阿里云RDMA通信库XRDMA论文详解
RDMA(remote direct memory access)即远端直接内存访问,是一种高性能网络通信技术,具有高带宽、低延迟、无CPU消耗等优点。RDMA相比TCP在性能方面有明显的优势,但在编程复杂度上RDMA verbs却比TCP socket复杂一个数量级。
开源社区和各大云厂商在RDMA通信库方面都有不少尝试,今天我们精读阿里云的RDMA通信库论文X-RDMA: Effective RDMA Middleware in Large-scale Production Environments,来看看阿里云是如何使用RDMA技术的。
摘要和背景介绍
(2019年)RDMA技术在数据中心越来越受欢迎,当前最新的ConnectX-6 Infiniband网卡可以支持200Gbps的带宽和极低的延迟(0.6微妙)。RDMA技术也在越来越多的系统中得到应用,比如KV存储、文件系统、图计算等。
但是在规模生产环境中,RDMA的实际收益还不够明显,一个重要原因是RDMA编程复杂性太高,想用好它很难,RDMA verbs编程有一堆的新概念(QP,MR,PD,RQ,SQ,CQ,……),这根传统socket编程迥异。想要直接把已有应用直接迁移到RDMA更是不可能。
使用RDMA需要解决以下问题:
- 问题定位困难
- 大规模集群中存在性能抖动和拥塞
- 大消息会增加incast拥塞概率
本文分享我们关于大规模RDMA部署的经验,以及如何启发我们设计出RDMA通信中间件X-RDMA。X-RDMA很多功能是业务需求推动的,比如稳健性、高效的资源管理以及用于调试和性能调整的便捷工具。
X-RDMA已经在阿里大量使用近两年(16年至今),几乎所有的基于RDMA的应用都在使用X-RDMA,包括云数据库和存储系统。X-RDMA收益如下:
- 网络吞吐提升24%
- 网络延迟降低5%(相比于ucx-am-rc)
RDMA的编程模型
原生以太网无法满足我们的网络性能要求,而RDMA可以提供:
- 超低延迟(2微秒)
- 高吞吐
- 零拷贝
- 不经过内核
因此RDMA可以降低传统TCP协议栈的1. 上下文切换开销,2. 协议处理开销,3. 数据拷贝开销。
RDMA提供RC、UD、RD等多种连接,同时提供两类数据语义:
- 单边语义:Write/Read/Atomic,这类语义不需要对端CPU参与。
- 双边语义:Send/Recv,这类语义跟传统以太网有些相似,需要对端CPU配合做一些事情(但不需要CPU做协议栈处理)。
RDMA verbs编程有一堆的新概念,跟socket编程迥异。使用verbs编写一个简单的echo server/client程序需要200行以上,流程十分繁琐。关于RDMA基础介绍感兴趣的同学可以阅读 李豪:RDMA入门介绍。
阿里的数据中心网络部署
阿里数据中心网络是基于以太网的clos网络,由三层交换机组成,分别是spine、leaf、ToR,拓扑如下:
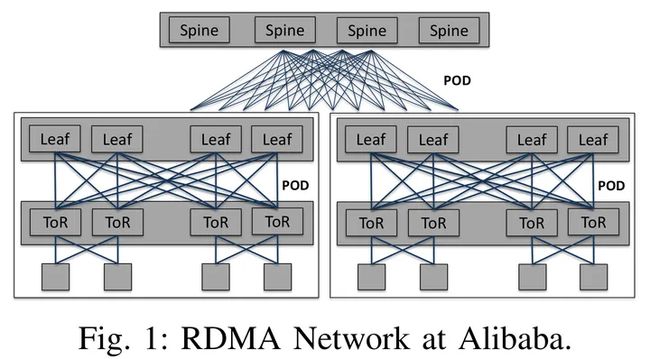
每个ToR下面有40个节点,每台机器有一张双口网卡,上联两台ToR。
阿里的RDMA使用场景
RDMA有三种实现方式:李豪:什么是RDMA技术
- Infiniband
- RoCE/RoCEv2
- iWARP
