基于Python的信用卡欺诈检测机器学习案例报告
本报告借助Python语言探究了在机器学习中,面对一个大型的人与人之间交易的数据集,如何尽快处理大量数据并区分某交易记录是正常的用户行为还是潜在的信用卡欺诈行为,最终通过构建分类模型来对欺诈交易进行分类区分,并通过恰当的方式对构建的模型进行评估,来解决上述问题。
一、背景介绍
1.1 研究问题
当今时代,在线支付已成为一种高效便捷的支付方式,我们可以突破时间和空间的限制,输入我们的信用卡各项信息就可以完成在线支付。但随之而来的是这种支付方式也具备一定的风险性,我们无法辨别对方是否是恶意套取我们资金的非法分子。当信用卡信息数据泄露导致金钱失窃并最终失去客户忠诚度和公司声誉时,组织、消费者、银行和商家都会面临风险。
2017 年,未经授权的信用卡操作达到了惊人的 1670 万受害者。此外,据美国联邦贸易委员会 (FTC) 报告,2017 年信用卡欺诈索赔数量比上一年高出 40%。加利福尼亚州报告了大约 13,000 起案件,佛罗里达州报告了 8,000 起案件,这两个州是此类犯罪人均最多的州。由此可以看出,信用卡欺诈检测已变得十分必要。为鉴别信用卡交易中的欺诈性行为,并采用合适的模型对非欺诈行为和欺诈行为进行分类,本报告以Kaggle网站上的信用卡欺诈案例数据集为例进行信用卡欺诈检测。
1.2 研究意义
当今时代,在线支付已经越来越普及,随之而来的电信诈骗案件也越来越频繁,给受害者的生活和心理造成了严重的影响,我们的资金安全问题亟待解决,刻不容缓。拥有一种好的信用卡欺诈检测服务,能够在很大程度上减少资金失窃的问题,对维护社会和平稳定安定有序,具有重大意义。
二、数据介绍及说明
本报告的数据来源于Kaggle这一网站,Kaggle是由联合创始人、首席执行官安东尼·高德布卢姆(Anthony Goldbloom)2010年在墨尔本创立的,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台,该平台已经吸引了80万名数据科学家的关注。
数据内容为2017年Kaggle网站上的案例Credit Card Fraud Detection这一部分的数据集,数据集文件名称为creditcard.csv。该数据集中收集的是2013年9月欧洲人使用信用卡在两天内产生的交易数据,其中284807笔交易中有492笔被盗刷。这个文件中包含特征 V1 到 V28,是我们分析数据所需要的主要成分,银行为了保密,并没有提供具体代表的内容。在该数据集中,忽略了对构建模型没有用的时间Time特征。其余的特征是当前交易总金额的“金额”特征Amount和当前交易是否为欺诈案件的“类别”特征Class,如果发生被盗刷,则取值1,否则为0。
三、信用卡欺诈检测的解决方案
3.1 项目总体规划
该信用卡欺诈检测案例项目有两个文件组成,分别是main.py和creditcard.csv。
其中creditcard.csv是我们项目所测试和训练的数据集,该数据集中的数据质量高,正负样本比例非常悬殊,很典型的异常检测数据集,在这个数据集上来测试各种异常检测手段的效果。main.py用来导入数据,对数据进行预处理,并进行建模对数据进行分类,最后对模型进行正确性评估。
3.2 导入相关模块
在该信用卡欺诈检测案例中,所需要用到的主要模块是处理数据的Pandas、处理数组的 NumPy、用于数据拆分、构建和评估分类模型的 scikit-learn,最后是用于 xgboost 分类器模型算法的 xgboost 包。其中scikit-learn包安装有要求,需要是Python3.5以上版本,且需要NumPy、SciPy、Pandas工具包的支持,部分内容需要使用Matplotlib。包安装指令如下:
1.pip install pandas
2.pip install numpy
3.pip install scipy
4.pip install matplotlib
5.pip3 install -U scikit-learn -i https://pypi.douban.com/simple
6.pip install xgboost在main.py中导入相关模块
1.import pandas as pd
2.import numpy as np
3.import matplotlib.pyplot as plt
4.from termcolor import colored as cl
5.import itertools
6.from sklearn.preprocessing import StandardScaler
7.from sklearn.model_selection import train_test_split
8.from sklearn.tree import DecisionTreeClassifier
9.from sklearn.neighbors import KNeighborsClassifier
10.from sklearn.linear_model import LogisticRegression
11.from sklearn.svm import SVC
12.from sklearn.ensemble import RandomForestClassifier
13.from xgboost import XGBClassifier
14.from sklearn.metrics import confusion_matrix
15.from sklearn.metrics import accuracy_score
16.from sklearn.metrics import f1_score3.3 导入数据
使用pd.read_csv方法导入数据,并查看部分数据样例。
1.df = pd.read_csv('creditcard.csv')
2.df.drop('Time', axis = 1, inplace = True)
3.print(df.head())部分数据如下:

