构建安全可靠的系统:第六章到第十章
第六章:面向可理解性的设计
原文:6. Design for Understandability
译者:飞龙
协议:CC BY-NC-SA 4.0
由 Julien Boeuf、Christoph Kern和 John Reese
与 Guy Fischman、Paul Blankinship、Aleksandra Culver、Sergey Simakov、Peter Valchev 和 Douglas Colish 一起
为了本书的目的,我们将系统的“可理解性”定义为具有相关技术背景的人能够准确自信地推理以下两点的程度:
-
系统的操作行为
-
系统的不变性,包括安全性和可用性
为什么可理解性很重要?
设计一个可理解的系统,并在一段时间内保持其可理解性,需要努力。一般来说,这种努力是一种投资,以持续的项目速度回报(如第四章中所讨论的)。更具体地说,可理解的系统具有具体的好处:
降低安全漏洞或韧性故障的可能性
无论何时您修改系统或软件组件,例如添加功能,修复错误或更改配置,都存在您可能会意外引入新的安全漏洞或损害系统操作韧性的风险。系统越不易理解,修改它的工程师犯错的可能性就越大。该工程师可能会误解系统的现有行为,或者可能不知道与更改冲突的隐藏、隐含或未记录的要求。
促进有效的事故响应
在事故发生时,响应者能够快速准确地评估损害,控制事故,并确定和纠正根本原因至关重要。一个复杂、难以理解的系统显著阻碍了这一过程。
增加对系统安全状况的断言的信心
关于系统安全性的断言通常以“不变性”来表达:系统的所有可能行为都必须满足的属性。这包括系统对其外部环境的意外交互的响应,例如,当系统接收到格式错误或恶意制作的输入时。换句话说,系统对恶意输入的响应不得违反所需的安全属性。在难以理解的系统中,很难或有时不可能以高度自信来验证这样的断言是否成立。测试通常不足以证明“对于所有可能的行为”属性成立——测试通常只对系统进行了相对较小比例的行为的练习,这些行为对应于典型或预期的操作。¹ 您通常需要依赖对系统的抽象推理来建立这样的属性作为不变性。
系统不变性
系统不变性是一个属性,无论系统的环境如何行为或不当行为,它始终为真。系统完全负责确保所需的属性实际上是不变的,即使系统的环境以任意意外或恶意的方式行为不当。该环境包括您无法直接控制的一切,从用恶意制作的请求击中您的服务前端的恶意用户到导致随机崩溃的硬件故障。分析系统的主要目标之一是确定特定所需属性是否实际上是不变的。
以下是系统所需的一些安全性和可靠性属性的一些示例:
-
只有经过身份验证并得到适当授权的用户才能访问系统的持久数据存储。
-
系统的持久数据存储中对敏感数据的所有操作都根据系统的审计政策记录在审计日志中。
-
系统信任边界之外接收到的所有值在传递给易受注入漏洞的 API(例如 SQL 查询 API 或用于构建 HTML 标记的 API)之前都经过适当的验证或编码。
-
系统后端接收到的查询数量与系统前端接收到的查询数量成比例增长。
-
如果系统后端在预定时间后未能响应查询,系统前端将优雅地降级,例如通过返回一个近似答案。
-
当任何组件的负载大于该组件可以处理的负载时,为了减少级联故障的风险,该组件将提供超载错误而不是崩溃。
-
系统只能从一组指定系统接收 RPC,并且只能向一组指定系统发送 RPC。
如果您的系统允许违反所需安全属性的行为,换句话说,如果所述属性实际上不是不变的,那么系统就存在安全弱点或漏洞。例如,想象一下,列表中的属性 1 对于您的系统来说并不成立,因为请求处理程序缺少访问检查,或者因为这些检查实现不正确。现在您的系统存在安全漏洞,可能允许攻击者访问用户的私人数据。
同样,假设您的系统不满足第四个属性:在某些情况下,系统为每个传入的前端请求生成过多的后端请求。例如,也许前端如果后端请求失败或花费太长时间会快速生成多个重试(并且没有适当的退避机制)。您的系统存在潜在的可用性弱点:一旦系统达到这种状态,其前端可能会完全压倒后端并使服务无响应,形成一种自我造成的拒绝服务场景。
分析不变量
在分析系统是否满足给定的不变量时,存在违反该不变量可能造成的潜在危害与您花费在满足不变量和验证其实际成立的努力之间的权衡。在这个光谱的一端,这种努力可能涉及运行一些测试并阅读源代码的部分,以寻找可能导致违反不变量的错误,例如遗忘的访问检查。这种方法并不能带来特别高的信心。很可能,许多情况下未经测试或深入代码审查的行为将存在错误。值得注意的是,像 SQL 注入、跨站脚本(XSS)和缓冲区溢出等众所周知的常见软件漏洞类别一直在“顶级漏洞”列表中保持领先地位。[2] 缺乏证据并不意味着证据的缺失。
另一方面,您可能会进行基于可证明的合理形式推理的分析:系统和所声称的属性在一个正式逻辑中建模,并且您构建一个逻辑证明(通常在自动证明助手的帮助下),证明该属性对系统成立。[3] 这种方法很困难,需要大量工作。例如,迄今为止最大的软件验证项目之一构建了一个证明,证明了微内核实现在机器代码级别的全面正确性和安全性属性;该项目大约耗费了 20 人年的工作。[4] 尽管形式验证在某些情况下正在变得实用,比如微内核或复杂的加密库代码,[5] 但对于大规模应用软件开发项目来说通常是不可行的。
本章旨在提出一个实用的中间立场。通过设计一个明确的可理解性目标的系统,您可以支持有原则的(但仍然是非正式的)论证,即系统具有某些不变量,并且在合理的努力下对这些断言有相当高的信心。在谷歌,我们发现这种方法对大规模软件开发非常实用,并且在减少常见漏洞发生方面非常有效。有关测试和验证的更多讨论,请参见第十三章。
心理模型
高度复杂的系统对人类来说很难以整体方式进行推理。在实践中,工程师和主题专家经常构建解释系统相关行为的心理模型,同时忽略不相关的细节。对于复杂系统,您可能构建多个相互补充的心理模型。这样,当思考给定系统或子系统的行为或不变量时,您可以抽象出其周围和底层组件的细节,而代之以它们各自的心理模型。
心理模型很有用,因为它们简化了对复杂系统的推理。出于同样的原因,心理模型也是有限的。如果您根据系统在典型操作条件下的经验形成了心理模型,那么该模型可能无法预测系统在不寻常情况下的行为。在很大程度上,安全性和可靠性工程关注的是在这些不寻常条件下分析系统,例如当系统处于主动攻击、过载或组件故障场景时。
考虑一个系统,其吞吐量通常会随着传入请求的速率可预测地逐渐增加。然而,在某个负载阈值之上,系统可能会达到一个状态,其响应方式截然不同。例如,内存压力可能导致在虚拟内存或堆/垃圾收集器级别出现抖动,使系统无法跟上额外负载。太多的额外负载甚至可能导致减少吞吐量。在这种状态下排除系统故障时,除非您明确意识到该模型不再适用,否则您可能会被系统的过度简化心理模型误导。
在设计系统时,考虑软件、安全和可靠性工程师不可避免地会为自己构建的心理模型是很有价值的。在设计要添加到较大系统中的新组件时,理想情况下,其自然形成的心理模型应与人们为类似的现有子系统形成的心理模型一致。
在可能的情况下,您还应设计系统,使其心理模型在系统在极端或不寻常条件下运行时仍然具有预测性和实用性。例如,为了避免抖动,您可以配置生产服务器在没有磁盘虚拟内存交换空间的情况下运行。如果生产服务无法分配所需的内存来响应请求,它可以以可预测的方式快速返回错误。即使有错误或行为不端的服务无法处理内存分配失败并崩溃,您至少可以清楚地将故障归因于潜在问题——在这种情况下是内存压力;这样,观察系统的人的心理模型仍然是有用的。
设计可理解的系统
本章的其余部分讨论了一些具体措施,可以使系统更易理解,并在系统随时间演变时保持其可理解性。我们将首先考虑复杂性问题。
复杂性与可理解性
可理解性的主要敌人是未受控制的复杂性。
由于现代软件系统的规模(尤其是分布式系统)及其解决的问题,某种程度的复杂性通常是内在的和不可避免的。例如,谷歌雇佣了数万名工程师,他们在一个包含超过 10 亿行代码的源代码库中工作。这些代码共同实现了大量的用户服务以及支持它们的后端和数据管道。即使是只提供单一产品的较小组织,也可能在数十万行代码中实现数百个功能和用户故事,由数十甚至数百名工程师编辑。
让我们以 Gmail 为例,这是一个具有重要内在特性复杂性的系统。你可以简要总结 Gmail 为基于云的电子邮件服务,但这一概括掩盖了它的复杂性。在其众多功能中,Gmail 提供以下功能:
-
多个前端和用户界面(桌面 Web、移动 Web、移动应用)
-
允许第三方开发人员开发附加组件的几个 API
-
入站和出站 IMAP 和 POP 接口
-
与云存储服务集成的附件处理
-
以多种格式呈现附件,如文档和电子表格
-
离线可用的 Web 客户端和底层同步基础设施
-
垃圾邮件过滤
-
自动消息分类
-
用于提取关于航班、日历事件等结构化信息的系统
-
拼写纠正
-
智能回复和智能撰写
-
提醒回复消息
具有这些功能的系统本质上比没有这些功能的系统更复杂,但我们不能告诉 Gmail 的产品经理这些功能增加了太多复杂性,并要求他们出于安全性和可靠性的考虑将其删除。毕竟,这些功能提供了价值,并在很大程度上定义了 Gmail 作为产品。但如果我们努力管理这种复杂性,系统仍然可以足够安全和可靠。
如前所述,可理解性与系统和子系统的特定行为和属性相关。我们的目标必须是构建系统设计,以便以一种允许人类高度准确地推理这些特定、相关系统属性和行为的方式来分隔和包含这种内在复杂性。换句话说,我们必须特别管理妨碍可理解性的复杂性方面。
当然,说起来容易做起来难。本节的其余部分将探讨未受管理的复杂性的常见来源以及相应的降低可理解性的设计模式,以及可以帮助控制复杂性并使系统更易理解的设计模式。
虽然我们的主要关注点是安全性和可靠性,但我们讨论的模式在很大程度上并不特定于这两个领域,它们与旨在管理复杂性和促进可理解性的一般软件设计技术非常一致。你可能还想参考有关系统和软件设计的一般文本,如约翰·奥斯特豪特的《软件设计哲学》(Yaknyam Press,2018)。
分解复杂性
要理解复杂系统行为的所有方面,你需要内化并维护一个庞大的心智模型。人类在这方面并不擅长。
通过由较小的组件组合而成,可以使系统更易理解。你应该能够独立地推理每个组件,并以这样的方式组合它们,以便从组件属性推导出整个系统的属性。这种方法使你能够建立整个系统的不变性,而无需一次性考虑整个系统。
这种方法在实践中并不简单。您能够建立子系统的属性,并将子系统的属性组合成系统范围的属性,取决于整个系统如何被结构化为组件以及这些组件之间的接口和信任关系的性质。我们将在“系统架构”中讨论这些关系和相关考虑。
集中负责安全和可靠性要求
如第四章所述,安全和可靠性要求通常横跨系统的所有组件。例如,安全要求可能规定,对于响应用户请求执行的任何操作,系统必须完成一些常见任务(例如审计日志记录和操作指标收集)或检查某些条件(例如身份验证和授权)。
如果每个单独的组件都负责独立实现常见任务和检查,很难确定最终系统是否真正满足要求。您可以通过将常见功能的责任移交给集中组件(通常是库或框架)来改进这种设计。例如,RPC 服务框架可以确保系统根据为整个服务集中定义的策略为每个 RPC 方法实现身份验证、授权和日志记录。有了这种设计,单个服务方法不再负责这些安全功能,应用程序开发人员也不会忘记实现它们或者实现不正确。此外,安全审阅者可以理解服务的身份验证和授权控制,而无需阅读每个单独的服务方法实现。相反,审阅者只需理解框架并检查特定于服务的配置。
再举一个例子:为了防止负载下的级联故障,传入请求应该受到超时和截止日期的限制。任何重试由于过载引起的故障的逻辑都应受到严格的安全机制的约束。为了实现这些策略,您可能依赖应用程序或服务代码来配置子请求的截止日期并适当处理故障。单个应用程序中任何相关代码的错误或遗漏都可能导致整个系统的可靠性弱点。通过在底层 RPC 服务框架中包含支持自动截止日期传播和请求取消的集中处理机制,您可以使系统更加健壮和可理解。⁷
这些例子突出了集中负责安全和可靠性要求的两个好处:
提高系统的可理解性
审阅者只需查看一个地方,就能理解和验证安全/可靠性要求是否正确实现。
增加最终系统实际正确的可能性
这种方法消除了应用代码中对要求的临时实现不正确或缺失的可能性。
虽然在构建和验证应用程序框架或库的集中实现时存在前期成本,但这些成本可以分摊到基于该框架构建的所有应用程序中。
系统架构
将系统结构化为层和组件是管理复杂性的关键工具。使用这种方法,您可以按块来思考系统,而不必一次性理解整个系统的每个细节。
您还需要仔细考虑如何将系统分解为组件和层。过于紧密耦合的组件和层与单片系统一样难以理解。要使系统可理解,您必须像关注组件本身一样关注组件之间的边界和接口。
有经验的软件开发人员通常知道系统必须将来自外部环境的输入(和交互序列)视为不可信,并且系统不能对这些输入做出假设。相比之下,很容易将内部、较低层 API 的调用者(如进程内服务对象的 API 或内部后端微服务暴露的 RPC)视为可信任,并依赖这些调用者遵守 API 使用的文档约束。
假设系统的安全属性取决于内部组件的正确操作。另外,假设其正确操作又取决于组件 API 的调用者确保的前提条件,比如操作的正确顺序,或者方法参数的值的约束。确定系统是否实际具有所需的属性不仅需要理解 API 的实现,还需要理解整个系统中 API 的每个调用点,以及每个调用点是否确保了所需的前提条件。
组件对其调用者做出的假设越少,就越容易独立推理该组件。理想情况下,组件对其调用者不做任何假设。
如果组件被迫对其调用者做出假设,重要的是要在接口设计中明确捕获这些假设,或者在环境的其他约束中明确捕获这些假设,例如限制可以与组件交互的主体集。
可理解的接口规范
结构化接口、一致的对象模型和幂等操作有助于系统的可理解性。如下节所述,这些考虑因素使得更容易预测输出行为以及接口之间的交互方式。
更喜欢提供较少解释空间的窄接口
服务可以使用许多不同的模型和框架来公开接口。举几个例子:
-
带有 OpenAPI 的 RESTful HTTP 和 JSON
-
gRPC
-
Thrift
-
W3C Web Services(XML/WSDL/SOAP)
-
CORBA
-
DCOM
其中一些模型非常灵活,而其他模型提供更多结构。例如,使用 gRPC 或 Thrift 的服务定义了它支持的每个 RPC 方法的名称,以及该方法的输入和输出类型。相比之下,自由格式的 RESTful 服务可能接受任何 HTTP 请求,而应用代码验证请求体是否为具有预期结构的 JSON 对象。
支持用户定义类型的框架(如 gRPC、Thrift 和 OpenAPI)使得更容易创建工具,用于增强 API 表面的可发现性和可理解性,比如交叉引用和一致性检查。这些框架通常也允许 API 表面随着时间的推移更安全地演化。例如,OpenAPI 具有 API 版本控制作为内置功能。用于声明 gRPC 接口的协议缓冲区有关如何更新消息定义以保持向后兼容性的详细文档指南。
相比之下,基于自由格式 JSON 字符串构建的 API 在不检查其实现代码和核心业务逻辑的情况下可能难以理解。这种无约束的方法可能导致安全或可靠性事件。例如,如果客户端和服务器独立更新,它们可能以不同方式解释 RPC 有效负载,这可能导致其中一个崩溃。
缺乏明确的 API 规范也使得评估服务的安全姿态变得困难。例如,除非您可以访问 API 定义,否则很难构建一个自动安全审计系统,将授权框架(如Istio 授权策略中描述的策略与服务实际暴露的表面积相关联。
优先选择强制实现通用对象模型的接口
管理多种类型资源的系统可以从一个通用的对象模型中受益,比如Kubernetes使用的模型。通用对象模型让工程师可以使用单一的思维模型来理解系统的大部分内容,而不是单独处理每种资源类型。例如:
-
系统中的每个对象都可以保证满足一组预定义的基本属性(不变量)。
-
系统可以提供标准的方式来范围、注释、引用和分组所有类型的对象。
-
操作可以在所有类型的对象上具有一致的行为。
-
工程师可以创建自定义对象类型来支持他们的用例,并且可以使用与内置类型相同的思维模型来推理这些对象类型。
Google 提供了关于设计面向资源的 API 的一般指南。
注意幂等操作
幂等操作在多次应用时会产生相同的结果。例如,如果一个人在电梯里按下二楼的按钮,电梯每次都会到达二楼。再次按下按钮,甚至多次按下,都不会改变结果。
在分布式系统中,幂等性很重要,因为操作可能以无序的方式到达,或者服务器在完成操作后的响应可能永远不会到达客户端。如果一个 API 方法是幂等的,客户端可以重试操作,直到收到成功的结果。如果一个方法不是幂等的,系统可能需要使用次要方法,比如轮询服务器来查看新创建的对象是否已经存在。
幂等性也会影响工程师的思维模型。API 的实际行为与预期行为之间的不匹配可能导致不可靠或不正确的结果。例如,假设客户端想要向数据库添加一条记录。虽然请求成功,但由于连接重置,响应未被传递。如果客户端代码的作者认为该操作是幂等的,客户端很可能会重试该请求。但如果操作实际上不是幂等的,系统将创建一个重复的记录。
虽然非幂等操作可能是必要的,但幂等操作通常会导致更简单的思维模型。当操作是幂等的时,工程师(包括开发人员和事件响应者)不需要跟踪操作何时开始;他们可以简单地不断尝试操作,直到知道它成功为止。
一些操作自然是幂等的,通过重新构造其他操作也可以使其成为幂等。在前面的例子中,数据库可以要求客户端在每次变异的 RPC 中包含一个唯一标识符(例如 UUID)。如果服务器收到具有相同唯一标识符的第二次变异,它就知道该操作是重复的,并可以相应地做出响应。
可理解的身份、认证和访问控制
任何系统都应该能够确定谁有权访问哪些资源,特别是如果这些资源非常敏感。例如,支付系统的审计员需要了解哪些内部人员可以访问客户的个人身份信息。通常,系统具有授权和访问控制策略,限制特定实体在特定上下文中对特定资源的访问——在这种情况下,策略将限制员工在处理信用卡时对 PII 数据的访问。当发生这种特定访问时,审计框架可以记录访问。稍后,您可以自动分析访问日志,作为例行检查的一部分,或作为事故调查的一部分。
身份
身份是与实体相关的属性或标识符集合。凭证断言了特定实体的身份。凭证可以采用不同的形式,例如简单密码、X.509 证书或 OAuth2 令牌。凭证通常使用定义好的认证协议发送,访问控制系统用于识别访问资源的实体。识别实体并选择一个用于识别它们的模型可能是复杂的。虽然系统识别人类实体(包括客户和管理员)相对容易,但大型系统需要能够识别所有实体,而不仅仅是人类实体。
大型系统通常由一系列相互调用的微服务组成,无论是否涉及人类。例如,数据库服务可能希望定期快照到较低级别的磁盘服务。这个磁盘服务可能需要调用配额服务,以确保数据库服务有足够的磁盘配额来存储需要快照的数据。或者,考虑一个客户对食品订购前端服务进行身份验证。前端服务调用后端服务,后端服务再调用数据库来检索客户的食品偏好。一般来说,活动实体是系统中相互交互的人类、软件组件和硬件组件的集合。
注意
传统的网络安全实践有时使用 IP 地址作为访问控制和日志记录和审计(例如防火墙规则)的主要标识符。不幸的是,在现代微服务系统中,IP 地址存在许多缺点。因为它们缺乏稳定性和安全性(并且很容易被伪造),IP 地址简单地不能提供一个适当的标识符来识别服务并模拟它们在系统中的特权级别。首先,微服务部署在主机池上,多个服务托管在同一主机上。端口并不提供一个强大的标识符,因为它们可以随着时间的推移被重复使用,或者更糟糕的是,由运行在主机上的不同服务任意选择。一个微服务也可能为在不同主机上运行的不同实例提供服务,这意味着您不能使用 IP 地址作为稳定的标识符。
访问控制和审计机制的质量取决于系统中使用的身份的相关性和它们的信任关系。在系统中为所有活动实体附加有意义的标识符是理解能力的基本步骤,无论是在安全性还是可靠性方面。在安全性方面,标识符帮助您确定谁可以访问什么。在可靠性方面,标识符帮助您规划和执行共享资源的使用,如 CPU、内存和网络带宽。
组织范围的身份系统强化了共同的心智模型,意味着整个员工队伍在提及实体时可以使用相同的语言。对于相同类型的实体存在竞争性的身份系统,例如全球和本地实体的共存系统,会使工程师和审计员的理解变得不必要复杂。
类似于第四章中小部件订购示例中的外部支付处理服务,公司可以将其身份子系统外部化。OpenID Connect(OIDC)提供了一个框架,允许特定提供者断言身份。组织只需配置接受哪些提供者,而不是实现自己的身份子系统。然而,与所有依赖关系一样,这里需要考虑一个权衡——在这种情况下,是这种模型的简单性还是受信任提供者的感知安全性和可靠性的稳健性之间的权衡。
示例:谷歌生产系统的身份模型
谷歌通过使用不同类型的活动实体来建模身份:
管理员
人类(谷歌工程师)可以采取行动改变系统的状态,例如推送新版本或修改配置。
机器
谷歌数据中心的物理机器。这些机器运行实现我们服务的程序(如 Gmail),以及系统本身需要的服务(例如内部时间服务)。
工作负载
这些实体由类似于 Kubernetes 的 Borg 编排系统在机器上调度。大多数情况下,工作负载的身份与其运行的机器的身份不同。
客户
谷歌客户访问由谷歌提供的服务。
管理员是生产系统内所有交互的基础。在工作负载之间的交互中,管理员可能不会主动修改系统的状态,但他们在引导阶段启动工作负载的行为(可能会启动另一个工作负载)。
如第五章中所述,您可以使用审计来追溯所有操作到管理员(或一组管理员),以便建立责任和分析特定员工的特权级别。管理员和他们管理的实体的有意义的身份使审计成为可能。
管理员由全局目录服务集成的单点登录管理。全局组管理系统可以将管理员分组以代表团队的概念。
机器在全局库存服务/机器数据库中进行分类。在谷歌生产网络上,可以使用 DNS 名称寻址机器。我们还需要将机器身份与管理员联系起来,以表示谁可以修改机器上运行的软件。实际上,我们通常将发布机器软件镜像的组与可以以 root 身份登录到机器的组合在一起。
谷歌数据中心的每台生产机器都有一个身份。身份指的是机器的典型用途。例如,专用于测试的实验室机器与运行生产工作负载的机器具有不同的身份。运行机器上的核心应用程序的机器管理守护程序引用此身份。
工作负载使用编排框架在机器上调度。每个工作负载都有一个由请求者选择的身份。编排系统负责确保发出请求的实体有权发出请求,特别是请求者有权以所请求的身份调度运行工作负载。编排系统还对工作负载可以调度到哪些机器施加约束。工作负载本身可以执行组管理等管理任务,但不应具有底层机器的根或管理员权限。
客户身份也有一个专门的身份子系统。在内部,每当服务代表客户执行操作时,这些身份都会被使用。访问控制解释了客户身份如何与工作负载身份协调工作。在外部,Google 提供OpenID Connect 工作流程允许客户使用其 Google 身份对不受 Google 控制的端点(例如zoom.us)进行身份验证。
身份验证和传输安全
身份验证和传输安全是复杂的学科,需要对诸如密码学、协议设计和操作系统等领域有专门的知识。不合理地期望每个工程师都深入了解所有这些主题。
相反,工程师应该能够理解抽象和 API。像 Google 的应用层传输安全(ALTS)这样的系统为应用程序提供了自动的服务对服务身份验证和传输安全。这样,应用程序开发人员就不需要担心凭据是如何配置的,或者用于在连接上保护数据的具体加密算法是什么。
应用程序开发人员的心智模型很简单:
-
应用程序以有意义的身份运行:
-
管理员工作站上的工具通常以管理员的身份运行,用于访问生产环境。
-
机器上的特权进程通常以该机器的身份运行。
-
使用编排框架将应用程序部署为工作负载,通常以特定于环境和服务提供的工作负载身份运行(例如myservice-frontend-prod)。
-
ALTS 提供了零配置的传输安全。
-
常见访问控制框架的 API 检索经过身份验证的对等信息。
ALTS 和类似系统(例如Istio 的安全模型)以可理解的方式提供身份验证和传输安全。
除非基础设施的应用程序间安全姿态采用系统化的方法,否则很难或不可能进行推理。例如,假设应用程序开发人员必须就要使用的凭据类型以及这些凭据将断言的工作负载身份做出个别选择。要验证应用程序是否正确执行身份验证,审计员需要手动阅读所有应用程序的代码。这种方法对安全性来说是不好的——它不具备可扩展性,而且代码的某部分很可能是未经审计或不正确的。
访问控制
使用框架对传入服务请求的访问控制策略进行编码和强制执行对于全局系统的可理解性是一个净利益。框架强化了共同的知识,并提供了一种统一的描述策略的方式,因此是工程师工具包的重要组成部分。
框架可以处理固有复杂的交互,例如在工作负载之间传输数据涉及的多个身份。例如,图 6-1 显示了以下内容:
-
