利用 AWS pcluster + Vina 进行百万级分子库虚拟筛选
在上一篇博文中《使用Autodock Vina进行分子对接》中我们介绍使用Vina进行单分子虚拟筛选的过程。现在,我们介绍利用AWS 的pcluster工具进行大规模分子虚拟筛选。
如果你需要自己使用AWS的资源配置一个超算集群,那么重头阅读到尾。
如果你已经有了超算资源(slurm调度),例如:并行科技,超算中心,那么可以直接跳到第三部分。
AWS pcluster+ Vina 进行百万级分子库虚拟筛选的整体架构如下:
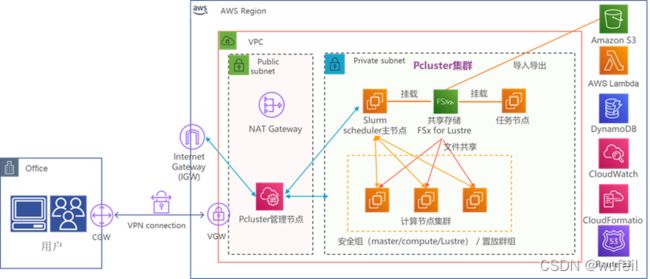
一、关于AWS pcluster
AWS pcluster的全程是Amazon ParallelCluster,是Amazon支持的开源集群管理工具,可在Amazon Web Services云中部署和管理高性能计算 (HPC) 集群。它会根据配置自动启动所需的计算资源和共享文件系统。支持Amazon Batch和Slurm等调度程序并充分利用云端的弹性和扩展性,用户只需为实际使用的计算和存储等资源付费。
我们这里使用的是Slurm调度程序。
二、配置pcluster集群环境
2.1 创建pcluster虚拟环境
创建pcluster conda环境。
$ conda create -n Pcluster python=3.8
激活pcluster环境,安装AWS pcluster, Node.js
$ conda activate Pcluster
$ python3 -m pip install --upgrade "aws-parallelcluster<3.0" #AWS 中国区不支持pcluster3.0版本
$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.38.0/install.sh | bash ~/.nvm/nvm.sh
$ nvm install node
$ node --version
注意,我这里的pcluster是2.8版本。不同版本会有差异。
2.2 配置系统环境,创建文件系统
我们使用Amazon FSx for Lustre作为集群的文件系统。创建模式参考文档:https://aws.amazon.com/cn/fsx/lustre/getting-started/?nc=sn&loc=4
根据向导创建一个1.2TiB, 60MiB/s吞吐的SSD存储类型的文件系统。创建以后会生成一个FSx的id,保留这个id即可。
2.3 集群的配置文件
集群配置文件记录了集群所需的信息,包括:主节点的实例类型、计算节点实例类型,计算节点最大容量等。下面是一个具体的例子,改配置文件名为Pcluster_create_config_Vina
由于大规模虚拟筛选是一个耗时耗资源的事情,我们往往会使用AWS的spot模式(空余资源)启动计算节点,可以节省大量的计算费用。spot模式最大的问题是,计算节点会被AWS系统自动回收,因此,在虚拟筛选过程会出现job被重复提交的情况。
我试过500以上的,都出现了计算节点job频繁重启的问题,特别是在m5.large等实例,现象更为严重。而vcpu数量较多的机型则比较少见重启情况,因为我们选择72核、96核的18xlarge和24xlarge机型。
Pcluster_create_config_Vina文件具体内容如下:
[aws]
aws_region_name = cn-northwest-1 #aws西北宁夏区
[global]
cluster_template = VinaBatch #集群名字
update_check = true
sanity_check = true
[cluster Vina_Batch]
custom_ami = ami-0c8475cadd4209d99 #启动集群需要的ami,不同可用区ami不一样,请联系AWS的售后团队。
key_name = AIDrugs #秘钥名称
scheduler = slurm #调度器
master_instance_type = i3en.large #主节点类型
base_os = ubuntu1804 #主节点类型
vpc_settings = aidrugsvpc #vpc
queue_settings=c5,m5,spe,vita,chem #计算资源队列, 我配置了多个队列,vita,chem等都用不到的
cw_log_settings = hpc-cw
scaling_settings = hpc-asg
fsx_settings = fs #共享文件系统
[queue spe] #spe队列,每一个队列可以有三种实例机型
compute_resource_settings = c5d.18xlarge, c5a.24xlarge, c5.18xlarge
compute_type = spot #调用实例模式为spot,比较省钱
