谷粒商城Ⅱ
文章目录
-
- 1、核心技术复习
- 2、架构图
- 3、provided 只在编译的时候用
- 4、Maven构建项目出现多个root模块解决方法
- 5、查看虚拟机ip: ifconfig ens33
- 6、mybatis中resultMap组合返回参数
- 7、优化分类查询
- 8、resultType和resultMap的区别
- 9、在有事务的情况下mybatis添加useGeneratedKeys=true才能返回主键(主键自增类型)
- 10、跨域
- 11、使用网关的目的
- 12、fastdfs
- 13、minio
- 14、项目启动时爆错 问题原因
- 15、封装minio上传工具类
- 16、Mybatis在collection调用其他mapper方法查询数据
- 17、gateway 域名匹配
- 18、BindingException: Invalid bound statement (not found)的一种原因
- 19、Mapper中返回map格式、List
- 20、将pojo和feign单独写成模块的好处
- 21、redis的数据结构与使用场景
- 22、java的序列化和反序列化
- 23、 分布式锁解决方案
- 24、分布式锁案例
-
- 1.分布式锁案例一
- 2.分布式锁案例二
- 3.分布式锁案例三
- 4.分布式锁案例四
- 5.分布式死锁问题
- 25、堆溢出和栈溢出
-
- 一、jvm堆溢出
- 二、jvm栈溢出
- 26、内存泄漏与内存溢出
- 27、ThreadLocal
- 28、Redisson
- 29、红锁算法(一般公司是不会用的)
- 30、Redisson读写锁 信号量 闭锁 公平锁 非公平锁
- 31、缓存击穿 、缓存穿透 、缓存随机穿透攻击
- 32、布隆过滤器
- 33、缓存不一致问题
- 34、通过切面Aspect+注解的方式 查询数据
- 35、synchronized 本地锁
- 36、string.intern()方法 解决synchronized (String s){} 加锁失效问题
- 37、读写锁
- 38、异步编排
- 39、idea 一次性启动多个服务 compound
- 40、配置类 报错:MyThreadPool required a single bean, but 2 were found
- 41、nacos配置不生效 一直连接localhost:8848 问题
- 42、JVM内存模型
- 43、elasticsearch 全文检索工具
- 44、打印Feign日志
- 45、openFeign 服务调用实体类无法接收问题
- 46、@PostConstruct详解
- 47、@RequestParam @RequestBody 不加注解接收 的区别
- 47、Content-Type之x-www-form-urlencoded和json
- 48、redis zset的使用场景 用于排行榜
- 49、AntPathMatcher
- 50、网关请求拦截
- 51、redis 中操作hash
- 52、@RequestMapping 路径会自动添加/ @getMapping @PostMapping@deleteMapping @putMapping路径必须加/
- 53、防止重复提交订单
- 54、在原有项目导入一个新模块(model)
- 55、为什么使用rabbitmq
- 56、 延迟队列与延迟消息
- 57、延迟插件 保证消息精准过期
- 58、消息确认、消息回退
- 59、消息确认、消息回退 简单配置类代码(上面代码的简化写法)
- 60、备份交换机
- 61、消费者消息手动确认
- 62、事务的解决方式:通过mq保证最终一致性
- 63、ShardingSphere 读写分离
- 64、主从复制
- 65、分库分表
- 66、RAS2 非对称加密 todo
- 67、如何通过@Value 给静态字段赋值 todo原因
- 68、内网穿透工具
- 69、创建支付二维码
- 70、异步通知验签
- 71、mysql模糊替换某个字段的内容
- 72、支付流程
- 73、Lombok的@SneakyThrows详解
- 74、JSONObject转换String key:value 格式
- 75、redis的发布订阅
- 76、代码中使用redis发布订阅
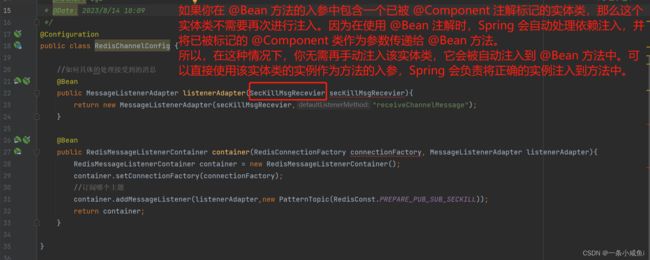
- 77、@bean 的入参中包含一个自定义的已被@component实体类 该实体类不需要@autowrie或者@resource注入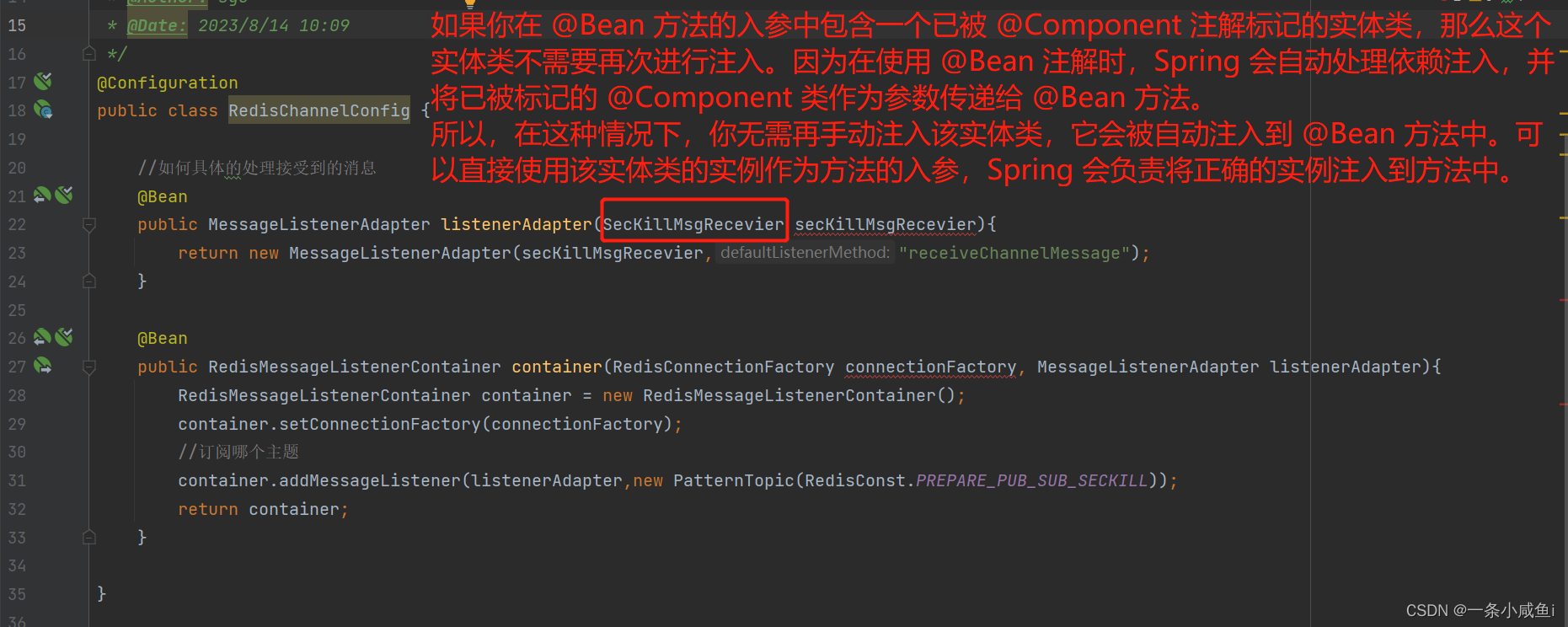
- 78、
- 79、
- 80、
- 81、
- 82、
- 83、
- 84、
- 85、
- 86、
- 87、
- 88、
- 89、
- 90、
- 91、
- 92、
- 93、
- 94、
- 95、
- 96、
- 97、
- 98、
- 99、
- 100、
1、核心技术复习
a.springboot
1).对比springmvc/structs2
作业
2).有starter 封装了和该环境有关的所有依赖
3).自动配置
4).基本上没有xml文件 @Configuration @SpringBootConfiguration
5).习惯优于配置
b.springcloud
对微服务进行治理
说到里面的组件有哪些 用来做什么
c.mybatis-plus(对比mybatis,hibernate,dbutils)
1).帮我们生成controller,service,dao,bean
2).自动生成id
3).字段自动填充
4).线程安全的操作数据库(乐观锁)
5).逻辑删除数据
d.redis
1).redis的数据结构有哪些
2).rdb aof
3).缓存击穿 缓存穿透 缓存雪崩
4).session共享 springsession
5).推荐书籍
Redis设计与实现
https://item.jd.com/27156817180.html
e.rabbitmq
1).流量销峰
2).异步
3).解耦
4).是一个消息中间件
f.文件存储服务
1).minio
2).fastdfs
g.分布式事务
1).数据库事务的概念
2).spring的事务
3).分布式事务的概念(如何解决的)
4).seata(强一致性)
h.seata
1).可用性(Availability)
b活着,就是少了一些数据,无伤大雅,影响不大
勉强可用,修复网线之后,数据恢复正常,系统一切恢复正常
2).一致性(Consistency)
数据对应我们系统运行非常重要,数据如果不一致,会出现严重的问题,此时
只有等待A机器恢复
3).分区容错性(Partition tolerance)
节点被隔离,运行系统容错
4).如何选择
CP 一定要保障数据一致性 只能等待网络恢复 ,系统不可用
AP 保证系统可用性 不要求数据一致性
CA 没有这种组合(单机节点)
2、架构图

3、provided 只在编译的时候用
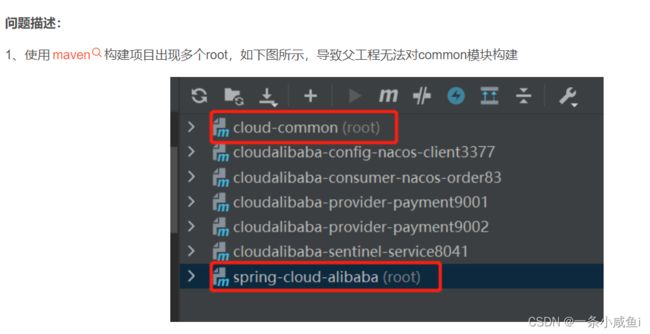
4、Maven构建项目出现多个root模块解决方法

5、查看虚拟机ip: ifconfig ens33

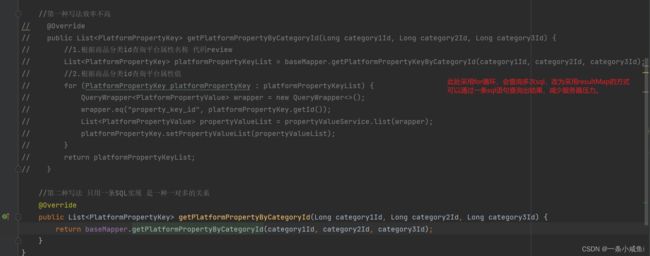
6、mybatis中resultMap组合返回参数
出参格式
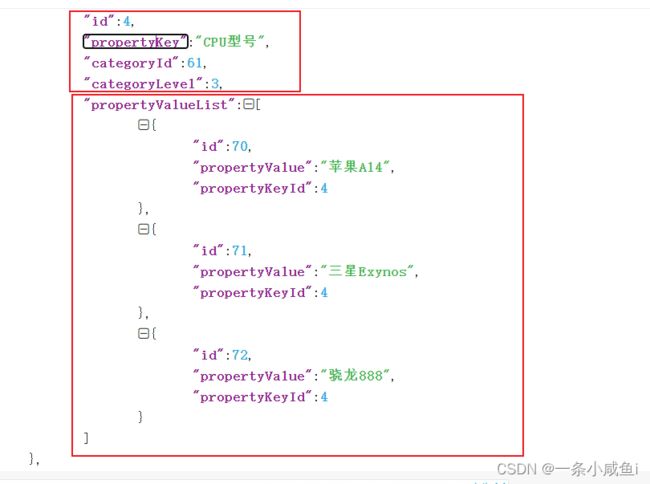 出参实体类
出参实体类
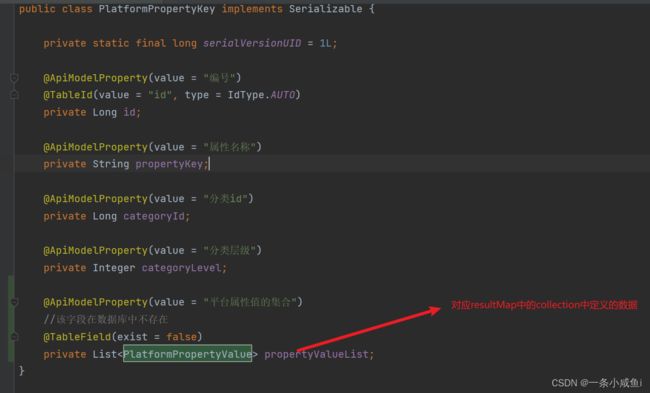
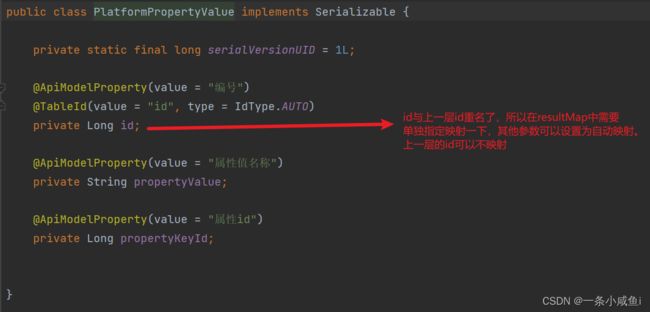
定义resultMap
<resultMap id="platformPropertyMap" type="com.atguigu.entity.PlatformPropertyKey" autoMapping="true">
<id property="id" column="id">id>
<collection property="propertyValueList" ofType="com.atguigu.entity.PlatformPropertyValue" autoMapping="true">
<id property="id" column="property_value_id">id>
collection>
resultMap>
对应关系

