自动化测试代码中到底用了集中设计模式?
目录
一、单例设计模式
1.使用模块
2.使用装饰器
3.使用类
4.基于__new__方法实现(推荐使用,方便)
5.基于metaclass方式实现
二、工厂模式
三、PO设计模式
为什么要用PO
PO是什么:
PO的优势
PO实现示例
四、数据驱动模式
五、面向接口编程设计模式
一、单例设计模式
单例模式
单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场。
比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息。如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪费内存资源,尤其是在配置文件内容很多的情况下。事实上,类似 AppConfig 这样的类,我们希望在程序运行期间只存在一个实例对象。
在 Python 中,我们可以用多种方法来实现单例模式
实现单例模式的几种方式
1.使用模块
其实,Python 的模块就是天然的单例模式,因为模块在第一次导入时,会生成 .pyc 文件,当第二次导入时,就会直接加载 .pyc 文件,而不会再次执行模块代码。因此,我们只需把相关的函数和数据定义在一个模块中,就可以获得一个单例对象了。如果我们真的想要一个单例类,可以考虑这样做:
mysingleton.py
class Singleton(object):
def foo(self):
pass
singleton = Singleton()将上面的代码保存在文件 mysingleton.py 中,要使用时,直接在其他文件中导入此文件中的对象,这个对象即是单例模式的对象
from a import singleton
2.使用装饰器
def Singleton(cls):
_instance = {}
def _singleton(*args, **kargs):
if cls not in _instance:
_instance[cls] = cls(*args, **kargs)
return _instance[cls]
return _singleton
@Singleton
class A(object):
a = 1
def __init__(self, x=0):
self.x = x
a1 = A(2)
a2 = A(3)3.使用类
class Singleton(object):
def __init__(self):
pass
@classmethod
def instance(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
Singleton._instance = Singleton(*args, **kwargs)
return Singleton._instance一般情况,大家以为这样就完成了单例模式,但是这样当使用多线程时会存在问题
class Singleton(object):
def __init__(self):
pass
@classmethod
def instance(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
Singleton._instance = Singleton(*args, **kwargs)
return Singleton._instance
import threading
def task(arg):
obj = Singleton.instance()
print(obj)
for i in range(10):
t = threading.Thread(target=task,args=[i,])
t.start()程序执行后,打印结果如下:
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>
<__main__.Singleton object at 0x02C933D0>看起来也没有问题,那是因为执行速度过快,如果在init方法中有一些IO操作,就会发现问题了,下面我们通过time.sleep模拟
我们在上面__init__方法中加入以下代码:
def __init__(self):
import time
time.sleep(1)重新执行程序后,结果如下
<__main__.Singleton object at 0x034A3410>
<__main__.Singleton object at 0x034BB990>
<__main__.Singleton object at 0x034BB910>
<__main__.Singleton object at 0x034ADED0>
<__main__.Singleton object at 0x034E6BD0>
<__main__.Singleton object at 0x034E6C10>
<__main__.Singleton object at 0x034E6B90>
<__main__.Singleton object at 0x034BBA30>
<__main__.Singleton object at 0x034F6B90>
<__main__.Singleton object at 0x034E6A90>问题出现了!按照以上方式创建的单例,无法支持多线程
解决办法:加锁!未加锁部分并发执行,加锁部分串行执行,速度降低,但是保证了数据安全
import time
import threading
class Singleton(object):
_instance_lock = threading.Lock()
def __init__(self):
time.sleep(1)
@classmethod
