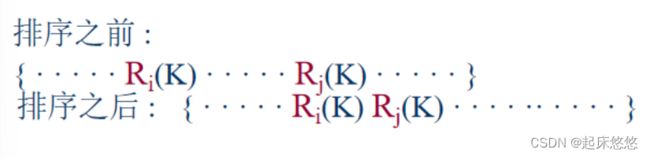数据结构知识点整理(期末复习/知识点学习/笔试/考研)
第一章:数据结构绪论
一、数据
1.数据是信息的载体,是描述客观事物的数、字符、以及所有能输入到计算机中,被计算机程序识别和处理的符号的集合。
2.数据分为:数值性数据和非数值性数据。
二、数据元素
1.数据元素是数据的基本单位,是数据集合的个体。
2.一个数据元素可以由若干数据项组成(此时数据元素被称为记录)。
3.数据元素又称为元素、结点、记录。
三、数据项
1.数据项是具有独立含义的最小标识单位。
2.数据项是数据的最小单位。
四、数据对象
1.数据对象是具有相同性质的数据元素的集合,是数据的一个子集。
(整数数据对象,字母字符数据对象)
五、结构
1.结构是元素之间的。
2.结构包含空间位置关系,相互作用和依赖关系。
3.四种基本结构:集合结构、线性结构、树形结构、图形结构。
(1)集合结构:结构中的数据元素之间除“同属一个集合”外,别无其他关系。
(2)线性结构:数据元素一对一关系。
(3)树形结构:一对多。
(4)图形结构:多对多。
六、数据结构
1.形式定义:某一数据对象的所有数据成员之间的关系。记为:
Data_Structure={D,S}
其中,D是某一数据对象,即数据元素的有限集合,S是该对象中所有数据成员之间的关系的有限集合。
2.数据结构是相互之间存在一种或多种特点关系的数据元素的集合。
3.数据结构包含三方面的内容:逻辑结构,存储结构和数据的运算。
2.线性数据结构:L={K,R}(其中K为点集,R为关系<>)
3.树形数据结构:T={K,R}(其中K为点集,R为关系<>)
4.图形数据结构:G={K,R}(其中K为点集,R为关系() )
七、数据结构要解决的问题
1.从广义上讲,数据结构描述现实世界实体的数学模型及其上的操作在计算机中的表示和实现。
八、逻辑结构
1.逻辑结构描述数据元素之间的关系。
2.逻辑结构包括线性结构和非线性结构。
(1)线性结构包括线性表(表、栈、队列、串)。栈、队列、串是受限线性表。
(2)非线性结构包括树(二叉树、赫夫曼树、二叉排序树)和图(有向图、无向图)。
九、物理结构(存储结构)
1.物理结构是数据结构在计算机中的表示(或映像)。(存储结构是逻辑结构在计算机中的存储映像,包括数据元素映像和关系映像,但是逻辑结构是独立于存储结构的。)
2.物理结构包括:顺序存储表示、非顺序存储(链式存储表示、索引存储表示、散列存储表示)。
注意:有序表属于逻辑结构;顺序表、哈希表、单链表属于存储结构
(1)顺序存储:逻辑上相邻的元素,存储的物理位置也相邻。优点:随机存取,每个元素占用最少的存储空间;缺点:只能使用相邻的一整块存储单元,可能产生较多的外部碎片。
(2)链式存储:不要求逻辑上相邻的元素,存储的物理位置也相邻。借助指针表示元素之间的逻辑关系。优点:不会出现碎片现象,充分利用所有存储单元;缺点:每个元素因存储指针占用额外的存储空间,且只能实现顺序存取。
(3)索引存储:建立附加索引表。优点:检索速度快;缺点:附加的索引表占内存,增加和删除数据也会修改索引表,花费较多时间。
(4)散列存储:根据关键字直接计算存储地址。优点:检索、删除、增加都很快;缺点:会发生冲突,花费时间。
十、数据类型
1.数据类型是一个值的集合和定义在这个值集上的一组操作的总称。
(如int整型变量,其值集为某个区间上的整数,定义在其上的操作为+、-、x、/等)
2.原子数据类型是不可分解的数据类型(如int、float、char、*等等)。
3.结构数据类型
(1)由若干成分(原子类型或结构类型)按照某种结构组成的数据类型)
(2)结构数据类型可以看做是一种数据结构和定义在其上的一组操作组成的整体。
(3)如数组,由若干个分量组成,每个分量可以是整数,也可以是数组(int A[10])。
4.抽象数据类型
(1)由用户定义,用以表示应用问题的数据模型。
(2)由基本的数据类型组成,并包括一组相关的操作。
(3)信息隐蔽和数据封装,使用与现实相分离。
(4)抽象数据类型ADT是一个数学模型以及定义在该模型上的一组操作。
(5)抽象数据类型=数据结构+定义在此数据结构上的一组操作。
(6)(D,S,P)三元组表示。(D是数据对象,S是D上的关系集,P是对D的基本操作集)
(7)ADT定义:
ADT 抽象数据类型名{
数据对象:<数据对象的定义>
数据关系:<数据关系的定义>
基本操作:<基本操作(函数)的定义>
}ADT 抽象数据类型名
例子:
ADT Triplet {
数据对象:D = {e1,e2,e3 | e1,e2,e3∈ElemSet}
数据关系:R = {, }
基本操作:Max(T, &e)
初始条件:三元组T已存在。
操作结果:用e返回T的3个元素中的最大值。
Min(T, &e)
初始条件:三元组T已存在。
操作结果:用e返回T的3个元素中的最小值。
} ADT Triplet
(7)抽象数据类型可以通过固有的数据类型来实现:
抽象数据类型:类class
数据对象:数据成员
基本操作:成员函数(方法)
十一、算法
1.算法是对特定问题求解步骤的一种描述。
2.算法是一有限长的操作序列。
3.算法特性:
(1)有穷性:算法在执行有穷步后能结束。
(2)确定性:每步定义都是确切、无歧义,相同输入相同输出。
(3)可行性:每一条运算应足够基本(已验算正确)。
(4)输入:有0个或多个输入。
(5)输出:有1个或多个输出。
4.算法设计要求(目标):
(1)正确性:满足具体题目的需求。
(2)可读性:便于理解和修改。
(3)健壮性:当输入数据非法时,也能适当反应。
(4)效率高:执行时间少。
(5)空间省:执行中需要的最大存储空间少。
十二、时间复杂度
1.算法效率的度量是通过时间复杂度和空间复杂度来描述的。
衡量算法的效率,主要依据算法执行所需要的时间,即时间复杂度。
注意:算法分析的目的:分析算法的效率以求改进。
2.事后统计法:计算算法开始时间与完成时间差值。
缺点:(必须执行程序;其它因素遮盖算法本质)
3.事前统计法:依据算法选用何种策略及问题的规模n,是常用的方法。
4.(事前统计法)和算法执行时间相关的因素:
(1)算法选用的策略(主要)
(2)问题的规模(主要)
(3)编写的语言
(4)编译程序产生的机器代码的质量
(5)计算机执行指令的速度
5.一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,算法的时间量度记作 T(n)=O(f(n)),称作算法的渐近时间复杂度,简称时间复杂度。它表示随问题规模n的增大,算法执行时间的增长率和f(n)的增长率相同。
(1)加法规则:T(n)=T1(n)+T2(n)=O(f(n))+O(g(n))=O(max(f(n),g(n)))
(2)乘法规则:T(n)=T1(n)*T2(n)=O(f(n)) * O(g(n))=O(f(n)*g(n))
6.时间复杂度除常量阶[O(1)], 线性阶[O(n)], 平方阶[O(n^2)]外,还有对数阶[O(logn)],排列阶[O(n!)],指数阶[O(2^n)]等,是相对于问题规模n的增长率的表示方法。
(1)多项式:O(1) (2)指数时间:O(2^n) 7.如果算法的执行有多种可能的操作顺序,则求其平均时间复杂度。 如果无法求取平均时间复杂度,则采用最坏情况下的时间复杂度。 时间复杂度是衡量算法好坏的一个最重要的标准。 1.空间复杂度指算法执行时,所需要存储空间的量度,它也是问题规模的函数,即:S(n) = O(f(n))。 2.算法的存储量包括: (1)程序本身所占空间(与算法无关) (2)输入数据所占空间(与算法无关) (3)辅助变量所占空间(若所需额外空间相对于输入数据量来说是常数,则称此算法为原地工作。否则,按最坏情况分析) 注意:只有辅助变量所占空间与算法有关 在数据元素的非空有限集中 : 1.存在惟一的一个被称作“第一个”的数据元素。 2.存在惟一的一个被称作“最后一个”的数据元素。 3.除第一个元素外,每个数据元素均只有一个前驱 。 4.除最后一个元素外,每个数据元素均只有一个后继 。 1.线性表是最简单的一类线性数据结构。 2.线性表是由n个数据元素组成的有限序列,相邻数据元素之间存在着序偶关系,可以写为:(a1, a2,…ai-1, ai, ai+1,…an-1, an)其中,ai是表中元素,i表示元素ai的位置,n是表的长度。 3.线性表中的元素具有相同的特性,属于同一数据对象,如:1.26个字母的字母表: (A,B,C,D,…,Z)2.近期每天的平均温度:(30℃, 28℃, 29℃,…)。 1.顺序表是线性表的顺序表示。(线性表的顺序存储称为顺序表) 2.用一组地址连续的存储单元依次存储线性表的数据元素。逻辑相邻,物理也相邻。 3.顺序表数据元素的位置: loc(a[i])=loc(a[i-1])+length loc(a[i])=loc(a[1])+(i-1)*length 其中length表示元素占用的内存单元数。 4.顺序表的插入操作: (1)顺序表的插入操作是指在顺序表的第i-1个数据元素和第i个数据元素之间插入一个新的数据元素,即将长度为n的顺序表:(a1,…ai-1, ai, …, an) 变成长度为n+1的顺序表:(a1,…ai-1, e, ai, …, an) (2)在顺序表中的第i个位置插入一个元素,需要向后移动的元素个数为:n-i+1 (3)平均移动元素数为(假设在第i个元素之间插入的概率为pi):Eis = ∑ pi x (n-i+1) 其中i从1到n+1。 (4)当插入位置等概率时pi=1/(n+1),因为可以插在最后面。因此: Eis = ∑ [1/(n+1)] x (n-i+1) = n/2其中i从1到n+1。 注意:顺序表插入平均移动元素数为n/2 (5) 顺序表插入操作的时间复杂度为O(n)。 5.顺序表的删除操作: (1)顺序表的删除操作是指将顺序表的第i个数据元素删除,即将长度为n的顺序表:(a1,…ai-1, ai, ai+1,…, an) 变成长度为n-1的顺序表:(a1,…ai-1, ai+1, …, an) (2)在顺序表中删除一个元素,需要向前移动元素个数为:n-i(不用加一) (3)平均移动元素数为:Edl = ∑ qi x (n-i) 其中i从1到n。 (4)当删除位置等概率时qi=1/n,因为只有n个元素可以删除。因此: Edl = ∑ [1/n] x (n-i) = (n-1)/2其中i从1到n。 注意:顺序表删除平均移动元素数为(n-1)/2 (5)顺序表删除操作的时间复杂度为O(n)。 6.顺序表的其它操作: (1)查找第i个位置的元素值。 (2)查找元素所在位置。 (3)得到表长。 (4)置空表。 (5)销毁表(析构函数~SqList())。 7.顺序表的优缺点: (1)优点:元素可以随机存取;元素位置可用一个简单、直观的公式表示并求取。通过首地址和元素序号,O(1)内找到指定元素。存储密度高,每个结点只存储数据元素。 (2)缺点:在作插入或删除操作时,需要移动大量元素 。 注意:一个顺序表的第一个元素存储地址为2001,每个元素占用4个地址单元,第6个元素的存储地址为:2001+(6-1)5=2021;对于顺序存储的线性表,删除、增加结点的时间复杂度为O(n) 1.链表是线性表的链式存储表示。 2.链表中逻辑关系相邻的元素不一定在存储位置上相连,用指针表示元素之间的邻接关系。 3.线性表的链式存储表示主要有三种形式:线性链表、循环链表、双向链表。 4.线性链表: (1)线性链表的元素称为结点。 (2)结点除包含数据元素信息的数据域外,还包含指示直接后继的指针域。 (3)每个结点,在需要时动态生成,在删除时释放。 (4)N个结点(ai(1≤i ≤ n)的存储映像)链结成一个链表,即为线性表的链式存储结构。 (5)链表的每个结点中只包含一个指针域,故又称线性链表或单链表。 (6)线性链表可由头指针惟一确定。 (7)以线性表中的第一个数据元素a1的存储地址作为线性表的地址,称作线性表的头指针。 (8)有时为了操作方变,在第一个节点之前虚加一个"头结点",以指向头结点的指针为链表的头指针。 注意:头结点和头指针区分:不管带不带头结点,头指针始终指向链表的第一个结点,而头结点是带头结点的链表中第一个结点,结点内通常不存储信息。增加头结点的目的是为了方便运算。 头结点的优点:(1)由于第一个数据结点的位置被存放在头结点的指针域中,所以在链表的第一个位置上的操作和在表的其他位置上的操作一致,无需进行特殊处理;(2)无论链表是否为空,其头指针都指是向头结点的非空指针(空表中头结点的指针域为空) 单链表的头指针为head,不带头结点的判空条件:head==NULL 带头结点的判空条件:head->next==NULL (L ->[ |^] (head->next==NULL)) (9)找第i个元素getelement:在线性链表中找到第i个元素,并返回指针;从头结点开始,顺链一步步查找;查找第i个数据元素的基本操作为:移动指针,比较k和i(k为当前指针所指向的结点序号)。时间复杂度为O(n)。 (10)线性链表的插入:在线性链表的第i-1个元素与第i和元素之间插入一个新元素。s->next=p->next;p->next=s。(其中s为新元素)时间复杂度主要取决于getelement的时间复杂度,getelement的时间复杂度为O(n),因此线性链表插入的时间复杂度为O(n)。 注意:在单链表中第i个结点之前进行插入的基本操作:找到线性表中的第i-1个结点p,创建新结点s,然后修改第i-1个结点和s结点的后继指针。s->next=p->next;p->next=s (11)线性链表的删除:将线性链表的第i个元素删除。 找到线性表中第i-1个结点p,修改其指向后继的指针。 q=p->next;p->next=q->next;(e=q->data)delete q;(删除p->next这个结点)时间复杂度主要取决于getelement的时间复杂度,getelement的时间复杂度为O(n),因此线性链表删除的时间复杂度为O(n)。 (12)线性链表的创建:链表是一个动态的结构,不需要预分配空间,生成链表的过程是一个结点"逐个插入"的过程。依次调用insert即可,时间复杂度O(n^2)。n个结点,每个结点每次插入Insert函数,头指针指向最后,表尾插入故为n*n。 (13)线性链表的创建-头插法:即表头不断插入新结点。逆序输入数据值。头插法时间复杂度O(n)。 (14)线性链表的创建-尾插法:即表尾不断插入新结点。按链表序输入数据值。为记录尾结点,增加一个尾指针tail,指向最后一个结点。尾插法时间复杂度O(n) (15)单链表的合并:将两个有序链表合并成一个有序链表。 (16)拷贝构造函数被调用的三种情况:一个对象以值传递的方式传入函数体;一个对象以值传递的方式从函数返回;一个对象需要通过另一个对象进行初始化。 (17)赋值函数被调用的时机:当一个类的对象向该类的另一个对象赋值时,就会用到该类的赋值函数。 (18)拷贝构造函数与赋值函数比较: 调用拷贝构造函数来初始化一个对象: A a;A b(a); A b=a; 都是拷贝构造函数来创建对象b(b还不存在) 调用赋值函数对对象复制: A a;A b;b=a; 强调:这里a,b对象是已经存在的,是用a 对象来赋值给b的!! 5.静态链表:线性链表也可以采用静态数组实现。 与顺序表有两点不同: (1)每个元素包括数据域和指针域。 (2)元素的逻辑关系由指针确定。 与单链表的区别: (1)静态链表暂时不用结点,链成一个备用链表。 (2)插入时,从备用链表中申请结点。 (3)删除结点时,将结点放入备用链表。 6.循环链表: (1)循环链表是一种特别的线性链表。 (2)循环链表中最后一个结点的指针域指向头结点,整个链表形成一个环。 (3)在只有尾指针的单循环链表中: 表头插入结点:在只有尾指针的情况下,要在表头插入结点,首先需要找到尾结点,然后将新结点插入到尾结点之后。因此,表头插入结点的时间复杂度为 O(1)(常数时间),因为无论链表有多长,插入操作所需的时间都是相对固定的。 虽然在只有尾指针的情况下,插入结点时需要找到尾结点,但这并不会导致时间复杂度变为 O(n)。在单循环链表中,尾结点指向头结点,因此我们可以直接通过尾指针找到头结点,然后在头结点之后插入新结点。 因此,表头插入结点的时间复杂度仍然是 O(1),因为无论链表有多长,插入操作所需的时间都是相对固定的。 表尾插入结点:由于只有尾指针,直接在尾结点之后插入新结点即可。因此,表尾插入结点的时间复杂度同样为 O(1)。 (4)查找、插入和删除:与线性链表基本一致,差别仅在于算法中的循环条件不是p->next或p是否为空(^),而是它们是否等于头指针(L)。 注意循环链表带头结点判空:head->next==head 7.双向链表 (1)双向链表是一种特殊的线性链表:每个结点有两个指针,一个指针指向直接后继(next),另一个指针指向直接前驱(prior)。 (2)对于任何一个中间节点有:p=p->next->prior/p=p->prior->next。 (3)插入操作需要改变两个方向的指针:s->next=p;s->prior=p->prior;p->prior->next=s;p->prior=s; (4)删除操作需要改变两个方向的指针:p->prior->next=p->next;p->next->prior=p->prior; 8.双向循环链表 (1)存在两个环:一个是直接后继环,另一个是直接前驱环。 1.pn (x) = p0 + p1x + p2 x^ 2 + ... + pn x^ n 在计算机中,可以用一个线性表来表示:P = (p0 , p1 , …,pn) 2.pn(x)=p1x^e1+p2x^e2+...+pmx^em 线性表示((p1,e1),(p2,e2),...,(pm,em)) 1.基于空间的比较 (1)存储分配的方式:顺序表的存储空间是静态分配的,链表的存储空间是动态分配的。 (2)存储密度=结点数据本身所占的存储量/结点结构所占的存储总量 顺序表的存储密度=1,链表的存储密度<1 2.基于时间的比较 (1)存取方式:顺序表可以随机存取也可以顺序存取,链表必须顺序存取。 (2)插入、删除时移动元素个数:顺序表平均需要移动近一半元素,链表不需要移动元素只需要修改指针。 3.基于应用的比较 (1)线性表主要是存储大量数据,并用于查找时,采用顺序表比较好。 (2)若线性表存储的数据元素要经常插入和删除,采用链表比较好。 注意:某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用带尾指针的单循环链表最节省时间。 仅有尾指针的单循环链表,可以非常方便地找到尾结点,尾结点后面的第一个结点往往是头结点,头结点的下一个结点就是线性表的第一个结点。对最后一个元素和第一个元素操作对带尾指针的单循环链表是非常方便的 循环链表是线性表,它是线性表的链表存储结构之一。 在一个以h为头的单循环链表中,p指针指向链尾的条件是p->next=h。 1.栈是限定仅在表尾(top)进行插入或删除操作的线性表。 2.允许插入和删除的一端称为栈顶(top,表尾),另一端称为栈底(bottom,表头) 3.特点:后进先出 (LIFO) 4.栈的存储结构:顺序栈和链式栈。 5.顺序栈: (1)顺序栈是栈的顺序存储结构。 (2)利用一组地址连续的存储单元依次存放自栈底到栈顶的数据元素。 (3)指针top指向栈顶元素在顺序栈中的下一个位置,base为栈底指针,指向栈底的位置。 (4)top=0 或top=base 表示空栈。 (5)base=NULL表示栈不存在。 (6)当插入新的栈顶元素时,指针top+1。 (7)删除栈顶元素时,指针top-1。 (8)当top>stacksize时,栈满,溢出。 注意:向顺序表中压入新元素,应当先移动栈顶指针,再入栈,出栈时先取栈顶元素再移动指针 6.链栈: (1)栈的链式存储结构称为链栈,它是运算受限的单链表,可插入和删除操作仅限制在表头位置上进行。 (2)由于只能在链表头部进行操作,故链表没有必要像单链表那样附加头结点。栈顶指针就是链表的头指针。 (3)链栈中为何不设头指针?因为链栈只在链表头插入和删除结点,不可能在链表中间插入或删除结点,算法实现很简单,所以一般不设置头结点。 (4)链栈对比顺序栈主要优点在于,通常不会栈满的情况 7.C++中栈容器: (1)stack 模板类的定义在 (2)定义stack 对象的示例代码如下:stack (3)stack 的基本操作有: 入栈,如例:s.push(x); 出栈,如例:s.pop();注意,出栈操作只是删除栈顶元素,并不返回该元素。 访问栈顶,如例:s.top() 判断栈空,如例:s.empty(),当栈空时,返回true。 访问栈中的元素个数,如例:s.size()。 8.栈的应用举例 (1)数值转换: 将十进制转换为其他进制(d):N=(Nd)d+N mod d (计算顺序与输出顺序相反) (2)行编辑程序 (3)迷宫求解(用一个栈来记录已走过的路径) 设定当前位置为入口位置 do {若当前位置可通,则 { 将该位置插入栈顶(Push);若该位置是出口,则结束 否则切换当前位置的东邻方块为当前位置; 若栈不空则{ 如果找到栈顶位置的下一方向未经探索,则将该方向 方块设为当前位置}}}while(栈不空);找不到路径; (4)表达式求值:表达式由操作数、运算符和界限符组成,它们皆称为单词。 操作数:常数或变量。运算符:+, -, *, / 等。界限符:(, ), #(表达式开始及结束符)。 计算步骤:假设操作数栈NS和运算符栈OS, --(1)依次读取表达式,若为操作数,则直接进栈; 若为运算符(记为op2),转(2) --(2)将op2与运算符栈顶元素(记为op1)按P53的表3.13 比较优先权,并按如下规则进行操作: 若prec(op1) < prec(op2), 则op2入OS; 若prec(op1) = prec(op2), 则op1出栈,回到(1); 若prec(op1) > prec(op2), 则NS出2个操作数 num2,num1,op1出栈, 计算num2 op1 num2,结果入NS;回到(2) 。 --(3)重复(1)、(2)直至整个表达式求值完毕。 例如: Exp = a x b + (c - d / e) x f 前缀式: + x a b x - c / d e f 中缀式: a x b + c - d / e x f 后缀式: a b x c d e / - f x + 前缀式的运算规则为:连续出现的两个操作数和在它们之前且紧靠它们的运算符构成一个最小表达式; 中缀式丢失了括弧信息,致使运算的次序不确定;(编译系统中:中缀转后缀进行计算) 后缀式的运算规则为: 运算符在式中出现的顺序恰为表达式的运算顺序; 每个运算符和在它之前出现 且 紧靠它的两个操作数构成一个最小表达式。 结论:操作数之间的相对次序不变;运算符的相对次序不同。 得到后缀表达式后,我们在计算表达式时,可以设置一个栈,从左到右扫描后缀表达式,每读到一个操作数就将其压入栈中;每到一个运算符时,则从栈顶取出两个操作数进行运算,并将结果压入栈中,一直到后缀表达式读完。最后栈顶就是计算结果。 9.栈与递归的实现 (1)当在一个函数的运行期间调用另一个函数时,在运行该被调用函数之前,需先完成三项任务:将所有的实在参数、返回地址等信息传递给被调用函数保存;为被调用函数的局部变量分配存储区;将控制转移到被调用函数的入口。 (2)从被调用函数返回调用函数之前,应该完成下列三项任务:保存被调函数的计算结果;释放被调函数的数据区;依照被调函数保存的返回地址将控制转移到调用函数 (3)多个函数嵌套调用:后调用先返回!此时的内存管理实行“栈式管理”。 (4)递归函数执行的过程可视为同一函数进行嵌套调用。 注意:n个不同元素进栈,出栈元素不同排列个数为:(1/(n+1))C(2n,n)其中C为组合数,从2n个选n个 1.队列是只允许在表的一端进行插入,而在另一端删除元素的线性表。 2.在队列中,允许插入的一端叫队尾(rear),允许删除的一端称为对头(front)。特点:先进先出 (FIFO) 3.顺序队列:采用一组地址连续的存储单元依次存储从队列头到队列尾的元素。顺序队列有两个指针:队头指针front和队尾指针rear 4.顺序队列的进队和出队原则:进队时,新元素按rear指针位置插入,然后队尾指针增一,即 rear = rear + 1;出队时,将队头指针位置的元素取出,然后队头指针增一,即 front = front + 1;队头指针始终指向队列头元素;队尾指针始终指向队列尾元素的下一个位置。 5.顺序队列存在的问题: (1)当队尾指针指向队列存储结构中的最后单元时,如果再继续插入新的元素,则会产生溢出当队列发生溢出时。 (2)不能用rear==maxsize判断队满。 (3)队列存储结构中可能还存在一些空白位置(已被取走数据的元素),假上溢。(前面还有空位) (3)解决办法之一:将队列存储结构首尾相接,形成循环(环形)队列。 6.循环队列: (1)循环队列采用一组地址连续的存储单元。 (2)将整个队列的存储单元首尾相连。 (3)判断对空和队满: 对循环队列而言,无法通过front==rear来判断队列“空”还是“满”。 解决此问题的方法至少有三种: 其一是另设一个布尔变量以匹别队列的空和满; 其二是少用一个元素的空间,约定入队前,测试尾指针在循环意义下加1后是否等于头指针,若相等则认为队满(注意:rear所指的单元始终为空!!); front = rear,(都指向空)循环队列空;(rear+1) % MAXQSIZE = front,循环队列满。 其三是使用一个计数器记录队列中元素的总数(实际上是队列长度)。 (4)循环队列: 初始时:front=rear=0 出队,队首指针加一:front=(front+1)%maxsize 进队,队尾指针加一:rear=(rear+1)%maxsize 队列长度:(rear-front+maxsize)%maxsize 若牺牲一个单元来区分队列空和队列满,队列少用一个队列单元: 队满:(rear+1)%maxsize==front 队空:front==rear 题目:假设Q[ 11] (下标为从0到10)是一个循环队列,初始状态为front=rear=0;画出分别做完下列操作后队列的头尾指针的装填变化情况,若不能入队,请指出其元素,说明理由..(采用少用一个元素空间的方式) d,e,b,g,h入队 d,e出队 i,j,k,l,m入队 b 出队 n,o,p,q,r 入队 (上述答案采用front指向空,应改为rear时刻指向空!) 7.链队列 (1)链队列采用链表存储单元链队列中,有两个分别指示队头和队尾的指针。 (2)链式队列在进队时无队满问题,但有队空问题。 (3)链队列是链表操作的子集。 设长度为n的链队列用单循环链表表示,若只设头指针,则入度时间复杂度为O(n),出队时间复杂度为O(1);若只设尾指针,则入队时间复杂度和出队时间复杂度都为O(1),出队队头之间是tail->next即可。 删除一个结点,即出队时的指针操作为:front=front->next 8.C++中的队列容器 (1)queue 模板类的定义在 (2)定义queue 对象的示例代码如下:queue (3)queue 的基本操作有: 入队,如例:q.push(x); 将x 接到队列的末端。 出队,如例:q.pop(); 弹出队列的第一个元素,注意,并不会返回被弹出元素的值。 访问队首元素,如例:q.front(),即最早被压入队列的元素。 访问队尾元素,如例:q.back(),即最后被压入队列的元素。 判断队列空,如例:q.empty(),当队列空时,返回true。 访问队列中的元素个数,如例:q.size() 9.C++中的map容器 (1)map是c++的一个标准容器,提供了key和value的映射。map 模板类定义在 (2)map对象定义:map (3)map添加数据:map -2.maplive.insert(map -3.maplive[112]="April";//map中最简单最常用的插入添加! (4)map中查找数据: -1.使用map的下标运算符重载 map< std::string,int> mapTest; cout< -2.使用map的find接口。 map< std::string,int> mapTest; map< std::string,int>::iterator it = mapTest.find("index"); if(it!=mapTest.end()) cout<< it->second< 大题重点:表达式求值 (同种符号比较,先出现的优先级高) 1.字符串是n个字符的有限序列。 2.字符串术语: (1)空串:不含任何字符的串,串长度=0。 (2)空格串:仅由一个或多个空格组成的串。 (3)子串:由串中任意个连续的字符组成的子序列。 (4)主串:包含子串的串。 (5)位置:字符在主串中的序号。子串在主串中的位置以子串第一个字符在主串中的位置来表示。 (6)串相等的条件:当两个串的长度相等且各个对应位置的字符都相等时才相等。 (7)模式匹配:确定子串在主串中首次出现的位置的运算 3.字符串与线性表的关系 ---串的逻辑结构和线性表极为相似: (1)它们都是线性结构。 (2)串中的每个字符都仅有一个前驱和一个后继。 ---串与线性表又有区别,主要表现为: (1)串的数据对象约定是字符集。 (2)在线性表的基本操作中,以“单个元素”作为操作对象。 (3)在串的基本操作中,通常以“串的整体”作为操作对象,如:在串中查找某个子串、在串的某个位置上插入一个子串等。 4.字符串的操作 13种操作中的最小操作子集(五种):串赋值StrAssign;串比较StrCompare;求串长StrLength;串联接Concat;求子串SubString。 最小操作集: 这些操作不可能利用其他串操作来实现,反之,其他串操作(除串清除ClearString和串销毁DestroyString外)可在这个最小操作子集上实现。 5.字符串的操作(index) (1)串匹配(查找)的定义: INDEX (S, T, pos) (2)初始条件:串S和T存在,T是非空串,1≤pos≤StrLength(S)。 (3)操作结果:若主串S中存在和串T值相同的子串返回它在主串S中第pos个字符之后第一次出现的位置;否则函数值为0。 1.定长顺序存储表示(静态存储分配) (1)用一组地址连续的存储单元存储字符序列。 (2)如C语言中的字符串定义(以“\0”为串结束标志) char Str[MAXSTRLEN+1]; (3)定义了长度为MAXSTRLEN字符存储空间字符串长度可以是小于MAXSTRLEN的任何值(最长串长度有限制,多余部分将被截断) (4)隐含:一般可使用一个不会出现在串中的特殊字符在串值的尾部来表示串的结束。 优点:便于系统自动实现。 缺点:不利于某些操作(如合并). 例如,C语言中以字符‵\0′表示串值的终结,这就是为什么在上述定义中,串空间最大值maxstrlen为256,但最多只能存放255个字符的原因。 (5)显式:若不设终结符,可用一个整数来表示串的长度,那么该长度减1的位置就是串值的最后一个字符的位置(下标)。 优点:便于在算法中用长度参数控制循环过程。 2.堆分配存储表示 (1)在程序执行过程中,动态分配(malloc)一组地址连续的存储单元存储字符序列。 (2)在C++语言中,由new和delete动态分配与回收的存储空间称为堆。 (3)堆分配存储结构的串既有顺序存储结构的特点,处理方便,操作中对串长又没有限制,更显灵活。 3.链存储表示 (1)采用链表方式存储串值。 (2)每个结点中,可以存放一个字符,也可以存放多个字符。 (3)存储密度=数据元素所占存储位/实际分配的存储位。 1.求子串位置函数Index() (1)子串的定位操作通常称做串的模式匹配。 (2)算法(穷举法,朴素算法,BF(Brute-Force)算法): 从主串的指定位置开始,将主串与模式(要查找的子串)的第一个字符比较: 若相等,则继续逐个比较后续字符;若不等,从主串的下一个字符起再重新和模式的字符比较。 (3)在最好的情况下,除比较成功的位置外,其余位置仅需比较一次(模式第一个字符),其时间复杂度为:O(n+m)(n,m分别为主串和模式的长度) (4)但在最坏的情况下,如模式为‘00000001’,主串为‘0000000000000000000000000000000001’,则每次模式的前7个0都要与主串逐一比较,因此,其时间复杂度为:O(n*m) 2.KMP算法(时间复杂度O(n+m)) (1)当一趟匹配过程中出现字符比较不等(失配)时 --1.不需回溯i指针 --2.利用已经得到的“部分匹配”的结果 --3.将模式向右“滑动”尽可能远的一段距离(next[j])后,继续进行比较 (2)在模式串中第j个字符“失配”时,模式串第k个字符再同主串中对应的失配位置(i)的字符继续进行比较 :‘p1p2…pk-1’ = ‘pj-k+1pj-k+2…pj-1’ k值可以在做串的匹配之前,求出一般用next函数求取k值。 (3)next函数定义为(下标从1开始): --当j=1时next[j] = 0; --next[j] = max{k | 0 --当其它情况时next[j]=1。 (4)next函数定义为(下标从0开始): --当j=0时next[j] = -1; --next[j] = max{k | 0 --当其它情况时next[j]=0。 即寻找当前j前可相互重叠(不完全重叠)的最长真子串的长度。从第一个字符开始的子串的下一个元素的下标,指示出,如果j所指示的模式串的字符与目标串中的当前字符不相等时,j应回退的位置。 (5)求next[j]值的算法: --1. j的初值为0, next[0]=-1, k=-1 --2. While(j<模式串长度-1) { --(1).若k=-1或者Tj=Tk,则j++,k++,next[j]=k --(2).否则,k=next[k] } 这实际上也是一个匹配的过程,不同在于:主串和模式串是同一个串。 (6)KMP算法: --1.