可以看到,该数据集包含V1~V28的特征,以及总金额Amount和类别Class。V1~V28的特征是我们分析的主要数据;Amount是当前交易记录涉及总金额;Class是当前交易记录的类别,非欺诈案件类别为0,欺诈案件类别为1。
3.4 数据预处理和数据分析
接下来进行一些数据预处理和探索性数据分析,看看数据集中有多少欺诈案件和非欺诈案件。此外,还计算整个记录交易中欺诈案件的百分比。
3.4.1 案件类别分析统计
非欺诈案件即Class特征量为0的记录,则计算Class为0的记录的数量即为非欺诈案件的数量;欺诈案件即Class特征量为1的记录,则计算Class为1的记录的数量即为欺诈案件的数量;欺诈案件比例是:欺诈案件数目/非欺诈案件数目*100,并保留两位小数。
1.cases = len(df)
2.nonfraud_count = len(df[df.Class == 0])
3.fraud_count = len(df[df.Class == 1])
4.fraud_percentage = round(fraud_count/nonfraud_count*100, 2)
5.print(cl('案件统计', attrs = ['bold']))
6.print(cl('---------------------------------', attrs = ['bold']))
7.print(cl('总案件数量 {}'.format(cases), attrs = ['bold']))
8.print(cl('非欺诈案件数 {}'.format(nonfraud_count), attrs = ['bold']))
9.print(cl('欺诈案件数 {}'.format(fraud_count), attrs = ['bold']))
10.print(cl('欺诈案件比例 {}'.format(fraud_percentage), attrs = ['bold']))
11.print(cl('---------------------------------', attrs = ['bold']))之后对计算所得进行输出:

可以看到,总案件条数为284807,即共有284807条交易记录;非欺诈案件数即Class为0的有284315条记录;欺诈案件数即Class为1的有492条记录,两者比例超过500,欺诈案件比例为0.17,表明数据集非常不平衡,欺诈案件数占所有交易的0.17%。
接下来分别统计欺诈案件和非欺诈案件,使用 Python 中的describe方法获取欺诈和非欺诈交易金额数据的统计视图。
1.nonfraud_cases = df[df.Class == 0]
2.fraud_cases = df[df.Class == 1]
3.print(cl('案件统计:', attrs = ['bold']))
4.print(cl('------------------------------', attrs = ['bold']))
5.print(cl('非欺诈案件统计', attrs = ['bold']))
6.print(nonfraud_cases.Amount.describe())
7.print(cl('------------------------------', attrs = ['bold']))
8.print(cl('欺诈案件统计', attrs = ['bold']))
9.print(fraud_cases.Amount.describe())
10.print(cl('------------------------------', attrs = ['bold']))对计算结果进行输出:


在上述的输出结果中,count行统计了此列共有多少行没有缺失值;mean平均值,即是算术平均值,反应此列特征的一般水平;std标准差,反应此列数据的离散程度,一个较大的标准差,代表大部分数值和其平均值之间差异较大,一个较小的标准差,代表这些数值较接近平均值;min、25%、50%、75%、max,其中min max分别是最小值和最大值,而25%、50%、75%为四分位数,分位数是将总体的全部数据按大小顺序排列后,处于各等分位置的变量值。如果将全部数据分成相等的两部分,它就是中位数;如果分成四等分,就是四分位数, 50%的值就是中位数。通过四分位数,可以看出一个变量的分布情况是左偏、右偏或对称分布。
3.4.2 数据标准化处理
根据上述的统计数据,可以看到与其余变量相比,Amount变量中的值变化很大。我们需要对数据进行常规的预处理,将可能的特征属性进行标准化处理,因为算法都假设所有数据集的所有特征集中在0附近,并且有相同的方差,如果某个特征方差远大于其他特征方差,那么该特征可能在目标函数中占得权重更大,而且差距太大的话,这会对收敛速度产生很大的影响,甚至可能不收敛,这里采用sk-learn自带的StandardScaler()来对其进行标准化处理。
1.print('标准化之前')
2.print(cl(df['Amount'].head(10), attrs = ['bold']))
3.sc = StandardScaler()
4.amount = df['Amount'].values
5.df['Amount'] = sc.fit_transform(amount.reshape(-1, 1))
6.print('标准化之后')
7.print(cl(df['Amount'].head(10), attrs = ['bold']))标准化处理后该列数据会变成均值为0,方差为1的一列数据。