[compute_resource c5d.18xlarge] #计算节点1
instance_type = c5d.18xlarge
max_count = 60
[compute_resource c5a.24xlarge] #计算节点2
instance_type = c5a.12xlarge
max_count = 30
[compute_resource c5.18xlarge] #计算节点3
instance_type = c5.18xlarge
max_count = 60
[queue chem]
compute_resource_settings = m5.12xlarge, m5a.16xlarge, c5a.16xlarge
compute_type = spot
[compute_resource m5a.16xlarge]
instance_type = m5a.16xlarge
max_count = 60
[compute_resource c5a.16xlarge]
instance_type = c5a.16xlarge
max_count = 60
[compute_resource m5.12xlarge]
instance_type = m5.12xlarge
max_count = 90
[compute_resource m5.xlarge]
instance_type = m5.xlarge
max_count = 1000
[queue c5]
compute_resource_settings = c5.large
compute_type = spot
[compute_resource c5.large]
instance_type = c5.large
max_count = 10
[queue m5]
compute_resource_settings = m5.large
compute_type = spot
[compute_resource m5.large]
instance_type = m5.large
max_count = 1000
[aliases]
ssh = ssh {CFN_USER}@{MASTER_IP} {ARGS}
[vpc aidrugsvpc]
vpc_id = vpc-057ec8549db8a5f
master_subnet_id = subnet-03f298e4b1365c3
compute_subnet_id = subnet-03f298a3e4365c3
[fsx fs]
shared_dir = /data #文件系统的挂载目录
fsx_fs_id = fs-0658c26308ac75936 #2.2配置文件系统fsx的id
2.4 启动集群
通过Pcluster_create_config_Vina配置文件创建VinaBatch集群:
$ pclusterr create VinaBatch -c Pcluster_create_config_Vina
启动集群后,通过ssh等方法链接进入主节点(头结点),修改集群参数,增加任务数上限为50万,默认为1W是不够的。
进入主节点:
$ pcluster ssh VinaBatch -i AIDrugs.perm #进入主节点
$ sudo vim /opt/slurm/etc/slurm.conf
添加MaxJobCount=500000至末行,重启slurmctld服务:
$ sudo systemctl restart slurmctld
在主节点可以通过sinfo或者squeue查看节点或者任务状态。
$ sinfo

可以看到里面有5个队列,每个队列里面有数量不等的计算资源。这里我建立了一个很大的资源池,想用多少就用多少,具体可以根据项目时间和预算情况进行分配。
squeue
![]()
现在没有任务在跑,没有job自然为空。
顺路插一句,自己搭建集群的好处是,想拉5W vcpu的时候,不需要和超算中心那边商量,想起机子就起机子,只要你有钱,有预算。另外,由于一些二级供应商,往往不会开放root权限,所以安装软件也不是随心所欲的。另外,就是保密性问题,供应商有root权限。总之,好处多多,但是更复杂了,这种技术架构适合拥有云服务维护团队的公司。
2.5 安装Vina及其相关环境
安装方法可以参考之前的那一篇博客《使用Autodock Vina进行分子对接》,这里就不在复述。
要安装的软件包括:vina, obabel, MGLTools。注意,我这里的安装目录全部都是挂载盘/data。
三、利用集群+Vina进行百万级分子的虚拟筛选
任务主要涉及到以下工作流程:
1. 分子库拆分:我们将下载的比较大的的分子库拆分成独立的分子文件,这里一个分子库可能可能包含百万级别的分子数量。
2. 分子构象生成:通过Open Babel工具为每个分子生成三维构象(sdf格式)。
3. 格式转换:通过工具MGLTools将每个分子的三维构象从sdf转换为pdbqt格式用于后续分子对接。