def instance(cls, *args, **kwargs):
with Singleton._instance_lock:
if not hasattr(Singleton, "_instance"):
Singleton._instance = Singleton(*args, **kwargs)
return Singleton._instance
def task(arg):
obj = Singleton.instance()
print(obj)
for i in range(10):
t = threading.Thread(target=task,args=[i,])
t.start()
time.sleep(20)
obj = Singleton.instance()
print(obj)打印结果如下:
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>
<__main__.Singleton object at 0x02D6B110>这样就差不多了,但是还是有一点小问题,就是当程序执行时,执行了time.sleep(20)后,下面实例化对象时,此时已经是单例模式了,但我们还是加了锁,这样不太好,再进行一些优化,把intance方法,改成下面的这样就行:
@classmethod
def instance(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
with Singleton._instance_lock:
if not hasattr(Singleton, "_instance"):
Singleton._instance = Singleton(*args, **kwargs)
return Singleton._instance这样,一个可以支持多线程的单例模式就完成了
import time
import threading
class Singleton(object):
_instance_lock = threading.Lock()
def __init__(self):
time.sleep(1)
@classmethod
def instance(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
with Singleton._instance_lock:
if not hasattr(Singleton, "_instance"):
Singleton._instance = Singleton(*args, **kwargs)
return Singleton._instance
def task(arg):
obj = Singleton.instance()
print(obj)
for i in range(10):
t = threading.Thread(target=task,args=[i,])
t.start()
time.sleep(20)
obj = Singleton.instance()
print(obj)这种方式实现的单例模式,使用时会有限制,以后实例化必须通过 obj = Singleton.instance()
如果用 obj=Singleton() ,这种方式得到的不是单例
4.基于__new__方法实现(推荐使用,方便)
通过上面例子,我们可以知道,当我们实现单例时,为了保证线程安全需要在内部加入锁
我们知道,当我们实例化一个对象时,是先执行了类的__new__方法(我们没写时,默认调用object.__new__),实例化对象;然后再执行类的__init__方法,对这个对象进行初始化,所有我们可以基于这个,实现单例模式
import threading
class Singleton(object):
_instance_lock = threading.Lock()
def __init__(self):
pass
def __new__(cls, *args, **kwargs):
if not hasattr(Singleton, "_instance"):
with Singleton._instance_lock:
if not hasattr(Singleton, "_instance"):
Singleton._instance = object.__new__(cls)
return Singleton._instance
obj1 = Singleton()
obj2 = Singleton()
print(obj1,obj2)
def task(arg):
obj = Singleton()
print(obj)
for i in range(10):
t = threading.Thread(target=task,args=[i,])
t.start()打印结果如下:
<__main__.Singleton object at 0x038B33D0> <__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>
<__main__.Singleton object at 0x038B33D0>采用这种方式的单例模式,以后实例化对象时,和平时实例化对象的方法一样 obj = Singleton()
5.基于metaclass方式实现
相关知识
"""
1.类由type创建,创建类时,type的__init__方法自动执行,类() 执行type的 __call__方法(类的__new__方法,类的__init__方法)
2.对象由类创建,创建对象时,类的__init__方法自动执行,对象()执行类的 __call__ 方法
"""例子:
class Foo:
def __init__(self):
pass
def __call__(self, *args, **kwargs):
