一文打通,Web自动化测试从0到1落地项目实战(详细)
目录:导读
-
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
1、web自动化测试的流程实施
1)需求分析
在这一阶段,需要明确测试的目标和范围,例如需要测试哪些功能,需要覆盖哪些场景,需要满足
哪些性能指标等。同时也要考虑测试数据的准备,例如如何生成测试数据、如何管理测试数据等。
2)技术选型
在这一阶段,需要根据项目需求和特点,选择合适的自动化测试框架和工具。例如选择Selenium
WebDriver作为自动化测试框架,使用Python语言编写测试脚本,使用Pytest作为测试运行工具等。
3)环境搭建
在这一阶段,需要搭建测试环境,包括测试服务器、测试数据库、测试数据、测试工具等。例如在本地搭建测试服务器、使用Docker容器搭建测试环境、使用Jenkins作为持续集成工具等。
4)测试脚本编写
在这一阶段,需要根据需求和用例编写测试脚本,实现自动化测试。测试脚本应该具有可重复性、可维护性、可扩展性等特点。
同时,也需要考虑如何管理测试脚本,例如如何组织测试用例、如何管理测
试数据等。
5)测试执行
在这一阶段,需要执行测试脚本,收集测试结果和日志。测试执行可以手动执行,也可以使用自动化测试工具执行。
在执行测试脚本之前,需要准备好测试数据和测试环境,确保测试的准确性和可靠性。
6)结果分析
在这一阶段,需要对测试结果进行分析,发现测试缺陷和性能瓶颈。测试结果可以通过测试报告、测试日志、缺陷管理系统等方式来记录和分析。
同时,也需要对测试结果进行归档和保留,以备后续使用。
7)缺陷管理
在这一阶段,需要将测试缺陷记录在缺陷管理系统中,并跟踪缺陷的解决过程。缺陷管理系统应该具有良好的可扩展性和可定制性,可以根据项目需求进行定制和扩展。
8)性能优化
在这一阶段,需要根据测试结果和性能瓶颈,进行性能优化和问题排查。性能优化可以从多个方面入手,例如优化数据库查询、优化网络传输、优化代码逻辑等。
9)测试报告
在这一阶段,需要生成测试报告,反馈测试结果和缺陷情况。测试报告应该具有良好的可读性和可扩展性,可以帮助项目组和业务部门了解测试情况和测试结果。
10)持续集成
在这一阶段,需要将自动化测试集成到持续集成系统中,实现自动化测试的持续化和自动化部署。
持续集成系统应该具有良好的可定制性和可扩展性,可以根据项目需求进行定制和扩展。
