了解一下InternLM1
-
InternLM 是在过万亿 token 数据上训练的多语千亿参数基座模型。通过多阶段的渐进式训练,InternLM 基座模型具有较高的知识水平,在中英文阅读理解、推理任务等需要较强思维能力的场景下性能优秀,在多种面向人类设计的综合性考试中表现突出。在此基础上,通过高质量的人类标注对话数据结合 RLHF 等技术,使得 InternLM 可以在与人类对话时响应复杂指令,并且表现出符合人类道德与价值观的回复。书生·浦语 (intern-ai.org.cn)
-
多阶段的渐进式训练:大模型的渐进式训练可以通过多个阶段进行,每个阶段的目标是逐步提高模型的性能。每个阶段的训练过程中,可以使用不同的评估指标来监测模型的性能,并根据评估结果进行调整和优化。通过多阶段的渐进式训练,大模型可以从基础的语言表示逐渐进化为特定领域的精细语言表示,从而更好地满足实际应用的需求。
-
预训练阶段:首先,使用大规模无标签数据进行预训练,以学习到一些基础的语言表示能力。这一阶段的目标是让模型了解语言的语法、语义和上下文信息。
-
微调阶段:在预训练阶段之后,使用有标签的细粒度数据进行微调。这一阶段的目标是让模型学习到更精细的语言表示,以便更好地理解和生成特定领域的文本。
-
调优阶段:在微调阶段之后,可以通过更多的训练和调优来进一步提高模型的性能。这一阶段可以包括更多的数据、更复杂的训练方法和更长的训练时间。
-
集成学习阶段:为了提高模型的泛化能力,可以使用集成学习的方法,如bagging、boosting等,将多个模型组合起来形成一个更强大的模型。这一阶段的目标是利用不同模型的优点,提高整体的性能。
-
持续学习阶段:随着时间的推移,语言和知识会不断演变。为了使模型能够适应这些变化,需要不断地更新和改进模型。这一阶段的目标是利用新的数据和算法来持续改进模型的性能。
-
-
RLHF技术:RLHF(Reinforcement Learning from Human Feedback)是一种先进的AI系统训练方法,它将强化学习与人类反馈相结合。简单来说,它是一种通过将人类训练师的智慧和经验纳入模型训练过程中,创建更健壮的学习过程的方法。强化学习是一个过程,其中AI代理通过与环境的交互和以奖励或惩罚的形式获得的反馈来学习做出决策。代理的目标是随时间最大化累积奖励。在RLHF中,人类生成的反馈被用作奖励信号,然后通过强化学习来改善模型的行为。RLHF技术可以用于各种领域,如对话系统、推荐系统、游戏等。它可以帮助AI系统更好地理解人类意图和需求,提高模型的性能和健壮性。同时,由于RLHF技术需要大量的人类反馈数据,因此也需要建立一个有效的数据收集和标注机制来支持该技术的实现和应用。
-
初始模型训练:AI模型使用监督学习进行训练,人类训练者提供正确行为的标记示例。模型学习根据给定的输入预测正确的动作或输出。
-
收集人类反馈:在初始模型被训练之后,人类训练者提供对模型表现的反馈。他们根据质量或正确性排名不同的模型生成的输出或行为。这些反馈被用来创建强化学习的奖励信号。
-
强化学习:使用Proximal Policy Optimization(PPO)或类似的算法对模型进行微调,这些算法将人类生成的奖励信号纳入其中。模型通过从人类训练者提供的反馈学习,不断提高其性能。
-
迭代过程:收集人类反馈并通过强化学习改进模型的过程是重复进行的,这导致模型的性能不断提高。
-
-
-
InternLM有 1040亿参数,是在包含1.6万亿token的多语种高质量数据集上训练而成。同时,InternLM-7B完全可商用,支持8k语境窗口长度,中文超ChatGPT,训练和评估动态反馈调整,基于LMdeploy部署(基于Fast Transform研发)快速加载大模型,比Transform快到2~3倍,Hybrid Zero提速 ,开放OpenCompass 评测标准。
-
InternLM 启动一个 Demo 模型训练,需要进行三项准备,安装,数据集准备和模型训练配置。InternLM训练任务的数据集包括一系列的
bin和meta文件。使用tokenizer从原始文本文件生成训练用数据集。通过在tools/tokenizer.py中指定模型参数路径的方式来导入tokenizer模型。目前提供V7_sft.model来生成tokens。若想使用不同的模型,可直接修改tokernizer.py中的模型参数路径。可以运行以下命令生成原始数据对应的bin和meta文件,其中参数text_input_path表示原始文本数据路径,目前支持txt、json和jsonl三种输入格式,bin_output_path表示生成的bin文件的保存路径。LLMs之InternLM:InternLM-7B模型的简介、安装、使用方法之详细攻略-CSDN博客-
python tools/tokenizer.py --text_input_path your_input_text_path --bin_output_path your_output_bin_path -
需要注意的是,生成的
bin文件需要保存在cn或者en或者code或者ja或者ar或者kaoshi这六个目录下,以区分数据集的类型。其中,cn表示中文数据集;en表示英文数据集;code表示代码数据集;ja表示日语数据集;ar表示阿拉伯语数据集;kaoshi表示考试数据集。如: -
