redis基础
目录
一、redis简介
二、redis基本原理
三、redis数据类型
1、String
2、list
3、hash
4、set
5、zset(sorted_set)
四、redis持久化
1、rdb(Redis Database)
2、aof(Append Only File)
一、redis简介
Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库、缓存和消息中间件。 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询。 Redis 内置了 复制(replication),LUA脚本(Lua scripting), LRU驱动事件(LRU eviction),事务(transactions) 和不同级别的 磁盘持久化(persistence), 并通过 Redis哨兵(Sentinel)和自动 分区(Cluster)提供高可用性(high availability)。(来自redis官方中文文档)
二、redis基本原理
redis是使用c语言进行的开发,内部使用的是基于epoll实现的单线程多路复用技术。简单描述一下这种方式,就是内核与应用程序之间存在一个共享空间,应用程序将数据放入共享空间,然后告诉内核,我准备好数据了,然后内核从共享空间中获取数据,然后当其中某些数据准备好以后,就告诉应用程序,有数据好了,然后应用去共享空间中获取对应数据的标识,再根据该标识通过内核获取相应的详细数据。与select的一个很大的区别就是,select在与内核交互的时候,需要把文件标识符都当参数传递过去,这些参数已再内核和用户之前一直在复制。
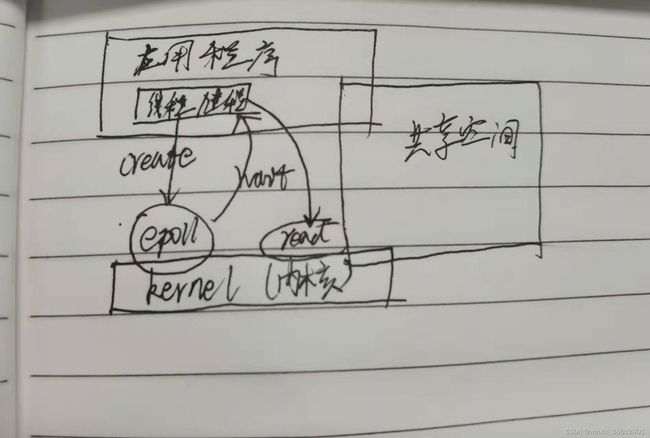
三、redis数据类型
提到redis的数据类型,就会很自然的想到memcached,这两个都是典型的key-value型数据库,而现在基本上都选择使用redis的一个原因就是memcached支持的数据类型单一,这就会造成一个问题,网络IO的成本,因为每次客户端在读取的时候,需要把key对应的value数据全部读取,然后由客户端进行数据解析然后获取其中需要的数据,而redis有着丰富的数据类型可供选择,string,hash,list,set,zset(sorted_set),客户端在做数据存储时可选择对应的数据类型,然后选择合适的api就能获取到key中指定的部分数据,而不需要整体数据传输。
redis底层实现的是二进制安全,只关注字节流,这就需要客户端在调用redis时,采用统一的编码集,不然会出现读写不一致的情况。
每种数据类型都可以使用type key来查看具体的数据类型,当我们发送一个对应的命令的时候,redis会先通过type获取值的类型,然后判断指定和数据类型是否匹配,如果不匹配则直接返回失败。
1、String
对于字符串我们都很熟悉,但是对于redis的字符串而言,其实string还可以细分为:
1)字符串,常规字符串,涉及的相关命令:get/set/strlen/append/mset/mget,还有两个特殊的命令,msetnx/msetex这两个命令是原子性操作,在对过个key-value进行操作的时候,要么都成功,要么都失败
2)数值,(对key使用object encoding可以查看)我们常见的incry/incrby指令其实就是对数据的相关操作
3)bitmap,位图,我感觉这个类型真的是特别厉害的一个类型,布隆过滤器就是基于这个类型进行的实现。这是基于二进制进行的操作。简述一下布隆过滤器的实现,其实也是对位图这个数据类型的了解。首先redis中维护一个bitmap,各个位置初始数值都为二进制0,当系统中存在新的商品的时候,先根据一定的算法进行映射,将这个bitmap中指定位置的0改为1,当客户端进行查询的时候,先根据指定算法对商品进行映射,然后去这个bitmap中查找是否存在,但是需要注意的是,可能会存在误判的情况,比如现有商品1和商品2,bitmap只有8位,商品1对应1和3位,商品2对应5和8位,在查询商品3的时候,商品三对应的是3和5位,就出现了误判的情况。