pass
obj = Foo()
# 执行type的 __call__ 方法,调用 Foo类(是type的对象)的 __new__方法,用于创建对象,然后调用 Foo类(是type的对象)的 __init__方法,用于对对象初始化。
obj() # 执行Foo的 __call__ 方法 元类的使用
class SingletonType(type):
def __init__(self,*args,**kwargs):
super(SingletonType,self).__init__(*args,**kwargs)
def __call__(cls, *args, **kwargs): # 这里的cls,即Foo类
print('cls',cls)
obj = cls.__new__(cls,*args, **kwargs)
cls.__init__(obj,*args, **kwargs) # Foo.__init__(obj)
return obj
class Foo(metaclass=SingletonType): # 指定创建Foo的type为SingletonType
def __init__(self,name):
self.name = name
def __new__(cls, *args, **kwargs):
return object.__new__(cls)
obj = Foo('xx')实现单例模式
import threading
class SingletonType(type):
_instance_lock = threading.Lock()
def __call__(cls, *args, **kwargs):
if not hasattr(cls, "_instance"):
with SingletonType._instance_lock:
if not hasattr(cls, "_instance"):
cls._instance = super(SingletonType,cls).__call__(*args, **kwargs)
return cls._instance
class Foo(metaclass=SingletonType):
def __init__(self,name):
self.name = name
obj1 = Foo('name')
obj2 = Foo('name')
print(obj1,obj2)二、工厂模式
需求:有一个学雷锋活动,有买米和扫地两个内容,参与的人有大学生和社区志愿者,他们各自的方法不一样。
如果用简单工厂模式实现:
#encoding=utf-8
__author__ = '[email protected]'
class LeiFeng():
def buy_rice(self):
pass
def sweep(self):
pass
class Student(LeiFeng):
def buy_rice(self):
print '大学生帮你买米'
def sweep(self):
print '大学生帮你扫地'
class Volunteer(LeiFeng):
def buy_rice(self):
print '社区志愿者帮你买米'
def sweep(self):
print '社区志愿者帮你扫地'
class LeiFengFactory():
def create_lei_feng(self, type):
map_ = {
'大学生': Student(),
'社区志愿者': Volunteer()
}
return map_[type]
if __name__ == '__main__':
leifeng1 = LeiFengFactory().create_lei_feng('大学生')
leifeng2 = LeiFengFactory().create_lei_feng('大学生')
leifeng3 = LeiFengFactory().create_lei_feng('大学生')
leifeng1.buy_rice()
leifeng1.sweep()写一个雷锋类,定义买米和扫地两个方法,写一个学生类和社区志愿者类,继承雷锋类,写一个工厂类,根据输入的类型返回学生类或志愿者类。
用工厂方法模式实现:
#encoding=utf-8
__author__ = '[email protected]'
class LeiFeng():
def buy_rice(self):
pass
def sweep(self):
pass
class Student(LeiFeng):
def buy_rice(self):
print '大学生帮你买米'
def sweep(self):
print '大学生帮你扫地'
class Volunteer(LeiFeng):
def buy_rice(self):
print '社区志愿者帮你买米'
def sweep(self):
print '社区志愿者帮你扫地'
class LeiFengFactory():
def create_lei_feng(self):
pass
class StudentFactory(LeiFengFactory):
def create_lei_feng(self):
return Student()
class VolunteerFactory(LeiFengFactory):
def create_lei_feng(self):
return Volunteer()
if __name__ == '__main__':
myFactory = StudentFactory()
leifeng1 = myFactory.create_lei_feng()
leifeng2 = myFactory.create_lei_feng()
