Python 架构模式:引言到第四章
引言
原文:Introduction
译者:飞龙
协议:CC BY-NC-SA 4.0
为什么我们的设计会出错?
当你听到混乱这个词时,你会想到什么?也许你会想到喧闹的股票交易所,或者早上的厨房——一切都混乱不堪。当你想到秩序这个词时,也许你会想到一个空旷的房间,宁静而平静。然而,对于科学家来说,混乱的特征是同质性(相同),而秩序的特征是复杂性(不同)。
例如,一个精心照料的花园是一个高度有序的系统。园丁用小路和篱笆定义边界,并标出花坛或菜园。随着时间的推移,花园会不断发展,变得更加丰富和茂密;但如果没有刻意的努力,花园就会变得狂野。杂草和草会扼杀其他植物,覆盖小路,最终每个部分看起来都一样——野生和无管理。
软件系统也倾向于混乱。当我们开始构建一个新系统时,我们有很大的想法,认为我们的代码会整洁有序,但随着时间的推移,我们发现它积累了垃圾和边缘情况,最终变成了令人困惑的混乱的经理类和工具模块。我们发现我们明智地分层的架构已经像过于湿润的杂果布丁一样崩溃了。混乱的软件系统的特征是功能的相同性:具有领域知识并发送电子邮件和执行日志记录的 API 处理程序;“业务逻辑”类不进行计算但执行 I/O;以及一切与一切耦合,以至于改变系统的任何部分都充满了危险。这是如此普遍,以至于软件工程师有自己的术语来描述混乱:大泥球反模式(图 P-1)。
图 P-1. 真实的依赖关系图(来源:“企业依赖:大毛线球” by Alex Papadimoulis)
提示
软件的自然状态就像你的花园的自然状态一样,都是一团大泥巴。阻止崩溃需要能量和方向。
幸运的是,避免创建一团大泥巴的技术并不复杂。
封装和抽象
封装和抽象是我们作为程序员本能地使用的工具,即使我们并不都使用这些确切的词语。让我们稍微停留一下,因为它们是本书中不断出现的背景主题。
术语封装涵盖了两个密切相关的概念:简化行为和隐藏数据。在这个讨论中,我们使用的是第一个意义。我们通过识别代码中需要完成的任务,并将该任务交给一个明确定义的对象或函数来封装行为。我们称该对象或函数为抽象。
看一下以下两个 Python 代码片段:
使用 urllib 进行搜索
import json
from urllib.request import urlopen
from urllib.parse import urlencode
params = dict(q='Sausages', format='json')
handle = urlopen('http://api.duckduckgo.com' + '?' + urlencode(params))
raw_text = handle.read().decode('utf8')
parsed = json.loads(raw_text)
results = parsed['RelatedTopics']
for r in results:
if 'Text' in r:
print(r['FirstURL'] + ' - ' + r['Text'])
使用 requests 进行搜索
import requests
params = dict(q='Sausages', format='json')
parsed = requests.get('http://api.duckduckgo.com/', params=params).json()
results = parsed['RelatedTopics']
for r in results:
if 'Text' in r:
print(r['FirstURL'] + ' - ' + r['Text'])
这两个代码清单都做同样的事情:它们提交表单编码的值到一个 URL,以便使用搜索引擎 API。但第二个更容易阅读和理解,因为它在更高的抽象级别上操作。
我们可以进一步迈出这一步,通过识别和命名我们希望代码为我们执行的任务,并使用更高级别的抽象来明确地执行它:
使用 duckduckgo 模块进行搜索
import duckduckgo
for r in duckduckgo.query('Sausages').results:
print(r.url + ' - ' + r.text)
通过使用抽象来封装行为是使代码更具表现力、更易于测试和更易于维护的强大工具。
注意
在面向对象(OO)世界的文献中,这种方法的经典特征之一被称为责任驱动设计;它使用角色和责任这些词,而不是任务。主要观点是以行为的方式思考代码,而不是以数据或算法的方式。¹
本书中的大多数模式都涉及选择抽象,因此您将在每一章中看到很多例子。此外,第三章专门讨论了选择抽象的一些一般启发法。
分层
封装和抽象通过隐藏细节和保护数据的一致性来帮助我们,但我们还需要注意对象和函数之间的交互。当一个函数、模块或对象使用另一个时,我们说一个依赖于另一个。这些依赖形成一种网络或图。
在一个巨大的泥球中,依赖关系失控(正如您在图 P-1 中看到的)。改变图的一个节点变得困难,因为它有可能影响系统的许多其他部分。分层架构是解决这个问题的一种方式。在分层架构中,我们将代码分成离散的类别或角色,并引入关于哪些代码类别可以相互调用的规则。
最常见的例子之一是图 P-2 中显示的三层架构。

图 P-2。分层架构
[ditaa,apwp_0002]
+----------------------------------------------------+
| Presentation Layer |
+----------------------------------------------------+
|
V
+----------------------------------------------------+
| Business Logic |
+----------------------------------------------------+
|
V
+----------------------------------------------------+
| Database Layer |
+----------------------------------------------------+
分层架构可能是构建业务软件最常见的模式。在这个模型中,我们有用户界面组件,可以是网页、API 或命令行;这些用户界面组件与包含我们的业务规则和工作流程的业务逻辑层进行通信;最后,我们有一个负责存储和检索数据的数据库层。
在本书的其余部分,我们将通过遵循一个简单的原则系统地将这个模型颠倒过来。
依赖反转原则
您可能已经熟悉依赖反转原则(DIP),因为它是 SOLID 中的D。²
不幸的是,我们无法像我们为封装所做的那样使用三个小的代码清单来说明 DIP。然而,第 I 部分的整个内容本质上是一个在整个应用程序中实现 DIP 的示例,因此您将得到大量具体的例子。
与此同时,我们可以谈谈 DIP 的正式定义:
-
高级模块不应该依赖于低级模块。两者都应该依赖于抽象。
-
抽象不应该依赖于细节。相反,细节应该依赖于抽象。
但这意味着什么呢?让我们一点一点来看。
高级模块是您的组织真正关心的代码。也许您在制药公司工作,您的高级模块处理患者和试验。也许您在银行工作,您的高级模块管理交易和交易所。软件系统的高级模块是处理我们真实世界概念的函数、类和包。
相比之下,低级模块是您的组织不关心的代码。您的人力资源部门不太可能对文件系统或网络套接字感到兴奋。您不经常与财务团队讨论 SMTP、HTTP 或 AMQP。对于我们的非技术利益相关者来说,这些低级概念并不有趣或相关。他们关心的只是高级概念是否正常工作。如果工资按时发放,您的业务不太可能关心这是一个 cron 作业还是在 Kubernetes 上运行的临时函数。
依赖于并不一定意味着导入或调用,而是一个更一般的想法,即一个模块知道或需要另一个模块。
我们已经提到了抽象:它们是简化的接口,封装了行为,就像我们的 duckduckgo 模块封装了搜索引擎的 API 一样。
计算机科学中的所有问题都可以通过增加另一个间接层来解决。
——大卫·惠勒
因此,DIP 的第一部分表示我们的业务代码不应该依赖于技术细节;相反,两者都应该使用抽象。
为什么?大体上,因为我们希望能够独立地对它们进行更改。高级模块应该易于根据业务需求进行更改。低级模块(细节)在实践中通常更难更改:想想重构以更改函数名称与定义、测试和部署数据库迁移以更改列名称之间的区别。我们不希望业务逻辑的更改因为与低级基础设施细节紧密耦合而变慢。但同样地,当需要时,重要的是能够更改基础设施细节(例如考虑分片数据库),而不需要对业务层进行更改。在它们之间添加一个抽象(著名的额外间接层)允许它们更独立地进行更改。
第二部分更加神秘。“抽象不应该依赖于细节”似乎很清楚,但“细节应该依赖于抽象”很难想象。我们怎么可能有一个不依赖于它所抽象的细节的抽象呢?到了第四章,我们将有一个具体的例子,这应该会让这一切更加清晰一些。
我们所有业务逻辑的归宿:领域模型
但在我们能够将我们的三层架构颠倒过来之前,我们需要更多地讨论中间层:高级模块或业务逻辑。我们设计出错的最常见原因之一是业务逻辑分散在应用程序的各个层中,使得很难识别、理解和更改。
第一章展示了如何使用领域模型模式构建业务层。第一部分中的其余模式展示了我们如何通过选择正确的抽象并持续应用 DIP 来保持领域模型易于更改并且不受低级关注的影响。
¹ 如果你遇到过类-责任-协作(CRC)卡,它们指的是同样的事情:思考责任可以帮助你决定如何分割事物。
² SOLID 是 Robert C. Martin 关于面向对象设计的五个原则的首字母缩写:单一职责、开放封闭、里氏替换、接口隔离和依赖反转。参见 Samuel Oloruntoba 的文章“S.O.L.I.D: The First 5 Principles of Object-Oriented Design”。
第一部分:构建支持领域建模的架构
原文:Part 1: Building an Architecture to Support Domain Modeling
译者:飞龙
协议:CC BY-NC-SA 4.0
大多数开发人员从未见过领域模型,只见过数据模型。
——Cyrille Martraire, DDD EU 2017
我们与关于架构的开发人员交谈时,他们常常有一种隐隐的感觉,觉得事情本可以更好。他们经常试图拯救一些出了问题的系统,并试图将一些结构重新放入一团混乱之中。他们知道他们的业务逻辑不应该分散在各个地方,但他们不知道如何解决。
我们发现许多开发人员在被要求设计一个新系统时,会立即开始构建数据库模式,将对象模型视为事后补充。这就是问题的根源。相反,行为应该首先驱动我们的存储需求。毕竟,我们的客户不关心数据模型。他们关心系统做什么;否则他们就会使用电子表格。
本书的第一部分介绍了如何通过 TDD 构建丰富的对象模型(在第一章中),然后我们将展示如何将该模型与技术关注点解耦。我们展示了如何构建与持久性无关的代码,以及如何围绕我们的领域创建稳定的 API,以便我们可以进行积极的重构。
为此,我们介绍了四个关键的设计模式:
-
存储库模式,是对持久性存储概念的抽象
-
服务层模式清晰地定义了我们的用例从何处开始和结束
-
工作单元模式提供原子操作
-
聚合模式以强制执行我们数据的完整性
如果你想知道我们的目标是什么,请看一下图 I-1,但如果现在还一头雾水也不要担心!我们会在本书的这一部分逐一介绍图中的每个框。
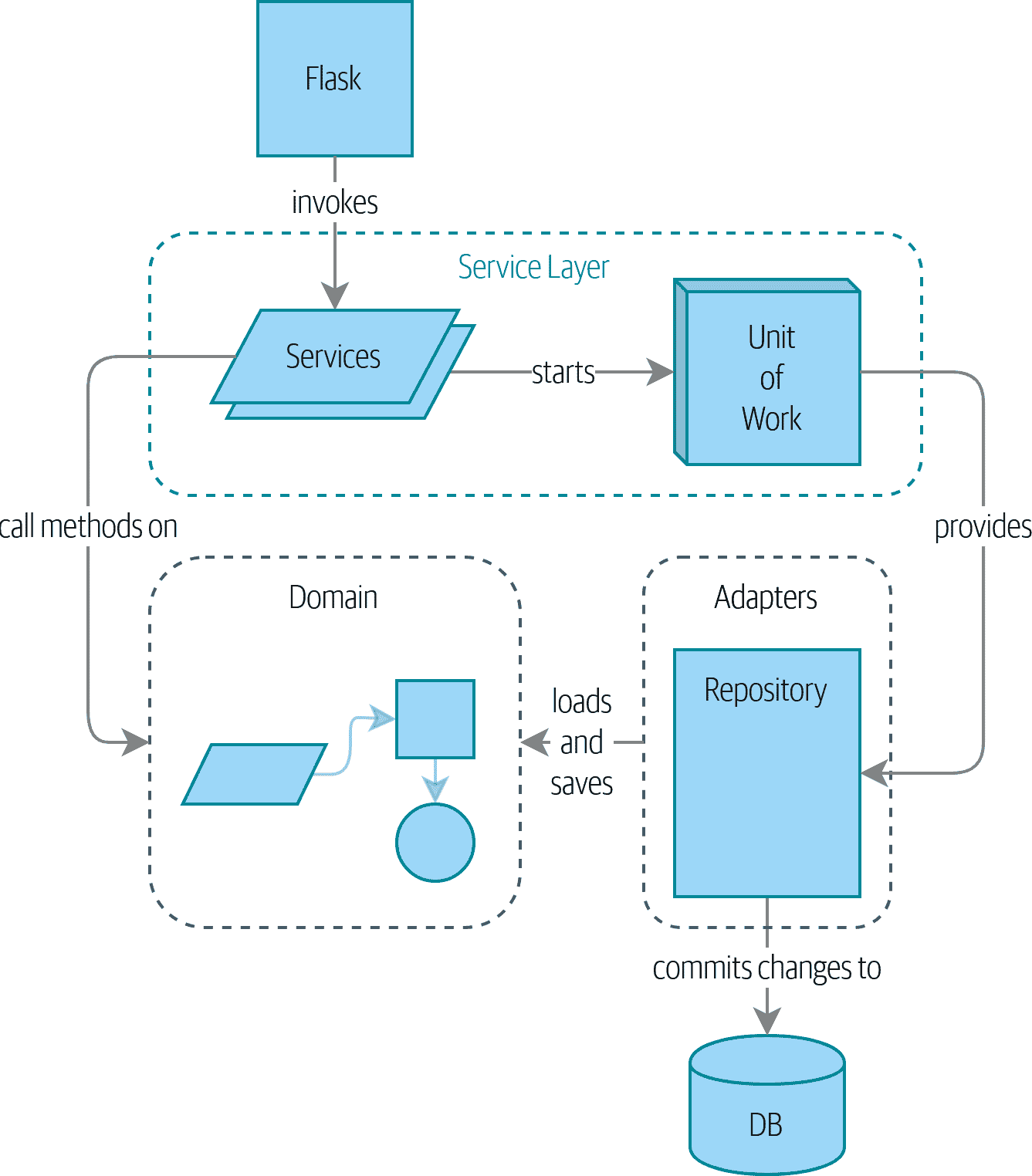
图 I-1:我们应用程序的组件图在第 I 部分结束时
我们还抽出一点时间来谈论耦合和抽象,并用一个简单的例子来说明我们选择抽象的方式及原因。
三个附录进一步探讨了第一部分的内容:
-
附录 B 是我们示例代码的基础设施的描述:我们如何构建和运行 Docker 镜像,我们在哪里管理配置信息,以及我们如何运行不同类型的测试。
-
附录 C 是一种“见证成败”的内容,展示了如何轻松地更换我们整个基础架构——Flask API、ORM 和 Postgres——以完全不同的 I/O 模型,涉及 CLI 和 CSV。
-
最后,附录 D 可能会引起兴趣,如果你想知道使用 Django 而不是 Flask 和 SQLAlchemy 时这些模式会是什么样子。
第一章:领域建模
原文:1: Domain Modeling
译者:飞龙
协议:CC BY-NC-SA 4.0
本章将探讨如何用代码对业务流程进行建模,以一种与 TDD 高度兼容的方式。我们将讨论领域建模的重要性,并将介绍一些建模领域的关键模式:实体、值对象和领域服务。
图 1-1 是我们领域模型模式的一个简单的视觉占位符。在本章中,我们将填写一些细节,随着我们继续其他章节,我们将围绕领域模型构建东西,但您应该始终能够在核心找到这些小形状。
图 1-1:我们领域模型的一个占位符插图
什么是领域模型?