python tools/tokenizer.py --text_input_path raw_data.txt --bin_output_path cn/output.bin -
在
meta文件中,每个元组对应着bin文件中每一个sequence的元信息。其中,元组的第一个元素表示每个sequence在所有sequence中的starting index,第二个元素表示每个sequence中有多少个tokens。
-
-
微调任务的数据集格式与预训练任务保持一致,生成的数据格式为一系列的
bin和meta文件。以下以 Alpaca 数据集为例,介绍微调的数据准备流程。-
python tools/alpaca_tokenizer.py /path/to/alpaca_dataset /path/to/output_dataset /path/to/tokenizer --split_ratio 0.1 -
以 7B Demo 的配置文件
configs/7B_sft.py为例:-
JOB_NAME = "7b_train" DO_ALERT = False SEQ_LEN = 2048 HIDDEN_SIZE = 4096 NUM_ATTENTION_HEAD = 32 MLP_RATIO = 8 / 3 NUM_LAYER = 32 VOCAB_SIZE = 103168 MODEL_ONLY_FOLDER = "local:llm_ckpts/xxxx" # Ckpt folder format: # fs: 'local:/mnt/nfs/XXX' SAVE_CKPT_FOLDER = "local:llm_ckpts" LOAD_CKPT_FOLDER = "local:llm_ckpts/49" # boto3 Ckpt folder format: # import os # BOTO3_IP = os.environ["BOTO3_IP"] # boto3 bucket endpoint # SAVE_CKPT_FOLDER = f"boto3:s3://model_weights.{BOTO3_IP}/internlm" # LOAD_CKPT_FOLDER = f"boto3:s3://model_weights.{BOTO3_IP}/internlm/snapshot/1/" CHECKPOINT_EVERY = 50 ckpt = dict( enable_save_ckpt=False, # enable ckpt save. save_ckpt_folder=SAVE_CKPT_FOLDER, # Path to save training ckpt. # load_ckpt_folder= dict(path=MODEL_ONLY_FOLDER, content=["model"], ckpt_type="normal"), load_ckpt_folder="local:llm_ckpts/", # 'load_ckpt_info' setting guide: # 1. the 'path' indicate ckpt path, # 2. the 'content‘ means what states will be loaded, support: "model", "sampler", "optimizer", "scheduler", "all" # 3. the ’ckpt_type‘ means the type of checkpoint to be loaded, now only 'normal' type is supported. load_ckpt_info=dict(path=MODEL_ONLY_FOLDER, content=("model",), ckpt_type="internlm"), checkpoint_every=CHECKPOINT_EVERY, async_upload=True, # async ckpt upload. (only work for boto3 ckpt) async_upload_tmp_folder="/dev/shm/internlm_tmp_ckpt/", # path for temporarily files during asynchronous upload. oss_snapshot_freq=int(CHECKPOINT_EVERY / 2), # snapshot ckpt save frequency. ) TRAIN_FOLDER = "/path/to/dataset" VALID_FOLDER = "/path/to/dataset" data = dict( seq_len=SEQ_LEN, # micro_num means the number of micro_batch contained in one gradient update micro_num=4, # packed_length = micro_bsz * SEQ_LEN micro_bsz=2, # defaults to the value of micro_num