Kv缓存用法指南
8-27 kv缓存初步学习
一、理解业务中的使用缓存优势
举个简单的例子,我们可以类比去图书馆看书。
没有使用缓存的情况
当我们想要查看某本书的时候(查看数据库的记录),需要先去图书馆找到这本书所在的类目(记录存在的表),然后再找到这本书,看一会后再把这本书还回去。
但是如果有几本我们常看的数,我们每次看都要去图书馆取,取完了再放回去太麻烦。
使用缓存的情况
当我们想要查看某本书的时候(查看数据库的记录),需要先去图书馆找到这本书所在的类目(记录存在的表),然后再找到这本书,把这本书借回去放到自己的书架上。
这样做我们可以对一些我们频繁阅读的书籍放在触手可及的书架上,大大节约了时间成本。
- 就像书架(redis占据的内存)和图书馆(数据库占据的磁盘)一样,书架的资源和空间非常的宝贵,因此一些不必要的书籍没有必要放在书架(redis中)上。
- 就像去图书馆和用手拿书一样,内存的读取速度时磁盘的500-1000倍,当我们需要对一些热点数据访问的时候,大大节约了时间成本。
总结:redis缓存是一种key-value缓存数据库,是对数据库频繁访问的某些热点字段的一种优化方案。
二、搭建kv缓存使用环境
kv是把热点数据作为Key-Value形式存储的一种
2.1 连接redis服务器
- 引入redis服务端依赖
- 配置redis相关信息
- 启动redis服务和spring程序
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>2.5.1version>
dependency>
2.2 引入jedis客户端
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>2.9.0version>
dependency>
2.3 引入Kv缓存框架
- 引入所需要的包
三、使用Kv缓存框架
3.1 通过kv工厂创建 特定kvCacheWrapper(服务包装接口)
kv缓存框架采用的是工厂设计模式创建指定存储的kvCacheWrapper
当然,这些CacheWrapper我们需要随着spring的启动而被创建(就像Repository一样),因此我们需要指定在springbean初始化的时候对其进行创建。@PostConstruct注解下的方法可以在spring加载这个类的时候自动调用。
首先,我们通过依赖注入的方式引入KvCacheFactory。
@Autowired
private KvCacheFactory kvCacheFactory;
接着,在初始化方法下通过kvCacheFactory.create()创建特定的kvCacheWrapper接口
在创建之前,先来了解一下KvCacheFactory.created()所需的参数
- CacheOptions:缓存配置项。(key:redis某一类数据的标识,相当于mysql中的表明。version:版本号。expireIn:每条缓存记录的时限。)
- RepositoryProvider:持久层的支持(这里支持我们访问数据库)。我们需要实现两个方法
-
findByKey是指定,我们通过什么类型的key来获取缓存中的value,当然这里也意味着我们存数据的时候key与这个类型一致,这个约定是在keyWrapper中约定的。 - ModelConverter:模型和json的转换,这里写我们需要存取数据的model模型,当我们在存取的时候参与转换。
比如说我们这里创建一个User的缓存接口。
@PostConstruct
public void init()
{
userCache = kvCacheFactory.create(new CacheOptions("user", 1, DateUtils.SECOND_PER_DAY),
new RepositoryProvider<Long, User>() {
@Override
public User findByKey(Long key) throws Exception
{
return repository.findById(key).orElse(null);
}
@Override
public Map<Long, User> findByKeys(java.util.Collection<Long> keys) throws Exception
{
return repository.findByIdIn(keys).stream().collect(Collectors.toMap(User::getId, t -> t));
}
}, new BeanModelConverter<>(User.class));
}
3.2 使用cacheWrapper
通过查看KvCache接口我们可以查看它的所有用法
public interface KvCache<K, T>
{
// 只从缓存中查找,如果缓存中没有,则返回null(不进入数据库)。
T findByKey(K key, boolean cacheOnly);
// 先从缓存中查找,如果缓存中没有进入数据库中查找,找到后缓存到redis中。
T findByKey(K key);
// 同上
Map<K, T> findByKeys(Collection<K> keys, boolean cacheOnly) throws KvCacheException;
// 同上
Map<K, T> findByKeys(Collection<K> keys) throws KvCacheException;
// 保存到缓存中
void save(K key, T value) throws KvCacheException;
// 批量保存
void saveMany(Map<K, T> items) throws KvCacheException;
// 刷新缓存(重新加载内容,写入缓存并返回)
T refresh(K key) throws Exception;
// 从缓存中删除
void remove(K key) throws KvCacheException;
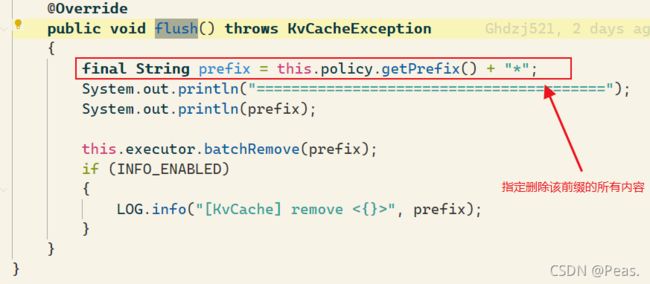
// 根据prefix清理全部数据(这个prefix是我们在配置Policy配置的)
void flush() throws KvCacheException;
}
Policy策略
policy默认的为我们提供了一些策略
![]()
- 过期时间使用的是我们在CacheOption中配置的过期时间
- 前缀策略(供定制批量删除策略):是我们的 CacheOption中key(也就是redis的表明)+:+版本号+:组成的,比如 admin:1:xxx
flush()
通过前缀策略,批量删除某个数据组的某个版本的所有数据。
因为我们在通过工厂create cacheWrapper的时候,我们自动在这里的前缀策略默认使用的是:“组名:版本号:”

flush源码:
3.3 如何使用缓存
因为内存资源的珍贵,我们并不能任意的缓存数据库记录到缓存中,如何合理的使用缓存在业务中至关重要。
- 缓存中应该存入频繁访问的热点数据。比如每次请求都需要包装的上下文信息。
- 不允许缓存重要数据,比如密码。我们可以设置该字段禁用反序列化来达到不缓存的目的。
- 做redis缓存的时候,注意以下几点:
- 是否从缓存中获取的模型有被禁止序列化的字段,如果需要用到这些字段应该从数据库中直接查询
- 修改和删除数据库记录的时候要注意及时清除脏数据(删除缓存信息,下一次访问该缓存信息的时候直接在从数据库中查询最新数据),避免脏读
- 缓存的session字段,如果过期了也要及时清除:(可以设置缓存过期时间跟session过期一样的时间,因为在用户初次登录产生session的时候,就会把session缓存起来(通过token获取wrapper的时候),让两者的存在时间保持同步)