在介绍中,我们使用了术语业务逻辑层来描述三层架构的中心层。在本书的其余部分,我们将使用术语领域模型。这是 DDD 社区的一个术语,更能准确地捕捉我们的意思(有关 DDD 的更多信息,请参见下一个侧边栏)。
领域是说您正在尝试解决的问题的一种花哨的说法。您的作者目前为一家家具在线零售商工作。根据您所谈论的系统,领域可能是采购和采购、产品设计或物流和交付。大多数程序员都在努力改进或自动化业务流程;领域是支持这些流程的一系列活动。
模型是捕捉有用属性的过程或现象的地图。人类在脑海中制作事物的模型非常擅长。例如,当有人向您扔球时,您能够几乎下意识地预测其运动,因为您对物体在空间中移动的方式有一个模型。您的模型并不完美。人类对物体在接近光速或真空中的行为有着糟糕的直觉,因为我们的模型从未设计来涵盖这些情况。这并不意味着模型是错误的,但这确实意味着一些预测超出了其领域。
领域模型是业务所有者对其业务的心智地图。所有的商业人士都有这些心智地图——这是人类思考复杂流程的方式。
当他们在这些地图上导航时,您可以通过他们使用商业用语来判断。术语在协作处理复杂系统的人群中自然产生。
想象一下,您,我们不幸的读者,突然被传送到光年之外的外星飞船上,与您的朋友和家人一起,不得不从头开始弄清楚如何回家。
在最初的几天里,您可能只是随机按按钮,但很快您会学会哪些按钮做什么,这样您就可以给彼此指示。“按下闪烁的小玩意旁边的红色按钮,然后把雷达小玩意旁边的大杠杆扔过去”,您可能会说。
在几周内,您会变得更加精确,因为您采用了用于描述船舶功能的词汇:“增加货舱三的氧气水平”或“打开小推进器”。几个月后,您将采用整个复杂流程的语言:“开始着陆序列”或“准备跃迁”。这个过程会很自然地发生,而不需要任何正式的努力来建立共享词汇表。
因此,在日常商业世界中也是如此。商业利益相关者使用的术语代表了对领域模型的精炼理解,复杂的想法和流程被简化为一个词或短语。
当我们听到我们的业务利益相关者使用陌生的词汇,或者以特定方式使用术语时,我们应该倾听以理解更深层的含义,并将他们辛苦获得的经验编码到我们的软件中。
在本书中,我们将使用一个真实的领域模型,具体来说是我们目前的雇主的模型。MADE.com 是一家成功的家具零售商。我们从世界各地的制造商那里采购家具,并在整个欧洲销售。
当您购买沙发或咖啡桌时,我们必须想出如何最好地将您的商品从波兰、中国或越南运送到您的客厅。
在高层次上,我们有独立的系统负责购买库存、向客户销售库存和向客户发货。中间的一个系统需要通过将库存分配给客户的订单来协调这个过程;参见图 1-2。

图 1-2:分配服务的上下文图
[plantuml, apwp_0102]
@startuml Allocation Context Diagram
!include images/C4_Context.puml
System(systema, "Allocation", "Allocates stock to customer orders")
Person(customer, "Customer", "Wants to buy furniture")
Person(buyer, "Buying Team", "Needs to purchase furniture from suppliers")
System(procurement, "Purchasing", "Manages workflow for buying stock from suppliers")
System(ecom, "E-commerce", "Sells goods online")
System(warehouse, "Warehouse", "Manages workflow for shipping goods to customers.")
Rel(buyer, procurement, "Uses")
Rel(procurement, systema, "Notifies about shipments")
Rel(customer, ecom, "Buys from")
Rel(ecom, systema, "Asks for stock levels")
Rel(ecom, systema, "Notifies about orders")
Rel_R(systema, warehouse, "Sends instructions to")
Rel_U(warehouse, customer, "Dispatches goods to")
@enduml
为了本书的目的,我们想象业务决定实施一种令人兴奋的新的库存分配方式。到目前为止,业务一直根据仓库中实际可用的库存和交货时间来展示库存和交货时间。如果仓库用完了,产品就被列为“缺货”,直到下一批从制造商那里到货。
这里的创新是:如果我们有一个系统可以跟踪我们所有的货物运输及其到达时间,我们就可以将这些货物视为真实库存和我们库存的一部分,只是交货时间稍长一些。更少的商品将显示为缺货,我们将销售更多商品,业务可以通过在国内仓库保持较低的库存来节省成本。
但是分配订单不再是在仓库系统中减少单个数量的琐事。我们需要一个更复杂的分配机制。是时候进行一些领域建模了。
探索领域语言
理解领域模型需要时间、耐心和便利贴。我们与业务专家进行了初步对话,并就领域模型的第一个最小版本的术语表和一些规则达成一致。在可能的情况下,我们要求提供具体的例子来说明每条规则。
我们确保用业务行话(在 DDD 术语中称为普遍语言)来表达这些规则。我们为我们的对象选择了易于讨论的可记忆的标识符,以便更容易地讨论示例。
“分配的一些注释”显示了我们在与领域专家讨论分配时可能做的一些注释。
领域模型的单元测试
我们不会在这本书中向您展示 TDD 的工作原理,但我们想向您展示我们如何从这次业务对话中构建模型。
我们的第一个测试可能如下所示:
分配的第一个测试(test_batches.py)
def test_allocating_to_a_batch_reduces_the_available_quantity():
batch = Batch("batch-001", "SMALL-TABLE", qty=20, eta=date.today())
line = OrderLine('order-ref', "SMALL-TABLE", 2)
batch.allocate(line)
assert batch.available_quantity == 18
我们的单元测试的名称描述了我们希望从系统中看到的行为,我们使用的类和变量的名称取自业务行话。我们可以向非技术同事展示这段代码,他们会同意这正确地描述了系统的行为。
这是一个满足我们要求的领域模型:
批次的领域模型的初步版本(model.py)
@dataclass(frozen=True) #(1) (2)
class OrderLine:
orderid: str
sku: str
qty: int
class Batch:
def __init__(self, ref: str, sku: str, qty: int, eta: Optional[date]): #(2)
self.reference = ref
self.sku = sku
self.eta = eta
self.available_quantity = qty
def allocate(self, line: OrderLine): #(3)
self.available_quantity -= line.qty
①
OrderLine是一个没有行为的不可变数据类。²
②
我们在大多数代码清单中不显示导入,以保持其整洁。我们希望您能猜到这是通过from dataclasses import dataclass导入的;同样,typing.Optional和datetime.date也是如此。如果您想要进行双重检查,可以在其分支中查看每个章节的完整工作代码(例如,chapter_01_domain_model)。
③
类型提示在 Python 世界仍然是一个有争议的问题。对于领域模型,它们有时可以帮助澄清或记录预期的参数是什么,而且使用 IDE 的人通常会对它们表示感激。您可能会认为在可读性方面付出的代价太高。
我们的实现在这里是微不足道的:Batch只是包装了一个整数available_quantity,并在分配时减少该值。我们写了相当多的代码来从另一个数字中减去一个数字,但我们认为精确建模我们的领域将会得到回报。³
让我们写一些新的失败测试:
测试我们可以分配什么的逻辑(test_batches.py)
def make_batch_and_line(sku, batch_qty, line_qty):
return (
Batch("batch-001", sku, batch_qty, eta=date.today()),
OrderLine("order-123", sku, line_qty)
)
def test_can_allocate_if_available_greater_than_required():
large_batch, small_line = make_batch_and_line("ELEGANT-LAMP", 20, 2)
assert large_batch.can_allocate(small_line)
def test_cannot_allocate_if_available_smaller_than_required():
small_batch, large_line = make_batch_and_line("ELEGANT-LAMP", 2, 20)
assert small_batch.can_allocate(large_line) is False
def test_can_allocate_if_available_equal_to_required():
batch, line = make_batch_and_line("ELEGANT-LAMP", 2, 2)
assert batch.can_allocate(line)
def test_cannot_allocate_if_skus_do_not_match():
batch = Batch("batch-001", "UNCOMFORTABLE-CHAIR", 100, eta=None)
different_sku_line = OrderLine("order-123", "EXPENSIVE-TOASTER", 10)
assert batch.can_allocate(different_sku_line) is False
这里没有太多意外。我们重构了我们的测试套件,以便我们不再重复相同的代码行来为相同的 SKU 创建批次和行;我们为一个新方法can_allocate编写了四个简单的测试。再次注意,我们使用的名称与我们的领域专家的语言相呼应,并且我们商定的示例直接写入了代码。
我们也可以直接实现这一点,通过编写Batch的can_allocate方法:
模型中的一个新方法(model.py)
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qty
到目前为止,我们可以通过增加和减少Batch.available_quantity来管理实现,但是当我们进入deallocate()测试时,我们将被迫采用更智能的解决方案:
这个测试将需要一个更智能的模型(test_batches.py)
def test_can_only_deallocate_allocated_lines():
batch, unallocated_line = make_batch_and_line("DECORATIVE-TRINKET", 20, 2)
batch.deallocate(unallocated_line)
assert batch.available_quantity == 20
在这个测试中,我们断言从批次中取消分配一行,除非批次先前分配了该行,否则不会产生任何影响。为了使其工作,我们的Batch需要了解哪些行已经被分配。让我们来看看实现:
领域模型现在跟踪分配(model.py)
class Batch:
def __init__(
self, ref: str, sku: str, qty: int, eta: Optional[date]
):
self.reference = ref
self.sku = sku
self.eta = eta
self._purchased_quantity = qty
self._allocations = set() # type: Set[OrderLine]
def allocate(self, line: OrderLine):
if self.can_allocate(line):
self._allocations.add(line)
def deallocate(self, line: OrderLine):
if line in self._allocations:
self._allocations.remove(line)
@property
def allocated_quantity(self) -> int:
return sum(line.qty for line in self._allocations)
@property
def available_quantity(self) -> int:
return self._purchased_quantity - self.allocated_quantity
def can_allocate(self, line: OrderLine) -> bool:
return self.sku == line.sku and self.available_quantity >= line.qty
图 1-3 显示了 UML 中的模型。

图 1-3. 我们的 UML 模型
[plantuml, apwp_0103, config=plantuml.cfg]
left to right direction
hide empty members
class Batch {
reference
sku
eta
_purchased_quantity
_allocations
}
class OrderLine {
orderid
sku
qty
}
Batch::_allocations o-- OrderLine
现在我们有了进展!批次现在跟踪一组已分配的OrderLine对象。当我们分配时,如果我们有足够的可用数量,我们只需添加到集合中。我们的available_quantity现在是一个计算属性:购买数量减去分配数量。
是的,我们还可以做很多事情。令人不安的是,allocate()和deallocate()都可能悄悄失败,但我们已经掌握了基础知识。
顺便说一句,使用._allocations的集合使我们能够简单地处理最后一个测试,因为集合中的项目是唯一的:
最后的批次测试!(test_batches.py)
def test_allocation_is_idempotent():
batch, line = make_batch_and_line("ANGULAR-DESK", 20, 2)
batch.allocate(line)
batch.allocate(line)
assert batch.available_quantity == 18
目前,可以说领域模型太琐碎,不值得费心去做 DDD(甚至是面向对象!)。在现实生活中,会出现任意数量的业务规则和边缘情况:客户可以要求在特定未来日期交付,这意味着我们可能不想将它们分配给最早的批次。一些 SKU 不在批次中,而是直接从供应商那里按需订购,因此它们具有不同的逻辑。根据客户的位置,我们只能分配给其地区内的一部分仓库和货运,除了一些 SKU,如果我们在本地区域缺货,我们可以从不同地区的仓库交付。等等。现实世界中的真实企业知道如何比我们在页面上展示的更快地增加复杂性!
但是,将这个简单的领域模型作为更复杂东西的占位符,我们将在本书的其余部分扩展我们简单的领域模型,并将其插入到 API 和数据库以及电子表格的真实世界中。我们将看到,严格遵守封装和谨慎分层的原则将帮助我们避免一团泥。
数据类非常适合值对象
在先前的代码列表中,我们大量使用了line,但是什么是 line?在我们的业务语言中,一个订单有多个行项目,每行都有一个 SKU 和数量。我们可以想象,一个包含订单信息的简单 YAML 文件可能如下所示:
订单信息作为 YAML
Order_reference: 12345
Lines:
- sku: RED-CHAIR
qty: 25
- sku: BLU-CHAIR
qty: 25
- sku: GRN-CHAIR
qty: 25
请注意,订单具有唯一标识它的引用,而线路没有。(即使我们将订单引用添加到OrderLine类中,它也不是唯一标识线路本身的东西。)
每当我们有一个具有数据但没有身份的业务概念时,我们通常选择使用价值对象模式来表示它。价值对象是任何由其持有的数据唯一标识的领域对象;我们通常使它们是不可变的:
OrderLine 是一个价值对象
@dataclass(frozen=True)
class OrderLine:
orderid: OrderReference
sku: ProductReference
qty: Quantity
数据类(或命名元组)给我们带来的一个好处是值相等,这是说“具有相同orderid、sku和qty的两行是相等的”这种花哨的方式。
价值对象的更多示例
from dataclasses import dataclass
from typing import NamedTuple
from collections import namedtuple
@dataclass(frozen=True)
class Name:
first_name: str
surname: str
class Money(NamedTuple):
currency: str
value: int
Line = namedtuple('Line', ['sku', 'qty'])
def test_equality():
assert Money('gbp', 10) == Money('gbp', 10)
assert Name('Harry', 'Percival') != Name('Bob', 'Gregory')
assert Line('RED-CHAIR', 5) == Line('RED-CHAIR', 5)
这些价值对象与我们对其值如何工作的现实世界直觉相匹配。讨论的是哪张10 英镑钞票并不重要,因为它们都有相同的价值。同样,如果名字的名和姓都匹配,两个名字是相等的;如果客户订单、产品代码和数量相同,两行是等价的。不过,我们仍然可以在价值对象上有复杂的行为。事实上,在值上支持操作是很常见的;例如,数学运算符:
使用价值对象进行数学运算
fiver = Money('gbp', 5)
tenner = Money('gbp', 10)
def can_add_money_values_for_the_same_currency():
assert fiver + fiver == tenner
def can_subtract_money_values():
assert tenner - fiver == fiver
def adding_different_currencies_fails():
with pytest.raises(ValueError):
Money('usd', 10) + Money('gbp', 10)
def can_multiply_money_by_a_number():
assert fiver * 5 == Money('gbp', 25)
def multiplying_two_money_values_is_an_error():
with pytest.raises(TypeError):
tenner * fiver
价值对象和实体
订单行通过其订单 ID、SKU 和数量唯一标识;如果我们更改其中一个值,现在我们有了一个新的行。这就是价值对象的定义:任何仅由其数据标识并且没有长期身份的对象。不过,批次呢?那是由一个引用标识的。
我们使用术语实体来描述具有长期身份的领域对象。在上一页中,我们介绍了Name类作为一个价值对象。如果我们把哈利·珀西瓦尔的名字改变一个字母,我们就得到了新的Name对象巴里·珀西瓦尔。
哈利·珀西瓦尔显然不等于巴里·珀西瓦尔:
名字本身是不能改变的…
def test_name_equality():
assert Name("Harry", "Percival") != Name("Barry", "Percival")
但是作为人的哈利呢?人们确实会改变他们的名字,婚姻状况,甚至性别,但我们仍然认为他们是同一个个体。这是因为人类,与名字不同,具有持久的身份:
但一个人可以!
