翻译:Building Efficient RAG Systems: A Deep Dive into devv.ai
RAG 的全称是:Retrieval Augmented Generation(检索增强生成)
最初来源于 2020 年 Facebook 的一篇论文:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks(是的,你没有看错,2020 年就有这项技术了)。

这篇论文要解决的一个问题非常简单:如何让语言模型使用外部知识(external knowledge)进行生成。
通常,pre-train 模型的知识存储在参数中,这就导致了模型不知道训练集之外的知识(例如搜索数据、行业的 knowledge)。
之前的做法是有新的知识就再重新在 pre-train 的模型上 finetune。
这样的方式会有几个问题:
- 每次有新的知识后都需要进行 finetune
- 训练模型的成本是很高的
于是这篇论文提出了 RAG 的方法,pre-train 的模型是能够理解新的知识的,那么我们直接把要让模型理解的新知识通过 prompt 的方式给它即可。
所以一个最小的 RAG 系统就是由 3 个部分组成的:
- 语言模型
- 模型所需要的外部知识集合(以 vector 的形式存储)
- 当前场景下需要的外部知识
langchain, llama-index 本质上就是做的这套 RAG 系统(当然还包括构建在 RAG 上的 agent)。
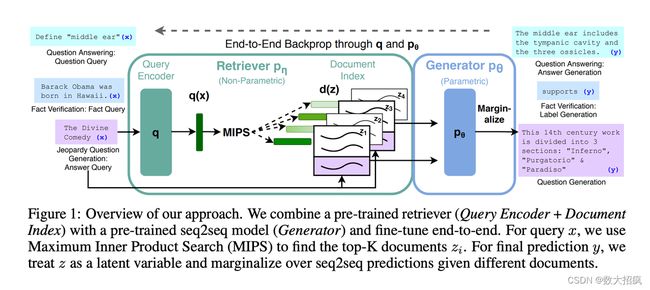
如果理解了本质,其实是没有必要再额外增加一层抽象的,根据自己的业务情况来搭建这套系统即可。
例如,我们为了保持高性能,采用了 Go + Rust 的架构,能够支持高并发的 RAG 请求。
把问题简化,不管是搭建什么样的 RAG,优化这套系统就是分别优化这 3 个模块。
1)语言模型
为什么 2020 年的这篇论文直到今年才火起来?一个主要的原因就是之前的基座模型能力不够。
如果底层模型很笨,那么即使给到了 丰富的外部知识,模型也不能基于这些知识进行推演。
从论文的一些 benchmark 上也可以看出效果有提升,但是并没有特别显著。
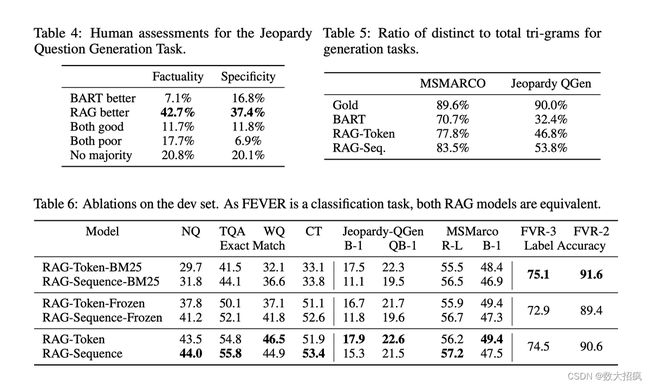
1.1)GPT-3 的出现第一次让 RAG 变得可用
第一波基于 RAG + GPT-3 的公司都获得了非常高的估值 & ARR(年经常性收入):
- Copy AI
- Jasper
这两个都是构建营销领域 RAG 的产品,曾经一度成为明星 AI 独角兽,当然现在祛魅之后估值也大幅度缩水。
1.2)2023 年以来,出现了大量的开源 & 闭源的基座模型,基本上都能够在上面构建 RAG 系统
最常见的方式就是:
- GPT-3.5/4 + RAG(闭源方案)
- Llama 2 / Mistral + RAG(开源方案)