3.4.3 特征选择和数据集拆分
在这个过程中,定义自变量 (X) 和因变量 (y)。使用定义的变量将数据分成训练集和测试集,进一步用于建模和评估。可以使用python中的train_test_split方法轻松拆分数据。
train_test_split方法中的第一个参数X,是所要划分的样本特征集;第二个参数y,是所要划分的样本结果;第三个参数test_size是样本占比,如果是整数的话就是样本的数量;第四个参数random_state是随机数种子,即该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
1.X = df.drop('Class', axis = 1).values
2.y = df['Class'].values
3.X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 0)
4.print(cl('X_train 样本 : ', attrs = ['bold']),X_train[:1])
5.print(cl('X_test 样本 : ', attrs = ['bold']),X_test[0:1])
6.print(cl('y_train 样本 : ', attrs = ['bold']),y_train[0:20])
7.print(cl('y_test 样本 : ', attrs = ['bold']),y_test[0:20])拆分结果如下:

到目前为止,已经做好了构建分类模型所需的所有准备。
3.5构建模型及模型评估
构建六种不同类型的分类模型,即决策树、K-最近邻 (KNN)、逻辑回归、支持向量机 (SVM)、随机森林和XGBoost。所有这些模型构建均比较方便,都可以使用scikit-learn包提供的算法来构建。仅对于XGBoost模型,将使用 xgboost包。接下来在 Python 中实现这些模型,所使用的算法可能需要花费一定的时间来实现。
将使用scikit-learn包提供的评估指标来评估我们构建的模型。在此过程中的主要目标是为给定案例找到最佳模型。这里将使用的评估指标是准确度评分指标、f1-score评分指标及混淆矩阵。
准确率:准确率是最基本的评价指标之一,广泛用于评价分类模型。准确率分数的计算方法很简单,就是将模型做出的正确预测的数量除以模型做出的预测总数(可以乘以 100 将结果转换为百分比)。一般可以表示为:
准确度分数 = 正确预测数 / 总预测数
所构建的六种不同分类模型的准确率分数要在python中完成,我们可以使用scikit-learn包提供的accuracy_score方法。
F1-score 或 F-score:是用于评估分类模型的最流行的评估指标之一,它可以简单地定义为模型的准确率和召回率的调和平均值。它的计算方法是将模型的精度和召回率的乘积除以模型的精度和召回率相加得到的值,最后乘以 2 得到的值。可以表示为:
F1-score = 2( (精度 * 召回率) / (精度 + 召回率) )
可以使用scikit-learn包提供的f1_score方法轻松计算F1-score。
混淆矩阵:是分类模型的可视化,显示模型与原始结果相比预测结果的程度。通常,预测结果存储在一个变量中,然后将其转换为相关表。使用相关表,以热图的形式绘制混淆矩阵。尽管有多种内置方法可以可视化混淆矩阵,但我们将从零开始定义和可视化它,以便更好地理解。
混淆矩阵的定义如下:
1.def plot_confusion_matrix(cm, classes, title, normalize=False, cmap=plt.cm.Blues):
2. title = 'Confusion Matrix--{}'.format(title)
3. if normalize:
4. cm = cm.astype(float) / cm.sum(axis=1)[:, np.newaxis]
5. plt.imshow(cm, interpolation='nearest', cmap=cmap)
6. plt.title(title)
7. plt.colorbar()
8. tick_marks = np.arange(len(classes))
9. plt.xticks(tick_marks, classes, rotation=45)
10. plt.yticks(tick_marks, classes)
11. fmt = '.2f' if normalize else 'd'
12. thresh = cm.max() / 2.
13. for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
14. plt.text(j, i, format(cm[i, j], fmt),
15. horizontalalignment='center',
16. color='white' if cm[i, j] > thresh else 'black')
17. plt.tight_layout()
18. plt.ylabel('true label')
19. plt.xlabel('predicted label')3.5.1决策树模型及评估
在决策树模型中,使用DecisionTreeClassifier算法来构建模型。在算法中,设置max_depth=4,意味着允许树最大分裂四次,criterion = 'entropy',与max_depth最相似,但决定何时停止分裂树。最后拟合模型后将预测值存储到tree_yhat变量中。
1.tree_model = DecisionTreeClassifier(max_depth = 4, criterion = 'entropy')
2.tree_model.fit(X_train, y_train)
3.tree_yhat = tree_model.predict(X_test)决策树模型的准确率代码:
1.print(cl('决策树模型的准确率: {}'.format(accuracy_score(y_test, tree_yhat)),attrs = ['bold']))决策树模型的准确率:
![]()
决策树模型的F1-score代码:
1.print(cl('决策树模型的F1-score: {}'.format(f1_score(y_test, tree_yhat)),attrs = ['bold']))决策树模型的F1-score:
![]()
决策树模型的混淆矩阵代码:
1.# 计算模型的混淆矩阵
2.tree_matrix = confusion_matrix(y_test, tree_yhat,labels=[0, 1])
3.# figure.figsize:图像显示大小
4.plt.rcParams['figure.figsize'] = (6, 6)
5.# 具体调用函数绘制混淆矩阵热图
6.tree_cm_plot = plot_confusion_matrix(tree_matrix,classes = ['no-default(0)','default(1)'],normalize = False, title = 'decision tree')
7.plt.savefig('decision tree.png')
8.plt.show()决策树混淆矩阵:

