【大数据进阶第三阶段之ClickHouse学习笔记】ClickHouse的简介和使用
1、ClickHouse简介
ClickHouse是一种列式数据库管理系统(DBMS),专门用于高性能数据分析和数据仓库应用。它是一个开源的数据库系统,最初由俄罗斯搜索引擎公司Yandex开发,用于满足大规模数据分析和报告的需求。
开源地址:GitHub - ClickHouse/ClickHouse: ClickHouse® is a free analytics DBMS for big data
1.1 优点
- 灵活的MPP架构,支持线性扩展,简单方便,高可靠性
- 多服务器分布式处理数据 ,完备的DBMS系统
- 底层数据列式存储,支持压缩,优化数据存储,优化索引数据 优化底层存储
- 容错跑分快:比Vertica快5倍,比Hive快279倍,比MySQL快800倍,其可处理的数据级别已达到10亿级别
- 功能多:支持数据统计分析各种场景,支持类SQL查询,异地复制部署
- 海量数据存储,分布式运算,快速闪电的性能,几乎实时的数据分析 ,友好的SQL语法,出色的函数支持
- 磁盘存储数据
- 多核并行处理:多核多节点并行化大型查询
- 在多个服务器上分布式处理:数据可以驻留在不同的分片上,每个分片都可以用于容错的一组副本,查询会在所有分片上进行处理
- 向量化引擎:数据不仅按列式存储,而且由矢量-列的部分进行处理,这使得开发者能够实现高CPU性能
- 实时数据更新:为了快速执行对主键范围的查询,数据使用合并数(MergeTree)进行递增排序
- 支持近似计算
- 数据复制和对数据完整性的支持:使用异步多主复制,写入任何可用的副本后,数据将分发到所有剩余的副本。系统在不同的副本上保持相同的数据,数据在失败后自动恢复
1.2 缺点
- 不支持事务,不支持真正的删除/更新 (批量)
- 不支持高并发,官方建议qps为100,可以通过修改配置文件增加连接数,但是在服务器足够好的情况下
- 不支持二级索引
- 不擅长多表join *** 大宽表,聚合结果必须小于一台机器的内存大小
- 元数据管理需要人为干预 ***
- 尽量做1000条以上批量的写入,避免逐行insert或小批量的insert,update,delete操作
- 不适合Key-value存储,不支持Blob等文档型数据库
- 支持有限操作系统
1.3 应用场景
- 绝大多数请求都是用于读访问的, 要求实时返回结果
- 数据需要以大批次(大于1000行)进行更新,而不是单行更新;或者根本没有更新操作
- 数据只是添加到数据库,没有必要修改
- 读取数据时,会从数据库中提取出大量的行,但只用到一小部分列
- 表很“宽”,即表中包含大量的列
- 查询频率相对较低(通常每台服务器每秒查询数百次或更少)
- 对于简单查询,允许大约50毫秒的延迟
- 列的值是比较小的数值和短字符串(例如,每个URL只有60个字节)
- 在处理单个查询时需要高吞吐量(每台服务器每秒高达数十亿行)
- 不需要事务
- .数据一致性要求较低 [原子性 持久性 一致性 隔离性]
- 每次查询中只会查询一个大表。除了一个大表,其余都是小表
- 查询结果显著小于数据源。即数据有过滤或聚合。返回结果不超过单个服务器内存大小
1.4 ClickHouse 架构
Clickhouse只有1个组件,每个组件即可以接受用户请求进行查询的分发,也可以进行查询的执行。 Clickhouse通过分片和副本实现高可靠,数据通过一定的规则均匀分散到各个Shard中。Clickhouse如果需要支持副本功能,则需要搭建Zookeeper来完成数据的复制。
ClickHouse 采用典型的分组式的分布式架构,具体集群架构如上图所示:

Shard:集群内划分为多个分片或分组(Shard 0 … Shard N),通过 Shard 的线性扩展能力,支持海量数据的分布式存储计算。
Node:每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
ZooKeeper Service:集群所有节点对等,节点间通过 ZooKeeper 服务进行分布式协调。副本: 数据存储副本,在集群模式下实现高可用 , 简单理解就是相同的数据备份,在CK中通过复制集,我们实现保障了数据可靠性外,也通过多副本的方式,增加了CK查询的并发能力。这里一般有2种方式:
(1)基于ZooKeeper的表复制方式;
(2)基于Cluster的复制方式。
由于我们推荐的数据写入方式本地表写入,禁止分布式表写入,所以我们的复制表只考虑ZooKeeper的表复制方案。
Clickhouse的每个节点都是一个类似mysql的数据库实例,可以单独提供local表的读写服务。 Clickhouse没有实现分布式元信息管理,实现的是手动元信息管理,每个节点的元信息可能不一样,因此查询需要发给特定的Clickhouse节点。ClickHouse的分布式查询里,请求节点会将查询改写并转发给所有shard,各shard在做完数据计算后把结果反馈给请求节点,最后在请求节点上再做数据的merge并返回给用户。Clickhouse目前的查询引擎是二阶段汇聚模型,不支持Shuffer的Join和Aggrgation。
2、ClickHouse 核心特性
ClickHouse 为什么会有如此高的性能,获得如此快速的发展速度?下面我们来从 ClickHouse 的核心特性角度来进一步介绍。
2.1 列存储
ClickHouse 采用列存储,这对于分析型请求非常高效。
一个典型且真实的情况是:如果我们需要分析的数据有 50 列,而每次分析仅读取其中的 5 列,那么通过列存储,我们仅需读取必要的列数据。相比于普通行存,可减少 10 倍左右的读取、解压、处理等开销,对性能会有质的影响。这是分析场景下,列存储数据库相比行存储数据库的重要优势。
行存储:从存储系统读取所有满足条件的行数据,然后在内存中过滤出需要的字段,速度较慢。
列存储:仅从存储系统中读取必要的列数据,无用列不读取,速度非常快。
2.2 向量化执行
在支持列存的基础上,ClickHouse 实现了一套面向向量化处理的计算引擎,大量的处理操作都是向量化执行的。
