如何用Prometheus和Grafana监控多云Kubernetes

介绍

为什么可能需要监控不止一个Kubernetes集群,一般有两大原因。第一个场景是不同阶段各有专门的集群,比如开发集群,预生产集群和生产集群。另一个场景是集群上运行着受托服务,或者有客户在集群上运行着工作负载,而你需要监控集群的可靠性,或者是监控自己服务的消费情况。
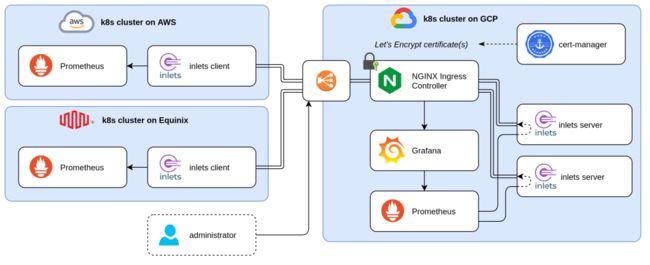
使用Prometheus和inlets监控多集群Kubernetes
上图架构图左侧我们有多个“Client(客户)”集群。使用的是Prometheus,它是应用广泛的,开源的,基于metric的监控和报警系统,正主动监控着应用程序和集群。每个集群的监控很健壮也很完整;但是,没有统一的视图来展现跨集群的metric。
使用安全的inlets tunnel,可以从右侧的集群访问到这些Prometheus服务器。这样,左侧的Prometheus服务器就可以从其他Prometheus服务器里获得选定的时间序列,这也就是Prometheus Federation[1]。
对于长期的存储,你可能还会考虑Thanos或者Cortex。
让我们看看这一切是如何实现的!
前提条件
一些运行在不同地方的Kubernetes集群,比如,在公有云上(比如GKE,AKS,EKS,DOKS等)或者在私有云里。
kubectl,配置好并且可以连接到集群上
kubectx,可选,但是在管理不同集群时很有用
arkade,便携的Kubernetes marketplace
一个域并且可以访问DNS管理panel去创建子域
本文使用inlets PRO是因为它很容易配置,并且遇到问题可以获得支持,但如果你想自己配置也可以使用免费版的inlets。
两个版本的区别在这里:inlets文档[2]。
本文准备了3个Kubernetes集群:
运行在Equinix Metal的Kubernetes集群,orion-equinix
运行在Amazon Web Services的Kubernetes集群,orion-aws
运行在Google Cloud Platform的Kubernetes集群,orion-gcp
前两个集群作为“客户”集群,monitoring的namespace里运行了Prometheus服务器。除了Prometheus,还安装了一些metric的导出器,比如node-exporter,kube-state-metrics和我的最爱kube-eagle。
第三个集群作为“Observability(观测)”集群,和前两个类似,也安装了Prometheus。
有多种方式来安装Prometheus和所有组件,但是最常用的还是使用Prometheus Operator或者官方的Helm chart来安装。
$ kubectx
orion-aws
orion-gcp
orion-equinix
$ kubectl get pods,services --context orion-aws -n monitoring
NAME READY STATUS RESTARTS AGE
pod/node-exporter-dh75f 1/1 Running 0 63m
pod/kube-eagle-6687579fd8-xcsns 1/1 Running 0 63m
pod/prometheus-54d7b46745-lvbvk 1/1 Running 0 63m
pod/node-exporter-w6xx6 1/1 Running 0 63m
pod/node-exporter-p7dbv 1/1 Running 0 63m
pod/kube-state-metrics-7476dc6466-74642 1/1 Running 0 63m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus ClusterIP 10.43.97.123 9090/TCP 63m
$ kubectl get pods,services --context orion-equinix -n monitoring
NAME READY STATUS RESTARTS AGE
pod/node-exporter-mzbv2 1/1 Running 0 61m
pod/prometheus-67746cf46c-twbjk 1/1 Running 0 61m
pod/node-exporter-9m4nc 1/1 Running 0 61m
pod/kube-eagle-546bd88874-p4wfd 1/1 Running 0 61m
pod/node-exporter-fjjqv 1/1 Running 0 61m
pod/kube-state-metrics-cbfb75b4-kndwz 1/1 Running 0 61m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/prometheus ClusterIP 10.43.148.58 9090/TCP 61m
准备观测集群
首先需要准备观测集群。目标是要让运行在远端“客户”集群的Prometheus服务器在观测集群里也能用。要实现这个目标,我们使用inlets PRO来创建观测和客户集群之间的安全通道(tunnel)。这些tunnel的服务器,exit-node必须在观测集群里创建,之后,客户端就可以连接并且将Prometheus连接到观测集群了。
我们没有用LoadBalancer来暴露每个exit-node,而是使用IngressController,比如Nginx,联合cert-manager来获取证书。
首先,切换到正确的集群:
$ kubectx orion-gcp
Switched to context "orion-gcp".