7、优化分类查询

8、resultType和resultMap的区别
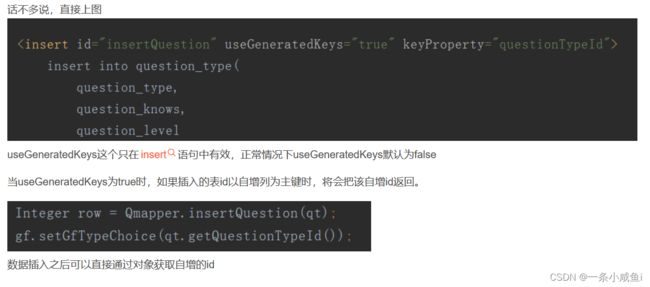
9、在有事务的情况下mybatis添加useGeneratedKeys=true才能返回主键(主键自增类型)
10、跨域
协议(http 、https),域名,端口号任何一个不同都属于跨域
可以通过在yml中的添加如下配置完成
spring:
cloud:
gateway:
globalcors:
cors-configurations:
'[/**]':
allowedOrigins: "*"
allowedMethods: "*"
allowedHeaders: "*"
allowCredentials: true
11、使用网关的目的
a.跨越问题每次都要添加注解
b.后面我们还要利用它对我们的请求进行拦截
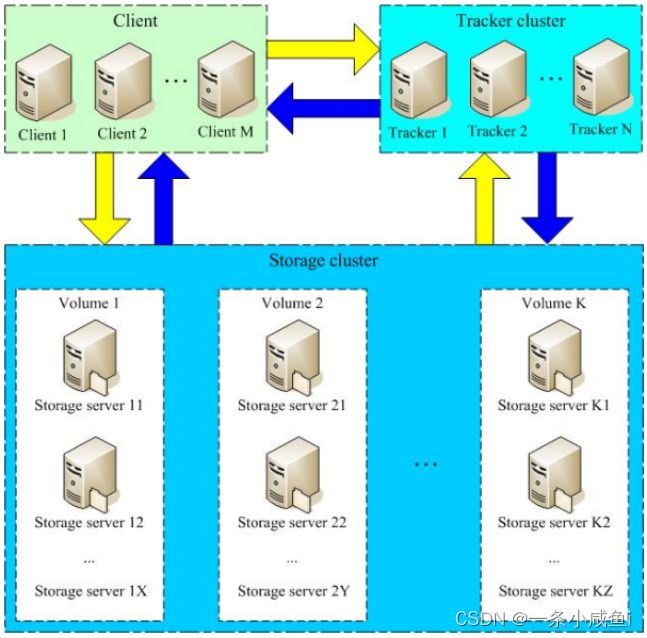
12、fastdfs
fastDFS介绍:
fastDFS是以C语言开发的一项开源轻量级分布式文件系统,他对文件进行管理,主要功能有:文件存储,文件同步,文件访问(文件上传/下载),特别适合以文件为载体的在线服务,如图片网站,视频网站等
分布式文件系统:
对等特性允许一些系统扮演客户端和服务器的双重角色,可供多个用户访问的服务器,比如,用户可以“发表”一个允许其他客户机访问的目录,一旦被访问,这个目录对客户机来说就像使用本地驱动器一样FastDFS由跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)构成。
Tracker server 追踪服务器
追踪服务器负责接收客户端的请求,选择合适的组合storage server ,tracker server 与 storage server之间也会用心跳机制来检测对方是否活着。Tracker需要管理的信息也都放在内存中,并且里面所有的Tracker都是对等的(每个节点地位相等),很容易扩展客户端访问集群的时候会随机分配一个Tracker来和客户端交互。
Storage server 储存服务器
实际存储数据,分成若干个组(group),实际traker就是管理的storage中的组,而组内机器中则存储数据,group可以隔离不同应用的数据,不同的应用的数据放在不同group里面,
优点:
海量的存储:主从型分布式存储,存储空间方便拓展,fastDFS对文件内容做hash处理,避免出现重复文件然后fastDFS结合Nginx集成, 提供网站效率
application.yaml
fastdfs:
prefix: http://192.168.87.128:8888/
tracker.conf
tracker_server=192.168.87.128:22122
# 连接超时时间,针对socket套接字函数connect,默认为30秒
connect_timeout=30000
# 网络通讯超时时间,默认是60秒
network_timeout=60000
@Value("${fastdfs.prefix}")
public String fastdfsPrefix;
@PostMapping("fileUpload")
public RetVal fileUpload(MultipartFile file) throws Exception {
//需要一个配置文件告诉fastdfs在哪里
String configFilePath = this.getClass().getResource("/tracker.conf").getFile();
//初始化
ClientGlobal.init(configFilePath);
//创建trackerClient 客户端
TrackerClient trackerClient = new TrackerClient();
//用trackerClient获取连接
TrackerServer trackerServer = trackerClient.getConnection();
//创建StorageClient1
StorageClient1 storageClient1 = new StorageClient1(trackerServer, null);
//对文件实现上传
String originalFilename = file.getOriginalFilename();
String extension = FilenameUtils.getExtension(originalFilename);
String path = storageClient1.upload_appender_file1(file.getBytes(), extension, null);
System.out.println("文件上传地址:"+fastdfsPrefix+path);
return RetVal.ok(fastdfsPrefix+path);
}
13、minio
官网地址
引入依赖
<dependency>
<groupId>io.miniogroupId>
<artifactId>minioartifactId>
<version>7.0.2version>
dependency>
测试类
public class FileUploader {
public static void main(String[] args) throws NoSuchAlgorithmException, IOException, InvalidKeyException, XmlPullParserException {
try {
//使用MinIO服务的URL,端口,Access key和Secret key创建一个MinioClient对象
MinioClient minioClient = new MinioClient("http://192.168.87.129:9000",
"guli2023", "guli2023");
//检查存储桶是否已经存在
boolean isExist = minioClient.bucketExists("java0216");
if(isExist) {
System.out.println("Bucket already exists.");
} else {
//创建一个名为asiatrip的存储桶,用于存储照片的zip文件。
minioClient.makeBucket("java0216");
}
//使用putObject上传一个文件到存储桶中。
FileInputStream fileInputStream = new FileInputStream("C:\\Users\\11388\\Pictures\\1.jpg");
PutObjectOptions options=new PutObjectOptions(fileInputStream.available(),-1);
options.setContentType("image/jpeg");
minioClient.putObject("java0216","new.jpg",fileInputStream, options);
System.out.println("上传成功");
} catch(MinioException e) {
System.out.println("Error occurred: " + e);
}
}
}
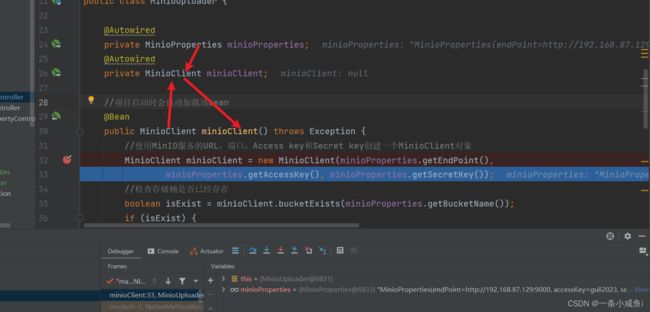
14、项目启动时爆错 问题原因
虽然MinioProperties、MinioClient 两者都被注入到容器中了 但是加载的时候会有先后顺序。
MinioClient在加载时会依赖MinioProperties,所以要先加载MinioProperties;
类中非静态属性(成员变量)的加载顺序与其在代码中的先后循序有关。详情加载顺序如下

错误:
 正确:
正确:
15、封装minio上传工具类
0.注意
1、注意MinioProperties 和 MinioClient 注入的顺序 会影响minioClient bean的加载
因为minioClient bean 在加载时会引用minioProperties中的配置
2、项目启动时会自动加载该bean 将minioClient放到bean中这样只需要在启动时加载一次 后面就可以直接注入后使用
1.配置文件
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
@Data
//在配置文件当中找到以minio开头的配置文件
@ConfigurationProperties(prefix = "minio")
public class MinioProperties {
private String endPoint;
private String accessKey;
private String secretKey;
private String bucketName;
}
2.工具类
import io.minio.MinioClient;
import io.minio.PutObjectOptions;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.stereotype.Component;
import org.springframework.web.multipart.MultipartFile;
import java.io.InputStream;
import java.util.UUID;
/**
* @Description:
* @Author: sgc
* @Date: 2023/5/18 21:48
*/
@EnableConfigurationProperties(MinioProperties.class)
@Component
public class MinioUploader {
//注意MinioProperties 和 MinioClient 注入的顺序 会影响minioClient bean的加载
//因为minioClient bean 在加载时会引用minioProperties中的配置
@Autowired
private MinioProperties minioProperties;
@Autowired
private MinioClient minioClient;
//项目启动时会自动加载该bean 将minioClient放到bean中这样只需要在启动时加载一次 后面就可以直接注入后使用
@Bean
public MinioClient minioClient() throws Exception {
//使用MinIO服务的URL,端口,Access key和Secret key创建一个MinioClient对象
MinioClient minioClient = new MinioClient(minioProperties.getEndPoint(),
minioProperties.getAccessKey(), minioProperties.getSecretKey());
//检查存储桶是否已经存在
boolean isExist = minioClient.bucketExists(minioProperties.getBucketName());
if (isExist) {
System.out.println("Bucket already exists.");
} else {
//创建一个名为asiatrip的存储桶,用于存储照片的zip文件。
minioClient.makeBucket(minioProperties.getBucketName());
}
return minioClient;
}
public String upload(MultipartFile file) throws Exception {
String fileName = UUID.randomUUID() + "name:" + file.getOriginalFilename();
//使用putObject上传一个文件到存储桶中。
InputStream inputStream = file.getInputStream();
PutObjectOptions options = new PutObjectOptions(inputStream.available(), -1);
options.setContentType(file.getContentType());
minioClient.putObject(minioProperties.getBucketName(), fileName, inputStream, options);
System.out.println("上传成功");
//http://39.108.163.132:9000/java0317/new.jpg
String retUrl = minioProperties.getEndPoint() + "/" + minioProperties.getBucketName() + "/" + fileName;
return retUrl;
}
}
16、Mybatis在collection调用其他mapper方法查询数据
<resultMap id="userDeptRspResult" type="com.ruoyi.system.domain.DeptStreetRsp" extends="SysDeptResult">
<collection property="childs" javaType="java.util.ArrayList" ofType="com.ruoyi.common.core.domain.entity.SysDept"
select="com.ruoyi.system.mapper.SysDeptMapper.selectDeptByParentId" column="dept_id" />
resultMap>
<select id="findUserDept" resultMap="userDeptRspResult" parameterType="string">
<include refid="selectDeptVo"/>
where dept_id = #{deptId}
and `status` = '0'
and del_flag='0'
select>
<select id="selectDeptByParentId" resultMap="SysDeptResult" parameterType="string">
<include refid="selectDeptVo"/>
where parent_id = #{pid}
and `status` = '0'
and del_flag='0'
select>
利弊分析
1、对于简单的sql而言,主要的时间消耗都在应用与数据库建立连接上,所以在写代码的时候要尽量考虑到建立网络连接消耗的时间,能一次查回来的情况下,就不要用java遍历查询。
2、就上述的mybatis写法而言,对于资源的节省并没有提升,基本上和使用java遍历调用是一样的,因为mybatis在查询的时候,查询父节点与查询子节点仍是相互独立的,仍是需要与数据库建立两次连接,只是代码编写上简单了些,方便简洁了些。
3、针对于需要查询父子节点这种需要关联节点的情况下,可以考虑使用collection的另一种写法,使用id标签作为父节点,result为子节点接受,这样便可以一次连接下,将结果都查询回来以后,再根据id和result解析到java对象中,节省了建立连接的时间。
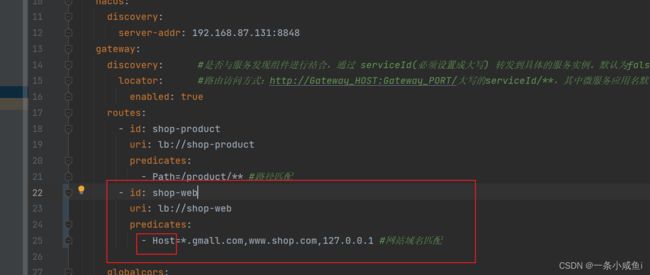
17、gateway 域名匹配
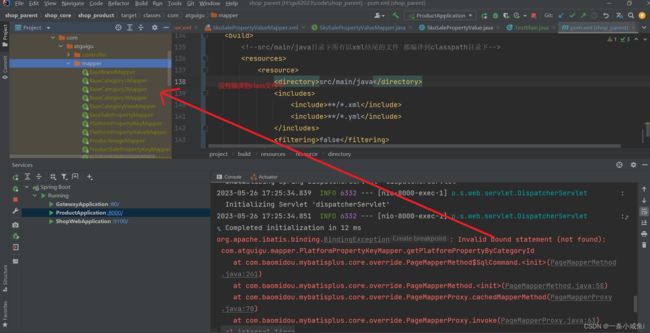
18、BindingException: Invalid bound statement (not found)的一种原因
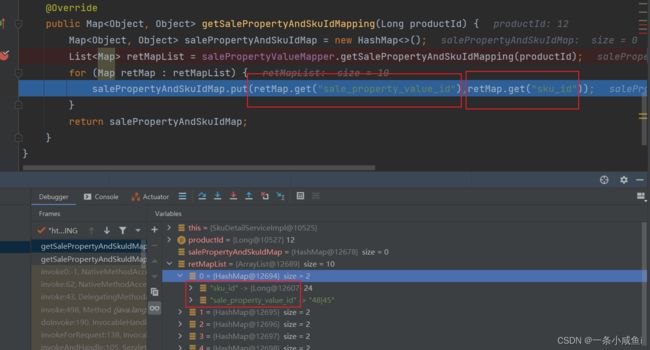
19、Mapper中返回map格式、List格式
首先保证返回值就俩字段,其次只需要将resultType指定为"java.util.Map"即可
如果是List 只需要在dao曾将出参改为List
<select id="getSalePropertyAndSkuIdMapping" resultType="java.util.Map">
SELECT
GROUP_CONCAT(sale_property_value_id SEPARATOR '|' ) sale_property_value_id,
sku_id
FROM
sku_sale_property_value
WHERE
product_id = #{productId}
GROUP BY
sku_id
select>
 使用
使用
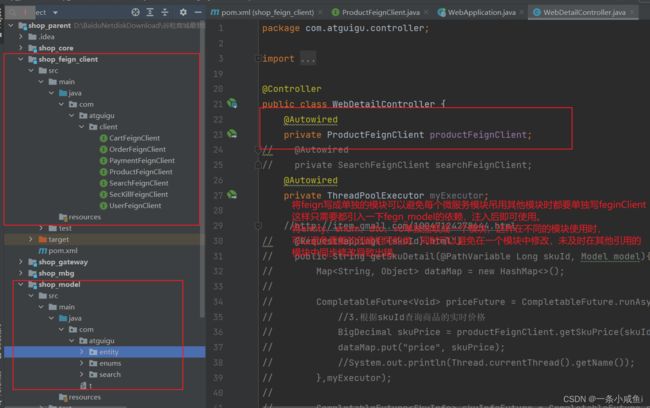
20、将pojo和feign单独写成模块的好处
21、redis的数据结构与使用场景
详情
redis里存的都是二进制数据,其实就是字节数组(byte[]),这些字节数据是没有数据类型的,只有把它们按照合理的格式解码后,可以变成一个字符串,整数或对象,此时才具有数据类型。
这一点必须要记住。所以任何东西只要能转化成字节数组(byte[])的,都可以存到redis里。
管你是字符串、数字、对象、图片、声音、视频、还是文件,只要变成byte数组。Redis使用UTF-8编码

