Spark SQL基础
SparkSQL基本介绍
什么是Spark SQL
Spark SQL是Spark多种组件中其中一个,主要是用于处理大规模的结构化数据
什么是结构化数据: 一份数据, 每一行都有固定的列, 每一列的类型都是一致的 我们将这样的数据称为结构化的数据
例如: mysql的表数据
1 张三 20
2 李四 15
3 王五 18
4 赵六 12
Spark SQL 的优势
1- Spark SQL 既可以编写SQL语句, 也可以编写代码, 甚至可以混合使用
2- Spark SQL 可以 和 HIVE进行集成, 集成后, 可以替换掉HIVE原有MR的执行引擎, 提升效率
Spark SQL特点:
1- 融合性: 既可以使用标准SQL语言, 也可以编写代码, 同时支持混合使用
2- 统一的数据访问: 可以通过统一的API来对接不同的数据源
3- HIVE的兼容性: Spark SQL可以和HIVE进行整合, 整合后替换执行引擎为Spark, 核心: 基于HIVE的metastore来处理
4- 标准化连接: Spark SQL也是支持 JDBC/ODBC的连接方式
Spark SQL与HIVE异同
相同点:
1- 都是分布式SQL计算引擎
2- 都可以处理大规模的结构化数据
3- 都可以建立Yarn集群之上运行
不同点:
1- Spark SQL是基于内存计算, 而HIVE SQL是基于磁盘进行计算的
2- Spark SQL没有元数据管理服务(自己维护), 而HIVE SQL是有metastore的元数据管理服务的
3- Spark SQL底层执行Spark RDD程序, 而HIVE SQL底层执行是MapReduce
4- Spark SQL可以编写SQL也可以编写代码,但是HIVE SQL仅能编写SQL语句
Spark SQL的数据结构对比

说明:
pandas的DataFrame: 二维表 处理单机结构数据
Spark Core: 处理任何的数据结构 处理大规模的分布式数据
Spark SQL: 二维表 处理大规模的分布式结构数据

RDD: 存储直接就是对象, 比如在图中, 存储就是一个Person的对象, 但是里面是什么数据内容, 不太清楚
DataFrame: 将Person的中各个字段数据, 进行结构化存储, 形成一个DataFrame, 可以直接看到数据
Dataset: 将Person对象中数据都按照结构化的方式存储好, 同时保留的对象的类型, 从而知道来源于一个Person对象
由于Python不支持泛型, 所以无法使用Dataset类型, 客户端仅支持DataFrame类型
Spark SQL构建SparkSession对象
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 创建SparkSQL中的顶级对象SparkSession
# alt+回车
"""
注意事项:
1- SparkSession和builder都没有小括号
2- appName():给应用程序取名词。等同于SparkCore中的setAppName()
3- master():设置运行时集群类型。等同于SparkCore中的setMaster()
"""
spark = SparkSession.builder\
.appName('create_sparksession_demo')\
.master('local[*]')\
.getOrCreate()
# 通过SparkSQL的顶级对象获取SparkCore中的顶级对象
sc = spark.sparkContext
# 释放资源
sc.stop()
spark.stop()
DataFrame详解
DataFrame基本介绍
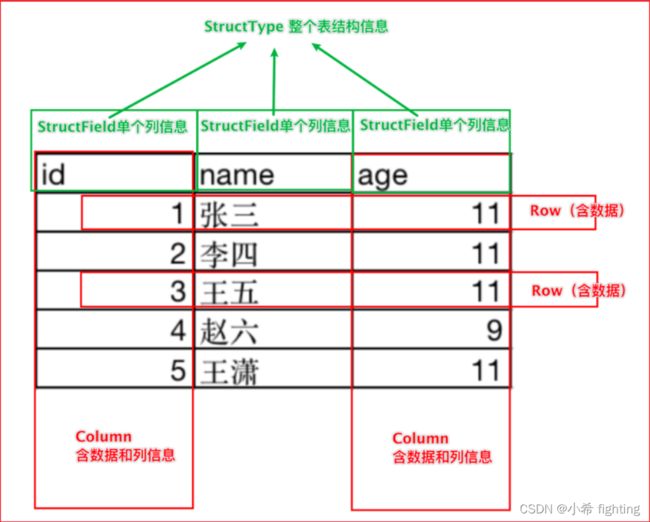
DataFrame表示的是一个二维的表。二维表,必然存在行、列等表结构描述信息
表结构描述信息(元数据Schema): StructType对象
字段: StructField对象,可以描述字段名称、字段数据类型、是否可以为空
行: Row对象
列: Column对象,包含字段名称和字段值
在一个StructType对象下,由多个StructField组成,构建成一个完整的元数据信息
如何构建表结构信息数据:

DataFrame的构建方式
通过RDD得到一个DataFrame
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
# 绑定指定的Python解释器
from pyspark.sql.types import StructType, IntegerType, StringType, StructField
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.appName('rdd_2_dataframe')\
.master('local[*]')\
.getOrCreate()
# 通过SparkSession得到SparkContext
sc = spark.sparkContext
# 2- 数据输入
# 2.1- 创建一个RDD
init_rdd = sc.parallelize(["1,李白,20","2,安其拉,18"])
# 2.2- 将RDD的数据结构转换成二维结构
new_rdd = init_rdd.map(lambda line: (
