开源 | 视频片段定位 TSG:一句话精准视频片段定位,清华新SOTA
本文来源 陈厚伦 投稿 量子位
只需一句话描述,就能在一大段视频中定位到对应片段!
比如描述“一个人一边下楼梯一边喝水”,通过视频画面和脚步声的匹配,新方法一下子就能揪出对应起止时间戳:

就连“大笑”这种语义难理解型的,也能准确定位:

方法名为自适应双分支促进网络(ADPN),由清华大学研究团队提出。
具体来说,ADPN是用来完成一个叫做视频片段定位(Temporal Sentence Grounding,TSG)的视觉-语言跨模态任务,也就是根据查询文本从视频中定位到相关片段。
ADPN的特点在于能够高效利用视频中视觉和音频模态的一致性与互补性来增强视频片段定位性能。
相较其他利用音频的TSG工作PMI-LOC、UMT,ADPN方法从音频模态获取了更显著地性能提升,多项测试拿下新SOTA。
目前该工作已经被ACM Multimedia 2023接收,且已完全开源。

一起来看看ADPN究竟是个啥~
一句话定位视频片段
视频片段定位(Temporal Sentence Grounding,TSG)是一项重要的视觉-语言跨模态任务。
它的目的是根据自然语言查询,在一个未剪辑的视频中找到与之语义匹配的片段的起止时间戳,它要求方法具备较强的时序跨模态推理能力。
然而,大多数现有的TSG方法只考虑了视频中的视觉信息,如RGB、光流(optical flows)、深度(depth)等,而忽略了视频中天然伴随的音频信息。
音频信息往往包含丰富的语义,并且与视觉信息存在一致性和互补性,如下图所示,这些性质会有助于TSG任务。

△图1
(a)一致性:视频画面和脚步声一致地匹配了查询中的“走下楼梯”的语义;(b)互补性:视频画面难以识别出特定行为来定位查询中的“笑”的语义,但是笑声的出现提供了强有力的互补定位线索。
因此研究人员深入研究了音频增强的视频片段定位任务(Audio-enhanced Temporal Sentence Grounding,ATSG),旨在更优地从视觉与音频两种模态中捕获定位线索,然而音频模态的引入也带来了如下挑战:
音频和视觉模态的一致性和互补性是与查询文本相关联的,因此捕获视听一致性与互补性需要建模文本-视觉-音频三模态的交互。
音频和视觉间存在显著的模态差异,两者的信息密度和噪声强度不同,这会影响视听学习的性能。
为了解决上述挑战,研究人员提出了一种新颖的ATSG方法“自适应双分支促进网络”(Adaptive Dual-branch Prompted Network,ADPN)。
通过一种双分支的模型结构设计,该方法能够自适应地建模音频和视觉之间的一致性和互补性,并利用一种基于课程学习的去噪优化策略进一步消除音频模态噪声的干扰,揭示了音频信号对于视频检索的重要性。
ADPN的总体结构如下图所示:
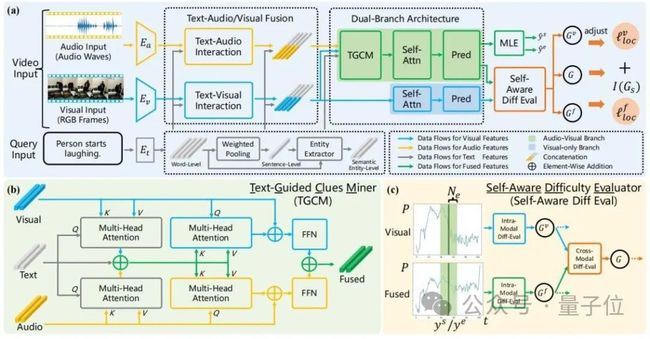
△图2:自适应双分支促进网络(ADPN)总体示意图
它主要包含三个设计:
1、双分支网络结构设计
考虑到音频的噪声更加明显,且对于TSG任务而言,音频通常存在更多冗余信息,因此音频和视觉模态的学习过程需要赋予不同的重要性,因此本文涉及了一个双分支的网络结构,在利用音频和视觉进行多模态学习的同时,对视觉信息进行强化。
具体地,参见图2(a),ADPN同时训练一个只使用视觉信息的分支(视觉分支)和一个同时使用视觉信息和音频信息的分支(联合分支)。
两个分支拥有相似的结构,其中联合分支增加了一个文本引导的线索挖掘单元(TGCM)建模文本-视觉-音频模态交互。训练过程两个分支同时更新参数,推理阶段使用联合分支的结果作为模型预测结果。
2、文本引导的线索挖掘单元(Text-Guided Clues Miner,TGCM)
考虑到音频与视觉模态的一致性与互补性是以给定的文本查询作为条件的,因此研究人员设计了TGCM单元建模文本-视觉-音频三模态间的交互。
参考图2(b),TGCM分为”提取“和”传播“两个步骤。
首先以文本作为查询条件,从视觉和音频两种模态中提取关联的信息并集成;然后再以视觉与音频各自模态作为查询条件,将集成的信息通过注意力传播到视觉与音频各自的模态,最终再通过FFN进行特征融合。
3、课程学习优化策略
研究人员观察到音频中含有噪声,这会影响多模态学习的效果,于是他们将噪声的强度作为样本难度的参考,引入课程学习(Curriculum Learning,CL)对优化过程进行去噪,参考图2(c)。
他们根据两个分支的预测输出差异来评估样本的难度,认为过于难的样本大概率表示其音频含有过多的噪声而不适于TSG任务,于是根据样本难度的评估分数对训练过程的损失函数项进行重加权,旨在丢弃音频的噪声引起的不良梯度。
(其余的模型结构与训练细节请参考原文。)
多项测试新SOTA
研究人员在TSG任务的benchmark数据集Charades-STA和ActivityNet Captions上进行实验评估,与baseline方法的比较如表1所示。
ADPN方法能够取得SOTA性能;特别地,相较其他利用音频的TSG工作PMI-LOC、UMT,ADPN方法从音频模态获取了更显著地性能提升,说明了ADPN方法利用音频模态促进TSG的优越性。