Redis五种数据结构如下:

对redis来说,所有的key(键)都是字符串。
1.String字符串类型
a.概念
最为简单的key-value结构 它可以存储几乎所有的类型
字符串,图片或者视频等信息放到redis中
b.场景
session共享场景 计数器
2.Hash
a.概念
类似于map结构,适用于存储对象
b.场景
缓存 存储对象比String节省空间
3.链表
a.概念
是一种list结构 可以重复有序
b.场景
微博的时间轴,有人发布微博 朋友圈
4.Set集合
a.概念
不允许有重复元素 无序 可以有交集 并集 差集
b.场景
点赞,或点踩,收藏
5.zset有序集合
a.概念
集合有序 给每个元素一个分数 利用分数进行排序
b.场景
抖音榜单 游戏排位
22、java的序列化和反序列化
详情
一、什么是序列化与反序列化?
1、java序列化就是将对象转化为字节序列的过程。
计算机中底层的数据都是以二进制01表示的,一个01二进制是一个位,一个字节包含8位01代码。
Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。
2.java反序列化是将字节序列转化为对象的过程
二、为什么要用序列化与反序列化
在 为什么要用序列化与反序列化 之前我们先了解一下对象序列化的两种用途:
1、把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2、在网络上传送对象的字节序列。


我们可以想象一下如果没有序列化之前,又是怎样一种情景呢?
举个栗子:
Web 服务器中的 Session 会话对象,当有10万用户并发访问,就有可能出现10万个 Session 对象,显然这种情况内存可能是吃不消的。
于是 Web 容器就会把一些 Session 先序列化,让他们离开内存空间,序列化到硬盘中,当需要调用时,再把保存在硬盘中的对象还原到内存中。
我们知道,当两个进程进行远程通信时,彼此可以发送各种类型的数据,包括文本、图片、音频、视频等, 而这些数据都会以二进制序列的形式在网络上传送。
同样的序列化与反序列化则实现了 进程通信间的对象传送,发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。

三、如何实现序列化与反序列化?
1、JDK类库中序列化API
使用到JDK中关键类 ObjectOutputStream(对象输出流) 和ObjectInputStream(对象输入流)
ObjectOutputStream 类中:通过使用 writeObject(Object object) 方法,将对象以二进制格式进行写入。
ObjectInputStream 类中:通过使用 readObject()方法,从输入流中读取二进制流,转换成对象。
2、目标对象实现Serizalizable接口
我们创建一个 User 类,实现 Serializable 接口,并生成一个版本号 :serialVersionUID
}
a. Serializable接口的作用只是用来标识我们这个类是需要进行序列化,并且Serializable接口中并没有提供任何方法。
b. SerialVersionUID序列化版本号的作用是用来区分我们所编写的类的版本,用于判断反序列化时类的版本是否一致,如果不一致会出现版本不一致异常。
c. transient关键字,主要用来忽略我们不希望进行序列化的变量。
四、serialVersionUID是什么?
答:序列化版本号,取值是 Java 运行时环境根据类的内部细节自动生成的。如果对类的源代码作了修改,再重新编译,新生成的类文件的 serialVersionUID 的取值有可能也会发生变化。。
继承程序帮我们自动生成,那为何还要去定义该属性?
序列化和反序列化就是通过对比其 SerialversionUID 来进行的,我们修改一个实现 Serializable 接口的实体类,重新编译后,显然程序会重新会生成新值,那么一旦SerialversionUID 跟之前不匹配,反序列化就无法成功。
在实际的生产环境中,我们可能会建一系列的中间 Object 来反序列化我们的 pojo,为了解决这个问题,我们就需要在实体类中自定义 SerialversionUID,就像上方示例,不管我们序列化之后如何更改我们的 实体(不删除原有字段),最终都可以反序列化成功

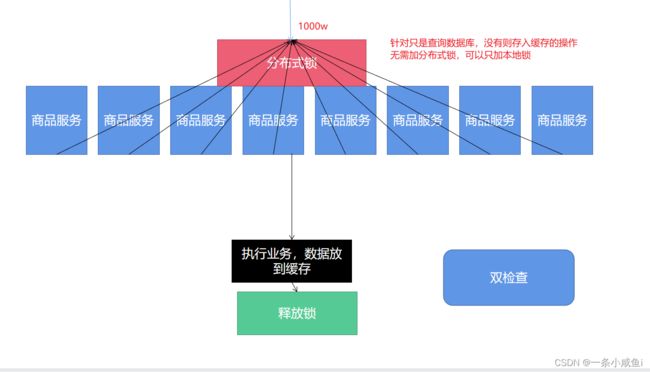
23、 分布式锁解决方案
a.基于数据库实现分布式锁
性能低 还可能出现锁表的情况
使用数据库实现分布式锁需要建一张lock表,表中设置一个unique索引,获取锁时,尝试给表中insert记录,若失败,则说明锁被别的线程抢占了,还未释放。当处理完业务,释放锁,删除表中的那条记录即可(物理删除)。
一旦解锁失败,会导致锁记录一直在数据库中,其他线程无法再获得锁,应该怎么解决?
每次加锁之前我们先判断已经存在的记录的创建时间和当前系统时间之间的差是否已经超过超时时间,如果已经超过则先删除这条记录,再插入新的记录
1.增加过期时间。 2.增加定时任务来维护过期未释放锁的场景。
详情
b.基于zookeeper
c.基于redis(重点学习)
d.redission(使用)
24、分布式锁案例
1.分布式锁案例一
a.概念
利用setnx来做判断 当设置的key不存在的时候 setnx会生效
SET if Not eXists 业务做完之后还需要删除锁
b.解决方案
setIfAbsent
2.分布式锁案例二
a.方案一可能出现的问题
如果doBusiness出现异常 可能导致锁一直占用 无法释放
b.解决方案
给它一个过期时间
3.分布式锁案例三
a.方案二可能出现的问题
由于锁的过期时间和业务时间不一致 可能会删除其他线程的锁
b.解决方案
设置锁的值为一个UUID,删除锁之前给一个判断 再删除
4.分布式锁案例四
a.方案三可能出现的问题
判断和删除这两个语句缺乏原子性
b.解决方案
让这两句话具备原子性 lua脚本实现比较与删除为原子操作
栈溢出异常 nested exception is java.lang.StackOverflowError
原因:一直递归调用 导致栈中不断产生方法压栈(一次方法调用就是一次入栈,方法执行完就会出栈)
-Xms100m -Xmx100m -Xss20m
5.分布式死锁问题
25、堆溢出和栈溢出
jvm内存模型详解

jvm内存模型
一、jvm堆溢出

1、介绍
在jvm运行java程序时,如果程序运行所需要的内存大于系统的堆最大内存(-Xmx),就会出现堆溢出问题。
2、案例

 3、总结
3、总结
在正式项目部署环境程序默认读取的是系统的内存,一般设置程序的堆初始内存(-Xms) == 堆最大可用内存(-Xmx)。
二、jvm栈溢出


1、介绍
a、线程请求的栈深度大于虚拟机允许的最大深度 StackOverflowError
b、虚拟机在扩展栈深度时,无法申请到足够的内存空间 OutOfMemoryError
理解:每次方法调用都会有一个栈帧压入虚拟机栈,操作系统给JVM分配的内存是有限的,JVM分配给“虚拟机栈”的内存是有限的。如果方法调用过多,导致虚拟机栈满了就会溢出。这里栈深度就是指栈帧的数量。
2、案例

 总结:每个计算机都会有一个极限最大调用深度,避免递归在代码中无限循环。
总结:每个计算机都会有一个极限最大调用深度,避免递归在代码中无限循环。
局部变量表内容越多,栈帧越大,栈深度越小。详解
知道了栈深度,该怎么用呢?对JVM调优有什么用呢?
当JVM我们定义的方法参数和局部变量过多,字节过大,考虑到可能会导致栈深度过小,可能使程序出现错误。
这个时候就需要手动的增加栈的深度,避免出错。
而且当看到StackOverFlow的时候我们也可以知道可能是栈溢出造成的错误。知道如果去解决。这才是最重要的。
26、内存泄漏与内存溢出
一、内存泄漏memory leak :
内存泄露就是堆内存中不再使用的对象,但是垃圾回收期无法从内存中删除他们的情况,因此他们会被不必要的一直存在。这种情况会耗尽内存资源并降低系统性能,最终以OOM终止。
二、内存溢出 out of memory :
指程序申请内存时,没有足够的内存供申请者使用,或者说,给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错OOM,即所谓的内存溢出。
三、二者的关系:
内存泄漏的堆积最终会导致内存溢出
内存溢出就是你要的内存空间超过了系统实际分配给你的空间,此时系统相当于没法满足你的需求,就会报内存溢出的错误。
四、常见内存泄漏
1、static字段引起的内存泄露
大量使用static字段会潜在的导致内存泄露,在Java中,静态字段通常拥有与整个应用程序相匹配的生命周期。
解决办法:最大限度的减少静态变量的使用;单例模式时,依赖于延迟加载对象而不是立即加载方式。
2、未关闭的资源导致内存泄露
每当创建连接或者打开流时,JVM都会为这些资源分配内存。如果没有关闭连接,会导致持续占有内存。在任意情况下,资源留下的开放连接都会消耗内存,如果我们不处理,就会降低性能,甚至OOM。
解决办法:使用finally块关闭资源;关闭资源的代码,不应该有异常;jdk1.7后,可以使用try-with-resource块。
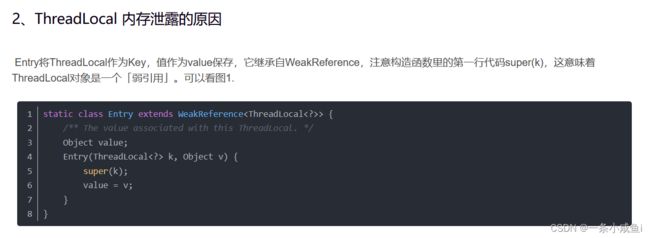
3、使用ThreadLocal造成内存泄露
使用ThreadLocal时,每个线程只要处于存活状态就可保留对其ThreadLocal变量副本的隐式调用,且将保留其自己的副本。使用不当,就会引起内存泄露。
一旦线程不在存在,ThreadLocals就应该被垃圾收集,而现在线程的创建都是使用线程池,线程池有线程重用的功能,因此线程就不会被垃圾回收器回收。所以使用到ThreadLocals来保留线程池中线程的变量副本时,ThreadLocals没有显示的删除时,就会一直保留在内存中,不会被垃圾回收。
解决办法:不在使用ThreadLocal时,调用remove()方法,该方法删除了此变量的当前线程值。不要使用ThreadLocal.set(null),它只是查找与当前线程关联的Map并将键值对设置为当前线程为null。
五、常见内存溢出
1、java堆内存溢出
当出现java.lang.OutOfMemoryError:Java heap space异常时,就是堆内存溢出了。
2、java堆内存泄漏
Java中的内存泄漏是一些对象不再被应用程序使用但垃圾收集无法识别的情况。因此,这些未使用的对象仍然在Java堆空间中无限期地存在。不停的堆积最终会触发java . lang.OutOfMemoryError。
3、栈内存溢出
当一个线程执行一个Java方法时,JVM将创建一个新的栈帧并且把它push到栈顶。此时新的栈帧就变成了当前栈帧,方法执行时,使用栈帧来存储参数、局部变量、中间指令以及其他数据。
当一个方法递归调用自己时,新的方法所产生的数据(也可以理解为新的栈帧)将会被push到栈顶,方法每次调用自己时,会拷贝一份当前方法的数据并push到栈中。因此,递归的每层调用都需要创建一个新的栈帧。这样的结果是,栈中越来越多的内存将随着递归调用而被消耗,如果递归调用自己一百万次,那么将会产生一百万个栈帧。这样就会造成栈的内存溢出。
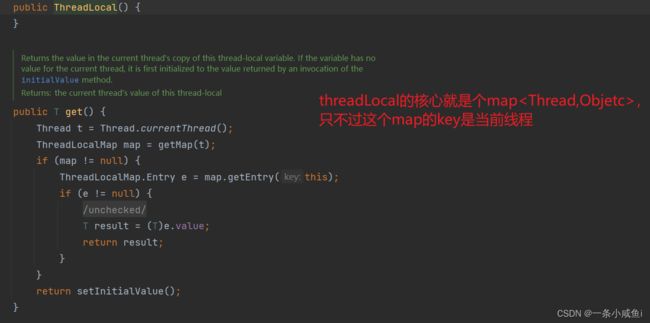
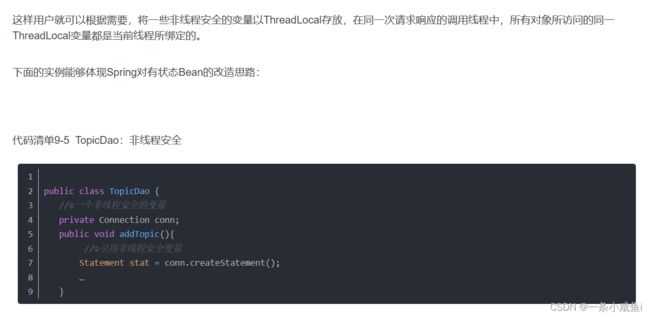
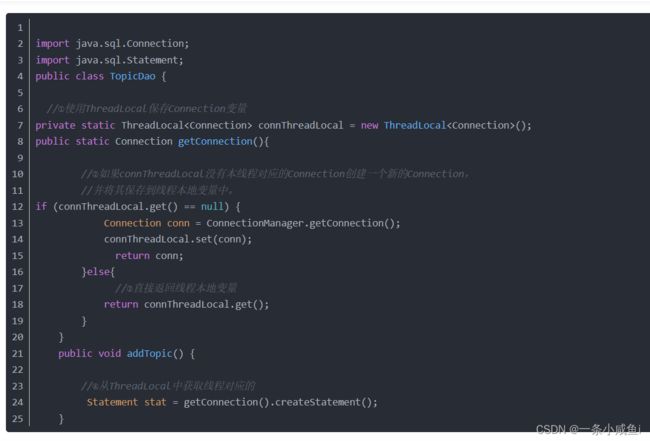
27、ThreadLocal
详解1
详解2
ThreadLocal叫做线程变量,意思是ThreadLocal中填充的变量属于当前线程,该变量对其他线程而言是隔离的,也就是说该变量是当前线程独有的变量。