leifeng3 = myFactory.create_lei_feng()
leifeng1.buy_rice()
leifeng1.sweep()雷锋类,大学生类,志愿者类和简单工厂一样,新写一个工厂方法基类,定义一个工厂方法接口(工厂方法模式的工厂方法应该就是指这个方法),然后写一个学生工厂类,志愿者工厂类,重新工厂方法,返回各自的类。
工厂方法相对于简单工厂的优点:
1.在简单工厂中,如果需要新增类,例如加一个中学生类(MiddleStudent),就需要新写一个类,同时要修改工厂类的map_,加入'中学生':MiddleStudent()。这样就违背了封闭开放原则中的一个类写好后,尽量不要修改里面的内容,这个原则。而在工厂方法中,需要增加一个中学生类和一个中学生工厂类(MiddleStudentFactory),虽然比较繁琐,但是符合封闭开放原则。在工厂方法中,将判断输入的类型,返回相应的类这个过程从工厂类中移到了客户端中实现,所以当需要新增类是,也是要修改代码的,不过是改客户端的代码而不是工厂类的代码。
2.对代码的修改会更加方便。例如在客户端中,需要将Student的实现改为Volunteer,如果在简单工厂中,就需要把
leifeng1 = LeiFengFactory().create_lei_feng('大学生')中的大学生改成社区志愿者,这里就需要改三处地方,但是在工厂方法中,只需要吧
myFactory = StudentFactory()改成
myFactory = VolunteerFactory()
就可以了
三、PO设计模式
整理一下python selenium自动化测试实践中使用较多的po设计模式。
为什么要用PO
基于python selenium2开始开始ui自动化测试脚本的编写不是多么艰巨的任务。只需要定位到元素,执行对应元素的操作即可。
下面我们看一下这个简单的脚本实现百度搜索。
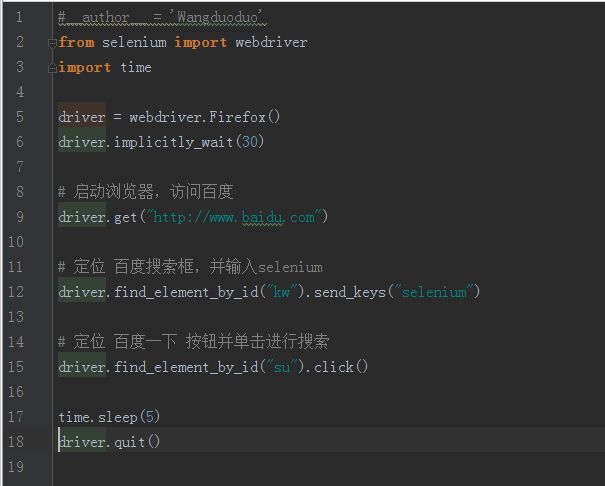
从上述代码来看,我们所能做的就是元素的定位,然后进行键盘输入或鼠标动作。就这个小程序而已,维护起来看起来是很容易的。
但随着时间的迁移,测试套件将持续的增长。脚本也将变的越来越多。如果我们需要维护10个页面,100个页面,甚至1000个呢?
那么页面元素的任何改变都会让我们的脚本维护变得繁琐复杂,而且变得耗时易出错。
那怎么解决呢?ui自动化中,常用的一种方式,引入Page Object(PO):页面对象模式来解决,po能让我们的测试代码变得可读
性更好,可维护性高,复用性高。
PO是什么:
1、页面对象模型(PO)是一种设计模式,用来管理维护一组web元素的对象库
2、在PO下,应用程序的每一个页面都有一个对应的page class
3、每一个page class维护着该web页的元素集和操作这些元素的方法
4、page class中的方法命名最好根据对应的业务场景进行,例如通常登录后我们需要等待几秒钟,
我们可以这样命名该方法:waitingForLoginSuccess()。
下面我们看下PO的代码目录组织示例:

PO的优势
1、PO提供了一种业务流程与页面元素操作分离的模式,这使得测试代码变得更加清晰。
2、页面对象与用例分离,使得我们更好的复用对象。
3、可复用的页面方法代码会变得更加优化
4、更加有效的命名方式使得我们更加清晰的知道方法所操作的UI元素。例如我们要回到首页,
方法命名为:gotoHomePage(),通过方法名即可清晰的知道具体的功能实现。
PO实现示例
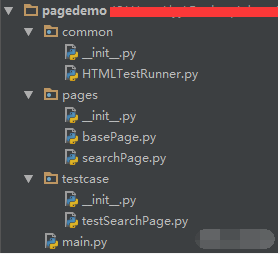
下面看下使用PO设计模式构建的百度搜索用例,先看下代码组织结构如下:
#basePage.py代码如下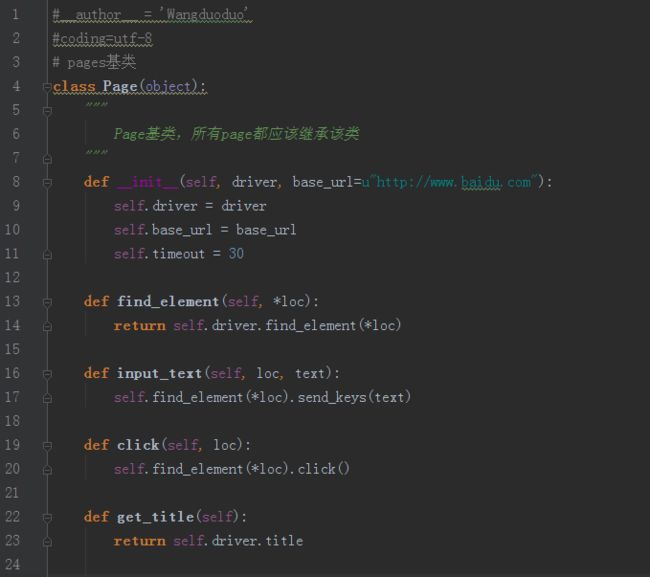
#searchPage.py代码如下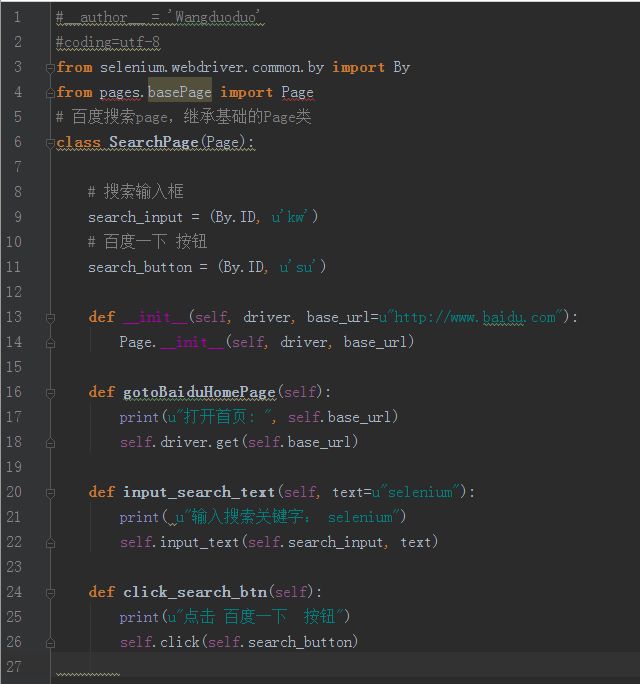
#testSearchPage.py代码如下
python selenium自动化测试实践中使用较多的po设计模式。 Page Object(PO):页面对象模式来解决,po能让我们的测试代码变得可读性更好,可维护性高,复用性高。 PO是什么: 1、页面对象模型(PO)是一种设计模式,用来管理维护一组web元素的对象库 2、在PO下,应用程序的每一个页面都有一个对应的page class 3、每一个page class维护着该web页的元素集和操作这些元素的方法 4、page class中的方法命名最好根据对应的业务场景进行,例如通常登录后我们需要等待几秒钟,我们可以这样命名该方法waitingForLoginSuccess()。 下面我们看下PO的代码目录组织示例:
PO的优势 1、PO提供了一种业务流程与页面元素操作分离的模式,这使得测试代码变得更加清晰。 2、页面对象与用例分离,使得我们更好的复用对象。 3、可复用的页面方法代码会变得更加优化 4、更加有效的命名方式使得我们更加清晰的知道方法所操作的UI元素。例如我们要回到首页,方法命名为:gotoHomePage(),通过方法名即可清晰的知道具体的功能实现。
四、数据驱动模式
数据驱动模式的测试好处相比普通模式的测试就显而易见了吧!使用数据驱动的模式,可以根据业务分解测试数据,只需定义变量,使用外部或者自定义的数据使其参数化,从而避免了使用之前测试脚本中固定的数据。可以将测试脚本与测试数据分离,使得测试脚本在不同数据集合下高度复用。不仅可以增加复杂条件场景的测试覆盖,还可以极大减少测试脚本的编写与维护工作。
下面将使用Python下的数据驱动模式(ddt)库,结合unittest库以数据驱动模式创建百度搜索的测试。
ddt库包含一组类和方法用于实现数据驱动测试。可以将测试中的变量进行参数化。
可以通过python自带的pip命令进行下载并安装:pip install ddt .