class Person:
def __init__(self, name: Name):
self.name = name
def test_barry_is_harry():
harry = Person(Name("Harry", "Percival"))
barry = harry
barry.name = Name("Barry", "Percival")
assert harry is barry and barry is harry
实体,与值不同,具有身份相等。我们可以改变它们的值,它们仍然可以被识别为同一件事物。在我们的例子中,批次是实体。我们可以为批次分配线路,或更改我们期望它到达的日期,它仍然是同一个实体。
我们通常通过在实体上实现相等运算符来在代码中明确表示这一点:
实现相等运算符(model.py)
class Batch:
...
def __eq__(self, other):
if not isinstance(other, Batch):
return False
return other.reference == self.reference
def __hash__(self):
return hash(self.reference)
Python 的__eq__魔术方法定义了类在==运算符下的行为。⁵
对于实体和价值对象,思考__hash__的工作方式也很重要。这是 Python 用来控制对象在添加到集合或用作字典键时的行为的魔术方法;你可以在Python 文档中找到更多信息。
对于价值对象,哈希应该基于所有值属性,并且我们应该确保对象是不可变的。通过在数据类上指定@frozen=True,我们可以免费获得这一点。
对于实体,最简单的选择是说哈希是None,这意味着对象是不可哈希的,不能用于集合中。如果出于某种原因,你决定确实想要使用集合或字典操作与实体,哈希应该基于定义实体在一段时间内的唯一身份的属性(如.reference)。你还应该尝试以某种方式使那个属性只读。
警告
这是一个棘手的领域;你不应该修改__hash__而不修改__eq__。如果你不确定自己在做什么,建议进一步阅读。我们的技术审阅员 Hynek Schlawack 的“Python Hashes and Equality”是一个很好的起点。
并非所有的东西都必须是一个对象:领域服务函数
我们已经制作了一个表示批次的模型,但我们实际上需要做的是针对代表我们所有库存的特定一组批次分配订单行。
有时,这只是一种事情。
——Eric Evans,领域驱动设计
Evans 讨论了领域服务操作的概念,这些操作在实体或值对象中没有自然的归属地。⁶ 分配订单行的东西,给定一组批次,听起来很像一个函数,我们可以利用 Python 是一种多范式语言的事实,只需将其变成一个函数。
让我们看看如何测试驱动这样一个函数:
测试我们的领域服务(test_allocate.py)
def test_prefers_current_stock_batches_to_shipments():
in_stock_batch = Batch("in-stock-batch", "RETRO-CLOCK", 100, eta=None)
shipment_batch = Batch("shipment-batch", "RETRO-CLOCK", 100, eta=tomorrow)
line = OrderLine("oref", "RETRO-CLOCK", 10)
allocate(line, [in_stock_batch, shipment_batch])
assert in_stock_batch.available_quantity == 90
assert shipment_batch.available_quantity == 100
def test_prefers_earlier_batches():
earliest = Batch("speedy-batch", "MINIMALIST-SPOON", 100, eta=today)
medium = Batch("normal-batch", "MINIMALIST-SPOON", 100, eta=tomorrow)
latest = Batch("slow-batch", "MINIMALIST-SPOON", 100, eta=later)
line = OrderLine("order1", "MINIMALIST-SPOON", 10)
allocate(line, [medium, earliest, latest])
assert earliest.available_quantity == 90
assert medium.available_quantity == 100
assert latest.available_quantity == 100
def test_returns_allocated_batch_ref():
in_stock_batch = Batch("in-stock-batch-ref", "HIGHBROW-POSTER", 100, eta=None)
shipment_batch = Batch("shipment-batch-ref", "HIGHBROW-POSTER", 100, eta=tomorrow)
line = OrderLine("oref", "HIGHBROW-POSTER", 10)
allocation = allocate(line, [in_stock_batch, shipment_batch])
assert allocation == in_stock_batch.reference
我们的服务可能看起来像这样:
我们的领域服务的独立函数(model.py)
def allocate(line: OrderLine, batches: List[Batch]) -> str:
batch = next(
b for b in sorted(batches) if b.can_allocate(line)
)
batch.allocate(line)
return batch.reference
Python 的魔术方法让我们可以使用我们的模型与惯用的 Python
你可能会喜欢或不喜欢在前面的代码中使用next(),但我们非常确定你会同意在我们的批次列表上使用sorted()是很好的,符合 Python 的惯用法。
为了使其工作,我们在我们的领域模型上实现__gt__:
魔术方法可以表达领域语义(model.py)
class Batch:
...
def __gt__(self, other):
if self.eta is None:
return False
if other.eta is None:
return True
return self.eta > other.eta
太棒了。
异常也可以表达领域概念
我们还有一个最后的概念要涵盖:异常也可以用来表达领域概念。在与领域专家的对话中,我们了解到订单无法分配的可能性,因为我们缺货,我们可以通过使用领域异常来捕获这一点:
测试缺货异常(test_allocate.py)
def test_raises_out_of_stock_exception_if_cannot_allocate():
batch = Batch('batch1', 'SMALL-FORK', 10, eta=today)
allocate(OrderLine('order1', 'SMALL-FORK', 10), [batch])
with pytest.raises(OutOfStock, match='SMALL-FORK'):
allocate(OrderLine('order2', 'SMALL-FORK', 1), [batch])
我们不会让你对实现感到厌烦,但需要注意的主要事情是,我们在通用语言中命名我们的异常,就像我们对实体、值对象和服务一样:
引发领域异常(model.py)
class OutOfStock(Exception):
pass
def allocate(line: OrderLine, batches: List[Batch]) -> str:
try:
batch = next(
...
except StopIteration:
raise OutOfStock(f'Out of stock for sku {line.sku}')
图 1-4 是我们最终达到的视觉表示。

图 1-4:本章结束时的我们的领域模型
现在可能就够了!我们有一个可以用于我们的第一个用例的域服务。但首先我们需要一个数据库…
¹ DDD 并非起源于领域建模。Eric Evans 提到了 2002 年 Rebecca Wirfs-Brock 和 Alan McKean 的书Object Design(Addison-Wesley Professional),该书介绍了责任驱动设计,而 DDD 是处理领域的特殊情况。但即使如此,这也太晚了,OO 爱好者会告诉你要更进一步地回溯到 Ivar Jacobson 和 Grady Booch;这个术语自上世纪 80 年代中期就已经存在了。
² 在以前的 Python 版本中,我们可能会使用一个命名元组。您还可以查看 Hynek Schlawack 的优秀的attrs。
³ 或者也许你认为代码还不够?OrderLine中的 SKU 与Batch.sku匹配的某种检查呢?我们在附录 E 中保存了一些关于验证的想法。
⁴ 这太糟糕了。请,拜托,不要这样做。 ——Harry
⁵ __eq__方法的发音是“dunder-EQ”。至少有些人是这么说的。
⁶ 领域服务与服务层中的服务不是同一回事,尽管它们经常密切相关。领域服务代表了一个业务概念或流程,而服务层服务代表了应用程序的用例。通常,服务层将调用领域服务。
第二章:仓储模式
原文:2: Repository Pattern
译者:飞龙
协议:CC BY-NC-SA 4.0
是时候兑现我们使用依赖倒置原则来将核心逻辑与基础设施问题解耦的承诺了。
我们将引入仓储模式,这是对数据存储的简化抽象,允许我们将模型层与数据层解耦。我们将通过一个具体的例子来展示这种简化的抽象如何通过隐藏数据库的复杂性使我们的系统更具可测试性。
图 2-1 显示了我们将要构建的一个小预览:一个Repository对象,位于我们的领域模型和数据库之间。

图 2-1:仓储模式之前和之后
提示
本章的代码在 GitHub 的 chapter_02_repository 分支中。
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_02_repository
# or to code along, checkout the previous chapter:
git checkout chapter_01_domain_model
持久化我们的领域模型
在第一章中,我们构建了一个简单的领域模型,可以将订单分配给库存批次。我们很容易对这段代码编写测试,因为没有任何依赖或基础设施需要设置。如果我们需要运行数据库或 API 并创建测试数据,我们的测试将更难编写和维护。
不幸的是,我们总有一天需要把我们完美的小模型交到用户手中,并应对电子表格、Web 浏览器和竞争条件的现实世界。在接下来的几章中,我们将看看如何将我们理想化的领域模型连接到外部状态。
我们期望以敏捷的方式工作,因此我们的优先任务是尽快实现最小可行产品。在我们的情况下,这将是一个 Web API。在一个真实的项目中,你可能会直接进行一些端到端的测试,并开始插入一个 Web 框架,从外到内进行测试驱动。
但是我们知道,无论如何,我们都需要某种形式的持久存储,这是一本教科书,所以我们可以允许自己多一点自下而上的开发,并开始考虑存储和数据库。
一些伪代码:我们需要什么?
当我们构建我们的第一个 API 端点时,我们知道我们将会有一些看起来更或多少像以下的代码。
我们的第一个 API 端点将是什么样子
@flask.route.gubbins
def allocate_endpoint():
# extract order line from request
line = OrderLine(request.params, ...)
# load all batches from the DB
batches = ...
# call our domain service
allocate(line, batches)
# then save the allocation back to the database somehow
return 201
注意
我们使用 Flask 是因为它很轻量,但你不需要是 Flask 用户才能理解这本书。事实上,我们将向你展示如何使你选择的框架成为一个细节。
我们需要一种方法从数据库中检索批次信息,并从中实例化我们的领域模型对象,我们还需要一种将它们保存回数据库的方法。
什么?哦,“gubbins”是一个英国词,意思是“东西”。你可以忽略它。这是伪代码,好吗?
应用 DIP 到数据访问
如介绍中提到的,分层架构是一种常见的系统结构方法,该系统具有 UI、一些逻辑和数据库(见图 2-2)。
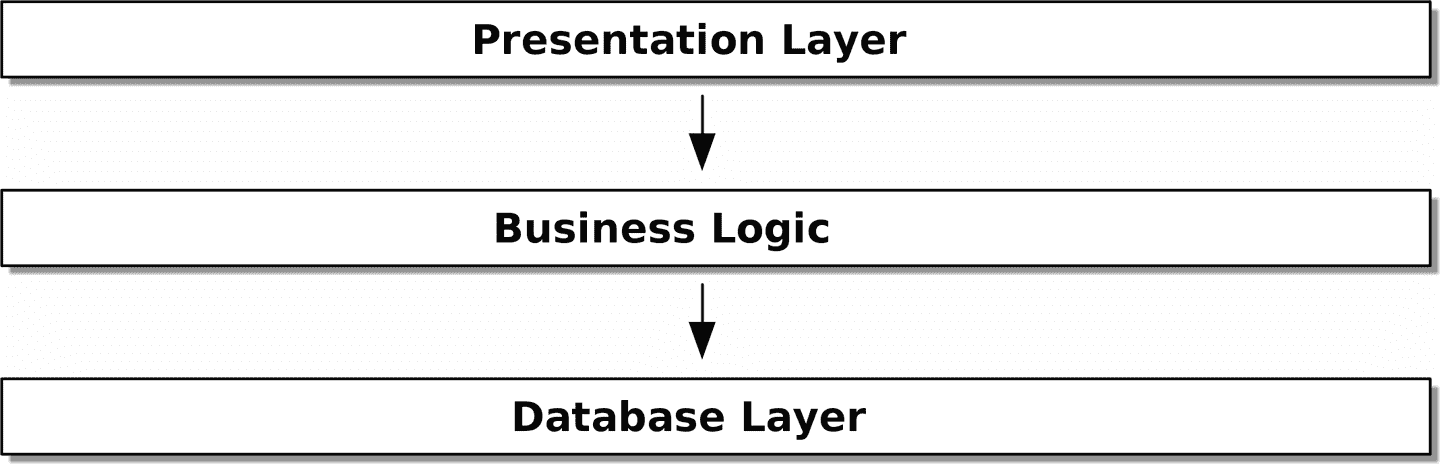
图 2-2:分层架构
Django 的模型-视图-模板结构是密切相关的,就像模型-视图-控制器(MVC)一样。无论如何,目标是保持各层分离(这是一件好事),并且使每一层仅依赖于其下面的一层。
但是我们希望我们的领域模型完全没有任何依赖。我们不希望基础设施问题渗入我们的领域模型,从而减慢我们的单元测试或我们进行更改的能力。
相反,正如在介绍中讨论的那样,我们将把我们的模型视为“内部”,并将依赖项向内流动;这就是人们有时称之为洋葱架构的东西(见图 2-3)。
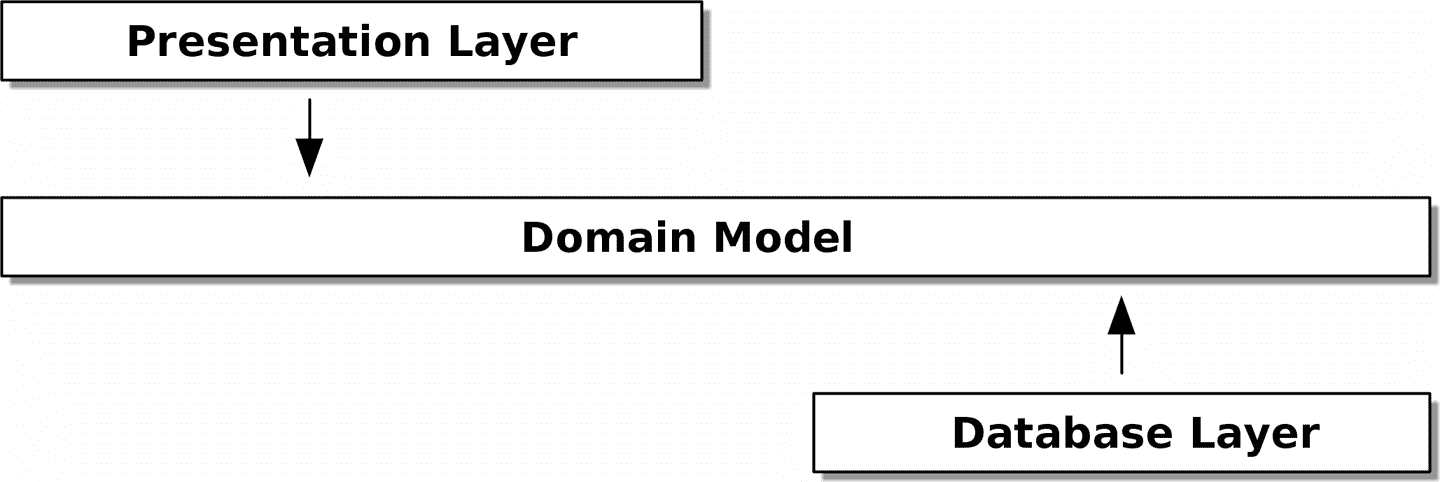
图 2-3:洋葱架构
[ditaa, apwp_0203]
+------------------------+
| Presentation Layer |
+------------------------+
|
V
+--------------------------------------------------+
| Domain Model |
+--------------------------------------------------+
^
|
+---------------------+
| Database Layer |
+---------------------+
提醒:我们的模型
让我们回顾一下我们的领域模型(见图 2-4):分配是将“OrderLine”链接到“Batch”的概念。我们将分配存储为我们“Batch”对象的集合。
图 2-4:我们的模型
让我们看看如何将其转换为关系数据库。
“正常”的 ORM 方式:模型依赖于 ORM
如今,您的团队成员不太可能手工编写自己的 SQL 查询。相反,您几乎肯定是在基于模型对象生成 SQL 的某种框架上使用。
这些框架被称为“对象关系映射器”(ORMs),因为它们存在的目的是弥合对象和领域建模世界与数据库和关系代数世界之间的概念差距。
ORM 给我们最重要的东西是“持久性无知”:即我们的精巧领域模型不需要知道如何加载或持久化数据。这有助于保持我们的领域不受特定数据库技术的直接依赖。³
但是,如果您遵循典型的 SQLAlchemy 教程,最终会得到类似于这样的东西:
SQLAlchemy 的“声明性”语法,模型依赖于 ORM(orm.py)
from sqlalchemy import Column, ForeignKey, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Order(Base):
id = Column(Integer, primary_key=True)
class OrderLine(Base):
id = Column(Integer, primary_key=True)
sku = Column(String(250))
qty = Integer(String(250))
order_id = Column(Integer, ForeignKey('order.id'))
order = relationship(Order)
class Allocation(Base):
...