28、Redisson
核心:
* a.默认有个30s的过期时间 internalLockLeaseTime=30s=lockWatchdogTimeout
* b.看门狗机制,将我们的锁自动续期 每隔10s(过期时间的三分之)就会自动续期 internalLockLeaseTime / 3
* c.获取锁/释放锁===>lua脚本

 如何解决锁过期问题
如何解决锁过期问题
一般来说,我们去获得分布式锁时,为了避免死锁的情况,我们会对锁设置一个超时时间,但是有一种情况是,如果在指定时间内当前线程没有执行完,由于锁超时导致锁被释放,那么其他线程就会拿到这把锁,从而导致一些故障。
为了避免这种情况,Redisson引入了一个Watch Dog机制,这个机制是针对分布式锁来实现锁的自动续约,简单来说,如果当前获得锁的线程没有执行完,那么Redisson会自动给Redis中目标key延长超时时间。默认情况下,看门狗的续期时间是30s,也可以通过修改Config.lockWatchdogTimeout来另行指定。
29、红锁算法(一般公司是不会用的)
如果只有redis为单节点(只有一台),宕机了怎么办?可以考虑搭建集群,主从复制、哨兵模式。
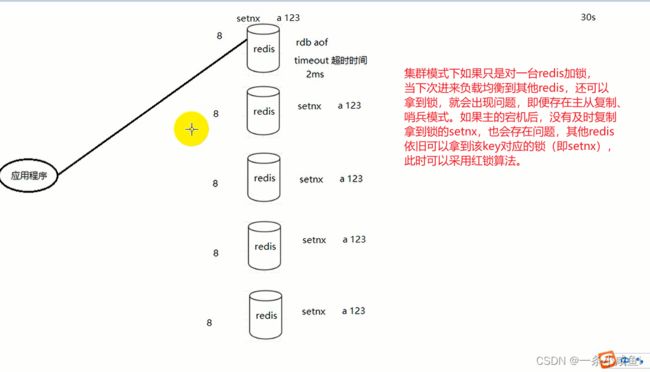



30、Redisson读写锁 信号量 闭锁 公平锁 非公平锁
1、读写锁
//测试写锁
String uuid="";
@GetMapping("write")
public String write() {
RReadWriteLock rwLock = redissonClient.getReadWriteLock("rwLock");
RLock writeLock = rwLock.writeLock();
try {
writeLock.lock();
SleepUtils.sleep(12);
uuid=UUID.randomUUID().toString();
System.out.println(Thread.currentThread().getName()+"执行业务"+uuid);
} finally {
writeLock.unlock();
}
return Thread.currentThread().getName()+"执行业务"+uuid;
}
@GetMapping("read")
public String read() {
RReadWriteLock rwLock = redissonClient.getReadWriteLock("rwLock");
RLock readLock = rwLock.readLock();
try {
readLock.lock();
return uuid;
} finally {
readLock.unlock();
}
}
2、信号量
用途:比如用信号量来作为商品库存,防止超卖,信号量设置为1,就表示库存是1,tryAcquire 之后,信号量减1,
减到0就表示库存不足了,这时候应该不需要release了的,release相当于又把库存加回去了
/**
* 测试Semaphore 停车场有5个车位
*/
@GetMapping("park")
public String park() throws Exception{
RSemaphore parkStation = redissonClient.getSemaphore("park_station");
parkStation.trySetPermits(5);
//信号量减1
parkStation.acquire(1);
System.out.println(Thread.currentThread().getName()+"找到车位");
return Thread.currentThread().getName()+"找到车位";
}
@GetMapping("left")
public String left() throws Exception{
RSemaphore parkStation = redissonClient.getSemaphore("park_station");
//信号量加1
parkStation.release(1);
System.out.println(Thread.currentThread().getName()+"left");
return Thread.currentThread().getName()+"left";
}
3、闭锁 CountDownLatch
@GetMapping("leftClassRoom")
public String leftClassRoom() throws Exception{
RCountDownLatch leftClassroom = redissonClient.getCountDownLatch("left_classroom");
//有人走了 数量减一
leftClassroom.countDown();
return Thread.currentThread().getName()+"学员离开";
}
@GetMapping("lockDoor")
public String lockDoor() throws Exception{
RCountDownLatch leftClassroom = redissonClient.getCountDownLatch("left_classroom");
//假如6个人
leftClassroom.trySetCount(6);
leftClassroom.await();
return Thread.currentThread().getName()+"班长离开";
}
4、公平锁 redissonClient.getFairLock("fair-lock")按照等待的顺序拿锁 (性能低)
每个线程获取锁的顺序是按照线程访问锁的先后顺序获取的,最前面的线程总是最先获取到锁
//公平锁
@GetMapping("fairLock/{id}")
public String fairLock(@PathVariable Long id) throws Exception{
RLock fairLock = redissonClient.getFairLock("fair-lock");
fairLock.lock();
SleepUtils.sleep(8);
System.out.println("公平锁-"+id);
fairLock.unlock();
return "success";
}
5、非公平锁(默认) redissonClient.getLock("unfair-lock")选择随机一个等待的线程拿锁 (性能高)
非公平锁:每个线程获取锁的顺序是随机的,并不会遵循先来先得的规则,所有线程会竞争获取锁
//非公平锁
@GetMapping("unFairLock/{id}")
public String unFairLock(@PathVariable Long id) throws Exception{
RLock unFairLock = redissonClient.getLock("unfair-lock");
unFairLock.lock();
SleepUtils.sleep(8);
System.out.println("非公平锁-"+id);
unFairLock.unlock();
return "success";
}
31、缓存击穿 、缓存穿透 、缓存随机穿透攻击
1.缓存击穿
a.概念
缓存中某个热点key失效,高并发场景下,大量请求访问数据库,导致数据库压力过大
b.解决方案
加锁 分布式锁
2.缓存穿透
a.概念
数据库中根本不存在要查询的值,就算查询了也是空值
放入缓存也是空值 高并发场景下,大量请求访问数据库,导致数据库压力过大
b.解决方案
创建一个skuInfo的空值对象 放入缓存 设置一个过期时间
3.缓存随机穿透攻击
a.概念
访问者每次访问数据在数据库中都不存在
此时缓存穿透解决方案不能解决 加锁也不能解决
b.解决方案
布隆过滤器
4.缓存雪崩
a.概念
缓存中大批量的key失效 高并发访问压力过大
b.解决方案
缓存时间key 不要设置为一样
32、布隆过滤器
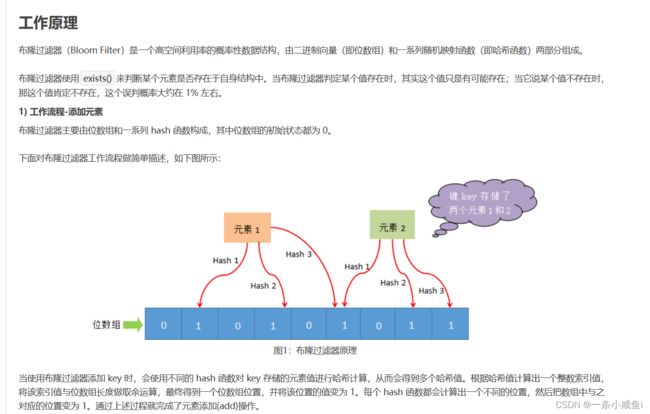
1.原理
把要查询的数据库表id放到一个集合(容器)中
查数据库之前看该id在容器中是否存在
如果容器中存在 那么数据库中也存在 反之不存在
所以在查数据之前就知道该数据在数据库中是否存在


2.用long类型存储在内存占用的空间
long=8字节 1字节=8位
1K=1024字节
10亿条记录 10000000008/1024/1024=7630MB=7GB
占用空间大 大V问题
3.大V问题(redis作为容器)
用位存储 比用字节存储占更少的空间
1000000008/1024/1024/8=95MB
按照1位存储 布隆过滤器有可能存在误判问题 布隆说没有就一定没有
误判率具体大小根据你们公司请求量还有资本决定
4、项目中使用
a、添加配置类
@Configuration
public class BloomFilterConfig {
@Autowired
private RedissonClient redissonClient;
@Bean
public RBloomFilter bloomFilter() {
//指定布隆过滤器的名称 存储的数据类型
RBloomFilter<Long> bloomFilter = redissonClient.getBloomFilter(RedisConst.BLOOM_SKU_ID);
//初始化布隆过滤器的大小与容错率
bloomFilter.tryInit(10000,0.001);
return bloomFilter;
}
}
b、初始化布隆过滤器
在数据库中加载需要布隆的表所有的id,以hash散列放到布隆过滤器中
放了之后布隆过滤器就知道你有哪些id
@RestController
@RequestMapping("/init")
public class BloomFilterController {
@Autowired
private RBloomFilter skuBloomFilter;
@Autowired
private SkuInfoService skuInfoService;
//TODO 定时任务 每天晚上或者其他时间 同步数据库与布隆过滤器里面的内容
@GetMapping("/sku/bloom")
public String setBloom() {
//如果数据库有变化 还需要同步布隆过滤器
skuBloomFilter.delete();
//初始化布隆过滤器的大小与容错率
skuBloomFilter.tryInit(10000, 0.001);
//加载数据库中所有的id
QueryWrapper<SkuInfo> wrapper = new QueryWrapper<>();
wrapper.select("id");
List<SkuInfo> skuInfoList = skuInfoService.list(wrapper);
for (SkuInfo skuInfo : skuInfoList) {
Long skuId = skuInfo.getId();
//把他放入到布隆过滤器里面
skuBloomFilter.add(skuId);
}
return "success";
}
}
c、每次在查数据库之前先查询布隆过滤器,看是否有数据
布隆说没有就一定没有(不需要再查数据库),布隆说有不一定有(误判)

33、缓存不一致问题
1.概念
对于多个数据源操作由于有先后顺序,导致数据不一致
addDB
addRedis
更新库存 decreaseDb-10(线程一) redis-10
2.双写模式
由于线程卡顿,慢线程覆盖了新的数据
如果对一致性要求不是太严苛,基于缓存可以给一个过期时间
该模式也可以实现最终一致性
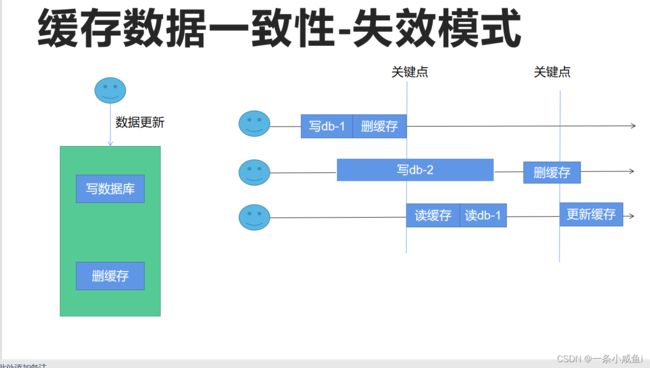
 3.失效模式
3.失效模式
第一个线程把数据库改为1,并立即删除缓存
第二个线程把数据库改为2(同时网络卡顿,写的时间延迟)
第三个线程来读,缓存里面没有数据,读到数据库1的数据
把数据写到缓存中(网络卡顿),但是第二个线程删除缓存删了个寂寞
删除了之后第三个线程才开始更新缓存,此时缓存的数据不是最新的db数据
 4.延迟双删
4.延迟双删
性能问题,需要延迟一些操作
异步处理(不能控制操作的先后顺序)
在极端情况下,如果更新缓存速度慢,也会出现缓存不一致的问题

