一、ORM简介
- MVC或者MVC框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- ORM是“对象-关系-映射”的简称。(Object Relational Mapping,简称ORM)(将来会学一个sqlalchemy,是和他很像的,但是django的orm没有独立出来让别人去使用,虽然功能比sqlalchemy更强大,但是别人用不了)
- 类对象--->sql--->pymysql--->mysql服务端--->磁盘,orm其实就是将类对象的语法翻译成sql语句的一个引擎,明白orm是什么了,剩下的就是怎么使用orm,怎么来写类对象关系语句。

原生sql和python的orm代码对比


#sql中的表 #创建表: CREATE TABLE employee( id INT PRIMARY KEY auto_increment , name VARCHAR (20), gender BIT default 1, birthday DATA , department VARCHAR (20), salary DECIMAL (8,2) unsigned, ); #sql中的表纪录 #添加一条表纪录: INSERT employee (name,gender,birthday,salary,department) VALUES ("alex",1,"1985-12-12",8000,"保洁部"); #查询一条表纪录: SELECT * FROM employee WHERE age=24; #更新一条表纪录: UPDATE employee SET birthday="1989-10-24" WHERE id=1; #删除一条表纪录: DELETE FROM employee WHERE name="alex" #python的类 class Employee(models.Model): id=models.AutoField(primary_key=True) name=models.CharField(max_length=32) gender=models.BooleanField() birthday=models.DateField() department=models.CharField(max_length=32) salary=models.DecimalField(max_digits=8,decimal_places=2) #python的类对象 #添加一条表纪录: emp=Employee(name="alex",gender=True,birthday="1985-12-12",epartment="保洁部") emp.save() #查询一条表纪录: Employee.objects.filter(age=24) #更新一条表纪录: Employee.objects.filter(id=1).update(birthday="1989-10-24") #删除一条表纪录: Employee.objects.filter(name="alex").delete()
二、单表操作
配置settings:
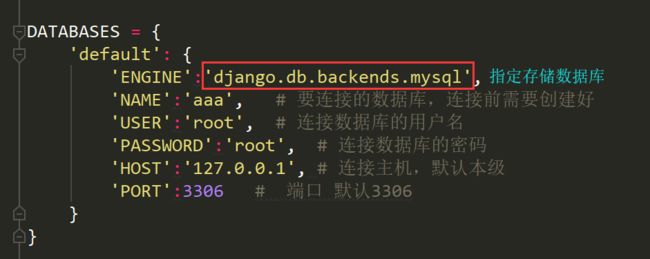
DATABASES = { 'default': { 'ENGINE':'django.db.backends.mysql', 'NAME':'aaa', # 要连接的数据库,连接前需要创建好 'USER':'root', # 连接数据库的用户名 'PASSWORD':'root', # 连接数据库的密码 'HOST':'127.0.0.1', # 连接主机,默认本级 'PORT':3306 # 端口 默认3306 } }