令i的初值为pos,j的初值为0 --2. While((i<主串长度)且(j<模式串长度)) { --(1).若j=-1或者si=pj,则i++, j++ --(2).否则,j=next[j] }//j=-1表示第一个字符失配 (7)时间复杂度: KMP()函数的时间复杂度为O(n),为了求模式串的next值,其算法与KMP很相似,其时间复杂度为O(m),因此,KMP算法的时间复杂度为O(n+m)。 (8)nextval: --1.首先计算next --2.比较当前字符t.ch[j]与其next值k所指字符 t.ch[k] --(1)不等: nextval[j]=next[j](即维持不变) --(2)相等: nextval[j]=nextval[k] 大题题目重点:字符串匹配 题目:求串eefegeef的next值。写出计算过程。假设主串为eefeefegeebeefegeeb,写出KMP算法查找串eefegeef的过程。 1.数组 数组是相同类型的数据元素的集合 数组是一种定长的线性表 数组一般不作插入和删除操作 一旦建立了数组,则结构中的数据元素个数和数据元素之间的关系就不再发生变动 判断:“数组的处理比其它复杂的结构要简单”,对吗? 答:对的。因为——① 数组中各元素具有统一的类型;② 数组元素的下标一般具有固定的上界和下界,即数组一旦被定义,它的维数和维界就不再改变。③数组的基本操作比较简单,除了结构的初始化和销毁之外,只有存取元素和修改元素值的操作。 2.一维数组 一维数组是一种简单的定长线性表 一维数组中的每个数据元素是一个(数)值 (原子)如:int A[8]={8,7,5,4,6,1,3,2} b=8,有8个数据元素,每个元素都是一个数值 3.二维数组 二维数组是这样一个定长线性表,其每个数据元素也是一个定长线性表(一维数组) Amxn= ((a00 a01…a0,n-1), (a10 a11…a1,n-1),…,(am-1,0 …am-1,n-1)) 4.多维数组 多维数组是这样一个定长线性表,其每个数据元素也是一个定长线性表(降一维) 如果其数据元素不是一维数组,则其数据元素的每个数据元素也是一个定长线性表 一直到最后一个定长线性表是一维数组,其每个数据元素为一个(数)值 1.数组的顺序表示 顺序存储:数组由相同类型的数据组成,且一般不作插入和删除操作,一般采用顺序存储结构表示数组 次序约定:计算机中,存储单元是一维结构,而数组为多维结构,则用一组连续的存储单元存放数组的数据元素时,有一个次序约定问题 Amxn= ((a00 a01…a0,n-1), (a10 a11…a1,n-1),…,(am-1,0 …am-1,n-1)) Amxn= ((a00 a10…am-1,0), (a01 a11…am-1,1),…,(a0,n-1 …am-1,n-1)) (1)行序(m行n列) LOC(aij) = LOC(a00) + (i x n + j) x L LOC(a00)是二维数组的起始存储地址 L为每个数据元素占用存储单元的长度(数目) Loc(aij)=Loc(a11)+[(j-1) +(i-1) * n ]*K (2)列序(m行n列) LOC(aij) = LOC(a00) + (i + j x m) x L LOC(a00)是二维数组的起始存储地址 L为每个数据元素占用存储单元的长度(数目) Loc(aij)=Loc(a11)+[(j-1) * m+(i-1)]*K 注意:已知二维数组Am,m按行存储的元素地址公式是: Loc(aij)= Loc(a11)+[(i-1) * m+(j-1)]K , 请问按列存储的公式相同吗? 答:尽管是方阵,但公式仍不同。应为: Loc(aij)=Loc(a11)+[(j-1) * m+(i-1)]K 2.多维数组的顺序表示 (1)以行序为主序存储,多(K)维数组元素存储位置 LOC(aj1,j2,..,jk) = LOC(a00 0) + ((b2xb3x…xbkxj1)+(b3x…xbkxj2)+…+jk) x L (2)以列序为主序存储,多(K)维数组元素存储位置 LOC(aj1,j2,..,jk) = LOC(a00 0) + ((b1xb2x…xbk-1xjk)+(b1x…xbk-2xjk-1)+…+j1)xLp 1.矩阵的压缩存储 (1)如果矩阵中有许多值相同的元素或者零元素(特殊矩阵、稀疏矩阵),为了节省存储空间,可以对这类矩阵进行压缩存储 (2)压缩存储:为多个值相同的元素只分配一个存储空间;对零元素不分配空间 2.特殊矩阵 (1)特殊矩阵:矩阵中,值相同的元素或者零元素的分布有一定规律 (2)对称矩阵:矩阵中,对角线两边对应位置上元素的值相同(aij=aji) (3)三角矩阵:矩阵中,对角线上(下)边元素值为常数(或者0),称下(上)三角矩阵 (4)如果只存储对称矩阵对角线上的值和对角线以上部分的值,则与上三角矩阵存储方法相同;如果只存储对称矩阵对角线上的值和对角线以下部分的值,则与下三角矩阵存储方法相同。 LOC(aij) = LOC(a00) + ((i+1)*i/2+j) *L 若i>=j,数组元素a[i] [j]在数组B中的存放位置为:1+2+..+i+j=(i+1)*i/2+j (i+1)*i/2为前i行元素总数,j为第i行第j个元素前元素个数(因为下标都从0开始) 若 i < j,数组元素 a[i] [j] 在矩阵的上三角部分, 在数组 B 中没有存放,可以找它的对称元素a[j] [i]:= j *(j +1) / 2 + i (在上则找对称到下) 若i <= j,数组元素A[i] [j]在数组B中的存放位置为 n + (n-1) + (n-2) + ... + (n-i+1) + j-i=(2*n-i-1) * i/2+j-i 其中(2*n-i-1) *i/2为前i行元素总数,j-i为第i行第j个元素前元素个数 若i > j,数组元素A[i] [j]在矩阵的下三角部分,在数组 B 中没有存放。因此,找它的对称元素A[j] [i]。 A[j] [i]在数组 B 的第 (2*n-j-1) * j / 2 + i 的位置中找到。 3.稀疏矩阵 (1)稀疏矩阵:矩阵中有许多值相同的元素或者零元素,而且分布没有任何规律 假设在mxn的矩阵中,有t个非零元素,令: δ= t /(m x n) 如果稀疏因子δ≤0.05,则称该矩阵为稀疏矩阵 (2)用三元组存储稀疏矩阵中的非零元素 三元组(i,j,aij)表示矩阵中i行、j列位置的值为aij (3)转置 设矩阵列数为m,对矩阵三元组表扫描m次 第k次扫描,找寻所有列号为k的项 将其行号变列号、列号变行号,顺次存于转置矩阵三元组表中 1.广义表的定义 (1)广义表:由n(≥0)个表元素组成的有限序列: LS = (a0, a1, a2, …, an-1) (2)LS是广义表的名称 (3)ai是广义表的元素,既可以是表(称为子表),也可以是数据元素(称为原子) (4)n为广义表的长度(n=0的广义表为空表) 2.广义表的举例 A=( ); //表A是一个空表 B=(e); //表B有一个原子 C=(a,(b,c,d)); //两个元素,分别为原子a和子表(b,c,d) D=(A,B,C); //有三个元素均为列表 E=(a,E); //递归的列表 其中,“表”以及“列表”,均指广义表 3.广义表的存储 广义表一般采用链式存储结构 表结点[Tag=1|hp|tp];原子结点[Tag=0|atom];hp表示表头,tp表示表尾 4.广义表的表头 表头(head):广义表的第一个元素 表头既可以是原子,也可以是列表(广义表) GetHead(B) = e;GetHead(D) = A;GetHead((B,C)) = B 5.广义表的表尾 表尾(tail):广义表中,除表头外的部分 注意:表尾一定是列表,要加括号! GetTail(B) = ();GetTail(D) = (B,C);GetTail((B,C)) = (C) GetTail【(b, k, p, h)】= (k,p,h) ; GetHead【( (a,b), (c,d) )】= (a,b) ; GetTail【( (a,b), (c,d) )】=((c,d)) ; GetTail【 GetHead【((a,b),(c,d))】】=(b); GetTail【(e)】=(); GetHead 【 ( ( ) )】=(); GetTail【 ( ( ) ) 】= (); 1.树的定义(Tree) (1)树是有n(n≥0)个结点的有限集合。 (2)如果 n=0,称为空树; (3)如果 n>0,称为非空树,对于非空树,有且仅有一个特定的称为根(Root)的节点(无直接前驱) (4)如果 n>1,则除根以外的其它结点划分为 m (m>0)个互不相交的有限集 T1, T2 ,…, Tm,其中每个集合本身又是一棵树,并且称为根的子树(SubTree)。(此为递归定义) (5)每个结点都有唯一的直接前驱,但可能有多个后继。 2.树的基本术语 (1)结点:包含一个数据元素及若干指向其子树的分支;(包括分支!) (2)结点的度:结点拥有的子树数;结点的深度是从根结点开始自顶向下逐层累加;结点的高度是从叶节点开始自底向上逐层累加。 (3)叶结点:度为0的结点[没有子树的结点] (终端结点 ) (4)分支结点:度不为0的结点[包括根结点],也称为非终端结点。除根外称为内部结点。 注意:除根之外都是内部结点! (5)孩子:结点的子树的根[直接后继,可能有多个] (6)双亲:孩子的直接前驱[最多只能有一个] (7)兄弟:同一双亲的孩子 (8)子孙:以某结点为根的树中的所有结点 (9)祖先:从根到该结点所经分支上的所有结点 (10)层次:根结点为第一层,其孩子为第二层,依此类推 (11)深度:树中结点的最大层次(从根算第一层),也为树的高度。 (12)有序树:子树之间存在确定的次序关系。 (13)无序树:子树之间不存在确定的次序关系。 (14)森林:互不相交的树的集合。对树中每个结点而言,其子树的集合即为森林。任何一棵非空树是一个二元组 Tree = (root,F)其中:root 被称为根结点 ,F 被称为子树森林。 3.树型结构与线性结构的区别在于:一个元素可以有多个后继。 4.树的相关性质: (1)树中的结点数等于所有结点的度数加一 (2)度为m的树中第i层上至多有m^(i-1)个结点 (3)高度为h的m叉树至多有(m^h-1)/(m-1)个结点 (4)具有n个结点的m叉树的最小高度为logm(n(m-1)+1) 1.二叉树是一种特殊的树,每个结点最多有2棵子树,子树有左右之分。 2.在二叉树的第i层上最多有2^(i-1)个结点。 3.深度为k的二叉树最多有2^k-1个结点。 4.如果二叉树终端结点数为n0(也为叶子结点数),度为2的结点数为n2,则n0=n2+1 1.一个深度为k且有2^k-1个结点的二叉树。 2.每层上的结点数都是最大数。 3.可以自上而下、自左至右连续编号。 1.当且仅当每一个结点都与深度相同的满二叉树中编号从1到n的结点一一对应的二叉树。 2.叶子结点只在最大两层上出现。 3.左子树深度与右子树深度相等或大1。 4.具有n个结点的完全二叉树,其深度为floor(log2(n)) +1 5.在完全二叉树中,结点i的双亲为 i/2; 结点i的左孩子LCHILD(i)=2i; 结点i的右孩子RCHILD(i)=2i+1. 1.用一组连续的存储单元依次自上而下,自左至右存储结点。 1.二叉链表:二叉链表结点由一个数据域和两个指针域组成,采用数据域加上左、右孩子指针。 2.三叉链表:采用数据域加上左、右孩子指针及双亲指针。 1.遍历二叉树:树的遍历就是按某种次序访问树中的结点,要求每个结点访问一次且仅访问一次(非线性结构线性化)。 2.一个二叉树由根节点与左子树和右子树组成,设访问根结点用D表示,遍历左、右子树用L、R表示,如果规定先左子树后右子树,则共有三种组合 (1)DLR [先序遍历] (2)LDR [中序遍历] (3)LRD [后序遍历] 1.利用空指针 (1)在有n个结点的二叉树中,必定存在n+1个空链域; (2)因为每个结点有两个链域(左、右孩子指针),因此共有2n个链域; (3)除根结点外,每个结点都有且仅有一个分支相连,即n-1个链域被使用。 1.树的存储结构 (1)双亲表示法:采用一组连续的存储空间;由于每个结点只有一个双亲,只需要一个指针。 (2)孩子表示法:可以采用多重链表,即每个结点有多个指针,最大缺点是空链域太多[(d-1)n+1个]。将每个结点的孩子排列起来,用单链表表示;将每个结点排列成一个线性表。 (3)孩子兄弟表示法(常用):采用二叉链表左边指针指向第一个孩子,右边指针指向兄弟。 2.树与二叉树的对于关系 (1)树与二叉树都可以采用二叉链表作存储结构。 (2)任意给定一棵树,可以找到一个唯一的二叉树(没有右子树)。 3.森林与二叉树的对应关系 4.树的遍历: (1)先根(次序)遍历(树的先根-----二叉树的先序) (2)后根(次序)遍历(树的后根-----二叉树的中序) 5.森林的遍历: (1)先序遍历:依次从左至右对森林中的每一棵树进行先根遍历。 (2)中序遍历:依次从左至右对森林中的每一棵树进行后根遍历。 1.最优二叉树 (1)路径:从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径 (2)路径长度:路径上的分支数目 (3)树的路径长度:从树根到每个结点的路径长度之和 (4)结点的带权路径长度:从结点到树根之间的路径长度与结点上权的乘积 (5)树的带权路径长度(WPL):树中所有叶子结点的带权路径长度之和(是叶子结点!) (6)最优二叉树:假设二叉树有n个叶子,其每个叶子结点带权wi,则带权路径长度WPL最小的二叉树称为最优二叉树 (7)赫夫曼(Huffman)树就是一棵最优二叉树 2.赫夫曼树 (1)在Huffman树中,权值最大的结点离根最近;权值最小的结点离根最远。 (2)构建算法: ---1.根据给定的n个权值(w1, w2, …, wn)构成n棵二叉树的集合F={T1, T2, …, Tn},其中每棵二叉树Ti中只有一个带权为wi的根结点,左右子树为空。 ---2.在F中选取两棵根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置其根结点的权值为其左右子树根结点的权值之和。 ---3.在F中删除这两棵树,同时将新得到的二叉树加入F中。 ---4.重复2, 3,直到F只含一棵树为止。 注意:画图时每一次要把所有点都画出来! (3)编码算法:(从叶子开始!) ---1.从Huffman树的每一个叶子结点开始 ---2、依次沿结点到根的路径,判断该结点是父亲结点的左孩子还是右孩子,如果是左孩子则得到编码‘0’,否则得到编码‘1’,先得到的编码放在后面 ----3、直到到达根结点,编码序列即为该叶子结点对应的Huffman编码 (4)译码算法: ---1.指针指向Huffman树的根结点,取第一个Huffman码 ---2、如果Huffman码为‘0’,将指针指向当前结点的左子树的根结点;如果Huffman码为‘1’,将指针指向当前结点的右子树的根结点 ---3、如果指针指向的当前结点为叶子结点,则输出叶子结点对应的字符;否则,取下一个Huffman码,并返回2 ---4、如果Huffman码序列未结束,则返回1继续译码 题目:(4)设给出一段报文:GOOD_GOOD_GOOD_GOOOOOOOO_OFF字符集合是 { O, G, _, D, F},各个字符出现的频度(次数)是 W={ 15, 4, 4, 3, 2}。 若给每个字符以等长编码 O: 000 G: 001 _: 010 D: 011 F: 100 则总编码长度为 (15+4+4+3+2) * 3 = 84. 若按各个字符出现的概率不同而给予不等长编码,可望减少总编码长度。 各字符{ O, G, _, D, F }出现概率为 { 15/28, 4/28, 4/28, 3/28, 2/28 },化整为 { 15, 4, 4, 3, 2 } 令左孩子分支为编码‘0’,右孩子分支为编码‘1’将根结点到叶子结点路径上的分支编码,组合起来,作为该字符的Huffman码,则可得到: O:1 _:011 G:010 D:001 F:000 则总编码长度为 15*1+(2+3+4+4) *3 = 54 < 84 Huffman是一种前缀编码,解码时不会混淆 如GOOD编码为:01011001 如Huffman编码序列01011001,译码后的字符串为GOOD (5)前缀编码:指的是,任何一个字符的编码都不是同一字符集中另一个字符的编码的前缀。利用赫夫曼树可以构造一种不等长的二进制编码,并且构造所得的赫夫曼编码是一种最优前缀编码,即使所传电文的总长度最短。 题目:(1)设有字符集{A, B, C, D},各字符在电文中出现的次数集为{1, 3, 5, 7},则哈夫曼树构造过程如下图所示: (最终哈夫曼树的构造结果如上,一定要记得写结果!) (2)已知一颗完全二叉树第7层有20个结点,则整棵树的结点数? 83 (3)在二叉树中,指针p指向的结点是叶子,则p满足条件? p->leftChild==NULL&&p->rightChild==NULL (4)由3个结点组成的二叉树最多有多少种形态? 