相比于传统火山模型中的逐行处理模式,向量化执行引擎采用批量处理模式,可以大幅减少函数调用开销,降低指令、数据的 Cache Miss,提升 CPU 利用效率。并且 ClickHouse 可利用 SIMD 指令进一步加速执行效率。这部分是 ClickHouse 优于大量同类 OLAP 产品的重要因素。
以商品订单数据为例,查询某个订单总价格的处理过程,由传统的按行遍历处理的过程,转换为按 Block 处理的过程。
2.3 编码压缩
由于 ClickHouse 采用列存储,相同列的数据连续存储,且底层数据在存储时是经过排序的,这样数据的局部规律性非常强,有利于获得更高的数据压缩比。
此外,ClickHouse 除了支持 LZ4、ZSTD 等通用压缩算法外,还支持 Delta、DoubleDelta、Gorilla 等专用编码算法,用于进一步提高数据压缩比。其中 DoubleDelta、Gorilla 是 Facebook 专为时间序数据而设计的编码算法,理论上在列存储环境下,可接近专用时序存储的压缩比,详细可参考 Gorilla 论文。
在实际场景下,ClickHouse 通常可以达到 10:1 的压缩比,大幅降低存储成本。同时,超高的压缩比又可以降低存储读取开销、提升系统缓存能力,从而提高查询性能。
2.4 多索引
列存用于裁剪不必要的字段读取,而索引则用于裁剪不必要的记录读取。ClickHouse 支持丰富的索引,从而在查询时尽可能的裁剪不必要的记录读取,提高查询性能。
ClickHouse 中最基础的索引是主键索引。前面我们在物理存储模型中介绍,ClickHouse 的底层数据按建表时指定的 ORDER BY 列进行排序,并按 index_granularity 参数切分成数据块,然后抽取每个数据块的第一行形成一份稀疏的排序索引。用户在查询时,如果查询条件包含主键列,则可以基于稀疏索引进行快速的裁剪。
这里通过下面的样例数据及对应的主键索引进行说明:
样例中的主键列为 CounterID、Date,这里按每 7 个值作为一个数据块,抽取生成了主键索引 Marks 部分。
当用户查询 CounterID equal ‘h’ 的数据时,根据索引信息,只需要读取 Mark number 为 6 和 7 的两个数据块。
ClickHouse 支持更多其他的索引类型,不同索引用于不同场景下的查询裁剪,具体汇总如下,更详细的介绍参考 ClickHouse 官方文档:
2.5 物化视图(Cube/Rollup)
物化视图是查询结果集的一份持久化存储,所以它与普通视图完全不同,而非常趋近于表。“查询结果集”的范围很宽泛,可以是基础表中部分数据的一份简单拷贝,也可以是多表join之后产生的结果或其子集,或者原始数据的聚合指标等等。所以,物化视图不会随着基础表的变化而变化,所以它也称为快照(snapshot)。如果要更新数据的话,需要用户手动进行,如周期性执行SQL,或利用触发器等机制。
产生物化视图的过程就叫做“物化”(materialization)。广义地讲,物化视图是数据库中的预计算逻辑+显式缓存,典型的空间换时间思路。所以用得好的话,它可以避免对基础表的频繁查询并复用结果,从而显著提升查询的性能。它当然也可以利用一些表的特性,如索引。
Clickhouse的物化视图的导入和查询数据流如上图所示:实线为导入流程,虚线为查询流程。基表数据 导入数据后,会像触发器一样将数据传递并应用到物化视图。查询时需要指定是查物化视图还是查base 表。用户可以直接向物化视图导入数据,此时基表数据不会有变化。Clickhouse数据导入不保证原子 性,同一批数据可能会依次生效,如果导入中途失败,此时数据库已经生效部分数据,此时需要用户重 新导入数据。
2.6 其他特性
除了前面所述,ClickHouse 还有非常多其他特性,抽取列举如下,更多详细内容可参考 ClickHouse官方文档:
- SQL 方言:在常用场景下,兼容 ANSI SQL,并支持 JDBC、ODBC 等丰富接口。
- 权限管控:支持 Role-Based 权限控制,与关系型数据库使用体验类似。
- 多机多核并行计算:ClickHouse 会充分利用集群中的多节点、多线程进行并行计算,提高性能。
- 近似查询:支持近似查询算法、数据抽样等近似查询方案,加速查询性能。
- Colocated Join:数据打散规则一致的多表进行 Join 时,支持本地化的 Colocated Join,提升查询性能。
3、clickhouse的部署
文档:安装 | ClickHouse Docs
3.1 系统要求
ClickHouse可以在任何具有x86_64,AArch64或PowerPC64LE CPU架构的Linux,FreeBSD或Mac OS X上运行。
官方预构建的二进制文件通常针对x86_64进行编译,并利用SSE 4.2指令集,因此,除非另有说明,支持它的CPU使用将成为额外的系统需求。下面是检查当前CPU是否支持SSE 4.2的命令:
$ grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
要在不支持SSE 4.2或AArch64,PowerPC64LE架构的处理器上运行ClickHouse,您应该通过适当的配置调整从源代码构建ClickHouse。
3.2 可用安装包
3.2.1 DEB安装包
建议使用Debian或Ubuntu的官方预编译deb软件包。运行以下命令来安装包:
sudo apt-get install -y apt-transport-https ca-certificates dirmngr
sudo apt-key adv --keyserver hkp://keyserver.ubuntu.com:80 --recv 8919F6BD2B48D754
echo "deb https://packages.clickhouse.com/deb stable main" | sudo tee \
/etc/apt/sources.list.d/clickhouse.list
sudo apt-get update
sudo apt-get install -y clickhouse-server clickhouse-client
sudo service clickhouse-server start
clickhouse-client # or "clickhouse-client --password" if you've set up a password.
