【RPC系列】3、序列化技术(必读)
通过上面两篇的介绍,应该可以理解RPC网络通信方面的大体流程,那么通信过程中我们Java处理会转化成定制化的对象,那么如果让对象在网络中传输,就需要一种序列化协议进行数据存储和消息传输。
选择序列化工具需要衡量一下三个性能指标:
- 对象序列化后的字节占位大小。(序列化的数据比较大就会影响传输效率)
- 序列化与反序列化的性能,说白了就是编解码效率(处理序列方法的性能)。
- 序列化工具的性能。
序言:看了很多讲序列化的博客,很多都没有讲到为什么要序列化的根本目的,很多都千篇一律讲了Java要实现Serializeable接口,根本目的还是为了数据存储和消息传输。
下面这句话引用了IBM社区的一段话
序列化的思想是 “冻结” 对象状态,传输对象状态(写到磁盘、通过网络传输等等)
然后 “解冻” 状态,重新获得可用的 Java 对象。所有这些事情的发生有点像是魔术
这要归功于 ObjectInputStream/ObjectOutputStream 类、
完全保真的元数据以及程序员愿意用 Serializable 标识接口标记他们的类,从而 “参与” 这个过程。一、文本序列化(Json和xml)
Json号为JavaScript的对象标记,可以直接转化为JavaScript对象,配置简单,文本所占空间更小,采用完全独立于编程语言的文本格式来存储和表示数据。
但是在Java中无法直接用文本和对象互相转换操作,于是产生了很多第三方处理JSON的框架,比如Jackson等
-
流式解析JSON序列化框架Jackson
想必Java程序员都用过Jackson的类库,主要作用就是序列化Java对象成为JSON文本,或反序列化JSON文本成Java对象。
由于该框架是使用流式增量的处理方式,所以在转换大数据量的对象文本时比较有优势
Jackson有两个模块组成(jackson-core和jackson-databind),从名称就可以知道core模块是为databind提供底层的解析和转换方法,而databind提供了数据绑定和树模型功能。
生成文本方法:
ObjectMapper objectMapper = new ObjectMapper();
String jsonValue = objectMapper.writeValueAsString(pojo);读取文本方法:
Pojo pojo = objectMapper.readValue(jsonValue, Pojo.class);-
轻量级JSON序列化框架Gson
Gson是Google公司开源的第三方Java库。Gson可以通过@Since标注对象属性的出现版本,可以向后兼容
序列化方法:
GsonBuilder build = new GsonBuilder();
build.setVersion(version);//注意版本号的定义规则
Gson gson = build.create();
String json = gson.toJson(pojo);反序列化:
Pojo pojo = new Gson().fromJson(jsonValue, Pojo.class);二、二进制Java序列化
以上基于Json和xml的序列化简单清晰,只需要开发支持文本解析即可,但是文本毕竟占据空间较大,加之解析的方法不确定性,在较高的互联网传输背景下相对于二进制略显劣势。
Java语言的序列化作为Java程序员是再熟悉不过了,只需要实现Serializable接口即可,相当于被标记了序列化版本的一个标识,同样实现了接口后,我们都要给个serialVersionUID的版本编号,如果不指定,JDK会默认自动生成,后面对修改对象时,会再次变化,这样对需要严格的存储解析会造成很大的影响,对版本要求不高但是有存储解析要求的指定默认版本即可。
举个很简单的例子,在存储设备上存储了录入页的对象数据后,由于后期开发要求,变更或减少了某些序列化字段的属性,再次解析的时候会造成版本不一致的错误。添加字段是不会报错的。
虽然Java原生支持的序列化机制足够简单,但是在性能方面就没那么令人满意,根据开篇时的三个性能要求,对序列化后的字段过于臃肿,于是要求较高的网络传输环境下,不建议使用,可选择高性能序列化框架(Kryo)。
使用Kryo无需进行序列化接口的实现。
Kryo序列化的核心代码:
Kryo kryo = new Kryo();
File file = new File("foo.bin");
try {
ObjectOutputStream os = new ObjectOutputStream(new FileOutputStream(file));
Output op = new Output(os);
Pojo pojo = new Pojo();
kryo.writeObject(op, pojo);
}catch(Exception e) {