一个简单的数据驱动测试
为了创建数据驱动测试,需要在测试类上使用@ddt装饰符,在测试方法上使用@data装饰符。@data装饰符把参数当作测试数据,参数可以是单个值、列表、元组、字典。对于列表,需要用@unpack装饰符把元组和列表解析成多个参数。
下面实现百度搜索测试,传入搜索关键词和期望结果,代码如下:
import unittest
from selenium import webdriver
from ddt import ddt, data, unpack
@ddt
class SearchDDT(unittest.TestCase):
'''docstring for SearchDDT'''
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com")
# specify test data using @data decorator
@data(('python', 'PyPI'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value)
search_button = self.driver.find_element_by_id('su')
search_button.click()
tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag)
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2) 在test_search()方法中,search_value与expected_result两个参数用来接收元组解析的数据。当运行脚本时,ddt把测试数据转换为有效的python标识符,生成名称为更有意义的测试方法。结果如下:
使用外部数据的数据驱动测试
如果外部已经存在了需要的测试数据,如一个文本文件、电子表格或者数据库,那也可以用ddt来直接获取数据并传入测试方法进行测试。
下面将借助外部的CSV(逗号分隔值)文件和EXCLE表格数据来实现ddt。
通过CSV获取数据
同上在@data装饰符使用解析外部的CSV(testdata.csv)来作为测试数据(代替之前的测试数据)。其中数据如下:
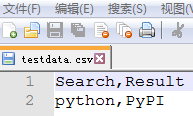
接下来,先要创建一个get_data()方法,其中包括路径(这里默认使用当前路径)、CSV文件名。调用CSV库去读取文件并返回一行数据。再使用@ddt及@data实现外部数据驱动测试百度搜索,代码如下:
import csv, unittest
from selenium import webdriver
from ddt import ddt, data, unpack
def get_data(file_name):
# create an empty list to store rows
rows = []
# open the CSV file
data_file = open(file_name, "r")
# create a CSV Reader from CSV file
reader = csv.reader(data_file)
# skip the headers
next(reader, None)
# add rows from reader to list
for row in reader:
rows.append(row)
return rows
@ddt
class SearchCSVDDT(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com")
# get test data from specified csv file by using the get_data funcion
@data(*get_data('testdata.csv'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value)
search_button = self.driver.find_element_by_id('su')
search_button.click()
tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag)
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)测试执行时,@data将调用get_data()方法读取外部数据文件,并将数据逐行返回给@data。执行的结果也同上~
通过Excel获取数据
测试中经常用Excle存放测试数据,同上在也可以使用@data装饰符来解析外部的CSV(testdata.csv)来作为测试数据(代替之前的测试数据)。其中数据如下:
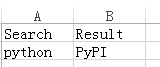
接下来,先要创建一个get_data()方法,其中包括路径(这里默认使用当前路径)、EXCEL文件名。调用xlrd库去读取文件并返回数据。再使用@ddt及@data实现外部数据驱动测试百度搜索,代码如下:
import xlrd, unittest
from selenium import webdriver
from ddt import ddt, data, unpack
def get_data(file_name):
# create an empty list to store rows
rows = []
# open the CSV file
book = xlrd.open_workbook(file_name)
# get the frist sheet
sheet = book.sheet_by_index(0)
# iterate through the sheet and get data from rows in list
for row_idx in range(1, sheet.nrows): #iterate 1 to maxrows
rows.append(list(sheet.row_values(row_idx, 0, sheet.ncols)))
return rows
@ddt
class SearchEXCLEDDT(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.driver.get("https://www.baidu.com")
# get test data from specified excle spreadsheet by using the get_data funcion
@data(*get_data('TestData.xlsx'))
@unpack
def test_search(self, search_value, expected_result):
search_text = self.driver.find_element_by_id('kw')
search_text.clear()
search_text.send_keys(search_value)
search_button = self.driver.find_element_by_id('su')
search_button.click()
tag = self.driver.find_element_by_link_text("PyPI").text
self.assertEqual(expected_result, tag)
def tearDown(self):
self.driver.quit()
if __name__ == '__main__':
unittest.main(verbosity=2)与上面读取CVS文件一样,测试执行时,@data将调用get_data()方法读取外部数据文件,并将数据逐行返回给@data。执行的结果也同上~
如果想从数据库的库表中获取数据,同样也需要一个get_data()方法,并且通过DB相关的库来连接数据库、SQL查询来获取测试数据。
五、面向接口编程设计模式
让我们再重申一下:Python是一种具有动态类型和动态绑定的高级编程语言。我将它描述为一个强大的高级动态语言。许多开发人员都喜欢Python,因为它具有清晰的语法、结构良好的模块和包,以及巨大的灵活性和广泛的现代功能。
在Python中,并不要求您写的类和对象进行实例化。如果您的项目中不需要复杂的结构,则可以只编写函数。更好的是,您可以编写一个平面脚本来执行一些简单而快速的任务,而不需要构建代码。
与此同时,Python是面向对象的100%语言。那是什么意思呢?简单地说,Python中的一切都是一个对象。 函数是对象,第一类对象(无论什么意思)。关于函数是对象的这个事实很重要,所以请记住它。
所以,您可以在Python中编写简单的脚本,或者只是打开Python终端,并在那里执行语句(这非常有用!)。但同时,您可以创建复杂的框架、应用程序、库等。您可以在Python中做这么多。当然还有一些限制,但这不是本文的主题。
然而,由于Python是如此强大和灵活,我们在编程时需要一些规则(或模式)。所以,让我们看看什么是模式,以及它们与Python的关系。我们还将着手实施一些基本的Python设计模式。
为什么Python对模式有好处?
