mysql(一)
文章目录
-
- DDL
-
- 数据库操作
- 表结构操作
- DML
-
- 新增
- 修改
- 删除
- DQL
-
- 聚合函数
- where与having区别
- 分页查询
- 流程控制函数
SQL语句通常被分为四大类:

DDL
包括:
1.数据库 - 创建、查询、使用、删除
2.表结构 - 创建(语法、约束、数据类型、设计)、查询、修改、删除
数据库操作
查询所有数据库:show databases;
查询当前数据库:select database();
使用数据库:use 数据库名;
创建数据库:create database [ if not exists ] 数据库名;
删除数据库:drop database [ if exists ] 数据库名;
注意:上述语法中的database,也可以替换成 schema。如:create schema db01;
表结构操作
略
DML
新增
指定字段添加数据:insert into 表名 (字段名1, 字段名2) values (值1, 值2);
全部字段添加数据:insert into 表名 values (值1, 值2, …);
批量添加数据(指定字段):insert into 表名 (字段名1, 字段名2) values (值1, 值2), (值1, 值2);
批量添加数据(全部字段):insert into 表名 values (值1, 值2, …), (值1, 值2, …);
注意:
字符串和日期型数据应该包含在引号中。
修改
修改数据:update 表名 set 字段名1 = 值1 , 字段名2 = 值2 , … [ where 条件 ];
删除
删除数据:delete from 表名 [ where 条件 ];
DQL

聚合函数

语法:
select 聚合函数(字段列表) from 表名 ;
注意:
null值不参与所有聚合函数运算
统计数量可以使用:count(*) count(字段) count(常量),推荐使用count(*),因为被优化过效率高。
where与having区别
1.执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
2.判断条件不同:where不能对聚合函数进行判断,而having可以。
注意:
1.分组之后,查询的字段一般为聚合函数和分组字段,查询其他字段无任何意义。
2.执行顺序: where > 聚合函数 > having 。
分页查询

select 字段列表 from 表名 limit 起始索引, 查询记录数 ;
注意:
1.起始索引从0开始,起始索引 = (查询页码 - 1)* 每页显示记录数。
2.如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10。
流程控制函数
1.if(条件表达式, true取值 , false取值)
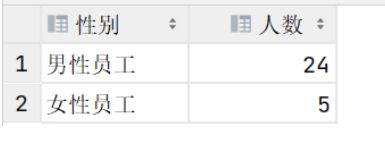
select if(gender=1,'男性员工','女性员工') AS 性别, count(*) AS 人数
from tb_emp
group by gender;
2.case 表达式 when 值1 then 结果1 when 值2 then 结果2 … else result end
select (case job
when 1 then '班主任'
when 2 then '讲师'
when 3 then '学工主管'
when 4 then '教研主管'
else '未分配职位'
end) AS 职位 ,
count(*) AS 人数
from tb_emp
group by job;
