BitMap解析之RoaringBitMap
文章目录
-
- BitMap计算的问题
- Roaring BitMap原理解析
-
- Container 介绍
- 1. ArrayContainer
- 2. BitmapContainer
- 3. RunContainer
- 小结
- Roaring BitMap的集合运算
-
- 1. 两个ArrayContainer的and过程
- 2. 两个BitmapContainer的and过程
- 时空分析
- Container的创建与转换
- 为什么说Roaring Bitmap压缩了Bitmap?
RoaringBitmap是一个高效的压缩位图数据结构,用于处理大量的布尔型数据。它是由Facebook开发的一种数据结构,主要用于处理大规模的集合运算,如交集、并集、差集等。RoaringBitmap的主要优点是节省内存和计算资源,因为它使用了一种称为Run-Length Encoding(RLE)的压缩算法来存储数据。
BitMap计算的问题
普通的bitmap如果数据稀疏,那么会浪费大量的空间。例如只存储一个数1000000,那么数组的实际长度是1000000,但是0~999998个位置都是0(999999位是1),需要内存大小为1000000/8/1024 约等于100kb以上,显然浪费了大量内存;假设你需要计算这个位集和另一个位集之间的交集,而另外的那个位集的在1000001处为真,那么你需要遍历所有这些0,显然这对计算资源来说也是一种浪费。
bitmap存储数据,其所占用的存储空间取决于数据集合中值最大的那个数字本身,因为这个数字本身就决定了bit数组的长度,即使只存储一位数字n,那么这个数字之前的0~n-1也都需要存储(值为0)。
鉴于这种情况,虽然用bitmap本身已经给我们的计算带来了存储和速度的极大提升,但是,在一些数据分布不均匀的情况下(数据量比较少,但是其中的数字值本身又比较大的情况),还是可以有进一步的优化空间的。我们需要一种可以进行数据压缩的bitmap,这也就是下面要讨论的Roaring BitMap。
Roaring BitMap原理解析
虽然bitmap已经让数据的存储空间有了N倍的缩减,但使用传统的bitmap仍会占用大量内存(线性增长),所以我们一般还需要对BitMap进行压缩处理。Roaring BitMaps (简称RBM) 就是一种压缩算法。每个RoaringBitmap中都包含一个名为highLowContainer 的 RoaringArray,而highLowContainer则存储了RoaringBitmap中的全部数据。下面以用Java实现的Roaring Bitmap存储32位整数为列来介绍RBM的原理。
RoaringArray highLowContainer;
其中,RoaringArray的数据结构主要包含以下三个成员:
short[] keys;
Container[] values;
int size;
每32位的整数会被切分为高低16位两部分,其中高16位会被作为key存储到short[] keys中(short类型为2个字节即16位),低16位作为value,存储到Container[] values中。keys数组和values数组通过下标一一对应,组成一个32位的数。size则表示当前包含的key-value
对的数量,即keys和values中有效数据的数量。数据结构如下图:
Java使用依赖:
<dependency>
<groupId>org.roaringbitmapgroupId>
<artifactId>RoaringBitmapartifactId>
<version>0.9.0version>
dependency>
Container 介绍
Container是RoaringBitmap的核心,主要有ArrayContainer、BitmapContainer和RunContainer三种。
我们已经知道,每个32位整形的高16位已经作为key存储在RoaringArray中了,那么Container只需要处理低16位的数据。
1. ArrayContainer
static final int DEFAULT_MAX_SIZE = 4096
short[] content;
ArrayContainer结构很简单,只有一个short[] content,用于存储16位的value。并且content不会存储重复数值且始终保持有序,方便二分查找。因为short是2个字节,所以也就是16位,所以说content里面每一个元素存储的就是实际的低16位的数值,此处并没有用位图。
由于这种Container存储数据没有任何压缩,因此只适合存储少量数据。
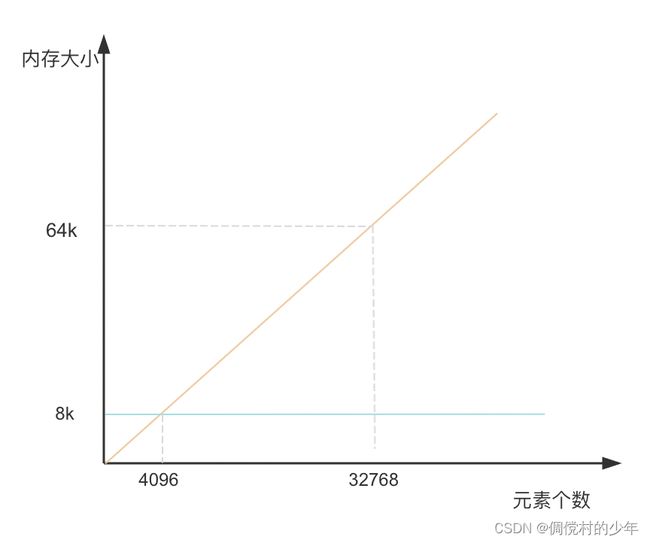
ArrayContainer占用的空间大小与存储的数据量为线性关系,每个short为2字节,也即存储一个数据占用2字节且最多存储4096个数据(DEFAULT_MAX_SIZE),也即最多占用8KB。当容量超过这个值的时候会将当前Container替换为BitmapContainer。
当bitmap数据比较稀疏的时候,例如:2,20000000,那么使用ArrayContainer会大幅缩小内存
2. BitmapContainer
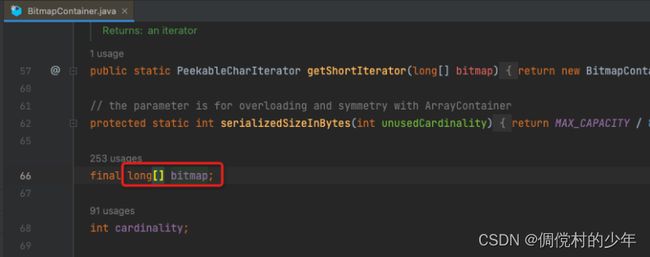
final long[] bitmap;
BtimapContainer使用long[]存储位图数据。由于每个Container处理16位整形的value数据,其数值范围为0~65535,根据位图的原理,每个比特位用1来表示有,0来表示无,因此需要65536个比特来存储数据,而每个long有64位,因此需要1024个long来提供65536个比特。