5 (5)已知一棵完全二叉树有100个结点,根节点编号为1,按层次遍历编号,则结点45的父亲编号为?结点50的孩子编号情况如何? 22;100,101 1.图是由顶点集合(vertex)及顶点间的关系集合组成的一种数据结构: Graph=( V, E ) 其中V = {x | x属于数据对象}是顶点的有穷非空集合 E是顶点之间关系的有穷集合,包括E1 = {(x, y) | x, y 属于 V } 边的集合或E2 = { 注意:在一个图中,所有顶点的度数之和等于边数的2倍! 2.无向图(无向图的邻接矩阵是对称矩阵) 用(x,y)表示两个顶点x,y之间的一条边(edge)N={V,E},V={0,1,2,3,4,5},E={(0,1), (0,4), (0,5), (1,2), (1,3), (1,5), (2,3), (3,4), (3,5), (4,5)} (1)邻接点:如果(x,y)属于E,称x,y互为邻接点,即x,y相邻接 (2)依附:边(x,y)依附于顶点x,y (3)相关联:边(x,y)与x,y相关联 (4)顶点的度:和顶点相关联的边的数目,记为TD(x) 3.无向图(完全图):如果无向图有n(n-1)/2条边,则称为无向完全图。 4.有向图 用 (1)邻接:如果 (2)自x相关联:弧 (3)入度:以顶点为头的弧的 数目,记为ID(x) (4)出度:以顶点为尾的弧的 数目,记为OD(x) (5)度:TD(x)=ID(x)+OD(x) 4.有向图(完全图):如果有向图有n(n-1)条边,则称为有向完全图。 5.路径:是一个从顶点x到y的顶点序列(x, vi1, vi2,…, vin, y)其中,(x,vi1),(vij-1,vij),(vin,y)皆属于E。 6.回路: (1)回路或环:路径的开始顶点与最后一个顶点相同,即路径中(x, vi1, vi2,…, vin, y),x=y (2)简单路径:路径的顶点序列中,顶点不重复出现 7.连通: (1)连通:如果顶点x到y有路径,称x和y是连通的 (2)连通图:图中所有顶点都连通 8.子图: 设有两个图 G=(V, E) 和 G’=(V’, E’)。 若 V’包含于 V 且 E’包含于E, 称图G’是图G的子图 9.生成树 一个连通图的生成树是一个极小连通子图,它含图中全部n个顶点,但只有足以构成一棵树的n-1条边。 图的存储结构有4种:邻接矩阵,邻接表,十字链表(有向),邻接多重表(无向) 1.邻接矩阵 (1)邻接矩阵:记录图中各顶点之间关系的二维数组。 (2)对于不带权的图,以1表示两顶点存在边(或弧)(相邻接),以0表示两顶点不邻接,即 如果(i,j)属于E 或 (3)无向图的邻接矩阵为对称矩。 (4)其第i行1的个数等于顶点i的出度OD(i),第j列1的个数等于顶点j的入度ID(j)。 2.邻接矩阵(网络) 在网络中,两个顶点如果不邻接,则被视为距离为无穷大;如果邻接,则两个顶点之间存在一个距离值(即权值),即如果(i,j)属于E 或 3.邻接表 (1)邻接表是图的一种链式存储结构。 (2)在邻接表中,每个顶点设置一个单链表,其每个结点都是依附于该顶点的边(或以该顶点为尾的弧)。 无向图中,注意左侧的表格数组! (邻接表(有向网络)) (3)在一个无向图的邻接表表示中,每个顶点对应一个链表,链表中包含该顶点相邻的其他顶点。每条边在邻接表中对应两个链表结点,因为无向图的边是双向的。给定图包含 10 个顶点和 20 条边,那么每个顶点的平均度数是 2×边数/顶点数=4。 由于每个链表结点对应一条边,总的链表结点数是 2×边数。所以,邻接表包含 2×20=40 个链表结点。 注意:n个结点,e条边的无向图邻接表中,有n个头结点和2e个表结点 (4)在有向图的邻接表中不易找到指向该顶点的弧。 (5)对于有向图的邻接表,其第i个链表中结点的个数只是该顶点的出度;如果要计算入度,必须遍历整个邻接表[也可以建立一个逆邻接表]要判定两个顶点i和j是否有边(或弧),必须搜索整个第i个和第j个链表,不及邻接矩阵方便。 在有向图的逆邻接表找每个结点入度: (5)无向邻接表所需存储空间O(|V|+2|E|),有向邻接表所需存储空间O(|V|+|E|) (6)对于稀疏图,采用邻接表能极大节省空间。 4.十字链表(有向图!) (1)十字链表是有向图的另一种存储结构 (2)十字链表是将有向图的邻接表和逆邻接表结合起来的一种存储结构 绿色代表:相同弧尾(邻接表) 红色代表:相同弧头(逆邻接表) 5.邻接多重表(无向图!) (1)邻接多重表是无向图的另一种存储结构 (2)在无向图中,一条边要用2个结点表示(分别从2个顶点的角度看) (3)在邻接多重表中,一条边只用一个结点表示 (4)将所有具有某顶点的结点,全部用链连结起来,链所在的域为该顶点对应的指针域 1.从图的某一顶点开始,访遍图中其余顶点,且使每一个顶点仅被访问一次 2.图的遍历主要应用于无向图 3.深度优先搜索DFS (1)图的深度优先搜索是树的先根遍历的推广 (2)图中可能存在回路,且图的任一顶点都可能与其它顶点相通,在访问完某个顶点之后可能会沿着某些边又回到了曾经访问过的顶点。 (3)为了避免重复访问,可设置一个标志顶点是否被访问过的辅助数组 visited [ ] (4)算法: 所有顶点访问标志visited[]设置为FALSE 从某顶点v0开始,设v=v0 --1.如果visited[v]=FALSE,则访问该顶点,且设visited[v]=TRUE --2.如果找到当前顶点的一个新的相邻顶点w,设v=w,重复1 --3.否则(说明当前顶点的所有相邻顶点都已被访问过,或者当前顶点没有相邻顶点),如果当前顶点是v0,退出;否则返回上一级顶点,重复2 (5)存储结构未定,则遍历顺序不确定。 4.广度优先搜索(BFS) (1)广度优先搜索(BFS)是一种分层搜索方法 (2)BFS每向前走一步可能访问一批顶点, 不存在往回退的情况 (3)BFS不是一个递归的过程。 (4)算法: 所有顶点访问标志visited[]设置为FALSE 从某顶点v0开始,访问v0,visited[v0]=TRUE,将v0插入队列Q --1.如果队列Q不空,则从队列Q头上取出一个顶点v,否则结束 --2.依次找到顶点v的所有相邻顶点v’,如果visited[v’]=FALSE,访问该顶点v’,visited[v’]=TRUE,将v’插入队列Q --3.重复1,2 5.结论 (1)如果图为连通图,则从该图的任意一个顶点开始执行一次深度优先遍历或广度优先遍历,即可访问该连通图的所有顶点。 (2)如果图为非连通图,则依次从未访问过的顶点开始执行深度优先遍历或广度优先遍历,直至所有的顶点均被访问。 (3)事实上执行一次深度优先可以遍历一个连通分支。图有多少个连通分支,就调用多少次深度优先遍历。 6.时间复杂度 (1)可以看出无论是深度优先遍历还是广度优先遍历,其实质都是透过边或弧找邻接点的过程,只是访问的顺序不同。 (2)两者的时间复杂度相同,取决于采取的存储结构,若用邻接矩阵为O(N^2),若 用邻接表则为O(N+E) 即O(n)。 注意:深度优先搜索遍历类似于树的先根遍历,广度优先搜索遍历类似于树的层次遍历。 题目:假设用邻接表存储,下图中边上序号表示边输入顺序(链表头插入),画出该图邻接表,写出用该邻接表存储时其深度优先顺序和广度优先顺序。 1.无向图的连通性 如果无向图中,存在不连通的顶点,则该图称为非连通图。 2.无向图的连通分量 (1)非连通图的极大连通子图叫做连通分量。 (2)若从无向图的每一个连通分量中的一个顶点出发进行DFS或BFS遍历,可求得无向图的所有连通分量的生成树(DFS或BFS生成树)。 (3)所有连通分量的生成树组成了非连通图的生成森林。 (4)连通分量是无向图的极大连通子图,其中极大的含义是将依附于连通分量中顶点的所有边都加上,所以连通分量中可能存在回路。 (5)生成树是一个连通图的极小连通子图,包含连通图的所有顶点,且使其连通的边数最少。 (6)极大连通子图是无向图(不一定连通)的连通分量。极小连通子图是连通无向图的生成树。 (7)任何连通图的连通分量只有一个,即使其自身。 3.无向图的生成树 (1)由DFS遍历,求得连通分量称为DFS生成树 (2)由BFS遍历,求得连通分量称为BFS生成树 4.有向图的强连通分量 强连通图是指在有向图中,对于每一对不同的顶点u和v,都存在从u到v及v到u的路径,n个顶点用弧向同一方向连接形成一个环时,就是强连通图,需要弧最少。 (1)深度优先搜索算法是求有向图的强连通分量的有效方法。 (2)在有向图G上,从某个顶点出发沿该顶点为尾的弧进行深度优先搜索,并按其所有邻接点的搜索都完成(即退出dfs函数)的顺序将顶点排列起来。 (3) 在有向图G上,从最后搜索的顶点出发,沿着以该顶点为头的弧作逆向的深度优先搜索遍历。若此次遍历不能访问到有向图中的所有顶点,则从余下顶点中最后完成搜索的顶点出发继续进行逆向的深度优先搜索遍历。 (4)每次调用dfs作逆向深度优先遍历所访问到的顶点集便是有向图G中的一个强连通分量的顶点集。 (5)为了实现以上遍历,需要对深度优先遍历算法作以下修改 --1.在进入DFStraverse函数时,对计数变量count进行初始化,count=0 --2.在退出DFS函数之前,将完成搜索的顶点号记录在另一个辅助数组finish【vernum】中,在DFS函数结束之前加上finished【++count】=v 5.最小生成树 (1)如果无向图中,边上有权值,则称该无向图为无向网 (2)如果无向网中的每个顶点都相通,称为连通网 (3)最小生成树(Minimum Cost Spanning Tree)是代价最小的连通网的生成树,即该生成树上的边的权值和最小 (4)准则:必须使用且仅使用连通网中的n-1条边来联结网络中的n个顶点;不能使用产生回路的边;各边上的权值的总和达到最小。常用于道路建设、线路铺设等应用中计算成本。 6.Prim普里姆算法生成最小生成树 (1)假设N=(V,E)是连通网 (2)TE是N上最小生成树中边的集合 --1.U={u0},(u0属于V), TE={} --2.在所有u属于U,v属于V-U的边(u,v)属于E中找一条代价最小的边(u,v0)并入集合TE,同时v0并入U --3.重复2,直到U=V。T=(V,TE)即为所求最小生成树。 (记得每一次画上所有点!) (Prim V1-Vn mindis flag U) (3)在生成树的构造过程中,图中 n 个顶点分属两个集合:已落在生成树上的顶点集 U 和尚未落在生成树上的顶点集V-U,应在所有连通U中顶点和V-U中顶点的边中选取权值最小的边逐渐加入TE,相应顶点加入U中。 7.Kruscal克鲁斯卡尔算法生成最小生成树 (1)假设N=(V,E)是连通网 --1.非连通图T={V,{}},图中每个顶点自成一个连通分量 --2.在E中找一条代价最小,且其两个顶点分别依附不同的连通分量的边,将其加入T中 --3.重复2,直到T中所有顶点都在同一连通分量上 (2)把边按照从小到大的顺序排序; 判断边的顶点不在同一个联通分支-》并查集。 8.生成最小生成树: 当为稠密图(邻接矩阵)prim算法 O(n^2) 当为稀疏图(邻接表)Kruscal算法O(eloge) 1.最短路径 (1)最短路径是求从图(或网)中某一顶点,到其余各顶点的最短路径 (2)最短路径与最小生成树主要有三点不同: --1.最短路径的操作对象主要是有向图(网),而最小生成树的操作对象是无向图 --2.最短路径有一个始点,最小生成树没有(Prim算法有起点) --3.最短路径关心的是始点到每个顶点的路径最短,而最小生成树关心的是整个树的代价最小 2.基本概念 (1)路径长度:一条路径上所经过的边的数目 (2)带权路径长度:路径上所经过边的权值之和 (跟树的带权路径长度区分好!) (3)最短路径:(带权)路径长度(值)最小的那条路径 (4)最短路径长度或最短距离:最短路径长度 3.Dijkstra算法(O(n^3)) (1)Dijkstra算法思想:采用按路径长度递增的次序产生最短路径 --1.设置两个顶点的集合U和T,集合U中存放已找到最短路径的顶点,集合T中存放当前还未找到最短路径的顶点。 --2.初始状态时,集合U中只包含源点,设为v0; --3.然后从集合T中选择到源点v0路径长度最短的顶点u加入到集合U中; --4.集合U中每加入一个新的顶点u都要修改源点v0到集合T中剩余顶点的当前最短路径长度值,集合T中各顶点的新的当前最短路径长度值,为原来的当前最短路径长度值与从源点过顶点u到达该顶点的路径长度中的较小者。 --5.转到3,此过程不断重复,直到集合T中的顶点全部加入到集合U中为止。 (2)在Dijkstra算法中,引进了一个辅助向量D 每个分量D[i]表示当前所找到的从始点到每个终点vi的最短路径长度。 D[i]初值为始点v0到各终点vi的直接距离,即若从始点到某终点有(出)弧,则为弧上的权值,否则为∞。 (3)得到路径: --1.设置另一个辅助向量path[],用来存放得到的从源点v0到其余各顶点的最短路径上到达目标顶点的前一顶点下标。 --2.为每一个顶点i设置辅助向量pathi,用来存放得到的从源点v0到该顶点的最短路径中依次访问过的顶点。第一个值是路径上的顶点数。 题目:对下图求从V0出发到各顶点的最短路径。 (最后的过程5“无”一定要加,且要补充最后最短路径的结果!) 4.求n个顶点之间的最短路径 (1)用Dijkstra算法也可以求得有向图G=(V,E)中每一对顶点间的最短路径。 方法是: 设置二维数组D [i] [j],数组每一行D[i]表示从顶点vi出发到其它顶点的最短路径,即每次以一个不同的顶点vi为源点重复Dijkstra算法便可求得每一对顶点间的最短路径,时间复杂度是O(n^3) 。 (2)弗罗伊德(Floyd)算法,其时间复杂度仍是O(n^3) , 但算法形式更为简明,步骤更为简单,数据结构是基于图的邻接矩阵。 将图中一个顶点Vk 加入到S中,修改A[i] [j]的值,修改方法是: A[i] [j] = Min{ A[i] [j] , (A[i] [k]+A[k] [j]) } 找路径:定义二维数组Path[n] [n] (n为图的顶点数) ,元素Pathi保存从Vi到Vj的最短路径所经过的顶点。若Path[i] [j]=k:从Vi到Vj 经过Vk ,最短路径序列是(Vi , …, Vk , …, Vj) ,则路径序列:(Vi , …, Vk)和(Vk , …, Vj)一定是从Vi到Vk和从Vk到Vj 的最短路径。从而可以根据Path[i] [k]和Path[k] [j]的值再找到该路径上所经过的其它顶点,…依此类推。 初始时令Path[i] [j]=-1,表示从Vi到Vj 不经过任何(S中的中间)顶点。当某个顶点Vk加入到S中后使A[i] [j]变小时,令Path[i] [j]=k。 1.AOV网(有向图!) (1)如果用有向图的顶点表示活动,用弧表示活动间的优先关系,则称该有向图为顶点表示活动的网AOV(Activity On Vertex Network) (2)AOV的应用包括流程图、工程安排等。对AOV网,应判定图中不存在环,因为存在环意味着某项活动应以自己为先决条件。 2.有向无环图(DAG)Directed Acycline Graph 3.检查有向图中是否有回路: (1)深度优先搜索 :从某个顶点v出发,进行DFS,如果存在一条从顶点u到v的回边,则有向图中存在环。 (2)拓扑排序:由严格偏序定义得到的拓扑有序的操作称拓扑排序。 若集合X上的关系R是:⑴.自反的:x R x⑵.反对称的:x R y => y R x⑶.传递的:xRy & yRz => xRz 则称R是集合X上的偏序关系。 全序:设关系R是集合X上的偏序,如果对每个x,y属于X,必有xRy或者yRx,则称R是X上的全序关系。 偏序:指集合中仅有部分成员之间可比较。 全序:指集合中全体成员之间均可比较 算法:⑴.在有向图中选一个没有前驱的顶点(无入度)且输出之⑵.从图中删除该顶点和所有以它为尾的弧;重复⑴⑵两步,直到所有顶点输出为止或跳出循环。 (3)拓扑排序与AOV网: 拓扑排序可检测AOV网是否存在环。如果通过拓扑排序能将AOV网络的所有顶点都排入一个拓扑有序的序列中, 则该网络中必定不会出现有向环。反之其中存在环。 4.拓扑排序实现 (1)没有前驱的顶点 == 入度为零的顶点 (2)删除顶点及以它为尾的弧 == 弧头顶点的入度减1 题目:写出某AOV网的邻接表存储结构如下,写出分别用队列和栈存储入读为零的顶点时的拓扑排序序列。 栈的拓扑:C4,C0,C2,C1,C3,C5 队列的拓扑:C2,C4,C0,C1,C5,C3 5.AOV-网 (1)如果用有向图的顶点表示事件,用弧表示活动,则称该有向图为边表示活动的网AOE(Activity On Edge) (2)AOE应该同样是DAG,AOE包括估算工程的完成时间。 注意:AOE网和AOV网都是有向无环图,不同在于AOE网中的边有权值;而AOV网中的边无权值,仅表示顶点之间的前后关系。 6.