您无需了解 SQLAlchemy 就能看到我们的原始模型现在充满了对 ORM 的依赖,并且看起来非常丑陋。我们真的能说这个模型对数据库一无所知吗?当我们的模型属性直接耦合到数据库列时,它怎么能与存储问题分离?
反转依赖关系:ORM 依赖于模型
幸运的是,这并不是使用 SQLAlchemy 的唯一方式。另一种方法是分别定义架构,并定义一个显式的映射器,用于在架构和我们的领域模型之间进行转换,SQLAlchemy 称之为经典映射:
使用 SQLAlchemy Table 对象显式 ORM 映射(orm.py)
from sqlalchemy.orm import mapper, relationship
import model #(1)
metadata = MetaData()
order_lines = Table( #(2)
"order_lines",
metadata,
Column("id", Integer, primary_key=True, autoincrement=True),
Column("sku", String(255)),
Column("qty", Integer, nullable=False),
Column("orderid", String(255)),
)
...
def start_mappers():
lines_mapper = mapper(model.OrderLine, order_lines) #(3)
①
ORM 导入(或“依赖”或“了解”)领域模型,而不是相反。
②
我们通过使用 SQLAlchemy 的抽象来定义我们的数据库表和列。⁴
③
当我们调用mapper函数时,SQLAlchemy 会通过其魔术将我们的领域模型类绑定到我们定义的各种表上。
最终结果将是,如果我们调用start_mappers,我们将能够轻松地从数据库加载和保存领域模型实例。但如果我们从未调用该函数,我们的领域模型类将幸福地不知道数据库的存在。
这为我们带来了 SQLAlchemy 的所有好处,包括能够使用alembic进行迁移,并且能够透明地使用我们的领域类进行查询,我们将会看到。
当您首次尝试构建 ORM 配置时,编写测试可能会很有用,如以下示例所示:
直接测试 ORM(一次性测试)(test_orm.py)
def test_orderline_mapper_can_load_lines(session): #(1)
session.execute(
"INSERT INTO order_lines (orderid, sku, qty) VALUES "
'("order1", "RED-CHAIR", 12),'
'("order1", "RED-TABLE", 13),'
'("order2", "BLUE-LIPSTICK", 14)'
)
expected = [
model.OrderLine("order1", "RED-CHAIR", 12),
model.OrderLine("order1", "RED-TABLE", 13),
model.OrderLine("order2", "BLUE-LIPSTICK", 14),
]
assert session.query(model.OrderLine).all() == expected
def test_orderline_mapper_can_save_lines(session):
new_line = model.OrderLine("order1", "DECORATIVE-WIDGET", 12)
session.add(new_line)
session.commit()
rows = list(session.execute('SELECT orderid, sku, qty FROM "order_lines"'))
assert rows == [("order1", "DECORATIVE-WIDGET", 12)]
①
如果您还没有使用 pytest,需要解释此测试的session参数。您无需担心 pytest 或其固定装置的细节,但简单的解释是,您可以将测试的常见依赖项定义为“固定装置”,pytest 将通过查看其函数参数将它们注入到需要它们的测试中。在这种情况下,它是一个 SQLAlchemy 数据库会话。
您可能不会保留这些测试,因为很快您将看到,一旦您采取了反转 ORM 和领域模型的步骤,实现另一个称为存储库模式的抽象只是一个小的额外步骤,这将更容易编写测试,并将为以后的测试提供一个简单的接口。
但我们已经实现了我们颠倒传统依赖的目标:领域模型保持“纯粹”并且不受基础设施问题的影响。我们可以放弃 SQLAlchemy 并使用不同的 ORM,或者完全不同的持久性系统,领域模型根本不需要改变。
根据您在领域模型中所做的工作,特别是如果您偏离 OO 范式,您可能会发现越来越难以使 ORM 产生您需要的确切行为,并且您可能需要修改您的领域模型。⁵就像经常发生的架构决策一样,您需要考虑权衡。正如 Python 之禅所说:“实用性胜过纯粹!”
不过,此时我们的 API 端点可能看起来像下面这样,并且我们可以让它正常工作:
在我们的 API 端点直接使用 SQLAlchemy
@flask.route.gubbins
def allocate_endpoint():
session = start_session()
# extract order line from request
line = OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
# load all batches from the DB
batches = session.query(Batch).all()
# call our domain service
allocate(line, batches)
# save the allocation back to the database
session.commit()
return 201
引入存储库模式
存储库模式是对持久性存储的抽象。它通过假装我们所有的数据都在内存中来隐藏数据访问的无聊细节。
如果我们的笔记本电脑有无限的内存,我们就不需要笨拙的数据库了。相反,我们可以随时使用我们的对象。那会是什么样子?
你必须从某处获取你的数据
import all_my_data
def create_a_batch():
batch = Batch(...)
all_my_data.batches.add(batch)
def modify_a_batch(batch_id, new_quantity):
batch = all_my_data.batches.get(batch_id)
batch.change_initial_quantity(new_quantity)
尽管我们的对象在内存中,但我们需要将它们放在某个地方,以便我们可以再次找到它们。我们的内存中的数据可以让我们添加新对象,就像列表或集合一样。因为对象在内存中,我们永远不需要调用.save()方法;我们只需获取我们关心的对象并在内存中修改它。
抽象中的存储库
最简单的存储库只有两种方法:add()用于将新项目放入存储库,get()用于返回先前添加的项目。⁶我们严格遵守在我们的领域和服务层中使用这些方法进行数据访问。这种自我施加的简单性阻止了我们将领域模型与数据库耦合。
这是我们存储库的抽象基类(ABC)会是什么样子:
最简单的存储库(repository.py)
class AbstractRepository(abc.ABC):
@abc.abstractmethod #(1)
def add(self, batch: model.Batch):
raise NotImplementedError #(2)
@abc.abstractmethod
def get(self, reference) -> model.Batch:
raise NotImplementedError
①
Python 提示:@abc.abstractmethod是 Python 中使抽象基类实际“工作”的少数几件事之一。Python 将拒绝让您实例化未实现其父类中定义的所有abstractmethods的类。⁷
②
raise NotImplementedError很好,但既不是必要的也不是充分的。实际上,如果您真的想要,您的抽象方法可以具有子类可以调用的真实行为。
这是一种权衡吗?
你知道他们说经济学家知道一切的价格,但对任何价值一无所知吗?嗯,程序员知道一切的好处,但对任何权衡一无所知。
——Rich Hickey
每当我们在本书中引入一个架构模式时,我们总是会问:“我们从中得到了什么?以及我们付出了什么代价?”
通常情况下,我们至少会引入一个额外的抽象层,尽管我们可能希望它会减少整体复杂性,但它确实会增加局部复杂性,并且在移动部件的原始数量和持续维护方面会有成本。
存储库模式可能是本书中最容易的选择之一,尽管如果您已经在走领域驱动设计和依赖反转的路线。就我们的代码而言,我们实际上只是将 SQLAlchemy 抽象(session.query(Batch))替换为我们设计的另一个抽象(batches_repo.get)。
每当我们添加一个新的领域对象想要检索时,我们将不得不在我们的存储库类中写入几行代码,但作为回报,我们得到了一个简单的抽象层,我们可以控制。存储库模式将使我们能够轻松地对存储方式进行根本性的更改(参见附录 C),正如我们将看到的,它很容易为单元测试伪造出来。
此外,存储库模式在 DDD 世界中是如此常见,以至于,如果你与从 Java 和 C#世界转到 Python 的程序员合作,他们可能会认识它。图 2-5 说明了这种模式。
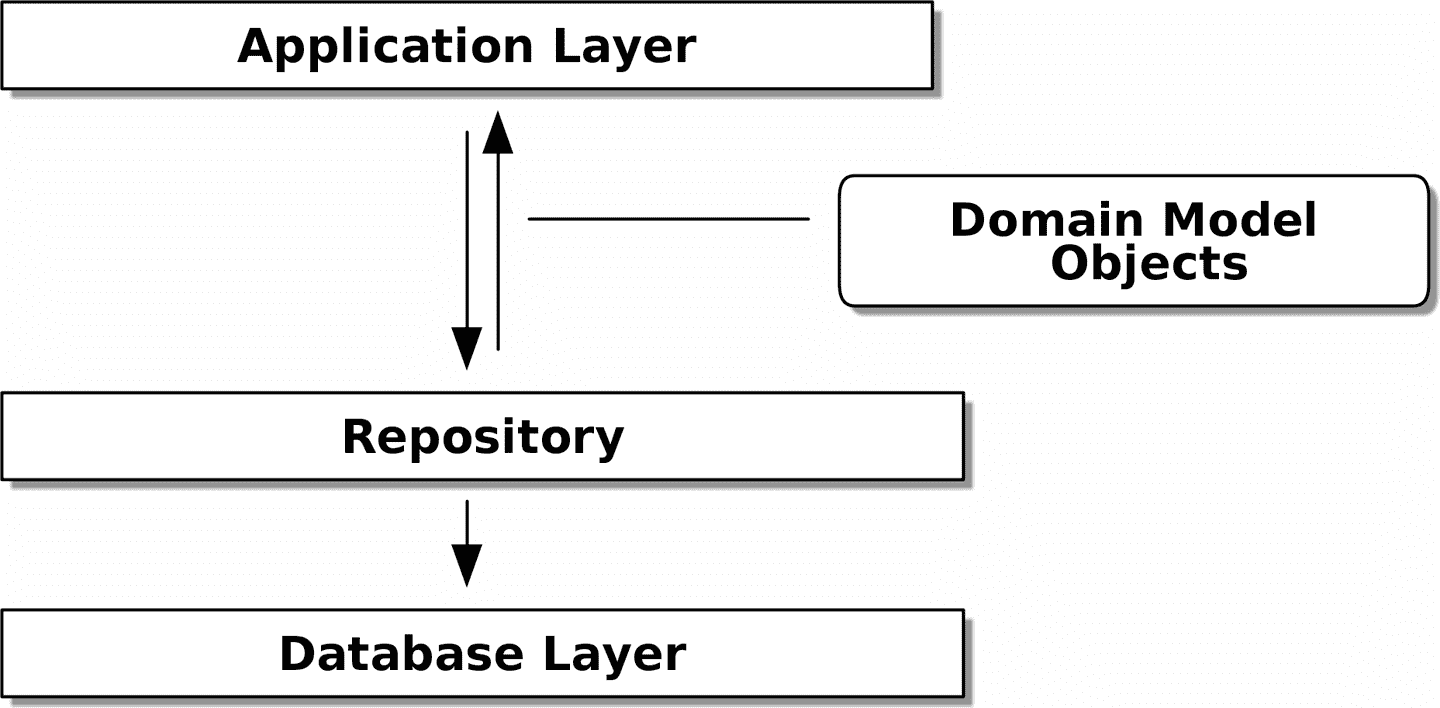
图 2-5:存储库模式
[ditaa, apwp_0205]
+-----------------------------+
| Application Layer |
+-----------------------------+
|^
|| /------------------\
||----------| Domain Model |
|| | Objects |
|| \------------------/
V|
+------------------------------+
| Repository |
+------------------------------+
|
V
+------------------------------+
| Database Layer |
+------------------------------+
与往常一样,我们从测试开始。这可能被归类为集成测试,因为我们正在检查我们的代码(存储库)是否与数据库正确集成;因此,测试往往会在我们自己的代码上混合原始 SQL 调用和断言。
提示
与之前的 ORM 测试不同,这些测试是长期留在代码库中的好选择,特别是如果领域模型的任何部分意味着对象关系映射是非平凡的。
保存对象的存储库测试(test_repository.py)
def test_repository_can_save_a_batch(session):
batch = model.Batch("batch1", "RUSTY-SOAPDISH", 100, eta=None)
repo = repository.SqlAlchemyRepository(session)
repo.add(batch) #(1)
session.commit() #(2)
rows = session.execute( #(3)
'SELECT reference, sku, _purchased_quantity, eta FROM "batches"'
)
assert list(rows) == [("batch1", "RUSTY-SOAPDISH", 100, None)]
①
repo.add()是这里测试的方法。
②
我们将.commit()放在存储库之外,并将其作为调用者的责任。这样做有利有弊;当我们到达第六章时,我们的一些原因将变得更加清晰。
③
我们使用原始 SQL 来验证已保存正确的数据。
下一个测试涉及检索批次和分配,所以它更复杂:
检索复杂对象的存储库测试(test_repository.py)
def insert_order_line(session):
session.execute( #(1)
"INSERT INTO order_lines (orderid, sku, qty)"
' VALUES ("order1", "GENERIC-SOFA", 12)'
)
[[orderline_id]] = session.execute(
"SELECT id FROM order_lines WHERE orderid=:orderid AND sku=:sku",
dict(orderid="order1", sku="GENERIC-SOFA"),
)
return orderline_id
def insert_batch(session, batch_id): #(2)
...
