2024-01学习笔记
1.关于数据库事务
这个博客写的挺好的,通俗易懂
用买票过程来讲解事务
MySQL——事物-CSDN博客

1.如何理解隔离性
1.MySQL服务可能会同时被多个客户端进程(线程)访问,访问的方式以事务方式进行
2.一个事务可能由多条SQL构成,也就意味着,任何一个事务,都有执行前执行中,,执行后的阶段。3.而所谓的原子性,其实就是让用户层,要么看到执行前,要么看到执行后。执行中出现问题,可以随时回滚。所以单个事务,对用户表现出来的特性,就是原子性。
4.但,毕竟所有事务都要有个执行过程,那么在多个事务各自执行多个SQL的时候,就还是有可能会出现互相影响的情况。比如:多个事务同时访问同一张表,甚至同一行数据。
5.就如同你妈妈给你说:你要么别学,要学就学到最好。至于你怎么学,中间有什么困难,你妈妈不关心。那么你的学习,对你妈妈来讲,就是原子的。那么你学习过程中,很容易受别人干扰,此时,就需要将你的学习隔离开,保证你的学习环境是友好,健康的。
6.数据库中,为了保证事务执行过程中尽量不受干扰,就有了一个重要特征:隔离性。
7.数据库中,允许事务受不同程度的干扰,就有了一种重要特征:隔离级别 。
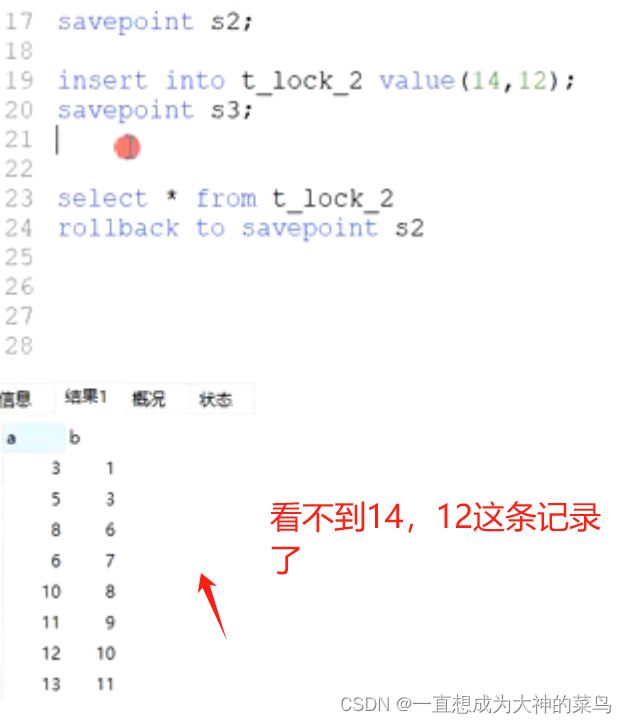
2.事务语法
跟代码里一样


