#Paper Reading# Training language models to follow instructions with human feedback
论文题目: Training language models to follow instructions with human feedback
论文地址: https://arxiv.org/abs/2203.02155
论文发表于: arXiv 2022
论文所属单位: OpenAI
论文大体内容
本文主要提出了GPT-3.5(InstructGPT)模型,通过使用人类反馈的数据集进行监督学习(RLHF,即reinforcement
learning from human feedback),对GPT模型进行Fine-tune,来达到预期效果。
Motivation
本文作者发现,GPT无论多大,都无法遵循人类的意图(Alignment),也就是说继续使用无监督学习去扩大模型始终无法达到使用目的(编造事实、生成有偏见或有毒的文本)。
Contribution
①本文提出构建人类反馈的数据集,使用监督学习去Fine-tune GPT模型,这样能使得模型往大家希望的方向行进(模型输出与人类意图Alignment)。
②Fine-tune后,仅使用13亿参数量的GPT-3.5比1750亿参数量的GPT-3效果要好。
1. 本文提出的GPT-3.5的模型架构图如下,主要分为3部分:

①SFT(Supervised Fine-Tuning):根据人工标注的数据集,进行Fine-tune GPT-3[1]模型;
②RM(Reward Model):人工对Output的结果进行标注,根据结果的得分相对关系,训练Reward Model;

③PPO(Proximal policy optimization):使用PPO算法去优化SFT的输出,让其在RM中得到更好的分数;

2. GPT-3.5的Output相比GPT-3:
①质量提升;
②真实性提升;
③有毒性降低;
④通过修改RLHF可以降低公共数据集的损失;
⑤对于没有标注过数据的人员,也认为GPT-3.5的质量比GPT-3好;
⑥公共数据集不太适用;
⑦拥有泛化能力;
⑧仍然会犯一些错误;
3. 训练中帮助度优先,而评估时真实性和无害性优先,会存在两者目标conflict的情况;
4. Evaluation的时候,主要是怎么定义Alignment,本文是通过helpful,honest,harmless三个层面来体现Alignment;
实验
5. Dataset
数据集Size

RM dataset分布
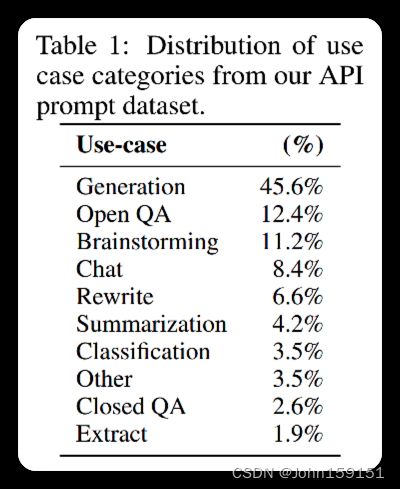
Prompt dataset例子

6. 本文主要做2方面的实验来证明RLHF的有效性:
①人工评测Output,打分维度如下;

②公开NLP数据集的评测,主要关注truthfulness,toxicity,bias;
7. 人工评测Output实验结果



8. 公开NLP数据集的实验结果
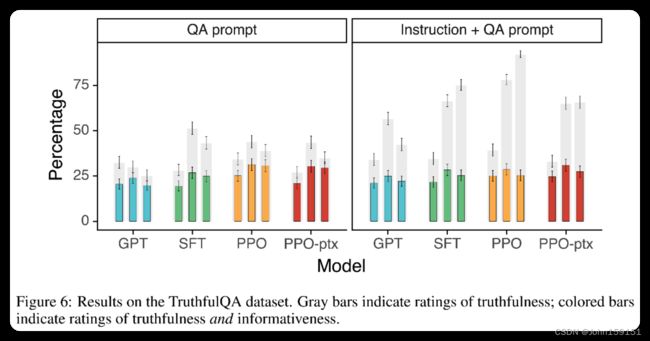

9. 作者对GPT-3.5在其泛化性上的表现感到吃惊,尤其在非英语任务上和coding任务上,这两部分在训练数据集中占得比例很少,却也能表现的很好;
10. GPT-3.5常见的错误
①问题中带有错误的前提,模型会将这个前提错误地认为是真的;-->训练集中没有错误的前提数据;
②回答过于转弯抹角,显示出模型在乱说话;-->可能跟RM数据集的标注有关,乱说话比不说话得分高;
③问题含有较多限制条件,会导致模型效果下降;
作者提出可以加入对抗性数据集,能降低这些错误。
11. 本文对于alignment的一些经验
①相对于pre-train,alignment的cost不多且可接受;
②GPT-3.5的泛化性强,比如在非英语任务上和coding任务上;
③可以降低Fine-tune带来的效果降低问题;
④alignment在实际应用上验证有效;
12. GPT-3.5的表现受限于标注者的观点和价值取向;
13. 思考
虽然ChatGPT的表现引发了一轮轰动,但是我觉得我们离真正的人工智能还有很远。从ChatGPT的技术原理以及表现来看,该模型只是擅长于language,而非thought。而这两者有着本质的区别(thought != language)。
当我们构建像GPT这样的LM系统时,尽管它的工作方式与人类的根本不同,但是其能力越来越类似于人类,所以我们也将其视为像人的系统。但是,LM只是由大量人类生成文本公共语料库中标记统计分布所生成的数学模型,这个模型的主要作用就是我们问它具体的问题,比如:这是一段文字,告诉我这个片段会如何继续下去。或者:根据你的语言统计模型,接下来可能会出现什么词?
一个简单的LM并不能“知道”某件事情,而它只是做了一些序列预测。模型本身没有真或假的概念,因为它缺乏像我们那样以任何方式运用这些概念的方法。不过有了这个language技能,应用于AIGC倒是可以,尤其现在泛内容这么多。后续肯定也会从NLP到Image到Video,期待其在短视频的颠覆。
参考资料
[1] GPT-3 https://blog.csdn.net/John159151/article/details/129128224
[2] GPT-2 https://blog.csdn.net/John159151/article/details/129098787
[3] GPT-1 https://blog.csdn.net/John159151/article/details/129062724
[4] GPT-3 Github https://github.com/openai/gpt-3
[5] Paper reading by Li Mu https://www.bilibili.com/video/BV1hd4y187CR/
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!