2)模型所需要的外部知识集合
现在应该大家都了解了 embedding 模型了,包括 embedding 数据的召回。
embedding 本质上就是把数据转化为向量,然后通过余弦相似度来找到最匹配的两个或多个向量。
knowledge -> chunks -> vector
user query -> vector
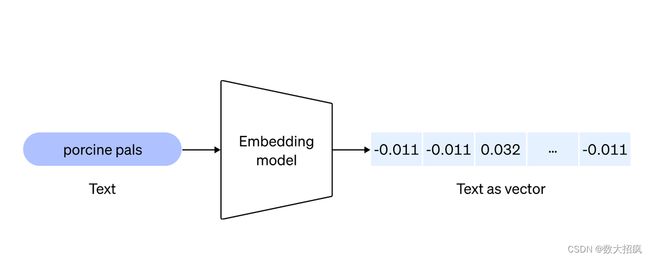
2.1)这个模块分成两个部分:
- embedding 模型
- 存储 embedding vector 的数据库
前者基本上都使用 OpenAI 的 embedding 模型,后者可选方案非常多,包括 Pinecone,国内团队的 Zilliz,开源的 Chroma,在关系型数据库上构建的 pgvector 等。
2.2)这些做 embedding 数据库的公司也在这一波 AI Hype 中获得了非常高的融资额和估值。
但是从第一性原理思考,模块 2 个目的是为了存储外部的知识集合,并在需要的时候进行召回。
这一步并不一定需要 embedding 模型,传统的搜索匹配在某些场景下可能效果更好(Elasticsearch)。
2.3)devv.ai 采用的方式是 embedding + 传统的 relation db + Elasticsearch。
并在每个场景下都做了很多优化,一个思路是在 encoding knowledge 的时候做的工作越多,在 retrieve 的时候就能够更快 & 更准确(先做工 & 后做工的区别)。
2.4)我们使用 Rust 构建了整套 knowledge index
包括:
- GitHub 代码数据
- 开发文档数据
- 搜索引擎数据
3)更好地召回当前场景下需要的外部知识
根据优先做工的法则,我们在 encoding 的时候对于原始的 knowledge 数据做了很多处理:
- 对代码进行程序分析
- 对开发文档进行逻辑级别的 chunk 分块
- 对网页信息的提取 & page ranking 优化
3.1)做完了上面的工作之后保证了我们在 retrieve 的时候获取到的数据本身就是结构化的了,不需要做太多的处理,而且可以提升召回的准确率。
现在再来看 a16z 的这张图,就是在每个步骤上扩展出了对应的组件,核心本质并没有变。
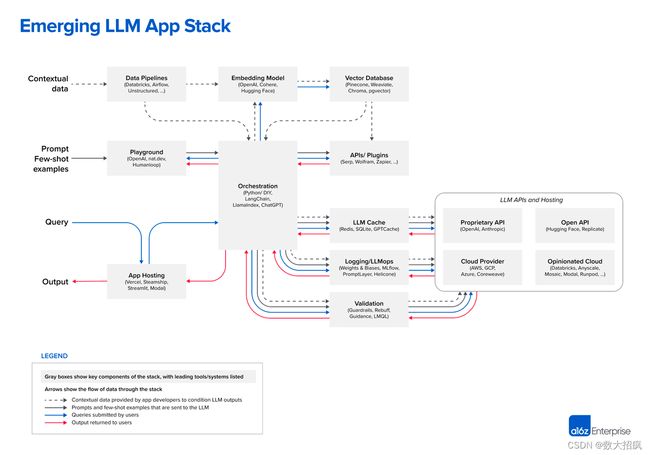
2022 年基于这套 RAG system 做的搜索引擎 Perplexity 每个月已经拥有了几千万的流量,LangChain 也获得了几亿美金的估值。
不管是通用的 RAG,还是专有的 RAG,这是一个做得马马虎虎很容易的领域,但是要做到 90 分很难。
每一步骤都没有最佳实践,例如 embedding chunk size,是否需要接搜索引擎,都需要根据实际的业务场景来多试。
相关的论文非常多,但是并不是每篇论文里面提到的方法都是有用的。