作为三个身份运行的工作负载链:Ingress、Frontend和Backend
-
进行请求的经过身份验证的客户

图 6-1:工作负载之间传输数据涉及的交互
对于链中的每个链接,框架必须能够确定是工作负载还是客户是请求的权威。策略还必须足够表达性,以便它决定允许哪个工作负载身份代表客户检索数据。
具备一种统一的方式来捕获这种固有复杂性,大多数工程师都能理解这些控制。如果每个服务团队都有自己的临时系统来处理相同的复杂用例,理解起来将是一个挑战。
框架规定了在指定和应用声明式访问控制策略方面的一致性。这种声明式和统一的性质使工程师能够开发工具来评估基础设施中服务和用户数据的安全风险。如果访问控制逻辑是以自发方式在应用程序代码级别实现的,开发这种工具基本上是不可能的。
深入探讨:安全边界
系统的可信计算基础(TCB)是“足以确保执行安全策略的一组组件(硬件、软件、人员等)的正确功能,或者更生动地说,其失败可能导致安全策略的违反。”。因此,TCB 必须维护安全策略,即使 TCB 之外的任何实体以任意可能恶意的方式行为不端。当然,TCB 之外的区域包括您系统的外部环境(例如互联网上某处的恶意行为者),但这个区域也包括不在 TCB 内的您自己系统的部分。
TCB 与“其他一切”之间的接口被称为安全边界。“其他一切”——系统的其他部分、外部环境、通过网络与其交互的系统客户端等——通过跨越这个边界进行通信与 TCB 交互。这种通信可能以进程间通信通道、网络数据包和建立在这些基础上的更高级协议的形式进行(如 gRPC)。TCB 必须对跨越安全边界的任何东西持怀疑态度——包括数据本身和其他方面,如消息排序。
构成 TCB 的系统部分取决于您所考虑的安全策略。思考安全策略及其必要的 TCB 在层面上维护的相关性可能是有用的。例如,操作系统的安全模型通常具有“用户身份”的概念,并提供规定在不同用户下运行的进程之间分离的安全策略。在类 Unix 系统中,运行在用户 A 下的进程不应能够查看或修改属于不同用户 B 的进程的内存或网络流量。在软件级别上,确保这一属性的 TCB 基本上由操作系统内核和所有特权进程和系统守护程序组成。反过来,操作系统通常依赖于底层硬件提供的机制,如虚拟内存。这些机制包括在与 OS 级用户之间的分离相关的安全策略的 TCB 中。
网络应用服务器的软件(例如,公开 Web 应用程序或 API 的服务器)不是此操作系统级安全策略的 TCB 的一部分,因为它在非特权的操作系统级角色(例如httpd用户)下运行。但是,该应用程序可能会强制执行自己的安全策略。例如,假设一个多用户应用程序具有安全策略,只能通过显式文档共享控件访问用户数据。在这种情况下,应用程序的代码(或其中的部分)是与该应用程序级安全策略相关的 TCB 内。
为了确保系统执行所需的安全策略,您必须了解并推理与该安全策略相关的整个 TCB。根据定义,TCB 的任何部分的失败或错误可能导致安全策略的违反。
随着 TCB 扩大以包括更多的代码和复杂性,对 TCB 的推理变得更加困难。因此,将 TCB 保持尽可能小,并排除任何实际上不涉及维护安全策略的组件是有价值的。除了损害可理解性外,将这些不相关的组件包括在 TCB 中还增加了风险:这些组件中的任何错误或故障都可能导致安全漏洞。
让我们重新审视一下第四章中的例子:一个允许用户在线购买小部件的网络应用。应用程序的 UI 结账流程允许用户输入信用卡和送货地址信息。系统存储其中一些信息,并将其他部分(如信用卡数据)传递给第三方支付服务。
我们希望确保只有用户自己可以访问他们自己的敏感用户数据,比如送货地址。我们将使用 TCB[AddressData]来表示这个安全属性的受信任计算基础。
使用许多流行的应用程序框架之一,我们可能会得到一个像图 6-2 的架构。
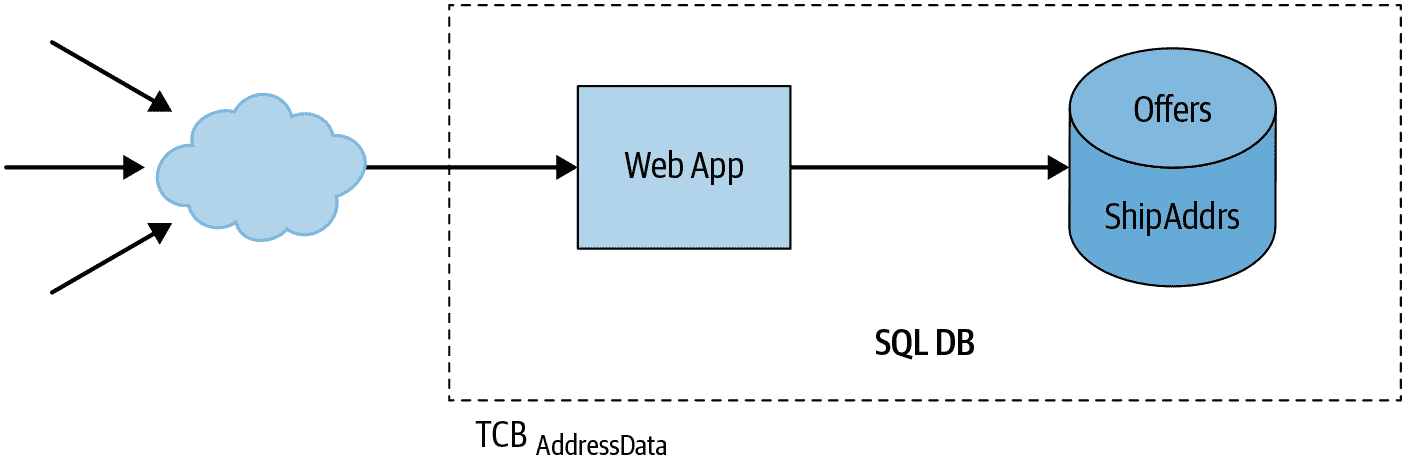
图 6-2:销售小部件的应用程序的示例架构
在这个设计中,我们的系统由一个整体的网络应用和一个相关的数据库组成。应用可能使用多个模块来实现不同的功能,但它们都是同一个代码库的一部分,整个应用作为一个单一的服务器进程运行。同样,应用将所有数据存储在一个单一的数据库中,服务器的所有部分都可以读取和写入整个数据库。
应用的一部分处理购物车结账和购买,数据库的一些部分存储与购买相关的信息。应用的其他部分处理与购买相关的功能,但它们本身并不依赖于购买功能(例如,管理购物车的内容)。应用的其他部分与购买无关(它们处理诸如浏览小部件目录或阅读和编写产品评论等功能)。由于所有这些功能都是单个服务器的一部分,并且所有这些数据都存储在单个数据库中,整个应用及其依赖项——例如数据库服务器和操作系统内核——都是我们想要提供的安全属性的 TCB 的一部分:执行用户数据访问策略。
风险包括目录搜索代码中的 SQL 注入漏洞,允许攻击者获取敏感用户数据,如姓名或送货地址,或者 Web 应用程序服务器中的远程代码执行漏洞,例如CVE-2010-1870,允许攻击者读取或修改应用程序数据库的任何部分。
小的 TCB 和强大的安全边界
我们可以通过将应用拆分成微服务来改进设计的安全性。在这种架构中,每个微服务处理应用功能的一个独立部分,并将数据存储在自己的独立数据库中。这些微服务通过 RPC 进行通信,并将所有传入请求视为不一定可信,即使调用者是另一个内部微服务。
使用微服务,我们可以重构应用,如图 6-3 所示。
现在,我们不再有一个整体的服务器,而是有一个网络应用前端和产品目录和与购买相关功能的独立后端。每个后端都有自己独立的数据库。前端从不直接查询数据库;相反,它发送 RPC 到适当的后端。例如,前端查询目录后端以搜索目录中的项目或检索特定项目的详细信息。同样,前端发送 RPC 到购买后端以处理购物车结账流程。正如本章前面讨论的那样,后端微服务和数据库服务器可以依赖工作负载标识和基础设施级身份验证协议,如 ALTS 来验证调用者并限制对授权工作负载的请求。¹³
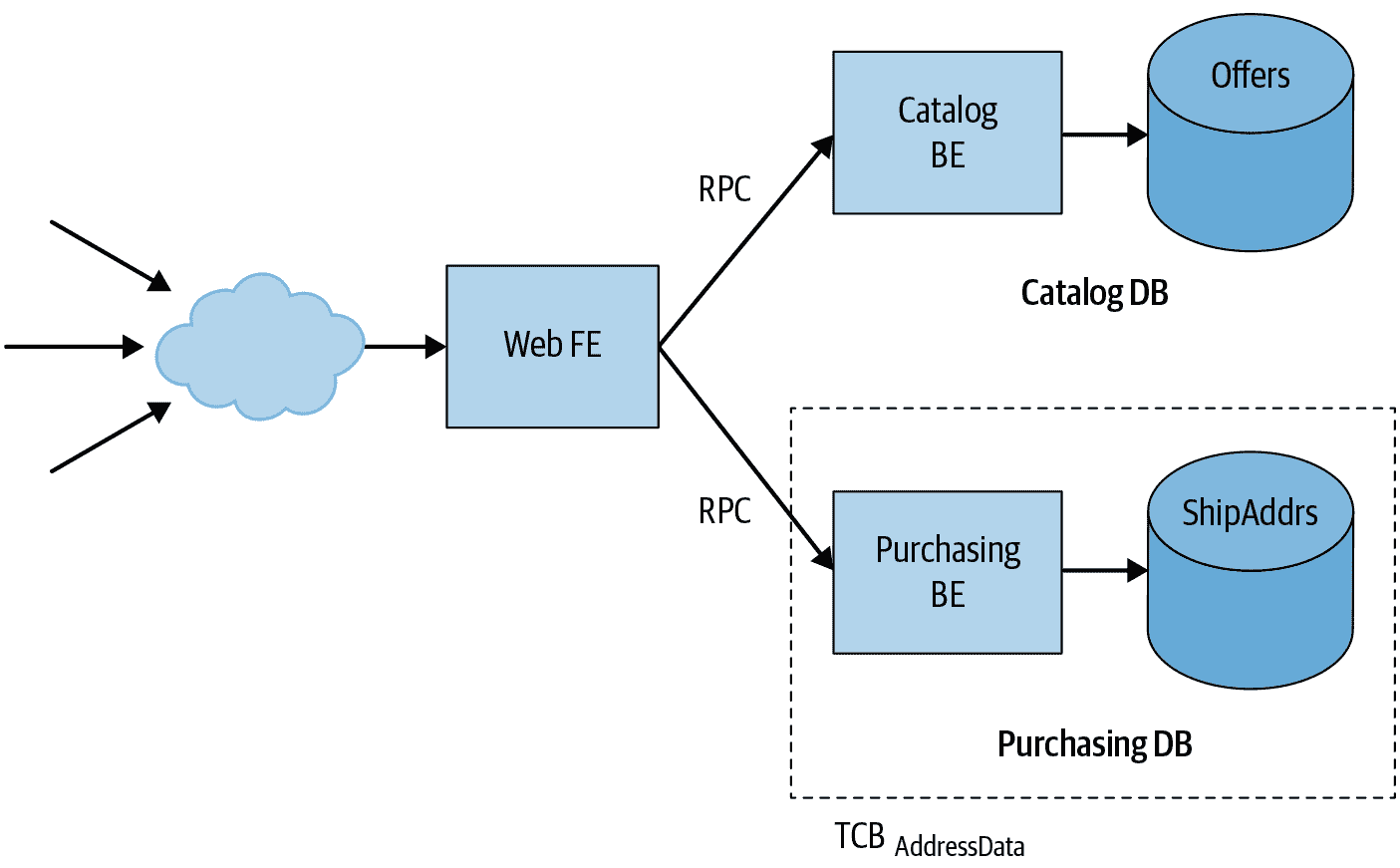
图 6-3:小部件销售应用程序的示例微服务架构
在这种新的架构中,地址数据安全策略的受信任计算基础要小得多:它仅包括购买后端及其数据库,以及它们的相关依赖项。攻击者不再能够利用目录后端中的漏洞来获取付款数据,因为目录后端根本无法访问该数据。因此,这种设计限制了主要系统组件中漏洞的影响(这是第八章中进一步讨论的主题)。
安全边界和威胁模型
受信任的计算基础的大小和形状将取决于您想要保证的安全属性和系统的架构。您不能只是在系统的一个组件周围画一个虚线并称其为 TCB。您必须考虑组件的接口,以及它可能隐含地信任系统的其他部分的方式。
假设我们的应用程序允许用户查看和更新他们的送货地址。由于购买后端处理送货地址,该后端需要公开一个 RPC 方法,允许 Web 前端检索和更新用户的送货地址。
如果购买后端允许前端获取任何用户的送货地址,那么入侵 Web 前端的攻击者可以使用此 RPC 方法来访问或修改任何和所有用户的敏感数据。换句话说,如果购买后端比随机第三方更信任 Web 前端,那么 Web 前端就是 TCB 的一部分。
另外,购买后端可以要求前端提供所谓的终端用户上下文票证(EUC),以在特定外部用户请求的上下文中对请求进行身份验证。EUC 是由中央认证服务发行的内部短期票证,以外部凭据(例如身份验证 cookie 或与特定请求相关的令牌(例如 OAuth2))交换而来。如果后端只对具有有效 EUC 的请求提供数据,那么入侵前端的攻击者就无法完全访问购买后端,因为他们无法为任意用户获取 EUC。最坏的情况是,他们可能会在攻击期间获取正在使用应用程序的用户的敏感数据。
为了提供另一个例子,说明 TCB 相对于正在考虑的威胁模型的相关性,让我们思考一下这种架构与 Web 平台的安全模型的关系。¹⁴在这个安全模型中,Web 来源(服务器的完全合格主机名,加上协议和可选端口)代表一个信任域:在给定来源的上下文中运行的 JavaScript 可以观察或修改该上下文中存在或可用的任何信息。相反,浏览器根据称为同源策略的规则限制不同来源之间内容和代码之间的访问。
我们的 Web 前端可能会从单个 Web 来源(例如https://widgets.example.com)提供其整个 UI。这意味着,例如,通过目录显示 UI 中的 XSS 漏洞¹⁵注入到我们的来源中的恶意脚本可以访问用户的个人资料,并且甚至可能能够以该用户的名义“购买”物品。因此,在 Web 安全威胁模型中,TCB[AddressData]再次包括整个 Web 前端。
我们可以通过进一步分解系统并建立额外的安全边界来解决这种情况,这种情况是基于 Web 来源的。如图 6-4 所示,我们可以操作两个单独的 Web 前端:一个实现目录搜索和浏览,并在https://widgets.example.com提供服务,另一个负责购买配置文件和结账,在https://checkout.example.com提供服务。¹⁶ 现在,目录 UI 中的 Web 漏洞(例如 XSS)不能危害支付功能,因为该功能被隔离到其自己的 Web 来源中。

图 6-4:分解 Web 前端
TCB 和可理解性
除了安全性的好处外,TCB 和安全边界还使系统更容易理解。为了符合 TCB 的资格,组件必须与系统的其余部分隔离。该组件必须具有明确定义的干净接口,并且您必须能够独立地推理 TCB 的实现的正确性。如果组件的正确性取决于该组件控制范围之外的假设,那么它从定义上来说就不是 TCB。
TCB 通常是其自身的故障域,这使得更容易理解应用程序在面对错误、DoS 攻击或其他操作影响时的行为。第八章更深入地讨论了将系统分隔成更多部分的好处。
软件设计
一旦您将一个大型系统结构化为由安全边界分隔的组件,您仍然需要推理给定安全边界内所有代码和子组件的所有内容,这通常仍然是一个相当大而复杂的软件部分。本节讨论了构建软件以进一步使小型软件组件(如模块、库和 API)的不变性能够推理的技术。
使用应用程序框架满足服务范围的需求
如前所述,框架可以提供可重用功能的部分。一个给定的系统可能有身份验证框架、授权框架、RPC 框架、编排框架、监控框架、软件发布框架等。这些框架可以提供很大的灵活性,通常是太多的灵活性。所有可能的框架组合以及它们可以配置的方式可能会让与服务交互的工程师(应用程序和服务开发人员、服务所有者、SRE 和 DevOps 工程师)感到不知所措。
在 Google,我们发现创建更高级的框架来管理这种复杂性很有用,我们称之为应用程序框架。有时这些被称为全栈或内置电池框架。应用程序框架为各个功能模块提供了一个规范的子框架集,具有合理的默认配置,并保证所有子框架可以协同工作。应用程序框架使用户无需选择和配置一组子框架。
例如,假设一个应用程序开发人员使用他们喜欢的 RPC 框架公开了一个新的服务。他们使用自己喜欢的身份验证框架设置了身份验证,但忘记配置授权和/或访问控制。从功能上看,他们的新服务似乎运行良好。但是,没有授权策略,他们的应用程序是非常不安全的。任何经过身份验证的客户端(例如系统中的每个应用程序)都可以随意调用这个新服务,违反了最小特权原则(参见第五章)。这种情况可能导致严重的安全问题,例如,想象一下,服务公开的一个方法允许调用者重新配置数据中心中的所有网络交换机!
一个应用程序框架可以通过确保每个应用程序都有有效的授权策略,并通过提供安全的默认值来避免这个问题,从而禁止所有未经明确允许的客户端。
一般来说,应用程序框架必须提供一种有见地的方式来启用和配置应用程序开发人员和服务所有者需要的所有功能,包括(但不限于)以下内容:
-
请求分派、请求转发和截止时间传播
-
用户输入净化和区域设置检测
-
身份验证、授权和数据访问审计
-
日志记录和错误报告
-
健康管理、监控和诊断
-
配额执行
-
负载平衡和流量管理
-
二进制和配置部署
-
集成、预发布和负载测试
-
仪表板和警报
-
容量规划和供应
-
处理计划的基础设施中断
应用程序框架解决了与可靠性相关的问题,如监控、警报、负载平衡和容量规划(见第十二章)。因此,应用程序框架允许跨多个部门的工程师使用相同的语言,从而增加团队之间的可理解性和共鸣。
理解复杂的数据流
许多安全属性依赖于关于值在系统中流动的断言。
例如,许多 Web 服务在各种情况下使用 URL。最初,在整个系统中将 URL 表示为字符串似乎是简单而直接的。然而,应用程序的代码和库可能会做出隐含的假设,即 URL 是格式良好的,或者 URL 具有特定的方案,如https。如果可以使用违反这些假设的 URL 调用此类代码,则此类代码是不正确的(并可能存在安全漏洞)。换句话说,存在一个隐含的假设,即从不可信的外部调用者接收输入的上游代码应用了正确和适当的验证。
然而,字符串类型的值并不附带任何关于它是否表示格式良好的 URL 的明确断言。“字符串”类型本身只表明该值是一系列特定长度的字符或代码点(具体取决于实现语言的细节)。关于该值的其他属性的任何假设都是隐含的。因此,对下游代码的正确性进行推理需要理解所有上游代码,以及该代码是否实际执行所需的验证。
通过将值表示为特定数据类型,使得对流经大型复杂系统的数据属性进行推理更加容易,该类型的合同规定了所需的属性。在更易理解的设计中,您的下游代码不是以基本字符串类型的形式使用 URL,而是作为一个类型(例如作为 Java 类实现)来表示格式良好的 URL。¹⁷ 这种类型的合同可以由类型的构造函数或工厂函数强制执行。例如,Url.parse(String)工厂函数将执行运行时验证,并返回Url的实例(表示格式良好的 URL),或者对于格式不正确的值发出错误信号或抛出异常。
有了这种设计,理解消耗 URL 的代码以及其正确性是否依赖于其格式良好性,不再需要理解所有的调用者以及它们是否执行适当的验证。相反,您可以通过理解两个较小的部分来理解 URL 处理。首先,您可以独立检查Url类型的实现。您可以观察到所有类型的构造函数都确保格式良好,并且它们保证所有类型的实例符合类型的文档合同。然后,您可以分别推理出消耗Url类型值的代码的正确性,使用类型的合同(即格式良好性)作为推理的假设。
以这种方式使用类型有助于理解,因为它可以显著减少你需要阅读和验证的代码量。没有类型,你必须理解所有使用 URL 的代码,以及所有以纯字符串形式传递 URL 到该代码的代码。通过将 URL 表示为一种类型,你只需要理解Url.parse()内部的数据验证实现(以及类似的构造函数和工厂函数),以及Url的最终用途。你不需要理解其余仅传递类型实例的应用程序代码。
在某种意义上,类型的实现行为就像 TCB 一样——它完全负责“所有 URL 都是格式良好的”属性。然而,在常用的实现语言中,接口、类型或模块的封装机制通常并不代表安全边界。因此,你不能将模块的内部视为可以抵御模块外部恶意代码行为的 TCB。这是因为在大多数语言中,模块边界“外部”的代码仍然可以修改模块的内部状态(例如,通过使用反射特性或类型转换)。类型封装允许你理解模块的行为,但只有在假设周围的代码是由非恶意开发人员编写,并且代码在未被破坏的环境中执行的情况下。这实际上是一个合理的假设;通常由组织和基础设施级别的控制来确保,例如存储库访问控制、代码审查流程、服务器加固等。但如果这个假设不成立,你的安全团队将需要解决由此产生的最坏情况(参见第四部分)。
你也可以使用类型来推理更复杂的属性。例如,防止注入漏洞(如 XSS 或 SQL 注入)取决于适当验证或编码任何外部和潜在恶意的输入,这是在接收输入和将其传递给易受注入的 API 之间的某个时刻。
断言应用程序没有注入漏洞需要理解从外部输入到所谓的注入接收器(即,如果提供不够验证或编码的输入,API 容易出现安全漏洞)的所有代码和组件。在典型应用程序中,这样的数据流可能非常复杂。通常会发现数据流通过前端接收值,通过一个或多个微服务后端层,持久化在数据库中,然后稍后读取并在注入接收器的上下文中使用。在这种情况下,常见的漏洞类别是所谓的存储型 XSS漏洞,其中不受信任的输入通过持久存储达到 HTML 注入接收器(例如 HTML 模板或浏览器端 DOM API),而没有适当的验证或转义。在合理的时间范围内审查和理解大型应用程序中所有相关流的并集通常远远超出了人类的能力,即使他们配备了工具。
防止这种注入漏洞的一种有效方法是使用类型来区分已知安全用于特定注入接收上下文的值,例如 SQL 查询或 HTML 标记:¹⁸
-
SafeSql或SafeHtml等类型的构造函数和构建器 API 负责确保这些类型的所有实例在相应的接收器上下文中确实是安全的(例如,SQL 查询 API 或 HTML 渲染上下文)。这些 API 通过潜在不受信任的值的运行时验证和正确构造的 API 设计的组合来确保类型契约。构造函数还可能依赖于更复杂的库,例如完整的 HTML 验证器/净化器或应用上下文敏感的 HTML 模板系统,这些系统对插入模板的数据应用上下文敏感的转义或验证。 -
修改接收器以接受适当类型的值。类型契约规定其值在相应的上下文中是安全的,这使得有类型的 API 在构造时是安全的。例如,当使用仅接受
SafeSql类型值(而不是String)的 SQL 查询 API 时,您不必担心 SQL 注入漏洞,因为所有SafeSql类型的值都可以安全地用作 SQL 查询。 -
接收器也可以接受基本类型的值(例如字符串),但在这种情况下,不能对接收器注入上下文中的值的安全性做出任何假设。相反,接收器 API 本身负责验证或编码数据,以确保在运行时该值是安全的。
通过这种设计,您可以支持一个断言,即整个应用程序基于对类型实现和类型安全接收器 API 的理解单独不会受到 SQL 注入或 XSS 漏洞的影响。您不需要理解或阅读转发这些类型值的任何应用程序代码,因为类型封装确保应用程序代码无法使安全相关的类型不变。您也不需要理解和审查使用类型的安全构造器创建类型实例的应用程序代码,因为这些构造器旨在确保其类型的契约,而不假设其调用者的行为。第十二章详细讨论了这种方法。
考虑 API 的可用性
考虑 API 的采用和使用对组织开发人员及其生产力的影响是一个好主意。如果 API 使用起来很麻烦,开发人员将会缓慢或不愿采用它们。构造安全的 API 有双重好处,使您的代码更易理解,并允许开发人员专注于应用程序的逻辑,同时还可以自动将安全方法构建到组织的文化中。
幸运的是,通常可以设计库和框架,使得构造安全的 API 对开发人员是一个净好处,同时也促进了安全和可靠性的文化。作为采用您的安全 API 的回报,理想情况下遵循他们已经熟悉的已建立模式和习惯语,您的开发人员将获得不需要负责确保与 API 使用相关的安全不变量的好处。
例如,上下文自动转义的 HTML 模板系统完全负责正确验证和转义插入模板的所有数据。这是整个应用程序的一个强大的安全不变量,因为它确保任何这样的模板的渲染都不会导致 XSS 漏洞,无论模板被喂入什么(潜在恶意的)数据。
同时,从开发者的角度来看,使用上下文自动转义的 HTML 模板系统就像使用常规的 HTML 模板一样-您提供数据,模板系统将其插入到 HTML 标记中的占位符中-只是您不再需要担心添加适当的转义或验证指令。
示例:安全的加密 API 和 Tink 加密框架
加密代码特别容易出现微妙的错误。许多加密原语(如密码和哈希算法)具有灾难性的故障模式,非专家很难识别。例如,在某些情况下,加密与身份验证不正确地结合在一起(或根本没有使用身份验证),只能观察服务请求是否失败或被接受的攻击者仍然可以利用服务作为所谓的“解密神谕”并恢复加密消息的明文。(21)一个不熟悉攻击技术的非专家几乎没有注意到这个缺陷的机会:加密数据看起来完全不可读,而代码使用的是标准的、推荐的、安全的密码,如 AES。然而,由于名义上安全密码的微妙错误用法,加密方案是不安全的。
根据我们的经验,涉及密码原语的代码如果不是由经验丰富的密码学家开发和审查的,通常会存在严重的缺陷。正确使用密码学确实非常困难。
我们在许多安全审查项目中的经验促使谷歌开发了 Tink:一个使工程师能够在其应用程序中安全使用密码学的库。Tink 源于我们与谷歌产品团队合作的丰富经验,修复密码实现中的漏洞,并提供了简单的 API,使没有密码学背景的工程师可以安全使用。
Tink 减少了常见的加密陷阱,并提供了易于正确使用且难以滥用的安全 API。以下原则指导了 Tink 的设计和开发:
默认安全
该库提供了一个难以被滥用的 API。例如,API 不允许在 Galois 计数器模式中重用 nonce,这是一个相当常见但微妙的错误,在RFC 5288中特别指出,因为它允许导致 AES-GCM 模式的完整认证失败的认证密钥恢复。多亏了Project Wycheproof,Tink 重用了经过验证和经过充分测试的库。
易用性
该库具有简单易用的 API,因此软件工程师可以专注于所需的功能,例如实现块和流的带关联数据的认证加密(AEAD)原语。
可读性和可审计性
功能在代码中清晰可读,Tink 保持对使用的加密方案的控制。
可扩展性
可以很容易地通过密钥管理器的注册表添加新功能、方案和格式。
敏捷性
Tink 内置了密钥轮换,并支持淘汰过时/损坏的方案。
互操作性
Tink 在许多语言和平台上都可用。
Tink 还提供了一个密钥管理的解决方案,与Cloud Key Management Service (KMS)、AWS Key Management Service和Android Keystore集成。许多密码库都可以轻松地将私钥存储在磁盘上,并且更容易地将私钥添加到您的源代码中——这是一种强烈不建议的做法。即使您运行“keyhunt”和“password hunt”活动来查找和清除代码库和存储系统中的秘密,也很难完全消除与密钥管理相关的事件。相比之下,Tink 的 API 不接受原始密钥材料。相反,API 鼓励使用密钥管理服务。
谷歌使用 Tink 来保护许多产品的数据,现在它是谷歌内部和与第三方通信时保护数据的推荐库。通过提供具有良好理解属性(如“经过身份验证的加密”)的抽象,支持良好设计的实现,它允许安全工程师专注于加密代码的更高级别方面,而不必担心底层加密原语的攻击。
然而,需要注意的是,Tink 无法防止加密代码中的高级设计错误。例如,没有足够密码学背景的软件开发人员可能会选择通过散列来保护敏感数据。如果问题数据来自一个(在密码学术语中)相对较小的集合,比如信用卡或社会安全号码,这是不安全的。在这种情况下使用密码散列,而不是经过身份验证的加密,是一个设计级错误,它在 Tink 的 API 之上表现出来。安全审查人员不能因为代码使用 Tink 而不是其他加密库就得出这样的结论,即这样的错误在应用程序中不存在。
软件开发人员和审查人员必须注意理解库或框架保证和不保证的安全性和可靠性属性。Tink 可以防止许多可能导致低级加密漏洞的错误,但不能防止基于使用错误的加密 API(或根本不使用加密)的错误。同样,一个安全构建的 Web 框架可以防止 XSS 漏洞,但不能防止应用程序业务逻辑中的安全漏洞。
结论
可靠性和安全性从根本上和紧密地与可理解系统相互关联。
尽管“可靠性”有时被视为“可用性”的同义词,但这个属性实际上意味着维护系统的所有关键设计保证——包括可用性、耐久性和安全不变量等。
我们构建可理解系统的主要指导是使用具有清晰和受限目的的组件。其中一些组件可能构成其受信任的计算基础,因此集中负责解决安全风险。
我们还讨论了强制执行理想属性的策略,例如安全不变量、架构弹性和数据耐久性,以及这些组件之间的关系。这些策略包括以下内容:
-
窄、一致、类型化的接口
-
一致和谨慎地实现身份验证、授权和会计策略
-
将身份清晰地分配给活动实体,无论它们是软件组件还是人类管理员
-
应用程序框架库和数据类型封装安全不变量,以确保组件始终遵循最佳实践
当您最关键的系统行为发生故障时,系统的可理解性可能是短暂事件和长期灾难之间的区别。SRE 必须了解系统的安全不变量才能完成他们的工作。在极端情况下,他们可能不得不在安全事件期间使服务脱机,以牺牲可用性换取安全性。
¹ 自动模糊测试,特别是如果结合仪器和覆盖指导,有时可以探索更大比例的可能行为。这在第十三章中有详细讨论。
² 例如SANS, MITRE, 和OWASP发布的内容。
³ 参见 Murray, Toby, and Paul van Oorschot. 2018. “BP: Formal Proofs, the Fine Print and Side Effects.” Proceedings of the 2018 IEEE Cybersecurity Development Conference: 1–10. doi:10.1109/SecDev.2018.00009.