目前数据中心广泛使用的是RoCEv2,RoCEv2依赖PFC保证网络无损,同时通过DCQCN做到端到端的拥塞的控制。关于DCQCN可阅读李豪:RDMA拥塞控制经典论文DCQCN。
本论文主要介绍三个阿里有代表性的应用:ESSD、XDB、PolarDB。Pangu一个阿里云开发的高可靠、高可用、高性能的分布式文件系统,类似于Ceph。Pangu中每个服务器上有两个核心组件:block server和chunk server。
block server从前端接收数据(ESSD、XDB等),然后将数据以三副本形式分发给不同机器上的chunck server。block server和chunk server通过RDMA进行fullmesh通信。

大规模生产环境遇到的问题
大规模生产环境使用RDMA主要遇到以下问题:
- RDMA编程复杂:verbs编程比socket编程复杂很多,一个简单的ping-pong程序RDMA需要200行代码,而socket只需要50行。
- RDMA可扩展性挑战:主要体现在几个方面:a. RDMA资源占用会随着集群规模增加,比如连接数和内存的占用。Pangu中每个block server上有N个线程,每个chunk server上有M个线程,而每两个线程之间都要建立fullmesh的链接,换算下来每个chunk server的内存占用为 �∗�∗�����������_������∗��_����ℎ∗���_���� 。b. 大规模RDMA集群存在拥塞和严重的incast。c. 建联速度太慢,通过rdmacm建联平均需要花4毫秒,而TCP只需要100微秒。
- RDMA健壮性问题:体现在 a. RDMA单边操作无法感知对端应用层的处理状态,这给内存管理带来挑战,因为对端接收完成之前发送方的buffer不能释放,两边配合不好会导致RNR出现。b. RDMA无法感知通信的对端是否还活着(这一点跟TCP很不同,TCP会有内核做链接保活,RDMA是kernel by pass的,即使对端挂了,本地也不会受到任何通知),这会导致链接泄露,跟这个链接相关的资源也无法释放。
- RDMA问题排查工具缺失:RDMA没有类似netstat和pingmesh之类的工具,也没有类似netfilter的工具。
基于以上挑战我们设计了X-RDMA通信库。
X-RDMA设计思想
整体架构
X-RDMA有三层抽象,包含16个核心组件:
- 最上层:提供简单的数据结构和API抽象,屏蔽RDMA verbs编程复杂性。
- 中间层:提供1. 可靠的协议拓展(KeepAlive),2. 资源管理(qp管理,内存管理,消息管理等),3. flow control, 4. 性能分析工具(trace, statistic, config, filter, mock, monitor)等功能。
- 底层:timer、task、fd数据结构。
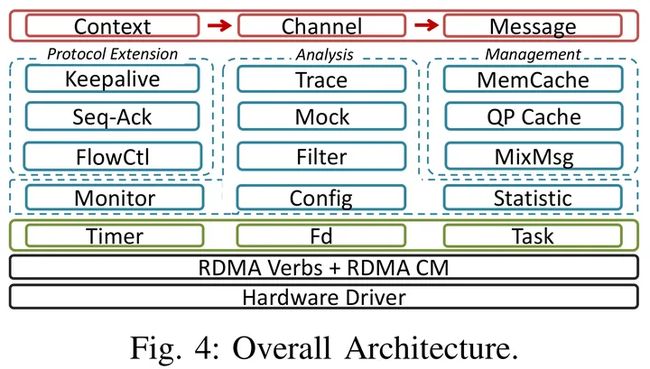

X-RDMA API
线程模型
X-RDMA采用run-to-complete线程模型,从而避免了数据路径上锁/原子变量/系统调用的使用,代价就是所有的核心资源都是线程粒度的,即每个线程都要有单独的内存池、链接池等。导致的后果就是内存占用和连接数的膨胀。但在存储场景下为了更好的性能多使用一些资源是可以接受的。
思考:存储之外的场景适合使用R2C的设计吗?