关键路径 (1)工程问题的AOE网中,从工程开始(顶点)到工程结束(顶点)之间路径长度最长的路径叫关键路径(最长路径!) (2)提前完成关键路径上的活动,工程进度会加快 (3)提前完成非关键路径上的活动,对工程无帮助 7.关键活动 (1)关键路径上的所有活动称为关键活动 (2)找到工程AOE中的所有关键活动,即找到了关键路径 8.关键活动有关的量 (1)e(i):活动ai最早开始时间 (2)l(i):活动ai最迟开始时间 (3)l(i)-e(i):活动ai开始时间余量 (4)如果l(i)=e(i),则称活动ai为关键活动 (5)ve(j):事件vj最早开始时间 (6)vl(j):事件vj最迟开始时间 (7)e(i)=ve(j) (8)l(i)=vl(k)-dut( dut( (9)活动的最早开始时间是活动的弧尾事件的最早发生时间, 活动的最晚发生时间是活动的弧头事件的最晚发生时间减去活动的持续时间。 j------>k(此边即活动的编号为i) (10)从ve(0)=0开始向前递推(事件的最早发生时刻) 事件的最早发生时间是以其为弧头事件的所有弧尾事件的最早发生时间与对应弧活动的持续时间之和的最大值 (11)从vl(n-1)=ve(n-1)起向后递推(事件的最晚发生时刻) 事件的最晚发生时间是以其为弧尾事件的所有弧头事件的最晚发生时间与对应弧活动的持续时间之差的最小值。 9.求关键活动算法(先计算事件,再计算活动) (1)从始点v0出发,令ve[0]=0(源点),按拓扑有序求ve[j] ve[k]=max{ve[j]+Weight(vj,vk)} (2)从终点vn-1出发,令vl[n-1]=ve[n-1](汇点),按逆拓扑有序求vl[i] vl[k]=min{ vl[j]-Weight(vk,vj)} (简单记忆:我们都想晚点开学早点放假,晚点开学即最早开始取max,早点放假即最晚开始取min) (3)根据各顶点的ve和vl值,求每条弧(活动)ai的最早开始时间e[ai]和最迟开始时间l[ai] 若边 l[i]=vl[j]-Weight(vk,vj) (4)如果e[ai]=l[ai],则ai为关键活动(e[i]-l[i]==0) (5)如果ve[i]=vl[i],则vi为关键路径上的事件 题目:下表给出了某工程各工序之间的优先关系和各工序所需的时间。 问: 该工程是否能够顺利进行? 如果能,请问要花多长时间? 缩短那些工序可以缩短整个工程的完工时间? 1.查找表 (1)查找表是由同一类型的数据元素(或记录)构成的集合 (2)对查找表的操作: --1.查询某个“特定的”数据元素是否在查找表中; --2.检索某个“特定的”数据元素的各种属性; --3.在查找表中插入一个数据元素; --4.从查找表中删去某个数据元素 (3)静态查找表:仅作查询和检索操作的查找表。 (4)动态查找表:在查找过程中同时插入查找表中不存在的数据元素,或者从查找表中删除已存在的某个数据元素。 2.关键字 (1)关键字是数据元素(或记录)中某个数据项的值,用以标识(识别)一个数据元素(或记录 注意:关键字是某个数据项的值!不是数据元素 (2)主关键字:可以识别唯一的一个记录的关键字 (3)次关键字:能识别若干记录的关键字 3.查找 (1)查找是根据给定的某个值,在查找表中确定一个其关键字等于给定值的数据元素(或记录)。 (2)查找成功:在查找表中查找到指定的记录。 (3)查找不成功:在查找表中没有找到指定记录。 4.衡量查找算法的标准 (1)时间复杂度 (2)空间复杂度 (3)平均查找长度ASL 5.平均查找长度ASL (1)平均查找长度定义为确定记录在表中的位置所进行的和关键字比较的次数的平均值。 (2)ASL = ∑ PiCi (i为1到n) n为查找表的长度,即表中所含元素的个数;Pi为查找第i个元素的概率(∑Pi=1);Ci是查找第i个元素时同给定值K比较的次数。 1.顺序查找 (1)顺序查找算法是顺序表的查找方法。 (2)在顺序查找算法中,以顺序表或线性链表表示静态查找表。 (3)顺序查找算法: --1.从表中最后一个记录开始 --2.逐个进行记录的关键字和给定值的比较 --3.若某个记录比较相等,则查找成功 --4.若直到第1个记录都比较不等,则查找不成功 (4)算法性能分析 对顺序表而言,Ci=n-i+1 在等概率查找的情况下,Pi=1/n ASL(成功)=n*P1 +(n-1)P2 +…+ 2Pn-1+ Pn = (n+1)/2 (5)顺序查找(不等概率) 如果被查找的记录概率不等时,取 Pn≥Pn-1≥···≥P2≥P1; 若查找概率无法事先测定,则查找过程采取的改进办法是,在每次查找之后,将刚刚查找到的记录直接移至表尾的位置上。 (6)特点: 优点:1.简单2.适应面广(对表的结构无任何要求) 缺点:1.平均查找长度较大2.特别是当n很大时,查找效率很低。 2.折半查找(有序表!) (1)折半查找算法是有序表的查找方法。 (2)在折半查找算法中,静态查找表按关键字大小的次序,有序地存放在顺序表中。 (3)折半查找的原理是:1.先确定待查记录所在的范围(前部分或后部分)2.逐步缩小(一半)范围直到找(不)到该记录为止。 (4)算法: --1.n个对象从小到大存放在有序顺序表ST中,k为给定值 --2.设low、high指向待查元素所在区间的下界、上界,即low=1, high=n --3.设mid指向待区间的中点,即mid=(low+high)/2 --4.让k与mid指向的记录比较若k=ST[mid].key,查找成功 若k 若k>ST[mid].key,则low=mid+1 [下半区间] --5.重复3,4操作,直至low>high时,查找失败。(严格大于) (5)折半查找(判定树) 判定树:描述查找过程的二叉树。 有n个结点的判定树的深度为floor(log2(n)) +1(与含有 n 个结点的完全二叉树的深度相同) 折半查找法在查找过程中进行的比较次数最多不超过floor(log2(n)) +1 题目:假设某有序表查找中有12个元素,请问该查找表查找成功时的平均查找长度为多少?(查找失败的ASL:为白块到根结点的路径长度之和/白块个数;ASL=1/2 * 成功+1/2* 失败) (6)性能分析 设有序表的长度n=2^h-1(即h=log2(n+1)),则描述折半查找的判定树是深度为h的满二叉树。 树中层次为1的结点有1个,层次为2的结点有2个,层次为h的结点有2^(h-1)个。 假设表中每个记录的查找概率相等,则查找成功时折半查找的平均查找长度:ASL(成功)=[(n+1)/n]*log2(n+1)-1 (7)特点 折半查找的效率比顺序查找高(特别是在静态查找表的长度很长时)。 折半查找只能适用于有序表,并且以顺序存储结构存储。 3.分块查找 (1)分块查找是一种索引顺序表(分块有序表)查找方法,是折半查找和顺序查找的简单结合。 (2)索引顺序表(分块有序表)将整个表分成几块,块内无序,块间有序。 (3)所谓块间有序是指后一块表中所有记录的关键字均大于前一块表中的最大关键字。 (4)分块查找(分块有序表) 主表:用数组存放待查记录,每个数据元素至少含有关键字域。 索引表:每个结点含有最大关键字域和指向本块第一个结点的指针。 (5)采用折半查找方法在索引表中找到块[第2块],用顺序查找方法在主表对 应块中找到记录[第3记录]。 (6)性能分析: 若将长度为n的表分成b块,每块含s个记录,并设表中每个记录查找概率相等。 用折半查找方法在索引表中查找索引块,ASL块间≈log2(n/s+1) 用顺序查找方法在主表对应块中查找记录,ASL块内=s/2 ASL(成功)≈log2(n/s+1) + s/2 1.动态查找表 (1)表结构本身是在查找过程中动态生成的 (2)若表中存在其关键字等于给定值key的记录,表明查找成功; (3)否则插入关键字等于key的记录。 2.二叉排序树(将判定树的结点信息从下标改为数据即为二叉排序树) (1)空树或者是具有如下特性的二叉树: --⑴.若它的左子树不空,则左子树上所有结点的值均小于根结点的值; --⑵.若它的右子树不空,则右子树上所有结点的值均大于根结点的值; --⑶.它的左、右子树也都分别是二叉排序树。 (2)二叉排序树又称二叉查找树 查找算法: 给定值与根结点比较:--1.若相等,查找成功--2.若小于,查找左子树--3.若大于,查找右子树 生成举例: 题目:画出在初始为空的二叉排序树中依次插入56,64,92,80,88,75时该树的生长全过程 (3)二叉排序树(插入) 二叉排序树是一种动态树表; 当树中不存在查找的结点时,作插入操作; 新插入的结点一定是叶子结点(只需改动一个结点的指针); 该叶子结点是查找不成功时路径上访问的最后一个结点左孩子或右孩子(新结点值小于或大于该结点值)。(最后一个!) (4)中序遍历二叉排序树,可得到一个关键字的有序序列。 (5)二叉排序树(删除) 删除二叉排序树中的一个结点后,必须保持二叉排序树的特性(左子树的所有结点值小于根结点,右子树的所有结点值大于根结点)也即保持中序遍历后,输出为有序序列。 被删除结点具有以下三种情况:1.是叶子结点(直接删除结点,并让其父结点指向该结点的指针变为空);2.只有左子树或右子树(删除结点,让其父结点指向该结点的指针指向其左子树(或右子树),即用孩子结点替代被删除结点即可);3.同时有左、右子树。(以中序遍历时的直接前驱s替代被删除结点p,然后再删除该直接前驱(只可能有左孩子)) (6)性能分析 (注意根算1!) 对于每一棵特定的二叉排序树,均可按照平均查找长度的定义来求它的 ASL 值。 显然,由值相同的 n 个关键字,构造所得的不同形态的各棵二叉排序树的平均查找长度的值不同,甚至可能差别很大。 在最坏的情况下,二叉排序树为近似线性表时(如以升序或降序输入结点时),其查找深度为n量级,即其时间复杂性为O(n) (7)特性 一个无序序列可以通过构造一棵二叉排序树而变成一个有序序列(通过中序遍历)。 插入新记录时,只需改变一个结点的指针,相当于在有序序列中插入一个记录而不需要移动其它记录。 二叉排序树既拥有类似于折半查找的特性,又采用了链表作存储结构。 但当插入记录的次序不当时(如升序或降序),则二叉排序树深度很深,增加了查找的时间。 3.平衡二叉树 (1)平衡二叉树是二叉排序(查找)树的另一种形式 (2)平衡二叉树又称AVL树(Adelsen-Velskii and Landis) (3)其特点为:树中每个结点的左、右子树深度之差的绝对值不大于1,即|hL-hR|≤1 (4)平衡因子:每个结点附加一个数字, 给出该结点左子树的高度减去右子树的高度所得的高度差,这个数字即为结点的平衡因子balance (左减右!) (5)AVL树任一结点平衡因子只能取 -1, 0, 1 (6)平衡二叉树(删除)与二叉排序树相同 如果被删结点A最多只有一个孩子,那么将结点A从树中删去,并将其双亲指向它的指针指向它的唯一的孩子,并作平衡化处理。 如果被删结点A没有孩子,则直接删除之,并作平衡化处理。 如果被删结点A有两个子女,则用该结点的直接前驱S替代被删结点,然后对直接前驱S作删除处理(S只有一个孩子或没有孩子)。 4.AVL平衡化旋转 (1)如果在一棵平衡的二叉查找树中插入一个新结点,造成了不平衡。此时必须调整树的结构,使之平衡化。 (2)平衡化旋转(处理)有两类: --1.单向旋转 (单向右旋和单向左旋) --2.双向旋转 (先左后右旋转和先右后左旋转) (3)每插入一个新结点时, AVL树中相关结点的平衡状态会发生改变。 --1.在插入一个新结点后,需要从插入位置沿通向根的路径回溯,检查各结点的平衡因子。 --2.如果在某一结点发现高度不平衡,停止回溯。(出现2或者-2) --3.从发生不平衡的结点起,沿刚才回溯的路径取直接下两层的结点。(做旋转操作) 题目:画出在初始为空的AVL树中依次插入64,5,13,21,19,80,75,37,56时该树的生长过程,并在有旋转时说出旋转的类型。 1.哈希表(散列表) (1)哈希(Hash)表又称散列表散列表,是一种直接计算记录存放地址的方法,它在关键码与存储位置之间直接建立了映象。 (2)哈希函数是从关键字空间到存储地址空间的一种映象。 (3)哈希函数在记录的关键字与记录的存储地址之间建立起一种对应关系。可写成:addr(ai)= H(keyi),H(·)为哈希函数k,eyi是表中元素ai关键字,addr(ai)是存储地址。 2.哈希表(查找) (1)哈希查找也叫散列查找,是利用哈希函数进行查找的过程。 --1.首先利用哈希函数及记录的关键字计算出记录的存储地址.。 --2.然后直接到指定地址进行查找 --3.不需要经过比较,一次存取就能得到所查元素 3.哈希表(冲突) (1)不同的记录,其关键字通过哈希函数的计算,可能得到相同的地址。把不同的记录映射到同一个散列地址上,这种现象称为冲突。 4.哈希表(定义) (1)根据设定的哈希函数 H(key) 和所选中的处理冲突的方法 (2)将一组关键字映象到一个有限的、地址连续的地址集 (区间) 上 (3)并以关键字在地址集中的“象”作为相应记录在表中的存储位置 (4)如此构造所得的查找表称之为“哈希表” 5.哈希函数(均匀性) (1)哈希函数实现的一般是从一个大的集合(部分元素,空间位置上一般不连续)到一个小的集合(空间连续)的映射 (2)一个好的哈希函数,对于记录中的任何关键字,将其映射到地址集合中任何一个地址的概率应该是相等的 (3)即关键字经过哈希函数得到一个“随机的地址“ 6.哈希函数(要求) (1)哈希函数应是简单的,能在较短的时间内计算出结果。 (2)哈希函数的定义域尽可能包括需要存储的全部关键字,如果散列表允许有 m 个地址时,其值域必须在 0 到 m-1 之间。 (3)散列函数计算出来的地址应能均匀分布在整个地址空间中。 7.哈希函数(直接定址法) (1)直接定址法中,哈希函数取关键字的线性函数: H(key) = a x key + b(其中a和b为常数) (2)直接定址法仅适合于地址集合的大小与关键字集合的大小相等的情况 (3)当a=1时,H(key)=key,即用关键字作地址 (4)在实际应用中能使用这种哈希函数的情况很少 8.哈希函数(数字分析法) (1)假设关键字集合中的每个关键字都是由 s 位数字组成 (u1, u2, …, us)。 (2)分析关键字集中的全体 (3)从中提取分布均匀的若干位或它们的组合作为地址 (4)数字分析法仅适用于事先明确知道表中所有关键码每一位数值的分布情况 (5)数字分析法完全依赖于关键码集合 (6)如果换一个关键码集合,选择哪几位要重新决定 9.哈希函数(平方取中法) (1)以关键字的平方值的中间几位作为存储地址。 (2)求“关键字的平方值” 的目的是“扩大差别” (3)同时平方值的中间各位又能受到整个关键字中各位的影响。 (4)此方法在词典处理中使用十分广泛。它先计算构成关键码的标识符的内码的平方, 然后按照散列表的大小取中间的若干位作为散列地址。 (5)平方取中法是较常用的构造哈希函数的方法 (6)适合于关键字中的每一位都有某些数字重复出现且频度很高的情况 (7)中间所取的位数,由哈希表长决定 10.哈希函数(折叠法) (1)将关键字分割成位数相同的若干部分(最后部分的倍数可以不同),然后取它们的叠加和(舍去进位)为哈希地址。 (2)移位叠加:将分割后的几部分低位对齐相加。 (3)间界叠加:从一端沿分割界来回折送,然后对齐相加。 (4)折叠法适合于关键字的数字位数特别多,而且每一位上数字分布大致均匀的情况。 11.哈希函数(除留余数法) (1)取关键字被某个不大于哈希表长m的数p除后所得余数为哈希地址: H(key) = key MOD p ( p≤m ) m为表长 p为不大于m的素数或是不含20以下的质因子 (2)除留余数法是一种最简单、最常用的构造哈希函数的方法 (3)不仅可以对关键字直接取模(MOD),也可在折叠、平方取中等运算之后取模 12.处理冲突的方法 “处理冲突” 的实际含义是:为产生冲突的地址寻找下一个哈希地址。 处理冲突的方法主要有三种:1.开放定址法2.再哈希法3.链地址法 13.处理冲突的方法(开放定址法) (1)为产生冲突的地址 H(key) 求得一个地址序列: H0, H1, H2, …, Hs,1≤s≤m-1 (2)Hi = [H(key)+di] MOD m i=1,2,…,s H(key)为哈希函数 m为哈希表长 (3)开放定址法-线性探测: 当di取1,2,3,…,m-1时,称这种开放定址法为线性探测再散列 (4)开放定址法-二次探测: 当di取= 1^2, -1^2,2^2, -2^2,3^2,…时,称这种开放定址法为二次探测再散列 (5)特性 当di取= 1^2, -1^2,2^2, -2^2,3^2,…时,称这种开放定址法为二次探测再散列; 二次探测再散列:m=4j+3的素数时总能找到。 缺点:易产生“二次聚集”,即在处理同义词的冲突过程中,又添加了非同义词的冲突,对查找不利 14.处理冲突的方法(再哈希法) (1)构造若干个哈希函数,当发生冲突时,计算下一个哈希地址,直到冲突不再发生,即:Hi = Rhi(key) i=1,2,……k Rhi—不同的哈希函数 (2)特点:不易产生聚集,但增加计算时间 15.