以上是Web自动化测试框架落地实施的一般流程和步骤,不同项目和公司可能会有不同的实施方案和流程。
2、搭建web自动化测试的环境
浏览器一般选择chrome
浏览器对应的驱动:driver(chromedriver)
Python环境
Selenium库
测试框架pytest
log日志信息
allure缺陷报告
这些工具和框架提供了丰富的API和库,可以帮助开发人员和测试人员编写高效、可维护的测试脚本,实现自动化测试的目的
3、web自动化测试的方法
Web自动化测试一般使用设计测试用例的方法跟功能测试相同,使用等价类划分、边界值、因果图、场景法等等。
用例设计跟功能一样,只是执行方式不一样
Web自动化测试实施的使用我们一般会采用pom模式设计
PO是page object module的简称,核心思想是通过对界面元素的封装减少冗余代码,同时在后期维护中,若元素定位发生变化, 只需要调整页面元素封装的代码,提高测试用例的可维护性、可读性。
PO模式可以把一个页面分为三层,对象库层、操作层、业务层。
对象库层:封装定位元素的方法定义成属性。
操作层:封装对元素的操作定义成方法。
业务层:将一个或多个操作组合起来完成一个业务功能
比如进入项目,需要准备的步骤:第一确定页面,第二找到元素(8种方法),第三操作元素(点击,输入,清除,键盘任何按键,获取属性,获取页面title,url,关闭,截图,滚动,下拉框,子页面切换,等待,文件上
传等等。)
数据驱动测试:从某个数据文件(例如json文件、Excel文件、Csv文件、yaml对象文件等)中读取输入、输出 的测试数据,然后通过pytest自动化测试框架的参数化结合传入事先编写的测试脚本中。
其中,这些参数变量被用作传递(输入/输出),用来验证应用程序的测试数据。在这个过程中, 数据文件的读取、测试状态和所有测试信息都被编写进测试脚本里,生成日志信息。
测试数据只包含在数据文件中,而不是脚本里,测试脚本只是一个“驱动”,或者说是一个传送数据的机制。
特点:
1)可变数据
2)高度抽象化的、重复的测试设计
优点:
减少重复劳动
解耦:降低耦合性,降低准入门槛,易于测试人员修改和维护:自动化测试工程师负责开发测试脚本,手工测试人员负责准备测试数据
KDT关键字极限封装,实现0代码,结合自动化测试框架执行excel用例
关键字驱动的思路是将关键字表中的对象及数据提取出来并构造成每个测试步骤