2.maven的正式版和快照版
maven中的仓库分为两种,snapshot快照仓库和release发布仓库。snapshot快照仓库用于保存开发过程中的不稳定版本,release正式仓库则是用来保存稳定的发行版本。定义一个组件/模块为快照版本,只需要在pom文件中在该模块的版本号后加上-SNAPSHOT即可(注意这里必须是大写),如下:
com.zang.rc
registry
2.0.0-SNAPSHOT maven会根据模块的版本号(pom文件中的version)中是否带有-SNAPSHOT来判断是快照版本还是正式版本。如果是快照版本,那么在mvn deploy时会自动发布到快照版本库中,而使用快照版本的模块,在不更改版本号的情况下,直接编译打包时,maven会自动从镜像服务器上下载最新的快照版本。如果是正式发布版本,那么在mvn deploy时会自动发布到正式版本库中,而使用正式版本的模块,在不更改版本号的情况下,编译打包时如果本地已经存在该版本的模块则不会主动去镜像服务器上下载。
3.mybatis
1.预编译
#{ }可以实现预编译,会先把#{ }编译成?,在执行时再取值,可以防止sql注入。
${ }是直接进行字符串替换
2.一级缓存二级缓存
mybatis对缓存提供支持,一级缓存是默认使用的,二级缓存需要手动开启。
区别:
一级缓存的作用域是一个sqlsession内;
二级缓存作用域是针对mapper进行缓存;
3.mybatis和hibernate
mybatis是半自动ORM映射工具
hibernate属于全自动ORM映射工具
4.JVM
JVM全称为Java Virtual Machine,翻译过来就是java虚拟机,Java程序(Java二进制字节码)的运行环境
Java最大的一个优点是,一次编写,到处运行。之所以能够实现这个功能就是依靠JVM,这是因为JVM屏蔽字节码与操作系统之间的差异,对外提供了一致的运行环境。
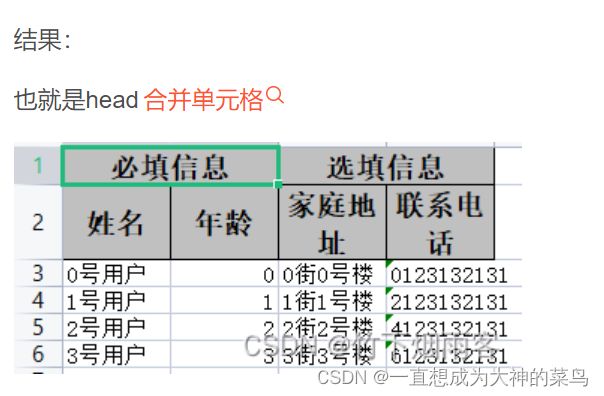
5.easyExcel合并表头
value是个数组,前边一样得情况下,后边表头会自动合并

6.事务注解
REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。

7.记录一次测试环境问题-内存溢出
测试环境每一两个小时就挂一次,日志报内存溢出。
我就把线上得内存模型下载下来,用mat打开,发现没有关闭得statment内存占比84%


检查了下代码,原来是同事直接用jdbc操作数据库,资源用完了没关闭。我在finally里边都关闭了重新部署,问题才解决

7.1说下内存分析工具使用
线上内存模型下载下来是一个.hrof后缀得文件,我用MemoryAnalyzer打开。
这个工具使用前提是,环境变量的jdk版本调整为17,否则报错
Version 1.8.0 92 of the JVM is not suitable for this product. Version: 17 orgreater is required.
打开之前先要修改MemoryAnalyzer.ini文件,-Xmx调整为比内存模型大的,我改成了-Xmx4g
文件打开后,调整到我截图的那个页面就能看到内存占比情况了
8.JWT
JWT 全称 JSON Web Token,JWT 主要用于用户登录鉴权,当用户登录之后,返回给前端一个Token,之后用户利用Token进行信息交互。
9.主键类型修改为自增后,需要注意的事
1.如果其实位点小于当前最大值,那么执行alter table时不报错,但是不会生效。
应该先删除表中的错误数据,再进行接下来的操作
2.生成的id特别大
原因:mytabits实体的id没加type = IdType.AUTO
解决办法:先把id特别大的数据删除,再重置起始位点,再把mybatis实体加上
@TableId(type = IdType.AUTO)3.部署环境之前需要检查数据库中数据
在部署环境之前应该删除目前id超大的数据,并且重置id起始位,否则下一个新增的数据会在最大的id基础上去新增
10.get请求前端在路径上携带了参数但是没传值

这样传,后端会认为是空字符串,而不是Null,所以处理上需要注意下
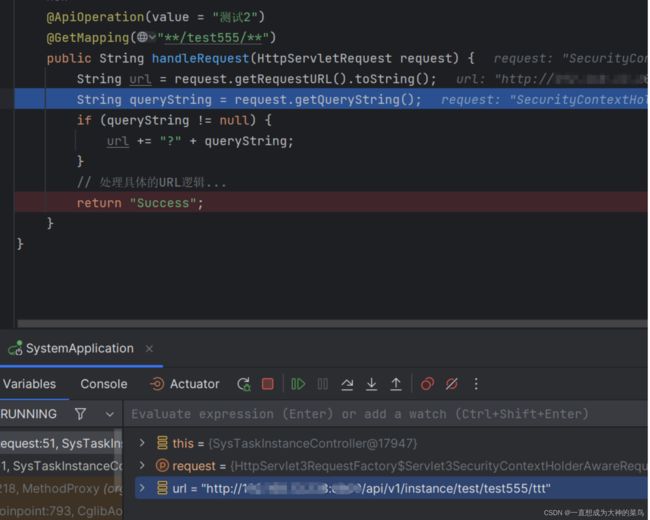
11.controller的请求路径也可以模糊匹配
12.主从,主主复制配置
为了防止数据冲突
auto_increment_offset主从不能一致,然后auto_increment_increment主从必须一致