X-RDMA混合使用epoll和busy polling 来平衡CPU占用和响应速度,当有消息到来或者timer超时是切换到busy polling模式,当长时间没有事件时则切换到epoll模式。KeepAlive和统计功能都是注册到timer上的事件。
消息模型
阿里大部分应用通信采用RPC模式,即request-response模式。X-RDMA实现了RPC的通信模式。
由于RDMA操作的内存需要reg_mr,这个动作是将虚地址pin在物理内存中防止page换出,然后将页表项也发给网卡,显然这个动作比较耗时间。为了降低内存准备的开销和过多的内存占用,X-RDMA将消息分成两类分别处理,这种划分类似于MPI中的eager和rendezvous模式:
- 小消息:小消息对延迟敏感,默认将4KB以内的消息称为小消息。采用RDMA SEND/RECV完成收发,两侧各只需要下发一个WR,效率比较高。但是这要求接收方率先准备好接收buffer,为避免较多的内存占用,该模式只能用于小消息收发。
- 大消息:大消息对吞吐敏感,大消息收发通过多轮协商完成,步骤如下:a. 发送方发送一个WR告知接收方有数据要发送,b. 接收方按需准备好接收buffer,c. 接收方通过RDMA READ读取数据。
每个线程的工作流
X-RDMA采用run-to-complete的线程模型,因此每个线程都有一个单独的工作流,如下图:

上图中信息很丰富,做几点说明:
- X-RDMA支持event模式和polling模式,可通过xrdma_get_event_fd()的方式获取polling所需的fd,然后调用xrdma_process_event()进行事件处理。
- X-RDMA发送消息是异步非阻塞的,因此可能有多个消息在同时发送,被称为inflight messages,但是X-RDMA会限制inflight messages不超过CQ深度。
- 链接的心跳信息依赖于timer超时事件,X-RDMA会自动发送keepAlive信息做链接保活。
资源管理
为了1. 提升性能,2. 降低内存占用,3. 缩短建联时间,X-RDMA为每个线程维护内存池和连接池。
- 内存池:RDMA内存池主要是管理MR(memory region),由于网卡可以管理的MR数量是有限的,因此过多的MR不仅可能会导致性能下降,甚至会导致超过网卡MR上限而无法注册新内存,因此X-RDMA采用4MB的粒度来注册MR,以此来降低MR的数量。
- 连接池:RDMA建联比TCP建联耗时更长(4ms VS. 100us),X-RDMA为每个线程维护一个qp cache来降低建联开销。如果一个链接断开,则会把qp设置为IBV_QPS_RESET状态,并放到qp cache中,以便后续复用。
X-RDMA没有使用CM建联,而是自己实现的一套带外建联,论文评估章节有说明。
RDMA协议拓展
X-RDMA从以下几个方面对RDMA做了拓展:
- KeepAlive
- Seq-Ack Window
- Flow Control
KeepAlive
TCP/IP协议栈会由内核发送心跳消息检查链接是否存活,但RDMA协议栈没有内核参与,因此无法由内核自动发送心跳信息。链接保活检查时必须的,因为有很多的原因会导致链接泄露。当一个链接在S毫秒内没有没有和对端通信时,X-RDMA会触发KeepAlive机制,通过RDMA Write探测链接是否存活,Write的payload是零字节,如果对端还存活,网卡会自动恢复ACK报文。
Seq-Ack Window
X-RDMA的seq-ack window机制主要出于以下考量:
- 网卡的ack只能保证数据已经到达对端,但并不能保证接收侧的应用程序已经处理了这些数据报文。
