数据同步工具chunjun(flinkx)-1.12.7 使用tips
目录
本文旨在记录chunjun使用过程中的tips,并且记录与官网描述不符的地方,以减少学习成本
1、在编写json的时候推荐使用在线json编辑器:
2、类似MySQL<—>MySQL这种需要编写带jdbcUrl的任务,注意reader和writer中jdbcUrl类型不一致
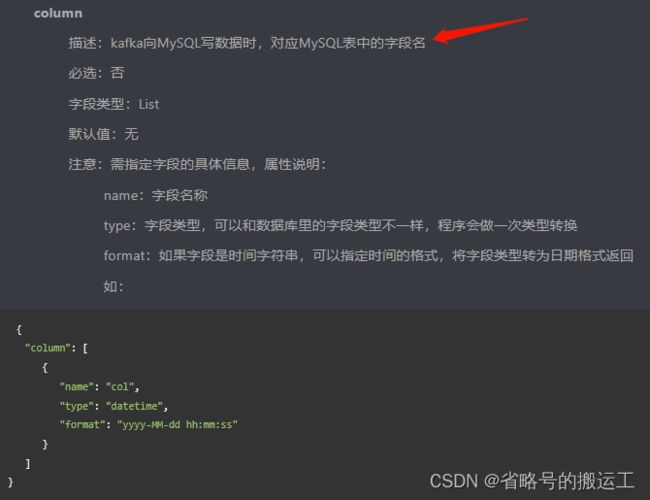
3、以kafka—>mysql举例解释字段间的映射关系
4、kafka—>mysql,当kafka输入脏数据时,mysql会写入空行
5、kafkareader,group-offsets模式读不到已提交offset的数据
本文旨在记录chunjun使用过程中的tips,并且记录与官网描述不符的地方,以减少学习成本
最简单快速上手的方法就是熟读官网文档(纯钧 (dtstack.github.io))中的连接器参数
1、在编写json的时候推荐使用在线json编辑器:
Editor | JSON Crack https://jsoncrack.com/editor这个工具可以检查json格式是否正确自动规范json格式,并且可以自动规范json格式,还可以生成树状图直观查看结构,避免因为json格式问题导致任务无法运行
https://jsoncrack.com/editor这个工具可以检查json格式是否正确自动规范json格式,并且可以自动规范json格式,还可以生成树状图直观查看结构,避免因为json格式问题导致任务无法运行
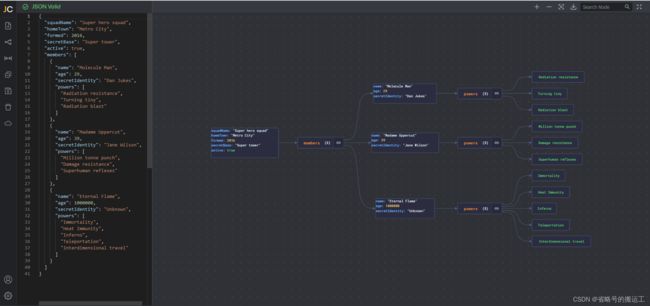
由于json格式问题引发的报错类似:Caused by: com.google.gson.stream.MalformedJsonException: Unterminated array at line 24 column 16 path $.job.content[0].reader.parameter.[1]
![]()
检查json格式后可以避免
2、类似MySQL<—>MySQL这种需要编写带jdbcUrl的任务,注意reader和writer中jdbcUrl类型不一致
在reader中jdbcUrl为Array

而writer中jdbcUrl为String

这与官网文档中的描述是不一致的

如果按照官网文档中写法,会产生格式匹配错误:
Caused by: java.lang.IllegalStateException: Expected STRING but was BEGIN_ARRAY at path $.jdbcUrl