server-id不能相同
主从数据库,单向同步,主负责写,主往从同步
13.分库分表中间件
水平分表/库:分担数据量
垂直分表/库:按功能(订单,购物车,商品)
可以即水平,又垂直
Mycat
想要做分库分表,要是自己去处理逻辑那比较麻烦,需要处理分配规则,存取规则,分布式事务。用中间件能方便些
14.undo commit
这是一条好用的git命令
使用场景:
在commit之后,push之前用
我有一次忘记把本地分支切回来了,直接在test分支上开发的,解决方式就是在test上先把本地写的commit了,然后在本地切到dev,用dev去合并本地的test。
合并之后再切回到本地test,在idea上去undo commit,代码就不见了
15.nginx的正向代理反向代理

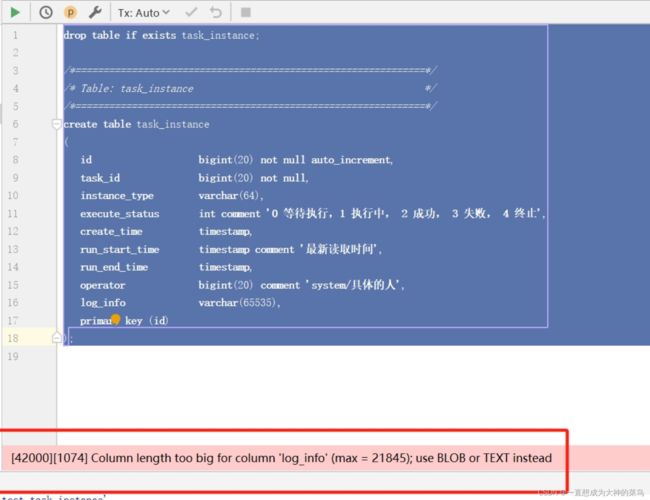
16.数据库长度定义
不是65535,和字符集有关

 17.数据库发生死锁
17.数据库发生死锁
可以在查询死锁后,执行
kill 线程id终止死锁事务后,需要重新执行被终止的事务。这可能需要一些逻辑处理,例如对数据进行回滚或者重新执行一些操作。
18.几个概念
SQL(Structured Query Language)
客户端/服务器模式 C/S
5.7前为中小型数据库
5.8后为中大型数据库 MySQL5.8为MySQL8
AOP:用于在不修改原始代码的情况下向现有应用程序添加新功能
定义数据库表结构字段时候最好不要用数据库关键字,比如描述desc最好改为description,name改为xx_name
19.防重放
19.1防重放是什么?
入侵者 C 可以从网络上截获 A 发给 B 的报文。C 并不需要破译这个报文(因为这
可能很花很多时间)而可以直接把这个由 A 加密的报文发送给 B,使 B 误认为 C 就是 A。然后
B 就向伪装是 A 的 C 发送许多本来应当发送给 A 的报文

19.2如何解决
1.时间戳用盐加密,先判断是否过期,限制60s
2.结合布隆过滤器
20.get请求传入[ ]这类字符 返回400错误解决
这个是帮同事看问题,发现了这个
因为get请求会将参数拼接在url之后,故参数中包含’[‘、’]'字符就会返回400。
解决办法:
- 把get请求改成post请求
- 对请求进行编码,拼在url后面的参数,先用encodeURI()转义
21.redis
都说redis是内存服务器,它占用的是redis服务器得内存,而不是什么jvm的堆栈内存
而且一般redis服务器,和java服务器都不是同一台机器,而且都是部署在内网,互相访问也比较快