}反序列化的核心代码使用kryo.readObject(input, Pojo.class);
实际框架中的应用
1、先自定义一个序列化工具类,可以用一个Queue
2、初始化创建kryo的过程如下
Kryo kryo = new Kryo();
kryo.setDefaultSerializer(CompatibleFieldSerializer.class);
kryo.setReferences(true);
StdInstantiatorStrategy instantiatorStrategy = new StdInstantiatorStrategy();
((DefaultInstantiatorStrategy) kryo.getInstantiatorStrategy()).setFallbackInstantiatorStrategy(instantiatorStrategy);
return kryo;3、读写对象就见上面的核心方法即可
三、二进制异构语言序列化(gRPC)
上一节讲的是Java同构语言序列化,这节介绍高性能异构语言序列化框架—Protobuf(Google)。
使用Protobuf时首先需要在系统上安装它的命令用于编译proto协议文件。使用CentOs7虚拟机为例
全新的服务器环境需要先安装命令插件
[root@localhost protobuf-3.11.4]# yum -y install gcc automake autoconf libtool make
[root@localhost protobuf-3.11.4]# yum install gcc gcc-c++
然后再执行:
#获取资源包,我是直接本机下载上传放到了CentOS7的/opt/下面
wget https://github.com/protocolbuffers/protobuf/releases/download/v3.11.4/protobuf-all-3.11.4.tar.gz
#解压
tar zxvf protobuf-all-3.11.4.tar.gz
#自动配置
./autogen.sh
#配置
./configure
#编译安装
make
make installprotobuf通过proto协议文件来定义程序中需要处理的结构化数据,结构化数据在protobuf中成为message。
proto协议文件以".proto"结尾,一个消息类型由一个或多个字段组成,每个字段中至少应该包括类型、名称和标识符。
由一个压缩生成二进制消息大小的敲门:
数字1-15对应的十六进制数范围是0x1~0xF,仅占用一个字节,尽量将频繁出现的消息字段保留在1~15标识符之内,还可以预留。保证只增不减,则是protobuf向后兼容的关键
//表示使用proto3的语法,默认情况下使用proto2
//syntax语句必须是.proto文件的第一行有效语句
syntax = "proto3";
//该文件编译为类之后的包名称是protobuf.pojo
package protobuf.pojo;
//定义消息类型,对应Java类名,消息体有三个字段
message ProtoPojo {
//类型为32位的整数,属性名为id,标识符为1
int32 id = 1;
//类型为字符串,属性名为name,标识符为2
string name = 2;
//类型为可重复的字符串对应java中的List,属性名为messages,标识符是3
repeated string messages = 3;
}以下是Protobuf支持的消息类型,详情可点击查看google官方文档
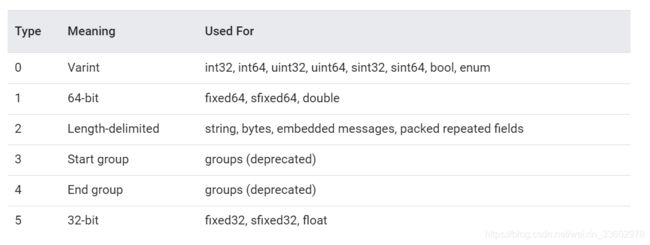
其中Java支持的有:double/float/int/long/boolean/String/ByteString。
Protobuf是向后兼容的,在修改时需要遵循一下原则:
- 不能更改已有字段的数字标识符
- 未被标示的字段会在反序列化被丢弃,新增字段将被赋值为默认值
- 非必须字段可以删除,但是必须保证他们的数字标识符在新的消息中不再被使用
- int32/uint32/int64/uint64/bool是全部兼容的,但是部分强制转换会导致精度丢失
- sint32/sint64相互兼容,但与其他整型不兼容等等
下面开始用Java语言进行相关代码演示:
首先我在/opt/下面写了上面的.proto的文件
[root@localhost opt]# ll
total 7244
drwx--x--x. 4 root root 28 Apr 1 06:13 containerd
-rw-r--r--. 1 root root 484 Apr 2 01:41 Pojo.proto
drwxr-xr-x. 18 411487 89939 4096 Apr 2 01:19 protobuf-3.11.4
