5.MapReduce之Combiner-预聚合
目录
- 概述
- 本地预计算 Combiner 意义
-
- 实践
-
- 前提
- 代码
- 日志观察
- 结束
概述
在 MR、Spark、Flink 中,常用的减少网络传输的手段。
通常在 Reducer 端合并,shuffle 的数据量比在 Mapper 端要大,根据业务情况及数据量极大时,将大幅度降低效率;且预聚合这种方式也是有其缺点,不能改变业务最终的逻辑,否则会出现,计算结果不正确的情况。
本地预计算 Combiner 意义
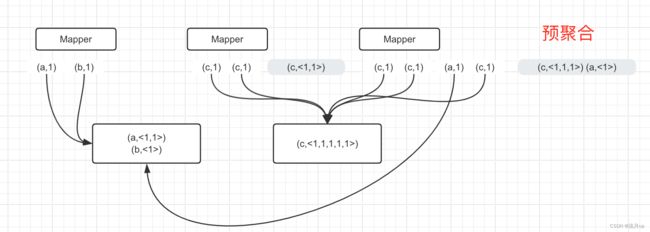
如下图,可以清晰看出,预聚合和在 Reducer 端合并的数据量差距,数据量小时,作用不明显,当接近 TB 级时,就非常不一样了。
实践
前提
注意:前提是不能改变最终的业务逻辑。下面是一个求平均数的例子
举例:
求平均数
3,5,7 --> 15/3 = 5
2,6 -->8/2=4
(5+4)/2=4.5
(3+5+7+2+6)/5=4.6
最终结果不对
代码
注意:这里的代码为了区分,Combiner 是单独写成一个类,实际使用中,直接使用 Reducer 实现,就可以了。官方的单词统计,就是这样使用的。可以对比一下。
public class WordCountCombiner {
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
String str = value.toString();
String[] split = str.split(",");
IntWritable ONE = new IntWritable(1);
for (String word : split) {
context.write(new Text(word), ONE);
}
}
}
public static class WordCountCombinerExample extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count = count + value.get();
}
context.write(key, new IntWritable(count));
}
}
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable value : values) {
count = count + value.get();
}
context.write(key, new IntWritable(count));
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration configuration = new Configuration();
String sourcePath = "data/wc.data";
String distPath = "downloadOut/wc-out.data";
FileUtil.deleteIfExist(configuration, distPath);
Job job = Job.getInstance(configuration, "word count");
job.setJarByClass(WordCountCombiner.class);
// 注意此
job.setCombinerClass(WordCountCombinerExample.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(sourcePath));
FileOutputFormat.setOutputPath(job, new Path(distPath));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
日志观察
注意:观察下面注释的说明信息,预聚合和未预聚合的区别就比较明显,易观察到了。
Map-Reduce Framework
Map input records=3
Map output records=5
Map output bytes=52
Map output materialized bytes=46
Input split bytes=113
# 此处就是 Combine
# 注销此处, recoreds =0 job.setCombinerClass(WordCountCombinerExample.class);
Combine input records=5
Combine output records=3
# 对比
Map-Reduce Framework
Map input records=3
Map output records=5
Map output bytes=52
Map output materialized bytes=68
Input split bytes=113
Combine input records=0
Combine output records=0
结束
至此,MapReduce之Combiner-预合并 就结束了,如有疑问,欢迎评论区留言。