rime中州韵小狼毫 联想词组 滤镜
在 rime中州韵小狼毫 自定义词典 一文中,我们分享了如何在rime中州韵小狼毫须鼠管输入法中定义用户自定义词典;通过自定义词典,我们可以很方便的在输入法中加入个性化的词组。
根据 rime中州韵小狼毫 滤镜与字典的区别 一文所分析,通过自定义词典所定义和管理的个性化词组,会受到输入方案的耦合影响,这导致我们无法方便的直接的分享我们的自定义词典配置;并且对于一些动态词组(例如实时时间,实时日期,电脑信息等),也无法通过配置自定义词典来实现。
本文分享rime中州韵小狼毫须鼠管输入法的一个联想词组滤镜配置。该滤镜可以在候选列表中出现关键词组时,抛出附加的新的词组,例如下图中带有标记的词组,即为联想词组:

联想词组字典
联想词组字典的目的是提供有联想关系的词组,例如由词组“夫妻”,联想到词组“伉俪”,再如由词组“进步”,联想到词组“进步开始于起步”。
联想词组字典是txt的文档,lua滤镜脚本支持多个txt文档分类管理不同的联想词组,且滤镜脚本会自动进行去重处理。
联想词组字典文档内支持以符号#开头的行作为注释行,以提升词组管理的便捷性。
联想词组文档内的文本分为2列,以tab制表符分隔。第1列为关键词组,关键词组可以有多个,以空格分隔。第2列为联想词组,联想词组可以有多个,以空格分隔。联想词组的联想是意向的,即只能由第1更的关键词组联想到第2列的联想词组,但是可以通过使第1列与第2列相等来实现相互联想,例如 “夫妻 伉俪 →夫妻 伉俪”,这样可以使“夫妻”和“伉俪”相互联想。
phraseExt commonPhrase.txt
phraseExt commonPhrase.txt文档用于管理一般性的公共性的联想词组,phraseExt commonPhrase.txt词组定义截取如下:
# 支持使用 来定义空格,而正常的空格被用于分词
# 常用链接
知乎 https://www.zhihu.com
百度 度娘 www.baidu.com
淘宝 www.taobao.com
谷歌 谷哥 谷姐 www.google.com
画图 几何 画板 https://webgeo-8gn07v0t78c4ca57-1308819187.tcloudbaseapp.com
# 常用称呼
运气 华盖 运气 华盖
南冠 囚犯 南冠 囚犯
伉俪 夫妻 伉俪 夫妻
丝竹 音乐 丝竹 音乐
烽烟 战争 狼烟 战争 烽烟 狼烟
phraseExt esAppEmoji.txt
phraseExt esAppEmoji.txt文档用于管理一些应用专属的emoji表情,例如我们可以在微信聊天中输入 [微笑],则微信会将其自动转换成 emoji 表情符号 。我们在phraseExt esAppEmoji.txt文档中定义了一系列的此类emoji表情词组。phraseExt esAppEmoji.txt词组定义截取如下:
done 完成 搞定 esFs[完成] esDt[Done]
get 了解 知道 esFs[了解] esDt[Get]
no 不行 esFs[No] esFs[叉号] esDt[打叉]
错 错误 esFs[叉号] esDt[打叉]
ok 行 好的 好吧 可以 esFsWxDt[OK]
好 好的 esFs[Yes] esWx[好的]
行 esFs[我看行] esFs[好的]
okr 绩效 esFsDt[OKR]
如上,phraseExt esAppEmoji.txt 文档中的联想词组,以AppName作为前缀,不同的App应用,前缀符号映射如下:
| 应用 | 前缀 |
|---|---|
| 微信 | Wx |
| 飞书 | Fs |
| 钉钉 | Dt |
注意:
特别的,AppEmoji的联想,需要配置应用开关才可以使用,关于应用开关的配置,请参考 rime中州韵小狼毫 weasel.custom.yaml 配置 之 输入环境识别 一文。
phraseExt esUnicode.txt
在Unicode字符集中,存在着丰富的 emoji符号,如果不善于利用,则实在可惜。phraseExt esUnicode.txt文档专门用来管理与 Unicode 表情符号有关的联想词组,phraseExt esUnicode.txt联想词组定义截取如下:
垃圾 垃圾桶
开水
轮椅 残疾 无障碍 ♿
厕所
厕所 男人 男厕
厕所 女人 女厕
善于使用 Unicode 表情符号,会使你成为一个高情商的人。
phraseExt personal.txt
顾名思义,phraseExt personal.txt文档是用来管理一些个人和,私有的联想词组的,例如你的电话号码,例如你的邮寄地址,再如你的爱情口头禅。phraseExt personal.txt联想词组定义示例如下:
# 支持使用 来定义空格,而正常的空间被用于分词
# 这个字典用于管理 个人/私人 信息,以便在共享/分享rime配置时,可以方便的将个人信息进行隔离
# 常用联系方式
电话 手机 123456789AB 123456789AC
快递 地址 湖南省长春市快乐区开心社区2栋305室
# 常用办公信息
工号 000000
邮箱 [email protected]
快递 地址 浙江省杭州市阿里马马集团2号快递收发室
# 其它常用信息
博客 https://www.myblogs.com
如果你与它人分享你的rime输入法的配置方案,phraseExt personal.txt 的存在将使得你可以快速的将个人/私人信息与配置方案进行隔离。
phraseExt_Module.lua