任何编程语言对模式都有益。实际上,应该在任何给定的编程语言的上下文中考虑模式。模式,语言语法和类型都对我们的编程产生了限制。来自语言语法和语言本质(动态,功能,面向对象等)的限制可能与其背后存在的原因不同。模式的限制是有原因的,它们是有目的的。这是模式的基本目标; 告诉我们如何做到某事,以及怎么样会做不到。稍后我们将讨论模式,特别是Python设计模式。
Python是一种动态和灵活的语言。Python设计模式是利用其巨大潜力的好方法。
Python的理念建立在思想最好的做法之上。Python是一种动态语言(我已经说过了吗?),因此,已经实现了一些流行的设计模式,其中包含几行代码。一些设计模式是内置在Python中,所以即使不知道,我们也可以使用它们。由于语言的本质,不需要其他模式。
例如,Factory是一种结构化的Python设计模式,其旨在创建新对象,并在用户那儿隐藏实例化逻辑。但是在Python中创建对象是动态的,所以不需要像Factory这样添加。当然,如果您愿意,您可以自由地实现它。可能有些情况真的很有用,但它们是一个例外,而不是规范。
Python的哲学有什么好处?我们从这开始(在Python终端中探索它):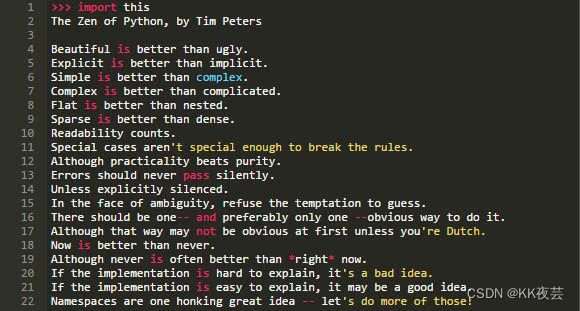
这些可能不是传统意义上的模式,但这些是以最优雅和最有用的方式定义“Pythonic”编程方法的规则。
我们还有PEP-8编码指南,有助于构建我们的代码。对我而言,当然有一些适当的例外。顺便说一句,PEP-8本身也鼓励这些例外:
但最重要的是:知道何时不一致 - 有时风格指南并不适用。如有疑问,请用最好的判断。看看其他的例子来决定什么看起来最好。不要犹豫,去问!
将PEP-8与Python的Zen(也是PEP - PEP-20)相结合,您将拥有创建可读和可维护代码的完美基础。添加设计模式,您已准备好创建具有一致性和可演变性的各种软件系统。
Python设计模式
什么是设计模式?
一切从四人帮(GOF)开始。如果您不熟悉GOF,请快速进行在线搜索。
设计模式是解决众所周知问题的常用方式。两个主要原则是基于GOF定义的设计模式:
面向接口编程,而不是面向实现编程
组合优于继承
从Python程序员的角度,我们来仔细看看这两个原则。
面向接口编程,而不是面向实现编程
想想Duck Typing。在Python中,我们不喜欢根据这些接口定义接口和程序类,是这样吗?但是,听我说!这并不意味着我们不会考虑接口,实际上我们一直在做这种Duck Typing。
让我们来谈谈一下臭名昭着的Duck Typing方法,看看它是如何适应这种范式的:面向接口编程。
如果它看起来像个鸭子并且像一个鸭子一样嘎嘎,那它就是一个鸭子!
我们不关心对象的本质,我们不必关心对象是什么; 我们只想知道是否能够做我们需要的(我们只对对象的接口感兴趣)。
对象可以嘎嘎叫吗?好吧,让它嘎嘎叫!
我们为鸭定义了一个接口吗?没有!我们是否面向接口编程而不是面向实现?是! 而且,我觉得这很好。
正如Alex Martelli在他关于Python中的设计模式的众所周知的演讲中指出的,“学会鸭子类型需要一段时间,但是以后可以节省您大量的工作!”