valid_micro_num=4, # defaults to 0, means disable evaluate valid_every=50, pack_sample_into_one=False, total_steps=50000, skip_batches="", rampup_batch_size="", # Datasets with less than 50 rows will be discarded min_length=50, # train_folder=TRAIN_FOLDER, # valid_folder=VALID_FOLDER, empty_cache_and_diag_interval=10, diag_outlier_ratio=1.1, ) grad_scaler = dict( fp16=dict( # the initial loss scale, defaults to 2**16 initial_scale=2**16, # the minimum loss scale, defaults to None min_scale=1, # the number of steps to increase loss scale when no overflow occurs growth_interval=1000, ), # the multiplication factor for increasing loss scale, defaults to 2 growth_factor=2, # the multiplication factor for decreasing loss scale, defaults to 0.5 backoff_factor=0.5, # the maximum loss scale, defaults to None max_scale=2**24, # the number of overflows before decreasing loss scale, defaults to 2 hysteresis=2, ) hybrid_zero_optimizer = dict( # Enable low_level_optimzer overlap_communication overlap_sync_grad=True, overlap_sync_param=True, # bucket size for nccl communication params reduce_bucket_size=512 * 1024 * 1024, # grad clipping clip_grad_norm=1.0, ) loss = dict( label_smoothing=0, ) adam = dict( lr=1e-4, adam_beta1=0.9, adam_beta2=0.95, adam_beta2_c=0, adam_eps=1e-8, weight_decay=0.01, ) lr_scheduler = dict( total_steps=data["total_steps"], init_steps=0, # optimizer_warmup_step warmup_ratio=0.01, eta_min=1e-5, last_epoch=-1, ) beta2_scheduler = dict( init_beta2=adam["adam_beta2"], c=adam["adam_beta2_c"], cur_iter=-1, ) model = dict( checkpoint=False, # The proportion of layers for activation aheckpointing, the optional value are True/False/[0-1] num_attention_heads=NUM_ATTENTION_HEAD, embed_split_hidden=True, vocab_size=VOCAB_SIZE, embed_grad_scale=1, parallel_output=True, hidden_size=HIDDEN_SIZE, num_layers=NUM_LAYER, mlp_ratio=MLP_RATIO, apply_post_layer_norm=False, dtype="torch.float16", # Support: "torch.float16", "torch.half", "torch.bfloat16", "torch.float32", "torch.tf32" norm_type="rmsnorm", layer_norm_epsilon=1e-5, use_flash_attn=True, num_chunks=1, # if num_chunks > 1, interleaved pipeline scheduler is used. ) """ zero1 parallel: 1. if zero1 <= 0, The size of the zero process group is equal to the size of the dp process group, so parameters will be divided within the range of dp. 2. if zero1 == 1, zero is not used, and all dp groups retain the full amount of model parameters. 