而关键字驱动,则进一步在技术上把 tester 分成了完全不懂技术的和懂点技术的,前者只能根据格式填写一下excel 表格,后者对工具/框架内置的所谓关键字库进行增补或二次开发
新建一个项目:po模式+selenium+allure测试报告+log日志模块+pytest(夹具,标记,参数化)+数据驱动(csv,json,excel)
文件夹和python包的区别: 项目当中区分文件夹和包唯一标识符是: 包有黑点,文件夹没有 文件夹:用来存储普通
文件: data:存放自动化需要的测试数据文件:(文件格式:csv,json,excel) log:存放日志信息的内容:日志时间,文件名字,日志等级,日志输入信息,实际结果 report:存放缺陷报告内容:allure使用步骤:
1)在配置文件修改配置信息
2)设置测试报告内容
3)运行测试用例脚本
4)生成测试报告命令:allure generate report/ -o report/html
python中包:主要是可以被导入使用里面的模块,类(类方法,实例方法),函数
base:获取驱动对象,用来被po模式里面对象层的定位标签的驱动作为继承使用
po:用来定位元素操作元素的包: 页面对象层:创建一个对象层类,定义方法去定位标签 页面操作层:创建一个操
作层类,创建一个页面层的对象,通过对象定义方法去定位标签,操作元素 页面业务层:创建一个业务层类,创建一个操作层的对象,通过对象调用操作层的方法实现业务逻辑
script:用来执行测试用例脚本的包,一个模块(注册,登录,会员列表)代表一个py文件 夹具:获取驱动
UtilsDriver.get_driver(cls),关闭驱动UtilsDriver.quit_driver(cls) po模式的业务层对象创建:调用业务层方法去执行
标签的操作逻辑 allure的使用:
1)导包:import allure
2)调用feature设置模块标题: @allure.feature(“注册功能”)
3)story设置测试用例标题:注册用户名错误 @allure.story(“注册用户名错误”)
4)添加测试步骤,获取输入注册信息 allure.step(“输入注册信息”)
5)attach添加描述信息,获取用户注册的数据 allure.attach(data_info, “用户注
册的数据”)
4,5重复设置一次获取实际结果