使用arkade安装Nginx Ingress控制器和cert-manager:
arkade install ingress-nginx --namespace ingress-nginx
arkade install cert-manager --namespace cert-manager
等Nginx负载均衡器创建好后,可以得到它的公开IP地址,将域指向这个IP。每个客户端都会连接到不同的子域,因此最简单的方式是创建带通配符的DNS记录(比如:*.prometheus.example.com)。如果你不喜欢通配符记录,那就将每个Prometheus客户端的记录都指向相同的公开IP地址(比如:rion-aws.prometheus.example.com,orion-equinix.prometheus.example.com……)。
安装证书Issuer:
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: letsencrypt-prod
namespace: monitoring
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory
email:
privateKeySecretRef:
name: letsencrypt-prod
solvers:
- selector: {}
http01:
ingress:
class: nginx
kubectl apply -f issuer-prod.yaml
为inlets服务器生成一个token:
export TOKEN=$(head -c 16 /dev/random | shasum|cut -d" " -f1)
kubectl create secret generic inlets-pro-secret -n monitoring --from-literal token=$TOKEN
# Save a copy for later
echo $TOKEN > token.txt
在dataplane创建带有所需端口的自定义文件。比如Prometheus,使用的是9090端口:
dataPlane:
type: ClusterIP
ports:
- targetPort: 9090
protocol: TCP
name: prom-http
port: 9090
现在获得inlets-pro的helm chart,并为每个远端Prometheus服务安装这个chart。
git clone https://github.com/inlets/inlets-pro
helm install orion-aws ./inlets-pro/chart/inlets-pro \
-n monitoring -f custom.yaml \
--set ingress.domain=orion-aws.prometheus.example.com
helm install orion-equinix ./inlets-pro/chart/inlets-pro \
-n monitoring -f custom.yaml \
--set ingress.domain=orion-equinix.prometheus.example.com
安装完的结果是:
inlets PRO服务器Pod运行
ClusterIP类型的Control Plane服务创建出来,暴露端口8123
带有证书的Ingress创建出来,以安全的方式暴露Control Plane服务
ClusterIP类型的Data Plane服务创建出来,暴露端口9090
这意味着inlets PRO客户端能够使用合适的域名,比如wss://orion-aws.prometheus.example.com/connect连接到Control Plane上,并且不对外暴露9090端口,让它只能从集群内部访问,因为这是ClusterIP类型。
连接到客户集群
既然exit-node pod已经运行起来了,现在就可以连接到客户端,并且创建tunnel了。
在客户集群里执行如下步骤。
切换kubectl连接到正确的客户集群:
$ kubectx orion-aws
Switched to context "orion-aws".