⁴ 参见 Klein, Gerwin 等人。2014 年。《Comprehensive Formal Verification of an OS Microkernel》。ACM 计算机系统交易 32(1):1-70。doi:10.1145/2560537。
⁵ 例如,参见 Erbsen, Andres 等人。2019 年。《Simple High-Level Code for Cryptographic Arithmetic—With Proofs, Without Compromises》。2019 年 IEEE 安全与隐私研讨会论文集:73-90。doi:10.1109/SP.2019.00005。另一个例子,请参见 Chudnov, Andrey 等人。2018 年。《Continuous Formal Verification of Amazon s2n》。第 30 届国际计算机辅助验证会议论文集:430-446。doi:10.1007/978-3-319-96142-2_26。
⁶ 参见 Denning, Peter J. 1968 年。《Thrashing: Its Causes and Prevention》。1968 年秋季联合计算机会议论文集:915-922。doi:10.1145/1476589.1476705。
⁷ 有关更多信息,请参见SRE workbook 中的第十一章。
⁸ 通常情况下,系统中有多个身份子系统。例如,系统可能有一个用于内部微服务的身份子系统,另一个用于人类管理员的身份子系统。
⁹ 有关 Borg 的更多信息,请参见 Verma, Abhishek 等人。2015 年。《Large-Scale Cluster Management at Google with Borg》。欧洲计算机系统会议论文集(EuroSys)。https://oreil.ly/zgKsd。
¹⁰ Anderson, Ross J. 2008 年。《Security Engineering: A Guide to Building Dependable Distributed Systems》。霍博肯,新泽西州:Wiley。
¹¹ 这是真的,除非用户 A 是根用户,以及其他一些特定条件,例如涉及共享内存,或者像 Linux 能力这样的机制赋予根用户特定的权限。
¹² 为了使示例简单化,图 6-2 没有显示与外部服务提供商的连接。
¹³ 在实际设计中,您可能会使用一个单独的数据库,其中有多组表,工作负载身份已被授予适当的访问权限。这样可以实现对数据的访问分离,同时允许数据库确保所有表之间的数据一致性属性,例如购物车内容和目录商品之间的外键约束。
¹⁴ Zalewski, Michał。2012 年。《The Tangled Web: A Guide to Securing Modern Web Applications》。旧金山,加利福尼亚州:No Starch Press。
¹⁵ 参见 Zalewski,《The Tangled Web》。
¹⁶ 我们需要配置我们的 Web 服务器,以便支付前端不可以在例如https://widgets.example.com/checkout上访问。
¹⁷ 或者更一般地说,一个满足特定相关属性的 URL,比如具有特定方案。
¹⁸ 参见 Kern, Christoph。2014 年。《Securing the Tangled Web》。ACM 通信 57(9):38-47。doi:10.1145/2643134。
¹⁹ 参见 Samuel, Mike, Prateek Saxena 和 Dawn Song。2011 年。《Context-Sensitive Auto-Sanitization in Web Templating Languages Using Type Qualifiers》。第 18 届 ACM 计算机与通信安全会议论文集:587-600。doi:10.1145/2046707.2046775。
²⁰ 正如前面所指出的,这种断言仅在假设应用程序的整个代码库都是非恶意的情况下才成立。换句话说,类型系统依赖于在代码库的其他地方发生非恶意错误的情况下维护不变量,但不能抵御积极恶意的代码,例如使用语言的反射 API 修改类型的私有字段。您可以通过额外的安全机制,如代码审查、访问控制和源代码存储库级别的审计跟踪来解决后者。
²¹ 参见 Rizzo, Juliano, and Thai Duong. 2010. “Practical Padding Oracle Attacks.” Proceedings of the 4th USENIX Conference on Offensive Technologies: 1–8. https://oreil.ly/y-OYm。
第七章:面向不断变化的环境的设计
原文:7. Design for a Changing Landscape
译者:飞龙
协议:CC BY-NC-SA 4.0
Maya Kaczorowski、John Lunney 和 Deniz Pecel
与 Jen Barnason、Peter Duff 和 Emily Stark 合作
“变化是唯一不变的”是一个至理名言,对于软件来说绝对是如此:随着我们每年使用的设备数量(和种类)的增加,图书馆和应用程序的漏洞数量也在增加。任何设备或应用程序都有可能受到远程利用、数据泄露、僵尸网络接管或其他引人注目的情景的影响。
与此同时,用户和监管机构对安全和隐私的期望不断提高,要求实现更严格的控制,如企业特定的访问限制和认证系统。
为了应对这种不断变化的漏洞、期望和风险,您需要能够频繁快速地改变您的基础设施,同时保持高度可靠的服务——这并不容易。实现这种平衡通常归结为决定何时以及多快地推出变更。
安全变更类型
您可能会做出许多种改变,以改善您的安全姿态或安全基础设施的弹性,例如:
-
对安全事件做出的变更(见第十八章)
-
对新发现的漏洞做出的变更
-
产品或功能变更
-
出于内部动机改善您的安全姿态的变更
-
外部动机的变更,如新的监管要求
一些类型的出于安全考虑的变更需要额外的考虑。如果你正在推出一个可选功能作为迈向强制性的第一步,你需要收集足够的早期采用者反馈,并彻底测试你的初始工具。
如果您正在考虑对依赖项进行更改,例如供应商或第三方代码依赖项,您需要确保新解决方案符合您的安全要求。
设计您的变更
安全变更受到与任何其他软件变更相同的基本可靠性要求和发布工程原则的约束;有关更多信息,请参阅本书中的第四章和 SRE 书中的第八章](https://landing.google.com/sre/sre-book/chapters/release-engineering/)。推出安全变更的时间表可能有所不同(请参阅[“不同的变更:不同的速度,不同的时间表”),但整体流程应遵循相同的最佳实践。
所有变更都应具有以下特征:
渐进式
进行尽可能小而独立的变更。避免将变更与不相关的改进(如重构代码)联系在一起的诱惑。
记录
描述您的变更的“如何”和“为什么”,以便他人能够理解变更和推出的相对紧急性。您的文档可能包括以下任何或所有内容:
-
要求
-
受影响的系统和团队
-
从概念验证中学到的经验
-
决策的基础(以防需要重新评估计划)
-
所有涉及的团队的联系点
测试
使用单元测试和(在可能的情况下)集成测试来测试您的安全变更(有关测试的更多信息,请参阅第十三章)。完成同行评审,以获得变更在生产环境中能够正常工作的信心。
隔离
使用功能标志来隔离彼此的变更,并避免发布不兼容性;有关更多信息,请参阅SRE 工作手册中的第十六章。当关闭功能时,底层二进制应该不会表现出任何行为上的变化。
合格的
使用您正常的二进制发布流程推出您的变更,在接收生产或用户流量之前,通过资格的各个阶段。
分阶段
逐步推出你的变更,并进行金丝雀测试的仪器化。你应该能够在变更前后看到行为上的差异。
这些做法建议采取“缓慢而稳定”的推出方式。根据我们的经验,速度和安全之间的有意的权衡是值得的。你不希望通过推出一个有问题的变更来冒险制造一个更大的问题,比如广泛的停机或数据丢失。
使变更更容易的架构决策
如何设计你的基础架构和流程,以应对你将面临的不可避免的变化?在这里,我们讨论了一些策略,使你能够灵活地调整系统并推出变化,同时也有助于建立安全可靠的文化(在第二十一章中讨论)。
保持依赖项最新并频繁重新构建
确保你的代码指向代码依赖的最新版本有助于使你的系统不太容易受到新的漏洞的影响。保持对依赖项的引用最新对于经常更改的开源项目尤为重要,比如 OpenSSL 或 Linux 内核。许多大型开源项目都有建立良好的安全漏洞响应和修复计划,澄清了新发布是否包含关键安全补丁,并将修复补丁迁移到受支持的版本。如果你的依赖项是最新的,你很可能可以直接应用关键补丁,而不需要合并一大堆变更或应用多个补丁。
新发布及其安全补丁在你的环境中不会生效,直到你重新构建。频繁重新构建和部署你的环境意味着当你需要时你将准备好推出新版本,并且紧急推出可以获取最新的变更。
使用自动化测试频繁发布
基本的 SRE 原则建议定期切割和推出发布,以促进紧急变更。通过将一个大的发布分割成许多较小的发布,你确保每个发布包含的变更更少,因此更不太可能需要回滚。有关这个主题的更深入探讨,请参见 SRE workbook 中的“善行循环”(https://landing.google.com/sre/workbook/chapters/canarying-releases/#the-virtuous-cycle-of-ci-cd)。
当每个发布包含更少的代码变更时,更容易理解发生了什么变化并找出潜在问题。当你需要推出安全变更时,你可以更加自信地预期结果。
为了充分利用频繁的发布,自动化它们的测试和验证。这样可以自动推送良好的发布,同时防止不足的发布进入生产环境。自动化测试还可以在需要推出修复以防止关键漏洞时给你额外的信心。
同样,通过使用容器²和微服务³,你可以减少需要修补的表面积,建立定期发布流程,并简化你对系统漏洞的理解。
使用容器
容器将应用程序所需的二进制文件和库与底层主机操作系统解耦。因为每个应用程序都打包了自己的依赖和库,所以主机操作系统不需要包含它们,因此可以更小。因此,应用程序更具可移植性,你可以独立地对其进行安全保护。例如,你可以在主机操作系统中修补内核漏洞,而无需更改应用程序容器。
容器的设计是不可变的,这意味着它们在部署后不会改变——而不是通过 SSH 进入机器,你重新构建和部署整个镜像。因为容器的寿命很短,它们经常被重新构建和部署。
与其对活动容器进行修补,不如对容器注册表中的镜像进行修补。这意味着您可以将一个完全打了补丁的容器镜像作为一个单元进行部署,使补丁的部署过程与您(非常频繁的)代码部署过程相同,包括监控、金丝雀发布和测试。因此,您可以更频繁地进行补丁。
随着这些变化应用到每个任务中,系统会无缝地将服务流量转移到另一个实例;参见《SRE 书》第七章中的“案例研究 4:在共享平台上运行数百个微服务”。您可以通过蓝/绿部署实现类似的结果,并在修补时避免停机;参见《SRE 工作手册》第十六章。
您还可以使用容器来检测和修补新发现的漏洞。由于容器是不可变的,它们提供内容可寻址性。换句话说,您实际上知道在您的环境中运行什么,例如,您部署了哪些镜像。如果您之前部署了一个完全打了补丁的镜像,恰好容易受到新漏洞的影响,您可以使用您的注册表来识别易受影响的版本并应用补丁,而不是直接扫描您的生产集群。
为了减少这种临时修补的需求,您应该监视生产环境中运行的容器的年龄,并定期重新部署,以确保旧容器不再运行。同样,为了避免重新部署较旧的未打补丁的镜像,您应该强制执行只有最近构建的容器才能在生产环境中部署。
使用微服务
理想的系统架构易于扩展,提供对系统性能的可见性,并允许您管理基础架构中服务之间的每个潜在瓶颈。使用微服务架构,您可以将工作负载分割为更小、更易管理的单元,以便进行维护和发现。因此,您可以独立扩展、负载平衡和在每个微服务中执行部署,这意味着您可以更灵活地进行基础架构更改。由于每个服务都单独处理请求,您可以独立和顺序地使用多种防御措施,提供深度防御(见“深度防御”)。
微服务还自然地促进了有限或零信任的网络,这意味着您的系统并不会因为一个服务位于同一网络中就本能地信任它(见第六章)。与使用基于边界的安全模型不同,该模型将不受信任的外部流量与受信任的内部流量进行区分,微服务使用更多元化的信任概念在边界内部:内部流量可能具有不同级别的信任。当前的趋势是朝着越来越分段化的网络发展。随着对单一网络边界(如防火墙)的依赖被消除,网络可以通过服务进一步分段。在极端情况下,网络可以实现微服务级别的分段,服务之间没有固有的信任关系。
使用微服务的一个次要后果是安全工具的收敛,因此一些流程、工具和依赖关系可以在多个团队之间重复使用。随着架构的扩展,整合您的努力以解决共享的安全需求可能是有意义的,例如,使用常见的加密库或常见的监控和警报基础设施。这样,您可以将关键的安全服务拆分为单独的微服务,由少数负责方更新和管理。重要的是要注意,实现微服务架构的安全优势需要克制,以确保服务尽可能简单,同时仍保持所需的安全属性。
使用微服务架构和开发流程允许团队在开发和部署生命周期的早期阶段解决安全问题——在进行更改成本较低的时候——以标准化的方式。因此,开发人员可以在花费较少时间处理安全性的同时实现安全的结果。
示例:谷歌的前端设计
谷歌的前端设计使用微服务提供弹性和深度防御。将前端和后端分开成不同的层有许多优势:Google Front End(GFE)作为大多数谷歌服务的前端层,实现为微服务,因此这些服务不直接暴露在互联网上。GFE 还终止了传入 HTTP(S)、TCP 和 TLS 代理的流量;提供了 DDoS 攻击对策;并将流量路由和负载平衡到谷歌云服务。
GFE 允许独立分区前端和后端服务,这在可伸缩性、可靠性、灵活性和安全性方面都有好处:
-
全局负载平衡有助于在 GFE 和后端之间移动流量。例如,我们可以在数据中心故障期间重定向流量,减少缓解时间。
-
后端和前端层内部可以有几个层。因为每个层都是一个微服务,我们可以对每个层进行负载平衡。因此,相对容易增加容量,进行一般性更改或对每个微服务应用快速更改。
-
如果服务过载,GFE 可以作为缓解点,在负载达到后端之前丢弃或吸收连接。这意味着微服务架构中并非每个层都需要自己的负载保护。
-
新协议和安全要求的采用相对简单。即使一些后端还没有准备好,GFE 也可以处理 IPv6 连接。GFE 还通过作为各种常见服务的终止点来简化证书管理,比如 SSL。例如,当发现 SSL 重新协商的实现中存在漏洞时,GFE 的控制限制了这些重新协商,保护了其后面的所有服务。快速的应用层传输安全加密也说明了微服务架构如何促进变化的采用:谷歌的安全团队将 ALTS 库集成到其 RPC 库中,以处理服务凭据,从而实现了广泛的采用,而对个别开发团队的负担不大。
在今天的云世界中,您可以通过使用微服务架构、构建安全控制层和使用服务网格来实现类似于此处描述的好处。例如,您可以将请求处理与管理请求处理的配置分开。行业将这种有意的分离称为数据平面(请求)和控制平面(配置)。在这种模型中,数据平面提供系统中的实际数据处理,通常处理负载平衡、安全性和可观察性。控制平面为数据平面服务提供策略和配置,从而提供可管理和可扩展的控制表面。
不同的更改:不同的速度,不同的时间轴
并非所有更改都在相同的时间轴上或以相同的速度发生。有几个因素影响您可能希望进行更改的速度:
严重性
每天都会发现漏洞,但并非所有漏洞都是关键的、正在被积极利用的,或者适用于您特定的基础设施。当您遇到这种情况时,您可能希望尽快发布补丁。加速的时间表会造成混乱,并更有可能破坏系统。有时速度是必要的,但一般来说,变化发生得越慢越安全,这样您就可以确保足够的产品安全性和可靠性。(理想情况下,您可以独立应用关键安全补丁,这样您就可以快速应用补丁,而不会不必要地加速其他正在进行的推出。)
依赖系统和团队
一些系统变化可能取决于其他团队,他们需要在推出之前实现新政策或启用特定功能。您的变化也可能取决于外部方面,例如,如果您需要从供应商那里接收补丁,或者如果客户需要在您的服务器之前打补丁。
敏感性
您的变化的敏感性可能会影响您何时可以将其部署到生产环境中。改进组织整体安全状况的非必要变化并不一定像关键补丁那样紧急。您可以更逐渐地推出这种非必要的变化,例如逐个团队。根据其他因素,进行变化可能不值得冒风险——例如,您可能不希望在关键的生产时间窗口内推出非紧急变化,比如假日购物活动期间,那里的变化通常是受严格控制的。
截止日期
一些变化有一个有限的截止日期。例如,监管变化可能有指定的合规日期,或者您可能需要在披露漏洞之前(请参见下面的侧边栏)应用补丁。
确定特定变化速度没有硬性规定——一个组织可能需要快速进行配置更改和推出,而另一个组织可能需要数月时间。虽然单个团队可能能够按照特定时间表进行特定变化,但您的组织可能需要很长时间才能完全采纳这种变化。
在接下来的几节中,我们将讨论变化的三种不同时间范围,并举例说明谷歌的情况:
-
对新安全漏洞的短期变化反应
-
中期变化,新产品采用可能会逐渐发生
-
出于监管原因的长期变化,谷歌必须构建新系统以实现变化
短期变化:零日漏洞
新发现的漏洞通常需要短期行动。零日漏洞是已知至少部分攻击者知道的漏洞,但尚未公开披露或被针对的基础设施提供者发现。通常,补丁要么尚未可用,要么尚未广泛应用。
有多种方法可以了解可能影响您环境的新漏洞,包括定期代码审查、内部代码扫描(参见“清理您的代码”)、模糊测试(参见“模糊测试”)、外部扫描如渗透测试和基础设施扫描,以及漏洞赏金计划。
在短期变化的背景下,我们将重点放在谷歌在零日得知漏洞的情况。尽管谷歌通常参与封锁漏洞响应,例如在开发补丁时,对于零日漏洞的短期变化是行业中大多数组织的常见行为。
注意
尽管零日漏洞受到了很多关注(无论是外部还是内部),但它们不一定是攻击者最经常利用的漏洞。在处理当天零日漏洞之前,请确保您已经为近年来的“热门”漏洞打了补丁。
当你发现一个新的漏洞时,要对其进行分类,以确定其严重程度和影响。例如,允许远程代码执行的漏洞可能被认为是关键的。但对你的组织的影响可能非常难以确定:哪些系统使用这个特定的二进制文件?受影响的版本是否部署在生产环境中?在可能的情况下,你还需要建立持续的监控和警报,以确定漏洞是否正在被积极利用。
要采取行动,你需要获取一个补丁——一个应用了修复的受影响软件包或库的新版本。首先要验证补丁是否真的解决了漏洞。使用一个有效的利用工具来做这件事可能是有用的。但要注意,即使你无法使用利用工具触发漏洞,你的系统可能仍然是有漏洞的(请记住,没有证据并不意味着没有证据)。例如,你应用的补丁可能只解决了一个更大类别的漏洞中的一个可能的利用。
一旦验证了你的补丁,就将其推出——最好是在测试环境中。即使在加速的时间表上,补丁也应该像任何其他生产变更一样逐渐推出——使用相同的测试、金丝雀发布和其他工具——大约需要几个小时或几天的时间。逐步推出可以让你及早发现潜在问题,因为补丁可能会对你的应用产生意想不到的影响。例如,使用你不知道的 API 的应用可能会影响性能特征或引起其他错误。
有时你无法直接修复漏洞。在这种情况下,最好的做法是通过限制或限制对易受攻击的组件的访问来减轻风险。这种减轻可能是临时的,直到补丁可用,或者是永久的,如果你无法将补丁应用到你的系统上——例如,因为性能要求。如果已经有适当的减轻措施来保护你的环境,你甚至可能不需要采取进一步的行动。
有关事件响应的更多细节,请参见第十七章。
示例:Shellshock
2014 年 9 月 24 日早上,谷歌安全团队得知了一个公开披露的、可以远程利用的漏洞,这个漏洞在shell上轻松地允许在受影响的系统上执行代码。漏洞披露很快就被野外利用所跟随,从同一天开始。
原始报告有一些混乱的技术细节,并没有清楚地说明对讨论这个问题的禁运的状态。这份报告,再加上几个类似漏洞的迅速发现,导致了对攻击的性质和可利用性的困惑。谷歌的事件响应团队启动了其黑天鹅协议,以应对一个特殊的漏洞,并协调了大规模的响应来做以下事情:⁸
-
确定范围内的系统和每个系统的相对风险级别
-
内部向所有可能受到影响的团队通报
-
尽快修补所有有漏洞的系统
-
外部向合作伙伴和客户通报我们的行动,包括补救计划
我们在公开披露之前不知道这个问题,所以我们将其视为需要紧急减轻的零日漏洞。在这种情况下,bash 的修补版本已经可用。
团队评估了不同系统的风险,并相应地采取了行动。
-
我们认为大量的谷歌生产服务器风险较低。这些服务器很容易通过自动化发布进行修补。一旦服务器经过足够的验证和测试,我们会比通常更快地对其进行修补,而不是长时间分阶段进行。
-
我们认为大量的谷歌工作站风险更高。幸运的是,这些工作站很容易快速修补。
-
少量非标准服务器和继承基础设施被认为存在高风险,需要手动干预。我们向每个团队发送通知,详细说明他们需要采取的后续行动,这使我们能够将努力扩展到多个团队,并轻松跟踪进展。
与此同时,团队开发了软件来检测谷歌网络范围内的易受攻击系统。我们使用这个软件完成了剩余的补丁工作,并将这个功能添加到了谷歌的标准安全监控中。
我们在这次应对工作中做得好(和不好)提供了许多其他团队和组织的教训:
-
尽可能标准化软件分发,这样补丁就成了简单的选择。这还要求服务所有者理解和接受选择非标准、不受支持分发的风险。服务所有者应负责维护和打补丁替代选项。
-
使用公共分发标准——理想情况下,你需要推出的补丁已经是正确的格式。这样,你的团队可以开始快速验证和测试补丁,而不需要重新制定补丁以解决你特定的环境。
-
确保你可以加速推动紧急变更的机制,比如零日漏洞。这个机制应该允许在向受影响系统全面推出之前进行比平时更快的验证。我们不一定建议你跳过验证你的环境仍然正常运行的步骤——你必须在需要减轻利用的需求之间平衡这一步骤。
-
确保你有监控来跟踪你的推出进度,识别未打补丁的系统,以及识别你仍然存在漏洞的地方。如果你已经有工具来识别漏洞是否正在被利用,它可能会帮助你决定根据你当前的风险放缓或加速。
-
尽早准备外部沟通,尽可能在应对工作的早期。当媒体要求回应时,你不希望在内部公关批准中被拖延。
-
提前起草可重复使用的事件或漏洞响应计划(见第十七章),包括外部沟通的语言。如果你不确定你需要什么,可以从以前事件的事后总结开始。
-
了解哪些系统是非标准的或需要特别关注。通过跟踪离群值,你将知道哪些系统可能需要积极通知和补丁协助。(如果你按照我们在第一条建议的标准化软件分发,离群值应该是有限的。)
中期变化:改善安全状况
安全团队经常实现改变以提高环境的整体安全状况并减少风险。这些积极的改变是由内部和外部的要求和截止日期驱动的,很少需要突然推出。
在规划安全状况变更时,你需要弄清楚哪些团队和系统受到影响,并确定最佳的开始地点。遵循“设计你的变更”中概述的 SRE 原则,制定逐步推出的行动计划。每个阶段都应包括必须在进入下一个阶段之前满足的成功标准。
受安全变更影响的系统或团队不能必然表示为推出的百分比。相反,你可以根据受影响的人和需要进行的变更来分阶段推出。
在受影响的人员方面,逐组推出您的变更,其中一组可能是一个开发团队、系统或一组最终用户。例如,您可以开始向经常在外出的用户(如销售团队)推出设备策略的变更。这样可以让您快速测试最常见的情况,并获得真实的反馈。在推出人员方面有两种相互竞争的哲学:
-
从最容易的用例开始,这样你将获得最大的动力并证明价值。
-
从最困难的用例开始,这样你将找到最多的错误和边缘情况。
当您仍在寻求组织的支持时,从最容易的用例开始是有意义的。如果您在一开始就得到了领导支持和投资,那么尽早发现实现错误和痛点就更有价值。除了组织上的考虑,您还应考虑哪种策略将在短期和长期内带来最大的风险降低。在所有情况下,成功的概念验证有助于确定如何最好地前进。进行变更的团队还必须经历这一过程,“吃自己的狗粮”,以便他们了解用户体验。
您可能还可以逐步推出变更本身。例如,您可以逐渐实现更严格的要求,或者变更最初可以选择加入,而不是强制性的。在可能的情况下,您还应考虑在警报或审计模式下进行变更的试运行,然后再切换到执行模式——这样,用户可以在变更强制执行之前体验到他们将受到的影响。这样可以帮助您找到错误地确定为受影响范围内的用户或系统,以及对于他们来说,达到合规性将特别困难的用户或系统。
示例:使用 FIDO 安全密钥进行强大的双因素认证
钓鱼是 Google 的一个重大安全问题。尽管我们已广泛实现了使用一次性密码(OTPs)的双因素认证,但 OTP 仍然容易在钓鱼攻击中被截取。我们假设即使是最复杂的用户也是出于善意并且做好了应对钓鱼的准备,但仍然容易受到由于混乱的用户界面或用户错误而导致的账户接管。为了解决这一风险,从 2011 年开始,我们调查和测试了几种更强大的双因素认证(2FA)方法。我们最终选择了通用双因素(U2F)硬件安全令牌,因为它们具有安全性和可用性属性。为了为 Google 庞大的全球分布的员工群体实现安全密钥,需要构建定制集成并协调大规模注册。
评估潜在解决方案和我们最终的选择是变更过程的一部分。一开始,我们定义了安全、隐私和可用性要求。然后,我们与用户一起验证潜在的解决方案,以了解正在发生的变化,获得真实的反馈,并衡量变化对日常工作流程的影响。
除了安全和隐私要求,潜在的解决方案还必须满足可用性要求,以促进无缝采用,这对于建立安全和可靠性文化至关重要(见第二十一章)。双因素认证需要简单易用——快速和“无脑”到足以使错误或不安全地使用它变得困难。这一要求对于 SREs 尤为重要——在发生故障时,双因素认证不能减慢响应流程。此外,内部开发人员需要能够通过简单的 API 轻松地将双因素认证解决方案集成到他们的网站中。在理想的可用性要求方面,我们希望找到一个高效的解决方案,适用于跨多个帐户的用户,并且不需要额外的硬件,而且在物理上轻松、易学、易于找回。
在评估了几种选择后,我们共同设计了FIDO 安全密钥。尽管这些密钥并不符合我们所有的理想要求,但在最初的试点中,安全密钥减少了总认证时间,并且认证失败率可以忽略不计。
一旦我们有了解决方案,就必须向所有用户推出安全密钥,并在谷歌全面停用 OTP 支持。我们从 2013 年开始推出安全密钥。为了确保广泛采用,注册是自助的:
-
最初,许多用户自愿选择安全密钥,因为这些密钥比现有的 OTP 工具更简单易用——他们不必从手机输入代码或使用物理 OTP 设备。用户获得了可以留在笔记本电脑的 USB 驱动器中的“纳米”安全密钥。
-
要获得安全密钥,用户可以前往任何办公室的任何 TechStop 位置。 (向全球办公室分发设备很复杂,需要法律团队进行出口合规和海关进口要求。)
-
用户通过自助注册网站注册他们的安全密钥。TechStops 为第一批采用者和需要额外帮助的人提供了帮助。用户需要在首次认证时使用现有的 OTP 系统,因此密钥在首次使用时是可信的(TOFU)。
-
用户可以注册多个安全密钥,这样他们就不必担心丢失密钥。这种方法增加了整体成本,但与我们的目标强烈一致,即不让用户携带额外的硬件。
团队在推出过程中确实遇到了一些问题,比如固件过时。在可能的情况下,我们以自助方式解决这些问题,例如允许用户自行更新安全密钥固件。
使安全密钥对用户可访问只是问题的一半。使用 OTP 的系统也需要转换为使用安全密钥。2013 年,许多应用程序并不原生支持这一最近开发的技术。团队首先专注于支持谷歌员工日常使用的应用程序,如内部代码审查工具和仪表板。在不支持安全密钥的情况下(例如某些硬件设备证书管理和第三方 Web 应用程序),谷歌直接与供应商合作请求并添加支持。然后我们必须处理长尾应用程序。由于所有 OTP 都是集中生成的,我们可以通过跟踪发出 OTP 请求的客户端来确定下一个目标应用程序。
2015 年,团队专注于完成推出并停用 OTP 服务。当用户使用 OTP 而不是安全密钥时,我们会发送提醒,并最终通过 OTP 阻止访问。尽管我们已经处理了大部分 OTP 应用需求,但仍然存在一些例外情况,比如移动设备设置。对于这些情况,我们为特殊情况创建了基于 Web 的 OTP 生成器。用户需要使用他们的安全密钥验证身份,这是一个合理的故障模式,但时间负担略高。我们成功地在 2015 年完成了全公司范围内的安全密钥推出。
这一经验提供了一些普遍适用的教训,对于建立安全和可靠性文化很有相关性(参见第二十一章):
确保所选择的解决方案适用于所有用户。
至关重要的是,2FA 解决方案必须是可访问的,以便视力受损的用户不会被排除在外。
使变更易于学习,并尽可能轻松。
如果解决方案比初始情况更用户友好,这一点尤为重要!这对于您期望用户频繁执行的操作或更改尤为重要,稍微的摩擦可能会导致用户负担重大。
使变更成为自助服务,以减轻中央 IT 团队的负担。
对于影响所有用户日常活动的广泛变化,重要的是他们能够轻松地注册、注销和解决问题。
向用户提供解决方案有效并符合他们最佳利益的有形证据。
清楚地解释变化对安全和风险减少的影响,并提供他们提供反馈的机会。
尽快使政策不合规的反馈循环。
这种反馈循环可以是身份验证失败、系统错误或电子邮件提醒。让用户在几分钟或几小时内知道他们的操作与期望的政策不一致,使他们能够采取措施解决问题。
跟踪进展并确定如何解决长尾问题。
通过检查应用程序的 OTP 请求,我们可以确定下一个要关注的应用程序。使用仪表板跟踪进展,并确定是否具有类似安全属性的替代解决方案可以适用于使用情况的长尾。
长期变化:外部需求
在某些情况下,您可能需要更多时间来推出变化,例如,需要进行重大架构或系统变更的内部驱动变化,或者更广泛的行业监管变化。这些变化可能受到外部截止日期或要求的激励或限制,并可能需要数年时间来实现。
在进行大规模、多年的努力时,您需要清晰地定义并衡量与目标的进展。文档尤为关键,既可以确保您考虑了必要的设计考虑因素(参见“设计您的变化”),也可以保持连续性。今天致力于变革的个人可能会离开公司并需要移交他们的工作。保持文档与最新计划和状态的更新对于维持持续的领导支持至关重要。
为了衡量持续的进展,建立适当的仪器和仪表板。理想情况下,配置检查或测试可以自动测量变化,无需人为干预。就像您为基础设施中的代码努力实现重要的测试覆盖率一样,您应该为受变化影响的系统的合规性检查覆盖率而努力。为了有效扩展这种覆盖范围,这种仪器应该是自助的,允许团队实现变化和仪器。透明地跟踪这些结果有助于激励用户,并简化沟通和内部报告。您还应该使用这个单一的真相来源进行高管沟通,而不是重复工作。
在保持持续领导支持的情况下,在组织中进行任何大规模、长期的变化是困难的。为了持续推动动力,进行这些变化的个人需要保持积极性。建立有限的目标,跟踪进展,并展示重大影响的实例可以帮助团队完成马拉松。实现总是会有长尾,因此要找出对你的情况最有意义的策略。如果变化不是必需的(根据法规或其他原因),达到 80%或 90%的采纳率可以对降低安全风险产生可衡量的影响,因此应被视为成功。
示例:增加 HTTPS 使用率
在过去的十年中,网络上的 HTTPS 采用率大幅增加,这得益于谷歌 Chrome 团队、Let’s Encrypt和其他组织的共同努力。HTTPS 为用户和网站提供了重要的保密性和完整性保证,对于网络生态系统的成功至关重要——它现在作为 HTTP/2 的一部分是必需的。
为了推动网络上的 HTTPS 使用,我们进行了广泛的研究以制定战略,通过各种外联渠道联系网站所有者,并为他们设置了强大的激励措施来进行迁移。长期而言,整个生态系统的变化需要深思熟虑的战略和重要的规划。我们采用了数据驱动的方法来确定最佳的接触每个利益相关者群体的方式:
-
我们收集了全球当前 HTTPS 使用情况的数据,以选择目标地区。
-
我们调查最终用户,以了解他们如何在浏览器中看待 HTTPS UI。
-
我们测量网站行为,以确定可以限制为 HTTPS 的网络平台功能,以保护用户隐私。
-
我们使用案例研究来了解开发人员对 HTTPS 的担忧以及我们可以构建的工具类型。
这不是一次性的努力:我们在多年的时间里继续监测指标并收集数据,必要时调整我们的战略。例如,随着我们逐渐在几年的时间内推出 Chrome 对不安全页面的警告,我们监测用户行为遥测,以确保 UI 变化不会导致意外的负面影响(例如,留存率或与网络的互动下降)。
过度沟通是成功的关键。在每次变更之前,我们利用所有可用的外联渠道:博客、开发人员邮件列表、新闻、Chrome 帮助论坛和与合作伙伴的关系。这种方法最大化了我们的影响力,使网站所有者不会感到惊讶,因为他们被推动迁移到 HTTPS。我们还根据地区情况进行了定制化的外联工作——例如,当我们意识到日本的 HTTPS 采用率因顶级网站的采用速度缓慢而滞后时,我们特别关注了日本。
最终,我们专注于创建和强调激励措施,以提供迁移到 HTTPS 的商业原因。即使是注重安全的开发人员也很难说服他们的组织,除非他们能将迁移与商业案例联系起来。例如,启用 HTTPS 允许网站使用 Web 平台功能,如Service Worker,这是一种使离线访问、推送通知和定期后台同步成为可能的后台脚本。这些功能,限制在 HTTPS 网站上,可以提高性能和可用性,并可能直接影响企业的底线。只有当组织感到迁移到 HTTPS 与他们的业务利益一致时,他们才更愿意投入资源。
如图 7-1 所示,跨平台的 Chrome 用户现在超过 90%的时间花在 HTTPS 网站上,而以前,Windows 上的 Chrome 用户这一数字低至 70%,Android 上的 Chrome 用户为 37%。来自许多组织的无数人——网页浏览器供应商、证书颁发机构和网页发布者——都为此增长做出了贡献。这些组织通过标准机构、研究会议和对每个面临的挑战和成功的公开沟通进行协调。Chrome 在这一转变中的角色产生了关于为生态系统范围的变化做出贡献的重要经验教训:
在承诺战略之前了解生态系统。
我们的战略基于定量和定性研究,重点关注包括不同国家和不同设备上的网页开发人员和最终用户在内的广泛利益相关者。
通过过度沟通来最大化影响力。
我们使用各种外联渠道来触达最广泛的利益相关者。
将安全变化与商业激励联系起来。
组织领导者在能够看到业务原因时更愿意迁移到 HTTPS。
建立行业共识。
多个浏览器供应商和组织同时支持网络迁移到 HTTPS;开发人员将 HTTPS 视为行业趋势。
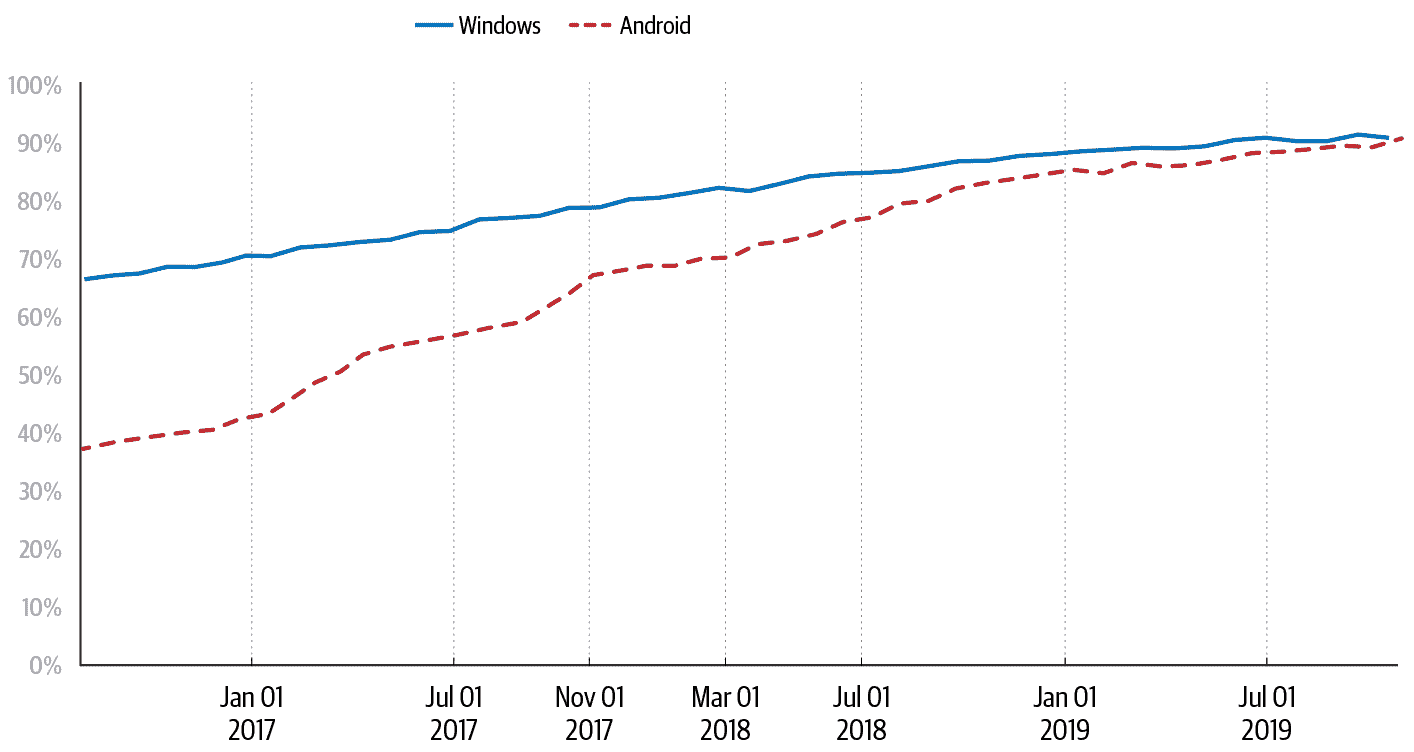
图 7-1:Chrome 平台上的 HTTPS 浏览时间百分比
复杂性:当计划改变时
安全和 SRE 的最佳计划经常会出现问题。有许多原因可能需要加快变化或放慢变化的速度。
通常,您需要根据外部因素加快变化的速度,通常是由于正在积极利用的漏洞。在这种情况下,您可能希望加快推出以尽快修补系统。要谨慎:加快速度并破坏系统并不一定对系统的安全性和可靠性更好。考虑是否可以改变推出顺序,以更快地覆盖某些更高风险的系统,或以其他方式通过限制操作的速率或将特别关键的系统下线来阻止攻击者的访问。
您也可以决定放慢变化的速度。这种方法通常是由于补丁存在问题,比如高于预期的错误率或其他推出失败。如果放慢变化的速度不能解决问题,或者在不对系统或用户造成负面影响的情况下无法完全推出,那么回滚、调试问题,然后再次推出是一种痛苦但谨慎的方法。您也可以根据更新的业务需求放慢变化的速度,例如内部截止日期的变更或行业标准的延迟。(你是什么意思,TLS 1.0 仍在使用?!)