def test_repository_can_retrieve_a_batch_with_allocations(session):
orderline_id = insert_order_line(session)
batch1_id = insert_batch(session, "batch1")
insert_batch(session, "batch2")
insert_allocation(session, orderline_id, batch1_id) #(2)
repo = repository.SqlAlchemyRepository(session)
retrieved = repo.get("batch1")
expected = model.Batch("batch1", "GENERIC-SOFA", 100, eta=None)
assert retrieved == expected # Batch.__eq__ only compares reference #(3)
assert retrieved.sku == expected.sku #(4)
assert retrieved._purchased_quantity == expected._purchased_quantity
assert retrieved._allocations == { #(4)
model.OrderLine("order1", "GENERIC-SOFA", 12),
}
①
这些测试是读取方面的,因此原始 SQL 正在准备数据以供repo.get()读取。
②
我们将不详细介绍insert_batch和insert_allocation;重点是创建一对批次,并且对我们感兴趣的批次,有一个现有的订单行分配给它。
③
这就是我们在这里验证的。第一个assert ==检查类型是否匹配,并且引用是否相同(因为你记得,Batch是一个实体,我们为它有一个自定义的*eq*)。
④
因此,我们还明确检查它的主要属性,包括._allocations,它是OrderLine值对象的 Python 集合。
无论你是否费心为每个模型编写测试都是一个判断调用。一旦你为创建/修改/保存测试了一个类,你可能会很高兴地继续做其他类的最小往返测试,甚至什么都不做,如果它们都遵循相似的模式。在我们的情况下,设置._allocations集的 ORM 配置有点复杂,所以它值得一个特定的测试。
你最终会得到这样的东西:
典型的存储库(repository.py)
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, batch):
self.session.add(batch)
def get(self, reference):
return self.session.query(model.Batch).filter_by(reference=reference).one()
def list(self):
return self.session.query(model.Batch).all()
现在我们的 Flask 端点可能看起来像下面这样:
直接在 API 端点中使用我们的存储库
@flask.route.gubbins
def allocate_endpoint():
batches = SqlAlchemyRepository.list()
lines = [
OrderLine(l['orderid'], l['sku'], l['qty'])
for l in request.params...
]
allocate(lines, batches)
session.commit()
return 201
为测试构建一个假存储库现在变得轻而易举!
这是存储库模式最大的好处之一:
使用集合的简单假存储库(repository.py)
class FakeRepository(AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)
因为它是一个围绕set的简单包装器,所有方法都是一行代码。
在测试中使用假存储库真的很容易,而且我们有一个简单易用且易于理解的抽象:
假存储库的示例用法(test_api.py)
fake_repo = FakeRepository([batch1, batch2, batch3])
你将在下一章中看到这个假存储库的实际应用。
提示
为你的抽象构建假对象是获得设计反馈的一个绝佳方式:如果很难伪造,那么这个抽象可能太复杂了。
什么是端口,什么是适配器,在 Python 中?
我们不想在这里过多地纠缠术语,因为我们想要专注于依赖反转,您使用的技术的具体细节并不太重要。此外,我们知道不同的人使用略有不同的定义。
端口和适配器来自 OO 世界,我们坚持的定义是端口是我们的应用程序与我们希望抽象的任何东西之间的接口,适配器是该接口或抽象背后的实现。
现在 Python 本身没有接口,因此虽然通常很容易识别适配器,但定义端口可能更难。如果您使用抽象基类,那就是端口。如果没有,端口就是您的适配器符合并且您的核心应用程序期望的鸭子类型——使用的函数和方法名称,以及它们的参数名称和类型。
具体来说,在本章中,AbstractRepository是端口,SqlAlchemyRepository和FakeRepository是适配器。
总结
牢记 Rich Hickey 的话,在每一章中,我们总结介绍的每种架构模式的成本和收益。我们想要明确的是,我们并不是说每个应用程序都需要以这种方式构建;只有在应用程序和领域的复杂性使得值得投入时间和精力来添加这些额外的间接层时,才会这样。
考虑到这一点,表 2-1 显示了存储库模式和我们的持久性无关模型的一些优缺点。
表 2-1. 存储库模式和持久性无知:权衡
| 优点 | 缺点 |
|---|---|
| 我们在持久存储和我们的领域模型之间有一个简单的接口。 | ORM 已经为您购买了一些解耦。更改外键可能很困难,但如果有必要,应该很容易在 MySQL 和 Postgres 之间进行切换。 |
| 很容易为单元测试制作存储库的虚假版本,或者交换不同的存储解决方案,因为我们已经完全将模型与基础设施问题解耦。 | 手动维护 ORM 映射需要额外的工作和额外的代码。 |
| 在考虑持久性之前编写领域模型有助于我们专注于手头的业务问题。如果我们想要彻底改变我们的方法,我们可以在模型中做到这一点,而无需担心外键或迁移直到以后。 | 任何额外的间接层都会增加维护成本,并为以前从未见过存储库模式的 Python 程序员增加“WTF 因素”。 |
| 我们的数据库模式非常简单,因为我们完全控制了如何将对象映射到表。 |
图 2-6 显示了基本的论点:是的,对于简单情况,解耦的领域模型比简单的 ORM/ActiveRecord 模式更难工作。⁸
提示
如果您的应用程序只是一个简单的围绕数据库的 CRUD(创建-读取-更新-删除)包装器,那么您不需要领域模型或存储库。
但是,领域越复杂,从基础设施问题中解放自己的投资将在进行更改方面产生更大的回报。
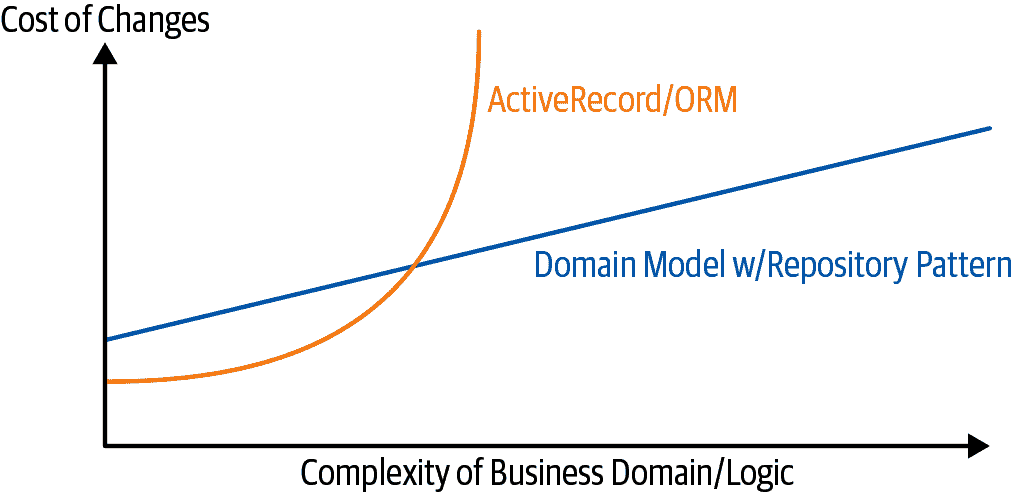
图 2-6. 领域模型权衡的图表
[ditaa, apwp_0206]
Cost of Changes
^ /
| ActiveRecord/ORM |
| | ----/
| / ----/
| | ----/
| / ----/
| | ----/ Domain model w/ Repository pattern
| / ----/
| | ----/
| ----/
| ----/ /
| ----/ /
| ----/ -/
|----/ --/
| ---/
| ----/
|------/
|
+--------------------------------------------------------------->
Complexity of business domain/logic
我们的示例代码并不复杂,无法给出图表右侧的更多提示,但提示已经存在。例如,想象一下,如果有一天我们决定要将分配更改为存在于OrderLine而不是Batch对象上:如果我们正在使用 Django,我们必须在运行任何测试之前定义并思考数据库迁移。因为我们的模型只是普通的 Python 对象,所以我们可以将set()更改为一个新属性,而无需考虑数据库直到以后。
你可能会想,我们如何实例化这些存储库,是虚拟的还是真实的?我们的 Flask 应用实际上会是什么样子?在下一个激动人心的部分中,服务层模式中会有答案。
但首先,让我们稍作偏离一下。
¹ 我想我们的意思是“不依赖有状态的依赖关系”。依赖于辅助库是可以的;依赖 ORM 或 Web 框架则不行。
² Mark Seemann 在这个主题上有一篇优秀的博客文章。
³ 从这个意义上讲,使用 ORM 已经是 DIP 的一个例子。我们不依赖硬编码的 SQL,而是依赖于 ORM 这种抽象。但对我们来说还不够——至少在这本书中不够!
⁴ 即使在我们不使用 ORM 的项目中,我们经常会在 Python 中使用 SQLAlchemy 和 Alembic 来声明性地创建模式,并管理迁移、连接和会话。
⁵ 向 SQLAlchemy 的维护者表示感谢,特别是向 Mike Bayer 表示感谢。
⁶ 你可能会想,“那list或delete或update呢?”然而,在理想的世界中,我们一次修改一个模型对象,删除通常是以软删除的方式处理——即batch.cancel()。最后,更新由工作单元模式处理,你将在第六章中看到。
⁷ 要真正享受 ABCs(尽管它们可能如此),请运行诸如pylint和mypy之类的辅助工具。
⁸ 图表灵感来自 Rob Vens 的一篇名为“全局复杂性,本地简单性”的帖子。
第三章:简短插曲:耦合和抽象
原文:3: A Brief Interlude: On Coupling and Abstractions
译者:飞龙
协议:CC BY-NC-SA 4.0
请允许我们在抽象主题上稍作偏离,亲爱的读者。我们已经谈论了抽象很多。例如,存储库模式是对永久存储的抽象。但是什么样的抽象才是好的?我们从抽象中想要什么?它们与测试有什么关系?
提示
本章的代码在 GitHub 的 chapter_03_abstractions 分支中链接:
git clone https://github.com/cosmicpython/code.git
git checkout chapter_03_abstractions
本书的一个关键主题,隐藏在花哨的模式中,是我们可以使用简单的抽象来隐藏混乱的细节。当我们写代码时,可以自由地玩耍,或者在一个 kata 中,我们可以自由地玩耍,大幅度地重构。然而,在大规模系统中,我们受到系统其他地方做出的决定的限制。
当我们因为担心破坏组件 B 而无法更改组件 A 时,我们说这些组件已经耦合。在本地,耦合是一件好事:这表明我们的代码正在一起工作,每个组件都在支持其他组件,所有这些组件都像手表的齿轮一样完美地配合在一起。在行话中,我们说当耦合元素之间存在高内聚时,这是有效的。
总体上,耦合是一种麻烦事:它增加了更改代码的风险和成本,有时甚至到了我们感到无法进行任何更改的地步。这就是“泥球”模式的问题:随着应用程序的增长,如果我们无法阻止没有内聚力的元素之间的耦合,那么耦合会超线性地增加,直到我们无法有效地更改我们的系统。
我们可以通过将细节抽象化(图 3-1)来减少系统内的耦合程度。

图 3-1:耦合很多
[ditaa,apwp_0301]
+--------+ +--------+
| System | ---> | System |
| A | ---> | B |
| | ---> | |
| | ---> | |
| | ---> | |
+--------+ +--------+

图 3-2:耦合减少
[ditaa,apwp_0302]
+--------+ +--------+
| System | /-------------\ | System |
| A | ---> | | ---> | B |
| | ---> | Abstraction | ---> | |
| | | | ---> | |
| | \-------------/ | |
+--------+ +--------+
在这两个图中,我们有一对子系统,其中一个依赖于另一个。在图 3-1 中,两者之间存在高度耦合;箭头的数量表示两者之间有很多种依赖关系。如果我们需要更改系统 B,很可能这种更改会传播到系统 A。
然而,在图 3-2 中,我们通过插入一个新的、更简单的抽象来减少耦合程度。因为它更简单,系统 A 对抽象的依赖种类更少。抽象用于保护我们免受变化的影响,它隐藏了系统 B 的复杂细节——我们可以在不更改左侧箭头的情况下更改右侧的箭头。
抽象状态辅助测试
让我们看一个例子。想象一下,我们想要编写代码来同步两个文件目录,我们将其称为源和目标:
-
如果源中存在文件,但目标中不存在文件,则复制文件。
-
如果源文件存在,但与目标文件名不同,则将目标文件重命名为匹配的文件。
-
如果目标中存在文件,但源中不存在文件,则删除它。
我们的第一个和第三个要求都很简单:我们只需比较两个路径列表。但是我们的第二个要求就比较棘手了。为了检测重命名,我们将不得不检查文件的内容。为此,我们可以使用 MD5 或 SHA-1 等哈希函数。从文件生成 SHA-1 哈希的代码非常简单:
对文件进行哈希(sync.py)
BLOCKSIZE = 65536
def hash_file(path):
hasher = hashlib.sha1()
with path.open("rb") as file:
buf = file.read(BLOCKSIZE)
while buf:
hasher.update(buf)
buf = file.read(BLOCKSIZE)
return hasher.hexdigest()
现在我们需要编写决定要做什么的部分——商业逻辑,如果你愿意的话。
当我们必须从第一原则解决问题时,通常我们会尝试编写一个简单的实现,然后朝着更好的设计进行重构。我们将在整本书中使用这种方法,因为这是我们在现实世界中编写代码的方式:从问题的最小部分开始解决方案,然后迭代地使解决方案更加丰富和更好设计。
我们的第一个 hackish 方法看起来是这样的:
基本同步算法(sync.py)
import hashlib
import os
import shutil
from pathlib import Path
def sync(source, dest):
# Walk the source folder and build a dict of filenames and their hashes
source_hashes = {}
for folder, _, files in os.walk(source):
for fn in files:
source_hashes[hash_file(Path(folder) / fn)] = fn
seen = set() # Keep track of the files we've found in the target
# Walk the target folder and get the filenames and hashes
for folder, _, files in os.walk(dest):
for fn in files:
dest_path = Path(folder) / fn
dest_hash = hash_file(dest_path)
seen.add(dest_hash)
# if there's a file in target that's not in source, delete it
if dest_hash not in source_hashes:
dest_path.remove()
# if there's a file in target that has a different path in source,
# move it to the correct path
elif dest_hash in source_hashes and fn != source_hashes[dest_hash]:
shutil.move(dest_path, Path(folder) / source_hashes[dest_hash])
# for every file that appears in source but not target, copy the file to
# the target
for src_hash, fn in source_hashes.items():
if src_hash not in seen:
shutil.copy(Path(source) / fn, Path(dest) / fn)
太棒了!我们有一些代码,它看起来不错,但在我们在硬盘上运行它之前,也许我们应该测试一下。我们如何测试这种类型的东西?