从该混淆矩阵中可以看出来的信息是:实际上,非欺诈案件数目为56849+12;欺诈案件数目为24+77。而在模型的预测结果中,非欺诈案件数目为56849+24;欺诈案件数目为12+77。由此可以得出,在预测结果中,将12件欺诈案件预测为了非欺诈案件,预测失误;有56849个案件预测准确。
3.5.2 K-近邻模型及评估
在K-近邻模型中,使用KNeighborsClassifier算法构建了模型,并设置n_neighbors=5。n_neighbors的值是随机选择的,其实可以通过迭代一系列值来有目的地选择,然后拟合模型后将预测值存储到knn_yhat变量中。
1.n = 5
2.knn = KNeighborsClassifier(n_neighbors = n)
3.knn.fit(X_train, y_train)
4.knn_yhat = knn.predict(X_test)K-近邻模型的准确率代码:
print(cl('K近邻模型的准确率: {}'.format(accuracy_score(y_test, knn_yhat)),attrs = ['bold']))K-近邻模型的准确率:
![]()
K-近邻模型的F1-score代码:
1.print(cl('K近邻模型的F1-score: {}'.format(f1_score(y_test, knn_yhat)),attrs = ['bold']))K-近邻模型的F1-score:
![]()
K-近邻模型的混淆矩阵代码:
1.# 计算模型的混淆矩阵
2.knn_matrix = confusion_matrix(y_test, knn_yhat, labels = [0, 1]) # K-Nearest Neighbors
3.# 绘制混淆矩阵 figure.figsize:图像显示大小
4.plt.rcParams['figure.figsize'] = (6, 6)
5.knn_cm_plot = plot_confusion_matrix(knn_matrix, classes = ['Non-Default(0)','Default(1)'], normalize = False, title = 'KNN')
6.plt.savefig('knn_cm_plot.png')
7.plt.show()K-近邻混淆矩阵:

从该混淆矩阵中可以看出来的信息是:实际上,非欺诈案件数目为56854+7;欺诈案件数目为20+81。而在模型的预测结果中,非欺诈案件数目为56854+20;欺诈案件数目为81+7。由此可以得出,在预测结果中,将13件欺诈案件预测为了非欺诈案件,预测失误;有56854个案件预测准确。
然而KNN算法的时间复杂度为O(D*N*N)。其中D为维度数,N为样本总数。从时间复杂度上我们可以很清楚的就知道KNN非常不适合高维度的数据集,容易发生维度爆炸的情况。在此案例中我们有V1~V28个特征值,计算速度相较决策树而言变慢。
3.5.3逻辑回归模型及评估
逻辑回归模型中使用LogisticRegression算法并全部使用默认值,并拟合模型后将预测值存储到lr_yhat变量中。
1.lr = LogisticRegression()
2.lr.fit(X_train, y_train)
3.lr_yhat = lr.predict(X_test)逻辑回归模型的准确率代码:
1.print(cl('Accuracy score of the Logistic Regression model is {}'.format(accuracy_score(y_test, lr_yhat)),attrs = ['bold'], color = 'red'))逻辑回归模型的准确率:
![]()
逻辑回归模型的F1-score代码:
1.print(cl('K近邻模型的F1-score: {}'.format(f1_score(y_test, lr_yhat)),attrs = ['bold']))逻辑回归模型的F1-score:
![]()
逻辑回归模型的混淆矩阵代码:
1.# 计算模型的混淆矩阵
2.lr_matrix = confusion_matrix(y_test, lr_yhat, labels = [0, 1])
3.# 绘制混淆矩阵 figure.figsize:图像显示大小
4.plt.rcParams['figure.figsize'] = (6, 6)
5.lr_cm_plot = plot_confusion_matrix(lr_matrix, classes = ['Non-Default(0)','Default(1)'], normalize = False, title = 'Logistic Regression')
6.plt.savefig('lr_cm_plot.png')
7.plt.show()逻辑回归模型混淆矩阵:

从该混淆矩阵中可以看出来的信息是:实际上,非欺诈案件数目为56852+9;欺诈案件数目为37+64。而在模型的预测结果中,非欺诈案件数目为56852+37;欺诈案件数目为9+64。由此可以得出,在预测结果中,将28件欺诈案件预测为了非欺诈案件,预测失误;有56854个案件预测准确。
3.5.4支持向量机模型及评估
使用SVC算法构建了支持向量机模型,并且同样使用默认值,并且默认内核就是我们所希望用到的模型,即"rbf"内核。之后,我们在拟合模型后将预测值存储到svm_yhat中。
1.svm = SVC()
2.svm.fit(X_train, y_train)
3.svm_yhat = svm.predict(X_test)支持向量机模型的准确率代码:
1.print(cl('支持向量机模型的准确度为 {}'.format(accuracy_score(y_test, svm_yhat)),attrs = ['bold'], color = 'red'))支持向量机模型的准确率:
![]()
支持向量机模型的F1-score代码:
1.print(cl('支持向量机模型的F1-score: {}'.format(f1_score(y_test, svm_yhat)),attrs = ['bold']))支持向量机模型的F1-score:
![]()
支持向量机模型的混淆矩阵代码:
1.# 计算模型的混淆矩阵
2.svm_matrix = confusion_matrix(y_test, svm_yhat, labels = [0, 1])
3.# 绘制混淆矩阵 figure.figsize:图像显示大小
4.plt.rcParams['figure.figsize'] = (6, 6)
5.svm_cm_plot = plot_confusion_matrix(svm_matrix, classes = ['Non-Default(0)','Default(1)'], normalize = False, title = 'SVM')
6.plt.savefig('svm_cm_plot.png')
7.plt.show()支持向量机模型混淆矩阵:

从该混淆矩阵中可以看出来的信息是:实际上,非欺诈案件数目为56855+6;欺诈案件数目为33+68。而在模型的预测结果中,非欺诈案件数目为56855+33;欺诈案件数目为6+68。由此可以得出,在预测结果中,将27件欺诈案件预测为了非欺诈案件,预测失误;有56855个案件预测准确。
在支持向量机模型中,如果数据特征(维度)大于样本量,支持向量机表现很差,表现在计算速度慢方面。
3.5.5随机森林模型及评估
使用RandomForestClassifier算法构建的随机森林模型,设置参数max_depth=4,就像构建决策树模型的方式一样。最后在拟合模型后将预测值存储到rf_yhat中。决策树和随机森林之间的主要区别在于,决策树使用整个数据集来构建单个模型,而随机森林使用随机选择的特征来构建多个模型。这就是为什么很多情况下选择使用随机森林模型而不是决策树的原因。
1.rf = RandomForestClassifier(max_depth = 4)
2.rf.fit(X_train, y_train)
3.rf_yhat = rf.predict(X_test)随机森林模型的准确率代码:
1.print(cl('随机森林模型的准确度为 {}'.format(accuracy_score(y_test, rf_yhat)),attrs = ['bold'], color = 'red'))随机森林模型的准确率:
![]()
随机森林模型的F1-score代码:
1.print(cl('随机森林模型的F1-score: {}'.format(f1_score(y_test, rf_yhat)),attrs = ['bold']))随机森林模型的F1-score:
![]()
随机森林模型的混淆矩阵代码:
1.# 计算模型的混淆矩阵
2.rf_matrix = confusion_matrix(y_test, rf_yhat, labels = [0, 1])
3.# 绘制混淆矩阵 figure.figsize:图像显示大小
4.plt.rcParams['figure.figsize'] = (6, 6)
5.rf_cm_plot = plot_confusion_matrix(rf_matrix, classes = ['Non-Default(0)','Default(1)'], normalize = False, title = 'Random Forest Tree')
6.plt.savefig('rf_cm_plot.png')
plt.show()随机森林模型混淆矩阵:

