数据存储提供支持,支持各种数据服务的连接器,可实现端到端元数据管理,让您可以自由地释放数据资产的价值。
官网地址:https://open-metadata.org/
源码地址:https://github.com/open-metadata/OpenMetadata
目前标星3.4K,最新版本为1.2.3。
主要开发语言,后端为Java,前端为TS。

其UI非常美观,其操作和使用逻辑,也符合业务人员的习惯。

优缺点对比
Datahub:
优势:
强大的数据发现和搜索功能,方便用户快速定位所需数据。
提供数据质量元数据,帮助用户理解和信任数据。
支持多种数据源,包括传统的关系数据库和现代的数据湖。
社区活跃,不断有新功能和改进加入。
劣势: 初学者可能会觉得界面和配置相对复杂。
在某些情况下,集成新的数据源可能需要额外的开发工作。
Atlas:
优势:
与Apache Hadoop生态系统深度集成,特别适合Hadoop用户。
提供强大的数据血缘和分类功能,有助于数据治理。
支持自定义的元数据类型和模型。
开源,有较大的社区支持和贡献。
劣势:
主要针对Hadoop生态系统,可能不适合非Hadoop环境。
用户界面和用户体验不如一些商业产品。
OpenMetadata:
优势:
设计现代且用户友好,易于使用。
强调社交元数据管理,如用户评分、评论和讨论。
提供丰富的API,便于与其他系统集成。
持续更新和改进,反映了最新的数据管理趋势。
劣势:
相比Datahub和Atlas,社区相对较小,可能在某些特定功能上支持有限。
作为较新的平台,可能还在某些方面需要时间来成熟。
如何选择?
毫无疑问,从活跃度和发展趋势来看,Datahub都是目前最炙手可热的元数据管理平台。Openmatadata更有数据治理、数据资产管理平台的样子。而Atlas和Hadoop联系紧密,也有自己优势。
那么我们该如何选择呢?首先应该明确需求。
相信读到这篇文章的人,大部分还是想做一个元数据管理平台,以开展企业的数据治理工作。如果学习过DAMA的数据治理体系,我们应该知道做元数据管理要梳理好数据源都在哪,并尽可能的管理公司的全量数据。
而功能方面,是否需要数据血缘功能,术语表、标签等功能都是需要调研的内容。那我们一步步来分析。
1、梳理数据源
数据仓库与BI是大部分企业必备的,也是重要的元数据来源。不同企业的的搭建方式不同,前几年可能更多的是离线数仓,多采用Hive,Spark等大数据技术搭建。近几年数据湖技术,实时数仓技术出现,更多的企业会选择如Hudi,Iceberg等技术,而实时数仓多采用Doris,Paimon等技术,在实时处理中,还要考虑收集Flink实时计算引擎的元数据。
而部分企业也希望将业务系统,如Oracle,Mysql等数据库的元数据进行收集。
除此以外,还有一些业务元数据也是需要梳理的,一般通过接口、页面都可以操作。
原生支持所有组件的元数据管理平台是不存在的。但是好在元数据管理平台都提供了丰富的API接口,是可以扩展的。
所以在对数据源梳理后,并结合上面元数据管理平台的特性,可以做出基本的选择。
如果企业需要管理的数据源主要是大数据组件,Hive和Spark为主,可以使用Atlas快速的搭建一个元数据管理平台,由于原生的支持,基本不需要做很多的适配,只要安装配置好就可以。
但是如果企业收集元数据不限于此,建议选择更灵活的Datahub和Openmetadata,反正都要做适配,做二次开发,不如直接选一个更灵活的。
2、明确需求
我们先来看看三个平台的功能。
Altas有搜索,数据血缘,标签,术语表等功能。
Datahub有搜索,数据血缘,数据分析,标签,术语表等功能,也可以集成数据质量框架,如GreatExceptions。
Openmetadata有搜索,数据血缘,数据质量,数据分析,标签,术语表功能,并且有团队协作的功能。
如果这些能满足公司的需要就是可以选择的,如果不能,那么多余的功能就需要另外的开发了。
二开这里简单说一下,如果是元数据管理平台+数据治理工具的组合,建议选择Datahub基本可以覆盖所有的元数据管理功能,也有很好的扩展性。
而如果想选择一个平台大而全,可以考虑在Openmetadata基础上二开,毕竟支持的功能多一些。
3、可行性
虽然完事具备,但是能不能实行,其实并不一定。实现元数据管理的难度巨大。
在项目开始之前,必须要考虑实现的难度,如果不需要二开,可能只需要有经验的技术人员或者运维人员安装好就可以。
但是如果需要二开,则必须考虑开发难度。
Atlas后端主要为Java,需要高级的Java开发人员进行钻研,如需要更改页面,也需要前端人员的配合。
Datahub后端Java和Python都有的,而核心的数据摄取部分,主要是Python为主,熟悉Python框架的同学会更好上手。如需要更改页面,也需要前端人员的配合。
Openmetadata后端为Java,前端为TS。同样都是要有相关经验的人员参与的。
元数据管理并不容易,我在搭建二开环境的过程中也是遇到了很大的困难,但是熟悉开源项目的源码对于自研项目也有着非常大的帮助,没有白走的路,越是困难收获也会更大。
欢迎加入大数据流动,共同学习元数据管理相关知识,未完待续~