setbit key 3 0 (3代表二进制索引的位置,0代表设置的值,需要注意的是,0这个未知只能是0和1)
get key(返回的是二进制代表的asc码值)
bitpos key 1 0 2(1代表的是要查找的二进制值,0和2代表的字符索引位置)
bitcount key 0 2(统计二进制1出险的次数,0和2代表的是字符索引)
bitop and/or result key1 key2(对key1和key2的value进行与/或操作,生成新的result)
(redis的value值是具有正负索引的,正索引是从0开始,负索引是从-1开始的)
2、list
集合,这个数据类型使用起来很简单,但是他可以对java的数据类型进行一个模拟。
1)栈:lpush,lpop就会实现先进后出(rpush,rpop)
2)队列:lpush,rpop实现先进先出(rpush,rpop)
3)常规数组:lrange,lindex这些基于索引操作的指令就相当于是数组
4)阻塞队列(单播队列):现在redis中不存在key这个值,当一个客户端执行blpop key指令的时候,发现没有值,他会在这里进行等待,直到有其它的客户端往里面存放值。单播队列的概念是,当有多个客户端执行blpop时,此时一个客户端往key里面存放值的时候,并不是所有等待客户端都会获取该信息,会按照顺序读取,如果存放了一个值,那么只有第一个执行blpop指令的客户端获取到该值。
3、hash
hash类型值得是redis中key-value中的value又是key-value类型。
常用指令hset/hget/hmset/hkeys/hvals/hgetall/hincrby。
4、set
set与list的主要区别是,set里面是无序并且没有重复数据。
常用指令sadd/smembers/srem/sinter(交集)/sdiff(差集)/sunion(并集),后面这三个命令可以添加store后缀,然后会将获得的结果放在一个新的key中。sdiff差集存在方向性,根据key的顺序不同,可以取到不同的值,想要取那个key的差集,就把这个值放到左面。
set可以用来进行随机事件的模拟,使用的指令是srandmember key count(从key中随机取出count个元素,count如果为正数,则取出的元素不会重复,count小于该value的长度,如果count大于value的长度就会出现重复元素;count如果为负数,则取出的元素可以重复)
spop指令:随机弹出一个元素
5、zset(sorted_set)
有序无重复集,这个元素除了元素以外,每个元素还有一个对应的分值,有序即根据这些分值进行的排序,在物理内存中左小右大。
常用的指令:zadd/zrange(按照索引,可以配合withscores,显示分值信息)/zrevrange/zrangebyscore/zrevrangebyscore(按照峰值)/zincryby
在使用集合操作的时候,zset是比较复杂的,以下面这个命令为例:
zunionstore result key1 key2 1 0.5 sum,其中result是新生成的key;key1和key2是要进行操作的key;1和0.5分别代表key1和key2的权重,即key1和key2的分支乘以的倍数,默认为1;sum代表分值的聚合操作,除了sum还有min和max,默认为sum。
zset是怎么实现排序的呢,这就涉及到了一种算法-跳表算法。具体的排序方式如下图:

假设目前zset中的一个key对应的score是3,5,12,17,22,正常情况下只有上图的最底层那个链表,如果是这样的话,每次插入一个数据的时间复杂度就是O(n),但是redis采用了跳表算法的方式来进行的排序,时间复杂度是O(logn)。首先是先对最下层链表的每个元素进行随机升阶,组成第二层链表,然后第二层元素再使用这种方式升阶,组成第三阶,以此类推。假设目前只有三阶,然后现在要插入一个7,首先与第三层的第一个元素比较,比3打,然后继续往右比较,发现右侧为空,则降阶到第二层,往右比较,比12小,那么继续降阶,往左比较,发现比5大,那么将7插入到5和12之间,修改5的next指针,然后再进行随机判断,7是否需要升阶,如果不需要,则插入结束,如果需要,那么第二层修改它前一个元素的指针即可。