Deprecated Method for installing deb-packages
如果您想使用最新的版本,请用testing替代stable(我们只推荐您用于测试环境)。
你也可以从这里手动下载安装包:下载。
安装包列表:
clickhouse-common-static— ClickHouse编译的二进制文件。clickhouse-server— 创建clickhouse-server软连接,并安装默认配置服务clickhouse-client— 创建clickhouse-client客户端工具软连接,并安装客户端配置文件。clickhouse-common-static-dbg— 带有调试信息的ClickHouse二进制文件。
3.2.2 RPM安装包
推荐使用CentOS、RedHat和所有其他基于rpm的Linux发行版的官方预编译rpm包。
首先,您需要添加官方存储库:
sudo yum install -y yum-utils
sudo yum-config-manager --add-repo https://packages.clickhouse.com/rpm/clickhouse.repo
sudo yum install -y clickhouse-server clickhouse-client
sudo /etc/init.d/clickhouse-server start
clickhouse-client # or "clickhouse-client --password" if you set up a password.
For systems with zypper package manager (openSUSE, SLES):
sudo zypper addrepo -r https://packages.clickhouse.com/rpm/clickhouse.repo -g
sudo zypper --gpg-auto-import-keys refresh clickhouse-stable
sudo zypper install -y clickhouse-server clickhouse-client
sudo /etc/init.d/clickhouse-server start
clickhouse-client # or "clickhouse-client --password" if you set up a password.
Deprecated Method for installing rpm-packages
如果您想使用最新的版本,请用testing替代stable(我们只推荐您用于测试环境)。prestable有时也可用。
然后运行命令安装:
sudo yum install clickhouse-server clickhouse-client
你也可以从这里手动下载安装包:下载。
3.2.3 Tgz安装包
如果您的操作系统不支持安装deb或rpm包,建议使用官方预编译的tgz软件包。
所需的版本可以通过curl或wget从存储库https://packages.clickhouse.com/tgz/下载。
下载后解压缩下载资源文件并使用安装脚本进行安装。以下是一个最新稳定版本的安装示例:
LATEST_VERSION=$(curl -s https://packages.clickhouse.com/tgz/stable/ | \
grep -Eo '[0-9]+\.[0-9]+\.[0-9]+\.[0-9]+' | sort -V -r | head -n 1)
export LATEST_VERSION
case $(uname -m) in
x86_64) ARCH=amd64 ;;
aarch64) ARCH=arm64 ;;
*) echo "Unknown architecture $(uname -m)"; exit 1 ;;
esac
for PKG in clickhouse-common-static clickhouse-common-static-dbg clickhouse-server clickhouse-client
do
curl -fO "https://packages.clickhouse.com/tgz/stable/$PKG-$LATEST_VERSION-${ARCH}.tgz" \
|| curl -fO "https://packages.clickhouse.com/tgz/stable/$PKG-$LATEST_VERSION.tgz"
done
tar -xzvf "clickhouse-common-static-$LATEST_VERSION-${ARCH}.tgz" \
|| tar -xzvf "clickhouse-common-static-$LATEST_VERSION.tgz"
sudo "clickhouse-common-static-$LATEST_VERSION/install/doinst.sh"
tar -xzvf "clickhouse-common-static-dbg-$LATEST_VERSION-${ARCH}.tgz" \
|| tar -xzvf "clickhouse-common-static-dbg-$LATEST_VERSION.tgz"
sudo "clickhouse-common-static-dbg-$LATEST_VERSION/install/doinst.sh"
tar -xzvf "clickhouse-server-$LATEST_VERSION-${ARCH}.tgz" \
|| tar -xzvf "clickhouse-server-$LATEST_VERSION.tgz"
sudo "clickhouse-server-$LATEST_VERSION/install/doinst.sh" configure
sudo /etc/init.d/clickhouse-server start
tar -xzvf "clickhouse-client-$LATEST_VERSION-${ARCH}.tgz" \
|| tar -xzvf "clickhouse-client-$LATEST_VERSION.tgz"
sudo "clickhouse-client-$LATEST_VERSION/install/doinst.sh"
Deprecated Method for installing tgz archives