组合优于继承
现在这就是我所说的Pythonic原理!与在其他类中包装一个类(或更多的是几个类)相比,我创建了更少的类/子类。
不是这样做:
我们可以这样做:
优点很明显。我们可以限制包装类的方法是否暴露。我们可以在运行时注入持久化实例!例如,今天它是一个关系型数据库,但是明天可能是任何需要的接口(再次是那些讨厌的鸭子)。
组合对于Python来说是优雅而自然的。
行为模式
行为模式涉及对象之间的通信、对象如何交互以及如何完成给定的任务。根据GOF原则,Python中共有11种行为模式:职能链,命令,解释器,迭代器,中介者,备忘录,观察者,状态,策略,模板方法,访问者。
行为模式处理对象间通信,控制各种对象如何交互和执行不同的任务。
我发现这些模式非常有用,但这并不意味着其他模式作用不大。
Iterator(迭代器)
迭代器被构建进了Python,这是这个语言最强大的特性之一。多年前,我读到别人说是迭代器使Python变得非常优秀,到现在我仍然是这么认为的。如果您对Python迭代器和生成器有足够多的了解,那您就会知道关于这个独特Python模式需要知道的一切。
Chain of responsibility(职能链)
这个模式为我们提供了一种使用不同方式对待一个请求的方法,每种方法都针对请求的特定部分。您知道的,对于好的代码来说,最好的原则之一就是单一职责原则。
每一块代码必须做一件事,并且只能做一件事。
这一原则深深融入了这一设计模式。
例如,如果我们要过滤一些内容,我们可以实现不同的过滤器,每个过滤器都要做一件精确的事情,并且明确定义其过滤类型。这些过滤器可用于过滤令人反感的单词,广告和不适合的视频内容等。

Command(命令)
这是我作为程序员实现的Python设计模式之一。这提醒了我:模式不是被发明的,而是被发现的。他们存在,我们只需要找到并使用它们。很多年前为了实现我们的一个很大的项目我发现了这一点:一个特殊的所见即所得的XML编辑器。在代码中集中使用这个模式后,我在另外一些网站上看到了更多关于它的内容。
出于某些原因,我们需要从准备执行的内容开始,然后在需要时执行该命令模式。这样的好处是在这种方式下封装的动作可以使Python开发人员添加与执行操作相关的其他功能,例如撤消、重做或者保留操作历史等。
让我们看一下简单但经常使用的例子:

Creational Patterns(创造者模式)
首先需要指出的是创建者模式在Python中并不常用。为什么?因为Python语言本身的动态性质。
某位比我更有智慧的人曾经说过工厂方法是内置在Python中的。这意味着语言本身为我们提供了一种可以以足够优雅的方式创建对象的全部灵活性; 我们很少需要在这之上实现任何东西,如单例和工厂方法。
在一个Python设计模式教程中,我发现了有关创造者模式的描述,它是这样来声明的“模式提供了一种在隐藏创建逻辑的同时创建对象的方法,而不是使用new运算符直接实例化对象”。
它恰到好处地总结了这个问题:我们不需要在Python中使用new运算符!
不管怎样,让我们来看下如何实现其中的某一小部分,看下使用这样的模式我们能否从中获得好处。
Singleton(单例)
当我们要保证运行时只有一个给定类的实例存在时,可以使用Singleton模式。在Python中我们是否真的需要这个模式? 根据我的经验,简单创建一个实例并且随后使用它比实现单例模式更为容易。
但是如果您想实现它,这里有一个好消息:在Python中,我们可以改变实例化过程(以及其他任何东西)。记得我之前提过的__new__()方法吗?就是它了:
在这个示例中,Logger是一个单例。
在Python中使用单例模式有以下这些备选方案:
使用模块
在应用程序的顶层创建一个实例,可以是配置文件
将实例传递给需要它的每个对象。这是一个依赖注入,它是一个强大而容易掌握的机制。
Dependency Injection(依赖注入)
我不打算讨论依赖注入是否是一种设计模式,但我会说这是一个实现松耦合的非常好的机制,它有助于让我们的应用变的更加可维护和可扩展。把它和鸭子类型结合起来然后力量就总是会与您同在。
鸭子?人类?Python都不关心。它灵活得很!
我之所在这篇文章的创造者模式部分列出来是因为它处理了何时(或者更好是:何地)创建对象这个问题。它是在外部创造的。更准确的说,对象并不是在我们使用它的地方创建的,所以依赖关系也不会在消费它的地方创建。消费者代码接收这些外部的对象并使用它。更多参考,请阅读这个Stackoverflow问题最受欢迎的答案。
这是一个关于依赖注入很好的解释,而且它给了我们关于这个特殊技术一个很好的想法。基本上,答案解释了以下示例的问题:不要自己从冰箱里面拿东西来喝,而是声明一个需要。告诉您的父母您需要在午餐喝点东西。
Python为我们提供了全部需要的东西并且实现起来很简单。想一下它在Java和C#其他语言中可能的实现,您将很快意识到Python的美丽。
让我们来看一个简单的关于依赖注入的例子:
我们在Command这个类中注入了authenticator和authorizer方法。Command类所需要的是成功地执行他们,而无须担心他们实现的细节。这样的话,我们可以在Command类中使用任何我们在运行时决定使用的认证和授权机制。
我们已经展示了如何通过构造函数注入依赖关系,但是我们可以通过直接设置对象属性来轻松地注入它们,从而解锁更多的潜力:
关于依赖注入还有很多的东西要学;例如,好奇的人会去搜索IoC。
但是在您这样做之前,请阅读Stackoverflow上的另一个回答,对于这个问题投票最多的回答。
还有,我们只是演示了如何在Python中只使用内置的语言功能来实现这个美妙的设计模式。
让我们不要忘记这一切的意义:依赖注入技术允许非常灵活和容易的单元测试。想象一下,您可以随时更改数据存储的架构。模拟数据库将会变成一个微不足道的任务,不是吗?有关进一步的信息,您可以查看Toptal的Python模拟简介。
您可能也会想研究原型、生成器和工厂方法设计模式。
结构化模式
Facade(外观模式)
这可能是最为出名的Python设计模式。
假设您有一个系统有着大量的对象。每一个对象都提供了丰富的接口方法 。您可以使用这个系统做很多很多事情,但是如何简化这个接口呢?为什么不添加一个接口对象来暴露出所有API方法的精心设计的子集呢?用Facade(外观模式)!