4. AutoDock Vina分子对接: 一个分子对接任务的输入为分子的某一个三维构象(pdbqt格式),pdbqt格式的受体蛋白文件和靶点对接坐标信息(grid space)。
3.1 配体预处理
目的是在将配体文件改为适合vina的pdbqt文件,同时生成保存对接位置的对接配置文件。这里我们已1a3w.pdb为例,在1a3w蛋白的变构位置(A链1007号小分子)进行进行大规模的虚拟筛选,位置如下图中紫色小分子位置。
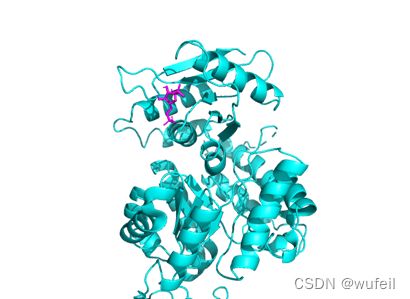
先利用pymol文件对配体pdb进行预处理,包括删除水分子,加氢,定位对接位置等。
#以下命令均在pymol cmd中执行
fetch 1a3w #加载配体
remove chain B #删除B链
remove resn HOH #删除水分子
h_add elem O or elem N #添加H原子
select mol, chain A and res 1007 3#选中小分子
select protein, 1a3w and not mol #选中配体,不包含小分子
save 1a3w-accptor.pdb, protein #保存配体
同样获得小分子中心位置(需要对接位置)坐标如下,对接范围15A, 保存在config.txt,内容如下:
center_x = 35.371
center_y = 17.826
center_z = 40.325
size_x = 20.0
size_y = 20.0
size_z = 20.0
整个对接项目的文件结构均在spe文件夹下。*.sh文件是相关的执行脚本,acceptor文件下是上述的1a3w-accptor.pdb和config.txt文件。
spe文件目录如下:
![]()
其中,*.sh就是我们要用到的shell脚本。然后Specs.sdf是小分子库,这里仅仅是一个示例,来源于陶署,具体可以替换成任何分子库。分子数量可以500W都没问题。
切换到acceptor目录下,使用MGLTools将1a3w-accptor.pdb转为Vina适用的pdbqt格式, 即1a3w-accptor.pdbqt。可参考上一篇博客《使用Autodock Vina进行分子对接》。
方法如下:
$ cd acceptor
$ pythonsh /data/mgltools_x86_64Linux2_1.5.7/MGLToolsPckgs/AutoDockTools/Utilities24/prepare_receptor4.py -r 1a3w-accptor.pdb
$ ls
![]()
至此,配体已经准备完成。
小分子的准备包括三个步骤:
3.2 小分子拆分
运行1-Prepare_sdf.sh:创建sdf 3D_mol2 3D_sdf split_txt pdbqt log同时使用pcluster的m5队列将所有sdf拆成单个小分子的sdf文件放置在sdf文件夹内。
1-Prepare_sdf.sh内容如下:
#! /bin/bash
echo "
Create a file directory, split the sdf file into a single molecule sdf files"
mkdir sdf 3D_mol2 3D_sdf split_txt pdbqt log
echo "Slipt the datasets which are in ./ with sdf filetype
into sdf file for each moleculars in sdf folder"
source /home/ubuntu/anaconda3/etc/profile.d/conda.sh
conda activate Vina
for f in *.sdf
do
b=`basename $f .sdf`
sbatch -c 1 -p m5 --output ./log/$f.out --job-name Splitsdf --wrap "srun bash Prepare_sdf.sh $f $b"
done
Prepare_sdf.sh使用obabel将sdf中的小分子拆分,内容如下:
#! /bin/bash
obabel -isdf $1 -osdf -O /sdf/$2_.sdf -p 7.4 -m
bash 1-Prepare_sdf.sh后,可以通过squeue查看队列情况:

![]()
看到节点处于“CF”状态,这是正在构建计算节点的过程中,等待几分钟后,在使用squeue可以看到计算节点处于R状态(正在运行任务中)。
由于当前目录下只有一个sdf文件(分子库),所以只提交一个job,id是154021,如果有多个sdf文件,则会提交相应数量的job。
ls查看当前目录,可以看到创建了一些相应的工作目录。
![]()
通过以下命令可以查看sdf生成文件数量。
$ cd sdf
$ ls -l | wc -l
经过简单30秒,其实还没运行完,就生成了7W+的分子。