对于生产环境,建议使用最新的stable版本。你可以在GitHub页面https://github.com/ClickHouse/ClickHouse/tags找到它,它以后缀`-stable`标志。
3.2.4 Docker安装包
要在Docker中运行ClickHouse,请遵循Docker Hub上的指南。它是官方的deb安装包。
3.2.5 其他环境安装包
对于非linux操作系统和Arch64 CPU架构,ClickHouse将会以master分支的最新提交的进行编译提供(它将会有几小时的延迟)。
- macOS —
curl -O 'https://builds.clickhouse.com/master/macos/clickhouse' && chmod a+x ./clickhouse - FreeBSD —
curl -O 'https://builds.clickhouse.com/master/freebsd/clickhouse' && chmod a+x ./clickhouse - AArch64 —
curl -O 'https://builds.clickhouse.com/master/aarch64/clickhouse' && chmod a+x ./clickhouse
下载后,您可以使用clickhouse client连接服务,或者使用clickhouse local模式处理数据,不过您必须要额外在GitHub下载server和users配置文件。
不建议在生产环境中使用这些构建版本,因为它们没有经过充分的测试,但是您可以自行承担这样做的风险。它们只是ClickHouse功能的一个部分。
3.2.6 使用源码安装
要手动编译ClickHouse, 请遵循Linux或Mac OS X说明。
您可以编译并安装它们,也可以使用不安装包的程序。通过手动构建,您可以禁用SSE 4.2或AArch64 cpu。
Client: programs/clickhouse-client
Server: programs/clickhouse-server
您需要创建一个数据和元数据文件夹,并为所需的用户chown授权。它们的路径可以在服务器配置(src/programs/server/config.xml)中改变,默认情况下它们是:
/opt/clickhouse/data/default/
/opt/clickhouse/metadata/default/
在Gentoo上,你可以使用emerge clickhouse从源代码安装ClickHouse。
3.2 启动
如果没有service,可以运行如下命令在后台启动服务:
$ sudo /etc/init.d/clickhouse-server start
日志文件将输出在/var/log/clickhouse-server/文件夹。
如果服务器没有启动,检查/etc/clickhouse-server/config.xml中的配置。
您也可以手动从控制台启动服务器:
$ clickhouse-server --config-file=/etc/clickhouse-server/config.xml
在这种情况下,日志将被打印到控制台,这在开发过程中很方便。
如果配置文件在当前目录中,则不需要指定——config-file参数。默认情况下,它的路径为./config.xml。
ClickHouse支持访问限制设置。它们位于users.xml文件(与config.xml同级目录)。 默认情况下,允许default用户从任何地方访问,不需要密码。可查看user/default/networks。 更多信息,请参见Configuration Files。
启动服务后,您可以使用命令行客户端连接到它:
$ clickhouse-client
默认情况下,使用default用户并不携带密码连接到localhost:9000。还可以使用--host参数连接到指定服务器。
终端必须使用UTF-8编码。 更多信息,请参阅Command-line client。
示例:
$ ./clickhouse-client
ClickHouse client version 0.0.18749.
Connecting to localhost:9000.
Connected to ClickHouse server version 0.0.18749.
:) SELECT 1
SELECT 1
┌─1─┐
│ 1 │
└───┘
1 rows in set. Elapsed: 0.003 sec.
:)
恭喜,系统已经工作了!
4、数据类型
注意在CK中关键字严格区分大小写
4.1 数值类型
Int类型
固定长度的整数类型又包括有符号和无符号的整数类型。
有符号整数类型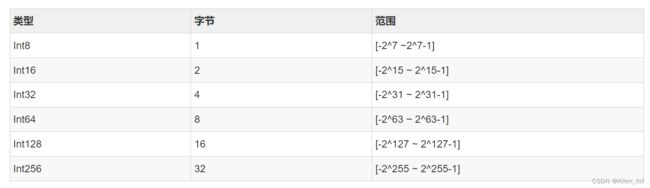
无符号类型
浮点类型
单精度浮点数
Float32从小数点后第8位起会发生数据溢出

双精度浮点数
Float32从小数点后第17位起会发生数据溢出

示例
-- Float32类型,从第8为开始产生数据溢出
kms-1.apache.com :) select toFloat32(0.123456789);SELECT toFloat32(0.123456789)
┌─toFloat32(0.123456789)─┐
│ 0.12345679 │
└────────────────────────┘
-- Float64类型,从第17为开始产生数据溢出
kms-1.apache.com :) select toFloat64(0.12345678901234567890);SELECT toFloat64(0.12345678901234568)
┌─toFloat64(0.12345678901234568)─┐
│ 0.12345678901234568 │
└────────────────────────────────┘
Decimal类型
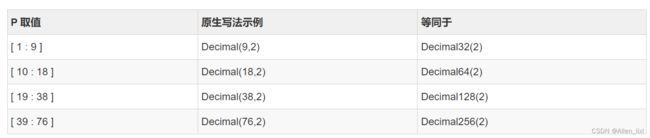
有符号的定点数,可在加、减和乘法运算过程中保持精度。ClickHouse提供了Decimal32、Decimal64和Decimal128三种精度的定点数,支持几种写法:
- Decimal(P, S)
- Decimal32(S) 数据范围:( -1 * 10^(9 - S), 1 * 10^(9 - S) )
- Decimal64(S) 数据范围:( -1 * 10^(18 - S), 1 * 10^(18 - S) )