在最理想的情况下,您在开始实现之前就改变了计划。作为回应,您只需要制定新计划!以下是更改计划的一些潜在原因,以及相应的策略:
您可能需要根据外部因素推迟变化。
如果你不能在禁令解除后立即开始打补丁(参见[“不同的变化:不同的速度,不同的时间表”](#different_changes_different_speedscomma)),与漏洞团队合作,看看是否有其他系统处于您的情况,并且是否可能改变时间表。无论如何,确保您已准备好与受影响的用户通信的计划。
你可能需要根据公开公告加快变化的速度。
对于一个受禁令的漏洞,您可能需要等待公开公告才能打补丁。如果公告泄露,如果有人公开利用漏洞,或者漏洞在野外被利用,您的时间表可能会改变。在这种情况下,您应该尽早开始打补丁。您应该在每个阶段都有一个行动计划,以应对禁令被打破时该怎么办。
你可能不会受到严重影响。
如果一个漏洞或变化主要影响公共面向网络的服务,并且您的组织拥有非常有限数量的此类服务,那么您可能不需要急于修补整个基础设施。修补受影响的部分,并减缓您对系统其他区域应用补丁的速度。
你可能依赖外部方。
大多数组织依赖第三方分发修补程序包和漏洞图像,或依赖软件和硬件交付作为基础设施变更的一部分。如果修补的操作系统不可用,或者您需要的硬件已经订购完毕,那么您可能无能为力。您可能不得不比最初计划的时间晚开始变化。
示例:范围扩大——心脏出血
2011 年 12 月,SSL/TLS 的心跳功能被添加到 OpenSSL 中,同时还出现了一个未被认识的错误,允许服务器或客户端访问另一个服务器或客户端的 64 KB 私有内存。2014 年 4 月,这个错误被谷歌员工尼尔·梅塔和 Codenomicon(一家网络安全公司)的一名工程师共同发现,并向 OpenSSL 项目报告。OpenSSL 团队提交了代码更改以修复错误,并制定了公开披露计划。出人意料的是,Codenomicon 发布了公告,并启动了解释性网站*heartbleed.com*。这是第一次使用巧妙的名称和标志,引起了意外的大规模媒体关注。
通过提前获得补丁(受到禁运限制)并在计划的公开披露之前,谷歌基础设施团队已经悄悄地修补了一小部分直接处理 TLS 流量的外部系统。然而,没有其他内部团队知道这个问题。
一旦漏洞公开,就会迅速在诸如Metasploit之类的框架中开发利用程序。面对加速的时间表,许多谷歌团队现在需要匆忙修补他们的系统。谷歌的安全团队使用自动扫描来发现其他脆弱的系统,并通知受影响的团队进行补丁,并跟踪他们的进展。内存泄露意味着私钥可能会泄露,这意味着许多服务需要密钥轮换。安全团队通知受影响的团队并在中央电子表格中跟踪他们的进展。
Heartbleed 阐明了许多重要的教训:
为禁运被突破或提前解除的最坏情况做准备。
负责任的披霆露面是理想的,但意外事件(以及激发媒体兴趣的可爱标志)可能会发生。尽可能多地进行预先工作,并迅速修补最脆弱的系统,而不管披露协议(这需要对禁运信息进行内部保密)如何。如果您能提前获得补丁,您可能可以在公开宣布之前部署它。当这不可能时,您仍应该能够测试和验证您的补丁,以确保平稳的推出过程。
为大规模快速部署做好准备。
使用持续构建来确保您可以随时重新编译,并使用金丝雀策略进行验证而不会造成破坏。
定期轮换您的加密密钥和其他机密信息。
密钥轮换是限制密钥泄露潜在影响范围的最佳实践。定期进行此操作,并确认您的系统仍然按预期工作;有关详细信息,请参阅SRE 工作手册中的第九章。通过这样做,您确保更换任何受损密钥不会是一个艰巨的工作。
确保您与最终用户(内部和外部)有沟通渠道。
当更改失败或导致意外行为时,您需要能够快速提供更新。
结论
区分不同类型的安全更改至关重要,以便受影响的团队知道他们应该做什么,以及您可以提供多少支持。
下次您被要求在您的基础设施中进行安全更改时,深呼吸并制定计划。从小处着手,或找到愿意测试更改的志愿者。建立反馈循环,了解用户遇到的问题,并使更改成为自助服务。如果计划发生变化,不要惊慌,但也不要感到惊讶。
设计策略,如频繁的推出、容器化和微服务,使得积极的改进和紧急的缓解更加容易,而分层方法则使外部表面积少且易于管理。深思熟虑的设计和持续的文档记录,都要考虑到变化,保持系统的健康,使团队的工作负担更加可管理,并且正如你将在下一章中看到的那样,这将导致更大的韧性。
¹ 广泛归因于以弗所的赫拉克利特。
² 有关容器的更多信息,请参阅 Dan Lorenc 和 Maya Kaczorowski 的博客文章“探索容器安全性”。另请参阅 Burns, Brendan 等人 2016 年的文章“Borg, Omega, and Kubernetes: Lessons Learned from Three Container-Management Systems Over a Decade.” ACM Queue 14(1)。https://oreil.ly/tDKBJ。
³ 有关微服务的更多信息,请参阅《SRE 书》第七章中的“案例研究 4:在共享平台上运行数百个微服务”。
⁴ 有关容器的更多信息,请参阅《SRE 书》第二章。
⁵ 有关更多信息,请参阅Google Cloud 中的传输加密白皮书。
⁶ 同前。
⁷ 请参阅《SRE 书》第 27 章中有关渐进和分阶段推出的讨论。
⁸ 另请参阅有关此事件的小组讨论的YouTube 视频。
⁹ 请参阅 Lang, Juan 等人 2016 年的文章“Security Keys: Practical Cryptographic Second Factors for the Modern Web.” 2016 年国际金融密码学和数据安全会议论文集:422–440。https://oreil.ly/S2ZMU。
¹⁰ TechStops 是 Google 的 IT 帮助台,由 Jesus Lugo 和 Lisa Mauck 在一篇博客文章中描述。
第八章:面向弹性的设计
原文:8. Design for Resilience
译者:飞龙
协议:CC BY-NC-SA 4.0
维塔利·希皮茨因、米奇·阿德勒、佐尔坦·埃吉德和保罗·布兰金希普
与耶稣·克利门特、杰西·杨、道格拉斯·科利什和克里斯托夫·科恩一起
作为系统设计的一部分,“弹性”描述了系统抵抗重大故障或中断的能力。具有弹性的系统可以自动从系统部分的故障中恢复,甚至可能是整个系统的故障,并在问题得到解决后恢复正常运行。弹性系统中的服务理想情况下在事故期间始终保持运行,可能是以降级模式。在系统设计的每一层中设计弹性有助于防御系统不可预期的故障和攻击场景。
为弹性设计系统与为恢复设计系统有所不同(在第九章中深入讨论)。弹性与恢复密切相关,但是恢复侧重于在系统发生故障后修复系统的能力,而弹性是关于设计延迟或承受故障的系统。注重弹性和恢复的系统更能够从故障中恢复,并且需要最少的人为干预。
弹性设计原则
系统的弹性属性建立在本书第 II 部分中讨论的设计原则之上。为了评估系统的弹性,您必须对系统的设计和构建有很好的了解。您需要与本书中涵盖的其他设计特性密切配合——最小特权、可理解性、适应性和恢复——以加强系统的稳定性和弹性属性。
以下方法是本章深入探讨的,它们表征了一个具有弹性的系统:
-
设计系统的每一层都具有独立的弹性。这种方法在每一层中构建了深度防御。
-
优先考虑每个功能并计算其成本,以便了解哪些功能足够关键,可以尝试在系统承受多大负载时维持,哪些功能不那么重要,可以在出现问题或资源受限时进行限制或禁用。然后确定在哪里最有效地应用系统有限的资源,以及如何最大化系统的服务能力。
-
将系统分隔成清晰定义的边界,以促进隔离功能部分的独立性。这样,也更容易构建互补的防御行为。
-
使用隔舱冗余来防御局部故障。对于全局故障,一些隔舱提供不同的可靠性和安全性属性。
-
通过自动化尽可能多的弹性措施来减少系统的反应时间。努力发现可能受益于新自动化或改进现有自动化的新故障模式。
-
通过验证系统的弹性属性来保持系统的有效性——包括其自动响应和系统的其他弹性属性。
深度防御
深度防御通过建立多层防御边界来保护系统。因此,攻击者对系统的可见性有限,成功利用更难发动。
特洛伊木马
特洛伊木马的故事,由维吉尔在《埃涅阿斯纪》中讲述,是一个关于不足防御危险的警示故事。在围困特洛伊城十年无果之后,希腊军队建造了一匹巨大的木马,作为礼物送给特洛伊人。木马被带进特洛伊城墙内,藏在木马里的攻击者突然冲出来,从内部利用了城市的防御,然后打开城门让整个希腊军队进入,摧毁了城市。
想象一下,如果这个城市计划了深度防御,这个故事的结局会是什么样子。首先,特洛伊的防御力量可能会更仔细地检查特洛伊木马并发现欺骗。如果攻击者设法进入城门,他们可能会面对另一层防御,例如,木马可能被封闭在一个安全的庭院里,无法进入城市的其他地方。
一个 3000 年前的故事告诉我们关于规模安全甚至安全本身的什么?首先,如果你试图了解你需要防御和遏制系统的策略,你必须首先了解攻击本身。如果我们把特洛伊城看作一个系统,我们可以按照攻击者的步骤(攻击的阶段)来发现深度防御可能解决的弱点。
在高层次上,我们可以将特洛伊木马攻击分为四个阶段:
-
威胁建模和漏洞发现——评估目标并专门寻找防御和弱点。攻击者无法从外部打开城门,但他们能从内部打开吗?
-
部署——为攻击设置条件。攻击者构建并交付了一个特洛伊最终带进城墙内的物体。
-
执行——执行实际的攻击,利用之前阶段的攻击。士兵们从特洛伊木马中出来,打开城门让希腊军队进入。
-
妥协——在成功执行攻击后,损害发生并开始减轻。
特洛伊人在妥协之前的每个阶段都有机会阻止攻击,并因错过这些机会而付出了沉重的代价。同样,你系统的深度防御可以减少如果你的系统被攻击的话可能需要付出的代价。
威胁建模和漏洞发现
攻击者和防御者都可以评估目标的弱点。攻击者对他们的目标进行侦察,找到弱点,然后模拟攻击。防御者应该尽力限制在侦察期间向攻击者暴露的信息。但是因为防御者无法完全阻止这种侦察,他们必须检测到它并将其用作信号。在特洛伊木马的情况下,防御者可能会因为陌生人询问城门的防御方式而保持警惕。鉴于这种可疑活动,当他们在城门口发现一个大木马时,他们会更加谨慎。
注意这些陌生人的询问相当于收集威胁情报。有许多方法可以为你自己的系统做到这一点,你甚至可以选择外包其中的一些。例如,你可以做以下事情:
-
监视你的系统进行端口和应用程序扫描。
-
跟踪类似你的 URL 的 DNS 注册情况——攻击者可能会利用这些注册进行钓鱼攻击。
-
购买威胁情报数据。
-
建立一个威胁情报团队来研究和被动监视已知和可能对你基础设施构成威胁的活动。虽然我们不建议小公司投入资源进行这种方法,但随着公司的发展,这可能会变得具有成本效益。
作为对你系统内部了解的防御者,你的评估可以比攻击者的侦察更详细。这是一个关键点:如果你了解你系统的弱点,你可以更有效地防御它们。而且你了解攻击者目前正在使用或有能力利用的方法越多,你就越能放大这种效果。一个警告:要小心对你认为不太可能或不相关的攻击向量产生盲点。
攻击部署
如果你知道攻击者正在对你的系统进行侦察,那么检测和阻止攻击的努力就至关重要。想象一下,如果特洛伊人决定不允许木马进入城门,因为它是由他们不信任的人创建的。相反,他们可能会在允许它进入之前彻底检查特洛伊木马,或者可能会将其点燃。
在现代,你可以使用网络流量检查、病毒检测、软件执行控制、受保护的沙箱¹和适当的特权配置来检测潜在的攻击。
攻击的执行
如果你无法阻止对手的所有部署,你需要限制潜在攻击的影响范围。如果防御者将特洛伊木马圈起来,从而限制了他们的暴露,攻击者将会更难从他们的藏身之处不被察觉地前进。网络战将这种策略称为沙盒化(在“运行时层”中有更详细的描述)。
妥协
当特洛伊人醒来发现敌人站在他们的床边时,他们知道他们的城市已经被妥协了。这种意识是在实际妥协发生之后才出现的。许多不幸的银行在 2018 年面临了类似的情况,因为他们的基础设施被EternalBlue和WannaCry污染了。
你如何从这一点做出回应,将决定你的基础设施被妥协的时间有多长。
Google App Engine 分析
让我们考虑深度防御如何应用到一个更现代的案例:Google App Engine。Google App Engine 允许用户托管应用程序代码,并在负载增加时进行扩展,而无需管理网络、机器和操作系统。图 8-1 显示了 App Engine 早期的简化架构图。保护应用程序代码是开发者的责任,而保护 Python/Java 运行时和基本操作系统是 Google 的责任。
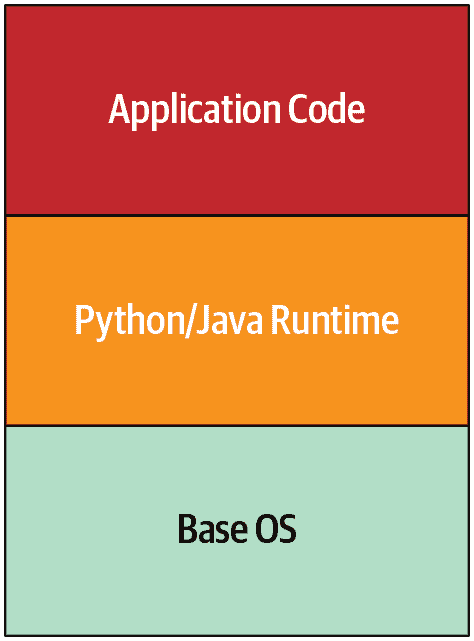
图 8-1:Google App Engine 架构的简化视图
Google App Engine 的原始实现需要特殊的进程隔离考虑。当时,Google 使用传统的 POSIX 用户隔离作为默认策略(通过不同的用户进程),但我们决定在计划的采用程度上,将每个用户的代码运行在独立的虚拟机中效率太低。我们需要找出如何以与 Google 基础设施中的任何其他作业相同的方式运行第三方、不受信任的代码。
风险的 API
App Engine 的初始威胁建模发现了一些令人担忧的领域:
-
网络访问存在问题。在那之前,所有在 Google 生产网络中运行的应用程序都被认为是受信任的和经过身份验证的基础设施组件。由于我们在这个环境中引入了任意的、不受信任的第三方代码,我们需要一种策略来将 App Engine 的内部 API 和网络暴露与其隔离开。我们还需要记住,App Engine 本身是运行在同一基础设施上的,因此依赖于对这些 API 的访问。
-
运行用户代码的机器需要访问本地文件系统。至少这种访问被限制在属于特定用户的目录中,这有助于保护执行环境,并减少用户提供的应用程序对同一台机器上其他用户的应用程序的干扰的风险。
-
Linux 内核意味着 App Engine 暴露在了大规模攻击的表面上,我们希望将其最小化。例如,我们希望尽可能防止许多本地权限提升的类别。
为了解决这些挑战,我们首先检查了限制用户对每个 API 的访问。我们的团队在运行时删除了用于网络和文件系统交互的内置 API。我们用“安全”版本替换了内置 API,这些版本调用其他云基础设施,而不是直接操作运行时环境。
为了防止用户重新引入解释器中故意删除的功能,我们不允许用户提供的编译字节码或共享库。用户必须依赖我们提供的方法和库,以及各种可能需要的允许的仅运行时开源实现。
运行时层
我们还对运行时基本数据对象实现进行了广泛的审计,以查找可能导致内存损坏错误的功能。这次审计在我们推出的每个运行时环境中产生了一些上游错误修复。
我们假设至少一些这些防御措施会失败,因为我们不太可能找到和预测所选择运行时中的每个可利用条件。我们决定将 Python 运行时专门适应编译为 Native Client (NaCL) 位码。NaCL 允许我们防止许多类内存损坏和控制流颠覆攻击,这些攻击我们深度代码审计和加固都错过了。
我们并不完全满意 NaCL 能够完全包含所有风险代码突破和错误,因此我们添加了第二层 ptrace 沙盒,以过滤和警报意外的系统调用和参数。对这些期望的任何违反立即终止运行时,并以高优先级发送警报,以及相关活动的日志。
在接下来的五年里,团队发现了一些异常活动的案例,这是由于其中一个运行时中的可利用条件。在每种情况下,我们的沙盒层都给我们带来了明显的优势,使我们能够控制他们的活动在设计参数内。
功能上,App Engine 中的 Python 实现具有 图 8-2 中显示的沙盒层。

图 8-2:App Engine 中 Python 实现的沙盒层
App Engine 的各层是互补的,每一层都预期了前一层的弱点或可能的失败。随着防御激活穿过各层,对妥协的信号变得更强,使我们能够集中精力应对可能的攻击。
尽管我们对 Google App Engine 的安全性采取了彻底和分层的方法,但我们仍然受益于在保护环境方面的外部帮助。除了我们的团队发现异常活动外,外部研究人员还发现了几种可利用的向量。我们对发现并披露这些漏洞的研究人员表示感激。
控制退化
在深度防御设计时,我们假设系统组件甚至整个系统都可能失败。失败可能由许多原因引起,包括物理损坏、硬件或网络故障、软件配置错误或错误,或安全妥协。当组件失败时,影响可能会扩展到依赖它的每个系统。类似资源的全局池也变得更小 - 例如,磁盘故障会减少整体存储容量,网络故障会减少带宽并增加延迟,软件故障会降低整个系统的计算能力。故障可能会相互叠加 - 例如,存储空间不足可能导致软件故障。
这些资源短缺,或者像Slashdot 效应所引起的突然请求激增,错误配置,或者拒绝服务攻击,都可能导致系统超载。当系统负载超过其容量时,其响应必然开始退化,这可能导致一个完全破碎的系统,没有可用性。除非您事先计划了这种情况,否则您不知道系统可能会在哪里崩溃,但这很可能是系统最薄弱的地方,而不是最安全的地方。
为了控制退化,当出现严重情况时,您必须选择禁用或调整哪些系统属性,同时尽一切可能保护系统的安全性。如果您故意为这些情况设计多个响应选项,系统可以利用受控的断点,而不是经历混乱的崩溃。您的系统可以通过优雅地退化来响应,而不是触发级联故障并处理随之而来的混乱。以下是一些实现这一目标的方法:
-
通过禁用不经常使用的功能、最不重要的功能或高成本的服务功能,释放资源并减少失败操作的频率。然后,您可以将释放的资源应用于保留重要功能和功能。例如,大多数接受 TLS 连接的系统都支持椭圆曲线(ECC)和 RSA 加密系统。根据您系统的实现,其中一个将更便宜,同时提供可比较的安全性。在软件中,ECC 对私钥操作的资源消耗较少。³当系统资源受限时,禁用对 RSA 的支持将为 ECC 的更低成本提供更多连接空间。
-
目标是使系统响应措施能够快速自动地生效。这在您直接控制的服务器上最容易,您可以任意切换任何范围或粒度的操作参数。用户客户端更难控制:它们具有较长的发布周期,因为客户端设备可能推迟或无法接收更新。此外,客户端平台的多样性增加了由于意外不兼容性而导致响应措施回滚的机会。
-
了解哪些系统对公司的使命至关重要,以及它们的相对重要性和相互依赖性。您可能需要按照它们的相对价值保留这些系统的最小功能。例如,谷歌的 Gmail 有一个“简单的 HTML 模式”,它禁用了花哨的 UI 样式和搜索自动完成,但允许用户继续打开邮件。如果网络故障限制了某个地区的带宽,甚至可以降低这种模式的优先级,如果这样可以让网络安全监控继续保护该地区的用户数据。
如果这些调整能够显著提高系统吸收负载或故障的能力,它们将为所有其他弹性机制提供关键的补充,并为事件响应者提供更多的响应时间。最好是提前做出必要和困难的选择,而不是在事件发生时承受压力。一旦个别系统制定了明确的退化策略,就更容易在更大范围内优先考虑退化,跨多个系统或产品领域。
区分故障成本
任何失败操作都会有一定的成本,例如,从移动设备上传数据到应用后端的失败数据上传会消耗计算资源和网络带宽来设置 RPC 并推送一些数据。如果您可以重构您的流程以便早期或廉价地失败,您可能能够减少或避免一些与失败相关的浪费。
对于故障成本的推理:
识别个别操作的总成本。
例如,您可以在对特定 API 进行负载测试期间收集 CPU、内存或带宽影响指标。如果时间紧迫,首先专注于最具影响力的操作,无论是通过关键性还是频率。
确定在操作的哪个阶段产生了这些成本。
您可以检查源代码或使用开发人员工具来收集内省数据(例如,Web 浏览器提供请求阶段的跟踪)。您甚至可以在不同阶段的代码中加入故障模拟。
利用您收集的有关操作成本和故障点的信息,您可以寻找可以推迟高成本操作的变化,直到系统更进一步朝着成功发展。
计算资源
从操作开始到失败期间消耗的计算资源对任何其他操作都是不可用的。如果客户端在失败时进行积极的重试,这种影响会成倍增加,甚至可能导致系统级联故障。通过在执行流程的早期检查错误条件,您可以更快地释放计算资源,例如,您可以在系统分配内存或启动数据读取/写入之前检查数据访问请求的有效性。SYN cookies可以让您避免为源自伪造 IP 地址的 TCP 连接请求分配内存。CAPTCHA 可以帮助保护最昂贵的操作免受自动滥用。
更广泛地说,如果服务器可以得知其健康状况正在下降(例如,来自监控系统的信号),您可以让服务器切换到“残废鸭”模式:它继续提供服务,但让其调用者知道要减少或停止发送请求。这种方法提供了更好的信号,整体环境可以适应,同时最小化了用于提供错误的资源。
也可能由于外部因素,多个服务器实例变得未被使用。例如,它们运行的服务可能因安全妥协而被“排空”或隔离。如果您监视这种情况,服务器资源可以暂时释放以供其他服务重用。然而,在重新分配资源之前,您应该确保保护任何可能对法医调查有帮助的数据。
用户体验
系统与用户的交互在降级条件下应具有可接受的行为水平。理想的系统会通知用户其服务可能出现故障,但允许他们继续与保持功能的部分进行交互。系统可能尝试不同的连接、认证和授权协议或端点以保持功能状态。由于故障造成的任何数据陈旧或安全风险应清楚地向用户传达。不再安全使用的功能应明确禁用。
例如,向在线协作应用添加离线模式可以在临时丢失在线存储、显示他人更新或集成聊天功能的情况下保留核心功能。在端到端加密的聊天应用中,用户可能偶尔更改用于保护通信的加密密钥。这样的应用将保持所有先前的通信可访问,因为它们的真实性不受此更改的影响。
相比之下,一个糟糕的设计示例是整个 GUI 变得无响应,因为其后端的 RPC 之一已超时。想象一下,设计为在启动时连接到后端以仅显示最新内容的移动应用。后端可能无法访问,仅仅是因为设备的用户有意禁用了连接;尽管如此,用户仍然看不到以前缓存的数据。
可能需要用户体验(UX)研究和设计工作,以找到在降级模式下提供可用性和生产力的 UX 解决方案。
减轻速度
系统在失败后的恢复速度会影响失败的成本。此响应时间包括人类或自动化进行减轻变化的时间以及最后一个受影响的组件实例更新和恢复的时间。避免将关键故障点放入像客户端应用这样更难控制的组件中。
回到之前的例子,移动应用在启动时发起新鲜度更新的设计选择将连接性转变为关键依赖。在这种情况下,初始问题会因应用程序更新的缓慢和不可控速度而被放大。
部署响应机制
理想情况下,系统应该通过安全的、预先编程的措施积极应对恶化的条件,以最大限度地提高响应的效果,同时最大限度地减少对安全性和可靠性的风险。自动化措施通常比人类表现更好——人类反应较慢,可能没有足够的网络或安全访问权限来完成必要的操作,并且在解决多个变量时不如机器。然而,人类应该保持在循环中,以提供检查和平衡,并在意外或非平凡情况下做出决策。
让我们详细考虑管理过度负载的问题——无论是由于服务能力的丧失、良性流量峰值,还是 DoS 攻击。人类可能反应不够快,流量可能会压倒服务器,导致级联故障和最终全局服务崩溃。通过永久超额配置服务器来创建保障会浪费金钱,并不能保证安全响应。相反,服务器应根据当前条件调整它们对负载的响应方式。在这里可以使用两种具体的自动化策略:
-
负载放弃是通过返回错误而不是提供请求来实现的。
-
客户端的限流是通过延迟响应直到接近请求截止日期来实现的。
图 8-3 说明了超出容量的流量峰值。图 8-4 说明了使用负载放弃和限流来管理负载峰值的效果。请注意以下内容:
-
曲线代表每秒请求,曲线下方代表总请求量。
-
空白表示处理流量而没有失败。
-
反斜线区域代表受损的流量(一些请求失败)。
-
斜线区域代表被拒绝的流量(所有请求失败)。
-
斜线区域代表受优先处理的流量(重要请求成功)。
图 8-3 显示了系统可能实际崩溃,导致在请求数量和停机时间方面产生更大的影响。图 8-3 还区分了系统崩溃前的受控流量的不受控制的性质(反斜线区域)。图 8-4 显示了负载放弃的系统拒绝的流量明显少于图 8-3 中的流量(斜线区域),其余流量要么在没有失败的情况下被处理(空白区域),要么如果优先级较低则被拒绝(斜线区域)。
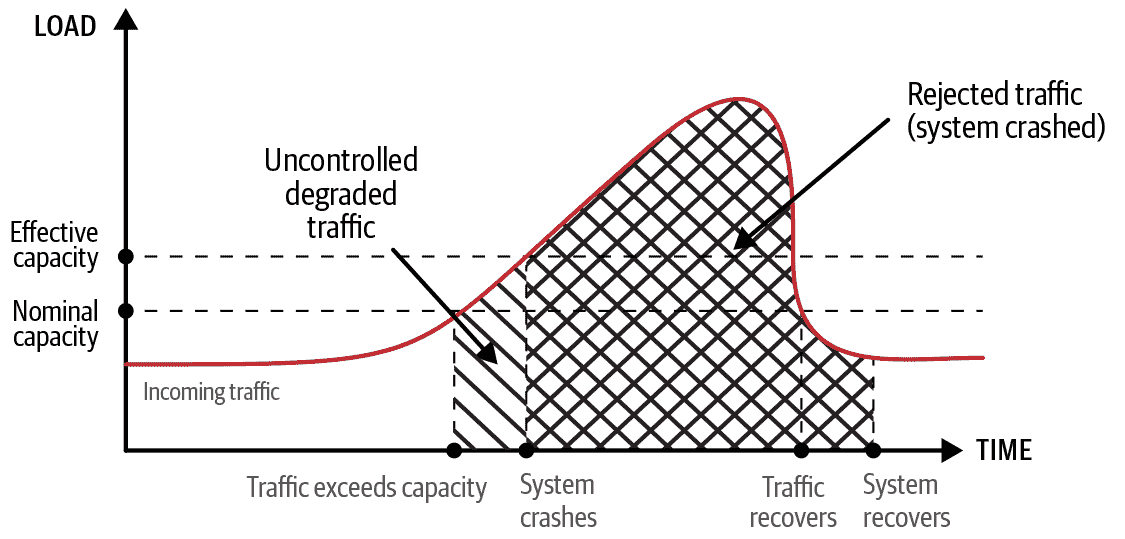
图 8-3:完全停机和负载峰值可能引发级联故障
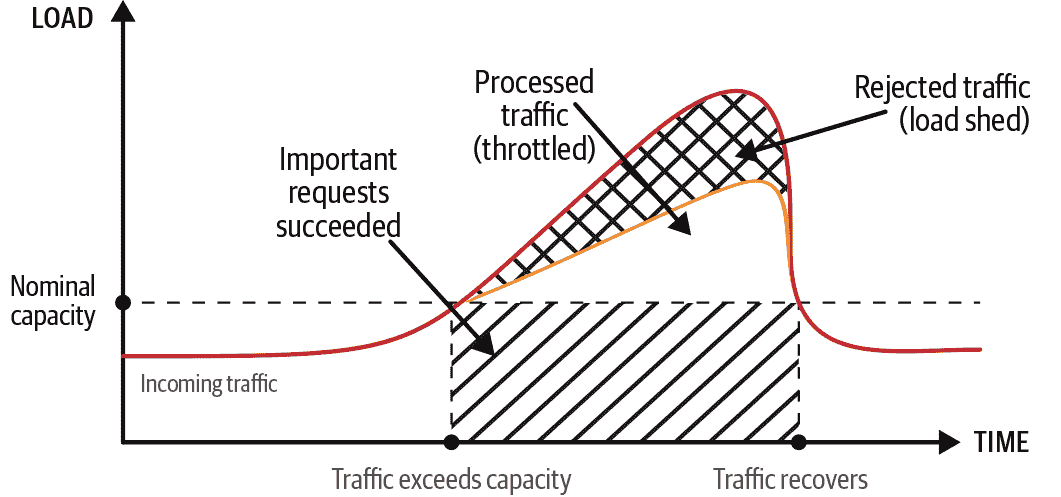
图 8-4:使用负载放弃和限流来管理负载峰值
负载放弃
负载分担的主要弹性目标(在SRE 书籍的第 22 章中描述)是将组件稳定在最大负载,这对于保护安全关键功能尤为有益。当组件的负载开始超过其容量时,您希望组件为所有过多的请求提供错误响应,而不是崩溃。崩溃会使所有组件的容量不可用——不仅仅是用于过多请求的容量。当这种容量消失时,负载会转移到其他地方,可能导致级联故障。
负载分担允许您在服务器负载达到容量之前释放服务器资源,并使这些资源可用于更有价值的工作。为了选择要分担的请求,服务器需要具有请求优先级和请求成本的概念。您可以定义一个策略,根据请求优先级、请求成本和当前服务器利用率来确定每种请求类型要分担多少。根据请求的业务关键性或其依赖关系分配请求优先级(安全关键功能应该获得高优先级)。您可以测量或经验估计请求成本。⁵无论哪种方式,这些测量应该与服务器利用率测量相当,例如 CPU 和(可能)内存使用。当然,计算请求成本应该是经济的。
限流
限流(在SRE 书籍的第二十一章中描述)通过延迟当前操作以推迟未来操作,间接修改客户端的行为。服务器收到请求后,可能会在处理请求之前等待,或者在处理完请求后,在向客户端发送响应之前等待。这种方法减少了服务器从客户端接收的请求的速率(如果客户端按顺序发送请求),这意味着您可以在等待时间内重定向所节省的资源。
类似于负载分担,您可以定义策略将限流应用于特定的有问题的客户端,或者更普遍地应用于所有客户端。请求优先级和成本在选择要限流的请求时起着作用。
自动响应
服务器利用统计数据可以帮助确定何时考虑应用诸如负载分担和限流之类的控制。服务器负载越重,它能处理的流量或负载就越少。如果控制需要太长时间才能激活,优先级较高的请求可能最终会被丢弃或限流。
为了有效地管理这些降级控制,您可能需要一个中央内部服务。您可以将关于使命关键功能和故障成本的业务考虑转化为该服务的策略和信号。这个内部服务还可以聚合关于客户端和服务的启发式信息,以便向几乎实时地所有服务器分发更新的策略。然后服务器可以根据基于服务器利用率的规则应用这些策略。
一些自动响应的可能性包括以下内容:
-
实现能够响应限流信号并尝试将流量转移到负载较低的服务器的负载平衡系统
-
提供可以在限流无效或有害时协助应对恶意客户端的 DoS 保护
-
使用关于关键服务的大规模停电报告来触发备用组件的故障转移准备(这是我们在本章后面讨论的一种策略)
您还可以使用自动化进行自主故障检测:确定无法为某些或所有类别的请求提供服务的服务器可以将自身降级为完全的负载分担模式。自包含或自托管的检测是可取的,因为您不希望依赖外部信号(可能是攻击者模拟的)来迫使整个服务器群陷入故障。
在实现优雅降级时,重要的是确定和记录系统降级的级别,无论是什么触发了问题。这些信息对诊断和调试很有用。报告实际的负载分担或限制(无论是自我施加的还是指导的)可以帮助您评估全局健康和容量,并检测错误或攻击。您还需要这些信息来评估当前剩余的系统容量和用户影响。换句话说,您想知道各个组件和整个系统的降级程度,以及您可能需要采取的手动操作。事件发生后,您将希望评估您的降级机制的有效性。
负责任地自动化
在创建自动响应机制时要谨慎,以防止它们使系统的安全性和可靠性降低到意外程度。