处理冲突的方法(链地址法) (1)将所有哈希地址相同的记录都链接在同一链表中 (2)表头插入和表后插入 题目:已知一组关键字(19,14,23,1,68,20,84,27,55,11,10,79)哈希函数为: H(key)=key MOD 13,用链地址法处理冲突[表头插入] (注意左侧数组表示和空符号^) 16.哈希表的实现 17.哈希表的性能分析 (1)虽然哈希表在关键字与记录的存储位置之间建立了直接映象,但由于“冲突”的产生,使得哈希表的查找过程仍然是一个给定值和关键字进行比较的过程 (2)因此,仍需以平均查找长度(ASL)作为衡量哈希表的查找效率的量度 (3)决定哈希表查找的ASL的因素: --1.选用的哈希函数 --2.选用的处理冲突的方法 --3.哈希表的装填因子:哈希表的装填因子是哈希表中填入的记录数与哈希表的长度的比值,即:α = 哈希表中填入的记录数 / 哈希表的长度。装填因子α标志哈希表的装满程序。 注意:散列表的平均查找长度依赖于装填因子,不直接依赖于n或m (4)装填因子α越小,发生冲突的可能性就越小;装填因子α越大,发生冲突的可能性就越大。 (5)平均查找长度ASL: 线性探测再散列的哈希表查找成功时:ASL ≈ (½)(1 + 1/(1-α)) ASL(成功)=(1/2)*(1+1/(1-记录数/哈希表长度)) 二次探测再散列的哈希表查找成功时:ASL ≈ -(1/α)ln(1-α) ASL(成功)=-(1/(记录数/哈希表长度))ln(1-记录数/哈希表长度) 链地址法处理冲突的哈希表查找成功时:ASL ≈ (1 + α/2) ASL(成功)=(1+(记录数/哈希表长度)/2) 1.B-树是一种特殊的多路平衡查找树 2.R.Bayer和E.Maccreight于1970年提出 3.B-树是一种在外存文件系统中常用的动态索引 4.技术磁盘中文件的读写以“盘块”为单位进行 5.将关键字索引信息,放在盘块中,可以加快数据的查找速度 6.结点结构: (1)Ki是关键字,且Ki (2)Ai是指向子树根结点的指针 (3)Ai-1所指子树中所有结点的关键字均小于Ki (4)Ai 所指子树中所有结点的关键字均大于Ki (5)对于m阶B-树,ceil(m/2) -1≤n≤m-1 (分支数比关键字数目多一) 7.m阶B-树定义: (1)树中每个结点至多有m棵子树(m-1个关键字) (2)若根结点不是叶子结点,则至少有两棵子树 (3)除根之外的所有非终端结点至少有 ceil(m/2) 棵子树 (4)所有叶子结点,都出现在同一层次上,且不带信息(可以看作是查找失败的结点,指向这些结点的指针为空指针) 题目:3阶B-树(11个结点) (1)关键字比分支数少一(B-),m=3(3阶) (2)关键字数目为n,ceil(3/2)-1<=n<=3-1即1<=n<=2 ceil(m/2)-1<=n<=m-1 (3)如图深度为3,结点数最少(所有都是关键字n=1,分支为2):2^3-1=7;结点数最多(所有都是关键字n=2,分支为3):1+3+3^2=13 结点数最少:2^h-1;结点数最多:1+m+m^2+..+m^(h-1) 1.排序 (1)排序:将一个数据元素(或记录)的任意序列,重新排列成一个按关键字有序的序列 (2)内部排序:在排序期间数据对象全部存放在内存的排序; (3)外部排序:在排序期间全部对象个数太多,不能同时存放在内存,必须根据排序过程的要求,不断在内、外存之间移动的排序。 2.排序基本操作: (1)比较:比较两个关键字的大小 (2)移动:将记录从一个位置移动至另一个位置 3.排序时间复杂度 排序的时间复杂度可用算法执行中的记录关键字比较次数与记录移动次数来衡量。 4.排序方法的稳定性 (1)如果在记录序列中有两个记录r[i]和r[j], 它们的关键字 key[i] == key[j] , 且在排序之前, 记录r[i]排在r[j]前面。 (2)如果在排序之后, 记录r[i]仍在记录r[j]的前面, 则称这个排序方法是稳定的, 否则称这个排序方法是不稳定的。 1.直接插入排序 (1)当插入第i(i≥1)个对象时, 前面的r[0], r[1], …, r[i-1]已经排好序。 (2)用r[i]的关键字与r[i-1], r[i-2], …的关键字顺序进行比较(和顺序查找类似),如果小于,则将r[x]向后移动(插入位置后的记录向后顺移) (3)找到插入位置即将r[i]插入 (4)每步将一个待排序的对象, 按其关键字大小, 插入到前面已经排好序的有序表的适当位置上, 直到对象全部插入为止。 (5)关键字比较次数和记录移动次数与记录关键字的初始排列有关。 (6)最好情况下, 排序前记录已按关键字从小到大有序, 每趟只需与前面有序记录序列的最后一个记录比较1次, 移动2次记录, 总的关键字比较次数为 n-1, 记录移动次数为 2(n-1)。 (7)最坏情况下, (i从1开始,下标从0开始)第i趟时第i个记录必须与前面i个记录都做关键字比较, 并且每做1次比较就要做1次数据移动。则总关键字比较次数KCN和记录移动次数RMN分别为 (8)在平均情况下的关键字比较次数和记录移动次数约为 n^2/4。 (9)直接插入排序的时间复杂度为O(n^2)。 (10)直接插入排序是一种稳定的排序方法。 (11)直接插入排序最大的优点是简单,在记录数较少时,是比较好的办法。 2.折半插入排序 (1)折半插入排序在查找记录插入位置时,采用折半查找算法 (2)折半查找比顺序查找快, 所以折半插入排序在查找上性能比直接插入排序好 (3)但需要移动的记录数目与直接插入排序相同(为O(n2)) (4)折半插入排序的时间复杂度为O(n^2)。 (5)折半插入排序是一种稳定的排序方法 3.希尔排序 (1)从直接插入排序可以看出,当待排序列为正序时,时间复杂度为O(n) (2)若待排序列基本有序时,插入排序效率会提高希尔排序方法是先将待排序列分成若干子序列分别进行插入排序,待整个序列基本有序时,再对全体记录进行一次直接插入排序 (3)希尔排序又称为缩小增量排序。 (4)算法: 首先取一个整数 gap < n(待排序记录数) 作为间隔, 将全部记录分为 gap 个子序列, 所有距离为 gap 的记录放在同一个子序列中。(gap为组数!) 在每一个子序列中分别施行直接插入排序。然后缩小间隔 gap, 例如取 gap = gap/2。 重复上述的子序列划分和排序工作,直到最后取gap = 1, 将所有记录放在同一个序列中排序为止。 (5)算法分析: 开始时 gap 的值较大, 子序列中的记录较少, 排序速度较快。 随着排序进展, gap 值逐渐变小, 子序列中记录个数逐渐变多,由于前面大多数记录已基本有序, 所以排序速度仍然很快。 Gap的取法有多种。 shell 提出取 gap = n/2,gap = gap/2,直到gap = 1。 对特定的待排序记录序列,可以准确地估算关键字的比较次数和记录移动次数。 希尔排序所需的比较次数和移动次数约为n^1.3 当n趋于无穷时可减少到n x(log2 n)^2 希尔排序的时间复杂度约为O(n x(log2 n)^2) 希尔排序是一种不稳定的排序方法 1.冒泡排序 (1)设待排序记录序列中的记录个数为n(下标从1到n)。 (2)一般地,第i趟起泡排序从1到n-i+1依次比较相邻两个记录的关键字,如果发生逆序,则交换之 i=1时,为第一趟排序,关键字最大的记录将被交换到最后一个位置 i=2时,为第二趟排序,关键字次大的记录将被交换到最后第二个位置 关键字小的记录不断上浮(起泡),关键字大的记录不断下沉(每趟排序最大的一直沉到底) (3)其结果是这n-i+1个记录中,关键字最大的记录被交换到第n-i+1的位置上,最多作n-1趟。 (4)最好情况:在记录的初始排列已经按关键字从小到大排好序时,此算法只执行一趟起泡,做n-1次关键字比较,不移动记录。 (5)最好情况:在记录的初始排列已经按关键字从小到大排好序时,此算法只执行一趟起泡,做n-1次关键字比较,不移动记录 (6)起泡排序的时间复杂度为O(n^2) (7)起泡排序是一种稳定的排序方法 (8)每一趟可以确定一个数的位置(从后往前) 2.快速排序 (1)任取待排序记录序列中的某个记录(例如取第一个记录)作为基准(枢),按照该记录的关键字大小,将整个记录序列划分为左右两个子序列 (2) 左侧子序列中所有记录的关键字都小于或等于基准记录的关键字 (3)右侧子序列中所有记录的关键字都大于基准记录的关键字 (4)基准记录则排在这两个子序列中间(这也是该记录最终应安放的位置)。 (5)然后分别对这两个子序列重复施行上述方法,直到所有的记录都排在相应位置上为止。 (6)基准记录也称为枢轴(或支点)记录。 (7)算法: 取序列第一个记录为枢轴记录,其关键字为Pivotkey。 指针low指向序列第一个记录位置。 指针high指向序列最后一个记录位置。 一趟排序(某个子序列)过程: --1.从high指向的记录开始,向前找到第一个关键字的值小于Pivotkey的记录,将其放到low指向的位置,low+1 --2.从low指向的记录开始,向后找到第一个关键字的值大于Pivotkey的记录,将其放到high指向的位置,high-1 --3.重复1,2,直到low=high,将枢轴记录放在low(high)指向的位置 对枢轴记录前后两个子序列执行相同的操作,直到每个子序列都只有一个记录为止。 (8)性能分析: 快速排序是一个递归过程。 利用序列第一个记录作为基准,将整个序列划分为左右两个子序列。只要是关键字小于基准记录关键字的记录都移到序列左侧。 如果每次划分对一个记录定位后, 该记录的左侧子序列与右侧子序列的长度相同, 则下一步将是对两个长度减半的子序列进行排序, 这是最理想的情况。 可以证明, 快速排序的平均计算时间也是O(nlog2 n)。 实验结果表明: 就平均计算时间而言, 快速排序是所有内排序方法中最好的一个。 但快速排序是一种不稳定的排序方法。 (9)在最坏情况下, 即待排序记录序列已经按其关键字从小到大排好序, 其递归树成为单支树, 时间复杂度达O(n2) 每次划分只得到一个比上一次少一个记录的子序列。 必须经过n-1 趟才能把所有记录定位, 而且第 i 趟需要经过 n-i 次关键字比较才能找到第 i 个记录的安放位置,总的关键字比较次数将达到: (10)改进:枢轴记录取low、high、(low+high)/2三者指向记录关键字居中的记录。 1.简单选择排序 (1)每一趟(例如第i趟,i=0,1,…,n-2)在后面n-i个待排序记录中选出关键字最小的记录,与第i个记录交换。 (2)每趟可确定一个数(从前往后) EQ 就是 EQUAL等于 NE 就是 NOT EQUAL不等于 GT 就是 GREATER THAN大于 LT 就是 LESS THAN小于 GE 就是 GREATER THAN OR EQUAL 大于等于 LE 就是 LESS THAN OR EQUAL 小于等于 (2)性能分析: 直接选择排序的关键字比较次数 KCN 与记录的初始排列无关。 设整个待排序记录序列有n个记录,则第i趟选择具有最小关键字记录所需的比较次数总是 n-i-1次。总的关键字比较次数为: 记录的移动次数与记录序列的初始排列有关。 当这组记录的初始状态是按其关键字从小到大有序的时候,记录的移动次数RMN=0,达到最少。 最坏情况是每一趟都要进行交换,总的记录移动次数为 RMN = 3(n-1)。 直接选择排序是一种不稳定的排序方法。 2.堆排序 (1)设有一个关键字集合,按完全二叉树的顺序存储方式存放在一个一维数组中。对它们从根开始,自顶向下,同一层自左向右从 1 开始连续编号。若满足 Ki >=K2i && Ki >=K2i+1则称该关键字集合构成一个堆(最大堆) 注意:只对根有要求,对左右节点大小关系顺序无要求 (2)最大堆(筛选): 输出根结点 用最后结点代替根结点值(最后的!) 比较根结点与两个子结点的值,如果小于其中一个子结点,则选择大的子结点与根结点交换 继续将交换的结点与其子结点比较 直到叶子结点或者根节点值大于两个子结点 (2)创建初始堆: 根据给定的序列,从1至n按顺序创建一个完全二叉树 由最后一个非终端结点(第n/2个结点)开始至第1个结点,逐步做筛选(第n/2个!) (3)性能排序 对于长度为n的序列,其对应的完全二叉树的深度为k(2^(k-1) <= n <= 2^k) 对深度为k的堆,筛选算法中进行的关键字比较次数至多为2(k-1)次 堆排序时间主要耗费在建初始堆和调整建新堆(筛选)上 建初始堆最多做n/2次筛选 对长度为n的序列,排序最多需要做n-1次调整建新堆(筛选) 因此共需要O(nxk)量级的时间k = log2n 堆排序时间复杂度为O(nlog2n) 堆排序是一个不稳定的排序方法 记录数较多时,推荐堆排序 1.归并(有序!) (1)归并是将两个或两个以上的有序表合并成一个新的有序表。 (2)两路归并 假设待归并两个有序表长度分别为m和n,则两路归并后,新的有序表长度为m+n 两路归并操作至多只需要m+n次移位和m+n次比较 因此两路归并的时间复杂度为O(m+n) 2.2路-归并排序 (1)将n个记录看成是n个有序序列 (2)将前后相邻的两个有序序列归并为一个有序序列(两路归并)(前后相邻!) (3)重复做两路归并操作,直到只有一个有序序列为止 (4)性能分析: 如果待排序的记录为n个,则需要做log2n趟两路归并排序 每趟两路归并排序的时间复杂度为O(n) 因此2路-归并排序的时间复杂度为O(nlog2n) 归并排序是一种稳定的排序方法 1.多关键字的排序(最低位优先法LSD) (1)从最低位关键字kd起进行排序, (2)然后再对高一位的关键字排序,…… (3)依次重复,直至对最高位关键字k1排序后,便成为一个有序序列 2.链式基数排序 (1)基数排序:借助“分配”和“收集”对单逻辑关键字进行排序的一种方法 (2)链式基数排序方法:用链表作存储结构的基数排序 (3)设置10个队列,f[i]和e[i]分别为第i个队列的头指针和尾指针 (4)第i趟分配:根据第i位关键字的值,改变记录的指针,将链表中记录分配至10个链队列中,每个队列中记录关键字的第i位关键字相同 (5)第i趟收集:改变所有非空队列的队尾记录的指针域,令其指向下一个非空队列的队头记录,重新将10个队列链成一个链表 (6)从最低位至最高位,逐位执行上述两步操作,最后得到一个有序序列 (7)性能分析 若每个关键字有 d 位,关键字的基数为radix 。 需要重复执行d 趟“分配”与“收集”。 每趟对 n 个对象进行“分配”,对radix个队列进行“收集”。 总时间复杂度为O(d(n+radix))。 若基数radix相同, 对于对象个数较多而关键字位数较少的情况, 使用链式基数排序较好。 基数排序需要增加n+2radix个附加链接指针。 基数排序是稳定的排序方法。 注意:在插入和选择排序中,若初始数据基本正序,则选用插入排序。 1.时间性能 (1) 时间复杂度为 O(nlogn):快速排序、堆排序和归并排序 时间复杂度为 O(n^2):直接插入排序、冒泡排序、简单选择排序 时间复杂度为 O(n): 基数排序 (2)当待排记录序列按关键字顺序有序时 直接插入排序和起泡排序能达到O(n)的时间复杂度; 快速排序的时间性能蜕化为O(n^2) 。 (3)简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变。 2.空间性能 (1)指的是排序过程中所需的辅助空间大小 (2)所有的简单排序方法(包括:直接插入、起泡和简单选择) 和堆排序的空间复杂度为O(1) (3)快速排序为O(logn),为递归程序执行过程中,栈所需的辅助空间; (4)归并排序所需辅助空间最多,其空间复杂度为 O(n); (5)链式基数排序需附设队列首尾指针,则空间复杂度为 O(rd)。 3.排序方法的稳定性能 口诀:考试情绪不稳定,就快些选堆朋友吧! (不稳定:快->快速排序,些->希尔排序,选->直接选择排序,堆->堆排序) (1)稳定的排序方法指的是,对于两个关键字相等的记录,它们在序列中的相对位置,在排序之前和经过排序之后,没有改变。 (2) 当对多关键字的记录序列进行LSD方法排序时,必须采用稳定的排序方法。 (3)对于不稳定的排序方法,只要能举出一个实例说明即可。 (4)快速排序、堆排序和希尔排序是不稳定的排序方法。 (5)所有时间复杂度为O(n^2) 的简单排序算法都是稳定的(直接选择排序算法除外)。 (6)归并排序和基数排序是稳定的。 所有排序整理: (创作不易,谢谢亲们点赞、关注、收藏!(*^▽^*) )i=1;
while(i<=n)i=i*2;
//令执行x次,2^x=n,x=log2(n),即时间复杂度为O(log2(n))
//递归算法,时间复杂度是O(n)
int rec(int n)
{
if (n==1) return 1;
else return (n*rec(n-1));
}
void bubble-sort(int a[],int n)
{
for(i=n-1,change=TURE;i>1 && change;--i)
{
change=false;
for(j=0;j
十三、空间复杂度
第二章:线性表
一、线性数据结构的特点
二、线性表
三、顺序表