int(line.split(",")[0]),
line.split(",")[1],
int(line.split(",")[2])
)
)
# 将RDD转成DataFrame:方式一
# schema方式一
schema = StructType()\
.add('id',IntegerType(),False)\
.add('name',StringType(),False)\
.add('age',IntegerType(),False)
# schema方式二
schema = StructType([
StructField('id',IntegerType(),False),
StructField('name',StringType(),False),
StructField('age',IntegerType(),False)
])
# schema方式三
schema = "id:int,name:string,age:int"
# schema方式四
schema = ["id","name","age"]
init_df = spark.createDataFrame(
data=new_rdd,
schema=schema
)
# 将RDD转成DataFrame:方式二
"""
toDF:中的schema既可以传List,也可以传字符串形式的schema信息
"""
# init_df = new_rdd.toDF(schema=["id","name","age"])
init_df = new_rdd.toDF(schema="id:int,name:string,age:int")
# 3- 数据处理
# 4- 数据输出
init_df.show()
init_df.printSchema()
# 5- 释放资源
sc.stop()
spark.stop()
运行结果截图:

场景:RDD可以存储任意结构的数据;而DataFrame只能处理二维表数据。在使用Spark处理数据的初期,可能输入进来的数据是半结构化或者是非结构化的数据,那么我可以先通过RDD对数据进行ETL处理成结构化数据,再使用开发效率高的SparkSQL来对后续数据进行处理分析。
内部初始化数据得到DataFrame
from pyspark import SparkConf, SparkContext
import os
# 绑定指定的Python解释器
from pyspark.sql import SparkSession
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("内部初始化数据得到DataFrame。类似SparkCore中的parallelize")
# 1- 创建SparkSession顶级对象
spark = SparkSession.builder\
.appName('inner_create_dataframe')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
"""
通过createDataFrame创建DataFrame,schema数据类型可以是:DataType、字符串、List
字符串:格式要求
格式一 字段1 字段类型,字段2 字段类型
格式二(推荐) 字段1:字段类型,字段2:字段类型
List:格式要求
["字段1","字段2"]
"""
# 内部初始化数据得到DataFrame
init_df = spark.createDataFrame(
data=[(1,'张三',18),(2,'李四',30)],
schema="id:int,name:string,age:int"
)
# init_df = spark.createDataFrame(
# data=[(1, '张三', 18), (2, '李四', 30)],
# schema="id int,name string,age int"
# )
# init_df = spark.createDataFrame(
# data=[(1, '张三', 18), (2, '李四', 30)],
# schema=["id","name","age"]
# )
# init_df = spark.createDataFrame(
# data=[(1, '张三', 18), (2, '李四', 30)],
# schema=["id:int", "name:string", "age:int"]
# )
# 3- 数据处理
# 4- 数据输出
# 输出dataframe的数据内容
init_df.show()
# 输出dataframe的schema信息
init_df.printSchema()
# 5- 释放资源
spark.stop()
运行结果截图:

场景:一般用在开发和测试中。因为只能处理少量的数据
Schema总结
通过createDataFrame创建DataFrame,schema数据类型可以是:DataType、字符串、List
1: 字符串
格式一 字段1 字段类型,字段2 字段类型
格式二(推荐) 字段1:字段类型,字段2:字段类型
2: List
[“字段1”,“字段2”]
3: DataType(推荐,用的最多)
格式一 schema = StructType()