3. zero1 > 1 and zero1 <= dp world size, the world size of zero is a subset of dp world size. For smaller models, it is usually a better choice to split the parameters within nodes with a setting <= 8. pipeline parallel (dict): 1. size: int, the size of pipeline parallel. 2. interleaved_overlap: bool, enable/disable communication overlap when using interleaved pipeline scheduler. tensor parallel: tensor parallel size, usually the number of GPUs per node. """ parallel = dict( zero1=8, pipeline=dict(size=1, interleaved_overlap=True), sequence_parallel=False, ) cudnn_deterministic = False cudnn_benchmark = False monitor = dict( # feishu alert configs alert=dict( enable_feishu_alert=DO_ALERT, feishu_alert_address=None, # feishu webhook to send alert message light_monitor_address=None, # light_monitor address to send heartbeat ), )
-
-
数据相关的关键参数配置及释义如下所示:
-
TRAIN_FOLDER = "/path/to/dataset" SEQ_LEN = 2048 data = dict( seq_len=SEQ_LEN, # 数据样本长度,默认值为 2048 micro_num=1, # micro_num 是指在一次模型参数更新中会处理的 micro_batch 的数目,默认值为 1 micro_bsz=1, # packed_length = micro_bsz * SEQ_LEN,为一次处理的 micro_batch 的数据大小,默认值为 1 total_steps=50000, # 总的所需执行的 step 的数目,默认值为 50000 min_length=50, # 若数据集文件中,数据行数少于50,将会被废弃 train_folder=TRAIN_FOLDER, # 数据集文件路径,默认值为 None;若 train_folder 为空,则以自动生成的随机数据集进行训练测试 pack_sample_into_one=False, # 数据整理的逻辑,决定是按照 seq_len 维度或者是 sequence 的真实长度来进行attention计算 ) -
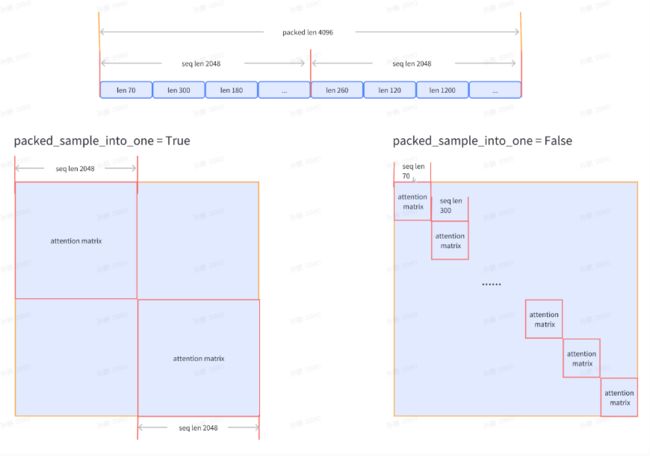
-
目前支持传入数据集文件路径
train_folder,且要求文件格式如下: -
- folder - code train_000.bin train_000.bin.meta
-
-
如果在启动训练时要加载模型
checkpoint,可进行如下相关配置:-
SAVE_CKPT_FOLDER = "local:/path/to/save/ckpt" LOAD_CKPT_FOLDER = "local:/path/to/load/resume/ckpt" ckpt = dict( save_ckpt_folder=SAVE_CKPT_FOLDER, # 存储模型和优化器 checkpoint 的路径 checkpoint_every=float("inf"), # 每多少个 step 存储一次 checkpoint,默认值为 inf # 断点续训时,加载模型和优化器等权重的路径,将从指定的 step 恢复训练 # content 表示哪些状态会被加载,支持: "model", "sampler", "optimizer", "scheduler", "all" # ckpt_type 表示加载的模型类型,目前支持: "internlm" load_ckpt_info=dict(path=MODEL_ONLY_FOLDER, content=("model",), ckpt_type="internlm"), )
-
-
模型相关关键参数配置如下所示:
-
