【机器学习】集成学习投票法:投票回归器(VotingRegressor) & 投票分类器(VotingClassifier)
前言
投票回归器和投票分类器都属于集成学习。在【机器学习】集成学习基础概念介绍中有提到过,集成学习的结合策略包括: 平均法、投票法和学习法。sklearn.ensemble库中的Voting Classifier和Voting Regressor,它们分别实现了对回归任务和分类任务的预测模型投票机制。
本文主要分成两个部分:
Vote Regressor
- 原理介绍;
- 代码示例:使用糖尿病数据集展示投票回归预测并绘制结果。
VoteClassifier
- 原理介绍:软、硬两种投票方法的逻辑和区别;
- 代码示例:使用鸢尾花数据集展示如何通过投票分类器提高整体模型的表现。
VotingRegressor
1. 原理介绍
投票回归器(VotingRegressor)聚合了多个基础模型的预测结果,最后的取所有模型预测值的平均值作为最后结果。
2. 详细代码示例
1)训练模型
我们将使用三个不同的回归器来预测数据:GradientBoostingRegressor, RandomForestRegressor, 和 LinearRegression)。然后,上述3个回归器将用于 VotingRegressor。
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import VotingRegressor
X, y = load_diabetes(return_X_y=True)
# Train classifiers
reg1 = GradientBoostingRegressor(random_state=1)
reg2 = RandomForestRegressor(random_state=1)
reg3 = LinearRegression()
reg1.fit(X, y)
reg2.fit(X, y)
reg3.fit(X, y)
ereg = VotingRegressor([('gb', reg1), ('rf', reg2), ('lr', reg3)])
ereg.fit(X, y)
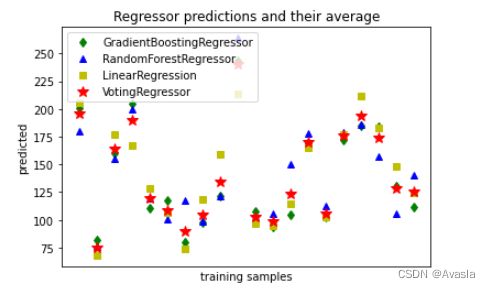
2)预测并绘制结果
我们使用每个回归器对前20个进行预测,并绘制出结果图展示。
#Making predictions
xt = X[:20]
pred1 = reg1.predict(xt)
pred2 = reg2.predict(xt)
pred3 = reg3.predict(xt)
pred4 = ereg.predict(xt)# Train classifiers
reg1 = GradientBoostingRegressor(random_state=1)
#绘制结果
plt.figure()
plt.plot(pred1, 'gd', label='GradientBoostingRegressor')
plt.plot(pred2, 'b^', label='RandomForestRegressor')
plt.plot(pred3, 'ys', label='LinearRegression')
plt.plot(pred4, 'r*', ms=10, label='VotingRegressor')
plt.tick_params(axis='x', which='both', bottom=False, top=False,
labelbottom=False)
plt.ylabel('predicted')
plt.xlabel('training samples')
plt.legend(loc="best")
plt.title('Regressor predictions and their average')
plt.show()
VoteClassifier
1. 原理介绍
VotingClassifier背后的想法是组合概念上不同的机器学习分类器,并使用多数投票或平均预测概率(软投票)来预测类别标签。这样的分类器可以用于一组性能同样良好的模型,以平衡它们各自的弱点。
#定义投票分类器
model= VotingClassifier(
estimators=[('lr',LR), ('rf', RF), ('gnb', GNB)], #指定需要投票的学习器,这里lr\rf\gnb代表3中不同的模型。
voting='soft', #选择投票方式,有soft和hard
weights=[2,10,1]) #权重设置
#使用投票分类器训练模型
model.fit(X,y)
硬投票(Majority/Hard Voting)
- 多数投票法,也叫硬投票,根据少数服从多数的原则 (Majority Class Labels),。
- 若是有并列的最高票,则会按照升序排序顺序选择。举例如下:
例子1:会被标记为class 1, 因为三个分类器中有两个投了"class 1"。
classifier 1 -> class 1
classifier 2 -> class 1
classifier 3 -> class 2
例子2:按照结果升序排列,最终标记为class 1。
classifier 1 -> class 2
classifier 2 -> class 1
软投票(Soft Voting):
- 加权投票法,增加了权重
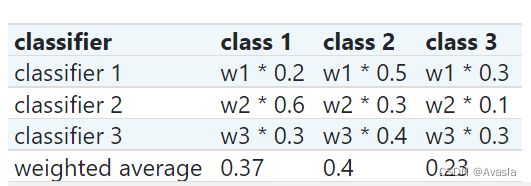
weight参数, 使用加权平均概率(Weighted Average Probabilities) - 该方法要求分类器支持