一些端到端测试(test_sync.py)
def test_when_a_file_exists_in_the_source_but_not_the_destination():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "I am a very useful file"
(Path(source) / 'my-file').write_text(content)
sync(source, dest)
expected_path = Path(dest) / 'my-file'
assert expected_path.exists()
assert expected_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
def test_when_a_file_has_been_renamed_in_the_source():
try:
source = tempfile.mkdtemp()
dest = tempfile.mkdtemp()
content = "I am a file that was renamed"
source_path = Path(source) / 'source-filename'
old_dest_path = Path(dest) / 'dest-filename'
expected_dest_path = Path(dest) / 'source-filename'
source_path.write_text(content)
old_dest_path.write_text(content)
sync(source, dest)
assert old_dest_path.exists() is False
assert expected_dest_path.read_text() == content
finally:
shutil.rmtree(source)
shutil.rmtree(dest)
哇哦,为了两个简单的情况需要做很多设置!问题在于我们的领域逻辑,“找出两个目录之间的差异”,与 I/O 代码紧密耦合。我们无法在不调用pathlib、shutil和hashlib模块的情况下运行我们的差异算法。
问题是,即使在当前的要求下,我们还没有编写足够的测试:当前的实现存在一些错误(例如shutil.move()是错误的)。获得良好的覆盖率并揭示这些错误意味着编写更多的测试,但如果它们都像前面的测试一样难以管理,那将会变得非常痛苦。
除此之外,我们的代码并不是很可扩展。想象一下,试图实现一个--dry-run标志,让我们的代码只是打印出它将要做的事情,而不是实际去做。或者,如果我们想要同步到远程服务器或云存储呢?
我们的高级代码与低级细节耦合在一起,这让生活变得困难。随着我们考虑的场景变得更加复杂,我们的测试将变得更加难以管理。我们肯定可以重构这些测试(例如,一些清理工作可以放入 pytest fixtures 中),但只要我们进行文件系统操作,它们就会保持缓慢,并且难以阅读和编写。
选择正确的抽象
我们能做些什么来重写我们的代码,使其更具可测试性?
首先,我们需要考虑我们的代码需要文件系统提供什么。通过阅读代码,我们可以看到三个不同的事情正在发生。我们可以将这些视为代码具有的三个不同责任:
-
我们通过使用
os.walk来询问文件系统,并为一系列路径确定哈希值。这在源和目标情况下都是相似的。 -
我们决定文件是新的、重命名的还是多余的。
-
我们复制、移动或删除文件以匹配源。
记住,我们希望为这些责任中的每一个找到简化的抽象。这将让我们隐藏混乱的细节,以便我们可以专注于有趣的逻辑。²
注意
在本章中,我们通过识别需要完成的各个任务并将每个任务分配给一个明确定义的执行者,按照类似于“duckduckgo”示例的方式,将一些混乱的代码重构为更具可测试性的结构。
对于步骤 1 和步骤 2,我们已经直观地开始使用一个抽象,即哈希到路径的字典。您可能已经在想,“为什么不为目标文件夹构建一个字典,然后我们只需比较两个字典?”这似乎是一种很好的抽象文件系统当前状态的方式:
source_files = {'hash1': 'path1', 'hash2': 'path2'}
dest_files = {'hash1': 'path1', 'hash2': 'pathX'}
那么,我们如何从第 2 步移动到第 3 步呢?我们如何将实际的移动/复制/删除文件系统交互抽象出来?
我们将在这里应用一个技巧,我们将在本书的后面大规模地使用。我们将想要做什么与如何做分开。我们将使我们的程序输出一个看起来像这样的命令列表:
("COPY", "sourcepath", "destpath"),
("MOVE", "old", "new"),
现在我们可以编写测试,只使用两个文件系统字典作为输入,并且我们期望输出表示操作的字符串元组列表。
我们不是说,“给定这个实际的文件系统,当我运行我的函数时,检查发生了什么操作”,而是说,“给定这个文件系统的抽象,会发生什么文件系统操作的抽象?”
我们的测试中简化了输入和输出(test_sync.py)
def test_when_a_file_exists_in_the_source_but_not_the_destination():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {}
expected_actions = [('COPY', '/src/fn1', '/dst/fn1')]
...
def test_when_a_file_has_been_renamed_in_the_source():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {'hash1': 'fn2'}
expected_actions == [('MOVE', '/dst/fn2', '/dst/fn1')]
...
实现我们选择的抽象
这一切都很好,但我们实际上如何编写这些新测试,以及如何改变我们的实现使其正常工作?
我们的目标是隔离系统的聪明部分,并且能够彻底测试它,而不需要设置真实的文件系统。我们将创建一个“核心”代码,它不依赖外部状态,然后看看当我们从外部世界输入时它如何响应(这种方法被 Gary Bernhardt 称为Functional Core, Imperative Shell,或 FCIS)。
让我们从将代码分离出有状态的部分和逻辑开始。
我们的顶层函数几乎不包含任何逻辑;它只是一系列命令式的步骤:收集输入,调用我们的逻辑,应用输出:
将我们的代码分成三部分(sync.py)
def sync(source, dest):
# imperative shell step 1, gather inputs
source_hashes = read_paths_and_hashes(source) #(1)
dest_hashes = read_paths_and_hashes(dest) #(1)
# step 2: call functional core
actions = determine_actions(source_hashes, dest_hashes, source, dest) #(2)
# imperative shell step 3, apply outputs
for action, *paths in actions:
if action == "COPY":
shutil.copyfile(*paths)
if action == "MOVE":
shutil.move(*paths)
if action == "DELETE":
os.remove(paths[0])
①
这是我们分解的第一个函数,read_paths_and_hashes(),它隔离了我们应用程序的 I/O 部分。
②
这是我们切出功能核心,业务逻辑的地方。
构建路径和哈希字典的代码现在非常容易编写:
只执行 I/O 的函数(sync.py)
def read_paths_and_hashes(root):
hashes = {}
for folder, _, files in os.walk(root):
for fn in files:
hashes[hash_file(Path(folder) / fn)] = fn
return hashes
determine_actions()函数将是我们业务逻辑的核心,它说:“给定这两组哈希和文件名,我们应该复制/移动/删除什么?”。它接受简单的数据结构并返回简单的数据结构:
只执行业务逻辑的函数(sync.py)
def determine_actions(src_hashes, dst_hashes, src_folder, dst_folder):
for sha, filename in src_hashes.items():
if sha not in dst_hashes:
sourcepath = Path(src_folder) / filename
destpath = Path(dst_folder) / filename
yield 'copy', sourcepath, destpath
elif dst_hashes[sha] != filename:
olddestpath = Path(dst_folder) / dst_hashes[sha]
newdestpath = Path(dst_folder) / filename
yield 'move', olddestpath, newdestpath
for sha, filename in dst_hashes.items():
if sha not in src_hashes:
yield 'delete', dst_folder / filename
我们的测试现在直接作用于determine_actions()函数:
更好看的测试(test_sync.py)
def test_when_a_file_exists_in_the_source_but_not_the_destination():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {}
actions = determine_actions(src_hashes, dst_hashes, Path('/src'), Path('/dst'))
assert list(actions) == [('copy', Path('/src/fn1'), Path('/dst/fn1'))]
...
def test_when_a_file_has_been_renamed_in_the_source():
src_hashes = {'hash1': 'fn1'}
dst_hashes = {'hash1': 'fn2'}
actions = determine_actions(src_hashes, dst_hashes, Path('/src'), Path('/dst'))
assert list(actions) == [('move', Path('/dst/fn2'), Path('/dst/fn1'))]
因为我们已经将程序的逻辑——识别更改的代码——与 I/O 的低级细节分离开来,我们可以轻松测试我们代码的核心部分。
通过这种方法,我们已经从测试我们的主入口函数sync(),转而测试更低级的函数determine_actions()。您可能会认为这没问题,因为sync()现在非常简单。或者您可能决定保留一些集成/验收测试来测试sync()。但还有另一种选择,那就是修改sync()函数,使其既可以进行单元测试又可以进行端到端测试;这是 Bob 称之为边缘到边缘测试的方法。
使用伪造和依赖注入进行边缘到边缘测试
当我们开始编写新系统时,我们经常首先关注核心逻辑,通过直接的单元测试驱动它。不过,某个时候,我们希望一起测试系统的更大块。
我们可以回到端到端测试,但这些仍然像以前一样难以编写和维护。相反,我们经常编写调用整个系统但伪造 I/O 的测试,有点边缘到边缘*:
显式依赖项(sync.py)
def sync(source, dest, filesystem=FileSystem()): #(1)
source_hashes = filesystem.read(source) #(2)
dest_hashes = filesystem.read(dest) #(2)
for sha, filename in source_hashes.items():
if sha not in dest_hashes:
sourcepath = Path(source) / filename
destpath = Path(dest) / filename
filesystem.copy(sourcepath, destpath) #(3)
elif dest_hashes[sha] != filename:
olddestpath = Path(dest) / dest_hashes[sha]
newdestpath = Path(dest) / filename
filesystem.move(olddestpath, newdestpath) #(3)
for sha, filename in dest_hashes.items():
if sha not in source_hashes:
filesystem.delete(dest / filename) #(3)
①
我们的顶层函数现在公开了两个新的依赖项,一个reader和一个filesystem。
②
我们调用reader来生成我们的文件字典。
③
我们调用filesystem来应用我们检测到的更改。
提示
虽然我们正在使用依赖注入,但没有必要定义抽象基类或任何明确的接口。在本书中,我们经常展示 ABCs,因为我们希望它们能帮助您理解抽象是什么,但它们并不是必需的。Python 的动态特性意味着我们总是可以依赖鸭子类型。
使用 DI 的测试
class FakeFilesystem:
def __init__(self, path_hashes): #(1)
self.path_hashes = path_hashes
self.actions = [] #(2)
def read(self, path):
return self.path_hashes[path] #(1)
def copy(self, source, dest):
self.actions.append(('COPY', source, dest)) #(2)
def move(self, source, dest):
self.actions.append(('MOVE', source, dest)) #(2)
def delete(self, dest):
self.actions.append(('DELETE', dest)) #(2)
①
Bob 非常喜欢使用列表来构建简单的测试替身,尽管他的同事们会生气。这意味着我们可以编写像assert *foo* not in database这样的测试。
②
我们FakeFileSystem中的每个方法都只是将一些内容附加到列表中,以便我们以后可以检查它。这是间谍对象的一个例子。
这种方法的优势在于我们的测试作用于与我们的生产代码使用的完全相同的函数。缺点是我们必须明确地表达我们的有状态组件并传递它们。Ruby on Rails 的创始人 David Heinemeier Hansson 曾经著名地将这描述为“测试诱导的设计损害”。
无论哪种情况,我们现在都可以着手修复实现中的所有错误;为所有边缘情况列举测试现在变得更容易了。
为什么不只是补丁?
在这一点上,你可能会挠头想,“为什么你不只是使用mock.patch,省点力气呢?”
我们在本书和我们的生产代码中都避免使用模拟。我们不会卷入圣战,但我们的直觉是,模拟框架,特别是 monkeypatching,是一种代码异味。
相反,我们喜欢清楚地确定代码库中的责任,并将这些责任分离成小而专注的对象,这些对象易于用测试替身替换。
注意
你可以在第八章中看到一个例子,我们在那里使用mock.patch()来替换一个发送电子邮件的模块,但最终我们在第十三章中用显式的依赖注入替换了它。
我们对我们的偏好有三个密切相关的原因:
-
消除你正在使用的依赖关系,可以对代码进行单元测试,但这对改进设计没有任何帮助。使用
mock.patch不会让你的代码与--dry-run标志一起工作,也不会帮助你针对 FTP 服务器运行。为此,你需要引入抽象。 -
使用模拟测试的测试倾向于更多地与代码库的实现细节耦合。这是因为模拟测试验证了事物之间的交互:我们是否用正确的参数调用了
shutil.copy?根据我们的经验,代码和测试之间的这种耦合倾向于使测试更加脆弱。 -
过度使用模拟会导致复杂的测试套件,无法解释代码。
注意
为可测试性而设计实际上意味着为可扩展性而设计。我们为了更清晰的设计而进行了一些复杂性的折衷,这样可以容纳新的用例。
我们首先将 TDD 视为一种设计实践,其次是一种测试实践。测试作为我们设计选择的记录,并在我们长时间离开代码后为我们解释系统的作用。
使用太多模拟的测试会被隐藏在设置代码中,这些设置代码隐藏了我们关心的故事。
Steve Freeman 在他的演讲“测试驱动开发”中有一个很好的过度模拟测试的例子。你还应该看看这个 PyCon 演讲,“Mocking and Patching Pitfalls”,由我们尊敬的技术审阅人员 Ed Jung 进行,其中也涉及了模拟和其替代方案。还有,我们推荐的演讲,不要错过 Brandon Rhodes 关于“提升你的 I/O”的讲解,他用另一个简单的例子很好地涵盖了我们正在讨论的问题。
提示
在本章中,我们花了很多时间用单元测试替换端到端测试。这并不意味着我们认为你永远不应该使用端到端测试!在本书中,我们展示了一些技术,让你尽可能地获得一个体面的测试金字塔,并且尽可能少地需要端到端测试来获得信心。继续阅读“总结:不同类型测试的经验法则”以获取更多细节。
总结
我们将在本书中一再看到这个想法:通过简化业务逻辑和混乱的 I/O 之间的接口,我们可以使我们的系统更容易测试和维护。找到合适的抽象是棘手的,但以下是一些启发和问题,你可以问问自己:
-
我可以选择一个熟悉的 Python 数据结构来表示混乱系统的状态,然后尝试想象一个可以返回该状态的单个函数吗?
-
我在哪里可以在我的系统中划出一条线,在哪里可以开辟一个接缝来放置这个抽象?
-
将事物划分为具有不同责任的组件的合理方式是什么?我可以将隐含的概念变得明确吗?
-
有哪些依赖关系,什么是核心业务逻辑?