- Decimal128(S) 数据范围:( -1 * 10^(38 - S), 1 * 10^(38 - S) )
- Decimal256(S) 数据范围:( -1 * 10^(76 - S), 1 * 10^(76 - S) )
其中:P代表精度,决定总位数(整数部分+小数部分),取值范围是1~76
S代表规模,决定小数位数,取值范围是0~P
根据P的范围,可以有如下的等同写法:
注意点:不同精度的数据进行四则运算时,**精度(总位数)和规模(小数点位数)**会发生变化,具体规则如下:
精度对应的规则
可以看出:两个不同精度的数据进行四则运算时,结果数据已最大精度为准
Decimal64(S1)
运算符
Decimal32(S2) -> Decimal64(S)
Decimal128(S1)
运算符
Decimal32(S2) -> Decimal128(S)
Decimal128(S1)
运算符
Decimal64(S2) -> Decimal128(S)
Decimal256(S1)
运算符
Decimal<32|64|128>(S2) -> Decimal256(S)
规模(小数点位数)对应的规则
加法|减法:S = max(S1, S2),即以两个数据中小数点位数最多的为准
乘法:S = S1 + S2(注意:S1精度 >= S2精度),即以两个数据的小数位相加为准
除法:S = S1,即被除数的小数位为准-- toDecimal32(value, S)
-- 加法,S取两者最大的,P取两者最大的
SELECT
toDecimal64(2, 3) AS x,
toTypeName(x) AS xtype,
toDecimal32(2, 2) AS y,
toTypeName(y) as ytype,
x + y AS z,
toTypeName(z) AS ztype;
-- 结果输出
┌─────x─┬─xtype──────────┬────y─┬─ytype─────────┬─────z─┬─ztype──────────┐
│ 2.000 │ Decimal(18, 3) │ 2.00 │ Decimal(9, 2) │ 4.000 │ Decimal(18, 3) │
└───────┴────────────────┴──────┴───────────────┴───────┴────────────────┘
-- 乘法,比较特殊,与这两个数的顺序有关
-- 如下:x类型是Decimal64,y类型是Decimal32,顺序是x*y,小数位S=S1+S2
SELECT
toDecimal64(2, 3) AS x,
toTypeName(x) AS xtype,
toDecimal32(2, 2) AS y,
toTypeName(y) as ytype,
x * y AS z,
toTypeName(z) AS ztype;
-- 结果输出
┌─────x─┬─xtype──────────┬────y─┬─ytype─────────┬───────z─┬─ztype──────────┐
│ 2.000 │ Decimal(18, 3) │ 2.00 │ Decimal(9, 2) │ 4.00000 │ Decimal(18, 5) │
└───────┴────────────────┴──────┴───────────────┴─────────┴────────────────┘
-- 交换相乘的顺序,y*x,小数位S=S1*S2
SELECT
toDecimal64(2, 3) AS x,
toTypeName(x) AS xtype,
toDecimal32(2, 2) AS y,
toTypeName(y) as ytype,
y * x AS z,
toTypeName(z) AS ztype;
-- 结果输出
┌─────x─┬─xtype──────────┬────y─┬─ytype─────────┬────────z─┬─ztype──────────┐
│ 2.000 │ Decimal(18, 3) │ 2.00 │ Decimal(9, 2) │ 0.400000 │ Decimal(18, 6) │
└───────┴────────────────┴──────┴───────────────┴──────────┴────────────────┘
-- 除法,小数位与被除数保持一致
SELECT
toDecimal64(2, 3) AS x,
toTypeName(x) AS xtype,
toDecimal32(2, 2) AS y,
toTypeName(y) as ytype,
x / y AS z,
toTypeName(z) AS ztype;
-- 结果输出
┌─────x─┬─xtype──────────┬────y─┬─ytype─────────┬─────z─┬─ztype──────────┐
│ 2.000 │ Decimal(18, 3) │ 2.00 │ Decimal(9, 2) │ 1.000 │ Decimal(18, 3) │
└───────┴────────────────┴──────┴───────────────┴───────┴────────────────┘
4.2 字符串类型
符串类型可以细分为String、FixedString和UUID三类。从命名来看仿佛不像是由一款数据库提供的类型,反而更像是一门编程语言的设计,没错CK语法具备编程语言的特征(数据+运算)
1) String
字符串由String定义,长度不限。因此在使用String的时候无须声明大小。它完全代替了传统意义上数据库的Varchar、Text、Clob和Blob等字符类型。String类型不限定字符集,因为它根本就没有这个概念,所以可以将任意编码的字符串存入其中。但是为了程序的规范性和可维护性,在同一套程序中应该遵循使用统一的编码,例如“统一保持UTF-8编码”就是一种很好的约定。所以在对数据操作的时候我们不在需要区关注编码和乱码问题!
2) FixedString
FixedString类型和传统意义上的Char类型有些类似,对于一些字符有明确长度的场合,可以使用固定长度的字符串。定长字符串通过FixedString(N)声明,其中N表示字符串长度。但与Char不同的是,
FixedString使用null字节填充末尾字符,而Char通常使用空格填充。比如在下面的例子中,字符串‘abc’虽然只有3位,但长度却是5,因为末尾有2位空字符填充 !