四、redis持久化
redis持久化的主要作用就是在服务器挂掉或者进行数据迁移的时候,可以实现一个快速的恢复,防止数据的丢失,目前redis的持久化方式主要有以下两种:
1、rdb(Redis Database)
存储当前时间redis缓存中的快照。针对这种持久化,redis中存在两种方式:
1)save:阻塞式持久化,使用这种方式的时候,redis将无法对外部提供读写服务,需要等待持久化完毕以后,才能对外部提供读写服务,这种方式只适合于准备关机维护的时候,否则的话就违背了redis高性能的原则,一个服务也不可能忍受由于redis持久化而无法使用redis。
2)bgsave:非阻塞式持久化,使用这种持久化方式的时候需要考虑一个问题,我要持久化9点的数据,持久化过程需要10秒,那么生成的持久化文件,是9点的数据,还是9点10秒的数据,还是9点到9点10秒之间的数据?答案是9点的数据,这是依赖于linux的copy-on-write(写时复制) 来实现的。在要进行持久化的时候,redis会fork一个子进程来进行数据持久化,而此时会对当时redis缓存做一个拷贝,但是需要注意的是拷贝的是指针而不是真实的数据,真实的数据存储在内存中,而此时如果对某个key进行修改,内存中会新增一个值,然后将主进程中这个key对应value的指针指向新增的值,而原有值不发生改变,那么子进程中这个key对应value的指针还是对应原有的值,这样就保证在持久化的时候,是保存fork子线程那个节点的数据。
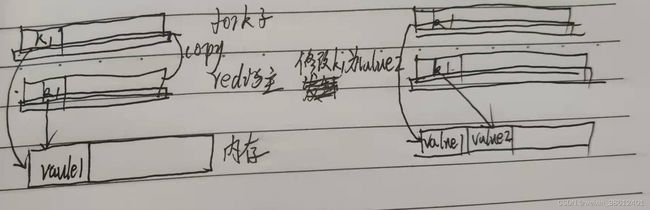
该种持久化方式存在以下优缺点:
优点:
1)备份的文件内容是序列化数据,再进行大批量数据恢复的时候,恢复速度较快,并且持久化文件较小;
缺点:
1)不支持拉链,只会生成一个dump.rdb文件,没有办法支持版本管理,只能由人工介入,编写脚本或者手动运维,在指定时间进行文件备份;
2)丢失数据量较大,rdb在达到一定条件的时候才会触发持久化,在下一次马上要触发持久化的时候,突然宕机,那么就丢失了上一次持久化时间点到目前的数据。持久化条件可以通过save t(时间/s) o(写操作)
2、aof(Append Only File)
进行操作日志的追加,持久化文件中存储的是每次操作的指令,因此会造成持久化文件的体量很大,并且在往持久化文件中同步指令的时候会触发IO。rdb持久化和aof持久化可以同时开启,但是redis在启动时会选择aof进行数据恢复。
触发aof持久化的条件目前支持三种:
1)每次写操作都会触发,相当于每次写操作都会触发IO,当并发量大的时候,IO会很大,可能会对性能造成影响,如果redis当数据库使用,推荐使用这种方式,不会丢失数据;
2)每秒触发,每秒将数据写入持久化文件,在写入之前,这些数据存在于内核的缓存中,推荐使用该方式;
3)交由操作系统处理,即命令一直写入到内核的缓存中,由内核控制何时写到持久化文件中,但是这种方式的不可控性很高,因为不知道丢失多少数据,因此这种方式很不推荐。
在上面提到了使用aof持久化的时候,由于再无限的追加写操作日志,会造成持久化文件很大,当文件越大,那么恢复起来就越慢,针对这个问题,redis提供了aof文件重写。aof文件重写在4.0前后有较大的区别:
1)4.0之前,aof文件重写是对指令信息进行合并,例如set k 0, set k 1,重写以后就只剩下set k 1命令;
2)4.0之后,aof文件重写就是aof与rdb两种方式的混合,在文件的前半部分是rdb持久化方式存储的序列化文件,而后半部分则是aop添加的相关指令。如果aof文件内容是REDIS开头,那么就证明采用了该种方式进行持久化。
可以在配置文件中配置触发重写的规则:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64M
在7.0版本的前后,重写方式也是不同的:
1)在7.0之前,在进行文件重写的时候,谢增的命令放入内存缓冲区中(同时写入就得aof文件),一个进程会在一个新的临时文件进行重写,然后等该进程重写完aof文件以后,缓冲区的指令会写入到该持久化文件中;
2)在7.0之后,最大的区别是,新指令不再是记录在缓存中,而是将这些指令写入到一个增量文件中。