练习使不完美减少!现在回到我们的常规编程…
¹ 代码卡塔是一个小的、独立的编程挑战,通常用于练习 TDD。请参阅 Peter Provost 的《Kata—The Only Way to Learn TDD》。
² 如果你习惯以接口的方式思考,那么这就是我们在这里尝试定义的内容。
³ 这并不是说我们认为伦敦学派的人是错的。一些非常聪明的人就是这样工作的。只是我们不习惯这种方式。
第四章:我们的第一个用例:Flask API 和服务层
原文:4: Our First Use Case: Flask API and Service Layer
译者:飞龙
协议:CC BY-NC-SA 4.0
回到我们的分配项目!图 4-1 显示了我们在第二章结束时达到的点,该章节涵盖了存储库模式。
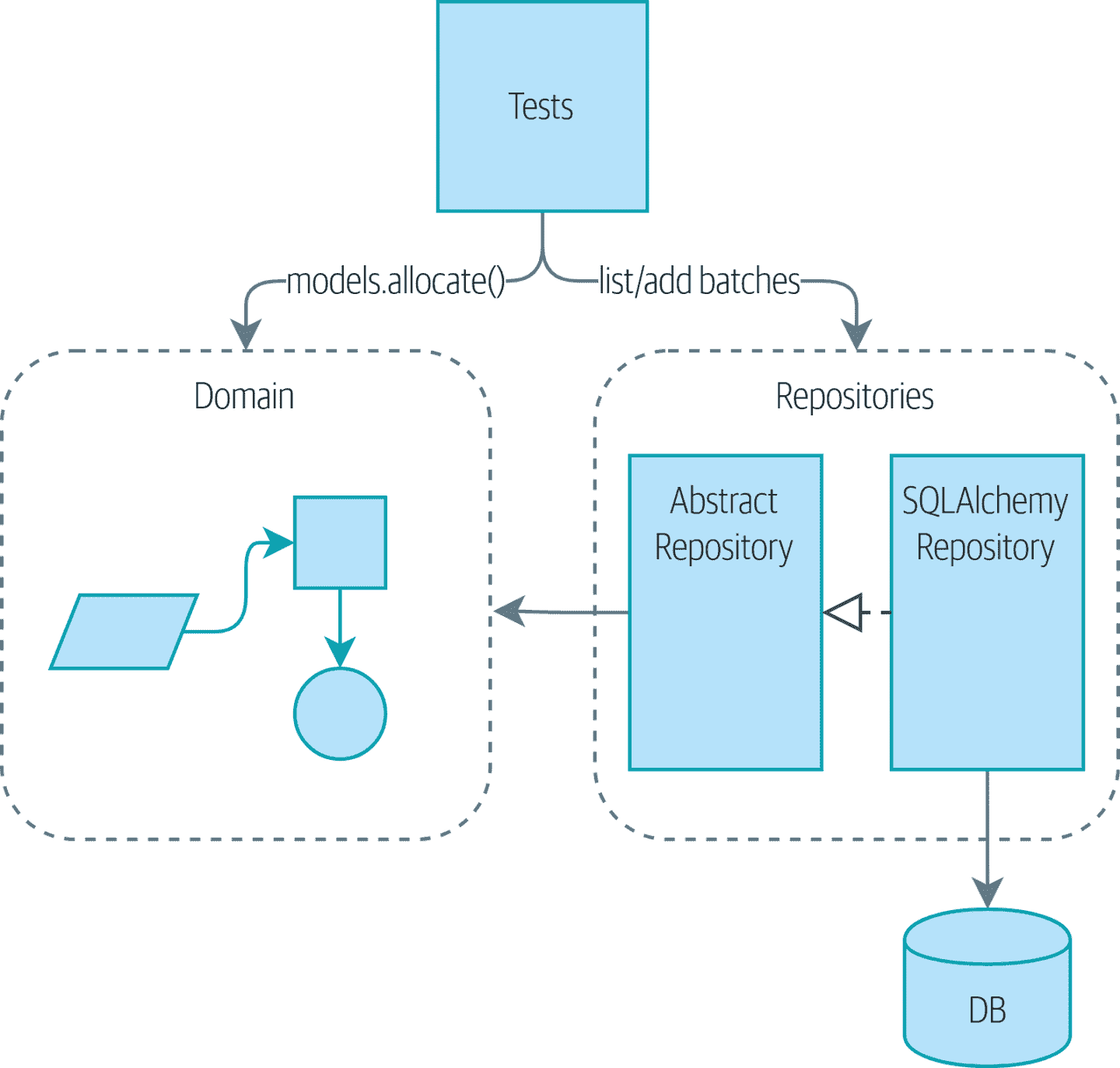
图 4-1:之前:我们通过与存储库和领域模型交谈来驱动我们的应用程序
在本章中,我们将讨论编排逻辑、业务逻辑和接口代码之间的区别,并介绍服务层模式来处理编排我们的工作流程并定义我们系统的用例。
我们还将讨论测试:通过将服务层与我们对数据库的存储库抽象结合起来,我们能够编写快速测试,不仅测试我们的领域模型,还测试整个用例的工作流程。
图 4-2 显示我们的目标:我们将添加一个 Flask API,它将与服务层交互,服务层将作为我们领域模型的入口。因为我们的服务层依赖于AbstractRepository,我们可以使用FakeRepository对其进行单元测试,但在生产代码中使用SqlAlchemyRepository。
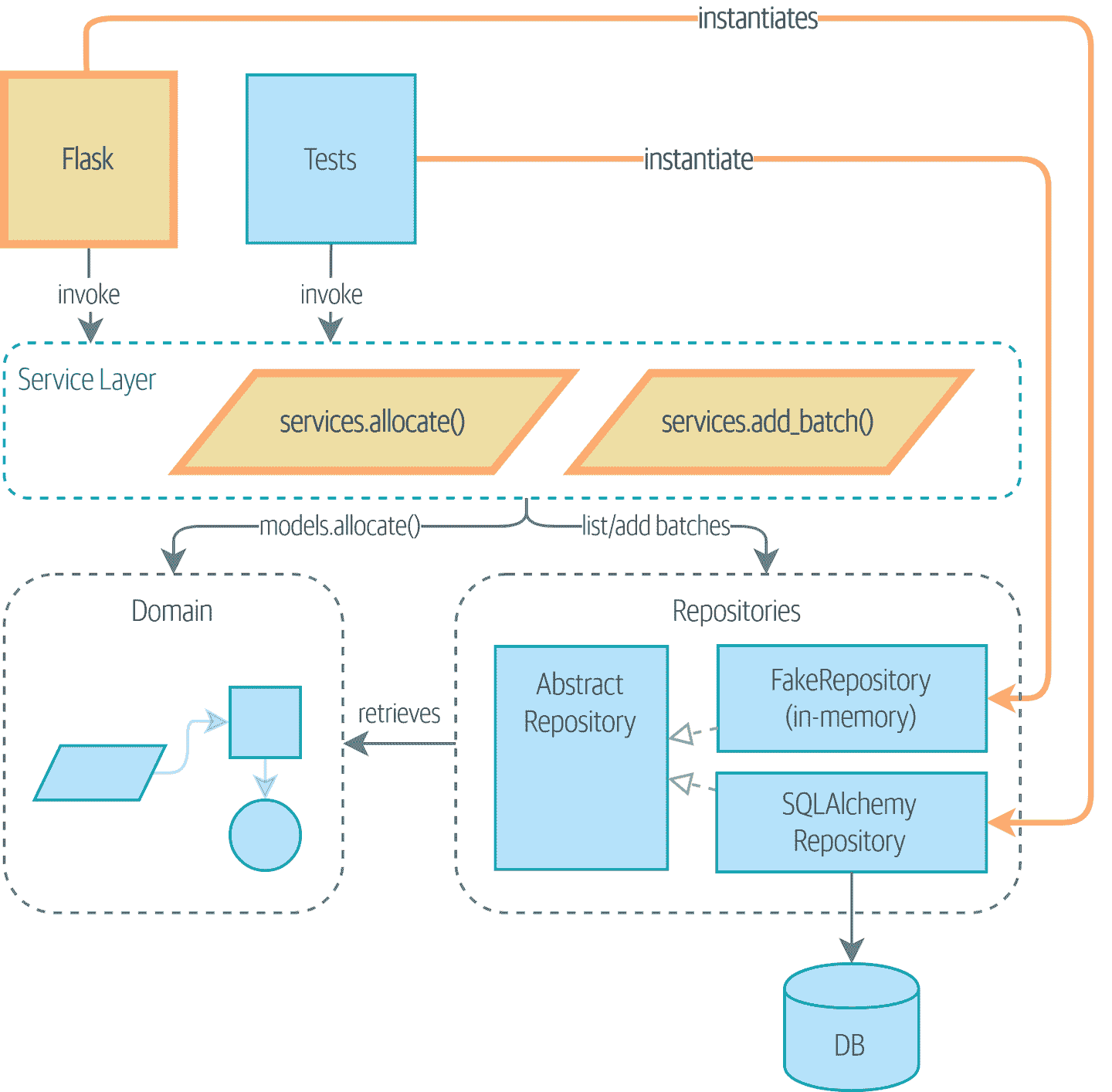
图 4-2:服务层将成为我们应用程序的主要入口
在我们的图表中,我们使用的约定是用粗体文本/线条(如果您正在阅读数字版本,则为黄色/橙色)突出显示新组件。
提示
本章的代码位于 GitHub 上的 chapter_04_service_layer 分支中(https://oreil.ly/TBRuy):
git clone https://github.com/cosmicpython/code.git
cd code
git checkout chapter_04_service_layer
# or to code along, checkout Chapter 2:
git checkout chapter_02_repository
将我们的应用程序连接到现实世界
像任何一个优秀的敏捷团队一样,我们正在努力尝试推出一个 MVP 并让用户开始收集反馈意见。我们已经拥有了我们的领域模型的核心和我们需要分配订单的领域服务,以及永久存储的存储库接口。
让我们尽快将所有的部分组合在一起,然后重构以实现更清晰的架构。这是我们的计划:
-
使用 Flask 在我们的
allocate领域服务前面放置一个 API 端点。连接数据库会话和我们的存储库。使用端到端测试和一些快速而肮脏的 SQL 来准备测试数据进行测试。 -
重构出一个可以作为抽象来捕捉用例的服务层,并将其放置在 Flask 和我们的领域模型之间。构建一些服务层测试,并展示它们如何使用
FakeRepository。 -
尝试使用不同类型的参数来调用我们的服务层函数;显示使用原始数据类型允许服务层的客户端(我们的测试和我们的 Flask API)与模型层解耦。
第一个端到端测试
没有人对什么算作端到端(E2E)测试与功能测试、验收测试、集成测试、单元测试之间的术语辩论感兴趣。不同的项目需要不同的测试组合,我们已经看到完全成功的项目将事情分成“快速测试”和“慢速测试”。
目前,我们希望编写一个或两个测试,这些测试将运行一个“真实”的 API 端点(使用 HTTP)并与真实数据库交互。让我们称它们为端到端测试,因为这是最直观的名称之一。
以下是第一次尝试:
第一个 API 测试(test_api.py)
@pytest.mark.usefixtures("restart_api")
def test_api_returns_allocation(add_stock):
sku, othersku = random_sku(), random_sku("other") #(1)
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock( #(2)
[
(laterbatch, sku, 100, "2011-01-02"),
(earlybatch, sku, 100, "2011-01-01"),
(otherbatch, othersku, 100, None),
]
)
data = {"orderid": random_orderid(), "sku": sku, "qty": 3}
url = config.get_api_url() #(3)
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 201
assert r.json()["batchref"] == earlybatch
①
random_sku()、random_batchref()等都是使用uuid模块生成随机字符的小助手函数。因为我们现在正在运行实际的数据库,这是防止各种测试和运行相互干扰的一种方法。
②
add_stock是一个辅助装置,只是隐藏了使用 SQL 手动插入行的细节。我们将在本章后面展示更好的方法。
③
config.py是一个模块,我们在其中保存配置信息。
每个人以不同的方式解决这些问题,但您需要一种方法来启动 Flask,可能是在容器中,并与 Postgres 数据库进行通信。如果您想了解我们是如何做到的,请查看附录 B。
直接实现
以最明显的方式实现,您可能会得到这样的东西:
Flask 应用程序的第一次尝试(flask_app.py)
from flask import Flask, jsonify, request
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
import config
import model
import orm
import repository
orm.start_mappers()
get_session = sessionmaker(bind=create_engine(config.get_postgres_uri()))
app = Flask(__name__)
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
batchref = model.allocate(line, batches)
return jsonify({'batchref': batchref}), 201
到目前为止,一切都很好。你可能会认为,“不需要太多你们的‘架构宇航员’废话,鲍勃和哈里。”
但等一下——没有提交。我们实际上没有将我们的分配保存到数据库中。现在我们需要第二个测试,要么检查数据库状态之后(不太黑盒),要么检查我们是否无法分配第二行,如果第一行应该已经耗尽了批次:
测试分配被持久化(test_api.py)
@pytest.mark.usefixtures('restart_api')
def test_allocations_are_persisted(add_stock):
sku = random_sku()
batch1, batch2 = random_batchref(1), random_batchref(2)
order1, order2 = random_orderid(1), random_orderid(2)
add_stock([
(batch1, sku, 10, '2011-01-01'),
(batch2, sku, 10, '2011-01-02'),
])
line1 = {'orderid': order1, 'sku': sku, 'qty': 10}
line2 = {'orderid': order2, 'sku': sku, 'qty': 10}
url = config.get_api_url()
# first order uses up all stock in batch 1
r = requests.post(f'{url}/allocate', json=line1)
assert r.status_code == 201
assert r.json()['batchref'] == batch1
# second order should go to batch 2
r = requests.post(f'{url}/allocate', json=line2)
assert r.status_code == 201
assert r.json()['batchref'] == batch2
不是那么可爱,但这将迫使我们添加提交。
需要数据库检查的错误条件
不过,如果我们继续这样做,事情会变得越来越丑陋。
假设我们想要添加一些错误处理。如果领域引发了一个错误,对于一个缺货的 SKU 呢?或者甚至不存在的 SKU 呢?这不是领域甚至知道的事情,也不应该是。这更像是我们应该在调用领域服务之前在数据库层实现的一个理智检查。
现在我们正在看另外两个端到端测试:
在 E2E 层进行更多的测试(test_api.py)
@pytest.mark.usefixtures("restart_api")
def test_400_message_for_out_of_stock(add_stock): #(1)
sku, small_batch, large_order = random_sku(), random_batchref(), random_orderid()
add_stock(
[(small_batch, sku, 10, "2011-01-01"),]
)
data = {"orderid": large_order, "sku": sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Out of stock for sku {sku}"
@pytest.mark.usefixtures("restart_api")
def test_400_message_for_invalid_sku(): #(2)
unknown_sku, orderid = random_sku(), random_orderid()
data = {"orderid": orderid, "sku": unknown_sku, "qty": 20}
url = config.get_api_url()
r = requests.post(f"{url}/allocate", json=data)
assert r.status_code == 400
assert r.json()["message"] == f"Invalid sku {unknown_sku}"
①
在第一个测试中,我们试图分配比我们库存中有的单位更多。
②
在第二个测试中,SKU 不存在(因为我们从未调用add_stock),因此在我们的应用程序看来是无效的。
当然,我们也可以在 Flask 应用程序中实现它:
Flask 应用程序开始变得混乱(flask_app.py)
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
@app.route("/allocate", methods=['POST'])
def allocate_endpoint():
session = get_session()
batches = repository.SqlAlchemyRepository(session).list()
line = model.OrderLine(
request.json['orderid'],
request.json['sku'],
request.json['qty'],
)
if not is_valid_sku(line.sku, batches):
return jsonify({'message': f'Invalid sku {line.sku}'}), 400
try:
batchref = model.allocate(line, batches)
except model.OutOfStock as e:
return jsonify({'message': str(e)}), 400
session.commit()
return jsonify({'batchref': batchref}), 201
但是我们的 Flask 应用程序开始变得有些笨重。我们的 E2E 测试数量开始失控,很快我们将以倒置的测试金字塔(或者鲍勃喜欢称之为“冰淇淋锥模型”)结束。
引入服务层,并使用 FakeRepository 进行单元测试
如果我们看看我们的 Flask 应用程序在做什么,我们会发现有很多我们可能称之为编排的东西——从我们的存储库中获取东西,根据数据库状态验证我们的输入,处理错误,并在正常情况下进行提交。这些大部分事情与拥有 Web API 端点无关(例如,如果您正在构建 CLI,您会需要它们;请参阅附录 C),它们不是真正需要通过端到端测试来测试的东西。
有时将服务层拆分出来是有意义的,有时被称为编排层或用例层。
您还记得我们在第三章中准备的FakeRepository吗?