65536 / 64 = 1024
每个BitmapContainer在构建时就会初始化长度为1024的long[]。也即,一个BitmapContainer中只存储了1个数据还是要占用8KB的空间。 这也是为什么ArrayContainer设置value数组的最大长度为4096的原因,这个数字正好是一个在资源利用上和BitmapContainer相等的分界值。
ArrayContainer和BitMapContainer对比:
3. RunContainer
private short[] valueslength;
int nbrruns = 0;
RunContainer中会根据行程长度压缩算法(Run Length Encoding,简称RLE)对连续数据进行压缩,它的原理是,对于连续出现的数字,只记录初始数字和后续数量。即:
- 对于数列10,它会压缩为10,0;
- 对于数列10,11,12,13,14,15,它会压缩为10,5;
- 对于数列10,11,12,13,14,15,21,22,23,31,32,39,它会压缩为10,5;21,2;31,1;39,0;
RunContainer中的valueslength中存储的就是压缩后的数据。
这种压缩算法的性能和数据的连续性关系非常密切,对于连续的100个short,它能从200字节压缩为4字节,但对于完全不连续的100个short,编码完之后反而会从200字节变为400字节。
对于分析RunContainer的容量,我们可以做下面两种假设:
- 最好情况,即只存在一个数据或只存在一串连续数字,那么只会存储2个short,占用4字节
- 最坏情况,0~65535的范围内填充所有的奇数位(或所有偶数位),需要存储65536个short,128kb
在实际业务场景中,由于人群数据分布的连续性较差,因此,使用RunContainer并不能带来存储空间的效率的提升,且其本身如果进行集合运算操作的话,则需要一个“解压”的过程,这样的话,在进行集合计算时候会显著地影响运算效率,因此处于这两方面的原因,在我们业务的实际场景中,并没有使用RunContainer。
小结
- Array Container:使用short数组存储低16位,元素排序后放入short数组中。没有数据压缩机制,在数据稀疏场景存储效率高。
- Bitmap Container:long数组存储低16位,数据内容对应long类型的bit位,数据稠密存储效率很高。如:1,5,6表达成一个long值为00110001.
- Run Container:低16位使用short数组存储,将连续数据值存储为[起始点,连续个数的格式]。在数据连续性好的场景存储效率高。例如数据[11,12,13,14,15]将存储为两个short数值[11,4]。
在存储效率方面,数据量离散且小于4096时使用array最优,在数据量大且无规律时bitmap最优,在数据连续性比较好的情况下,RunContainer的存储效率最优。
Roaring BitMap的集合运算
上面着重介绍了Roaring Bitmap的数据结构以及在存储方面的特点,在实际应用中,数据存储只是一方面,另一方面还需要基于存储的集合计算,下面以两个values间的求交集(add)操作来说明其实现过程。
1. 两个ArrayContainer的and过程
public ArrayContainer and(final ArrayContainer value2) {
ArrayContainer value1 = this;
final int desiredCapacity = Math.min(value1.getCardinality(), value2.getCardinality());
ArrayContainer answer = new ArrayContainer(desiredCapacity);
answer.cardinality = Util.unsignedIntersect2by2(value1.content, value1.getCardinality(),
value2.content, value2.getCardinality(), answer.content);
return answer;
}
第一步:首先,两个(每个集合内元素不重复)集合运算的交集结果的个数一定小于最小的集合的元素个数,因此用Math.min()方法求的value1和value2中的最小个,结果为desiredCapacity(cardinality表示每个container中values的元素个数)。
第二步:创建一个新的ArrayContainer对象,对其中的values数组初始化容量为desiredCapacity(理论上的最大容量)。
第三步:调用unsignedIntersect2by2方法分别循环两个values数组,然后判断该元素是否在另一个数组中存在,最后得出两个数组的交集元素。由于ArrayContainer中的values数组中的数据是已经排序好的,因此在查找元素时直接使用二分查找法,效率为O(log2n)。
由于ArrayContainer的values数组中存储的直接的数值本身,因此在进行求交集运算时,不能使用bitmap本身的位计算的优势,因此效率较差,但由于其存储的数据量比较小(最多4096个),因此从整体上来看也是兼顾了数据存储和集合运算间的一种平衡。
2. 两个BitmapContainer的and过程
public Container and(final BitmapContainer value2) {
int newCardinality = 0;
for (int k = 0; k < this.bitmap.length; ++k) {