3、以kafka—>mysql举例解释字段间的映射关系
kafka topic中有两种数据:
{"id":"1","name":"a1","A1":"0.001","A2":"0.005","A3":"100","A4":"abadc","A5":"eqerd"}
{"id":"2","name":"a2","A1":"0.001","A2":"0.005","A3":"5","A4":"abadc","A5":"eqerd"}
{"id":"3","name":"a3","A1":"0.1","A2":"0.3","A3":"20","A4":"","A5":"qerda"}
{"id":"4","name":"a4","A1":"0.00070","A2":"12.2","A3":"10","A4":null,"A5":"weaef"}
{"id":"5","name":"a5","A1":"0.1","A2":"0.3","A3":"20","A4":"adfsa","A5":"qerda"}
{"id":"6","name":"a1","A1":null,"A2":null,"A3":"100","A4":"abadc","A5":"eqerd"}
{"id":"1","name":"a1","B1":"0.1","B2":"5","B3":"GKLGU"}
{"id":"2","name":"a2","B1":"1.425","B2":"10","B3":"HJFV"}
{"id":"3","name":"a3","B1":"54.12","B2":"4325","B3":"FDGAD"}
{"id":"4","name":"a4","B1":"10.0","B2":"1","B3":null}
{"id":"5","name":"a5","B1":null,"B2":"11","B3":"SDF"}
{"id":"6","name":"a7","B1":null,"B2":null,"B3":null}
第一种包含id、name、A1、A2、A3、A4、A5字段
第二种包含id、name、B1、B2、B3字段
写入目标表字段 id、name、A1、A2、A3、A4、A5、B1、B2、B3
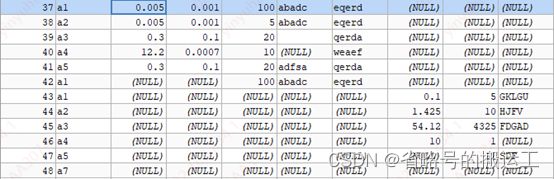
① 实验一:
kafkareader:name、A1、A2、A3、A4、A5、B1、B2、B3
mysqlwriter:name、A1、A2、A3、A4、A5、B1、B2、B3
结果正常写入
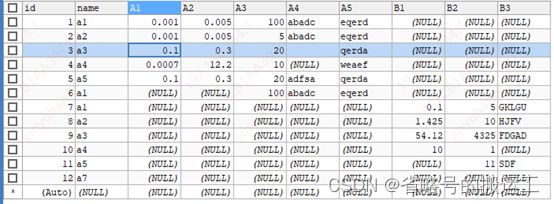
② 实验二
kafkareader:name、A1、A2、A3、A4、A5、B1、B2、B3
mysqlwriter:name、A2、A1、A3、A5、A4、B1、B2、B3
结果表中A1、A2列互换,A4、A5列互换
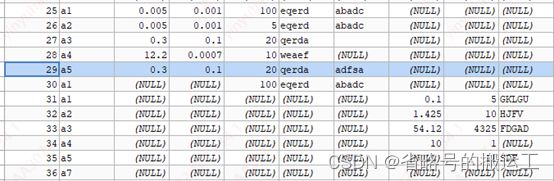
③ 实验三
kafkareader:name、A2、A1、A3、A4、A5、B1、B2、B3
mysqlwriter:name、A1、A2、A3、A4、A5、B1、B2、B3
结果表中A1、A2列互换
④ 实验四(忘截图了)
kafkareader:name、a1、a2、a3、A4、A5、b1、B2、B3
mysqlwriter:name、A1、A2、A3、A4、A5、B1、B2、B3
结果目标表中A1、A2、A3、B1列为null
⑤ 实验五(忘截图了)
kafkareader:name、A1、A2、A3、A4、A5、B1、B2、B3
mysqlwriter:name、a1、a2、A3、A4、A5、B1、B2、B3
结果运行失败,无法在mysql中找到a1、a2列
结论:
① 在任务运行至reader时,chunjun会依据kafkareader中定义的字段匹配topic中数据,且字段顺序不受kafka顺序限制,如果reader中的字段在kafka topic中没有出现,则赋予null,
② 在字段对应时按顺序赋值,当reader中为M、L、N,writer中为l、m、n时,M->l,L->m,N->n,官网文档描述不准确,因此只要了解kafka中数据与MySQL中表字段的对应关系即可快速编写json
③ 在任务运行至writer时,chunjun会依据mysqlwriter中定义的字段写入mysql表,且字段顺序不受mysql顺序限制,如果writer中的字段在mysql中没有出现,则报错
④ 字段对应可以做到一对多,比如reader中A1、A1、A1,writer中A1、A2、A3,则mysql表中A1、A2、A3列都会附A1值
4、kafka—>mysql,当kafka输入脏数据时,mysql会写入空行
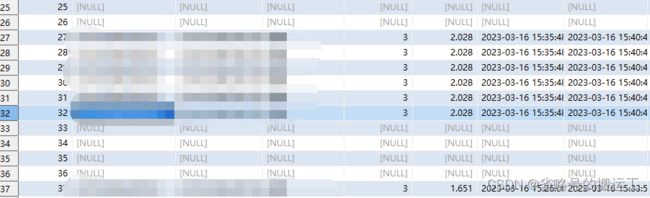
如果目标表中某列设置为not null则不论是否chunjun设置errorLimit,任务都将直接失败
注意向kafka中写入数据的合规性
5、kafkareader,group-offsets模式读不到已提交offset的数据
chunjun kafkareader中有五种mode:
- group-offsets: 从ZK / Kafka brokers中指定的消费组已经提交的offset开始消费
- earliest-offset: 从最早的偏移量开始(如果可能)
- latest-offset: 从最新的偏移量开始(如果可能)
- timestamp: 从每个分区的指定的时间戳开始
- specific-offsets: 从每个分区的指定的特定偏移量开始
group_offsets模式在group中数据没有被消费过时,默认offset为-915623761773L,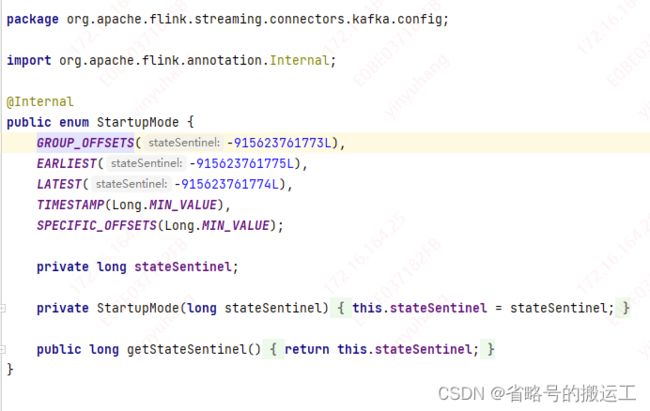
这时使用该模式实测会跳过原有数据直接到最新的offset,相当于latest-offset模式,查询原理发现:
chunjun这部分代码继承的是flink kafka api,当设置为group_offsets模式时如果该group的offset不存在,或者无效的话,将依据 "auto.offset.reset" 该属性来决定初始 offset。auto.offset.reset 默认为 largest。
若想消费到原有数据可以依如下办法,手动将"auto.offset.reset"设置为earliest
auto.offset.reset的earliest参数
在各分区下有提交的offset时:从offset处开始消费
在各分区下无提交的offset时:从头开始消费
如此可以实现绝大部分场景了