我们的假存储库,一个内存中的批次集合(test_services.py)
class FakeRepository(repository.AbstractRepository):
def __init__(self, batches):
self._batches = set(batches)
def add(self, batch):
self._batches.add(batch)
def get(self, reference):
return next(b for b in self._batches if b.reference == reference)
def list(self):
return list(self._batches)
这就是它将会派上用场的地方;它让我们可以使用快速的单元测试来测试我们的服务层:
在服务层使用伪造进行单元测试(test_services.py)
def test_returns_allocation():
line = model.OrderLine("o1", "COMPLICATED-LAMP", 10)
batch = model.Batch("b1", "COMPLICATED-LAMP", 100, eta=None)
repo = FakeRepository([batch]) #(1)
result = services.allocate(line, repo, FakeSession()) #(2) (3)
assert result == "b1"
def test_error_for_invalid_sku():
line = model.OrderLine("o1", "NONEXISTENTSKU", 10)
batch = model.Batch("b1", "AREALSKU", 100, eta=None)
repo = FakeRepository([batch]) #(1)
with pytest.raises(services.InvalidSku, match="Invalid sku NONEXISTENTSKU"):
services.allocate(line, repo, FakeSession()) #(2) (3)
①
FakeRepository保存了我们测试中将使用的Batch对象。
②
我们的服务模块(services.py)将定义一个allocate()服务层函数。它将位于 API 层中的allocate_endpoint()函数和领域模型中的allocate()领域服务函数之间。¹
③
我们还需要一个FakeSession来伪造数据库会话,如下面的代码片段所示。
一个假的数据库会话(test_services.py)
class FakeSession():
committed = False
def commit(self):
self.committed = True
这个假的会话只是一个临时解决方案。我们将摆脱它,并很快让事情变得更好,在第六章。但与此同时,假的.commit()让我们从 E2E 层迁移了第三个测试:
服务层的第二个测试(test_services.py)
def test_commits():
line = model.OrderLine('o1', 'OMINOUS-MIRROR', 10)
batch = model.Batch('b1', 'OMINOUS-MIRROR', 100, eta=None)
repo = FakeRepository([batch])
session = FakeSession()
services.allocate(line, repo, session)
assert session.committed is True
典型的服务函数
我们将编写一个类似于以下内容的服务函数:
基本分配服务(services.py)
class InvalidSku(Exception):
pass
def is_valid_sku(sku, batches):
return sku in {b.sku for b in batches}
def allocate(line: OrderLine, repo: AbstractRepository, session) -> str:
batches = repo.list() #(1)
if not is_valid_sku(line.sku, batches): #(2)
raise InvalidSku(f"Invalid sku {line.sku}")
batchref = model.allocate(line, batches) #(3)
session.commit() #(4)
return batchref
典型的服务层函数有类似的步骤:
①
我们从存储库中提取一些对象。
②
我们对请求针对当前世界的状态进行一些检查或断言。
③
我们调用一个领域服务。
④
如果一切顺利,我们保存/更新我们已经改变的状态。
目前,最后一步有点不尽如人意,因为我们的服务层与数据库层紧密耦合。我们将在第六章中通过工作单元模式改进这一点。
但服务层的基本内容都在那里,我们的 Flask 应用现在看起来更加清晰:
Flask 应用委托给服务层(flask_app.py)
@app.route("/allocate", methods=["POST"])
def allocate_endpoint():
session = get_session() #(1)
repo = repository.SqlAlchemyRepository(session) #(1)
line = model.OrderLine(
request.json["orderid"], request.json["sku"], request.json["qty"], #(2)
)
try:
batchref = services.allocate(line, repo, session) #(2)
except (model.OutOfStock, services.InvalidSku) as e:
return {"message": str(e)}, 400 #(3)
return {"batchref": batchref}, 201 #(3)
①
我们实例化一个数据库会话和一些存储库对象。
②
我们从 Web 请求中提取用户的命令,并将其传递给领域服务。
③
我们返回一些带有适当状态代码的 JSON 响应。
Flask 应用的职责只是标准的网络内容:每个请求的会话管理,解析 POST 参数中的信息,响应状态码和 JSON。所有的编排逻辑都在用例/服务层中,领域逻辑保留在领域中。
最后,我们可以自信地将我们的 E2E 测试简化为只有两个,一个是快乐路径,一个是不快乐路径:
只有快乐和不快乐路径的 E2E 测试(test_api.py)
@pytest.mark.usefixtures('restart_api')
def test_happy_path_returns_201_and_allocated_batch(add_stock):
sku, othersku = random_sku(), random_sku('other')
earlybatch = random_batchref(1)
laterbatch = random_batchref(2)
otherbatch = random_batchref(3)
add_stock([
(laterbatch, sku, 100, '2011-01-02'),
(earlybatch, sku, 100, '2011-01-01'),
(otherbatch, othersku, 100, None),
])
data = {'orderid': random_orderid(), 'sku': sku, 'qty': 3}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 201
assert r.json()['batchref'] == earlybatch
@pytest.mark.usefixtures('restart_api')
def test_unhappy_path_returns_400_and_error_message():
unknown_sku, orderid = random_sku(), random_orderid()
data = {'orderid': orderid, 'sku': unknown_sku, 'qty': 20}
url = config.get_api_url()
r = requests.post(f'{url}/allocate', json=data)
assert r.status_code == 400
assert r.json()['message'] == f'Invalid sku {unknown_sku}'
我们成功地将我们的测试分成了两个广泛的类别:关于网络内容的测试,我们实现端到端;关于编排内容的测试,我们可以针对内存中的服务层进行测试。
为什么一切都叫服务?
此时,你们中的一些人可能正在思考领域服务和服务层之间的确切区别是什么。
很抱歉——我们没有选择这些名称,否则我们会有更酷更友好的方式来谈论这些事情。
在本章中,我们使用了两个称为service的东西。第一个是应用服务(我们的服务层)。它的工作是处理来自外部世界的请求,并编排一个操作。我们的意思是服务层通过遵循一系列简单的步骤驱动应用程序:
-
从数据库获取一些数据
-
更新领域模型
-
持久化任何更改
这是系统中每个操作都必须进行的无聊工作,将其与业务逻辑分开有助于保持事物的整洁。
第二种类型的服务是领域服务。这是指属于领域模型但不自然地位于有状态实体或值对象内部的逻辑部分的名称。例如,如果您正在构建一个购物车应用程序,您可能会选择将税收规则构建为领域服务。计算税收是与更新购物车分开的工作,它是模型的重要部分,但似乎不应该为该工作创建一个持久化实体。而是一个无状态的 TaxCalculator 类或calculate_tax函数可以完成这项工作。
将事物放入文件夹中以查看它们的归属
随着我们的应用程序变得更大,我们需要不断整理我们的目录结构。我们项目的布局为我们提供了关于每个文件中可能包含的对象类型的有用提示。
这是我们可以组织事物的一种方式:
一些子文件夹
.
├── config.py
├── domain ①
│ ├── __init__.py
│ └── model.py
├── service_layer ②
│ ├── __init__.py
│ └── services.py
├── adapters ③
│ ├── __init__.py
│ ├── orm.py
│ └── repository.py
├── entrypoints ④
│ ├── __init__.py
│ └── flask_app.py
└── tests
├── __init__.py
├── conftest.py
├── unit
│ ├── test_allocate.py
│ ├── test_batches.py
│ └── test_services.py
├── integration
│ ├── test_orm.py
│ └── test_repository.py
└── e2e
└── test_api.py
①
让我们为我们的领域模型创建一个文件夹。目前只有一个文件,但对于更复杂的应用程序,您可能会为每个类创建一个文件;您可能会为Entity、ValueObject和Aggregate创建帮助父类,并且您可能会添加一个exceptions.py用于领域层异常,以及如您将在第二部分中看到的commands.py和events.py。
②
我们将区分服务层。目前只有一个名为services.py的文件用于我们的服务层函数。您可以在这里添加服务层异常,并且正如您将在第五章中看到的那样,我们将添加unit_of_work.py。
③
适配器是对端口和适配器术语的一种称呼。这将填充任何其他关于外部 I/O 的抽象(例如redis_client.py)。严格来说,您可以将这些称为secondary适配器或driven适配器,有时也称为inward-facing适配器。
④
入口点是我们驱动应用程序的地方。在官方端口和适配器术语中,这些也是适配器,并被称为primary、driving或outward-facing适配器。
端口呢?您可能还记得,它们是适配器实现的抽象接口。我们倾向于将它们与实现它们的适配器放在同一个文件中。
总结
添加服务层确实为我们带来了很多好处:
-
我们的 Flask API 端点变得非常轻量且易于编写:它们唯一的责任就是做“网络事务”,比如解析 JSON 并为 happy 或 unhappy 情况生成正确的 HTTP 代码。
-
我们为我们的领域定义了一个清晰的 API,一组用例或入口点,可以被任何适配器使用,而无需了解我们的领域模型类的任何信息 - 无论是 API、CLI(参见附录 C),还是测试!它们也是我们领域的适配器。
-
通过使用服务层,我们可以以“高速”编写测试,从而使我们可以自由地以任何我们认为合适的方式重构领域模型。只要我们仍然可以提供相同的用例,我们就可以尝试新的设计,而无需重写大量的测试。
-
我们的测试金字塔看起来不错 - 我们大部分的测试都是快速的单元测试,只有最少量的 E2E 和集成测试。
DIP 的实际应用
图 4-3 显示了我们服务层的依赖关系:领域模型和AbstractRepository(在端口和适配器术语中称为端口)。
当我们运行测试时,图 4-4 显示了我们如何使用FakeRepository(适配器)来实现抽象依赖。
当我们实际运行我们的应用程序时,我们会在图 4-5 中显示的“真实”依赖项中进行交换。
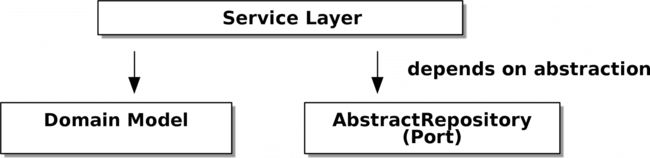
图 4-3. 服务层的抽象依赖
[ditaa, apwp_0403]
+-----------------------------+
| Service Layer |
+-----------------------------+
| |
| | depends on abstraction
V V
+------------------+ +--------------------+
| Domain Model | | AbstractRepository |
| | | (Port) |
+------------------+ +--------------------+
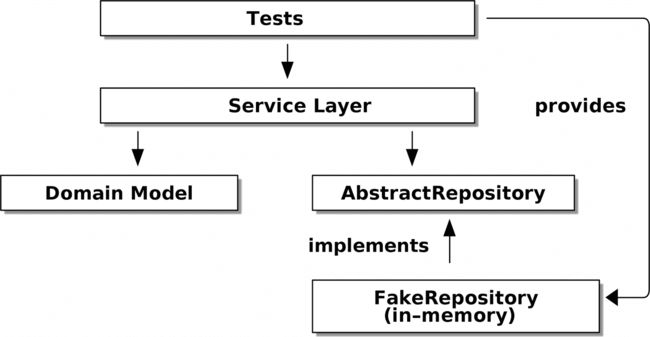
图 4-4. 测试提供了抽象依赖的实现
[ditaa, apwp_0404]
+-----------------------------+
| Tests |-------------\
+-----------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | provides |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ |
implements | |
| |
+----------------------+ |
| FakeRepository |<--/
| (in-memory) |
+----------------------+

图 4-5. 运行时的依赖关系
[ditaa, apwp_0405]
+--------------------------------+
| Flask API (Presentation Layer) |-----------\
+--------------------------------+ |
| |
V |
+-----------------------------+ |
| Service Layer | |
+-----------------------------+ |
| | |
V V |
+------------------+ +--------------------+ |
| Domain Model | | AbstractRepository | |
+------------------+ +--------------------+ |
^ ^ |
| | |
gets | +----------------------+ |
model | | SqlAlchemyRepository |<--/
definitions| +----------------------+
from | | uses
| V
+-----------------------+
| ORM |
| (another abstraction) |
+-----------------------+
|
| talks to
V
+------------------------+
| Database |
+------------------------+
太棒了。
让我们暂停一下,看看表 4-1,在其中我们考虑是否要有一个服务层的利弊。
表 4-1. 服务层:权衡
| 优点 | 缺点 |
|---|---|
| 我们有一个捕获应用程序所有用例的单一位置。 | 如果你的应用程序纯粹是一个 Web 应用程序,你的控制器/视图函数可以是捕获所有用例的唯一位置。 |
| 我们将聪明的领域逻辑放在了一个 API 后面,这使我们可以自由地进行重构。 | 这是另一种抽象层。 |
| 我们已经清晰地将“与 HTTP 通信的东西”与“与分配通信的东西”分开。 | 将太多的逻辑放入服务层可能会导致贫血领域反模式。最好在发现编排逻辑渗入控制器后引入这一层。 |
与存储库模式和FakeRepository结合使用时,我们有了一种很好的方法来以比领域层更高的级别编写测试;我们可以在不需要使用集成测试的情况下测试我们的工作流程(详见第五章以获取更多关于此的阐述)。 |
通过简单地将逻辑从控制器推到模型层,你可以获得丰富领域模型带来的许多好处,而无需在中间添加额外的层(即“胖模型,瘦控制器”)。 |
但仍然有一些需要整理的不便之处:
-
服务层仍然与领域紧密耦合,因为其 API 是以
OrderLine对象表示的。在第五章中,我们将解决这个问题,并讨论服务层如何实现更高效的 TDD。 -
服务层与
session对象紧密耦合。在第六章中,我们将介绍另一种与存储库和服务层模式紧密配合的模式,即工作单元模式,一切都会非常美好。你会看到的!
¹ 服务层服务和领域服务的名称确实非常相似。我们稍后会解决这个问题,详见“为什么一切都被称为服务?”。