newCardinality += Long.bitCount(this.bitmap[k] & value2.bitmap[k]);
}
if (newCardinality > ArrayContainer.DEFAULT_MAX_SIZE) {
final BitmapContainer answer = new BitmapContainer();
for (int k = 0; k < answer.bitmap.length; ++k) {
answer.bitmap[k] = this.bitmap[k] & value2.bitmap[k];
}
answer.cardinality = newCardinality;
return answer;
}
ArrayContainer ac = new ArrayContainer(newCardinality);
Util.fillArrayAND(ac.content, this.bitmap, value2.bitmap);
ac.cardinality = newCardinality;
return ac;
}
第一步:由上面的介绍可以知道,BitmapContainer的values数组在初始化的时候大小就固定为了1024个,因此循环体中的this.bitmap.length=1024。循环遍历两个BitmapContainer的values,也就是long[] bitmap数组,对两个数组相同位置的元素(每个元素均等同于64个bit元素)进行按位与运算,那么得出的结果就是大的values中的某一个子集(包含64个元素)的计算结果。比如,10011(19) & 10101(22)= 10001。然后在调用Long的bitCount方法求的某个long型整数在二进制表示时候,其中包含“1”的个数。如果进行Long.bitCount(19 & 22)计算,那么得出的结果为2,也即本次计算中相同bit的个数。然后将每次计算的结果进行叠加,最终得出两个集合交集的结果的数量。
第二步:根据上个步骤得出的结果的数量和ArrayContainer的最大容量4096进行对比,如果大于4096那么生成一个ArrayContainer对象,否则生成一个BitmapContiner对象用于存储结果。
第三步:如果是用BitmapContiner存储结果,那么分别遍历两个values bitmap数组,进行step1中已经解释过的两个元素的按位与操作,每次计算得到的结果就是64个bit位的运算结果。然后将运算结果保存在结果中。
第四步:如果是用ArrayContainer存储结果,那么会调用fillArrayAND方法进行ArrayContainer values的填充操作。
从上面的介绍可以看出Roaring Bitmap由于采用了数据压缩在数据存储的空间利用率方面有比较大的优势,且在大数据量的情况下会自动使用Bitmap Container,在计算效率方面也有着极高的性能,因此Roaring Bitmap是一个在存储与计算能力比较平衡的一个选择。
目前,业界对Roaring BitMap的应用比较广泛,比如基于内存的大数据计算引擎Spark、全文搜索引擎Lucene等。
时空分析
增删改查的时间复杂度方面,BitmapContainer只涉及到位运算,显然为O(1)。
而ArrayContainer和RunContainer都需要用二分查找在有序数组中定位元素,故为O(logN)。
空间占用(即序列化时写出的字节流长度)方面,BitmapContainer是恒定为8kb的。ArrayContainer的空间占用与基数(c)有关,为(2 + 2c)B;RunContainer的则与它存储的连续序列数(r)有关,为(2 + 4r)B。
Container的创建与转换
在创建一个新container时,如果只插入一个元素,RBM默认会用ArrayContainer来存储。如果插入的是元素序列的话,则会先根据上面的方法计算ArrayContainer和RunContainer的空间占用大小,并选择较小的那一种进行存储。
当ArrayContainer的容量超过4096后,会自动转成BitmapContainer存储。4096这个阈值很聪明,低于它时ArrayContainer比较省空间,高于它时BitmapContainer比较省空间。也就是说ArrayContainer存储稀疏数据,BitmapContainer存储稠密数据,可以最大限度地避免内存浪费。
注意:ArrayContainer和BitmapContainer可以同时存在。
也就是说如果总数据大小m个字节,那么有m/8个BitmapContainer,剩下来不足8kb的数据用ArrayContainer装载

RBM还可以通过调用特定的API(名为optimize)比较ArrayContainer/BitmapContainer与等价的RunContainer的内存占用情况,一旦RunContainer占用较小,就转换之。也就是说,上图例子中的第二个ArrayContainer可以转化为只有一个二元组0, 100的RunContainer,占用空间进一步下降到10200字节。
为什么说Roaring Bitmap压缩了Bitmap?
1.共用高位
从数据结构就可以看出一个虽然一个key对应一个value(container),但是value是list类型有多个,所以是一对多。根据二八定律,越大的数越少,所以大部分情况下是可以共用高位的。
2.数据量分级
数据量%8kb的部分使用ArrayContainer存储数据的,ArrayContainer对于离散的数据相比于bitmap有很大的压缩空间。
3.连续数据可以使用runcontainer压缩