安全失败与安全失败
在设计处理故障的系统时,您必须在优化可靠性的失败开放(安全)和优化安全性的失败关闭(安全)之间取得平衡:^(6)
-
为了最大程度地提高可靠性,系统应该抵抗故障,并在面对不确定性时尽可能提供服务。即使系统的完整性没有得到保证,只要其配置是可行的,一个针对可用性进行优化的系统将提供其所能提供的服务。如果 ACL 加载失败,则假定默认 ACL 为“允许所有”。
-
为了最大程度地提高安全性,系统在面对不确定性时应完全封锁。如果系统无法验证其完整性——无论是由于故障的磁盘带走了其配置的一部分,还是攻击者更改了配置以进行利用——它就不能被信任运行,应尽可能保护自己。如果 ACL 加载失败,则假定默认 ACL 为“拒绝所有”。
这些可靠性和安全性原则显然是相互矛盾的。为了解决这种紧张局势,每个组织必须首先确定其最低不可妥协的安全姿态,然后找到提供所需安全服务关键特性的可靠性的方法。例如,配置为丢弃低 QoS(服务质量)数据包的网络可能需要为安全导向的 RPC 流量标记特殊的 QoS,以防止数据包丢失。安全导向的 RPC 服务器可能需要特殊标记,以避免被工作负载调度程序耗尽 CPU。
人类的立足点
有时人类必须参与服务降级决策。例如,基于规则的系统进行判断的能力受到预定义规则的固有限制。当自动化面临不符合系统任何预定义响应的未预见情况时,自动化不会起作用。由于编程错误,自动化响应也可能产生未预见的情况。允许适当的人类干预来处理这些和类似情况需要在系统设计中进行一些事先考虑。
首先,您应该防止自动化禁用员工用于恢复基础设施的服务(请参阅“紧急访问”)。重要的是为这些系统设计保护,以便即使是 DoS 攻击也不能完全阻止访问。例如,SYN 攻击不应该阻止响应者为 SSH 会话打开 TCP 连接。确保实现低依赖性的替代方案,并持续验证这些替代方案的能力。
此外,不要允许自动化进行大规模(例如,单个服务器放弃所有RPC)或大范围(所有服务器放弃一些 RPC)的无监督策略更改。考虑实现变更预算。当自动化耗尽该预算时,不会发生自动刷新。相反,必须由人类增加预算或做出不同的判断。请注意,尽管有人类干预,自动化仍然存在。
控制爆炸半径
通过限制系统的每个部分的范围,您可以为您的深度防御策略增加另一层。例如,考虑网络分段。过去,组织通常拥有一个包含所有资源(机器、打印机、存储、数据库等)的单一网络。这些资源对网络上的任何用户或服务都是可见的,并且访问由资源本身控制。
今天,改善安全性的常见方法是对网络进行分段,并为特定类别的用户和服务授予对每个段的访问权限。您可以通过使用具有网络 ACL 的虚拟局域网(VLAN)来实现这一点,这是一种易于配置的行业标准解决方案。您可以控制进入每个段的流量,并控制允许通信的段。您还可以限制每个段对“需要知道”的信息的访问。
网络分段是隔离的一般概念的一个很好的例子,我们在第六章中讨论过。隔离涉及有意地创建小的个体操作单元(隔间),并限制对每个隔间的访问和来自每个隔间的访问。对系统的大多数方面进行隔间化是一个好主意,包括服务器、应用程序、存储等等。当您使用单一网络设置时,入侵者如果窃取了用户的凭据,可能会访问网络上的每个设备。然而,当您使用隔间化时,一个隔间中的安全漏洞或流量过载并不会危及所有隔间。
控制爆炸半径意味着将事件的影响分隔开,类似于船舶上的隔舱可以使整艘船免于沉没。在设计弹性时,您应该创建约束攻击者和意外故障的隔舱壁垒。这些隔离壁垒可以让您更好地定制和自动化您的响应。您还可以使用这些边界来创建故障域,提供组件冗余和故障隔离,如在“故障域和冗余”中所讨论的那样。
隔间还有助于隔离努力,减少了响应者需要积极平衡防御和保留证据的需求。一些隔间可以被隔离和冻结以进行分析,而其他隔间则可以被恢复。此外,隔间在事件响应期间为更换和修复创建了自然边界,一个隔间可能被舍弃以拯救系统的其余部分。
要控制入侵的爆炸半径,您必须有一种建立边界并确保这些边界安全的方法。将生产中运行的作业视为一个隔间。这个作业必须允许一些访问(您希望这个隔间有用),但不能是无限制的访问(您希望保护这个隔间)。限制谁可以访问作业取决于您识别生产中的端点并确认其身份的能力。
您可以通过使用经过身份验证的远程过程调用来实现这一点,该调用可以在一个连接中识别双方。为了保护各方的身份免受欺骗,并将其内容隐藏在网络中,这些 RPC 使用相互认证的连接,可以证明连接到服务的双方的身份。为了让端点对其他隔间做出更明智的决定,您可以添加端点与其身份一起发布的附加信息。例如,您可以向证书添加位置信息,以便拒绝非本地请求。
一旦建立隔间的机制到位,您将面临一个艰难的抉择:您需要通过足够的分离来限制您的操作,以提供有用大小的隔间,但又不会创建太多的分离。例如,隔间化的一个平衡方法是将每个 RPC 方法视为单独的隔间。这样可以沿着逻辑应用边界对齐隔间,而隔间的数量与系统功能的数量成正比。
控制 RPC 方法可接受参数值的隔间分离需要更加谨慎的考虑。虽然这会创建更严格的安全控制,但每个 RPC 方法可能的违规次数与 RPC 客户端的数量成正比。这种复杂性会在系统的所有功能中累积,并需要协调客户端代码和服务器策略的更改。另一方面,无论 RPC 服务或其方法如何,包装整个服务器的隔间要容易得多,但提供的价值相对较少。在权衡这种权衡时,有必要与事件管理和运营团队协商,以考虑隔间类型的选择,并验证您的选择的效用。
不完美的隔间化并不能完全覆盖所有边缘情况,但也可以提供价值。例如,寻找边缘情况的过程可能会导致攻击者犯错,从而提醒您他们的存在。攻击者逃离隔间所需的任何时间都是您的事件响应团队有机会做出反应的额外时间。
事件管理团队必须计划和实践封锁隔间以遏制入侵或不良行为的策略。关闭生产环境的一部分是一个戏剧性的举措。设计良好的隔间给事件管理团队提供了执行与事件成比例的操作的选项,因此他们不一定要将整个系统下线。
当您实现隔间化时,您面临着一个抉择:让所有客户共享给定服务的单个实例,或者运行支持单个客户或客户子集的单独服务实例。
例如,在同一硬件上运行由不同互不信任的实体控制的两个虚拟机(VM)存在一定风险:可能会暴露在虚拟化层的零日漏洞,或者存在微妙的跨 VM 信息泄漏。一些客户可能会选择通过基于物理硬件对其部署进行隔间化来消除这些风险。为了促进这种方法,许多云提供商提供基于每个客户专用硬件的部署。在这种情况下,减少资源利用的成本反映在定价溢价中。
隔间分离为系统增加了韧性,只要系统有机制来维持这种分离。困难的任务是跟踪这些机制并确保它们保持在位。为了防止退化,验证跨隔间边界禁止的操作失败是有价值的。方便的是,因为运营冗余依赖于隔间化(在“故障域和冗余”中介绍),您的验证机制可以涵盖被禁止和预期的操作。
谷歌通过角色、位置和时间进行隔间化。当攻击者试图破坏隔间化系统时,任何单次攻击的潜在范围都大大减少。如果系统受到攻击,事件管理团队可以选择仅禁用部分系统以清除受攻击的影响,同时保持其他部分运行。接下来的部分将详细探讨不同类型的隔间化。
角色分离
大多数现代微服务架构系统允许用户以特定的角色或服务账户运行作业。然后,这些作业将获得凭据,允许它们以特定角色在网络上进行身份验证。如果对手损害了一个作业,他们将能够在网络上冒充该作业对应的角色。因为这允许对手访问其他作业作为该角色可以访问的所有数据,这实际上意味着对手也损害了其他作业。
为了限制这种损害的影响范围,不同的作业通常应该以不同的角色运行。例如,如果您有两个需要访问两种不同类型数据(比如照片和文本聊天)的微服务,将这两个微服务作为不同的角色运行可以增加系统的弹性,即使这两个微服务由同一个团队开发和运行。
位置分离
位置分离有助于限制攻击者的影响的另一个维度:微服务运行的位置。例如,您可能希望防止已经物理损害了一个数据中心的对手能够读取所有其他数据中心的数据。同样,您可能希望您最有权力的管理用户的访问权限仅限于特定地区,以减轻内部风险。
实现位置分离的最明显方法是在不同位置(如数据中心或云区域,通常对应不同的物理位置)运行相同的微服务作为不同的角色。然后,您可以使用正常的访问控制机制来保护不同位置的相同服务实例,就像您会保护不同角色的不同服务一样。
位置分离有助于抵抗从一个位置转移到另一个位置的攻击。基于位置的加密隔间可以让您限制对特定位置的应用程序和其存储的数据的访问,从而限制本地攻击的影响范围。
物理位置是自然的隔间边界,因为许多不利事件与物理位置有关。例如,自然灾害局限于一个地区,其他局部事件如光纤切断、停电或火灾也是如此。需要攻击者在物理上出现的恶意攻击也局限于攻击者实际可以到达的位置,而除了最有能力的(例如国家级攻击者)可能没有能力同时派遣攻击者到多个位置。
同样,风险暴露的程度可能取决于物理位置的性质。例如,特定类型的自然灾害风险随地理区域而异。此外,入侵者尾随进入建筑并找到一个开放的网络端口插入的风险在员工和访客流量大的办公地点要高于对物理访问严格受控的数据中心。
有了这个想法,您在设计系统时需要考虑位置,以确保局部影响保持在该地区的系统中,同时让您的多区域基础设施继续运行。例如,重要的是要确保由几个地区的服务器提供的服务不会对单一数据中心中的后端产生关键依赖。同样,您需要确保一个位置的物理损害不会让攻击者轻易损害其他位置:尾随进入办公室并插入会议室的开放端口不应该让入侵者轻易获得对数据中心生产服务器的网络访问。
调整物理和逻辑架构
当将架构分隔为逻辑故障和安全域时,将相关的物理边界与逻辑边界对齐是有价值的。例如,将网络分割为网络级风险(如受恶意互联网流量影响的网络与受信任的内部网络)和物理攻击风险是有用的。理想情况下,您应该在不同的建筑物中为公司和生产环境之间进行网络隔离。此外,您可能会进一步将公司网络细分,以隔离访客流量较大的区域,如会议和会议区域。
在许多情况下,物理攻击,比如窃取或在服务器上植入后门,可能会使攻击者获得重要的机密、加密密钥或凭证,从而可能允许他们进一步渗透您的系统。考虑到这一点,将机密、密钥和凭证的分发在逻辑上隔离到物理服务器上是一个好主意,以最小化物理妥协的风险。
例如,如果您在几个物理数据中心位置运行 Web 服务器,将为每台服务器部署单独的证书或仅在一个位置的服务器之间共享证书,而不是在所有服务器上共享单个证书,这可能是有利的。这可以使您对一个数据中心的物理妥协做出更灵活的响应:您可以将其流量排空,仅撤销部署到该数据中心的证书,并将数据中心下线进行事件响应和恢复,同时从其余数据中心提供流量。如果您在所有服务器上部署了单个证书,您将不得不非常快速地替换所有证书——甚至那些实际上没有受到威胁的证书。
信任隔离
虽然服务可能需要跨位置边界进行通信以正常运行,但服务也可能希望拒绝来自其不希望通信的位置的请求。为了做到这一点,您可以默认限制通信,并只允许跨位置边界的预期通信。任何服务上的所有 API 都不太可能使用相同的位置限制集。用户面向的 API 通常是全球开放的,而控制平面 API 通常是受限的。这使得对允许位置的细粒度(每个 API 调用)控制成为必要。创建工具,使得任何给定服务能够测量、定义和强制执行对个别 API 的位置限制,使团队能够利用其对每个服务的知识来实现位置隔离。
限制基于位置的通信,每个身份都需要包含位置元数据。谷歌的作业控制系统对生产中的作业进行认证和运行。当系统认证一个作业在特定隔间运行时,它会用该隔间的位置元数据注释作业的证书。每个位置都有自己的作业控制系统,用于认证在该位置运行的作业,并且该位置的机器只接受该系统的作业。这旨在防止攻击者突破隔间边界并影响其他位置。与单一的集中管理机构相比,这种方法有所不同——如果谷歌只有一个作业控制系统,那么它的位置对攻击者来说将是非常有价值的。
一旦信任隔离就位,我们可以扩展存储数据的 ACL,以包括位置限制。这样,我们可以将存储位置(放置数据的地方)与访问位置(谁可以检索或修改数据)分开。这也打开了信任物理安全与信任 API 访问的可能性——有时,物理操作员的额外要求是值得的,因为它消除了远程攻击的可能性。
为了帮助控制隔间违规行为,谷歌在每个位置都设有一个信任根,并将受信任的根和它们代表的位置的列表分发给机群中的所有机器。这样,每台机器都可以检测跨位置的欺骗行为。我们还可以通过向所有机器分发更新后的列表来撤销某个位置的身份,宣布该位置不可信任。
基于位置的信任的局限性
在谷歌,我们选择设计我们的企业网络基础设施,使位置不意味着任何信任。相反,在我们的 BeyondCorp 基础设施的零信任网络范式下(参见第五章),工作站是基于颁发给个体机器的证书以及关于其配置的断言(如最新软件)而受信任的。将一个不受信任的机器插入办公楼网络端口将其分配到一个不受信任的访客 VLAN。只有经过授权的工作站(通过 802.1x 协议进行身份验证)才会被分配到适当的工作站 VLAN。
我们还选择不依赖物理位置来建立数据中心服务器的信任。一个激励性的经验来自于对数据中心环境的红队评估。在这次演习中,红队在机架顶部放置了一个无线设备,并迅速将其插入一个开放端口,以便从建筑外部进一步渗透数据中心的内部网络。当他们回来清理演习后,他们发现一个细心的数据中心技术人员已经整齐地用拉链扎紧了接入点的电缆——显然对不整洁的安装工作感到不满,并假设该设备一定是合法的。这个故事说明了基于物理位置归因信任的困难,即使在一个物理安全的区域内也是如此。
在谷歌的生产环境中,类似于 BeyondCorp 设计,生产服务之间的身份验证是基于每台机器凭据的机器间信任。未经授权设备上的恶意植入物将不会受到谷歌生产环境的信任。
保密隔离
一旦我们有了一个隔离信任的系统,我们需要隔离我们的加密密钥,以确保通过一个位置的加密根保护的数据不会因为在另一个位置泄露加密密钥而受损。例如,如果公司的一个分支遭到攻击,攻击者不应该能够从公司的其他分支读取数据。
谷歌拥有保护密钥树的基本加密密钥。这些密钥最终通过密钥封装和密钥派生来保护静态数据。
为了将加密和密钥封装隔离到一个位置,我们需要确保该位置的根密钥只能被正确的位置访问。这需要一个分发系统,只将根密钥放置在正确的位置。密钥访问系统应该利用信任隔离,确保这些密钥不能被不在适当位置的实体访问。
使用这些原则,给定位置允许在本地密钥上使用 ACLs,以防止远程攻击者解密数据。即使攻击者可以访问加密数据(通过内部妥协或外泄),也可以防止解密。
从全局密钥树过渡到本地密钥树应该是逐渐的。虽然树的任何部分可以独立地从全局转移到本地,但在所有上面的密钥都转移到本地密钥之前,对于给定的叶子或分支,隔离并不完整。
时间分离
最后,限制对手随时间的能力是有用的。在这里要考虑的最常见情况是,对手已经破坏了系统并窃取了密钥或凭证。如果您随时间旋转您的密钥和凭证,并使旧的失效,对手必须保持他们的存在以重新获取新的秘密,这给了您更多的机会来检测窃取。即使您从未检测到窃取,旋转仍然至关重要,因为您可能会在正常的安全卫生工作中关闭对手用来获取密钥或凭证的途径(例如,通过修补漏洞)。
正如我们在第九章中讨论的那样,可靠地进行密钥和凭证旋转和失效需要仔细权衡。例如,如果存在阻止在旧凭证失效之前将其旋转到新凭证的故障,那么基于壁钟的凭证失效可能会有问题。提供有用的时间分隔需要在旋转频率与旋转机制失败时的停机风险或数据丢失风险之间进行平衡。
深入探讨:故障域和冗余
到目前为止,我们已经讨论了如何设计系统以响应攻击并通过隔离来包含攻击后果。为了解决系统组件的完全故障,系统设计必须包含冗余和不同的故障域。这些策略可以希望限制故障的影响并避免完全崩溃。减轻关键组件的故障尤为重要,因为任何依赖于失败的关键组件的系统也面临完全失败的风险。
与其旨在始终防止所有故障,不如通过结合以下方法为您的组织创建一个平衡的解决方案:
-
将系统分解为独立的故障域。
-
旨在降低单一根本原因影响多个故障域中元素的概率。
-
创建可以替代失败部分的冗余资源、组件或程序。
故障域
故障域是一种爆炸半径控制。与按角色、位置或时间进行结构分离不同,故障域通过将系统分区为多个等效但完全独立的副本来实现功能隔离。
功能隔离
对其客户端来说,故障域看起来像一个单一的系统。必要时,任何单个分区都可以在停机期间接管整个系统。因为分区只有系统资源的一部分,它只能支持系统容量的一部分。与管理角色、位置和时间分离不同,操作故障域并保持其隔离需要持续的努力。作为交换,故障域增加了系统的弹性,其他爆炸半径控制无法做到。
故障域有助于保护系统免受全局影响,因为单个事件通常不会同时影响所有故障域。然而,在极端情况下,重大事件可能会破坏多个,甚至所有故障域。例如,您可以将存储阵列的基础设备(HDD 或 SSD)视为故障域。尽管任何一个设备可能会失败,但整个存储系统仍然正常运行,因为它在其他地方创建了一个新的数据副本。如果大量存储设备失败,并且没有足够的备用设备来维护数据副本,进一步的故障可能导致存储系统中的数据丢失。
数据隔离
您需要为数据源或单个故障域内可能存在错误数据的可能性做好准备。因此,每个故障域实例都需要其自己的数据副本,以便在功能上独立于其他故障域。我们建议采取双重方法来实现数据隔离。
首先,您可以限制数据更新进入故障域的方式。系统只有在通过了所有典型和安全更改的验证检查后才接受新数据。一些异常情况需要进行理由说明,并且可以通过紧急机制¹⁰允许新数据进入故障域。因此,您更有可能防止攻击者或软件错误造成破坏性的更改。
例如,考虑 ACL 更改。人为错误或 ACL 生成软件中的错误可能会产生一个空的 ACL,这可能导致拒绝所有人的访问。¹¹这样的 ACL 更改可能导致系统故障。同样,攻击者可能会尝试通过向 ACL 添加“允许所有”条款来扩大其影响范围。
在谷歌,个别服务通常具有用于接收新数据和信令的 RPC 端点。编程框架,如第十二章中介绍的那些,包括用于对数据快照进行版本控制和评估其有效性的 API。客户端应用程序可以利用编程框架的逻辑来确定新数据是否安全。集中式数据推送服务实现数据更新的质量控制。数据推送服务检查数据的获取位置、打包方式以及何时推送打包的数据。为了防止自动化导致广泛的故障,谷歌使用每个应用程序的配额来限制全局更改的速度。我们禁止同时更改多个应用程序或在一段时间内过快地更改应用程序容量的操作。
其次,使系统能够将最后已知的良好配置写入磁盘,使系统能够抵御失去对配置 API 的访问:它们可以使用保存的配置。谷歌的许多系统在有限的时间内保留旧数据,以防最新数据因任何原因而损坏。这是深度防御的另一个例子,有助于提供长期的弹性。
实际方面
即使将系统分割成只有两个故障域也会带来实质性的好处:
-
拥有两个故障域提供了 A/B 回归的能力,并将系统更改的影响范围限制在单个故障域内。为了实现这种功能,使用一个故障域作为金丝雀,并制定一个政策,不允许同时更新两个故障域。
-
地理上分离的故障域可以为自然灾害提供隔离。
-
您可以在不同的故障域中使用不同的软件版本,从而减少单个错误破坏所有服务器或损坏所有数据的机会。
将数据和功能隔离相结合可以增强整体的弹性和事件管理。这种方法限制了未经理由接受的数据更改的风险。当问题出现时,隔离会延迟其传播到个别的功能单元。这给其他防御机制更多的时间来检测和反应,这在繁忙和时间紧迫的事件响应过程中尤为有益。通过并行地将多个候选修复方案推送到不同的故障域中,您可以独立地评估哪些修复方案产生了预期的效果。这样,您就可以避免意外地全局推送一个匆忙的更新,进一步降低整个系统的稳定性。
故障域会产生运营成本。即使是一个简单的服务,也需要您维护由故障域标识符键入的多个服务配置的副本。这需要以下工作:
-
确保配置的一致性
-
保护所有配置免受同时损坏
-
隐藏故障域的分离,以防止客户系统意外地耦合到特定的故障域
-
潜在地分区所有的依赖关系,因为一个共享的依赖关系变化可能会意外地传播到所有的故障域
值得注意的是,如果故障域的任何一个关键组件发生故障,故障域可能会遭受完全故障。毕竟,您最初将原始系统划分为故障域,以便在故障域的副本完全失败时系统仍然可以保持运行。然而,故障域只是将问题向下移动了一个级别。接下来的部分将讨论如何使用替代组件来减轻所有故障域完全失败的风险。
组件类型
故障域的韧性质量表现为其组件和它们的依赖关系的综合可靠性。整个系统的韧性随着故障域的数量增加而增加。然而,这种增加的韧性被维护更多故障域的操作开销所抵消。
通过减缓或停止新功能开发,您可以进一步提高韧性,以换取更稳定性。如果您避免添加新的依赖关系,您也将避免其潜在的故障模式。如果停止更新代码,新错误的速率会减少。然而,即使停止所有新功能的开发,您仍然需要对状态的偶发变化做出反应,比如安全漏洞和用户需求的增加。
显然,停止所有新功能的开发对大多数组织来说并不是一种可行的策略。在接下来的章节中,我们将介绍一系列替代方法来平衡可靠性和价值。一般来说,服务的可靠性有三种广泛的类别:高容量、高可用和低依赖。
高容量组件
您在日常业务中构建和运行的组件构成了您的高容量服务。这是因为这些组件构成了为用户提供服务的主要车队。这是您的服务吸收用户请求或由于新功能而导致的资源消耗激增的地方。高容量组件还吸收 DoS 流量,直到 DoS 缓解生效或优雅降级生效。
因为这些组件对于您的服务非常重要,您应该首先在这里集中精力,例如,遵循容量规划、软件和配置部署的最佳实践,如SRE 书的第三部分和SRE 工作手册的第二部分所涵盖的内容。
高可用组件
如果您的系统有组件的故障会影响所有用户,或者具有重大广泛影响的其他故障后果——在前一节中讨论的高容量组件——您可以通过部署这些组件的副本来减轻这些风险。如果这些组件的副本提供了更低的故障概率,那么这些组件的副本就是高可用的。
为了降低故障概率,这些副本应该配置更少的依赖关系和有限的变更速率。这种方法减少了基础设施故障或操作错误破坏组件的机会。例如,您可以做以下事情:
-
使用本地存储中缓存的数据,避免依赖远程数据库。
-
使用旧代码和配置,避免新版本中的最近错误。
运行高可用组件几乎没有操作开销,但需要额外的资源,其成本与车队规模成比例。确定高可用组件是否应该支撑整个用户群或仅支撑部分用户群是一个成本/效益决策。在每个高容量和高可用组件之间以相同的方式配置优雅降级功能。这使您可以用更积极的降级来交换更少的资源。
低依赖组件
如果高可用性组件的故障是不可接受的,低依赖性服务是下一个弹性级别。低依赖性需要具有最小依赖关系的替代实现。这些最小依赖关系也是低依赖性的。可能失败的服务、进程或作业的总集合与业务需求和成本相匹配。高容量和高可用性的服务可以为大型用户群提供服务并提供丰富的功能,因为它们具有多层合作平台(虚拟化、容器化、调度、应用框架)。虽然这些层通过允许服务快速添加或移动节点来帮助扩展,但它们也会导致合作平台的错误预算累积率更高。相比之下,低依赖性服务必须简化其服务堆栈,直到能够接受堆栈的总体错误预算。反过来,简化服务堆栈可能导致必须删除功能。
低依赖性组件要求您确定是否可能为关键组件构建替代方案,其中关键组件和替代组件不共享任何故障域。毕竟,冗余的成功与相同根本原因影响两个组件的概率成反比。
将存储空间视为分布式系统的基本构建块——当数据存储的 RPC 后端不可用时,您可能希望存储本地数据副本作为备用。然而,通常存储本地数据副本的一般方法并不总是切实可行。支持冗余组件的运营成本增加,而额外组件提供的好处通常为零。
实际上,您最终会得到一组低依赖性组件,用户、功能和成本有限,但可以自信地用于临时负载或恢复。虽然大多数有用的功能通常依赖于多个依赖项,但严重受损的服务总比不可用的服务好。
举个小例子,想象一台设备,假定可以通过网络进行只写或只读操作。在家庭安全系统中,这些操作包括记录事件日志(只写)和查找紧急电话号码(只读)。入侵者的入侵计划包括禁用家庭的互联网连接,从而破坏安全系统。为了对抗这种类型的故障,您配置安全系统还使用一个实现与远程服务相同的 API 的本地服务器。本地服务器将事件日志写入本地存储,更新远程服务,并重试失败的尝试。本地服务器还会响应紧急电话号码查找请求。电话号码列表会定期从远程服务刷新。从家庭安全控制台的角度来看,系统正在按预期工作,记录日志并访问紧急号码。此外,一个低依赖性的隐藏座机可能作为备用提供拨号功能,以应对禁用的无线连接。
作为业务规模的例子,全球网络故障是最可怕的故障类型之一,因为它影响了服务功能和响应者修复故障的能力。大型网络是动态管理的,更容易发生全球性故障。构建一个完全避免重复使用主网络中相同网络元素的备用网络-链接、交换机、路由器、路由域或SDN软件-需要仔细设计。这种设计必须针对特定和狭窄的用例和操作参数,使您能够专注于简单和可理解性。为这种很少使用的网络追求最小的资本支出也自然地导致限制可用功能和带宽。尽管存在限制,结果是足够的。目标是仅支持最关键的功能,并且仅为通常带宽的一小部分。
控制冗余
冗余系统配置为每个依赖项都有多个选项。管理这些选项之间的选择并不总是直截了当的,攻击者可能会潜在地利用冗余系统之间的差异-例如,通过将系统推向较不安全的选项。请记住,弹性设计实现了安全性和可靠性,而不是牺牲其中一个。如果有的话,当低依赖性的替代方案具有更强的安全性时,这可以作为攻击者考虑削弱您的系统的一种不利因素。
故障转移策略
通过负载平衡技术通常提供一组后端,可以在后端故障时增加弹性。例如,依赖单个 RPC 后端是不切实际的。每当该后端需要重新启动时,系统都会挂起。为简单起见,系统通常将冗余后端视为可互换,只要所有后端提供相同的功能行为。
需要不同可靠性行为的系统(对于相同的功能行为集)应依赖于提供所需可靠性行为的一组可互换的后端。系统本身必须实现逻辑来确定使用哪组行为以及何时使用它们-例如,通过标志。这使您完全控制系统的可靠性,特别是在恢复期间。将此方法与从相同的高可用性后端请求低依赖性行为进行对比。使用 RPC 参数,您可以阻止后端尝试联系其不可用的运行时依赖项。如果运行时依赖项也是启动依赖项,则您的系统仍然离灾难只有一次进程重启。
何时转移到具有更好稳定性的组件取决于特定情况。如果自动故障转移是目标,您应该通过使用“控制退化”中涵盖的方法来解决可用容量的差异。故障转移后,这样的系统会切换到使用针对备用组件调整的限流和负载放弃策略。如果您希望系统在失败的组件恢复后进行故障返回,请提供一种禁用故障返回的方法-在某些情况下,您可能需要稳定波动或精确控制故障转移。
常见陷阱
我们观察到一些常见的操作备用组件的常见陷阱,无论它们是高可用性还是低依赖性。
例如,随着时间的推移,您可能会开始依赖备用组件进行正常操作。任何开始将备用系统视为备份的依赖系统在故障期间可能会过载它们,使备用系统成为拒绝服务的意外原因。相反的问题是备用组件通常不会被常规使用,导致腐烂和意外故障每当它们需要时。
另一个陷阱是对其他服务或所需计算资源的依赖未经检查地增长。随着用户需求的变化和开发人员添加功能,系统往往会发展。随着时间的推移,依赖关系和依赖方增加,系统可能使用资源的效率降低。高可用副本可能落后于高容量舰队,或者低依赖服务可能在其预期的操作约束条件未经持续监控和验证时失去一致性和可重现性。
重要的是,备用组件的故障转移不会损害系统的完整性或安全性。考虑以下情景,正确的选择取决于您组织的情况:
-
出于安全原因(防御最近的漏洞),您的高可用服务运行了六周前的代码。然而,同一服务需要紧急安全修复。您会选择哪种风险:不应用修复,还是可能通过修复破坏代码?
-
一个远程密钥服务的启动依赖于获取解密数据的私钥,可以通过将私钥存储在本地存储中来降低依赖性。这种方法是否会给这些密钥带来无法接受的风险,或者增加密钥轮换频率是否足以抵消这种风险?