-rw-r--r--. 1 root root 7408292 Apr 2 01:09 protobuf-all-3.11.4.tar.gz
drwxr-xr-x. 2 root root 6 Mar 26 2015 rh执行命令:
[root@localhost opt]# protoc --java_out=. ./Pojo.proto
则会在当前目录生成一个protobuf的文件夹如下第三个文件
[root@localhost opt]# ll
total 7244
drwx--x--x. 4 root root 28 Apr 1 06:13 containerd
-rw-r--r--. 1 root root 484 Apr 2 01:41 Pojo.proto
drwxr-xr-x. 3 root root 18 Apr 2 01:49 protobuf
drwxr-xr-x. 18 411487 89939 4096 Apr 2 01:19 protobuf-3.11.4
-rw-r--r--. 1 root root 7408292 Apr 2 01:09 protobuf-all-3.11.4.tar.gz
drwxr-xr-x. 2 root root 6 Mar 26 2015 rh
一步步点进去(cd protobuf/pojo/)可以看到一个Pojo.java的文件,文件内容太多,简单看下如下:
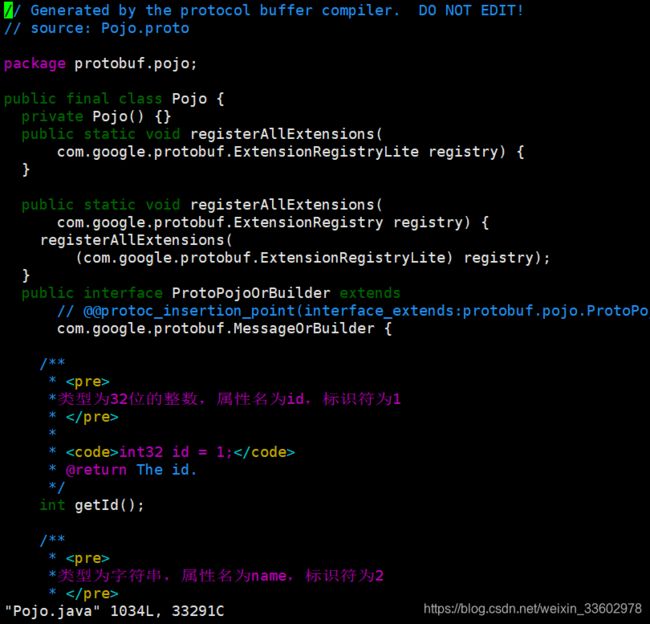
还记得我们的.proto文件中分别用了标识符1,2,3,对应生成的Java代码咱们可以看出:
- id = 1,则对应的Java代码中生成了一个getId()的方法,int32类型的数据无须进行复杂的序列化
- name = 2,则生成了两个方法,分别是getName()和getNameBytes(),用于序列化和反序列化
- messages = 3,则生成了4个方法,repeated代表了List集合,那么就有List
getMessagesList(),int getMessagesList(),String getMessages(int index)和ByteString getMessagesBytes(int index)。
下面咱们用Java支持的Protobuf API进行序列化和反序列化,都分别有两个方法:
- byte[] toByteArray():通过方法名称就知道该方法是将Java对象序列化成二进制字节数组
- void writeTo(OutputStream output):直接将Java对象序列化并写入一个输出流
- static T parseFrom(byte[] data):将二进制的字节数组反序列化为Java对象。
- static T parseFrom(InputStream input):通过一个输入流读取二进制字节数组并反序列化为Java对象
Maven的依赖为
com.google.protobuf
protobuf-java
3.11.0
com.google.protobuf
protobuf-java-util
3.11.0
Java的转换输出代码如下:
//通过protoc的命令生成的Java类
Person.ProtoPerson.Builder person = Person.ProtoPerson.newBuilder();
person.setId(1).setName("kaer");
byte[] messageBody = person.build().toByteArray();
//可供传输的二进制字节数组
System.err.println(new String(messageBody));
String json = JsonFormat.printer().print(person);
//与json转化
System.err.println(json);
//创建个Person对象用来json的转换
Person.ProtoPerson.Builder person_2 = Person.ProtoPerson.newBuilder();
//将json转化成Person对象
JsonFormat.parser().ignoringUnknownFields().merge(json, person_2);
person_2.setName("lina").addMessages("success");
System.err.println(JsonFormat.printer().print(person_2));具体用法到后面介绍gRpc再详细说明。
以上内容参考并摘抄书籍Leader-us著《架构解密·从分布式到微服务》、张亮等著《未来架构·从服务化到云原生》
具体序列化的一些知识和问题可以阅读《您不知道的5件事·Java对象序列化》