注释不用的django应用:方便日后对表的删除,如果不注释一些内置的表是互相关联的,或者将内置的表全部删除;
INSTALLED_APPS = [ # 'django.contrib.admin', # 'django.contrib.auth', 'django.contrib.contenttypes', # 'django.contrib.sessions', # 'django.contrib.messages', # 'django.contrib.staticfiles', 'app01.apps.App01Config', ]
注意2:确保配置文件中的INSTALLED_APPS中写入我们创建的app名称
INSTALLED_APPS = [ 'django.contrib.admin', #这是django给你提供的一些特殊功能的配置(应用,只是咱们看不到),也在应用这里给配置的,这些功能如果你注销了,那么我们执行同步数据库指令之后,就不会生成那些django自带的表了。因为执行数据库同步语句的时候,django会找这里面所有的应用,找到他们的models来创建表 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', "book" #直接写app的名字也行,写'app01.apps.App01Config'也行 ]
注意1:在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。然后,启动项目,会报错:no module named MySQLdb 。这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb 对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到和settings同级下的__init__,在里面写入:
import pymysql pymysql.install_as_MySQLdb()
在settings里面配置,打印原生sql语句:
LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, } }
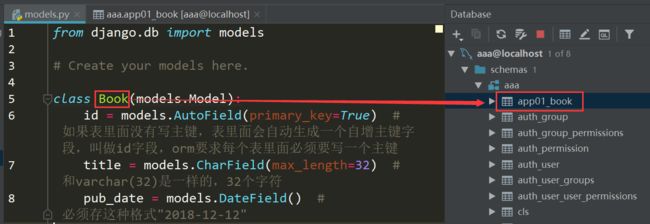
在应用文件夹下的models.py创建模型:
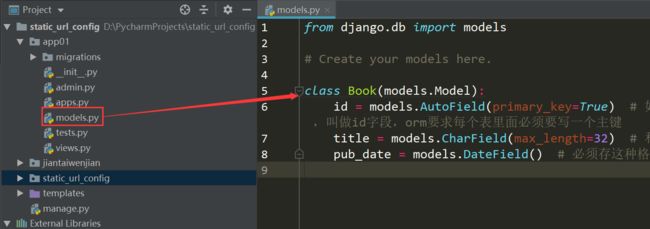
class Book(models.Model): id = models.AutoField(primary_key=True) # 如果表里面没有写主键,表里面会自动生成一个自增主键字段,叫做id字段,orm要求每个表里面必须要写一个主键 title = models.CharField(max_length=32) # 和varchar(32)是一样的,32个字符 pub_date = models.DateField() # 必须存这种格式"2018-12-12"
接下来要创建对应的数据:
连接上对应的数据库,然后执行创建表的命令,翻译成相应的sql,然后到数据库里面执行,从而创建对应的表。多了一步orm翻译成sql的过程,效率低了,但是没有太大的损伤,还能忍受,当你不能忍的时候,你可以自己写原生sql语句,一般的场景orm都够用了,开发起来速度更快,写法更贴近应用程序开发,还有一点就是数据库升级或者变更,那么你之前用sql语句写的数据库操作,那么就需要将sql语句全部修改,但是如果你用orm,就不需要担心这个问题,不管是你从mysql变更到oracle还是从oracle更换到mysql,你如果用的是orm来搞的,你只需要修改一下orm的引擎(配置文件里面改一些配置就搞定)就可以了,你之前写的那些orm语句还是会自动翻译成对应数据库的sql语句。
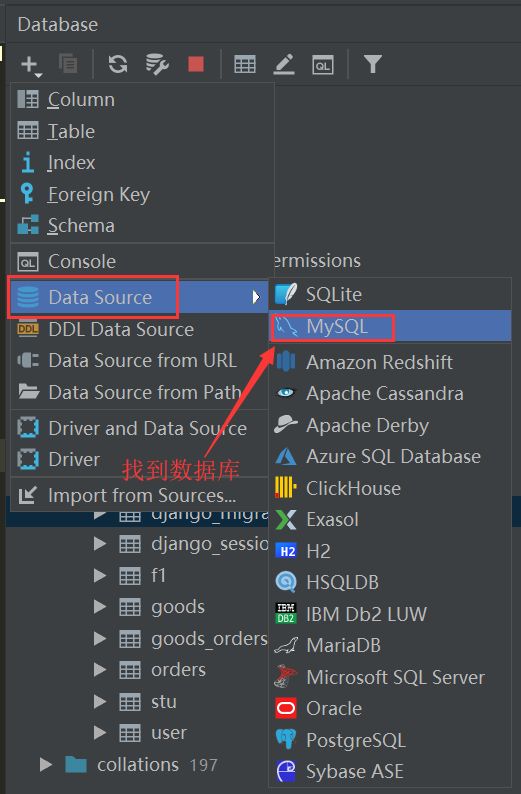
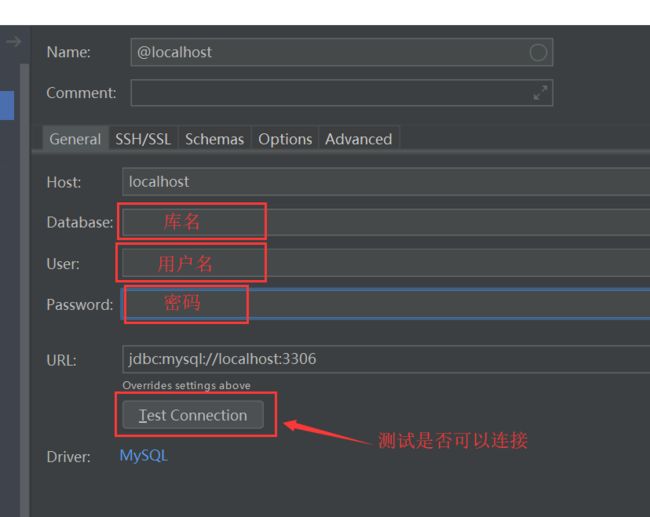
最后通过两条数据库迁移命令即可在指定的数据库中创建表 :
python manage.py makemigrations #生成记录,每次修改了models里面的内容或者添加了新的app,新的app里面写了models里面的内容,都要执行这两条 python manage.py migrate #执行上面这个语句的记录来创建表,生成的表名字前面会自带应用的名字,例如:你的book表在mysql里面叫做app01_book表
执行python manage.py makemigrations 会在migrations生成一个记录创建表的py文件;
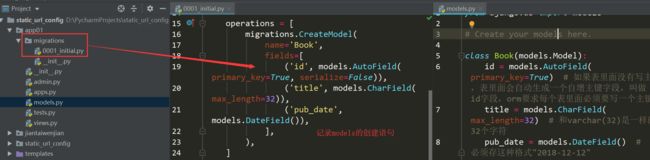
生成的表名====应用名称_小写的类名
小结:
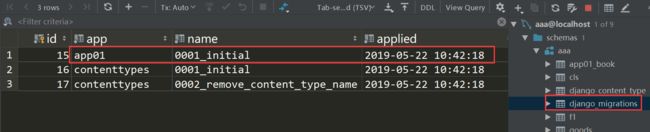
若想删除表重新创建我们需要将django_migratins的记录删除,然后从新执行创建语句
三、字段和参数
每个字段有一些特有的参数,例如,CharField需要max_length参数来指定VARCHAR数据库字段的大小。还有一些适用于所有字段的通用参数。 这些参数在文档中有详细定义,这里我们只简单介绍一些最常用的:
''' <1> CharField 字符串字段, 用于较短的字符串. CharField 要求必须有一个参数 maxlength, 用于从数据库层和Django校验层限制该字段所允许的最大字符数. <2> IntegerField #用于保存一个整数. <3> FloatField 一个浮点数. 必须 提供两个参数: 参数 描述 max_digits 总位数(不包括小数点和符号) decimal_places 小数位数 举例来说, 要保存最大值为 999 (小数点后保存2位),你要这样定义字段: models.FloatField(..., max_digits=5, decimal_places=2) 要保存最大值一百万(小数点后保存10位)的话,你要这样定义: models.FloatField(..., max_digits=17, decimal_places=10) #max_digits大于等于17就能存储百万以上的数了 admin 用一个文本框()表示该字段保存的数据. <4> AutoField 一个 IntegerField, 添加记录时它会自动增长. 你通常不需要直接使用这个字段; 自定义一个主键:my_id=models.AutoField(primary_key=True) 如果你不指定主键的话,系统会自动添加一个主键字段到你的 model. <5> BooleanField A true/false field. admin 用 checkbox 来表示此类字段. <6> TextField 一个容量很大的文本字段. admin 用一个