phraseExt_Module.lua 是一个lua脚本文档,phraseExt_Module.lua脚本文档的使用是将以上所管理的联想词组加载到lua程序中,并提供合适的检索方法接口,以便rime引擎可以使用联想词功能。phraseExt_Module.lua脚本内容如下:
-- myPhrase.lua
-- Copyright (C) 2023 yaoyuan.dou 以上脚本中,我们在M.init() 方法中看到了联想词组字典的加载方法:table.insert(files,"phraseExt personal.txt"),你如果有其它的联想词组字典,你也可以很方便的加载它们。
phraseExt_Module.lua 脚本提供了一个名为getPhraseList方法,该方法可以根据指定的关键词组,从联想词组字典对象dict中检索并返回对应的联想词组。
phraseExt_Filter.lua
phraseExt_Filter.lua脚本实现了匹配rime引擎的Filter滤镜,phraseExt_Filter.lua脚本定义并返回了phraseExt_Filter滤镜方法,phraseExt_Filter.lua脚本内容如下:
-- myPhrase_Filter.lua
-- Copyright (C) 2023 yaoyuan.dou 以下脚本代码中,我们可以看到一组开关状态获取代码,如下:

这些开关变量,使得一些特定的词组(例如App表情)只会在对应的应用程序环境下才会出现。例如只有在微信中进行录入时,才会出现微信专有的emoji词组,而在txt环境下录入时,则不会出现微信专属的emoji词组,这大大提升了输入法的录入体验。
注意:
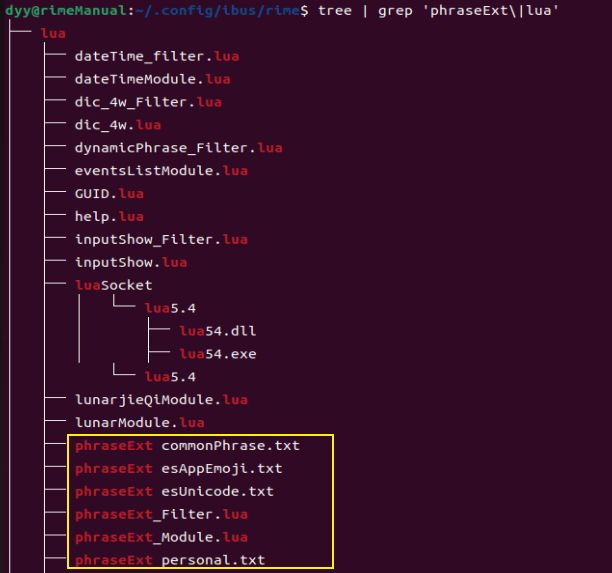
以上所述文档 phraseExt commonPhrase.txt、phraseExt esAppEmoji.txt、phraseExt esUnicode.txt、phraseExt personal.txt、phraseExt_Filter.lua、phraseExt_Module.lua 共6个文档,应该位于 用户文件夹下的 lua 文件夹内,如下:
rime.lua
rime.lua脚本的内容如下:
help_translator = require("help")
inputShow_translator = require("inputShow")
inputShow_Filter = require("inputShow_Filter")
Upper_Filter = require("Upper_Filter")
dic_4w_Filter = require("dic_4w_Filter")
phraseReplace_Filter = require("phraseReplace_Filter")
pinyinAdding_Filter = require("pinyinAdding_Filter")
dateTime_Filter = require("dateTime_filter")
dynamicPhrase_Filter = require("dynamicPhrase_Filter")
phraseExt_Filter = require("phraseExt_Filter")
述脚本,在最后一行中,我们加载了phraseExt_Filter滤镜。
wubi_pinyin.custom.yaml
以上, 我们完成了 phraseExt_Filter 滤镜的所有的功能定义,我们现在需要做的就是在我们的输入方案中配置使用该 phraseExt_Filter 滤镜。此处以五笔・拼音输入方案为例,展示如何配置使用 phraseExt_Filter 滤镜。
在 五笔・拼音 输入方案的方案文档 wubi_pinyin.schema.yaml 的补丁文档 wubi_pinyin.custom.yaml中,我们增加如下的Filters配置:
# encoding:utf-8
patch:
switches/+: #增加以下开关
- name: phraseExt # 候选词扩展开关
reset: 1
states: [Off, phraseExt]
engine/filters: # 设置以下filter
- simplifier
- lua_filter@phraseExt_Filter # 自定义短语滤镜,针对响应的关键字,添加新的选项进来
注意,以上配置并不是wubi_pinyin.custom.yaml的全部配置,此处仅展示了与phraseExt_Filter有关的部分。
文档获取
以上所述配置文档,你可以在 rime中州韵小狼毫须鼠管输入法 联想词组滤镜配置包.zip 下载取用。
如果你可以访问gitHub,你也可以在 dyyRime 中找到完全版本的配置包。
小结
文章分享了一种在rime中州韵小狼毫须鼠管输入法中配置联想词组滤镜的方法。通过分别在phraseExt commonPhrase.txt、phraseExt esAppEmoji.txt、phraseExt esUnicode.txt、phraseExt personal.txt四个文档中分类整理定义了不同的联想词组,然后在phraseExt_Filter.lua、phraseExt_Module.lua两个脚本文档中实现了phraseExt_Filter 滤镜功能。最后以五笔・拼音输入方案为例,展示了如何在 五笔・拼音 输入方案中配置使用 phraseExt_Filter 滤镜的方法,最实现了预期的功能效果。