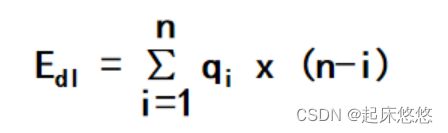
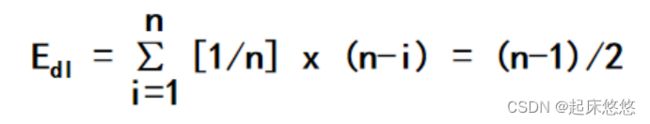
四、链表
LNode *head;//头指针
head = new LNode;//生成头结点 head->[ |^]
//head->[ |-]->[a|-]->[b|-]->....
五、一元多项式
六、顺序表与链表的比较
第三章:栈和队列
一、栈
} 否则 {
如果栈顶位置的四周均不可通,则删除栈顶位置(Pop)
并重新测试新的栈顶位置
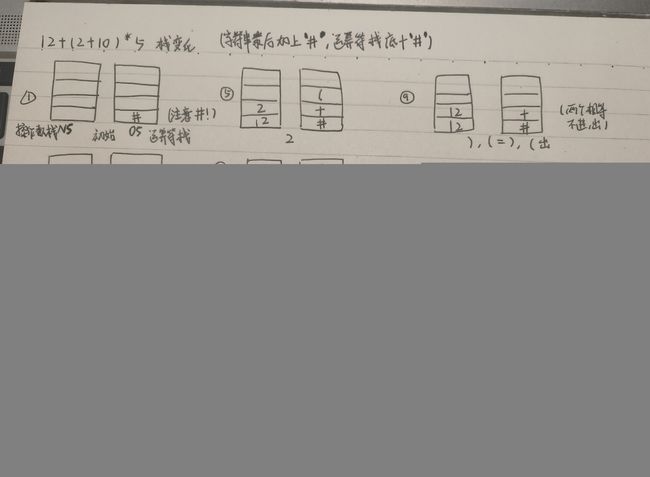