5.结论
无论如何,缓存一致性问题都没有办法解决
当然我们用的最多的就是延迟双删+缓存过期时间
6.是否还有其他办法
a.加锁
牺牲性能换取一致性 数据安全
本地锁 分布式锁 读写锁 重入锁 自旋锁 偏量锁 红锁 锁的的粒度
b.引入中间件 canel
增加学习成本,会增加维护成本
 7.缓存数据
7.缓存数据
读多写少
缓存数据
商品分类信息
商品信息
写多读多
增强数据库
写少读少
直接使用数据库
缓存过期时间
商品(5-10)
促销商品(1天)
不要过度设计
在公司里面不要太设计 增加成本 人力 资金成本
34、通过切面Aspect+注解的方式 查询数据
1、定义注解
//指明该注解可以用在什么地方
@Target({ElementType.TYPE,ElementType.METHOD})
//指明该注解的生命周期
@Retention(RetentionPolicy.RUNTIME)
public @interface ShopCache {
String prefix() default "cache";
boolean enableBloom() default false;
}
2、编写切面 环绕增强
import com.atguigu.constant.RedisConst;
import org.aspectj.lang.ProceedingJoinPoint;
import org.aspectj.lang.annotation.Around;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.reflect.MethodSignature;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RLock;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.stereotype.Component;
import java.lang.reflect.Method;
import java.util.concurrent.TimeUnit;
/**
* @Description:
* @Author: sgc
* @Date: 2023/6/3 16:30
*/
@Component
@Aspect
public class ShopCacheAspect {
@Autowired
private RedisTemplate redisTemplate;
@Autowired
private RedissonClient redissonClient;
@Autowired
private RBloomFilter skuBloomFilter;
//利用redisson分布式锁
@Around("@annotation(com.atguigu.cache.ShopCache)")
public Object cacheAroundAdvice(ProceedingJoinPoint target) throws Throwable {
//a.需要从目标方法上面去拿到参数skuId
Object[] methodParams = target.getArgs();
//b.拿到目标方法
MethodSignature methodSignature = (MethodSignature) target.getSignature();
Method targetMethod = methodSignature.getMethod();
ShopCache shopCache = targetMethod.getAnnotation(ShopCache.class);
//c.拿到注解里面的value的值 布隆开关
String prefix = shopCache.prefix();
boolean enableBloom = shopCache.enableBloom();
//sku:24:info
Object firtMethodParam = methodParams[0];
String cacheKey = prefix + ":" + firtMethodParam;
//从缓存中查询数据
Object cacheObject = (Object) redisTemplate.opsForValue().get(cacheKey);
//如果缓存不为空
if (cacheObject == null) {
String lockKey = "lock-" + firtMethodParam;
RLock lock = redissonClient.getLock(lockKey);
lock.lock();
try {
Object objectDb = null;
if (enableBloom) {
boolean flag = skuBloomFilter.contains(firtMethodParam);
if (flag) {
//执行目标方法
objectDb = target.proceed();
}
} else {
//执行目标方法
objectDb = target.proceed();
}
//把数据放入缓存
redisTemplate.opsForValue().set(cacheKey, objectDb, RedisConst.SKUKEY_TIMEOUT, TimeUnit.SECONDS);
return objectDb;
} finally {
lock.unlock();
}
}
return cacheObject;
}
}
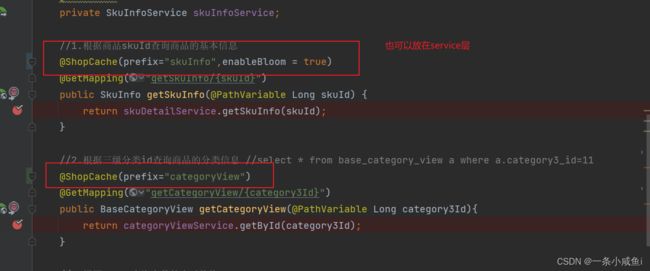
3、使用注解
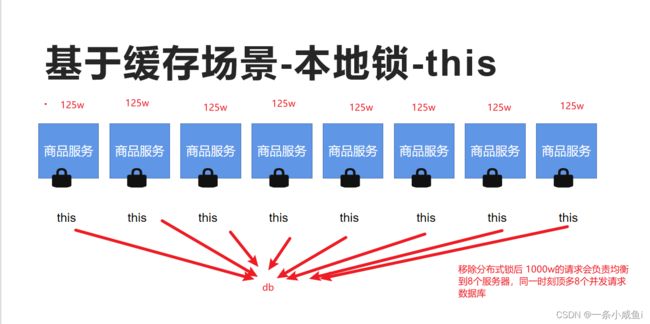
35、synchronized 本地锁
")
public Object cacheAroundAdvice2(ProceedingJoinPoint target) throws Throwable {
//a.需要从目标方法上面去拿到参数skuId
Object[] methodParams = target.getArgs();
//b.拿到目标方法
MethodSignature methodSignature = (MethodSignature) target.getSignature();
Method targetMethod = methodSignature.getMethod();
ShopCache shopCache = targetMethod.getAnnotation(ShopCache.class);
//c.拿到注解里面的value的值 布隆开关
String prefix = shopCache.prefix();
boolean enableBloom = shopCache.enableBloom();
//sku:24:info
Object firtMethodParam = methodParams[0];
String cacheKey = prefix + ":" + firtMethodParam;
//从缓存中查询数据
Object cacheObject = (Object) redisTemplate.opsForValue().get(cacheKey);
//如果缓存不为空
if (cacheObject == null) {
String lockKey = "lock-" + firtMethodParam;
//两个线程拿到的锁是一模一样的锁 第一次并发访问加锁会出现问题 双重检查实现
synchronized (lockKey.intern()) {
//从缓存中查询数据
cacheObject = (Object) redisTemplate.opsForValue().get(cacheKey);
if (cacheObject == null) {
Object objectDb = null;
if (enableBloom) {
boolean flag = skuBloomFilter.contains(firtMethodParam);
if (flag) {
//执行目标方法
objectDb = target.proceed();
}
} else {
//执行目标方法
objectDb = target.proceed();
}
//把数据放入缓存
redisTemplate.opsForValue().set(cacheKey, objectDb, RedisConst.SKUKEY_TIMEOUT, TimeUnit.SECONDS);
return objectDb;
}
}
}
return cacheObject;
}
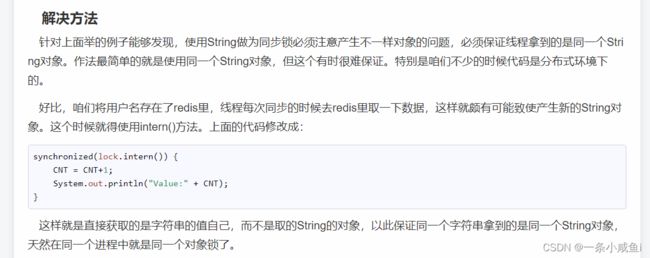
36、string.intern()方法 解决synchronized (String s){} 加锁失效问题

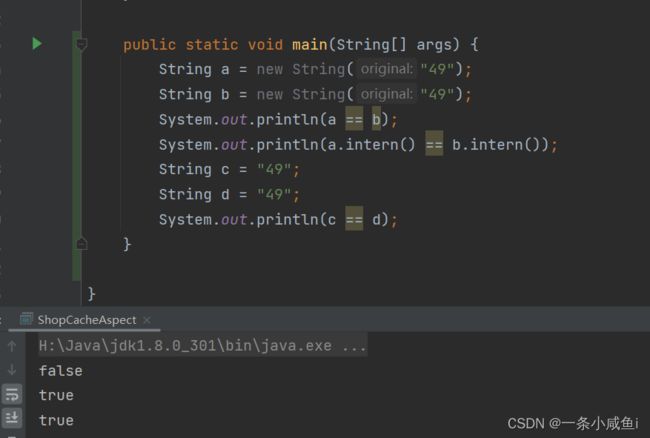
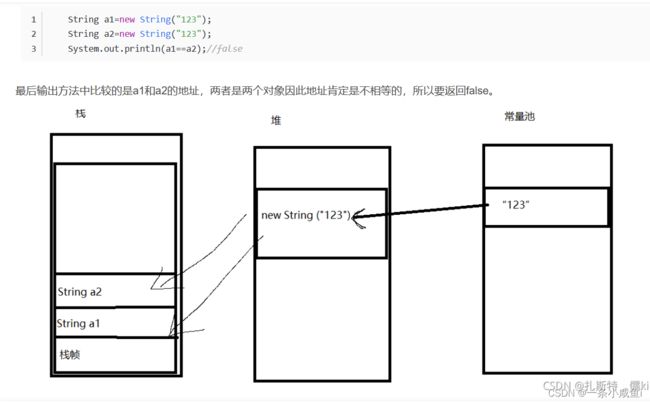
synchronized (String s){} 加锁失效问题 可以通过锁s.intern解决

37、读写锁

//利用读写锁实现
@Around("@annotation(com.atguigu.cache.ShopCache)")
public Object cacheAroundAdvice3(ProceedingJoinPoint target) throws Throwable {
//a.需要从目标方法上面去拿到参数skuId
Object[] methodParams = target.getArgs();
//b.拿到目标方法
MethodSignature methodSignature = (MethodSignature) target.getSignature();
Method targetMethod = methodSignature.getMethod();
ShopCache shopCache = targetMethod.getAnnotation(ShopCache.class);
//c.拿到注解里面的value的值 布隆开关
String prefix = shopCache.prefix();
//sku:24:info
Object firtMethodParam = methodParams[0];
String cacheKey = prefix + ":" + firtMethodParam;
String lockKey = "lock-" + firtMethodParam;
RReadWriteLock rwLock = redissonClient.getReadWriteLock(lockKey);
Object cacheObject;
try {
//读锁
rwLock.readLock().lock();
//从缓存中查询数据
cacheObject = (Object) redisTemplate.opsForValue().get(cacheKey);
rwLock.readLock().unlock();
//如果缓存不为空
if (cacheObject == null) {
rwLock.writeLock().lock();
//从缓存中查询数据 执行目标方法
Object objectDb = target.proceed();
//把数据放入缓存
redisTemplate.opsForValue().set(cacheKey, objectDb, RedisConst.SKUKEY_TIMEOUT, TimeUnit.SECONDS);
rwLock.writeLock().unlock();
return objectDb;
}
//纯粹了照顾finally
rwLock.readLock().lock();
} finally {
rwLock.readLock().unlock();
}
return cacheObject;
}
38、异步编排
1.使用它的原因
a.如果我们采用同步执行 需要花费更多的时间
b.如果我们创建多个线程,无法保证线程执行顺序
c.如果请求线程太多,会占用大量的内存,利用线程复用(线程池) 可以解决空间/开销
2.异步编排的基础知识
a.知识点一
supplyAsync 有返回值 异步请求
runAsync 没有返回值 异步请求
b.知识点二
whenComplete
类似于vue发起异步请求之后的then方法
不管是否有异常都会执行
exceptionally
类似于vue发起异步请求之后的catch方法
有异常才执行
c.知识点三
whenComplete(同步)
发起异步请求之后 交给发起异步请求的线程继续执行
whenCompleteAsync(异步)
发起异步请求之后 异步线程池继续执行
d.知识点四
thenAccept
没有返回值 依赖异步执行完再做 还是异步执行 串行
thenApply
有返回值 依赖异步执行完再做 还是异步执行 串行
e.知识点五
thenApply
使用的是串行
thenApplyAsync
使用的是并行
f.总结
只要多了一个Async就代表异步,异步就是启动另外的线程去执行
xxxpply代表有返回值
39、idea 一次性启动多个服务 compound

40、配置类 报错:MyThreadPool required a single bean, but 2 were found
//@Component
@ConfigurationProperties(prefix = "thread.pool")
public class MyThreadPoolProperties {
不能同时添加 @Component @ConfigurationProperties都是扫描组件的意思
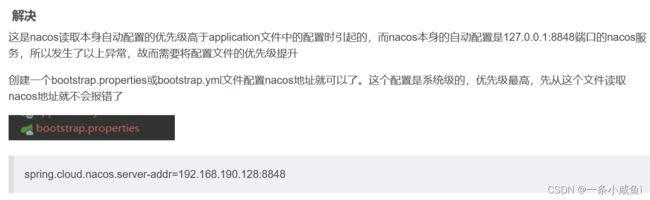
41、nacos配置不生效 一直连接localhost:8848 问题
在我的项目中引入nacos,启动后出现链接地址为localhost:8848错误,我配置的是192.168.11.230:8848

42、JVM内存模型
详情
43、elasticsearch 全文检索工具
概念
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式
倒排索引
倒排索引源于实际应用中需要根据属性的值来查找记录。这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。由于不是由记录来确定属性值,而是由属性值来确定记录的位置,因而称为倒排索引

44、打印Feign日志
微服务间通过Feign进行调用,我们希望能看到Feign发送请求的日志信息,怎么做呢?
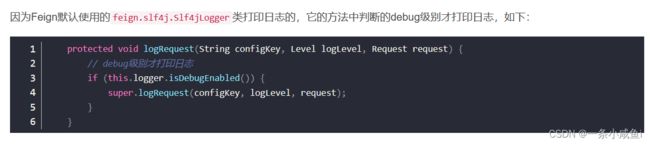
首先,需要将@FeignClient所在包的日志Level设置为Debug级别。

@Configuration
public class FooConfiguration {
@Bean
Logger.Level feignLoggerLevel() {
return Logger.Level.FULL;
}
}

45、openFeign 服务调用实体类无法接收问题
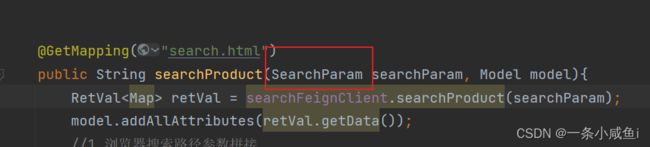
http://search.gmall.com/search.html?keyword=小米
页面通过url 拼接参数的方式请求接口,后端可以用一个实体类直接来接收拼接的参数,不需要@requestParam或者@requestBody
 该实体类包含的参数均可在url后面拼接传递
该实体类包含的参数均可在url后面拼接传递
 问题:接口接收到参数后通过openFeign调用其他服务的post方法 ,传递该实体类SearchParam,实体类中的参数丢失,为null.
问题:接口接收到参数后通过openFeign调用其他服务的post方法 ,传递该实体类SearchParam,实体类中的参数丢失,为null.
解决方法:openFeign调用的方法 添加 @requestBody注解。猜测原因是由于此处接收到的request中的content-type为json格式,只能通过@postmaping接受


46、@PostConstruct详解
定义
@PostConstruct是Java自带的注解,在方法上加该注解会在项目启动的时候执行该方法,也可以理解为在spring容器初始化的时候执行该方法。
从Java EE5规范开始,Servlet中增加了两个影响Servlet生命周期的注解,@PostConstruct和@PreDestroy,这两个注解被用来修饰一个非静态的void()方法。
作用:
@PostConstruct注解的方法在项目启动的时候执行这个方法,也可以理解为在spring容器启动的时候执行,可作为一些数据的常规化加载,比如数据字典之类的。
执行顺序:
其实从依赖注入的字面意思就可以知道,要将对象p注入到对象a,那么首先就必须得生成对象a和对象p,才能执行注入。所以,如果一个类A中有个成员变量p被@Autowried注解,那么@Autowired注入是发生在A的构造方法执行完之后的。
如果想在生成对象时完成某些初始化操作,而偏偏这些初始化操作又依赖于依赖注入,那么久无法在构造函数中实现。为此,可以使用@PostConstruct注解一个方法来完成初始化,@PostConstruct注解的方法将会在依赖注入完成后被自动调用。
Constructor >> @Autowired >> @PostConstruct