model_type = "INTERNLM" # 模型类型,默认值为 "INTERNLM",对应模型结构初始化接口函数 NUM_ATTENTION_HEAD = 32 VOCAB_SIZE = 103168 HIDDEN_SIZE = 4096 NUM_LAYER = 32 MLP_RATIO = 8 / 3 model = dict( checkpoint=False, # 进行重计算的模型层数比例,可选值为 True/False/[0-1] num_attention_heads=NUM_ATTENTION_HEAD, embed_split_hidden=True, vocab_size=VOCAB_SIZE, embed_grad_scale=1, parallel_output=True, hidden_size=HIDDEN_SIZE, num_layers=NUM_LAYER, mlp_ratio=MLP_RATIO, apply_post_layer_norm=False, dtype="torch.bfloat16", norm_type="rmsnorm", layer_norm_epsilon=1e-5, )
-
-
训练并行配置样例如下:
-
parallel = dict( zero1=8, tensor=1, pipeline=dict(size=1, interleaved_overlap=True), sequence_parallel=False, ) -
zero1:zero 并行策略,分如下三种情况,默认值为 -1
-
当
zero1 <= 0,则 zero1 进程组的大小等于数据并行进程组的大小,因此优化器状态参数将在数据并行范围内分配 -
当
zero1 == 1,则不使用 zero1 ,所有数据并行组保留完整的优化器状态参数 -
当
zero1 > 1且zero1 <= data_parallel_world_size,则 zero1 进程组是数据并行进程组的子集
-
-
tensor:张量并行大小,通常是每个节点的 GPU 数量,默认值为 1
-
pipeline:流水线并行策略
-
size:流水线并行大小,默认值为 1
-
interleaved_overlap:bool 类型,交错式调度时,开启或关闭通信优化,默认值为关闭
-
-
sequence_parallel:是否开启序列化并行,默认值为 False
-
注意:
数据并行大小 = 总的 GPU 数目 / 流水线并行大小 / 张量并行大小
-
-
完成了以上数据集准备和相关训练配置后,可启动 Demo 训练。接下来分别以 torch 环境为例,启动分布式运行环境,单节点 8 卡的运行命令如下所示:
-
torchrun --nnodes=1 --nproc_per_node=8 train.py --config ./configs/7B_sft.py --launcher "torch"
-
-
-
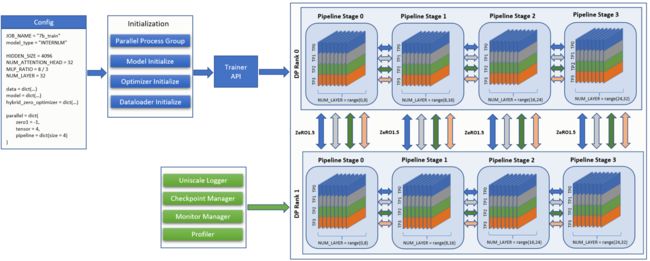
InternLM 的训练流程可以归纳为两个步骤:初始化,迭代训练
-
初始化模型、优化器、数据加载器、Trainer,生成不同种类的进程组,为混合并行的迭代训练做准备。初始化Logger、Checkpoint管理器、Monitor管理器、Profiler,对迭代训练的过程观察、预警、记录。
-
根据配置文件定义的张量并行、流水线并行、数据并行的大小,加载训练引擎和调度器进行混合并行训练。在迭代训练中,调用 Trainer API 进行梯度置零,前向传播计算损失并反向传播,参数更新。
-
-
-
InternLM 支持张量并行、流水线并行、序列并行、数据并行和 ZeRO1.5 等并行化训练策略。ZeRO1.5 的实现使用了分层分片的概念,通过配置值
parallel.zero1启用了本地节点内的分片。这个方法有助于有效管理和分配模型参数和梯度,以减少内存使用并提高训练效率。在初始化分布式环境时,我们需要指定张量并行大小、流水线并行大小、数据并行大小以及 ZeRO1.5 策略。InternLM 的并行设置由配置文件中的 parallel 字段指定,用户可以通过修改配置文件 config file 来更改并行配置。以下是一个并行训练配置示例:-
parallel = dict( zero1=8, tensor=1, pipeline=dict(size=1, interleaved_overlap=True), sequence_parallel=False, ) -
注意:数据并行大小 = 总的 GPU 数目 / 流水线并行大小 / 张量并行大小
-
ZeRO(Zero Redundancy Optimization)是一种优化技术,用于减少深度学习模型训练过程中的内存使用和显存使用。ZeRO技术通过将模型参数重新组织并压缩,使得每次更新模型参数时无需重新加载整个模型,从而提高了训练效率。ZeRO1.5是ZeRO技术的改进版,通过进一步优化内存使用和显存使用,使得训练更大规模的模型成为可能。ZeRO1.5技术采用了新的数据结构来存储模型参数,可以在不引入任何冗余的情况下,对模型参数进行高效地读取和更新。此外,ZeRO1.5还采用了新的算法来压缩和存储模型参数,可以在保持模型性能的同时,进一步减少内存和显存的使用。
-
-