△表1:Charades-STA与ActivityNet Captions上实验结果
研究人员进一步通过消融实验展示了ADPN中不同的设计单元的有效性,如表2所示。
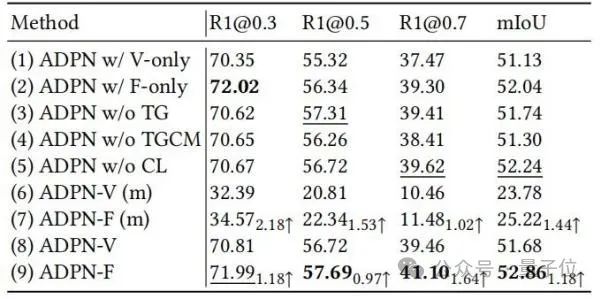
△表2:Charades-STA上消融实验
研究人员选取了一些样本的预测结果进行了可视化,并且绘制了TGCM中”提取“步骤中的”文本 to 视觉“(T→V)和”文本 to 音频“(T→A)注意力权重分布,如图3所示。
可以观察到音频模态的引入改善了预测结果。从“Person laughs at it”的案例中,可以看到T→A的注意力权重分布更接近Ground Truth,纠正了T→V的权重分布对模型预测的错误引导。
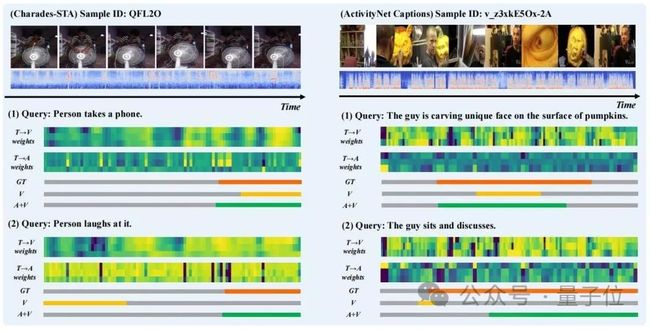
△图3:案例展示
总的来说,本文研究人员提出了一种新颖的自适应双分支促进网络(ADPN)来解决音频增强的视频片段定位(ATSG)问题。
他们设计了一个双分支的模型结构,联合训练视觉分支和视听联合分支,以解决音频和视觉模态之间的信息差异。
他们还提出了一种文本引导的线索挖掘单元(TGCM),用文本语义作为指导来建模文本-音频-视觉交互。
最后,研究人员设计了一种基于课程学习的优化策略来进一步消除音频噪音,以自感知的方式评估样本难度作为噪音强度的度量,并自适应地调整优化过程。
他们首先在ATSG中深入研究了音频的特性,更好地提升了音频模态对性能的提升作用。
未来,他们希望为ATSG构建更合适的评估基准,以鼓励在这一领域进行更深入的研究。
论文链接:https://dl.acm.org/doi/pdf/10.1145/3581783.3612504
仓库链接:https://github.com/hlchen23/ADPN-MM
关注公众号【机器学习与AI生成创作】,更多精彩等你来读
不是一杯奶茶喝不起,而是我T M直接用来跟进 AIGC+CV视觉 前沿技术,它不香?!
卧剿,6万字!30个方向130篇!CVPR 2023 最全 AIGC 论文!一口气读完
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!
经典GAN不得不读:StyleGAN
 戳我,查看GAN的系列专辑~!
戳我,查看GAN的系列专辑~!
最新最全100篇汇总!生成扩散模型Diffusion Models
ECCV2022 | 生成对抗网络GAN部分论文汇总
CVPR 2022 | 25+方向、最新50篇GAN论文
ICCV 2021 | 35个主题GAN论文汇总
超110篇!CVPR 2021最全GAN论文梳理
超100篇!CVPR 2020最全GAN论文梳理
拆解组新的GAN:解耦表征MixNMatch
StarGAN第2版:多域多样性图像生成
附下载 | 《可解释的机器学习》中文版
附下载 |《TensorFlow 2.0 深度学习算法实战》
附下载 |《计算机视觉中的数学方法》分享
《基于深度学习的表面缺陷检测方法综述》
《零样本图像分类综述: 十年进展》
《基于深度神经网络的少样本学习综述》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
点击跟进 AIGC+CV视觉 前沿技术,真香!,加入 AI生成创作与计算机视觉 知识星球!