pytest参数化标签的使用:通过调用工具模块utils.py,get_data()函数去获取数据执行测试用例 UtilsDriver.get_msg()
获取实际结果
日志信息:通过调用init_logger(logname)方法去获取日志信息 1,导包,调用函数 2,获取输入的用户信息,以及实际结果 3,将信息写入到日志文件夹里面
其他内容: 配置文件:pytest.ini: 1,用来控制代码需要执行的位置 2,输出指定位置的测试报告
工具模块utils.py: UtilsDriver工具类:定义了3个类方法:
1)获取驱动
2)关闭驱动
3)获取实际结果
其他函数: get_data()读取数据 init_logger(logname)设置日志信息步骤
驱动:保持和浏览器一致的版本
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
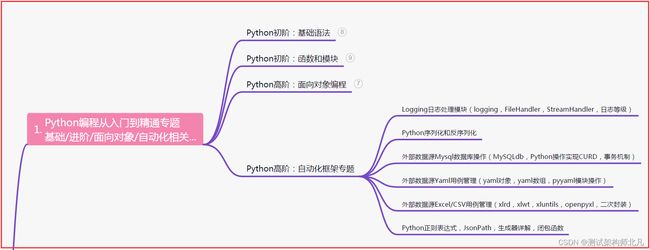
一、Python编程入门到精通
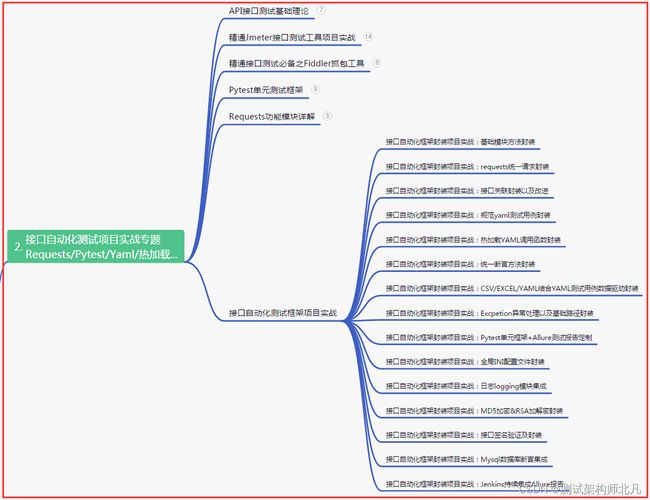
二、接口自动化项目实战
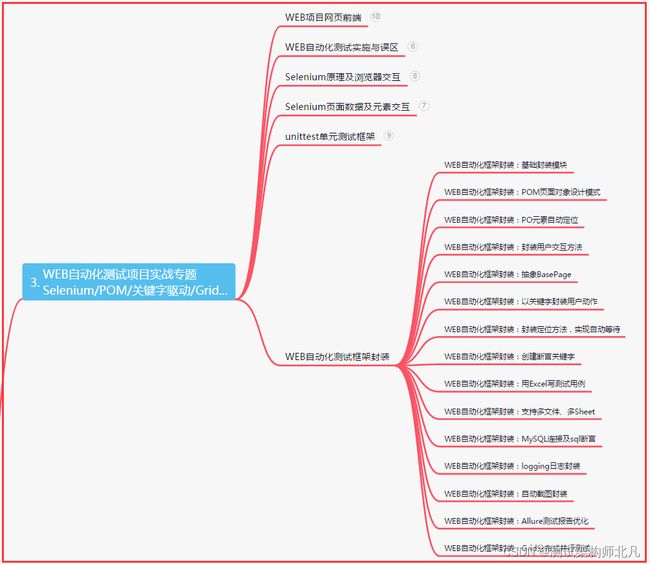
三、Web自动化项目实战
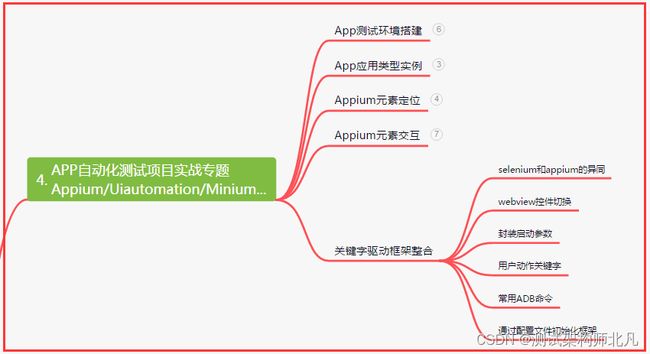
四、App自动化项目实战
五、一线大厂简历
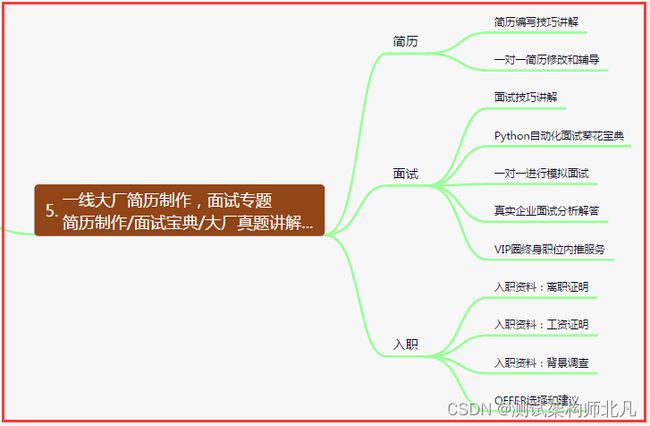
六、测试开发DevOps体系
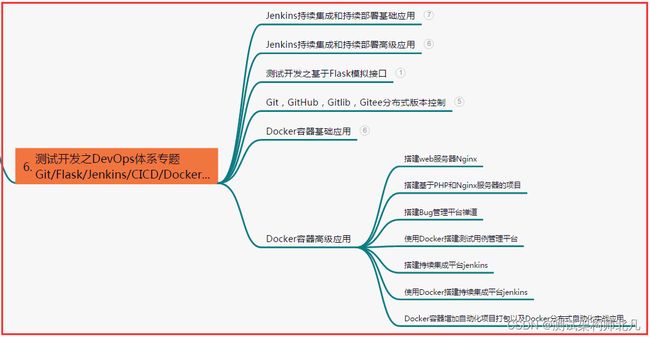
七、常用自动化测试工具
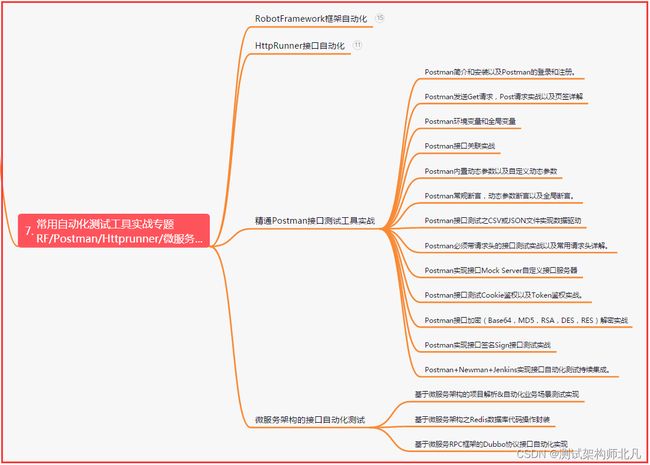
八、JMeter性能测试

九、总结(尾部小惊喜)
在追逐梦想的征程中,不怕步伐缓慢,只怕信念动摇。让我们以坚定的决心破浪前行,用不屈的精神攀登高峰,因为每一次的奋斗,都是对潜力的探索,对成功的呼唤,让我们携手共创辉煌的未来。
无论身处何种困境,都要坚信自己的力量与价值。奋斗不止,梦想不熄,每一次的挑战都是磨砺意志的砂石,唯有坚持到底,我们才能雕琢出独一无二的自我,闪耀在人生的舞台上。
在追逐梦想的道路上,每一次的挫折都是成长的洗礼,每一次的努力都是成功的铺垫。让我们以毅力为帆,智慧为舵,无畏航行在奋斗的海洋中,因为只有坚持不懈,我们才能抵达理想的彼岸,绽放生命的光彩。