- 发送小消息时X-RDMA需要接收方提前准备好接收buffer,如果消息数量很多而接收方的buffer数量不足,则会导致RNR(request not ready),这不仅会导致性能下降,甚至会导致链接断开。
通过X-RDMA的seq-ack window机制可以避免RNR出现,具体做法是:收发两边分别有一个缓存in-flight请求的ring buffer窗口,窗口大小设置为IO depth。每次发送数据时(RDMA Write/Send)X-RDMA都会将seq-ack编号通过RDMA immediate Data发送给对方。具体算法如下图:

Flow Control
在大规模incast场景下DCQCN并不能很好的工作,具体体现在:
- DCQCN是一种被动控制,在CC起作用之前可能已经出现了性能下降(比如ECN报文还没有返回,交换机buffer就已经出现了丢包)。
- 根据观察,incast导致CNP和PFC会导致网络性能和健壮性的下降。
X-RDMA通过1. 消息分片和2. 消息排队 来协助DCQCN缓解网络拥塞。
- 消息分片:对于大的请求,X-RDMA会把请求按照64KB的粒度进行切分,然后逐片发送。以避免大消息对网卡的阻塞。
- 消息排队:X-RDMA限制同时能发起的WR请求数量为N,多出来的请求放到队列里排队。
上述两种流控算法均实现X-RDMA通信库里,对网卡硬件没有限制。
性能和问题分析框架
X-RDMA提供了众多工具和机制定位各种类型的bug,分析工具如下图:
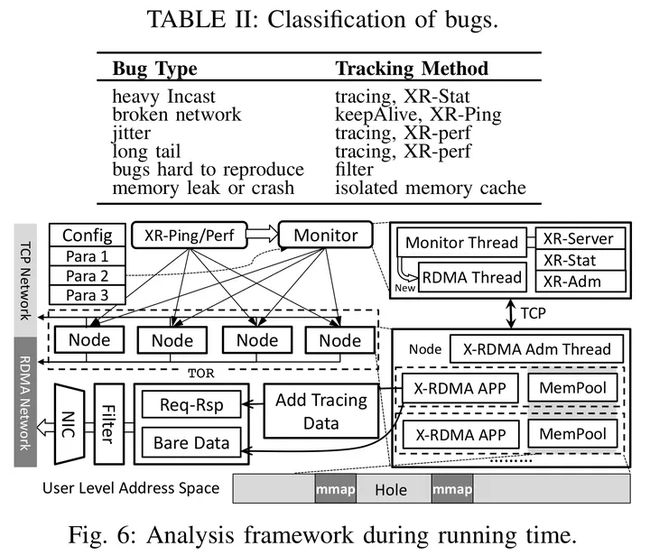
Tracing
X-RDMA数据通路有两种模式,分别是:
- bare-data模式:直接发送用户的原始数据,不做任何的链路追踪。
- req-res模式:会在用户的数据之前加入header,通过header记录必要的信息,用于tracing和问题定位。通过该机制可以计算出网络的RTT。
X-RDMA的tracing功能还可用于:
- 定位网络拥塞
- 发现慢polling:通过记录两次polling之间的时间差,发现慢polling。通常这可能是由于用户工作线程有比较耗时的操作所致。
- 发现执行较慢的代码片
Monitoring
我们提供三种工具弥补RDMA工具不足的问题,分别是:
- XR-Stat:对标TCP的netstat
- XR-Ping:对标TCP的ping,以及RDMA自己的rping(rping功能太简单了)
- XR-Perf:用于做RDMA性能和压力测试。
性能调优
X-RDMA通信库有很多参数可以调整,可分为两类:1. 运行时动态可调的(通过XR-adm命令控制),以及2. 启动程序是可配置的,具体如下表:
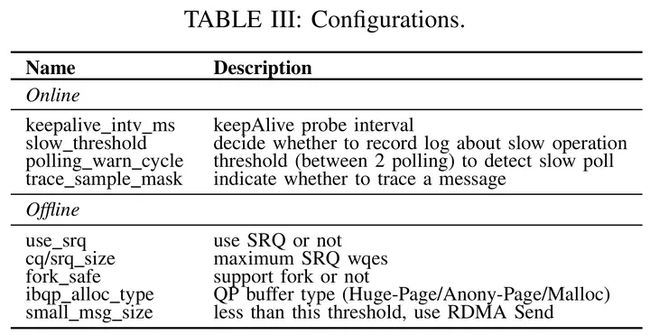
性能评估
(2017)目前阿里有超过4000台服务器部署了X-RDMA,使用RoCEv2协议。最大的一个RDMA集群有4个子集群,每个子集群有256个节点,每个节点有一张双口的25Gbps Mellanox ConnectX4-Lx网卡(总共50Gbps)。
(性能数据略过,具体可参看论文。)
读后总结
本文介绍了阿里X-RDMA的核心设计思想,包含线程模型、消息模型、资源管理、心跳检测、Flow Control等各个维度,对用好RDMA以及设计新的RDMA通信库有很好的参考价值。其Run-to-Complete线程模型大大降低了X-RDMA自身的设计和编程复杂性,在存储等典型场景下有很不错的效果。
美中不足的是X-RDMA没有公开代码,文中介绍的很多细节和工具无法进一步了解。