RDB:Redis Dababase Backup
AOF:Append Only File
22.数据库三范式
数据库三大范式(图文详解)-CSDN博客
最常用的三大范式
第一范式(1NF):属性不可分割,即每个属性都是不可分割的原子项。(实体的属性即表中的列)
第二范式(2NF):满足第一范式;且不存在部分依赖,即非主属性必须完全依赖于主属性。(主属性即主键;完全依赖是针对于联合主键的情况,非主键列不能只依赖于主键的一部分)
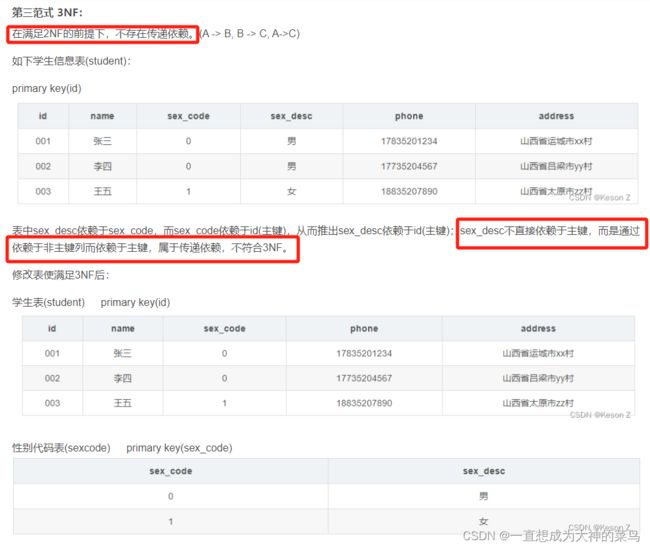
第三范式(3NF):满足第二范式;且不存在传递依赖,即非主属性不能与非主属性之间有依赖关系,非主属性必须直接依赖于主属性,不能间接依赖主属性。(A -> B, B ->C, A -> C)


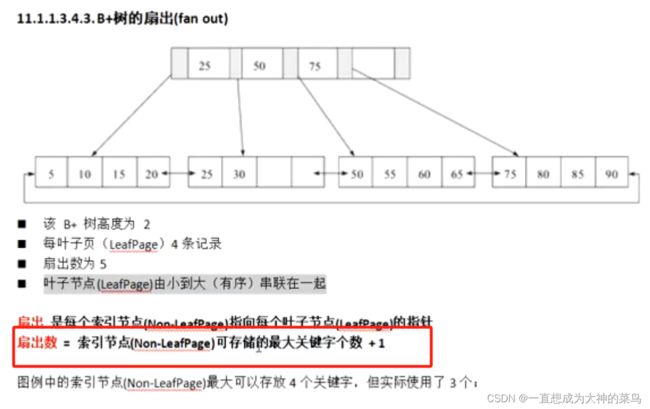
23.B+树
b意为balance
扇出数是指一个节点所拥有的子节点数量

 24.KONG
24.KONG
kong基于nginx,所以当kong挂了也会出现503
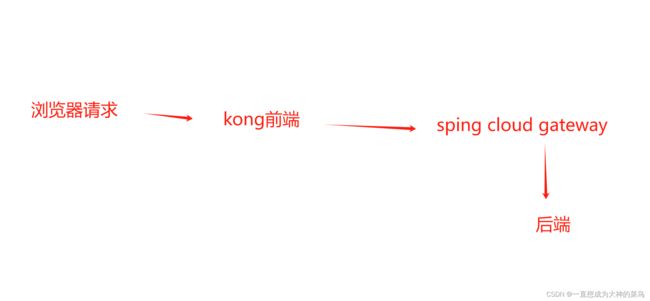
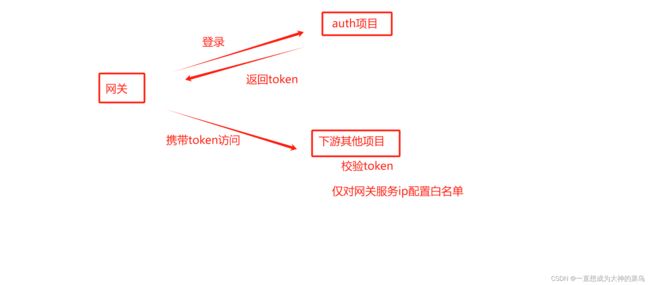
扩展下 ,网关设计有两种方式

25.泛型优点
1.统一处理
2.效率高(不用来回转换)
3.安全,不用强转,减少报错
将运行时期出现的classCastException转换成编译时出现,方便程序员解决问题,减少安全隐患。
避免了强制转换的麻烦。所以我们在使用迭代器的时候我们一定要添加泛型,不然就是要强行转换。