二、队列
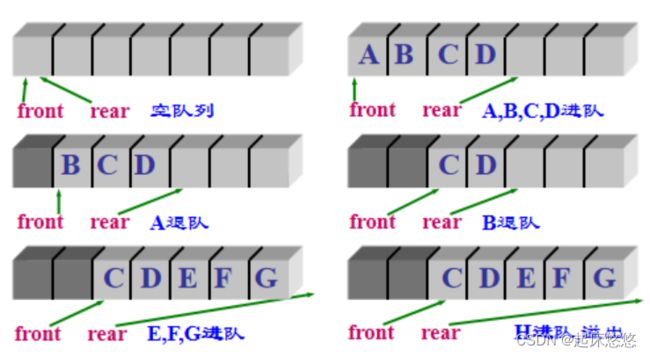


第四章:串
一、字符串
二、串的表示和实现
三、串的匹配算法




void getnext(string p)
{
int j,k;
j=0,k=-1;
next[0]=-1;//!
while(j
第五章:数组和广义表
一、数组的定义

二、数组的表示

三、矩阵的压缩存储


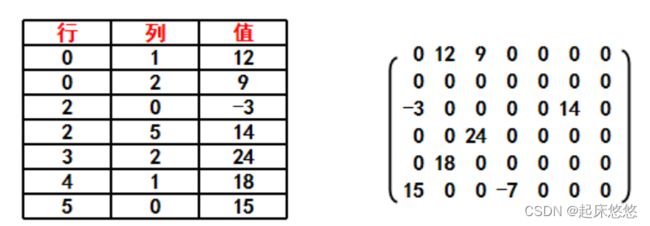

四、广义表

第六章:树与二叉树
一、树的概念与基本术语
二、二叉树
三、满二叉树
四、完全二叉树
五、二叉树的顺序存储结构
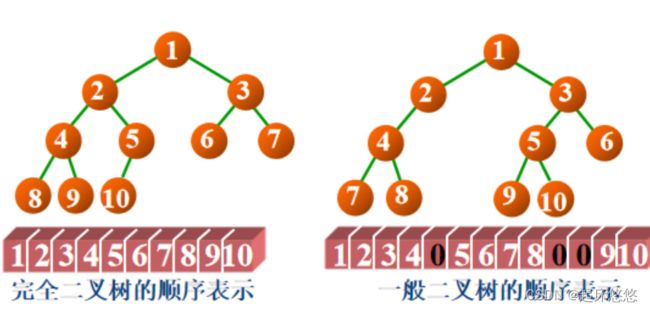
六、二叉树的链式存储结构


七、遍历二叉树

八、线索二叉树

十、树与森林




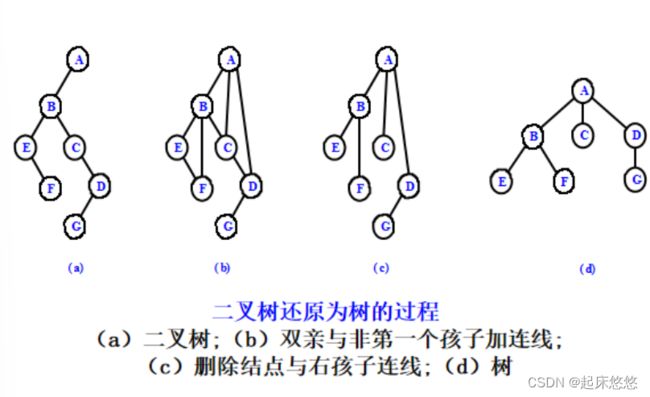




十一、赫夫曼树及其应用





第七章:图
一、图的定义与术语
二、图的存储结构



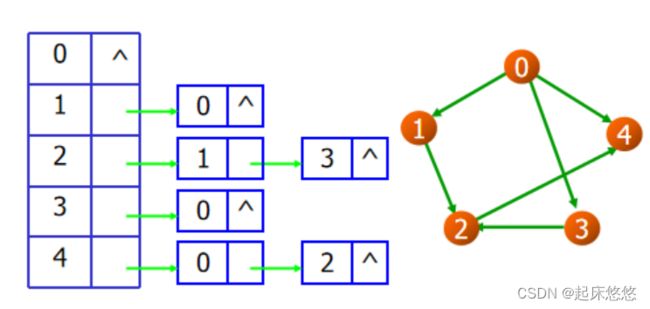




三、图的遍历

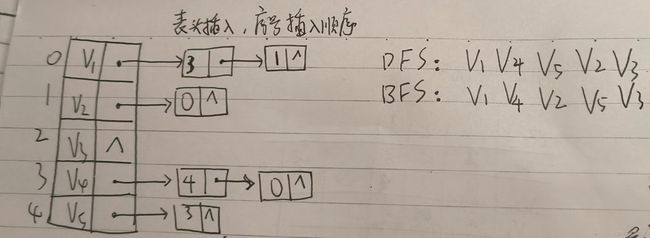
四、图的连通性问题

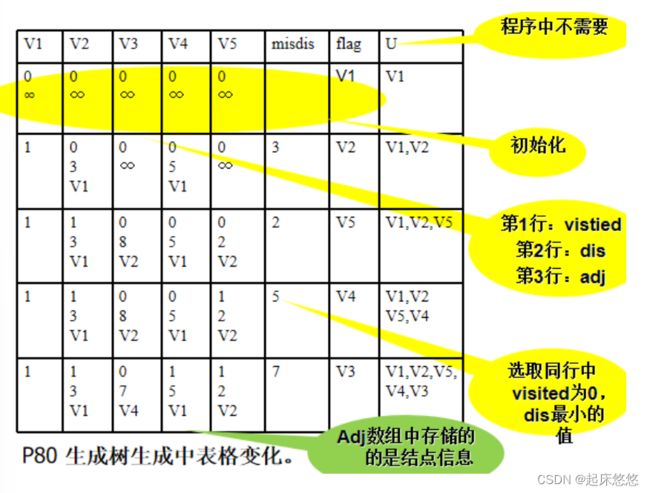


五、最短路径



六、有向无环图及其应用

工序代号
A
B
C
D
E
F
G
H
所需时间
3
2
2
3
4
3
2
1
先驱工序
-
-
A
A
B
B
C,E
D



第九章:查找
一、查找的概念

二、静态查找表(顺序、折半、分块)

三、动态查找表




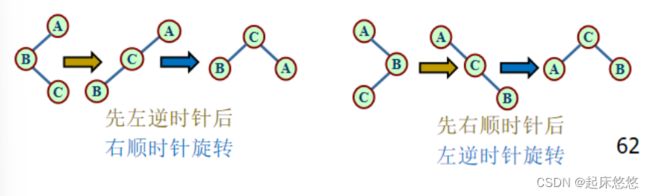

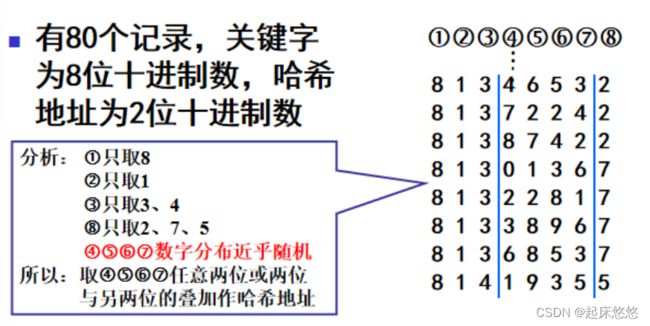
四、哈希表




五、B-树[结点结构]


第十章:内部排序
一、排序
二、插入排序


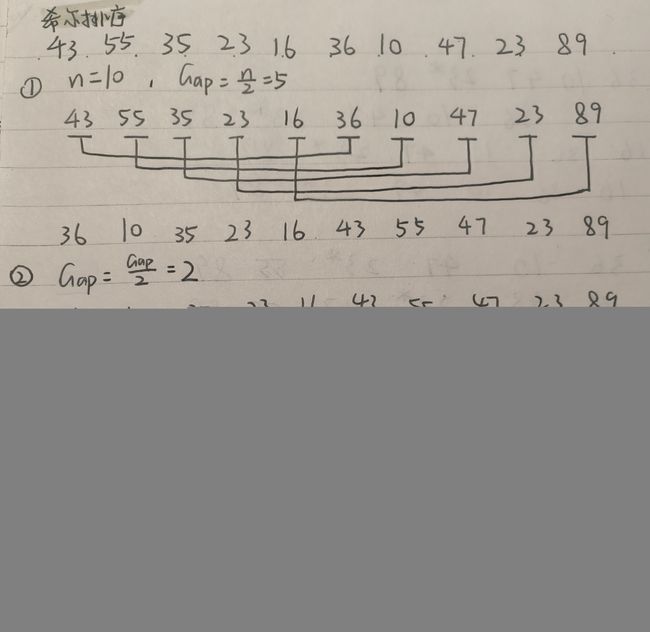
三、快速排序
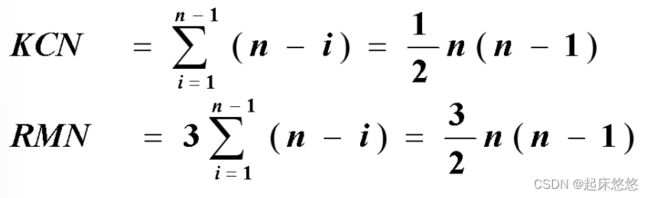


四、选择排序

算法中的几个表示关系的缩写
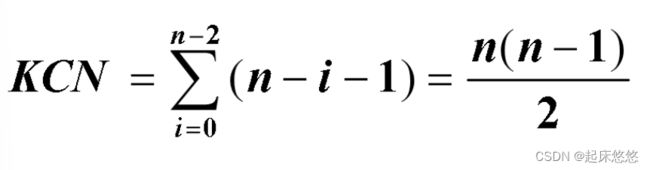

五、归并排序


六、基数排序



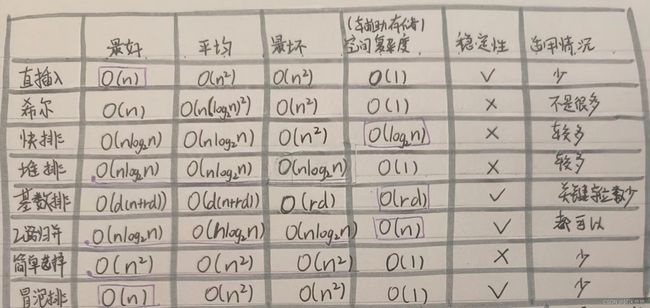
七、各种排序方法比较