.add(‘id’,IntegerType(),False)
.add(‘name’,StringType(),True)
.add(‘age’,IntegerType(),False)
格式二 schema = StructType([
StructField(‘id’,IntegerType(),False),
StructField(‘name’,StringType(),True),
StructField(‘age’,IntegerType(),False)
])
读取外部文件
复杂API
统一API格式:
sparksession.read
.format('text|csv|json|parquet|orc|avro|jdbc|.....') # 读取外部文件的方式
.option('k','v') # 选项 可以设置相关的参数 (可选)
.schema(StructType | String) # 设置表的结构信息
.load('加载数据路径') # 读取外部文件的路径, 支持 HDFS 也支持本地
简写API
格式:
spark.read.读取方式()
例如:
df = spark.read.csv(
path='file:///export/data/spark_sql/data/stu.txt',
header=True,
sep=' ',
inferSchema=True,
encoding='utf-8',
)
Text方式读取
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("text方式读取文件")
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.appName('text_demo')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
"""
load:支持读取HDFS文件系统和本地文件系统
HDFS文件系统:hdfs://node1:8020/文件路径
本地文件系统:file:///文件路径
text方式读取文件总结:
1- 不管文件中内容是什么样的,text会将所有内容全部放到一个列中处理
2- 默认生成的列名叫value,数据类型string
3- 我们只能够在schema中修改字段value的名称,其他任何内容不能修改
"""
init_df = spark.read\
.format('text')\
.schema("my_field string")\
.load('file:///export/data/stu.txt')
# 3- 数据处理
# 4- 数据输出
init_df.show()
init_df.printSchema()
# 5- 释放资源
spark.stop()
运行结果截图:
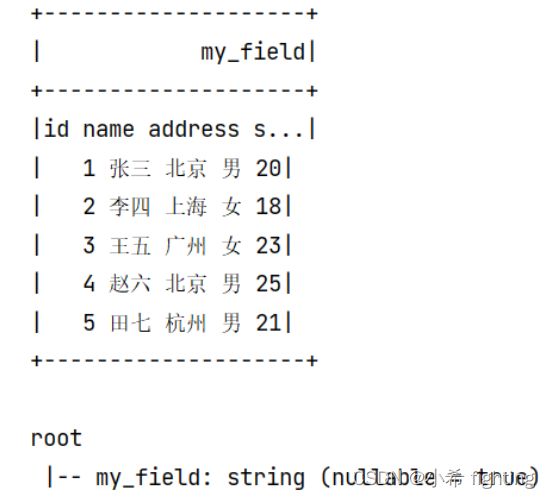
text方式读取文件总结:
1- 不管文件中内容是什么样的,text会将所有内容全部放到一个列中处理
2- 默认生成的列名叫value,数据类型string
3- 我们只能够在schema中修改字段value的名称,其他任何内容不能修改
CSV方式读取
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
print("csv方式读取文件")
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.appName('csv_demo')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
"""
csv格式读取外部文件总结:
1- 复杂API和简写API都必须掌握
2- 相关参数作用说明:
2.1- path:指定读取的文件路径。支持HDFS和本地文件路径
2.2- schema:手动指定元数据信息
2.3- sep:指定字段间的分隔符
2.4- encoding:指定文件的编码方式
2.5- header:指定文件中的第一行是否是字段名称
2.6- inferSchema:根据数据内容自动推断数据类型。但是,推断结果可能不精确
"""
# 复杂API写法
init_df = spark.read\
.format('csv')\
.schema("id int,name string,address string,sex string,age int")\
.option("sep"," ")\
.option("encoding","UTF-8")\
.option("header","True")\
.load('file:///export/data/stu.txt')
# 简写API写法
# init_df = spark.read.csv(
# path='file:///export/data/gz16_pyspark/02_spark_sql/data/stu.txt',
# schema="id int,name string,address string,sex string,age int",
# sep=' ',
# encoding='UTF-8',
# header="True"
# )
# init_df = spark.read.csv(
# path='file:///export/data/stu.txt',
# sep=' ',
# encoding='UTF-8',
# header="True",
# inferSchema=True
# )
# 3- 数据处理
# 4- 数据输出
init_df.show()