为inlets PRO创建secret和token:
kubectl create secret generic \
-n monitoring inlets-license \
--from-file license=$HOME/inlets-license
kubectl create secret generic \
-n monitoring inlets-pro-secret \
--from-file token=./token.txt
配好合适的值,安装inlets-pro-client,在观测集群里连接到exit-node pod上:
helm install prometheus-tunnel \
./inlets-pro/chart/inlets-pro-client \
-n monitoring \
--set url=wss://orion-aws2.prometheus.sphene.io/connect \
--set upstream=prometheus \
--set ports=9090
监控客户集群
安装好所有helm chart,服务器和客户端之后,所有的Prometheus服务在观测集群里都可用了,现在我们就可能在Grafana里可视化这些metric了。
要么将所有不同的Prometheus服务器都作为独立的数据源添加到Grafana里,要么在Prometheus服务器上配置这些endpoint。绝大多数情况下优先使用第二种方案,因为这让我们可以创建聚合视图。
添加这些的最简单的方式是通过静态配置:
scrape_configs:
- job_name: 'federated-clusters'
scrape_interval: 15s
honor_labels: true
params:
'match[]':
- '{app="kube-state-metrics"}'
- '{app="kube-eagle"}'
- '{app="node-exporter"}'
metrics_path: '/federate'
static_configs:
- targets:
- 'orion-aws-inlets-pro-data-plane:9090'
- 'orion-equinix-inlets-pro-data-plane:9090'
应用这些配置后,本文开头图中右侧的Prometheus就会开始从其他Prometheus服务器上抓metric了。
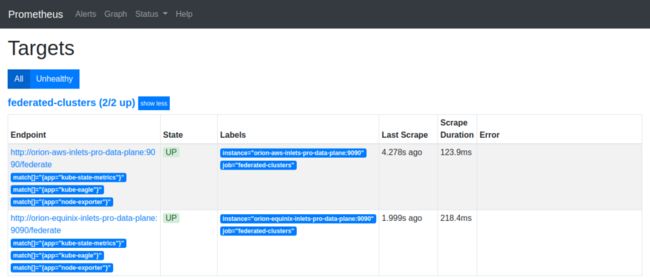
现在所有metric都被收集到一个Prometheus服务器上,剩下的事情就是构建漂亮的dashboard和alert。
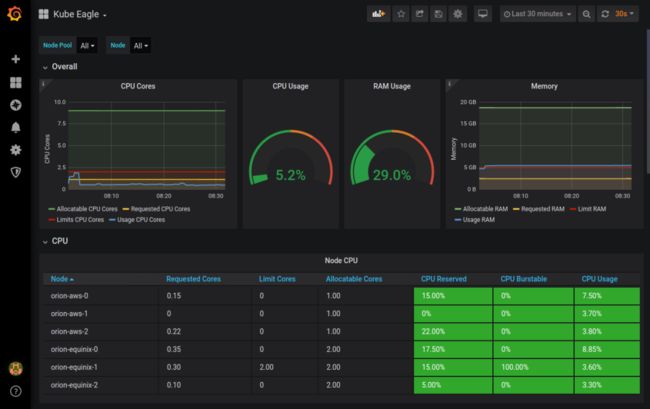
Kube Eagle仪表盘,多集群概览
总结
本文展示了如何将多个隔离的,分散在不同云供应商的Kubernetes集群,或者私有环境里的服务连接起来。
安全tunnel,服务器和客户端的Helm chart让安装变得很简单。
Prometheus Fedaration很好地展现了这些技术。这样的搭建方式在很多情况下都可以用,比如将应用程序连接到不同集群的数据库上。
相关链接:
https://prometheus.io/docs/prometheus/latest/federation/
https://inlets.dev/
原文链接:https://inlets.dev/blog/2020/12/15/multi-cluster-monitoring.html
Kubernetes管理员认证(CKA)培训
本次CKA培训在上海开班,基于最新考纲,通过线下授课、考题解读、模拟演练等方式,帮助学员快速掌握Kubernetes的理论知识和专业技能,并针对考试做特别强化训练,让学员能从容面对CKA认证考试,使学员既能掌握Kubernetes相关知识,又能通过CKA认证考试,学员可多次参加培训,直到通过认证。点击下方图片或者阅读原文链接查看详情。