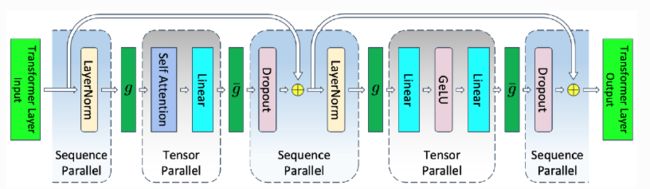
InternLM 的张量并行实现方案基于 flash attention, 主要对 attention 和 linear 这两个模块进行张量并行操作。随着研究的不断前进,Transformer尺寸变得越来越大、层数也越来越深,但是给Transformer配备更长的上下文仍然很困难,因为Transformer核心自注意力模块的时间复杂度以及内存复杂度在序列长度上是二次方的。有研究者提出一些近似注意力的方法,旨在减少注意力计算和内存需求。这些方法包括稀疏近似、低秩近似以及它们的组合。FlashAttention是一种具有IO感知,且兼具快速、内存高效的新型注意力算法。它通过减少GPU内存读取/写入,使得运行速度比PyTorch标准注意力快2-4倍,所需内存减少5-20倍。FlashAttention Transformer已然成为自然语言处理和图像分类等应用中最广泛使用的架构。
-
InternLM 在流水线并行中使用 1F1B (1F1B,一次前向传递后跟一次反向传递)策略。对于 1F1B 策略,有两种实现方式:非交错调度器,内存高效。交错调度器,内存高效且时间高效(GPU空泡较少)。
-
序列并行是一种在不引入额外计算、通信和内存开销的情况下,减少层
layer_norm和dropout操作中的激活值内存。InternLM 中的序列并行实现基于 flash attention。这个并行策略有助于降低模型的内存消耗,提高了模型在资源受限环境中的可扩展性。如果要启用序列并行, 用户需要设置parallel.sequence_parallel = True。 -
InternLM 使用
internlm.utils.model_checkpoint.CheckpointManager来管理模型保存。其中,可以使用CheckpointManager.try_save_checkpoint(train_state)来保存指定 step 的模型状态。InternLM支持启动时自动加载最新的模型备份,并在接收信号退出训练时自动进行模型备份。 -
InternLM 使用 internlm.train.initialize_llm_profile() 来收集和分析模型训练或推理期间的性能数据,如 CPU/CUDA/memory 等性能数据。这个实现基于 torch.profiler ,输出的性能分析 trace 文件可以使用 tensorboard 进行可视化。用户如果想使用这个 torch 性能分析工具,需要在启动训练时传递
--profiling参数以启用性能分析。完成 torch 性能分析后,用户可以在{JOB_NAME}/{start_time}/traces/rank{}_dp{}_tp{}_pp{}文件夹中看到性能分析结果。实际运行生成的Torch Profiler目录结构如下:-
# tree ./7b_train/Sep08_11-00-51/traces -L 2 ./7b_train/Sep08_11-00-51/traces/ └── rank0_dp0_tp0_pp0 └── SH-IDC1-10-140-1-78_238619.1694142354680.pt.trace.json -
其中,
traces可以通过TensorBoard可视化,运行命令 -
# visualize traces with tensorboard and custom port tensorboard --logdir rank0_dp0_tp0_pp0 --port 10088
-
-
InternLM 提供了一个实用的内存分析工具
internlm.utils.simple_memory_profiler.SimpleMemoryProfiler来监控实际的 GPU 内存使用情况。在实现中,会对模型数据(包括模型参数、模型梯度和优化器状态)和非模型数据(包括激活值)分别进行详细的统计。要使用这个内存分析工具,用户需要在启动训练时传递--profiling参数以启用内存分析。完成内存分析后,用户可以在memory_trace/rank{}_dp{}_tp{}文件夹中找到特定 rank 对应的内存分析结果(包括不同时间点的内存使用日志和显示总体内存使用情况的太阳图表)。 -
InternLM 使用
internlm.monitor.monitor.initialize_monitor_manager()来初始化上下文监控管理。其中,一个实例化的单例对象internlm.monitor.monitor.MonitorManager将管理监控线程并使用internlm.monitor.monitor.MonitorTracker来跟踪模型训练生命周期和训练状态。 -
InternLM 监控线程会周期性地检查模型训练过程中是否出现 loss spike、潜在的 training stuck、运行时异常等,并捕获 SIGTERM 异常信号。当出现上述情况时,将触发警报,并通过调用
internlm.monitor.alert.send_feishu_msg_with_webhook()向飞书的 Webhook 地址发送报警消息。训练样例 — InternLM 0.2.0 文档