pod 基础 3
在生产中设置探测时间,10-30秒
initialDelaySeconds: 10-30
探测的间隔时间 10-60之间
periodSeconds: 10-60
探测失败次数,成功次数,默认即可
failureThreshold: 3
successThreshold: 1
探测超时时间 可加可不加
timeoutSeconds: 10-30
readinessPorbe探针:
exec检测方法:

kubectl apply -f test1-pod.yaml

删除就失败了
kubectl exec -it nginx1 -- rm -rf /etc/passwd

状态不为ready,不会重启

可以进去但没什么用了。因为没有ready

httpGet检测方法

正常启动

进入删除

检测响应码为404,不健康


服务不可用,未就绪状态服务不可用。

tcpscoket检测方法


进入容器关闭关闭之后连接拒绝,直接退出,

但会自动拉起。

改端口:8080为8081

检测8081,失败
但是能访问正常端口8080

这个探针只是检测容器上的业务端口是否正常通信。
如果更改了容器的启动端口
mysql 3306 33066
t----->33066
resdinessProbe
就绪探针,pod的状态是runing ready状态是notready,容器不可以提供正常的业务访问,就绪探针不会重启容器。
面试题:存活探针和就绪探针,会伴随整个pos的生命周期。
startupProbe:
启动探针:


如果探测失败,pod的状态是notready,启动探针探测容器失败会重启容器会重启的。
会一直重启


把探针放一块
启动探针在之前

启动探针检测失败。

一直重启

看看存活探针会不会检测
kubectl exec -it nginx1 -- rm -rf /etc/passwd
启动探针没有成功之前,后续探针不会执行。

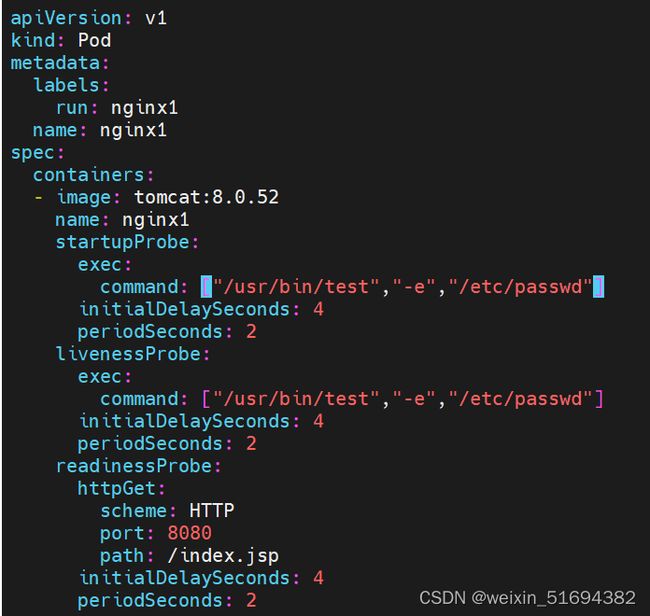
启动探针启动成功之后,在pod的生命周期内不会再检测成功了。会自动重启。
进入容器删除
kubectl exec -it nginx1 -- rm -rf /etc/passwd

重启了pod之后,相当于重新部署了一个初始版的新的容器。

重新运行
总结:
1,在一个yaml文件当中可以有多个探针。。启动存活 就绪都针对一个容器。
2,再度探针的优先级是最高的,只有启动探针成功,后续的探针才会执行。
3,启动探针成功之后。后续除非重启pod,不会再触发启动探针了。
4,在pod的生命周期当中,一直存在,一直探测的是存活探针和就绪探针。
5,在pod的生命周期当中,后续的条件是满足哪个探针的条件,触发哪个探针的条件。
6,就绪探针,如果不影响容器运行,status:running,这个时候不会重启,但是容器退出的话,就绪探针也会重启
容器启动和退出时的的动作:
postStart:容器启动钩子。容器启动触发的条件。
preStop:容器退出钩子,容器退出之后触发的条件。

![]()

删除之后:


启动和退出的作用:
1,启动可以自定义配置容器内的环境变量
2,通知机制,告诉用户容器启动完毕
3,退出时,可以执行自定义命令,删除或者生成一下必要的程序,自定义销毁方式以及自动会场的方式,以及容器的退出等待时间。
作业:在这个pod的生命周期事件当中,把启动停止,存活探针和就绪探针加入到yaml文件当中。
pod的重启策略:
k8s当中都是重启pod
Always:默认策略----->当pod内的容器退出,不论是一个还是两个容器退出,整个pod都会重启
Never:当pod内的容器退出时。退出一个还是退出N个,pod都不重启
onFailure:当pod内的容器退出时,状态码0,整个pod都不会重启,只有一个或者N个容器非正常退出,T 状态码非0,整个pod才会重启。
k8s就是集群化管理容器。k8s管理对象是封装容器的pod。