create table test_str(
name String ,
job FixedString(4) -- 最长4个字符
)engine=Memory ;
3) UUID
UUID是一种数据库常见的主键类型,在ClickHouse中直接把它作为一种数据类型。UUID共有32位,它的格式为8-4-4-4-12。如果一个UUID类型的字段在写入数据时没有被赋值,则会依照格式使用0填充
CREATE TABLE test_uuid
(
`uid` UUID,
`name` String
)
ENGINE = Log ;
DESCRIBE TABLE test_uuid┌─name─┬─type───┬
│ uid │ UUID │
│ name │ String │
└──────┴────────┴
insert into test_uuid select generateUUIDv4() , 'zss' ;
insert into test_uuid values (generateUUIDv4() , 'zss') ;
select * from test_uuid ;
┌──────────────────────────────────uid─┬─name─┐
│ 47e39e22-d2d6-46fd-8014-7cd3321f4c7b │ zss │
└──────────────────────────────────────┴──────┘-------------------------UUID类型的字段默认补位0-----------------------------
insert into test_uuid (name) values('hangge') ;
┌──────────────────────────────────uid─┬─name─┐
│ 47e39e22-d2d6-46fd-8014-7cd3321f4c7b │ zss │
└──────────────────────────────────────┴──────┘
┌──────────────────────────────────uid─┬─name───┐
│ 00000000-0000-0000-0000-000000000000 │ hangge │
└──────────────────────────────────────┴────────┘
4.3 时间类型
1) Date
Date类型不包含具体的时间信息,只精确到天,支持字符串形式写入:
CREATE TABLE test_date
(
`id` int,
`cd` Date
)
ENGINE = Memory ;
DESCRIBE TABLE test_date ;
┌─name─┬─type──┬
│ id │ Int32 │
│ ct │ Date │
└──────┴───────┴
insert into test_date vlaues(1,'2021-09-11'),(2,now()) ;
select id , ct from test_date ;┌─id─┬─────────ct─┐
│ 1 │ 2021-09-11 │
│ 2 │ 2021-05-17 │
└────┴────────────┘
2) DateTime
DateTime类型包含时、分、秒信息,精确到秒,支持字符串形式写入:
create table testDataTime(ctime DateTime) engine=Memory ;
insert into testDataTime values('2021-12-27 01:11:12'),(now()) ;
select * from testDataTime ;
3)DateTime64
DateTime64可以记录亚秒,它在DateTime之上增加了精度的设置
-- 建表
CREATE TABLE test_date_time64
(
`ctime` DateTime64
)
ENGINE = Memory ;
-- 建表
CREATE TABLE test_date_time64_2
(
`ctime` DateTime64(2)
)
ENGINE = Memory ;
-- 分别插入数据
insert into test_date_time64 values('2021-11-11 11:11:11'),(now()) ;
insert into test_date_time64_2 values('2021-11-11 11:11:11'),(now()) ;
-- 查询数据
SELECT *
FROM test_date_time64;
┌───────────────────ctime─┐
│ 2021-11-11 11:11:11.000 │
│ 2021-05-17 10:40:51.000 │
└─────────────────────────┘
SELECT
*, toTypeName(ctime)
FROM test_date_time64┌───────────────────ctime─┬─toTypeName(ctime)─┐
│ 2021-11-11 11:11:11.000 │ DateTime64(3) │
│ 2021-05-17 10:40:51.000 │ DateTime64(3) │
------------------------------------------------
SELECT
*, toTypeName(ctime)
FROM test_date_time64_2┌──────────────────ctime─┬─toTypeName(ctime)─┐
│ 2021-11-11 11:11:11.00 │ DateTime64(2) │
│ 2021-05-17 10:41:26.00 │ DateTime64(2) │
└────────────────────────┴───────────────────┘
4.4 复杂类型
1) Enum
ClickHouse支持枚举类型,这是一种在定义常量时经常会使用的数据类型。ClickHouse提供了Enum8和Enum16两种枚举类型,它们除了取值范围不同之外,别无二致。枚举固定使用(String:Int)Key/Value键值对的形式定义数据,所以Enum8和Enum16分别会对应(String:Int8)和(String:Int16)!
create table test_enum(id Int8 , color Enum('red'=1 , 'green'=2 , 'blue'=3)) engine=Memory ;
insert into test_enum values(1,'red'),(1,'red'),(2,'green');
也可以使用这种方式进行插入数据:
insert into test_enum values(3,3) ;
在定义枚举集合的时候,有几点需要注意。首先,Key和Value是不允许重复的,要保证唯一性。其次,Key和Value的值都不能为Null,但Key允许是空字符串。在写入枚举数据的时候,只会用到Key字符串部分,
注意: 其实我们可以使用字符串来替代Enum类型来存储数据,那么为什么是要使用枚举类型呢?这是出于性能的考虑。因为虽然枚举定义中的Key属于String类型,但是在后续对枚举的所有操作中(包括排序、分组、去重、过滤等),会使用Int类型的Value值 ,提高处理数据的效率!
限制枚举类型字段的值
底层存储的是对应的Int类型的数据 , 使用更小的存储空间
可以使用String来替代枚举 / 没有值的限定
插入数据的时候可以插入指定的字符串 也可以插入对应的int值
2) Array(T)
CK支持数组这种复合数据类型 , 并且数据在操作在今后的数据分析中起到非常便利的效果!数组的定义方式有两种 : array(T) [e1,e2…] , 我们在这里要求数组中的数据类型是一致的!