-
您确定可以通过减少不经常更改的数据(例如 ACL、证书吊销列表或用户元数据)的更新频率来释放资源。即使这样做可能会给攻击者更多时间进行更改或使更改未被检测到更长时间,这样做是否值得?
最后,您需要确保系统不会在错误的时间自动恢复。如果弹性措施自动限制了系统的性能,那么这些措施自动解除限制是可以的。然而,如果您应用了手动故障转移,请不要允许自动化覆盖故障转移——因为受到安全漏洞的影响,被排除的系统可能被隔离,或者您的团队可能正在减轻级联故障。
深入探讨:持续验证
从可靠性和安全性的角度来看,我们希望确保我们的系统在正常和意外情况下都能如预期般运行。我们还希望确保新功能或错误修复不会逐渐削弱系统的分层弹性机制。实际运行系统并验证其按预期工作是无法替代的。
验证侧重于观察系统在真实但受控的情况下,针对单个系统或跨多个系统的工作流程。与混沌工程不同,后者是探索性质的,验证确认了本章和第 5、6 和 9 章中涵盖的特定系统属性和行为。定期进行验证可以确保结果仍然符合预期,并且验证实践本身保持正常运行。
在使验证有意义方面有一些技巧。首先,您可以使用第十五章中涵盖的一些概念和实践,例如如何选择要验证的内容,以及如何衡量有效的系统属性。然后,您可以逐渐扩展验证范围,创建、更新或删除检查。您还可以从实际事件中提取有用的细节——这些细节是系统行为的最终真相,并经常突出了需要的设计更改或验证范围的空白。最后,重要的是要记住,随着业务因素的变化,个别服务往往也会发展和变化,可能导致不兼容的 API 或意想不到的依赖关系。
一般的验证维护策略包括以下内容:
-
发现新的故障
-
为每个故障实现验证器
-
反复执行所有验证器
-
当相关功能或行为不再存在时淘汰验证器
要发现相关故障,请依赖以下来源:
-
用户和员工的定期错误报告
-
模糊测试和类似模糊测试的方法(在第十三章中描述)
-
故障注入方法(类似于混沌猴工具)
-
操作您系统的主题专家的分析判断。
构建自动化框架可以帮助您安排不兼容的检查在不同时间运行,以避免它们之间的冲突。您还应该监视并定期审计自动化,以捕捉破损或受损的行为。
验证重点领域
验证整个系统以及其服务之间的端到端协作是有益的。但是,由于验证为真实用户提供服务的整个系统的故障响应是昂贵且风险的,因此您必须做出妥协。验证较小的系统副本通常更为经济实惠,并且仍然提供了通过验证单独的系统组件无法获得的见解。例如,您可以执行以下操作:
-
告诉调用者如何应对响应缓慢或变得无法访问的 RPC 后端。
-
查看资源短缺时会发生什么,以及在资源消耗激增时是否可获取紧急资源配额。
另一个实用的解决方案是依靠日志来分析系统和/或其组件之间的交互。如果您的系统实现了分隔,那么试图跨越角色、位置或时间分隔的操作应该失败。如果您的日志记录了意外的成功,那么这些成功应该被标记。日志分析应始终处于活动状态,让您在验证过程中观察实际的系统行为。
您应该验证安全设计原则的属性:最小特权、可理解性、适应性和恢复能力。验证恢复尤为关键,因为恢复工作必然涉及人类行为。人类是不可预测的,单元测试无法检查人类的技能和习惯。在验证恢复设计时,您应该审查恢复说明的可读性以及不同恢复工作流程的效力和互操作性。
验证安全属性意味着不仅要确保系统正确响应,还要检查代码或配置是否存在已知的漏洞。对部署系统进行主动渗透测试可以黑盒视角地查看系统的弹性,通常会突出开发人员未考虑的攻击向量。
与低依赖组件的交互值得特别关注。根据定义,这些组件部署在最关键的情况下。除了这些组件之外没有后备。幸运的是,设计良好的系统应该具有有限数量的低依赖组件,这使得为所有关键功能和交互定义验证器的目标成为可能。只有在需要时这些低依赖组件才能发挥作用。您的恢复计划通常应依赖于低依赖组件,并且您应该验证人类在系统降级到该级别时的使用情况。
实践中的验证
本节介绍了谷歌用于展示持续验证方法的几种验证场景。
注入预期的行为变化
您可以通过向服务器注入行为变化来验证系统对负载分担和限流的响应,然后观察所有受影响的客户端和后端是否适当地响应。
例如,Google 实现了服务器库和控制 API,允许我们向任何 RPC 服务器添加任意延迟或故障。我们在定期的灾难准备演习中使用这些功能,团队可以随时轻松地进行实验。使用这种方法,我们研究隔离的 RPC 方法、整个组件或更大的系统,并专门寻找级联故障的迹象。从延迟的小幅增加开始,我们构建一个阶跃函数,以模拟完全的故障。监控图表清楚地反映了响应延迟的变化,就像在真正的问题中一样,在阶跃点。将这些时间轴与客户端和后端服务器的监控信号相关联,我们可以观察效果的传播。如果错误率与我们在早期步骤中观察到的模式不成比例地飙升,我们就知道要退后一步,暂停,并调查行为是否出乎意料。
快速而安全地取消注入行为的可靠机制非常重要。如果发生故障,即使原因似乎与验证无关,正确的决定是首先中止实验,然后评估何时可以安全地再次尝试。
将紧急组件作为正常工作流程的一部分
当我们观察系统执行其预期功能时,我们可以确信低依赖或高可用系统正在正确运行并准备投入生产。为了测试准备就绪,我们将真实流量的一小部分或真实用户的一小部分推送到我们正在验证的系统。
高可用系统(有时是低依赖系统)通过镜像请求进行验证:客户端发送两个相同的请求,一个发送到高容量组件,另一个发送到高可用组件。通过修改客户端代码或注入一个可以将一个输入流量复制成两个等效输出流的服务器,您可以比较响应并报告差异。当响应差异超出预期水平时,监控服务会发送警报。一些差异是可以预期的;例如,如果备用系统具有较旧的数据或功能。因此,客户端应该使用高容量系统的响应,除非发生错误或客户端明确配置为忽略该系统——这两种情况都可能在紧急情况下发生。镜像请求不仅需要在客户端进行代码更改,还需要能够自定义镜像行为。因此,这种策略更容易部署在前端或后端服务器上,而不是在最终用户设备上。
低依赖系统(有时是高可用系统)更适合通过真实用户而不是请求镜像进行验证。这是因为低依赖系统在功能、协议和系统容量方面与其更不可靠的对应系统有很大不同。在 Google,值班工程师将低依赖系统作为值班职责的一个重要部分。我们之所以使用这种策略,有几个原因:
-
许多工程师参与值班轮班,但一次只有少部分工程师值班。这自然限制了参与验证的人员范围。
-
当工程师值班时,他们可能需要依赖紧急路径。熟练使用低依赖系统可以减少值班工程师在真正紧急情况下切换到使用这些系统所需的时间,并避免意外的配置错误风险。
逐步将值班工程师转换为仅使用低依赖系统可以逐步实现,并且可以通过不同的方式实现,具体取决于每个系统的业务关键性。
当无法镜像流量时进行分割
作为请求镜像的替代方案,您可以将请求分割到不相交的服务器集之间。如果请求镜像不可行,例如当您无法控制客户端代码,但在请求路由级别进行负载均衡是可行的。因此,只有在替代组件使用相同的协议时,请求分割才有效,这在高容量和高可用性版本的组件中经常发生。
这种策略的另一个应用是将流量分布到一组故障域中。如果您的负载均衡针对单个故障域,您可以针对该域运行集中的实验。由于故障域的容量较低,攻击它并引发弹性响应需要更少的负载。您可以通过比较其他故障域的监控信号来量化实验的影响。通过增加负载放置和限流,您可以进一步提高实验的输出质量。
超额预订但防止自满
分配给客户但未使用的配额是资源的浪费。因此,为了最大限度地利用资源,许多服务通过一定合理的边际进行资源超额预订。资源的边际调用可能随时发生。弹性系统跟踪优先级,以便释放较低优先级的资源以满足对较高优先级资源的需求。但是,您应该验证系统是否能够可靠地释放这些资源,并且在可接受的时间内释放这些资源。
谷歌曾经有一个需要大量磁盘空间进行批处理的服务。用户服务优先于批处理,并为使用高峰分配了大量磁盘保留空间。我们允许批处理服务利用用户服务未使用的磁盘,但有一个特定条件:特定集群中的任何磁盘必须在X小时内完全释放。我们开发的验证策略包括定期将批处理服务从集群中移出,测量移动所需的时间,并在每次尝试中修复发现的任何新问题。这不是模拟。我们的验证确保承诺X小时 SLO 的工程师既有真实的证据又有真实的经验。
这些验证成本高,但大部分成本都由自动化吸收。负载均衡将成本限制在管理资源在源和目标位置的配置上。如果资源配置大部分是自动化的,例如云服务的情况,那么只需要运行脚本或 playbook 来执行一系列请求即可。
对于较小的服务或公司,定期执行再平衡的策略同样适用。对应用负载变化做出可预测响应的信心是可以为全球用户基础提供服务的软件架构的基础之一。
测量关键旋转周期
关键旋转在理论上很简单,但在实践中可能会带来令人不快的惊喜,包括完全的服务中断。在验证关键旋转是否有效时,您应该寻找至少两个不同的结果:
关键旋转延迟
完成单个旋转周期所需的时间
验证失去访问权限
确保旧密钥在旋转后完全无用
我们建议定期旋转密钥,以便它们保持随时准备好应对由安全威胁引发的不可协商的紧急密钥旋转。这意味着即使不必旋转密钥,也要进行旋转。如果旋转过程成本高,可以寻找降低成本的方法。
在谷歌,我们已经经历了测量关键旋转延迟对多个目标有所帮助:
-
您可以了解使用该密钥的每个服务是否能够更新其配置。也许某个服务并不是为密钥旋转而设计的,或者虽然设计了但从未经过测试,或者更改破坏了以前的工作。
-
您可以了解每项服务旋转密钥所需的时间。密钥旋转可能只是一个文件更改和服务器重启,也可能是逐步在所有世界地区推出。
-
您会发现其他系统动态如何延迟密钥旋转过程。
测量密钥旋转延迟有助于我们形成对整个周期的现实预期,无论是在正常情况下还是在紧急情况下。考虑可能由密钥旋转或其他事件引起的回滚,服务超出错误预算的更改冻结,以及由于故障域而产生的序列化推出。
如何验证通过旧密钥丧失访问的可能情况特定。很难证明旧密钥的所有实例都被销毁,因此理想情况下,您可以证明尝试使用旧密钥失败,之后您可以销毁旧密钥。当这种方法不切实际时,您可以依赖密钥拒绝列表机制(例如 CRL)。如果您有一个中央证书颁发机构和良好的监控,您可能能够在任何 ACL 列出旧密钥的指纹或序列号时创建警报。
实用建议:从何处开始
设计弹性系统并不是一项微不足道的任务。这需要时间和精力,并且会转移其他有价值的工作。您需要根据您想要的弹性程度仔细考虑权衡,然后从我们描述的广泛选项中选择——适合您需求的少数或多数解决方案。
按成本顺序:
-
故障域和冲击半径控制具有较低的成本,因为它们的相对静态性质,但提供了显著的改进。
-
高可用性服务是成本效益的下一个解决方案。
考虑接下来的这些选项:
-
如果您的组织规模或风险规避需要投资于弹性的主动自动化,考虑部署负载分担和限流能力。
-
评估您的防御措施对抗 DoS 攻击的有效性(参见第十章)。
-
如果构建低依赖解决方案,请引入一个过程或机制,以确保它随着时间的推移保持低依赖性。
克服对投资于弹性改进的抵制可能很困难,因为好处表现为问题的缺失。以下论点可能有所帮助:
-
部署故障域和冲击半径控制将对未来系统产生持久影响。隔离技术可以鼓励或强制执行操作故障域的良好分离。一旦建立,它们将不可避免地使设计和部署不必要耦合或脆弱的系统变得更加困难。
-
定期更改和旋转密钥的技术和练习不仅确保了安全事件的准备,还为您提供了一般的加密灵活性,例如,知道您可以升级加密原语。
-
部署高可用性服务实例的相对较低额外成本提供了一种廉价的方法,可以检查您可能能够提高服务可用性的程度。放弃也很便宜。
-
负载分担和限流能力以及“控制退化”中涵盖的其他方法,减少了公司需要维护的资源成本。由此产生的用户可见改进通常适用于最受重视的产品特性。
-
控制退化对于在防御 DoS 攻击时的第一反应的速度和有效性至关重要。
-
低依赖解决方案相对昂贵,但在实践中很少被使用。要确定它们是否值得成本,可以帮助了解启动业务关键服务的所有依赖项需要多长时间。然后可以比较成本,并得出是否最好将时间投资在其他地方的结论。
无论您组合了什么样的弹性解决方案,都要寻找经济实惠的方式来持续验证它们,并避免削减成本,从而影响它们的有效性。投资于验证的好处在于,长期来看,可以锁定所有其他弹性投资的复合价值。如果您自动化这些技术,工程和支持团队可以专注于提供新的价值。自动化和监控的成本理想情况下将分摊到公司正在追求的其他努力和产品中。
您可能会定期耗尽可以投入弹性的金钱或时间。下一次有机会花更多这些有限资源时,首先考虑简化已部署的弹性机制的成本。一旦您对它们的质量和效率有信心,再尝试更多的弹性选项。
结论
在本章中,我们讨论了从设计阶段开始将弹性构建到系统的安全性和可靠性中的各种方法。为了提供弹性,人类需要做出选择。我们可以通过自动化优化一些选择,但对于其他选择,我们仍然需要人类。
可靠性属性的弹性有助于保持系统最重要的功能,使系统在负载过重或大规模故障的情况下不会完全崩溃。如果系统出现故障,此功能将延长响应者组织、防止更多损害或必要时进行手动恢复的时间。弹性有助于系统抵御攻击,并防御长期访问的企图。如果攻击者侵入系统,设计功能如爆炸半径控制将限制损害。
将设计策略基于深度防御。以与可用性和可靠性相同的方式检查系统的安全性。在本质上,深度防御就像您的防御的N+1 冗余。您不会把所有的网络容量都信任一个路由器或交换机,那么为什么要信任一个防火墙或其他防御措施呢?在设计深度防御时,始终假设并检查不同安全层的故障:外围安全的故障,端点的妥协,内部人员的攻击等。计划进行横向移动,以阻止它们的意图。
即使您设计系统具有弹性,也有可能在某个时刻弹性不足,系统会崩溃。下一章将讨论发生这种情况后会发生什么:如何恢复崩溃的系统,以及如何最小化崩溃造成的损害?
¹ 受保护的沙箱为不受信任的代码和数据提供了隔离的环境。
² 谷歌运行漏洞赏金奖励计划。
³ 请参阅 Singh, Soram Ranbir, Ajoy Kumar Khan, and Soram Rakesh Singh. 2016. “Performance Evaluation of RSA and Elliptic Curve Cryptography.” Proceedings of the 2nd International Conference on Contemporary Computing and Informatics: 302–306. doi:10.1109/IC3I.2016.7917979。
⁴ 这在《SRE 书》的第二十章中有描述。
⁵ 请参阅《SRE 书》第二十一章。
⁶ “开放式失败”和“关闭式失败”的概念指的是服务保持运行(可靠)或关闭(安全),分别。术语“开放式失败”和“关闭式失败”通常与“故障安全”和“故障安全”互换使用,如第一章所述。
⁷ 有关 Google 生产环境的描述,请参阅SRE 书籍第二章。
⁸ 通常,该服务的实例仍然由基础服务器的许多副本提供,但它将作为单个逻辑隔间运行。
⁹ 例如,Google Cloud Platform 提供所谓的独占租户节点。
¹⁰ 突发情况处理机制是一种可以绕过策略以允许工程师快速解决故障的机制。请参阅“突发情况处理”。
¹¹ 使用 ACL 的系统必须失败关闭(安全),只有 ACL 条目明确授予访问权限。
¹² 请参阅SRE 书籍第三章。
¹³ 这与单元测试、集成测试和负载测试不同,这些内容在第十三章中有介绍。
¹⁴ 这类似于 Unix 命令tee对stdin的操作。
第九章:面向恢复的设计
原文:9. Design for Recovery
译者:飞龙
协议:CC BY-NC-SA 4.0
由 Aaron Joyner,Jon McCune 和 Vitaliy Shipitsyn
与 Constantinos Neophytou,Jessie Yang 和 Kristina Bennett
现代分布式系统面临许多类型的故障,这些故障是由无意错误和蓄意恶意行为造成的。当暴露于不断累积的错误、罕见的故障模式或攻击者的恶意行为时,人类必须介入,以恢复甚至最安全和最有弹性的系统。
将失败或受损的系统恢复到稳定和安全状态可能会以意想不到的方式变得复杂。例如,回滚一个不稳定的发布版本可能会重新引入安全漏洞。推出新版本以修补安全漏洞可能会引入可靠性问题。这些风险性的缓解措施充满了更微妙的权衡。例如,在决定多快部署更改时,快速推出更有可能赢得与攻击者的竞赛,但也限制了您能够对其进行的测试量。您可能最终会广泛部署具有关键稳定性错误的新代码。
在紧张的安全或可靠性事件中开始考虑这些微妙之处以及您的系统缺乏处理它们的准备是远非理想的。只有有意识的设计决策才能使您的系统具备所需的可靠性和灵活性,以本能地支持各种恢复需求。本章涵盖了一些我们发现在准备我们的系统以促进恢复工作方面非常有效的设计原则。这些原则中的许多原则适用于各种规模,从全球范围的系统到单个机器内的固件环境。
我们正在从什么中恢复?
在我们深入探讨促进恢复的设计策略之前,我们将介绍一些导致系统需要恢复的情景。这些情景可以分为几个基本类别:随机错误、意外错误、恶意行为和软件错误。
随机错误
所有分布式系统都是由物理硬件构建的,所有物理硬件都会出现故障。物理设备的不可靠性以及它们运行的不可预测的物理环境导致了随机错误。随着支持系统的物理硬件数量的增加,分布式系统遭遇随机错误的可能性也增加。老化的硬件也会导致更多的错误。
一些随机错误比其他错误更容易恢复。系统的某个部分的完全故障或隔离,例如电源供应或关键网络路由器,是最简单的故障处理之一。[1]解决由意外位翻转引起的短暂损坏,或者由多核 CPU 中一个核上的故障指令引起的长期损坏则更为复杂。当这些错误悄无声息地发生时,它们尤其阴险。
系统外的基本不可预测事件也可能在现代数字系统中引入随机错误。龙卷风或地震可能会导致您突然永久地失去系统的特定部分。发电站或变电站故障或 UPS 或电池异常可能会影响向一个或多个机器提供电力。这可能会引入电压下降或波动,导致内存损坏或其他瞬态错误。
意外错误
所有分布式系统都是由人类直接或间接操作的,而所有人类都会犯错误。我们将意外错误定义为由怀着良好意图的人类造成的错误。人为错误率根据任务类型而异。粗略地说,任务复杂度增加,错误率也会增加。[3]
人类可能在系统的任何部分出现错误,因此你需要考虑人为错误如何在系统工具、系统和作业流程的整个堆栈中发生。意外错误也可能以系统外的随机方式影响你的系统,例如,如果用于无关施工的挖掘机切断了光纤电缆。
软件错误
迄今为止,我们已经讨论过的错误类型可以通过设计更改和/或软件来解决。用一个经典的引用和其推论来解释,所有的错误都可以通过软件来解决……除了软件中的错误。软件错误实际上只是意外错误的一个特殊延迟案例:在软件开发过程中发生的错误。你的代码会有 bug,你需要修复这些 bug。一些基本且广泛讨论的设计原则,例如模块化软件设计、测试、代码审查以及验证依赖 API 的输入和输出,可以帮助你解决 bug。第六章和第十二章更深入地讨论了这些主题。
在某些情况下,软件 bug 会模仿其他类型的错误。例如,缺乏安全检查的自动化可能会对生产进行突然而剧烈的更改,模仿恶意行为者。软件错误也会放大其他类型的错误,例如,传感器错误返回意外值,软件无法正确处理,或者在用户正常工作过程中绕过故障机制时出现的意外行为,看起来像是恶意攻击。
恶意行为
人类也可能故意对抗你的系统。这些人可能是有特权和高度了解的内部人员,有意为之。恶意行为者指的是一整类人积极地试图颠覆你的系统安全控制和可靠性,或者可能试图模仿随机、意外或其他类型的错误。自动化可以减少但无法消除对人类参与的需求。随着你的分布式系统规模和复杂性的增加,维护它的组织规模也必须与系统规模相适应(理想情况下,以次线性方式)。与此同时,组织中的人员违反你对他们的信任的可能性也在增加。
这些信任的违反可能来自滥用其对系统的合法权威,读取与其工作无关的用户数据,泄露或暴露公司机密,甚至积极致使系统长时间宕机的内部人员。这个人可能会短暂地做出错误的决定,有真正的恶意,成为社会工程攻击的受害者,甚至被外部行为者胁迫。
系统的第三方妥协也可能引入恶意错误。第二章深入介绍了恶意行为者的范围。在系统设计方面,无论恶意行为者是内部人员还是第三方攻击者,都采取相同的缓解策略。
恢复的设计原则
以下部分提供了一些基于我们多年分布式系统经验的恢复设计原则。这个列表并不是详尽无遗的,我们将提供进一步阅读的建议。这些原则也适用于各种组织,不仅仅是谷歌规模的组织。总的来说,在设计恢复时,重要的是要对可能出现的问题的广度和多样性持开放态度。换句话说,不要花时间担心如何对错误的微妙边缘情况进行分类;专注于准备从中恢复。
尽快进行设计(受策略保护)
在妥协或系统故障期间,有很大的压力要尽快恢复系统到预期的工作状态。然而,你用来快速更改系统的机制本身可能会冒着太快做出错误更改的风险,加剧问题。同样,如果你的系统被恶意入侵,过早的恢复或清理行动可能会引发其他问题,例如,你的行动可能会让对手知道他们已经被发现。我们发现在设计支持可变恢复速率的系统时,平衡涉及的权衡的一些方法是有效的。
要从我们的四类错误中恢复你的系统,或者更好的是,避免需要恢复,你必须能够改变系统的状态。在构建更新机制(例如软件/固件推出过程、配置更改管理程序或批处理调度服务)时,我们建议设计更新系统以尽可能快地运行(或更快,以符合实际限制)。然后,添加控件来限制变更速率,以匹配你当前的风险和干扰政策。将执行推出的能力与推出的速率和频率政策分离有几个优点。
任何组织的推出需求和政策随着时间而改变。例如,在早期,一家公司可能每月进行推出,而且从不在夜间或周末进行。如果推出系统是围绕政策变化设计的,政策的变化可能需要进行困难的重构和侵入性的代码更改。如果推出系统的设计清楚地将变更的时间和速率与变更的行为和内容分开,那么就更容易调整不可避免的管理时间和变更速率的政策变化。
有时,你在推出过程中收到的新信息会影响你的应对方式。想象一下,作为对内部发现的安全漏洞的响应,你正在部署一个内部开发的补丁。通常情况下,你不需要以足够快的速度部署这个变更,以至于冒着破坏你的服务的风险。然而,你的风险计算可能会因为景观的变化而改变(参见第七章):如果你在推出过程中发现漏洞现在已经是公开的信息,并且正在野外积极利用,你可能希望加快程序。
必然会有一个时刻,突然或意外的事件会改变你愿意接受的风险。因此,你希望非常非常快地推出变更。例子可以从安全漏洞(ShellShock,Heartbleed 等)到发现活跃的妥协。*我们建议设计你的紧急推送系统只是将你的常规推送系统调到最大。*这也意味着你的正常推出系统和紧急回滚系统是一样的。我们经常说,未经测试的紧急实践在你需要它们时不起作用。使你的常规系统能够处理紧急情况意味着你不必维护两个单独的推送系统,并且你经常练习你的紧急发布系统。
如果应对紧张局势只需要你修改速率限制以便快速推出变更,你就会更有信心你的推出工具能够按预期工作。然后你可以把精力集中在其他不可避免的风险上,比如快速部署变更中的潜在错误,或者确保关闭攻击者可能用来访问你的系统的漏洞。
我们从我们内部 Linux 发行版的部署演变中学到了这些教训。直到最近,Google 在数据中心安装所有机器时都使用“基础”或“黄金”镜像,其中包含已知的静态文件集。每台机器有一些特定的定制,如主机名、网络配置和凭据。我们的政策是每个月在整个机群中部署新的“基础”镜像。多年来,我们围绕这一政策和工作流程构建了一套工具和软件更新系统:将所有文件捆绑成压缩存档,由高级 SRE 审查一组更改,然后逐渐更新机群中的机器到新镜像。
我们围绕这一政策构建了我们的部署工具,并设计了工具来将特定基础镜像映射到一组机器。我们设计了配置语言来表达如何在几周的时间内改变该映射,然后使用一些机制在基础镜像之上添加异常。一个异常包括越来越多的单个软件包的安全补丁:随着异常列表变得更加复杂,我们的工具遵循每月模式就变得不那么合理了。
作为回应,我们决定放弃每月更新基础镜像的假设。我们设计了更精细的发布单元,对应于每个软件包。我们还构建了一个干净的新 API,指定了要安装的精确软件包集,一次一个机器,放在现有的部署机制之上。如图 9-1 所示,这个 API 解耦了定义几个不同方面的软件:
-
部署和每个软件包应该更改的速率
-
定义所有机器当前配置的配置存储
-
管理将更新应用到每台机器的部署执行器

图 9-1:将软件包部署到机器的工作流程的演变
因此,我们可以独立开发每个方面。然后,我们重新利用现有的配置存储来指定应用于每台机器的所有软件包的配置,并构建了一个部署系统来跟踪和更新每个软件包的独立部署。
通过将镜像构建与每月部署策略解耦,我们可以为不同软件包启用更广泛的发布速度范围。同时,虽然仍然保持对机群中大多数机器的稳定和一致的部署,一些测试机器可以跟随所有软件的最新构建。更好的是,解耦策略解锁了整个系统的新用途。我们现在使用它定期向整个机群分发一部分经过仔细审核的文件。我们还可以通过调整一些速率限制并批准某种类型的软件包的发布比正常情况下更快地进行,简单地使用我们的正常工具进行紧急发布。最终结果更简单,更有用,更安全。
限制对外部时间概念的依赖
时间——即由手表和挂钟等设备报告的普通时间——是一种状态。因为通常无法改变系统体验时间流逝的方式,您的系统融入挂钟时间的任何位置都可能威胁到您完成恢复的能力。在您进行恢复工作的时间和系统上次正常运行的时间之间的不匹配可能导致意想不到的系统行为。例如,涉及重放数字签名交易的恢复可能会失败,如果一些交易是由过期证书签名的,除非您在验证证书时考虑原始交易日期。
如果您的系统时间依赖性更有可能引入安全或可靠性问题,如果它依赖于您无法控制的外部时间概念。这种模式以多种类型的错误形式出现,例如软件错误,如Y2K,Unix 时代翻转,或者开发人员选择将证书到期时间设置得太远,以至于“这不再是他们的问题”。明文或未经身份验证的NTP连接也会引入风险,如果攻击者能够控制网络。代码中的固定日期或时间偏移展现出一种代码异味,表明您可能正在制造一个定时炸弹。
注意
将事件与挂钟时间绑定通常是一种反模式。我们建议使用以下之一,而不是挂钟时间:
-
费率
-
手动推进前进的概念,如时代编号或版本编号
-
有效性列表
如第八章中所述,谷歌的 ALTS 传输安全系统在数字证书中不使用到期时间,而是依赖于撤销系统。活动撤销列表由定义证书序列号有效与撤销范围的向量组成,并且不依赖于挂钟时间。您可以通过定期健康地推送更新的撤销列表来实现隔离目标,以创建时间区段。如果您怀疑对手可能已经获得了基础密钥的访问权限,您可以紧急推送新的撤销列表来撤销证书,并且您可以在异常情况下停止定期推送以进行调试或取证。有关该特定主题的更多讨论,请参见“使用显式撤销机制”。
依赖挂钟时间的设计选择也可能导致安全弱点。由于可靠性约束,您可能会有诱惑力禁用证书有效性检查以执行恢复。然而,在这种情况下,治疗比疾病更糟糕——最好是省略证书到期时间(从允许登录到一组服务器的 SSH 密钥对)而不是跳过有效性检查。要提供一个显着的例外,挂钟时间是用于有意限时访问。例如,您可能希望要求大多数员工每天重新进行身份验证。在这种情况下,重要的是要有一条修复系统的路径,而不依赖于挂钟时间。
依赖绝对时间也可能导致问题,当您尝试从崩溃中恢复,或者期望单调递增时间的数据库尝试从损坏中恢复时。恢复可能需要详尽的事务重放(随着数据集的增长,这很快变得不可行),或者尝试在多个系统之间协调地回滚时间。举个简单的例子:在具有不准确时间概念的系统之间进行日志相关会给您的工程师增加不必要的间接层,使意外错误更加普遍。
您还可以通过使用时代或版本的推进来消除对挂钟时间的依赖,这需要系统的所有部分围绕一个整数值进行协调,该值表示“有效”与“过期”的前进。时代可以是存储在分布式系统组件中的整数,例如锁定服务,或者是根据策略向前(只能向前移动)推进的机器本地状态。为了使您的系统能够尽快进行发布,您可能会设计它们以允许快速的时代推进。单个服务可能负责宣布当前时代或启动时代推进。在遇到问题时,您可以暂停时代的推进,直到您理解并纠正问题。回到我们先前的公钥示例:尽管证书可能会过期,但您不会因为可以停止时代的推进而被诱使完全禁用证书验证。时代与“最低可接受安全版本号”中讨论的 MASVN 方案有一些相似之处。
注意
过于激进地增加时代值可能会导致翻转或溢出。要谨慎对待系统部署更改的速度,以及您可以容忍地跳过多少中间时代或版本值。
暂时控制您系统的对手可能通过大幅加速时代的推进或导致时代翻转来对系统造成持久性的损害。解决这个问题的常见方法是选择具有足够大范围的时代值,并建立一个基础的后备速率限制,例如,将 64 位整数速率限制为每秒增加一次。硬编码后备速率限制是我们先前设计建议的一个例外,即尽快推出更改并添加策略以指定更改的速率。然而,在这种情况下,很难想象有理由改变系统状态超过一秒一次,因为您将要处理数十亿年的时间。这种策略也是合理的,因为 64 位整数在现代硬件上通常是廉价的。
即使在等待经过的挂钟时间是可取的情况下,也要考虑仅仅测量经过的时间,而不需要实际的日期时间。即使系统不知道挂钟时间,后备速率限制也能起作用。
深入探讨:回滚代表了安全之间的权衡
在事件响应期间恢复的第一步是通过安全地回滚任何可疑更改来减轻事件。需要人工注意的生产问题的大部分是自我造成的(参见“意外错误”和“软件错误”),这意味着对系统的预期更改包含错误或其他错误配置,导致了事件。当这种情况发生时,可靠性的基本原则要求系统尽快而安全地回滚到上一个已知的良好状态。
在其他情况下,您需要防止回滚。在修补安全漏洞时,您经常在与攻击者竞赛,试图在攻击者利用漏洞之前部署补丁。一旦成功部署补丁并显示稳定,您需要防止攻击者应用可能重新引入漏洞的回滚,同时仍然保留自己自愿回滚的选项——因为安全补丁本身是代码更改,它们可能包含自己的错误或漏洞。
考虑到这些因素,确定回滚的适当条件可能会很复杂。应用层软件是一个更为直接的情况。系统软件,如操作系统或特权包管理守护程序,可以轻松终止和重新启动任务或进程。您可以将不良版本的名称(通常是唯一的标签字符串、数字或哈希¹⁰)收集到一个拒绝列表中,然后将其纳入部署系统的发布策略中。或者,您可以管理一个允许列表,并构建您的自动化以包括部署的应用软件在该列表中。
负责处理自己更新的特权或低级系统组件更具挑战性。我们称这些组件为自更新。例如,包管理守护程序通过覆盖自己的可执行文件并重新执行自己来更新自己,或者固件图像(如 BIOS)会在自身上重新刷写一个替换图像,然后强制重新启动。如果这些组件被恶意修改,它们可能会主动阻止自己被更新。硬件特定的实现要求增加了挑战。您需要回滚控制机制,即使对于这些组件,但是所需的行为本身可能很难定义。让我们考虑两个示例策略及其缺陷,以更好地理解问题:
允许任意回滚
这种解决方案并不安全,因为导致您执行回滚的任何因素都可能重新引入已知的安全漏洞。漏洞越老或越明显,稳定的、武器化的利用这些漏洞的可能性就越大。
永远不要允许回滚
这种解决方案消除了返回到已知稳定状态的路径,只允许您向前移动到更新的状态。这是不可靠的,因为如果更新引入了错误,您将无法回滚到上一个已知的良好版本。这种方法隐含地要求构建系统生成新版本,以便您可以向前滚动,这会给构建和发布工程基础设施增加时间和可避免的依赖关系。
除了这两种极端方法之外,还有许多其他实用的权衡方案。这些包括:
-
使用拒绝列表
-
使用安全版本号(SVNs)和最低可接受安全版本号(MASVNs)
-
轮换签名密钥
在接下来的讨论中,我们假设在所有情况下,更新都经过了加密签名,并且签名覆盖了组件图像及其版本元数据。
在这里讨论的三种技术的组合可能最好地管理自更新组件的安全性/可靠性权衡。然而,这种组合的复杂性,以及它对ComponentState的依赖,使这种方法成为一项巨大的工作。我们建议逐步引入一个功能,并允许足够的时间来识别您引入的每个组件的任何错误或特殊情况。最终,所有健康的组织都应该使用密钥轮换,但拒绝列表和 MASVN 功能对于高速响应是有用的。
拒绝列表
当您在发布版本中发现错误或漏洞时,您可能希望构建一个拒绝列表,以防止已知的不良版本被(重新)激活,也许可以通过在组件本身中硬编码拒绝列表来实现。在下面的示例中,我们将其写为Release[DenyList]。在组件更新到新发布的版本后,它会拒绝更新到拒绝列表中的版本。
def IsUpdateAllowed(self, Release) -> bool:
return Release[Version] not in self[DenyList]
不幸的是,这个解决方案只解决了意外错误,因为硬编码的拒绝列表呈现了一个无法解决的安全/可靠性权衡。如果拒绝列表总是留有至少一个较旧的已知良好的镜像的回滚空间,该方案就容易受到解压的攻击——攻击者可以逐步回滚版本,直到他们到达包含已知漏洞的较旧版本,然后利用这些漏洞。这种情况基本上就是之前描述的“允许任意回滚”的极端情况,中间还有一些跳跃。或者,将拒绝列表配置为完全阻止关键安全更新的回滚会导致“永远不允许回滚”的极端情况,伴随着可靠性的缺陷。
如果您正在从安全或可靠性事件中恢复,当您的系统可能在整个系统中进行多个更新时,硬编码的拒绝列表是一个很好的选择,可以避免意外错误。向列表中追加一个版本是快速且相对容易的,因为这样做对任何其他版本的有效性几乎没有影响。然而,您需要一个更强大的策略来抵抗恶意攻击。
更好的拒绝列表解决方案将拒绝列表编码在自更新组件之外。在下面的示例中,我们将其写为ComponentState[DenyList]。这个拒绝列表在组件升级和降级时都会保留下来,因为它独立于任何单个发布,但组件仍然需要逻辑来维护拒绝列表。每个发布可能合理地编码在其发布时已知的最全面的拒绝列表:Release[DenyList]。然后,维护逻辑将这些列表合并并在本地存储(请注意,我们写self[DenyList]而不是Release[DenyList],以表明“self”已安装并且正在运行):
ComponentState[DenyList] = ComponentState[DenyList].union(self[DenyList))
检查临时更新的有效性,拒绝拒绝列表中的更新(不要明确引用“self”,因为它对拒绝列表的贡献已经反映在ComponentState中,即使未来版本被安装后仍然存在):
def IsUpdateAllowed(self, Release, ComponentState) -> bool:
return Release[Version] not in ComponentState[DenyList]
现在,您可以有意地进行安全/可靠性权衡,作为一种政策。当您决定在Release[DenyList]中包含什么时,您可以权衡解压攻击的风险与不稳定发布的风险。
即使您将拒绝列表编码在一个ComponentState数据结构中,该数据结构在自更新组件之外维护,这种方法也有缺点:
-
即使拒绝列表存在于集中式部署系统的配置意图之外,您仍然需要监视和考虑它。
-
如果一个条目被意外添加到拒绝列表中,您可能希望将该条目从列表中删除。然而,引入删除功能可能会打开解压攻击的大门。
-
拒绝列表可能会无限增长,最终达到存储的大小限制。您如何管理拒绝列表的垃圾收集?