从该混淆矩阵中可以看出来的信息是:实际上,非欺诈案件数目为56853+8;欺诈案件数目为31+70。而在模型的预测结果中,非欺诈案件数目为56853+31;欺诈案件数目为8+70。由此可以得出,在预测结果中,将23件欺诈案件预测为了非欺诈案件,预测失误;有56853个案件预测准确。
3.5.6 XGBoost模型及评估
使用xgboost包提供的XGBClassifier算法构建模型。设置max_depth=4,最后在拟合模型后将预测值存储到xgb_yhat中
1.xgb = XGBClassifier(max_depth = 4)
2.xgb.fit(X_train, y_train)
3.xgb_yhat = xgb.predict(X_test)XGBoost模型的准确率代码:
1.print(cl('XGBoost模型的准确度为 {}'.format(accuracy_score(y_test, xgb_yhat)),attrs = ['bold'], color = 'red'))XGBoost模型的准确率:
![]()
XGBoost模型的F1-score代码:
1.print(cl('XGBoost模型的F1-score: {}'.format(f1_score(y_test, xgb_yhat)),attrs = ['bold']))XGBoost模型的F1-score:
![]()
XGBoost模型的混淆矩阵代码:
1.# 计算模型的混淆矩阵
2.xgb_matrix = confusion_matrix(y_test, xgb_yhat, labels = [0, 1])
3.# 绘制混淆矩阵 figure.figsize:图像显示大小
4.plt.rcParams['figure.figsize'] = (6, 6)
5.xgb_cm_plot = plot_confusion_matrix(xgb_matrix, classes = ['Non-Default(0)','Default(1)'], normalize = False, title = 'XGBoost')
6.plt.savefig('xgb_cm_plot.png')
7.plt.show()XGBoost模型混淆矩阵:

从该混淆矩阵中可以看出来的信息是:实际上,非欺诈案件数目为56854+7;欺诈案件数目为22+79。而在模型的预测结果中,非欺诈案件数目为56855+22;欺诈案件数目为7+79。由此可以得出,在预测结果中,将15件欺诈案件预测为了非欺诈案件,预测失误;有56854个案件预测准确。
到此,我们完成了6种模型对我们数据集的预测。
四、信用卡欺诈检测模型数据分析
4.1模型准确度对比
决策树模型的准确率:0.9993679997191109
K近邻模型的准确率:0.9995259997893332
逻辑回归模型的准确度为0.9991924440855307
支持向量机模型的准确度为0.9993153330290369
随机森林模型的准确度为0.9993153330290369
XGBoost模型的准确度为0.9994908886626171
根据准确性评分评估指标来看,K-近邻模型为最准确的模型,而 逻辑回归模型最不准确。然而,当我们对每个模型的结果进行四舍五入时,得到 99% 的准确性,这看是一个非常好的分数。
4.2模型F1-score对比
决策树模型的F1-score: 0.8105263157894738
K近邻模型的F1-score: 0.8571428571428572
逻辑回归模型的F1-score : 0.7356321839080459
支持向量机模型的F1-score: 0.7771428571428572
随机森林模型的F1-score: 0.7821229050279329
XGBoost模型的准确度为0.9994908886626171
模型的排名几乎与之前的评估指标相似。在 F1-score 评估指标的基础上,K-近邻模型再次夺得第一,逻辑回归模型仍然是最不准确的模型。
4.3模型混淆矩阵对比





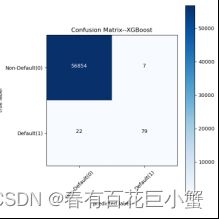
在比较所有模型的混淆矩阵时可以看出,K-近邻模型在从非欺诈交易中分类欺诈交易方面做得非常好,其次是 XGBoost 模型。所以可以得出结论,最适合本次案例的模型是K-近邻模型,可以忽略的模型是逻辑回归模型。
五、总结
欺诈是整个信用卡行业的一个主要问题,随着电子货币转账的日益普及,该行业变得越来越大。为有效防范导致银行账户信息泄露、盗刷、伪造信用卡、每年数十亿美元被盗以及声誉和客户忠诚度损失的犯罪行为,信用卡发卡机构应考虑实施高级信用信用卡欺诈预防和欺诈检测方法。基于机器学习的方法可以根据每个持卡人的行为信息不断提高欺诈预防的准确性。