数组的定义
[1,2,3,4,5]
array('a' , 'b' , 'c')
[1,2,3,'hello'] -- 错误
create table test_array(
id Int8 ,
hobby Array(String)
)engine=Memory ;
insert into test_array values(1,['eat','drink','la']),(2,array('sleep','palyg','sql'));
┌─id─┬─hobby───────────────────┐
│ 1 │ ['eat','drink','la'] │
│ 2 │ ['sleep','palyg','sql'] │
└────┴─────────────────────────┘
select id , hobby , toTypeName(hobby) from test_array ;
┌─id─┬─hobby───────────────────┬─toTypeName(hobby)─┐
│ 1 │ ['eat','drink','la'] │ Array(String) │
│ 2 │ ['sleep','palyg','sql'] │ Array(String) │
└────┴─────────────────────────┴───────────────────┘
select id , hobby[2] , toTypeName(hobby) from test_array ; -- 数组的取值 [index] 1-based
select * , hobby[1] , length(hobby) from test_array ; length(arr) -- 数组的长度
3) Tuple
在java中封装一个用户的基本信息 (id,name,age,gender)
需要创建一个POJO/JavaBean类 UserBean , 然后将字段的值set进去 . .属性操作任意的属性
Tuple4(1,zss,23,M) 通过获取指定位置 _2 的值 操作数据
(2,lss,24,F)
元组类型由1~n个元素组成,每个元素之间允许设置不同的数据类型,且彼此之间不要求兼容。元组同样支持类型推断,其推断依据仍然以最小存储代价为原则。与数组类似,元组也可以使用两种方式定义,常规方式tuple(T):元组中可以存储多种数据类型,但是要注意数据类型的顺序
tuple(…)
(…)
col Tuple(Int8 , String …)
(‘’ , ‘’) 对偶元组 entry --> map
select tuple(1,'asb',12.23) as x , toTypeName(x) ;
┌─x───────────────┬─toTypeName(tuple(1, 'asb', 12.23))─┐
│ (1,'asb',12.23) │ Tuple(UInt8, String, Float64) │
└─────────────────┴────────────────────────────────────┘
---简写形式
SELECT
(1, 'asb', 12.23) AS x,
toTypeName(x)┌─x───────────────┬─toTypeName(tuple(1, 'asb', 12.23))─┐
│ (1,'asb',12.23) │ Tuple(UInt8, String, Float64) │
└─────────────────┴────────────────────────────────────┘
注意:建表的时候使用元组的需要制定元组的数据类型
CREATE TABLE test_tuple (
c1 Tuple(UInt8, String, Float64)
) ENGINE = Memory;
(1,2,3,‘abc’)
tuple(1,2,3,‘abc’)
col Tuple(Int8,Int8,String) – 定义泛型
tuple(1,‘zss’,12.12)
select tupleElement(c1 , 2) from test_tuple; -- 获取元组指定位置的值
4) Nested
Nested是一种嵌套表结构。一张数据表,可以定义任意多个嵌套类型字段,但每个字段的嵌套层级只支持一级,即嵌套表内不能继续使用嵌套类型。对于简单场景的层级关系或关联关系,使用嵌套类型也是一种不错的选择。
create table test_nested(
uid Int8 ,
name String ,
props Nested(
pid Int8,
pnames String ,
pvalues String
)
)engine = Memory ;
desc test_nested ;
┌─name──────────┬─type──────────┬
│ uid │ Int8 │
│ name │ String │
│ props.pid │ Array(Int8) │
│ props.pnames │ Array(String) │
│ props.pvalues │ Array(String) │
└───────────────┴───────────────┴
嵌套类型本质是一种多维数组的结构。嵌套表中的每个字段都是一个数组,并且行与行之间数组的长度无须对齐。需要注意的是,在同一行数据内每个数组字段的长度必须相等。
create table test_nested(
id Int8 ,
name String ,
scores Nested(
seq UInt8 ,
sx Float64 ,
yy Float64 ,
yw Float64
)
)engine = Memory ;
insert into test_nested values (1,'wbb',[1,2,3],[11,12,13],[14,14,11],[77,79,10]);
insert into test_nested values (2,'taoge',[1,2],[99,10],[14,40],[77,11]);
-- 注意 每行中的数组的个数一致 行和行之间可以不一直被┌─id─┬─name─┬─scores.seq─┬─scores.sx──┬─scores.yy──┬─scores.yw──┐
│ 1 │ wbb │ [1,2,3] │ [11,12,13] │ [14,14,11] │ [77,79,10] │
└────┴──────┴────────────┴────────────┴────────────┴────────────┘
┌─id─┬─name──┬─scores.seq─┬─scores.sx─┬─scores.yy─┬─scores.yw─┐
│ 2 │ taoge │ [1,2] │ [99,10] │ [14,40] │ [77,11] │
└────┴───────┴────────────┴───────────┴───────────┴───────────┘
SELECT
name,
scores.sx
FROM test_nested;
┌─name─┬─scores.sx──┐
│ wbb │ [11,12,13] │
└──────┴────────────┘
┌─name──┬─scores.sx─┐
│ taoge │ [99,10] │
└───────┴───────────┘
和单纯的多个数组类型的区别是
每行数据中的每个属性数组的长度一致
5) Map
clickEvent 用户打开页面 , 点击一个按钮, 触发了点击事件
set allow_experimental_map_type = 1 ; -- 启用Map数据类型
CREATE TABLE test_map (
a Map(String, UInt64)
) ENGINE=Memory;
desc test_map ;insert into test_map valeus({'lss':21,'zss':22,'ww':23}) ,({'lss2':21,'zss2':22,'ww2':23});
SELECT
*,
mapKeys(a),
mapValues(a),
a['lss'],
length(a)
FROM test_map
Map集合就是K->V 映射关系
tuple('zss',23) 元组中的元素只有两个 对偶元组 K->V
Map中内容(tuple2)
cast(v , dataType) 强制类型转换
select cast('21' , 'UInt8')+3 ;
-- 拉链操作