47、@RequestParam @RequestBody 不加注解接收 的区别
1.@RequestParam
主要用来接收GET请求拼接在URL后的参数,或者是POST传递,且Content-type为x-www-form-urlencoded方式。
因为不管是GET方式还是用x-www-form-urlencoded方式传递,参数都是以键值对方式拼接的,然后经过URLencoded编码,传递给服务端。
@RequestParam只能接收简单参数类型,复杂的参数类型要用@RequestBody来接收,或者不加注解来接收。
2.@RequestBody
使用@RequestBody该注解,前端请求只能为POST,因为该注解是从请求体中获得对象的。且请求头中的Content-type一般为application/json方式。所以使用该注解能够接收JSON格式的数据,并且能把接收到的JSON数据绑定到JAVA对象中。复杂对象包括List,实体类,Map对象等。
在用该注解的时候有两个注意事项:
1. 一个方法中只能有一个@RequestBody注解,但是@RequestBody注解可以和@RequestParam注解一起使用,而且@RequestParam注解一个方法中可以有多个。
2. @RequestBody注解的参数类型可以是复杂对象类。
3.不加注解接收
不加注解接收参数,参数类型可以为简单类型,也可以为复杂类型(JAVA对象等,前端传递的参数会和类中的属性名对应并且绑定)。也就是两种类型都可接收。而且GET请求和POST请求也都能接收到参数。但是POST请求时,和@RequestParam注解一样,Content-type只能为x-www-form-urlencoded。不加注解可以接收复杂对象,但是不能接收Map类型的对象。
47、Content-Type之x-www-form-urlencoded和json
Content-Type,内容类型,一般是指网页中存在的Content-Type,用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件,


48、redis zset的使用场景 用于排行榜
根据某个key查询并每次查询score都会加1

查询时zset会根据score自动排序。
49、AntPathMatcher
背景:在做uri匹配规则发现这个类,根据源码对该类进行分析,它主要用来做类URLs字符串匹配;
 使用:
使用:


50、网关请求拦截
import com.alibaba.fastjson.JSONObject;
import com.atguigu.result.RetVal;
import com.atguigu.result.RetValCodeEnum;
import com.atguigu.util.IpUtil;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.io.buffer.DataBuffer;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.http.HttpCookie;
import org.springframework.http.HttpHeaders;
import org.springframework.http.HttpStatus;
import org.springframework.http.server.reactive.ServerHttpRequest;
import org.springframework.http.server.reactive.ServerHttpResponse;
import org.springframework.stereotype.Component;
import org.springframework.util.AntPathMatcher;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.nio.charset.StandardCharsets;
import java.util.List;
/**
* @Description:
* @Author: sgc
* @Date: 2023/6/18 20:10
*/
@Component
public class AccessFilter implements GlobalFilter {
@Value("${filter.whiteFilter}")
private String whiteFilterList;
@Autowired
private RedisTemplate redisTemplate;
//匹配路由的规则
private AntPathMatcher antPathMatcher = new AntPathMatcher();
/**
* @param exchange 服务网络交换机 存储着我们的请求和响应信息 它是一个不可变的实例
* @param chain 网关过滤链表 用于链式调用 设计模式:责任链模式
* @return 谈谈你对设计模式的理解-->单例模式 工厂模式 代理模式 模板模式 享元模式 大话设计模式
*/
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
//获取请求路径
ServerHttpRequest request = exchange.getRequest();
ServerHttpResponse response = exchange.getResponse();
/**
* 3.获取用户信息(包含两个)
* 获取用户临时id(用户在未登录的时候也可以加入购物车)
* 获取用户的id信息 如果有用户id说明已经登录过了
*/
String userId = getUserId(request);
String userTempId = getUserTempId(request);
//addCart.html
String path = request.getURI().getPath();
//2.对于内部接口 不允许访问 /sku/**
if (antPathMatcher.match("/sku/**", path)) {
return writeDataToBrowser(response, RetValCodeEnum.NO_PERMISSION);
}
//1.对于指定的某些路径我们必须先登录
for (String whiteFilter : whiteFilterList.split(",")) {
//请求路径在白名单内 此时需要用户去登录
if (path.indexOf(whiteFilter) != -1 && StringUtils.isEmpty(userId)) {
//让它跳转到登录页面
response.setStatusCode(HttpStatus.SEE_OTHER);
response.getHeaders().set(HttpHeaders.LOCATION, "http://passport.gmall.com/login.html?originalUrl=" + request.getURI());
//指示消息处理已完成
return response.setComplete();
}
}
//把用户信息保存到header当中传给shop-web
if (!StringUtils.isEmpty(userId) || !StringUtils.isEmpty(userTempId)) {
if (!StringUtils.isEmpty(userId)) {
request.mutate().header("userId", userId);
}
if (!StringUtils.isEmpty(userTempId)) {
request.mutate().header("userTempId", userTempId);
}
//过滤器放开拦截 继续往下执行(传递了参数)
return chain.filter(exchange.mutate().request(request).build());
}
//如果不想拦截 就放开
return chain.filter(exchange);
}
private Mono<Void> writeDataToBrowser(ServerHttpResponse response, RetValCodeEnum retValCodeEnum) {
//写信息给浏览器 没有访问权限
response.getHeaders().add("Content-Type", "application/json;charset=UTF-8");
//写什么数据
RetVal<Object> retVal = RetVal.build(null, retValCodeEnum);
byte[] bytes = JSONObject.toJSONString(retVal).getBytes(StandardCharsets.UTF_8);
//搞一个dataBuffer
DataBuffer dataBuffer = response.bufferFactory().wrap(bytes);
return response.writeWith(Mono.just(dataBuffer));
}
private String getUserTempId(ServerHttpRequest request) {
//此时的请求 没有被前端拦截器拦截到
String userTempId = "";
List<String> headerValueList = request.getHeaders().get("userTempId");
if (!CollectionUtils.isEmpty(headerValueList)) {
userTempId = headerValueList.get(0);
} else {
HttpCookie cookie = request.getCookies().getFirst("userTempId");
if (cookie != null) {
userTempId = cookie.getValue();
}
}
return userTempId;
}
private String getUserId(ServerHttpRequest request) {
//此时的请求 没有被前端拦截器拦截到
String token = "";
List<String> headerValueList = request.getHeaders().get("token");
if (!CollectionUtils.isEmpty(headerValueList)) {
token = headerValueList.get(0);
} else {
HttpCookie cookie = request.getCookies().getFirst("token");
if (cookie != null) {
token = cookie.getValue();
}
}
//通过token从redis中拿到userId
if (!StringUtils.isEmpty(token)) {
String userKey = "user:login:" + token;
//你们遇到这样的问题就废了 因为redis配置类 没有被依赖进来
JSONObject loginUserInfoJson = (JSONObject) redisTemplate.opsForValue().get(userKey);
if (loginUserInfoJson != null) {
//拿到之前的ip地址
String redisLoginIp = loginUserInfoJson.getString("loginIp");
//拿到当前服务器的ip地址
String ipAddress = IpUtil.getGatwayIpAddress(request);
if (ipAddress.equals(redisLoginIp)) {
return loginUserInfoJson.getString("userId");
} else {
return null;
}
}
}
return null;
}
}
51、redis 中操作hash
//放入一个hash
redisTemplate.boundHashOps(userCartKey).put(cartInfo.getSkuId().toString(),cartInfo);
//全部放入
Map<String, CartInfo> cartMap = new HashMap<>();
for (CartInfo cartInfo : cartInfoList) {
//redisTemplate.boundHashOps(userCartKey).put(cartInfo.getSkuId().toString(),cartInfo);
cartMap.put(cartInfo.getSkuId().toString(),cartInfo);
}
redisTemplate.boundHashOps(userCartKey).putAll(cartMap);
52、@RequestMapping 路径会自动添加/ @getMapping @PostMapping@deleteMapping @putMapping路径必须加/
53、防止重复提交订单
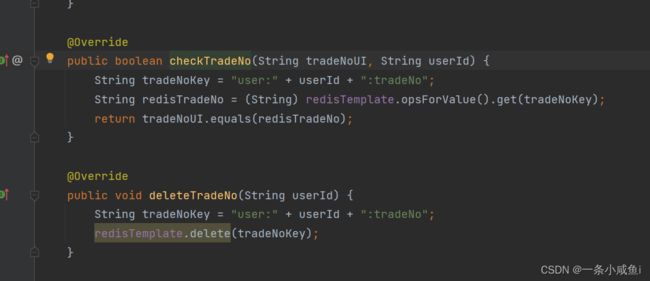
逻辑:在查询订单信息时生成一个流水号,保存至redis,并返回给前端。提交订单时前段需要将该流水号传递给后端。后端根据key去Redis中取流水号进行对比,如果一致则正常调用保存订单接口,并将该流水号从Redis中删除,如果不一致则说明流水号已被提交过 是重复提交。



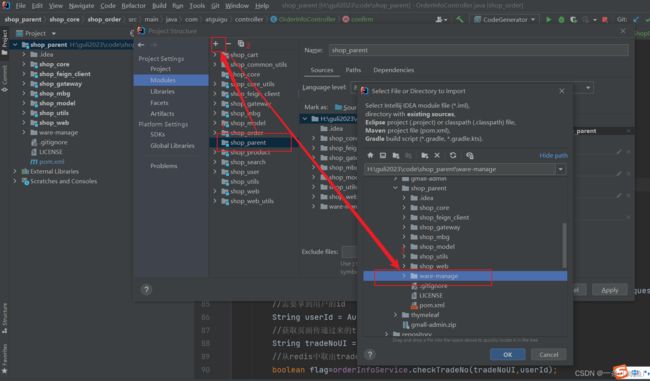
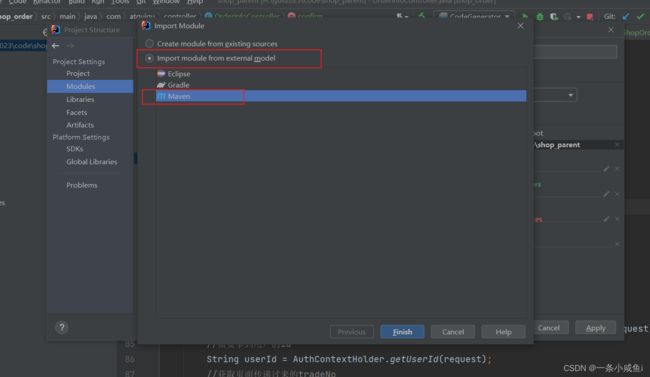
54、在原有项目导入一个新模块(model)
55、为什么使用rabbitmq
ActiveMQ:最早的mq,单机吞吐量万级,消息可靠性较低的概率丢失数据
缺点:官方社区现在对ActiveMQ 5.x维护越来越少,高吞吐量场景较少使用。
Kafka:吞吐量高 数据领域的实时计算以及日志采集被大规模使用
缺点:社区更新较慢
RocketMQ:阿里巴巴的开源产品,用Java语言实现 单机吞吐量十万级 消息可以做到0丢失
缺点:支持的客户端语言不多,目前是java及c++,其中c++不成熟
RabbitMQ:由于erlang语言的高并发特性,性能较好;吞吐量到万级 支持多种语言 如:Python、Ruby、.NET、Java、JMS、C、PHP、ActionScript、XMPP、STOMP等 社区活跃度高

56、 延迟队列与延迟消息
可以设置及消息ttl(存活时间) 也可以设置队列ttl

延迟队列配置
import org.springframework.amqp.core.*;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
/**
* @Description:
* @Author: sgc
* @Date: 2023/7/4 23:15
*/
@Configuration
public class TtlQueueConfig {
private static final String X_EXCHANGE = "X";
private static final String QUEUE_A = "QA";
private static final String QUEUE_B = "QB";
private static final String Y_DEAD_LETTER_EXCHANGE = "Y";
private static final String DEAD_LETTER_QUEUE = "QD";
//声明xExchange
@Bean("xExchange")
public DirectExchange xExchange() {
return new DirectExchange(X_EXCHANGE, false, false);
}
//声明xExchange
@Bean("yExchange")
public DirectExchange yExchange() {
return new DirectExchange(Y_DEAD_LETTER_EXCHANGE, false, false);
}
//声明队列A ttl为10s并绑定到对应的死信交换机
@Bean("queueA")
public Queue aQueue() {
HashMap<String, Object> args = new HashMap<>(3);
//声明当前队列绑定的死信交换机
args.put("x-dead-letter-exchange", Y_DEAD_LETTER_EXCHANGE);
//声明当前队列的死信路由key
args.put("x-dead-letter-routing-key", "YD");
//声明队列的TTL
args.put("x-message-ttl", 10000);
return QueueBuilder.nonDurable(QUEUE_A).withArguments(args).build();
}
// 声明队列A绑定X交换机
@Bean
public Binding queueaBindingX(@Qualifier("queueA") Queue queueA,
@Qualifier("xExchange") DirectExchange xExchange) {
return BindingBuilder.bind(queueA).to(xExchange).with("XA");
}
//声明队列B ttl为40s并绑定到对应的死信交换机
@Bean("queueB")
public Queue queueB() {
Map<String, Object> args = new HashMap<>(3);
//声明当前队列绑定的死信交换机
args.put("x-dead-letter-exchange", Y_DEAD_LETTER_EXCHANGE);
//声明当前队列的死信路由key
args.put("x-dead-letter-routing-key", "YD");
//声明队列的TTL
args.put("x-message-ttl", 40000);
return QueueBuilder.nonDurable(QUEUE_B).withArguments(args).build();
}
//声明队列B绑定X交换机
@Bean
public Binding queuebBindingX(@Qualifier("queueB") Queue queue1B,
@Qualifier("xExchange") DirectExchange xExchange) {
return BindingBuilder.bind(queue1B).to(xExchange).with("XB");
}
//声明死信队列QD
@Bean("queueD")
public Queue queue() {
return new Queue(DEAD_LETTER_QUEUE, false);
}
//声明死信队列QD绑定关系
@Bean
public Binding deadLetterBindingQAD(@Qualifier("queueD") Queue queueD,
@Qualifier("yExchange") DirectExchange yExchange) {
return BindingBuilder.bind(queueD).to(yExchange).with("YD");
}
}
生产者
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Date;
/**
* @Description:
* @Author: sgc
* @Date: 2023/7/5 0:03
*/
@Slf4j
@RequestMapping("ttl")
@RestController
public class SendMsgController {
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("sendMsg/{message}")
public void sendMsg(@PathVariable String message){
log.info("当前时间:{},发送一条信息给两个TTL队列:{}", new Date(), message);
rabbitTemplate.convertAndSend("X","XA","消息来自ttl为10S的队列: "+message);
rabbitTemplate.convertAndSend("X","XB","消息来自ttl为40S的队列: "+message);
}
@GetMapping("sendExpirationMsg/{message}/{ttlTime}")
public void sendMsg(@PathVariable String message,@PathVariable String ttlTime) {
rabbitTemplate.convertAndSend("X", "XC", message,correlationData -> {
correlationData.getMessageProperties().setExpiration(ttlTime);
return correlationData;
});
log.info("当前时间:{},发送一条时长{}毫秒TTL信息给队列C:{}", new Date(),ttlTime, message);
}
}
消费者
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
import java.util.Date;
/**
* @Description:
* @Author: sgc
* @Date: 2023/7/5 0:06
*/
@Slf4j
@Component
public class DeadLetterQueueConsumer {
@RabbitListener(queues = "QD")
public void receiveD(Message message){
log.info("当前时间:{},收到死信队列信息{}", new Date().toString(), message);
}
}