Facade(外观模式)是一个优雅的Python设计模式。它是精简接口的一个完美方式。
Python外观模式示例:
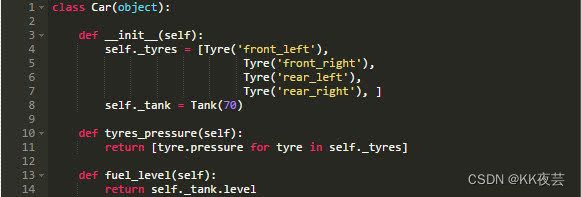
没有什么惊喜,也没有技巧,Car类是一个外观模式,就是这样。
Adapter(适配器)
如果说外观模式用于精简接口,那么适配器就是关于修改接口。就像当系统期待鸭子时却只有牛一样。
假设您有一个将信息记录到给定目的地的工作方法。您的方法期望目标有一个write()方法(例如,每个文件对象都有)。
我会说这是一个写得很好的带依赖注入的方法,它拥有巨大的扩展能力。假设您想要纪录到某些UDP套接字中而不是某个文件里,您知道如何打开这个UDP套接字,但唯一的问题是套接字对象没有write()方法。您需要一个适配器!

但是为什么我发现适配器如此重要?好吧,当它有效地和依赖注入结合时,它就会给予我们极大的灵活性。当我们可以实现一个适配器并将新接口转换为众所周知的接口时,为什么要修改我们经过验证的代码来支持新的接口?
由于桥接和代理设计模式与适配器的相似性,您还应该了解和掌握它们。想一下在Python中实现他们是多么的简单,并且考虑一下在您的项目中可能通过哪些不同的方式来使用它们。
Decorator(装饰者模式)
哦,我们真是太幸运了!装饰者模式真的很好,而且我们也已经集成到了这门语言中。在Python中我最喜欢的是使用它来教我们使用最佳的实践。这并不是指我们不会意识到最佳实践(尤其和设计模式),但不管怎样使用Python 我感觉我正在遵循着最佳实践。就我个人而言,我发现Python的最佳实践是非常符合直觉的,这是新手和精英开发人员都赞赏的东西。
装饰者模式是关于引入额外的功能,特别的是它没有使用继承。
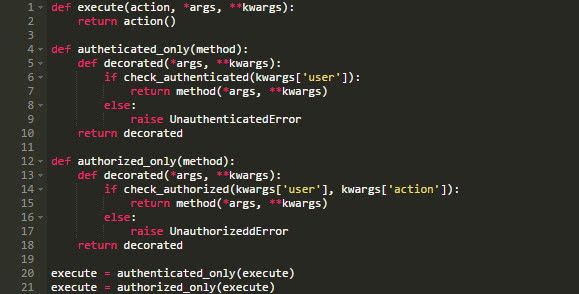
那么,让我们来看下如何不用内建的Python功能来装饰一个方法。以下是一个直截了当的示例。
这里不太好的是execute方法不仅仅是执行某些功能,还做了别的事情。我们没有遵循单一职责原则。
像下面这样简单编写会好点:
我们可以在另一个地方,在装饰者模式中实现任何授权和认证功能,如下所示:
现在的execute()方法是:
简单易读
只做一件事(至少在看代码时)
用身份验证装饰
装饰有授权
我们使用Python集成的装饰者语法编写类似的代码:
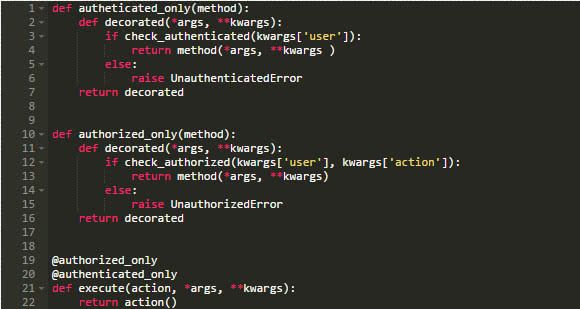
重要的是要注意,您没有限制像装饰者那样的活动。一个装饰者可能涵盖了整个类。唯一的要求是它们必须是可调用的。但对此我们毫无疑问;我们只需要定义__call__(self)方法。
您可能也想再进一步了解Python的函数工具(functools)模块。有待发现的东西还有很多!
结论
我已经展示了使用Python的设计模式是多么的自然和容易,而且我也展示了如何在Python中简单的编程。
“简单比复杂好,”记得吗?也许您已经注意到,没有一个设计模式是完全且正式描述的。没有展示复杂全面的实现。您需要“感觉”并以最适合您的风格和需要的方式实施它们。Python是一种伟大的语言,它给了您创作灵活、可重用代码的全部力量。
然而,它给您的远胜于这些。它给了您编写非常糟糕的代码的“自由”。不要这么做!不要重复(DRY),并且不要写超过80个字符的代码行。还有不要忘了在合适的地方使用设计模式;它是从别人那里学习并从他们丰富的免费经验中获益的最好方式之一。