SELECT CAST(([1, 2, 3], ['Ready', 'Steady', 'Go']), 'Map(UInt8, String)') AS map;
([1, 2, 3], ['Ready', 'Steady', 'Go'])
SELECT CAST(([1, 2, 3], ['Ready', 'Steady', 'Go']), 'Map(UInt8, String)') AS map , mapKeys(map) as ks , mapValues(map) as vs;
6) GEO
Point
SET allow_experimental_geo_types = 1;
CREATE TABLE geo_point (p Point) ENGINE = Memory();
INSERT INTO geo_point VALUES((10, 10));
SELECT p, toTypeName(p) FROM geo_point;
┌─p───────┬─toTypeName(p)─┐
│ (10,10) │ Point │
└─────────┴───────────────┘
Ring
SET allow_experimental_geo_types = 1;
CREATE TABLE geo_ring (r Ring) ENGINE = Memory();
INSERT INTO geo_ring VALUES([(0, 0), (10, 0), (10, 10), (0, 10)]);
SELECT r, toTypeName(r) FROM geo_ring;
┌─r─────────────────────────────┬─toTypeName(r)─┐
│ [(0,0),(10,0),(10,10),(0,10)] │ Ring │
└───────────────────────────────┴───────────────┘
Polygon
SET allow_experimental_geo_types = 1;
CREATE TABLE geo_polygon (pg Polygon) ENGINE = Memory();
INSERT INTO geo_polygon VALUES([[(20, 20), (50, 20), (50, 50), (20, 50)], [(30, 30), (50, 50), (50, 30)]]);
SELECT pg, toTypeName(pg) FROM geo_polygon;
MultiPolygon
SET allow_experimental_geo_types = 1;
CREATE TABLE geo_multipolygon (mpg MultiPolygon) ENGINE = Memory();
INSERT INTO geo_multipolygon VALUES([[[(0, 0), (10, 0), (10, 10), (0, 10)]], [[(20, 20), (50, 20), (50, 50), (20, 50)],[(30, 30), (50, 50), (50, 30)]]]);
SELECT mpg, toTypeName(mpg) FROM geo_multipolygon;
7)IPV4
域名类型分为IPv4和IPv6两类,本质上它们是对整型和字符串的进一步封装。IPv4类型是基于UInt32封装的
(1)出于便捷性的考量,例如IPv4类型支持格式检查,格式错误的IP数据是无法被写入的,例如:
INSERT INTO IP4_TEST VALUES (‘www.51doit.com’,‘192.0.0’)
Code: 441. DB::Exception: Invalid IPv4 value.
(2)出于性能的考量,同样以IPv4为例,IPv4使用UInt32存储,相比String更加紧凑,占用的空间更小,查询性能更快。IPv6类型是基于FixedString(16)封装的,它的使用方法与IPv4别无二致, 在使用Domain类型的时候还有一点需要注意,虽然它从表象上看起来与String一样,但Domain类型并不是字符串,所以它不支持隐式的自动类型转换。如果需要返回IP的字符串形式,则需要显式调用 IPv4NumToString或IPv6NumToString函数进行转换。
create table test_domain(
id Int8 ,
ip IPv4
)engine=Memory ;
insert into test_domain values(1,'192.168.133.2') ;
insert into test_domain values(1,'192.168.133') ; 在插入数据的会进行数据的检查所以这行数据会报错
-- Exception on client:
-- Code: 441. DB::Exception: Invalid IPv4 value.
-- Connecting to database doit1 at localhost:9000 as user default.
-- Connected to ClickHouse server version 20.8.3 revision 54438.
8) Boolean和Nullable
ck中没有Boolean类型 ,使用1和0来代表true和false
Nullable 某种数据类型允许为null , 或者是没有给值的情况下模式是NULL
create table test_null(
id Int8 ,
age Int8
)engine = Memory ;create table test_null2(
id Int8 ,
age Nullable(Int8)
)engine = Memory ;
5、引擎
5.1 数据库引擎
数据库引擎允许您处理数据表。
默认情况下,ClickHouse使用Atomic数据库引擎。它提供了可配置的table engines和SQL dialect。
您还可以使用以下数据库引擎:
MySQL
MaterializeMySQL
Lazy
Atomic
PostgreSQL
MaterializedPostgreSQL
Replicated
SQLite
5.2 表引擎
表引擎(即表的类型)决定了:
- 数据的存储方式和位置,写到哪里以及从哪里读取数据
- 支持哪些查询以及如何支持。
- 并发数据访问。
- 索引的使用(如果存在)。
- 是否可以执行多线程请求。
- 数据复制参数。
5.3 引擎类型
5.3.1 MergeTree
适用于高负载任务的最通用和功能最强大的表引擎。这些引擎的共同特点是可以快速插入数据并进行后续的后台数据处理。 MergeTree系列引擎支持数据复制(使用Replicated* 的引擎版本),分区和一些其他引擎不支持的其他功能。
该类型的引擎:
- MergeTree
- ReplacingMergeTree
- SummingMergeTree
- AggregatingMergeTree
- CollapsingMergeTree
- VersionedCollapsingMergeTree
- GraphiteMergeTree
5.3.2 日志
具有最小功能的轻量级引擎。当您需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的。
该类型的引擎:
- TinyLog
- StripeLog
- Log
5.3.3 集成引擎
用于与其他的数据存储与处理系统集成的引擎。 该类型的引擎:
- Kafka
- MySQL
- ODBC
- JDBC
- HDFS
5.3.4 用于其他特定功能的引擎
该类型的引擎:
- Distributed
- MaterializedView
- Dictionary
- Merge
- File
- Null
- Set
- Join
- URL
- View
- Memory
- Buffer
5.3.5 虚拟列
虚拟列是表引擎组成的一部分,它在对应的表引擎的源代码中定义。
您不能在 CREATE TABLE 中指定虚拟列,并且虚拟列不会包含在 SHOW CREATE TABLE 和 DESCRIBE TABLE 的查询结果中。虚拟列是只读的,所以您不能向虚拟列中写入数据。
如果想要查询虚拟列中的数据,您必须在SELECT查询中包含虚拟列的名字。SELECT * 不会返回虚拟列的内容。
若您创建的表中有一列与虚拟列的名字相同,那么虚拟列将不能再被访问。我们不建议您这样做。为了避免这种列名的冲突,虚拟列的名字一般都以下划线开头。
6、函数
参考:函数 | ClickHouse Docs