如果每次都通过延迟队列来实现延迟接受消息的功能,那么每次延迟时间不同,就要创建一个新的队列。此时可以采用设置消息ttl,然后新增一个普通队列c 用于专门接收延迟消息,这样消息过期后就会进入死信队列。
延迟消息
@GetMapping("sendExpirationMsg/{message}/{ttlTime}")
public void sendMsg(@PathVariable String message,@PathVariable String ttlTime) {
rabbitTemplate.convertAndSend("X", "XC", message,correlationData -> {
correlationData.getMessageProperties().setExpiration(ttlTime);
return correlationData;
});
log.info("当前时间:{},发送一条时长{}毫秒TTL信息给队列C:{}", new Date(),ttlTime, message);
}
延迟消息存在的问题
由于队列是先进先出,所有第一个的消息等待过期堵塞时,哪怕后面的消息已经过期。也需要等待第一个消息出去(进入死信队列)后才能出去。

57、延迟插件 保证消息精准过期
原理:接收到消息后会先在交换机中等待ttl到期,到期后才会进入对应的队列。

 linux下安装延迟插件的方法(1、直接安装 2、镜像安装)
linux下安装延迟插件的方法(1、直接安装 2、镜像安装)
 依赖于延迟插件的延迟配置
依赖于延迟插件的延迟配置
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.CustomExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.HashMap;
import java.util.Map;
/**
* @Description:
* @Author: sgc
* @Date: 2023/7/7 22:47
*/
@Configuration
public class DelayedQueueConfig {
public static final String DELAYED_QUEUE_NAME = "delayed.queue";
public static final String DELAYED_EXCHANGE_NAME = "delayed.exchange";
public static final String DELAYED_ROUTING_KEY = "delayed.routingkey";
@Bean
public Queue delayedQueue() {
return new Queue(DELAYED_QUEUE_NAME, false);
}
@Bean
public CustomExchange delayedExchange() {
Map<String, Object> arguments=new HashMap<>();
//固定写法 x-delayed-type direct
arguments.put("x-delayed-type","direct");
//固定写法 x-delayed-message
return new CustomExchange(DELAYED_EXCHANGE_NAME, "x-delayed-message", false, false, arguments);
}
@Bean
public Binding bindingDelayedQueue(@Qualifier("delayedQueue") Queue delayedQueue,
@Qualifier("delayedExchange") CustomExchange delayedExchange) {
return BindingBuilder.bind(delayedQueue).to(delayedExchange).with(DELAYED_ROUTING_KEY).noargs();
}
}
生产者
@GetMapping("sendDelayMsg/{message}/{delayTime}")
public void sendMsg(@PathVariable String message,@PathVariable Integer delayTime) {
rabbitTemplate.convertAndSend(DELAYED_EXCHANGE_NAME, DELAYED_ROUTING_KEY, message,correlationData -> {
correlationData.getMessageProperties().setDelay(delayTime);
return correlationData;
});
log.info("当前时间:{},发送一条延迟{}毫秒的信息给队列delayed.queue:{}", new Date(),delayTime, message);
}
消费者
public static final String DELAYED_QUEUE_NAME = "delayed.queue";
@RabbitListener(queues = DELAYED_QUEUE_NAME)
public void receiveDelayedQueue(Message message){
log.info("当前时间:{},收到延时队列的消息:{}", new Date(), message.getBody().toString());
}
gitee代码
58、消息确认、消息回退


在配置文件当中需要添加
spring.rabbitmq.publisher-confirm-type=correlated

回调配置
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.stereotype.Component;
/**
* @Description:
* #需要再配置文件中开启生产者发送消息到交换机的消息确认
* spring.rabbitmq.publisher-confirm-type=correlated
* @Author: sgc
* @Date: 2023/7/8 11:14
*/
@Component
@Slf4j
public class MyCallBack implements RabbitTemplate.ConfirmCallback,RabbitTemplate.ReturnCallback {
/**
* 交换机接受到生产者的消息后做点啥
*
* @param correlationData 消息id
* @param ack 代表交换机是否已收到消息
* @param cause 交换机没有收到消息的原因
*/
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
String id = correlationData != null? correlationData.getId() : "";
if(ack){
log.info("交换机已经收到id为:{}的消息", id);
}else {
log.info("交换机没有收到id为:{}消息,原因;{}",id,cause);
}
}
/**
* 消息没有被路由时 做点啥
* @param message
* @param replyCode
* @param replyText
* @param exchange
* @param routingKey
*/
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
log.info("消息:{}被服务器退回,退回原因:{}, 交换机是:{}, 路由key:{}", new String(message.getBody()),replyText, exchange, routingKey);
}
}
生产者
通过@PostConstruct注解(会在@Autowire之后执行)执行rabbitTemplate回调对象 设置回调接口、回退接口
import com.sgc.callback.MyCallBack;
import lombok.extern.slf4j.Slf4j;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import javax.annotation.PostConstruct;
/**
* @Description:
* @Author: sgc
* @Date: 2023/7/8 10:59
*/
@RestController
@RequestMapping("/confirm")
@Slf4j
public class Producer {
public static final String CONFIRM_EXCHANGE_NAME = "confirm.exchange";
@Autowired
private RabbitTemplate rabbitTemplate;
@Autowired
private MyCallBack myCallBack;
//依赖注入rabbitTemplate之后再设置回调对象 @PostConstruct在@Autowired之后执行
//此处最好领出来 单独写一个配置类 如59所示
@PostConstruct
public void init(){
//设置确认回调
rabbitTemplate.setConfirmCallback(myCallBack);
/**
* true
* 交换机无法将该消息进行路由时 会将该消息返回给生产者
* false(默认)
* 交换机无法将该消息进行路由时 会将该消息直接丢弃
*/
rabbitTemplate.setMandatory(true);
//设置回退回调 消息找不到队列接收时 将消息回退给生产者(默认消息会丢弃)
rabbitTemplate.setReturnCallback(myCallBack);
}
@GetMapping("sendMessage/{message}")
public void sendMessage(@PathVariable String message){
//指定消息id为1
CorrelationData correlationData1 = new CorrelationData("1");
String routingKey = "key1";
rabbitTemplate.convertAndSend(CONFIRM_EXCHANGE_NAME,routingKey,message+routingKey,correlationData1);
CorrelationData correlationData2=new CorrelationData("2");
//不创建接受该路由的队列
routingKey="key2";
rabbitTemplate.convertAndSend(CONFIRM_EXCHANGE_NAME,routingKey,message+routingKey,correlationData2);
log.info("发送消息内容:{}",message);
}
}
59、消息确认、消息回退 简单配置类代码(上面代码的简化写法)
由于@Autowire注解注入的bean默认都是单例的 所以只要在某一处配置了rabbitTemplate的消息确认、消息回退 全局都会生效
创建配置类
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.connection.CorrelationData;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Configuration;
import javax.annotation.PostConstruct;
/**
* @Author: sgc
* @Date: 2021/7/14 16:26
*/
@Configuration
public class RabbitmqConfirmCallBack {
@Autowired
private RabbitTemplate rabbitTemplate;
public static final Logger log = LoggerFactory.getLogger(RabbitmqConfirmCallBack.class);
@PostConstruct
public void initRabbitMq(){
//消息发送成功
rabbitTemplate.setConfirmCallback(new RabbitTemplate.ConfirmCallback() {
@Override
public void confirm(CorrelationData correlationData, boolean ack, String cause) {
log.info("消息唯一标识: {}", correlationData);
log.info("确认状态: {}", ack);
log.info("造成原因: {}", cause);
}
});
//消息发送失败
rabbitTemplate.setReturnCallback(new RabbitTemplate.ReturnCallback() {
@Override
public void returnedMessage(Message message, int replyCode, String replyText, String exchange, String routingKey) {
log.info(new String(message.getBody()) + "到达队列失败:" + replyCode + " " + replyText + " 交换机为:" + exchange + " 路由key:" + routingKey);
}
});
}
}
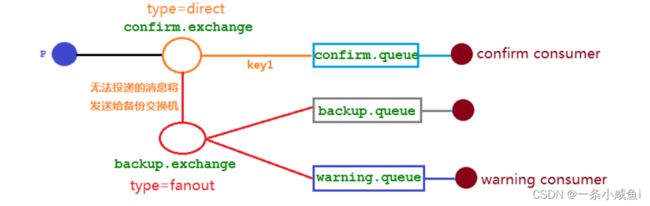
60、备份交换机
当路由为"key2"的消息被投递到confrim.exchange交换机后,由于找不到对应的路由,无法投递消息就会被发送给备份交换机,可以设置两个队列,接受被分解交换机的消息,一个用于保存未被投递的消息,另一个用于告警提醒未完成消息投递。
配置类
import org.springframework.amqp.core.*;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @Description:
* @Author: sgc
* @Date: 2023/7/8 10:23
*/
@Configuration
public class ConfirmConfig {
public static final String CONFIRM_EXCHANGE_NAME = "confirm.exchange";
public static final String CONFIRM_QUEUE_NAME = "confirm.queue";
public static final String BACKUP_EXCHANGE_NAME = "backup.exchange";
public static final String BACKUP_QUEUE_NAME = "backup.queue";
public static final String WARNING_QUEUE_NAME = "warning.queue";
// 声明确认队列
@Bean("confirmQueue")
public Queue confirmQueue(){
return QueueBuilder.nonDurable(CONFIRM_QUEUE_NAME).build();
}
//声明备份Exchange
@Bean("backupExchange")
public FanoutExchange backupExchange(){
return new FanoutExchange(BACKUP_EXCHANGE_NAME,false,false);
}
//声明确认Exchange交换机的备份交换机
@Bean("confirmExchange")
public DirectExchange confirmExchange(){
return ExchangeBuilder.directExchange(CONFIRM_EXCHANGE_NAME).durable(false)
//设置该交换机的备份交换机
.withArgument("alternate-exchange", BACKUP_EXCHANGE_NAME).build();
}
//声明确认队列绑定关系
@Bean
public Binding queueBinding(@Qualifier("confirmQueue") Queue confirmQueue,
@Qualifier("confirmExchange") DirectExchange confirmExchange){
return BindingBuilder.bind(confirmQueue).to(confirmExchange).with("key1");
}
// 声明警告队列
@Bean("warningQueue")
public Queue warningQueue(){
return QueueBuilder.nonDurable(WARNING_QUEUE_NAME).build();
}
// 声明报警队列绑定关系
@Bean
public Binding warningBinding(@Qualifier("warningQueue") Queue warningQueue,
@Qualifier("backupExchange") FanoutExchange backupExchange){
return BindingBuilder.bind(warningQueue).to(backupExchange);
}
// 声明备份队列
@Bean("backQueue")
public Queue backQueue(){
return QueueBuilder.nonDurable(BACKUP_QUEUE_NAME).build();
}
// 声明备份队列绑定关系
@Bean
public Binding backupBinding(@Qualifier("backQueue") Queue queue,
@Qualifier("backupExchange") FanoutExchange backupExchange){
return BindingBuilder.bind(queue).to(backupExchange);
}
}