predict_proba方法,即可以输出每个实例属于每一类的概率。 - 如下图所示, 有三个分类器(classifier 1、classifier 2、classifier 3)和三个分类(class1,2,3) ,我们分别给3个分类器都设置相同的权重,即:w1=1, w2=1, w3=1。class2的平均概率是最高的(0.4>0.37>0.23),所以该实例最后的分类为class 2。
2. 详细代码示例
1)导入包和数据准备
数据集使用的是鸢尾花数据集。
from sklearn import datasets
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings("ignore")
#数据提取
iris = datasets.load_iris()
#设置X、y
X, y = iris.data[:, 1:3], iris.target
#格式转换,整合成表格
iris_data = pd.DataFrame(np.hstack((X, y.reshape(-1, 1))),index = range(X.shape[0]),columns=['petal_length_cm','petal_width_cm','class'] )
2)基础分类器建模
这里使用了逻辑回归、随机森林、朴素贝叶斯三个模型作为基础的分类器
#逻辑回归
LR = LogisticRegression(random_state=1)
LR.fit(X,y)
iris_data['LR']=LR.predict(X)
#随机森林
RF = RandomForestClassifier(n_estimators=50, random_state=1)
RF.fit(X,y)
iris_data['RF']=RF.predict(X)
#朴素贝叶斯
GNB = GaussianNB()
GNB.fit(X,y)
iris_data['GNB']=GNB.predict(X)
3)VotingClassifier
集成学习使用硬投票、软投票以及设定权重后的软投票法。
#硬投票
hard_vote = VotingClassifier(
estimators=[('lr',LR), ('rf', RF), ('gnb', GNB)],
voting='hard')
hard_vote.fit(X,y)
iris_data['hard_vote']=hard_vote.predict(X)
# 软投票
soft_vote = VotingClassifier(
estimators=[('lr',LR), ('rf', RF), ('gnb', GNB)],
voting='soft')
soft_vote.fit(X,y)
iris_data['soft_vote']=soft_vote.predict(X)
# 软投票自定义权重
soft_weight_vote = VotingClassifier(
estimators=[('lr',LR), ('rf', RF), ('gnb', GNB)],
voting='soft',
weights=[2,10,1]) #权重设置
soft_weight_vote.fit(X,y)
iris_data['soft_weight_vote']=soft_weight_vote.predict(X)
3)结果查看
查找结果不同的实例:
- 通过对比RF、soft_vote和soft_weight_vote, 后者因为权重的设置增加了RF分类器的权重,所以soft_weight_vote 的结果和RF一致。
- hard_vote是根据LR、RF、GNB中的多数结果。
#查看结果
#iris_data.tail(10)
#iris_data.head(10)
iris_data[iris_data['RF']!=iris_data['soft_vote']]

仅这个实例而言,通过计算accuracy 对比模型效果:
- 三个基础模型的准确率差异较大;
- 三个投票分类器的准确率都在0.95,表明集成算法的准确性最高、也更稳定。
#查看各个模型表现
for clf, label in zip([LR, RF, GNB, hard_vote,soft_vote,soft_weight_vote],
['Logistic Regression', 'Random Forest', 'naive Bayes', 'Ensemble(hard)','Ensemble(soft_weight)']):
scores = cross_val_score(clf, X, y, scoring='accuracy', cv=5)
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), label))

参考链接
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.VotingRegressor.html#sklearn.ensemble.VotingRegressor
https://scikit-learn.org/stable/auto_examples/ensemble/plot_voting_regressor.html#sphx-glr-auto-examples-ensemble-plot-voting-regressor-py
https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.VotingClassifier.html#sklearn.ensemble.VotingClassifier
https://scikit-learn.org/stable/auto_examples/ensemble/plot_voting_probas.html#sphx-glr-auto-examples-ensemble-plot-voting-probas-py