最低可接受的安全版本号
随着时间的推移,拒绝列表会变得庞大而难以控制,因为条目被追加。您可以使用一个单独的安全版本号,写成Release[SVN],从拒绝列表中删除较旧的条目,同时防止它们被安装。因此,您减少了对系统负责的人的认知负担。
保持Release[SVN]独立于其他版本概念,可以以一种紧凑且在数学上可比较的方式逻辑地跟踪大量发布,而无需像拒绝列表那样需要额外的空间。每当您应用关键安全修复并证明其稳定性时,您都会增加Release[SVN],标记一个安全里程碑,用于调整回滚决策。因为您对每个版本的安全状态都有一个简单的指示器,所以您可以灵活地进行普通的发布测试和资格认证,并且有信心在发现错误或稳定性问题时迅速而安全地做出回滚决策。
请记住,您还希望防止恶意行为者以某种方式将系统回滚到已知的不良或易受攻击的版本。为了防止这些行为者在您的基础设施中立足并利用该立足点阻止恢复,您可以使用 MASVN 来定义一个低水位标记,低于该标记,您的系统不应该运行。这必须是一个有序值(而不是加密哈希),最好是一个简单的整数。您可以像管理拒绝列表一样管理 MASVN:
-
每个发布版本都包括一个 MASVN 值,反映了其发布时的可接受版本。
-
您在部署系统之外维护一个全局值,写为
ComponentState[MASVN]。
作为应用更新的先决条件,所有发布都包括逻辑验证试探性更新的Release[SVN]至少与ComponentState[MASVN]一样高。它被表达为伪代码如下:
def IsUpdateAllowed(self, Release, ComponentState) -> bool:
return Release[SVN] >= ComponentState[MASVN]
全球ComponentState[MASVN]的维护操作不是部署过程的一部分。相反,维护是在新版本初始化时进行的。您需要在每个发布中硬编码一个目标 MASVN - 您希望在创建该发布时强制执行该组件的 MASVN,写为Release[MASVN]。
当部署和执行新版本时,它会将其Release[MASVN](写为self[MASVN],以引用已安装和运行的版本)与ComponentState[MASVN]进行比较。如果Release[MASVN]高于现有的ComponentState[MASVN],那么ComponentState[MASVN]将更新为新的更大值。实际上,这个逻辑每次组件初始化时都会运行,但ComponentState[MASVN]只有在成功更新为更高的Release[MASVN]后才会更改。它被表达为伪代码如下:
ComponentState[MASVN] = max(self[MASVN], ComponentState[MASVN])
这个方案可以模拟前面提到的两种极端政策中的任何一种:
-
通过永远不修改
Release[MASVN]来允许任意回滚 -
通过将
Release[MASVN]与Release[SVN]同步修改,永远不允许回滚
实际上,Release[MASVN]通常在第i+1 个版本中提高,之前的版本解决了安全问题。这确保了i–1 或更旧的版本永远不会再次执行。由于ComponentState[MASVN]是外部的,版本i在安装i+1 后不再允许降级,即使它最初允许这样的降级。图 9-2 说明了三个发布及其对ComponentState[MASVN]的影响的示例值。
图 9-2:三个发布及其对 ComponentState[MASVN]的影响的序列
为了减轻第i–1 个版本中的安全漏洞,第i个版本包括安全补丁和递增的Release[SVN]。Release[MASVN]在第i个版本中不会改变,因为即使安全补丁也可能存在错误。一旦第i个版本在生产中被证明是稳定的,下一个版本,i+1,会递增 MASVN。这表示安全补丁现在是强制性的,没有它的版本是不允许的。
与“尽快进行”设计原则保持一致,MASVN 方案将合理的回滚目标策略与执行回滚的基础设施分开。在自更新组件中引入特定的 API 并从集中式部署管理系统接收命令来增加ComponentState[MASVN]是技术上可行的。通过该命令,您可以在部署管道的后期对接收更新的组件提高ComponentState[MASVN],在足够多的设备上验证了发布版本后,您对其能够按计划工作有很高的信心。在响应活动妥协或特别严重的漏洞时,这样的 API 可能非常有用,其中速度至关重要,风险容忍度比正常情况下更高。
到目前为止,这个例子避免了引入专门的 API 来改变ComponentState。ComponentState是一组影响您通过更新或回滚来恢复系统能力的敏感值。它是组件本地的,并且与配置的意图外部的一个集中式自动化直接控制。在面对并行开发、测试、金丝雀分析和部署的情况下,每个个体组件经历的软件/固件版本序列可能会在类似或相同设备的群集中有所不同。一些组件或设备可能会经历完整的发布版本集合,而其他可能会经历许多回滚。还有一些可能经历最小的变化,并直接从有缺陷或有漏洞的版本跳转到下一个稳定的、合格的发布版本。
因此,使用 MASVN 是一种与拒绝列表结合使用的有用技术,用于自更新组件。在这种情况下,您可能会非常迅速地执行拒绝列表操作,可能是在事件响应条件下。然后在更平静的情况下执行 MASVN 维护,以清除拒绝列表并永久排除(基于每个组件实例)任何容易受到攻击或足够旧的发布版本,并且永远不打算在给定的组件实例上再次执行。
旋转签名密钥
许多自更新组件包括支持对临时更新进行加密认证的功能,换句话说,组件的发布周期的一部分包括对该发布进行加密签名。这些组件通常包括已知公钥的硬编码列表,或作为ComponentState的一部分支持独立密钥数据库。例如:
def IsUpdateAllowed(self, Release, KeyDatabase) -> bool:
return VerifySignature(Release, KeyDatabase)
您可以通过修改组件信任的一组公钥来防止回滚,通常是为了删除旧的或受损的密钥,或者引入一个新的密钥来签署未来的发布版本。较旧的发布版本将失效,因为较新的发布版本不再信任用于验证较旧发布版本上的签名的公共签名验证密钥。然而,您必须小心地管理密钥轮换,因为突然从一个签名密钥更改到另一个可能会使系统面临可靠性问题。
或者,您可以通过引入一个新的更新签名验证密钥k+1,同时与旧的验证密钥k一起允许使用任一密钥进行认证的更新。一旦稳定性得到证明,您就可以放弃对密钥k的信任。这种方案需要对发布版本的多个签名进行支持,并在验证候选更新时需要多个验证密钥。它还具有签名密钥轮换的优势——这是加密密钥管理的最佳实践——并且因此在事件发生后可能会起作用。
密钥轮换可以帮助您从非常严重的妥协中恢复,攻击者设法暂时控制了发布管理并签署并部署了Release[MASVN]设置为最大值的发布。在这种类型的攻击中,通过将ComponentState[MASVN]设置为其最大值,攻击者迫使您将Release[SVN]设置为其最大值,以便未来的发布能够可行,从而使整个 MASVN 方案无效。作为回应,您可以在由新密钥签署的新发布中撤销受损的公钥,并添加专用逻辑来识别异常高的ComponentState[MASVN]并将其重置。由于这种逻辑本身是微妙且潜在危险的,您应该谨慎使用,并在它们达到目的后立即积极撤销任何包含它的发布。
本章不涵盖严重和有针对性的妥协事件的全部复杂性。有关更多信息,请参阅第十八章。
回滚固件和其他硬件中心的约束
具有相应固件的硬件设备——如机器及其 BIOS,或网络接口卡(NIC)及其固件——是自更新组件的常见表现形式。这些设备在健壮的 MASVN 或密钥轮换方案方面提出了额外的挑战,我们在这里简要涉及。这些细节在恢复中发挥着重要作用,因为它们有助于实现可扩展或自动化的从潜在恶意行为中恢复。
有时,只可编程一次(OTP)设备如保险丝被 ROM 或固件用于通过存储ComponentState[MASVN]来实现一种仅向前的 MASVN 方案。这些方案存在重大的可靠性风险,因为回滚是不可行的。额外的软件层有助于解决物理硬件的约束。例如,OTP 支持的ComponentState[MASVN]覆盖了一个小型、单一用途的引导加载程序,其中包含其自己的 MASVN 逻辑,并且具有对单独的可变 MASVN 存储区的独占访问。然后,该引导加载程序将更健壮的 MASVN 语义暴露给更高级别的软件堆栈。
对于验证签名的硬件设备,有时使用 OTP 存储器来存储与这些密钥相关的公钥(或其哈希)和吊销信息。支持的密钥轮换或吊销次数通常受到严重限制。在这些情况下,一个常见的模式再次是使用 OTP 编码的公钥和吊销信息来验证一个小型引导加载程序。该引导加载程序然后包含其自己的验证和密钥管理逻辑层,类似于 MASVN 的示例。
当处理大量积极利用这些机制的硬件设备时,管理备件可能是一个挑战。备件在库存中停留多年,然后被部署时将必然具有非常旧的固件。这些旧的固件必须进行更新。如果旧的密钥完全不再使用,并且更新的发布仅由在备件最初制造时不存在的新密钥签署,那么新的更新将无法验证。
注意
一种解决方案是通过一系列升级来引导设备,确保它们在密钥轮换事件期间停留在所有信任旧密钥和新密钥的发布上。另一种解决方案是支持每个发布的多个签名。即使更新的映像(和已更新以运行这些更新映像的设备)不信任旧的验证密钥,这些更新的映像仍然可以携带由该旧密钥签名的签名。只有旧的固件版本才能验证该签名——这是一种期望的操作,允许它们在被剥夺更新后恢复。
考虑设备在其生命周期内可能使用多少密钥,并确保设备具有足够的空间来存储密钥和签名。例如,一些 FPGA 产品支持多个密钥用于验证或加密它们的比特流。¹³
深入探讨:使用显式吊销机制
吊销系统的主要作用是阻止某种访问或功能。面对主动妥协,吊销系统可以成为救命稻草,让您快速吊销受攻击者控制的凭证,并恢复对系统的控制。然而,一旦建立了吊销系统,意外或恶意行为可能会导致可靠性和安全性后果。如果可能的话,在设计阶段考虑这些问题。理想情况下,吊销系统应该在任何时候都能够履行其职责,而不会引入太多自身的安全和可靠性风险。
为了说明有关吊销的一般概念,我们将考虑以下不幸但常见的情景:您发现攻击者以某种方式控制了有效凭证(例如允许登录到一组服务器的客户端 SSH 密钥对),并且您希望吊销这些凭证。
注意
吊销是一个涉及到恢复、安全性和可靠性许多方面的复杂话题。本节仅讨论了与恢复相关的吊销的一些方面。其他要探讨的主题包括何时使用允许列表与拒绝列表,如何以崩溃恢复的方式卫生地旋转证书,以及如何在部署过程中安全地进行新更改的试点。本书的其他章节提供了许多这些主题的指导,但请记住,没有一本单独的书是足够的参考。
吊销证书的集中式服务
您可能选择使用集中式服务来吊销证书。这种机制通过要求您的系统与存储证书有效性信息的集中式证书有效性数据库进行通信,从而优先考虑安全性。您必须仔细监控和维护这个数据库,以保持系统的安全性,因为它成为了哪些证书是有效的的权威记录存储。这种方法类似于构建一个独立于用于实现更改的服务的独立速率限制服务,如本章前面讨论的那样。然而,要求与证书有效性数据库通信确实有一个缺点:如果数据库宕机,所有其他依赖系统也会宕机。如果证书有效性数据库不可用,很容易产生失败开放的强烈诱惑,以便其他系统也不会变得不可用。请谨慎处理!
失败开放
失败开放避免了锁定和简化了恢复,但也带来了一个危险的权衡:这种策略规避了对滥用或攻击的重要访问保护。即使部分失败开放的情况也可能会引起问题。例如,想象一下,证书有效性数据库依赖的系统宕机了。假设数据库依赖于时间或时代服务,但接受所有正确签名的凭证。如果证书有效性数据库无法访问时间/时代服务,那么进行相对简单的拒绝服务攻击的攻击者,例如通过压倒时间/时代服务的网络链接,可能会重新使用甚至非常旧的吊销凭证。这种攻击之所以有效,是因为在拒绝服务攻击持续期间,吊销的证书再次有效。在您尝试恢复时,攻击者可能会侵入您的网络或找到新的传播方式。
与其失败开放,您可能希望将已知的良好数据从吊销服务分发到个别服务器,以吊销列表的形式,节点可以在本地缓存。然后,节点根据他们对世界状态的最佳理解继续进行,直到他们获得更好的数据。这种选择比超时和失败开放政策安全得多。
直接处理紧急情况
为了快速吊销密钥和证书,您可能希望设计基础设施直接处理紧急情况,通过部署更改到服务器的authorized_users或 Key Revocation List (KRL)文件。¹⁵这种解决方案在多个方面都很麻烦。
注意
在处理少量节点时,直接管理authorized_keys或known_hosts文件尤其诱人,但这种做法扩展性差,会在整个服务器群中模糊真相。很难确保一组给定的密钥已从所有服务器的文件中删除,特别是如果这些文件是唯一的真相来源。
与直接管理authorized_keys或known_hosts文件不同,您可以通过集中管理密钥和证书,并通过吊销列表将状态分发到服务器,以确保更新过程是一致的。实际上,部署显式吊销列表是在您以最大速度移动时最小化不确定性的机会:您可以使用通常的机制来更新和监控文件,包括您在各个节点上使用的速率限制机制。
消除对准确时间概念的依赖
使用显式吊销具有另一个优点:对于证书验证,这种方法消除了对准确时间概念的依赖。无论是意外还是恶意造成的,不正确的时间都会对证书验证造成严重破坏。例如,旧证书可能会突然再次变为有效,从而让攻击者进入,而正确的证书可能会突然无法通过验证,导致服务中断。这些都是您不希望在紧张的妥协或服务中断期间经历的复杂情况。
最好让系统的证书验证依赖于您直接控制的方面,例如推送包含根授权公钥或包含吊销列表的文件。推送文件的系统、文件本身以及真相的中央来源可能比时间的分发更安全、更有维护性和更受监控。然后,恢复只需简单地推送文件,监控只需检查这些是否是预期的文件——这些是您的系统已经使用的标准流程。
规模化吊销凭据
在使用显式吊销时,重要的是要考虑可扩展性的影响。可扩展的吊销需要谨慎,因为部分攻破您系统的攻击者可以利用这种部分妥协作为拒绝进一步服务的强大工具,甚至可能吊销整个基础设施中的每个有效凭据。继续之前提到的 SSH 示例,攻击者可能会尝试吊销所有 SSH 主机证书,但您的机器需要支持操作,如更新 KRL 文件以应用新的吊销信息。您如何保护这些操作免受滥用?
在更新 KRL 文件时,盲目地用新文件替换旧文件是麻烦的根源¹⁶——单次推送可能会吊销整个基础设施中的每个有效凭据。一个保护措施是让目标服务器在应用新 KRL 之前评估新 KRL,并拒绝吊销自己凭据的任何更新。忽略吊销所有主机凭据的 KRL 将被所有主机忽略。因为攻击者的最佳策略是吊销一半的机器,所以您至少可以保证在每次 KRL 推送后,至少一半的机器仍将正常运行。恢复和恢复一半的基础设施要容易得多,比恢复全部要容易得多。¹⁷
避免风险异常
由于规模,大型分布式系统可能会遇到分发吊销列表的问题。这些问题可能会限制您部署新的吊销列表的速度,并在删除受损凭据时减慢您的响应时间。
为了解决这个缺点,您可能会想要构建一个专门的“紧急”吊销列表。然而,这种解决方案可能不太理想。由于您很少使用紧急列表,当您最需要它时,这种机制可能不太可能起作用。更好的解决方案是对吊销列表进行分片,以便您可以逐步更新它。这样,在紧急情况下吊销凭据只需要更新部分数据。始终使用分片意味着您的系统始终使用多部分吊销列表,并且在正常和紧急情况下使用相同的机制。
同样,要注意添加“特殊”帐户(例如提供对高级员工的直接访问权限的帐户),这些帐户可以绕过吊销机制。这些帐户对攻击者非常有吸引力 - 对这种帐户的成功攻击可能使您所有的吊销机制失效。
了解您的预期状态,直到字节。
从任何类别的错误中恢复 - 无论是随机的、意外的、恶意的还是软件错误 - 都需要将系统恢复到已知的良好状态。如果您确实知道系统的预期状态并且有一种方法来读取部署状态,那么这样做就会更容易。这一点可能显而易见,但不知道预期状态是问题的常见根源。在每一层(每个服务、每个主机、每个设备等)彻底编码预期状态并减少可变状态,使得在返回到良好工作状态时更容易识别。最终,彻底编码预期状态是卓越自动化、安全、入侵检测和恢复到已知状态的基础。
主机管理
假设您管理一个单独的主机,比如物理机、虚拟机,甚至一个简单的 Docker 容器。您已经建立了基础设施来执行自动恢复,这带来了很多价值,因为它可以高效地处理可能发生的许多问题,比如在SRE 书的第七章中详细讨论的问题。为了实现自动化,您需要对该单独机器的状态进行编码,包括运行在上面的工作负载。您需要编码足够的信息,以便自动化安全地将机器恢复到良好状态。在谷歌,我们在每个抽象层次上都应用这种范例,上下硬件和软件堆栈。
谷歌的系统将我们主机的软件包分发到机器群中,如“尽快设计(受策略保护)”中所述,以非常规的方式持续监视系统的整个状态。每台机器不断监视其本地文件系统,维护一个包括文件系统中每个文件的名称和加密校验和的映射。我们使用一个中央服务收集这些映射,并将它们与每台机器的分配软件包的预期状态进行比较。当我们发现预期状态与当前状态之间存在偏差时,我们将该信息附加到偏差列表中。
由于将各种恢复手段统一为一个过程,捕获机器状态的策略为恢复提供了强大的优势。如果宇宙射线随机损坏了磁盘上的一个位,我们会发现校验和不匹配并修复偏差。如果机器的预期状态发生了变化,因为一个组件的软件部署无意中改变了另一个组件的文件,改变了该文件的内容,我们会修复偏差。如果有人试图在正常管理工具和审查流程之外修改机器的本地配置(无论是意外还是恶意),我们也会修复该偏差。您可能选择通过重新映像整个系统来修复偏差,这种方法不太复杂,更容易实现,但在规模上更具破坏性。
除了捕获磁盘上文件的状态之外,许多应用程序还具有相应的内存状态。自动化恢复必须修复这两种状态。例如,当 SSH 守护程序启动时,它会从磁盘读取配置,并且除非受到指示,否则不会重新加载配置。为了确保内存状态根据需要进行更新,每个软件包都需要具有幂等的post_install命令,每当其文件出现偏差时都会运行。OpenSSH软件包的post_install会重新启动 SSH 守护程序。类似的pre_rm命令会在删除文件之前清理任何内存状态。这些简单的机制可以维护机器的所有内存状态,并报告和修复偏差。
对这种状态进行编码,让自动化检查每个偏差是否存在任何恶意差异。关于机器状态的丰富信息在安全事件后的取证分析中也非常有价值,帮助您更好地理解攻击者的行动和意图。例如,也许攻击者找到了一种方法在一些机器上存放恶意 shellcode,但无法逆向监控和修复系统,后者恢复了一个或多个机器上的意外变化。攻击者很难掩盖自己的行踪,因为中央服务会注意到并记录主机报告的偏差。
总之,在这个抽象级别上,所有状态变化都是相等的。您可以以类似的方式自动化、保护和验证所有状态变化,将失败的金丝雀分析回滚和更新的 bash 二进制文件的紧急部署视为常规变化。使用相同的基础设施使您能够就如何快速应用每个变化做出一致的政策决策。在这个级别上的速率限制可防止不同类型的变化之间意外碰撞,并建立最大可接受的变化速率。
设备固件
对于固件更新,您还可以在更低的层次上捕获状态。现代计算机中的各个硬件部件都有自己的软件和配置参数。出于安全和可靠性的考虑,您至少应该跟踪每个设备固件的版本。理想情况下,您应该捕获该固件可用的所有设置,并确保它们设置为预期值。
在管理谷歌机器的固件及其配置时,我们利用了与我们用于管理主机软件更新和偏差分析的相同系统和流程(参见“主机管理”)。自动化安全地分发所有固件的预期状态作为一个软件包,报告任何偏差,并根据我们的速率限制政策和其他处理中断的政策来修复偏差。
通常,预期状态并不直接暴露给监视文件系统的本地守护程序,它对设备固件没有特殊知识。我们通过允许每个软件包引用激活检查来解耦与硬件交互的复杂性,即软件包中定期运行的脚本或二进制文件,以确定软件包是否正确安装。脚本或二进制文件会执行与硬件通信和比较固件版本和配置参数的操作,然后报告任何意外的偏差。这种功能对于恢复特别有用,因为它赋予主题专家(即子系统所有者)采取适当措施来解决他们的专业领域中的问题。例如,自动化跟踪目标状态、当前状态和偏差。如果一台机器的目标是运行 BIOS 版本 3,但当前正在运行 BIOS 版本 1,自动化对 BIOS 版本 2 没有意见。软件包管理脚本确定是否可以将 BIOS 升级到版本 3,或者是否唯一的约束要求通过多个安装版本来引导子系统。
一些具体的例子说明了管理预期状态对安全性和可靠性都至关重要。谷歌使用特殊供应商提供的硬件与外部时间源(例如 GNSS/GPS 系统和原子钟)进行接口,以在生产中实现准确的时间保持,这是 Spanner 的前提条件。我们的硬件在设备上存储了两个不同的固件版本,分别存储在两个不同的芯片上。为了正确操作这些时间源,我们需要仔细配置这些固件版本。作为额外的复杂性,一些固件版本存在已知的错误,影响它们如何处理闰秒和其他边缘情况。如果我们不仔细维护这些设备上的固件和设置,我们就无法在生产中提供准确的时间。状态管理还需要覆盖备用、次要或其他非活动代码或配置,这些在恢复期间可能突然变为活动状态。在这种情况下,如果机器启动但时钟硬件无法提供足够准确的时间来运行我们的服务,那么我们的系统就没有充分恢复。
举个例子,现代 BIOS 具有对引导(和引导后)系统安全至关重要的许多参数。例如,您可能希望引导顺序优先选择 SATA 而不是 USB 引导设备,以防止数据中心中的恶意行为者轻松地从 USB 驱动器引导系统。更高级的部署跟踪和维护允许签署 BIOS 更新的密钥数据库,既用于管理轮换,又用于防范篡改。如果在恢复过程中主引导设备发生硬件故障,您不希望发现 BIOS 因为您忘记监视和指定次要引导设备的设置而卡在等待键盘输入的状态。
全球服务
服务中的最高抽象层和基础设施中最持久的部分,例如存储、命名和身份,可能是系统恢复最困难的领域。捕获状态的范式也适用于堆栈的这些高层。在构建或部署像 Spanner 或 Hadoop 这样的新全局单例系统时,确保支持多个实例,即使您永远不打算使用多个实例,甚至在第一次部署时也是如此。除了备份和恢复之外,您可能需要重建整个系统的新实例,以恢复该系统上的数据。
与手动设置服务不同,你可以通过编写命令式的自动化或使用声明性的高级配置语言(例如,容器编排配置工具如 Terraform)来设置服务。在这些情况下,你应该捕获服务创建的状态。这类似于测试驱动开发捕获代码的预期行为的方式,然后指导你的实现并帮助澄清公共 API。这两种做法都会导致更易维护的系统。
容器的流行意味着许多全球服务的构建模块的状态通常会被默认捕获。虽然自动捕获“大部分”服务状态是很好的,但不要被误导以为安全感是虚假的。从头开始恢复基础设施需要执行一系列复杂的依赖关系。这可能会导致发现意外的容量问题或循环依赖。如果你在物理基础设施上运行,问问自己:你是否有足够的备用机器、磁盘空间和网络容量来启动基础设施的第二份副本?如果你在像 GCP 或 AWS 这样的大型云平台上运行,你可能可以购买所需的物理资源,但你是否有足够的配额来在短时间内使用这些资源?你的系统是否自然地产生了任何相互依赖,以阻止从头开始进行干净的启动?在受控情况下进行灾难测试可能是有用的,以确保你对意外情况有所准备。
持久数据
没有人关心备份;他们只关心恢复。
到目前为止,我们已经专注于安全地恢复运行服务所需的基础设施。这对于一些无状态服务是足够的,但许多服务还存储持久数据,这增加了一系列特殊的挑战。关于备份和恢复持久数据的挑战有很多优秀的信息。在这里,我们讨论与安全性和可靠性相关的一些关键方面。
为了防御前面提到的错误类型,尤其是恶意错误,你的备份需要与主要存储具有相同级别的完整性保护。恶意内部人员可能会更改备份的内容,然后强制从损坏的备份中进行恢复。即使你有强大的加密签名来覆盖你的备份,如果你的恢复工具在恢复过程中不验证这些签名,或者如果你的内部访问控制没有正确限制可以手动进行签名的人员,那么这些签名就是无用的。
在可能的情况下,对持久数据的安全保护进行分隔是很重要的。如果你在数据的服务副本中检测到损坏,你应该将损坏隔离到实际上最小的数据子集中。如果你能够识别备份数据的这个子集并验证其完整性,那么恢复 0.01%的持久数据将会快得多,而不需要读取和验证其他 99.99%的数据。这种能力在持久数据的大小增长时变得尤为重要,尽管如果你遵循大型分布式系统设计的最佳实践,分隔通常会自然发生。计算分隔的块大小通常需要在存储和计算开销之间进行权衡,但你还应该考虑块大小对 MTTR 的影响。
你还应该考虑系统需要部分恢复的频率。还要考虑在恢复和数据迁移中涉及的系统之间共享多少常见基础设施:数据迁移通常与低优先级的部分恢复非常相似。如果每次数据迁移——无论是到另一台机器、机架、集群还是数据中心——都能够对恢复系统的关键部分进行练习并建立信心,那么当你最需要时,你就会知道所涉及的基础设施更有可能正常工作并且被理解。
数据恢复也可能引入其自己的安全和隐私问题。删除数据对于许多系统来说是必要的,而且通常也是法律要求的功能。确保你的数据恢复系统不会无意中允许你恢复被假定已销毁的数据。要意识到删除加密密钥和删除加密数据之间的区别。通过销毁相关的加密密钥使数据无法访问可能是有效的,但这种方法要求以符合细粒度数据删除要求的方式对用于各种类型数据的密钥进行分隔。
设计测试和持续验证
如第八章所讨论的,持续验证可以帮助维护一个强大的系统。为了做好恢复的准备,你的测试策略需要包括对恢复过程的测试。由于其性质,恢复过程在不熟悉的条件下执行不寻常的任务,如果没有测试,它们将遇到意想不到的挑战。例如,如果你正在自动创建一个干净的系统实例,一个良好的测试设计可能会揭示一个特定服务只有一个全局实例的假设,并帮助识别难以为该服务恢复创建第二个实例的情况。考虑测试可想象的恢复场景,以便在测试效率和生产实际性之间取得正确的平衡。
你还可以考虑测试恢复特别困难的小众情况。例如,在谷歌,我们在各种环境中实现了一个加密密钥管理协议:Arm 和 x86 CPU、UEFI 和裸机固件、Microsoft Visual C++(MSVC)、Clang、GCC 编译器等。我们知道对这个逻辑的所有故障模式进行练习将是具有挑战性的——即使在全面投入端到端测试的情况下,要真实地模拟硬件故障或中断通信也是困难的。因此,我们选择在一个可移植、编译器中立、位宽中立的方式中实现核心逻辑。我们对逻辑进行了大量的单元测试,并关注了用于抽象外部组件的接口设计。例如,为了伪造个别组件并练习它们的故障行为,我们创建了用于从闪存读取和写入字节、用于加密密钥存储以及用于性能监控原语的接口。这种测试环境条件的方法经受住了时间的考验,因为它明确地捕捉了我们想要恢复的故障类别。
最后,寻找通过持续验证来对恢复方法建立信心的方法。恢复涉及人类采取的行动,而人类是不可靠和不可预测的。仅仅依靠单元测试,甚至连续集成/交付/部署也无法捕捉到由人类技能或习惯导致的错误。例如,除了验证恢复工作流的有效性和互操作性之外,你还必须验证恢复说明是否可读且易于理解。
紧急访问
本章描述的恢复方法依赖于响应者与系统进行交互的能力,并且我们倡导使用与正常运营相同的主要服务来进行恢复过程。然而,当正常访问方法完全破坏时,您可能需要设计一个专用解决方案来部署。
组织通常具有紧急访问的独特需求和选择。关键是制定计划并建立维护和保护该访问的机制。此外,您需要了解您无法控制的系统层——这些层面的任何故障都是无法采取行动的,尽管它们会影响您。在这些情况下,您可能需要在其他人修复公司所依赖的服务时静观其变。为了最大程度地减少第三方故障对您的服务的影响,寻找您可以在基础设施的任何层面部署的潜在具有成本效益的冗余。当然,可能没有任何具有成本效益的替代方案,或者您可能已经达到了服务提供商所保证的最高 SLA。在这种情况下,请记住,您的可用性取决于您的依赖关系的总和。
谷歌的远程访问策略集中在部署自包含的关键服务到地理分布的机架上。为了支持恢复工作,我们旨在提供远程访问控制、高效的本地通信、替代网络和基础设施中的关键防御点。在全球性故障期间,由于每个机架至少对某些响应者保持可用,响应者可以开始修复他们可以访问的机架上的服务,然后径向扩展恢复进度。换句话说,当全球协作实际上是不可能的时候,任意较小的地区可以尝试自行解决问题。尽管响应者可能缺乏发现他们最需要的地方的上下文,并且存在地区分歧的风险,但这种方法可能会显著加速恢复。
访问控制
组织的访问控制服务不应成为所有远程访问的单点故障是至关重要的。理想情况下,您将能够实现避免相同依赖关系的替代组件,但是这些替代组件的可靠性可能需要不同的安全解决方案。虽然它们的访问策略必须同样强大,但出于技术或实际原因,它们可能不太方便和/或具有降级的功能集。
由于远程访问凭据可能无法使用,因此不能依赖于典型的凭据服务。因此,除非您可以用低依赖性实现替换这些组件,否则不能从访问基础设施的动态组件(如单一登录(SSO)或联合身份提供者)派生访问凭据。此外,选择这些凭据的生命周期构成了一个困难的风险管理权衡:对用户或设备强制执行短期访问凭据的良好做法,如果故障持续时间超过了它们,那么这将成为一个定时炸弹,因此您被迫延长凭据的生命周期以超过任何预期故障的长度,尽管存在额外的安全风险。此外,如果您是按固定时间表主动发放远程访问凭据,而不是在故障开始时按需激活它们,那么故障可能会在它们即将到期时开始。
如果网络访问采用用户或设备授权,对于任何依赖于动态组件的风险,与凭据服务面临的风险类似。随着越来越多的网络使用动态协议,您可能需要提供更加静态的替代方案。您可用的网络提供商列表可能会限制您的选择。如果可以使用具有静态网络访问控制的专用网络连接,请确保它们的定期更新不会破坏路由或授权。实现足够的监控以检测网络访问中断的位置,或者帮助区分网络访问问题和网络上层的问题可能尤为重要。
通信
紧急通信渠道是紧急响应的下一个关键因素。当值班人员的常规聊天服务无法使用或无法访问时,他们应该怎么办?如果聊天服务受到攻击者的威胁或被监听,该怎么办?