mandatory参数与备份交换机可以一起使用的时候,如果两者同时开启,消息会走到备份交换机中,备份交换机优先级高
61、消费者消息手动确认
设置mq消费者手动签收
针对于一些绑定关系比较简单的 可以通过注解绑定mq队列交换机
import com.atguigu.constant.MqConst;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
/**
* @Description:
* @Author: sgc
* @Date: 2023/7/9 11:32
*/
@Component
public class EsConsumer {
/**
* 接受上架的消息 默认是自动签收 此处绑定关系比较简单 可以不用创建配置配进行绑定 直接通过注解绑定
* 此处为了测试方便 将持久化durable字段设置为false
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = MqConst.ON_SALE_QUEUE,durable = "false"),
exchange = @Exchange(value = MqConst.ON_OFF_SALE_EXCHANGE,durable = "false"),
key = {MqConst.ON_SALE_ROUTING_KEY}))
public void onOffMessage(Long skuId){
System.out.println("接收到skuid:"+skuId);
}
}
消息手动确认
import com.atguigu.constant.MqConst;
import com.atguigu.service.SearchService;
import com.rabbitmq.client.Channel;
import org.springframework.amqp.core.Message;
import org.springframework.amqp.rabbit.annotation.Exchange;
import org.springframework.amqp.rabbit.annotation.Queue;
import org.springframework.amqp.rabbit.annotation.QueueBinding;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import java.io.IOException;
/**
* @Description:
* @Author: sgc
* @Date: 2023/7/9 11:32
*/
@Component
public class EsConsumer {
@Autowired
private SearchService searchService;
/**
* 接受上架的消息 默认是自动签收 此处绑定关系比较简单 可以不用创建配置配进行绑定 直接通过注解绑定
* 此处为了测试方便 将持久化durable字段设置为false
*/
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = MqConst.ON_SALE_QUEUE,durable = "false"),
exchange = @Exchange(value = MqConst.ON_OFF_SALE_EXCHANGE,durable = "false"),
key = {MqConst.ON_SALE_ROUTING_KEY}))
public void onOffMessage(Long skuId, Channel channel, Message message) throws IOException {
//可以通过Long skuId 直接拿到消息 也可以在message中获取
if(skuId != null){
searchService.onSale(skuId);
}
/**
* 参数一 long deliveryTag 消息id
* 参数二 boolean multiple 是否确认所有消息 false-只确认当前消息
*/
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
}
//接受下架的消息 默认是自动签收
@RabbitListener(bindings = @QueueBinding(
value = @Queue(value = MqConst.OFF_SALE_QUEUE, durable = "false"),
exchange = @Exchange(value = MqConst.ON_OFF_SALE_EXCHANGE, durable = "false"),
key = {MqConst.OFF_SALE_ROUTING_KEY}))
public void offSale(Long skuId, Channel channel, Message message) throws Exception {
if(skuId!=null){
searchService.offSale(skuId);
}
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false);
}
}
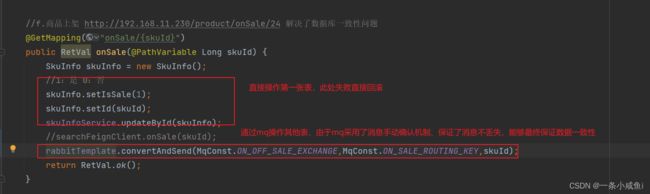
62、事务的解决方式:通过mq保证最终一致性
采用seata的方式必须等待执行完成,效率低。此处可以采用mq保证事务的最终一致性。
63、ShardingSphere 读写分离
1.官网文档
官网文档
2.主要功能
a.数据分片
把原来一堆数据存放一处 现在存放到多处 分库分表
b.分布式事务(跨库事务)
seata强一致性 mq最终一致性
c.读写分离
d.影子库压测
影子库是对线上环境的一个克隆
3.读写分离
a.需求
product微服务里面对品牌实现读写分离
127.0.0.1:8000/product/brand/getAllBrand
b.添加依赖
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starterartifactId>
<version>${shardingsphere.version}version>
dependency>
<shardingsphere.version>5.1.0shardingsphere.version>
c.在shop-product添加
<dependency>
<groupId>org.apache.shardingspheregroupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starterartifactId>
dependency>
yaml配置
spring:
shardingsphere:
datasource:
#真实数据库物理机节点名称
names: write-node,read-node1,read-node2
write-node:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/shop_product_01?characterEncoding=utf-8&useSSL=false
username: root
password: root
read-node1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/shop_product_02?characterEncoding=utf-8&useSSL=false
username: root
password: root
read-node2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://127.0.0.1:3306/shop_product_03?characterEncoding=utf-8&useSSL=false
username: root
password: root
#读写分离策略
rules:
readwrite-splitting:
data-sources:
master-node:
type: static
props:
write-data-source-name: write-node
read-data-source-names: read-node1,read-node2
loadBalancerName: read-lb
load-balancers:
read-lb:
type: ROUND_ROBIN
64、主从复制
生产环境中如果数据库只有一台服务器,容易产生单点故障问题,为了保障数据安全可靠性,我们需要将数据复制多份部署在多台不同的服务器上,就算一台坏了其他还可以提供服务主从复制可以实现对数据库备份和读写分离主服务器负责读和写,从服务器只负责读


详细配置见day16-05
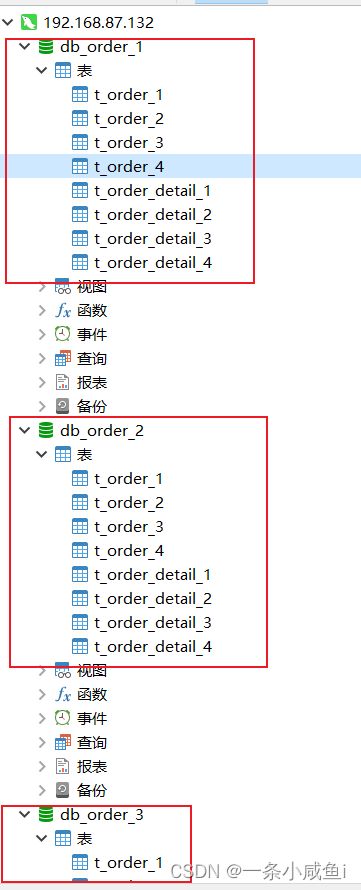
65、分库分表
1.准备三个数据库(主从复制)
创建db_order_1/创建db_order_2/创建db_order_3
2.分库分表
a.分析
分库
分库order_id%3=0,1,2 (跨库查询)
分表order_id%4=0,1,2,3 (跨表查询)
如果按照order_id分库分表 会出现跨库跨表查询
b.策略
采用user_id进行分库分表,同一个用户数据同一个库 同一张表
分库user_id%3=0,1,2
分表user_id%4=0,1,2,3
12%3=0+1=1
12%4=0+1=1
3.在项目中使用(shop_order)
a.添加依赖
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
</dependency>
b.利用逆向工程生成代码
@TableName("t_order")
TOrder
TOrderDetail 都要改
@TableId(value = "id", type = IdType.ID_WORKER)
private Long id;
c.查表过程
select * from db_order_{变量}.t_order_{变量}
d.编写分库分表配置文件
https://shardingsphere.apache.org/document/current/cn/user-manual/shardingsphere-jdbc/spring-boot-starter/rules/sharding/
配置实例:
spring:
shardingsphere:
datasource:
names: ds-1,ds-2,ds-3
ds-1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.87.132:3306/db_order_1?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-2:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.87.132:3306/db_order_2?characterEncoding=utf-8&useSSL=false
username: root
password: root
ds-3:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://192.168.87.132:3306/db_order_3?characterEncoding=utf-8&useSSL=false
username: root
password: root
#分库分表策略
rules:
sharding:
#配置一个分库的算法
default-database-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: sharding-db-by-user-id
#配置具体算法如何操作
sharding-algorithms:
#数据库分库算法具体实现
sharding-db-by-user-id:
type: INLINE
props:
#ds-1,ds-2,ds-3
algorithm-expression: ds-$->{user_id%3+1}
#数据库分表算法具体实现
sharding-table-order-by-user-id:
type: INLINE
props:
#t_order_1,t_order_2,t_order_3,t_order_4
algorithm-expression: t_order_$->{user_id%4+1}
sharding-table-detail-order-by-user-id:
type: INLINE
props:
#t_order_detail_1,t_order_detail_2,t_order_detail_3,t_order_detail_4
algorithm-expression: t_order_detail_$->{user_id%4+1}
#配置真实数据库表具体使用哪个算法
tables:
t_order:
#真实数据库节点
actual-data-nodes: ds-$->{1..3}.t_order_$->{1..4}
#表使用哪个策略
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: sharding-table-order-by-user-id
t_order_detail:
#真实数据库节点
actual-data-nodes: ds-$->{1..3}.t_order_detail_$->{1..4}
#表使用哪个策略
table-strategy:
standard:
sharding-column: user_id
sharding-algorithm-name: sharding-table-detail-order-by-user-id
#打印SQL的语句
props:
sql-show: true
66、RAS2 非对称加密 todo
发送双方A-B 都有一套公钥和私钥,公钥拿对方的,私钥拿自己的。A发送消息给B时,用B的公钥进行加密,加密可以防止信息泄露。然后用自己的私钥签名,签名防止信息被篡改。B收到消息之后,用公钥进行验签,验证信息是否篡改,用私钥解密获取原始信息。
详解
67、如何通过@Value 给静态字段赋值 todo原因
将@value注解放到set方法上

68、内网穿透工具
natapp(每次重启域名都会变化)/ngrok(不太稳定)
69、创建支付二维码
支付宝官方文档
要保存支付信息,防止客户扯皮,要指明支付成功后的回调接口,同步接口跳转页面,异步接口可以用来更新支付信息、订单状态、通知客户等
@Override
public String createQrCode(Long orderId) throws AlipayApiException {
//根据订单id订单信息
OrderInfo orderInfo = orderFeignClient.getOrder(orderId);
//保存支付信息--防止扯皮
savePaymentInfo(orderInfo);
AlipayTradePagePayRequest request = new AlipayTradePagePayRequest();
//支付成功之后的异步通知--调用商户系统的接口
request.setNotifyUrl(AlipayConfig.notify_payment_url);
//支付成功之后的同步通知--返回到商户系统的页面
request.setReturnUrl(AlipayConfig.return_payment_url);
JSONObject bizContent = new JSONObject();
//商户的订单号
bizContent.put("out_trade_no", orderInfo.getOutTradeNo());
//订单总金额
bizContent.put("total_amount", orderInfo.getTotalMoney());
//订单标题
bizContent.put("subject", orderInfo.getTradeBody());
//销售产品码
bizContent.put("product_code", "FAST_INSTANT_TRADE_PAY");
request.setBizContent(bizContent.toString());
AlipayTradePagePayResponse response = alipayClient.pageExecute(request);
if(response.isSuccess()){
String alipayHtml = response.getBody();
return alipayHtml;
} else {
System.out.println("调用失败");
}
return null;
}
70、异步通知验签
避免支付信息被篡改,支付完成后在支付宝异步回调里验签。 验签通过后更新订单信息。
支付宝官方文档

//2.支付成功之后的异步通知
@PostMapping("/async/notify")
public String asyncNotify(@RequestBody Map<String,String> alipayParam) throws Exception{
//JSONObject.toJSONString(alipayParam);
//调用SDK验证签名
boolean signVerified = AlipaySignature.rsaCheckV1(alipayParam, AlipayConfig.alipay_public_key, AlipayConfig.charset, AlipayConfig.sign_type);
if(signVerified){
//支付成功验签成功之后的逻辑
String tradeStatus = alipayParam.get("trade_status");
if("TRADE_SUCCESS".equals(tradeStatus)||"TRADE_FINISHED".equals(tradeStatus)){
//查询支付表看是否修改过
String outTradeNo = alipayParam.get("out_trade_no");
PaymentInfo paymentInfo = paymentInfoService.getPaymentInfo(outTradeNo);
String paymentStatus = paymentInfo.getPaymentStatus();
if(paymentStatus.equals(PaymentStatus.PAID.name())||paymentStatus.equals(PaymentStatus.ClOSED.name())){
return "success";
}
}
//修改支付表信息 发一个消息给MQ 手动确认签收
paymentInfoService.updatePaymentInfo(alipayParam);
}else{
return "failure";
}
return "failure";
}
71、mysql模糊替换某个字段的内容
替换http://192.168.87.128: ===》 http://192.168.87.133:
UPDATE cart_info
SET img_url = REPLACE ( img_url, 'http://192.168.87.128:', 'http://192.168.87.133:' )
WHERE
img_url LIKE '%http://192.168.87.128:%';
72、支付流程

73、Lombok的@SneakyThrows详解


74、JSONObject转换String key:value 格式

75、redis的发布订阅
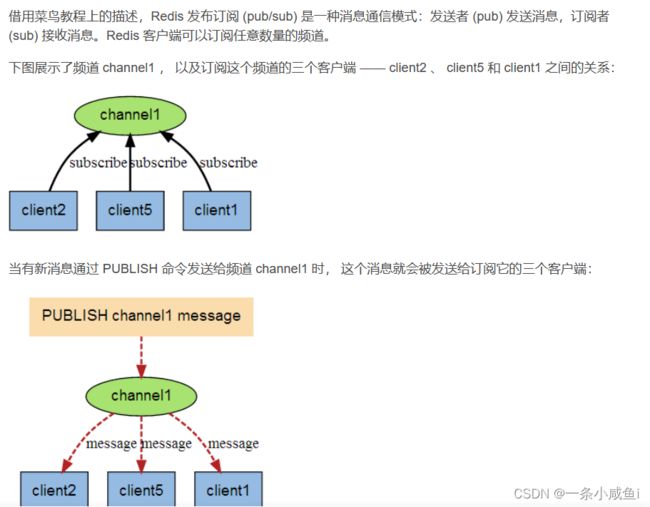 缺点:
缺点:
订阅者收不到最近的消息
订阅信息无法持久化
消息的传递不是可靠的
该功能风险太大,很容易造成消息丢失,所以并不建议做消息队列使用。
76、代码中使用redis发布订阅
1、生产者发布消息
 2、配置类
2、配置类
import com.atguigu.constant.RedisConst;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.listener.PatternTopic;
import org.springframework.data.redis.listener.RedisMessageListenerContainer;
import org.springframework.data.redis.listener.Topic;
import org.springframework.data.redis.listener.adapter.MessageListenerAdapter;
/**
* @Description:
* @Author: sgc
* @Date: 2023/8/14 10:09
*/
@Configuration
public class RedisChannelConfig {
//如何具体的处理接受到的消息
@Bean
public MessageListenerAdapter listenerAdapter(SecKillMsgRecevier secKillMsgRecevier){
return new MessageListenerAdapter(secKillMsgRecevier,"receiveChannelMessage");
}
@Bean
public RedisMessageListenerContainer container(RedisConnectionFactory connectionFactory, MessageListenerAdapter listenerAdapter){
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
//订阅哪个主题
container.addMessageListener(listenerAdapter,new PatternTopic(RedisConst.PREPARE_PUB_SUB_SECKILL));
return container;
}
}
import org.springframework.stereotype.Component;
/**
* @Description:
* @Author: sgc
* @Date: 2023/8/14 10:49
*/
@Component
public class SecKillMsgRecevier {
//把生产者发送过来的消息进行解析
public void receiveChannelMessage(String message){
System.out.println("message=====>" + message);
}
}