选择一种尽可能少依赖的通信技术(例如 Google Chat、Skype 或 Slack),并且对于响应团队的规模来说足够有用。如果该技术是外包的,那么即使系统外部的层面出现故障,响应者是否能够访问该系统?电话桥接虽然效率低下,但作为一种老式选择仍然存在,尽管它们越来越多地使用依赖于互联网的 IP 电话技术进行部署。如果公司希望部署自己的解决方案,互联网中继聊天(IRC)基础设施是可靠且自包含的,但缺乏一些安全方面的考虑。此外,您仍然需要确保在网络中断期间您的 IRC 服务器仍然可以访问。当您的通信渠道托管在自己的基础设施之外时,您可能还需要考虑提供商是否能够保证足够的身份验证和保密性来满足公司的需求。
响应者习惯
紧急访问技术的独特性通常导致与日常操作不同的做法。如果您不优先考虑这些技术的端到端可用性,响应者可能不知道如何在紧急情况下使用它们,您将失去这些技术的好处。整合低依赖性的替代方案可能会很困难,但这只是问题的一部分——一旦在很少使用的流程和工具中混入人类在压力下的混乱,结果复杂性可能会阻碍所有访问。换句话说,人类而不是技术可能会使紧急工具失效。
您能够最大程度地减少正常和紧急流程之间的区别,响应者就能够更多地依赖习惯。这将释放更多的认知能力,让他们能够更多地专注于不同之处。因此,组织对中断的弹性可能会提高。例如,在谷歌,我们集中在 Chrome、其扩展和与之相关的任何控件和工具作为远程访问的单一平台。将紧急模式引入 Chrome 扩展程序使我们能够在前期尽可能少地增加认知负荷,同时保留将其整合到更多扩展程序中的选项。
为了确保您的响应者定期进行紧急访问实践,引入将紧急访问整合到值班人员的日常习惯中的政策,并持续验证相关系统的可用性。例如,定义并强制执行所需练习之间的最短时间。团队负责人可以在团队成员需要完成必需的凭证刷新或培训任务时发送电子邮件通知,或者可以选择放弃练习,如果他们确定该个人定期参与等效活动。这增加了信心,当发生事故时,团队的其他成员确实拥有相关的凭证,并且最近完成了必要的培训。否则,让您的员工强制练习打破玻璃操作和任何相关流程。
最后,请确保相关的文件,如政策、标准和操作指南,是可用的。人们往往会忘记很少使用的细节,这样的文件也可以在压力和怀疑下减轻压力。架构概述和图表对于事件响应者也是有帮助的,并且可以让不熟悉该主题的人快速了解,而不太依赖于专家。
意想不到的好处
本章描述的设计原则,建立在弹性设计原则的基础上,提高了系统的恢复能力。可靠性和安全性之外的意想不到的好处可能会帮助您说服您的组织采用这些实践。考虑一个专门用于固件更新认证、回滚、锁定和证明机制的服务器。有了这些基本功能,您可以自信地从检测到的妥协中恢复机器。现在考虑在“裸金属”云托管服务中使用这台机器,供应商希望使用自动化清理和转售机器。已经考虑了恢复的机器已经有了一个安全和自动化的解决方案。
这些好处在供应链安全方面进一步增加。当机器由许多不同的组件组装而成时,您需要更少地关注那些完整性可以通过自动方式恢复的组件的供应链安全性。您的首次操作只需要运行恢复程序。作为额外的奖励,重新利用恢复程序意味着您定期锻炼您的关键恢复能力,因此当发生事故时,您的员工已经准备好采取行动。
为恢复设计系统被认为是一个高级话题,其商业价值只有在系统脱离预期状态时才能得到证明。但是,鉴于我们建议操作系统使用错误预算来最大化成本效率,我们预计这样的系统会经常处于错误状态。我们希望您的团队将慢慢开始在开发过程中尽早投资于速率限制或回滚机制。有关如何影响您的组织的更多见解,请参见第二十一章。
结论
本章探讨了为恢复设计系统的各个方面。我们解释了系统应该在部署更改的速率方面具有灵活性的原因:这种灵活性使您能够在可能的情况下缓慢推出更改,并避免协调失败,但也使您能够在必须接受更多风险以满足安全目标时快速而自信地推出更改。回滚更改的能力对于构建可靠的系统至关重要,但有时您可能需要防止回滚到不安全或足够旧的版本。了解、监视和尽可能重现系统的状态——通过软件版本、内存、挂钟时间等——是可靠地恢复系统到以前的工作状态的关键,并确保其当前状态符合您的安全要求。作为最后的手段,紧急访问允许响应者保持连接,评估系统并缓解情况。深思熟虑地管理政策与程序、中央真相来源与本地功能、预期状态与系统实际状态之间的关系为可恢复的系统铺平了道路,同时促进了韧性和日常运营的稳健性。
¹ CAP 定理描述了扩展分布式系统涉及的一些权衡以及其后果。
² 意外的位翻转可能是由于硬件故障,来自其他系统的噪音,甚至是宇宙射线引起的。第十五章更详细地讨论了硬件故障。
³ 一个名为人类可靠性分析(HRA)的研究领域记录了在给定任务中人为错误的可能性。有关更多信息,请参见美国核监管委员会的概率风险评估。
⁴ “计算机科学中的所有问题都可以通过另一级间接性来解决。” ——David Wheeler
⁵ “… 除了太多级别的间接性。” ——未知
⁶ 有关在受到威胁时如何应对以及确定您的恢复系统是否受到威胁的元问题的详细讨论,请参见第十八章。第七章还有额外的设计模式和示例,描述了如何选择适当的速率。
⁷ 请参见CVE-2014-6271、CVE-2014-6277、CVE-2014-6278和CVE-2014-7169。
⁸ 请参见CVE-2014-0160。
⁹ 这个原则的推论是:如果您在紧急情况下有一个有效的方法(通常是因为它的依赖性低),那就把它作为您的标准方法。
¹⁰ 例如,完整程序或固件映像的加密哈希(如 SHA256)。
¹¹ “已知不良”版本可能是由于成功但不可逆转的更改,例如主要模式更改,或者由于错误和漏洞。
¹² 另一个广泛部署的精心管理的安全版本号的例子存在于英特尔的微码 SVN 中,例如用于缓解安全问题 CVE-2018-3615。
¹³ 一个例子是Xilinx Zynq Ultrascale+设备中的硬件信任根支持。
¹⁴ 立即撤销凭证可能并不总是最佳选择。有关应对妥协的讨论,请参见第十七章。
-
KRL 文件是由证书颁发机构(CA)吊销的密钥的紧凑二进制表示。有关详细信息,请参阅
ssh-keygen(1)manpage。 -
虽然本章重点是恢复,但也至关重要的是考虑这样操作的弹性。在像 Linux 这样的 POSIX 系统上替换关键配置文件时,需要谨慎确保在崩溃或其他故障发生时具有稳健的行为。考虑使用带有
RENAME_EXCHANGE标志的renameat2系统调用。 -
连续的恶意 KRL 推送可能会扩大负面影响,但速度和广度的限制仍然会实质性地扩大响应窗口。
-
post_install和pre_rm的概念是从Debian的preinst、postinst、prerm和postrm中借鉴而来的。谷歌的软件包管理系统采取了更加强硬的方法:它不允许软件包的配置和安装分开,也不允许安装过程中出现一半的成功。任何软件包的更改都保证会成功,否则机器将完全回滚到先前的状态。如果回滚失败,机器将通过我们的修复流程进行重新安装和潜在的硬件更换。这种方法使我们能够消除软件包状态的许多复杂性。 -
有关应对妥协的进一步讨论,请参阅第十七章。
-
Spanner是谷歌的全球分布式数据库,支持外部一致的分布式事务。它需要数据中心之间非常紧密的时间同步。
-
请参阅 Krishnan, Kripa. 2012. “Weathering the Unexpected.” ACM Queue 10(9). https://oreil.ly/vJ66c。
-
许多版本的这一优秀建议都被归因于许多备受尊敬的工程师。我们在印刷品中找到的最古老版本,碰巧是在作者书架上的一本书中,是来自 W. Curtis Preston 的Unix Backup & Recovery(O’Reilly)。他将这句话归因于 Ron Rodriguez,即“没有人在乎你能否备份——只在乎你能否恢复”。
-
有关入门知识,请参阅 Kristina Bennett 的 SREcon18 演讲“Tradeoffs in Resiliency: Managing the Burden of Data Recoverability”。
-
例如,查看谷歌的数据保留政策。
-
请参阅 Treynor, Ben 等人。2017. “The Calculus of Service Availability.” ACM Queue 15(2). https://oreil.ly/It4-h。
-
例如,软件定义网络(SDN)。
-
Breakglass 工具是可以绕过策略以允许工程师快速解决故障的机制。请参阅“Breakglass”。
-
有关错误预算的更多信息,请参阅SRE 书中的第三章。
第十章:减轻拒绝服务攻击
原文:10. Mitigating Denial-of-Service Attacks
译者:飞龙
协议:CC BY-NC-SA 4.0
作者:Damian Menscher
与 Vitaliy Shipitsyn 和 Betsy Beyer 一起
安全从业者通常从攻击和防御的角度考虑他们保护的系统。但在典型的拒绝服务攻击中,经济学提供了更有用的术语:对手试图导致对特定服务的需求超过该服务容量的供应。¹ 最终结果是服务容量不足以为其合法用户提供服务。组织随后必须决定是承担更大的费用来吸收攻击,还是遭受停机时间(以及相应的财务损失),直到攻击停止。
虽然一些行业比其他行业更经常成为 DoS 攻击的目标,但任何服务都可能以这种方式受到攻击。DoS 勒索是一种金融攻击,对手威胁要破坏服务,除非付款,相对不加选择地打击。²
攻击和防御策略
攻击者和防御者资源有限,必须有效地利用资源来实现其目标。在制定防御策略时,了解对手的策略是有帮助的,这样您就可以在他们之前找到防御的弱点。有了这种理解,您可以构建已知攻击的防御,并设计具有灵活性的系统,以快速减轻新型攻击。
攻击者的策略
攻击者必须专注于有效地利用有限的资源来超过其目标的容量。聪明的对手可能能够破坏更强大对手的服务。
典型服务有几个依赖关系。考虑一个典型用户请求的流程:
-
DNS 查询提供应该接收用户流量的服务器的 IP 地址。
-
网络将请求传递到服务前端。
-
服务前端解释用户请求。
-
服务后端为自定义响应提供数据库功能。
成功破坏这些步骤中的任何一个的攻击将破坏服务。大多数新手攻击者将尝试发送一大堆应用程序请求或网络流量。更复杂的攻击者可能会生成更昂贵的请求来回答 - 例如,滥用许多网站上存在的搜索功能。
因为单台机器很少足以破坏大型服务(通常由多台机器支持),决心的对手将开发工具,利用许多机器的力量进行所谓的分布式拒绝服务(DDoS)攻击。要执行 DDoS 攻击,攻击者可以利用易受攻击的机器并将它们组合成僵尸网络,或发动放大攻击。
防御者的策略
资源充足的防御者可以通过过度配置整个堆栈来吸收攻击,但代价很大。充满耗电量的机器的数据中心很昂贵,而为吸收最大攻击而提供始终开启的容量是不可行的。虽然自动扩展可能是具有充足容量的云平台上构建的服务的选项,但防御者通常需要利用其他成本效益的方法来保护其服务。
在确定最佳的 DoS 防御策略时,您需要考虑工程时间 - 您应该优先考虑具有最大影响的策略。虽然专注于解决昨天的故障很诱人,但最近的偏见可能导致迅速变化的优先事项。相反,我们建议使用威胁模型方法,集中精力解决依赖链中的最薄弱环节。您可以根据攻击者需要控制的机器数量来比较威胁,以造成用户可见的破坏。
注意
我们使用术语DDoS来指代仅因其分布式性质而有效的 DoS 攻击,以及使用大型僵尸网络或放大攻击。我们使用术语DoS来指代可能源自单个主机的攻击。在设计防御时,这种区别是相关的,因为您通常可以在应用层部署 DoS 防御,而 DDoS 防御通常利用基础设施内的过滤器。
为防御而设计
理想的攻击会将所有力量集中在单一受限资源上,例如网络带宽、应用服务器 CPU 或内存,或者像数据库这样的后端服务。您的目标应该是以最有效的方式保护这些资源。
随着攻击流量深入系统,它变得更加集中和更加昂贵,因此,分层防御,即每一层保护其后面的层,是一种必不可少的设计特征。在这里,我们将研究导致两个主要层中的可防御系统的设计选择:共享基础设施和个体服务。
可防御的架构
大多数服务共享一些常见的基础设施,例如对等容量、网络负载均衡器和应用负载均衡器。
共享基础设施是提供共享防御的自然场所。边缘路由器可以限制高带宽攻击,保护骨干网络。网络负载均衡器可以限制数据包洪泛攻击,以保护应用负载均衡器。应用负载均衡器可以在流量到达服务前端之前限制特定于应用程序的攻击。
分层防御往往是具有成本效益的,因为您只需要为内部层的 DoS 攻击风格进行容量规划,这些攻击风格可以突破外部层的防御。尽早消除攻击流量既节省了带宽,也节省了处理能力。例如,通过在网络边缘部署 ACL,您可以在流量有机会消耗内部网络带宽之前丢弃可疑流量。在网络边缘附近部署缓存代理也可以提供显着的成本节约,同时还可以减少合法用户的延迟。
注意
有状态的防火墙规则通常不适合作为接收入站连接的生产系统的第一道防线。⁵对手可以进行状态耗尽攻击,其中大量未使用的连接填满了启用了连接跟踪的防火墙的内存。相反,使用路由器 ACL 来限制流量到必要的端口,而不会引入有状态的系统到数据路径中。
在共享基础设施中实现防御也提供了有价值的规模经济。虽然为任何个体服务提供重要的防御能力可能不具有成本效益,但共享防御可以让您一次性覆盖广泛的服务。例如,图 10-1 显示了一次针对一个站点的攻击产生的流量量远高于该站点的正常流量,但与Project Shield保护的所有站点接收到的流量相比,仍然是可以管理的。商业 DoS 缓解服务使用类似的捆绑方法来提供成本效益的解决方案。

图 10-1. 通过 Project Shield 保护的站点遭受的 DDoS 攻击,从(上)个体站点的角度和(下)Project Shield 负载均衡器的角度看
特别大规模的 DDoS 攻击可能会压倒数据中心的容量,就像放大镜可以利用太阳的能量点燃火一样。任何防御策略都必须确保分布式攻击所达到的能力不能集中到任何单一组件上。您可以使用网络和应用负载均衡器不断监视传入流量,并将流量传送到最近具有可用容量的数据中心,防止这种类型的过载。
您可以使用anycast来保护共享基础设施,而不依赖于一种被动系统,这是一种技术,其中一个 IP 地址从多个位置宣布。使用这种技术,每个位置都会吸引附近用户的流量。因此,分布式攻击将分散到世界各地的位置,并且因此无法将其能力集中到任何单一数据中心。
可防御服务
网站或应用程序设计可能会对服务的防御姿态产生重大影响。尽管确保服务在过载条件下能够优雅地降级提供了最佳的防御,但可以进行几项简单的更改来提高对攻击的弹性,并在正常运行中实现显着的成本节约:
利用缓存代理
使用Cache-Control和相关标头可以允许代理重复请求内容,而无需每个请求都命中应用程序后端。这适用于大多数静态图像,甚至适用于主页。
避免不必要的应用程序请求
每个请求都会消耗服务器资源,因此最好尽量减少所需的请求次数。如果一个网页包含多个小图标,最好将它们全部放在一个(较大的)图像中,这种技术称为图像合并。作为一个附带好处,减少真实用户对服务的请求次数将减少在识别恶意机器人时的误报。
最小化出口带宽
虽然传统攻击试图饱和入口带宽,但攻击也可能通过请求大资源来饱和您的带宽。将图像调整为所需大小将节省出口带宽,并减少用户的页面加载时间。限制速率或降低不可避免的大型响应也是另一种选择。
减轻攻击
虽然可防御的架构提供了抵御许多 DoS 攻击的能力,但您可能还需要积极的防御来减轻大规模或复杂的攻击。
监控和警报
停机解决时间由两个因素主导:检测到故障的平均时间(MTTD)和修复故障的平均时间(MTTR)。DoS 攻击可能会导致服务器 CPU 利用率飙升,或者应用程序在排队请求时耗尽内存。为了快速诊断根本原因,您需要监视请求速率以及 CPU 和内存使用情况。
对异常高的请求速率发出警报可以清楚地指示事件响应团队遭受了攻击。但是,请确保您的警报是可操作的。如果攻击没有对用户造成实质性伤害,通常最好是吸收它。我们建议只在需求超过服务容量并且自动 DoS 防御已经启动时发出警报。
只有在可能需要人工干预时才发出警报的原则同样适用于网络层攻击。许多 synflood 攻击可以被吸收,但如果触发了 syncookies,则可能需要发出警报。类似地,高带宽攻击只有在链接饱和时才值得关注。
优雅降级
如果吸收攻击是不可行的,您应尽量减少对用户的影响。
在大规模攻击期间,您可以使用网络 ACL 来限制可疑流量,提供有效的开关以立即限制攻击流量。重要的是不要一直阻止可疑流量,这样您可以保持对系统的可见性,并最小化影响与攻击特征匹配的合法流量的风险。因为聪明的对手可能模拟合法流量,所以限制可能不足够。此外,您可以使用服务质量(QoS)控件来优先处理关键流量。对于像批量复制这样不太重要的流量使用较低的 QoS 可以在需要时释放带宽到更高的 QoS 队列。
在超载的情况下,应用程序也可以退回到降级模式。例如,Google 处理超载的方式有:
-
博客服务以只读模式提供,禁用评论。
-
Web 搜索继续提供带有减少功能集的服务。
-
DNS 服务器会尽可能回答尽可能多的请求,但设计上不会在任何负载下崩溃。
有关处理超载的更多想法,请参见第八章。
DoS 缓解系统
自动防御,例如限制前几个 IP 地址或提供 JavaScript 或 CAPTCHA 挑战,可以快速而一致地缓解攻击。这使得事件响应团队有时间了解问题,并确定是否需要自定义缓解措施。
自动 DoS 缓解系统可以分为两个组件:
检测
系统必须对传入流量有尽可能详细的可见性。这可能需要在所有端点进行统计抽样,并将其汇总到一个中央控制系统。控制系统识别可能表明攻击的异常情况,同时与了解服务容量的负载均衡器一起确定是否需要响应。
响应
系统必须具有实现防御机制的能力,例如,提供一组要阻止的 IP 地址。
在任何大规模系统中,误报(和误报)是不可避免的。当通过 IP 地址阻止时,尤其如此,因为多个设备共享单个网络地址是很常见的(例如,在使用网络地址转换时)。为了最小化对相同 IP 地址后面的其他用户造成的附带损害,您可以利用 CAPTCHA 来允许真实用户绕过应用程序级别的阻止。
您还必须考虑 DoS 缓解系统的故障模式 - 问题可能由攻击,配置更改,不相关的基础设施故障或其他原因触发。
DoS 缓解系统本身必须对攻击具有弹性。因此,它应避免依赖可能受到 DoS 攻击影响的生产基础设施。这些建议不仅适用于服务本身,还适用于事件响应团队的工具和通信程序。例如,由于 Gmail 或 Google Docs 可能会受到 DoS 攻击的影响,Google 拥有备用通信方法和 playbook 存储。
攻击通常会导致立即中断。虽然优雅降级可以减少过载服务的影响,但最好的情况是 DoS 缓解系统可以在几秒钟而不是几分钟内做出响应。这种特性与缓慢部署变更的最佳实践产生自然的紧张关系,以防止中断。作为一种权衡,我们可以在我们的生产基础设施的子集上对所有变更(包括自动响应)进行金丝雀测试,然后再将其部署到所有地方。金丝雀测试可能非常简短 - 在某些情况下可能只有 1 秒钟!
如果中央控制器失败,我们不希望出现关闭失败(因为这将阻止所有流量,导致故障)或者开放失败(因为这将让正在进行的攻击通过)。相反,我们失败静态,这意味着策略不会改变。这允许控制系统在攻击期间失败(这实际上在 Google 发生过!)而不会导致故障。因为我们失败静态,DoS 引擎不必像前端基础设施那样高度可用,从而降低成本。
战略性响应
在应对故障时,很容易纯粹是被动的,并尝试过滤当前的攻击流量。虽然快速,但这种方法可能并不是最佳的。攻击者可能在第一次尝试失败后放弃,但如果他们不放弃呢?对手有无限的机会来探测防御并构建绕过。战略性的响应避免通知对手对您的系统的分析。例如,我们曾经收到一个攻击,它通过其User-Agent: I AM BOTNET.轻松识别。如果我们简单地丢弃所有带有该字符串的流量,我们将教会我们的对手使用更合理的User-Agent,比如Chrome。相反,我们列举了发送该流量的 IP,并拦截了他们一段时间内的所有请求,使用验证码。这种方法使对手更难使用A/B 测试来了解我们如何隔离攻击流量。即使他们修改为发送不同的User-Agent,它也会主动阻止他们的僵尸网络。
了解对手的能力和目标可以指导您的防御。小型放大攻击表明您的对手可能仅限于可以发送伪造数据包的单个服务器,而重复获取同一页面的 HTTP DDoS 攻击表明他们可能可以访问僵尸网络。但有时“攻击”是无意的-您的对手可能只是试图以不可持续的速度抓取您的网站。在这种情况下,您最好的解决方案可能是确保网站不容易被抓取。
最后,请记住您并不孤单-其他人也面临类似的威胁。考虑与其他组织合作,以改善您的防御和响应能力:DoS 缓解提供商可以清除某些类型的流量,网络提供商可以执行上游过滤,网络运营商社区可以识别和过滤攻击源。
处理自我造成的攻击
在主要故障的肾上腺素飙升期间,自然反应是专注于打败对手的目标。但如果没有对手可以打败呢?突然增加流量的一些其他常见原因。
用户行为
大多数时候,用户做出独立的决定,他们的行为平均成为平滑的需求曲线。然而,外部事件可以同步他们的行为。例如,如果夜间地震唤醒了人口中的每个人,他们可能会突然转向他们的设备搜索安全信息,发布到社交媒体,或者与朋友联系。这些同时的行动可能导致服务接收到突然增加的使用,就像图 10-2 中显示的流量峰值一样。
图 10-2:当 2019 年 10 月 14 日发生 4.5 级地震时,测量每秒 HTTP 请求达到谷歌基础设施的网络流量,为旧金山湾区的用户提供服务
我们通过设计更改来解决这种“攻击”:我们推出了一个功能,当您输入时会建议单词完成。
客户端重试行为
一些“攻击”是无意的,只是由于软件的不当行为。如果客户端期望从服务器获取资源,而服务器返回错误,会发生什么?开发人员可能认为重试是合适的,如果服务器仍在提供错误,就会导致循环。如果许多客户端陷入这种循环,由此产生的需求会使从停机中恢复变得困难。⁹
客户端软件应该被精心设计以避免紧密的重试循环。如果服务器失败,客户端可能会重试,但应该实现指数退避——例如,每次尝试失败时等待时间加倍。这种方法限制了对服务器的请求次数,但单独使用是不够的——停机会同步所有客户端,导致高流量的重复突发。为了避免同步重试,每个客户端应该等待一个随机的持续时间,称为抖动。在谷歌,我们在大多数客户端软件中实现了带有抖动的指数退避。
如果你不能控制客户端会怎么办?这是运营权威 DNS 服务器的人们的一个常见关注点。如果他们遭受停机,合法递归 DNS 服务器的重试率可能会导致流量显著增加——通常是正常使用量的 30 倍左右。这种需求会使从停机中恢复变得困难,并经常挫败找到其根本原因的尝试:运营商可能认为 DDoS 攻击是原因,而不是症状。在这种情况下,最好的选择是简单地回答尽可能多的请求,同时通过上游请求限流保持服务器的健康。每个成功的响应都将允许客户端摆脱其重试循环,问题很快就会得到解决。
结论
每个在线服务都应该为 DoS 攻击做好准备,即使他们认为自己不太可能成为目标。每个组织都有它可以吸收的流量上限,防御者的任务是以最有效的方式减轻超出部署能力的攻击。
重要的是要记住你的 DoS 防御的经济约束。简单地吸收攻击很少是最廉价的方法。相反,利用成本效益的缓解技术,从设计阶段开始。在遭受攻击时,考虑所有选项,包括阻止有问题的托管提供商(可能包括少量真实用户)或遭受短期停机并向用户解释情况。还要记住,“攻击”可能是无意的。
在服务堆栈的每一层实现防御措施需要与几个团队合作。对于一些团队来说,DoS 防御可能不是首要任务。为了获得他们的支持,要关注 DoS 缓解系统可以提供的成本节约和组织简化。容量规划可以专注于真实用户需求,而不需要在堆栈的每一层吸收最大规模的攻击。使用 Web 应用程序防火墙(WAF)过滤已知的恶意请求,允许安全团队专注于新型威胁。如果发现应用程序级别的漏洞,同样的系统可以阻止利用尝试,让开发团队有时间准备补丁。
通过仔细的准备,你可以按照自己的条件确定服务的功能和故障模式,而不是对手的条件。
¹ 为了讨论的方便,我们将专注于常见情况,即攻击者没有物理接触和挖掘机,也不知道崩溃漏洞。
² 一些勒索者会发动小规模的“示范攻击”来促使目标付款。几乎所有情况下,这些攻击者没有能力发动更大规模的攻击,如果他们的要求被忽视,他们也不会再做进一步的威胁。
(3)参见 Rossow, Christian. 2014. “Amplification Hell: Revisiting Network Protocols for DDoS Abuse.” Proceedings of the 21st Annual Network and Distributed System Security Symposium. doi:10.14722/ndss.2014.23233.
(4)基于 TCP 的协议也可以被利用进行这种类型的攻击。有关讨论,请参见 Kührer, Mark 等人。2014. “Hell of a Handshake: Abusing TCP for Reflective Amplification DDoS Attacks.” Proceedings of the 8th USENIX Workshop on Offensive Technologies. https://oreil.ly/0JCPP.
(5)有状态防火墙,执行连接跟踪,最适合用于保护发起出站流量的服务器。
(6)如果服务处于全局超载状态,它们也可能会丢弃流量。
(7)我们的一个服务设计为所有 UI 元素使用了圆角。在最初的形式中,浏览器为每个角都获取了图像。通过更改站点以下载一个圆形,然后在客户端分割图像,我们每天节省了 1000 万个请求。
(8)在 synflood 攻击中,TCP 连接请求以高速发送,但不完成握手。如果接收服务器没有实现防御机制,它将耗尽内存来跟踪所有入站连接。常见的防御是使用 syncookies,提供一种无状态机制来验证新连接。
(9)请参阅SRE 书中的第 22 章。