init_df.printSchema()
# 5- 释放资源
spark.stop()
csv格式读取外部文件总结:
1- 复杂API和简写API都必须掌握
2- 相关参数作用说明:
2.1- path:指定读取的文件路径。支持HDFS和本地文件路径
2.2- schema:手动指定元数据信息
2.3- sep:指定字段间的分隔符
2.4- encoding:指定文件的编码方式
2.5- header:指定文件中的第一行是否是字段名称
2.6- inferSchema:根据数据内容自动推断数据类型。但是,推断结果可能不精确
JSON方式读取
json的数据内容:
{'id': 1,'name': '张三','age': 20}
{'id': 2,'name': '李四','age': 23,'address': '北京'}
{'id': 3,'name': '王五','age': 25}
{'id': 4,'name': '赵六','age': 29}
代码实现
from pyspark import SparkConf, SparkContext
import os
from pyspark.sql import SparkSession
# 绑定指定的Python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# 1- 创建SparkSession对象
spark = SparkSession.builder\
.appName('json_demo')\
.master('local[*]')\
.getOrCreate()
# 2- 数据输入
"""
json读取数据总结:
1- 需要手动指定schema信息。如果手动指定的时候,字段名称与json中的key名称不一致,会解析不成功,以null值填充
2- csv/json中schema的结构,如果是字符串类型,那么字段名称和字段数据类型间,只能以空格分隔
"""
# init_df = spark.read.json(
# path='file:///export/data.txt',
# schema="id2 int,name string,age int,address string",
# encoding='UTF-8'
# )
# init_df = spark.read.json(
# path='file:///export/data.txt',
# schema="id:int,name:string,age:int,address:string",
# encoding='UTF-8'
# )
init_df = spark.read.json(
path='file:///export/data.txt',
schema="id int,name string,age int,address string",
encoding='UTF-8'
)
# 3- 数据输出
init_df.show()
init_df.printSchema()
# 4- 释放资源
spark.stop()
运行结果截图:

json读取数据总结:
1- 需要手动指定schema信息。如果手动指定的时候,字段名称与json中的key名称不一致,会解析不成功,以null值填充
2- csv/json中schema的结构,如果是字符串类型,那么字段名称和字段数据类型间,只能以空格分隔
DataFrame的相关API
操作DataFrame一般有二种操作方案:一种为【DSL方式】,另一种为【SQL方式】
SQL方式: 通过编写SQL语句完成统计分析操作
DSL方式: 特定领域语言,使用DataFrame特有的API完成计算操作,也就是代码形式
从使用角度来说: SQL可能更加的方便一些,当适应了DSL写法后,你会发现DSL要比SQL更好用
从Spark角度来说: 更推荐使用DSL方案,此种方案更加利于Spark底层的优化处理
SQL相关的API
- 创建一个视图/表
df.createTempView('视图名称'): 创建一个临时的视图(表名)
df.createOrReplaceTempView('视图名称'): 创建一个临时的视图(表名),如果视图存在,直接替换
临时视图,仅能在当前这个Spark Session的会话中使用
df.createGlobalTempView('视图名称'): 创建一个全局视图,运行在一个Spark应用中多个spark会话中都可以使用。在使用的时候必须通过 global_temp.视图名称 方式才可以加载到。较少使用
- 执行SQL语句
spark.sql('书写SQL')
DSL相关的API
- show():用于展示DF中数据, 默认仅展示前20行
- 参数1:设置默认展示多少行 默认为20
- 参数2:是否为阶段列, 默认仅展示前20个字符数据, 如果过长, 不展示(一般不设置)
- printSchema():用于打印当前这个DF的表结构信息
- select():类似于SQL中select, SQL中select后面可以写什么, 这样同样也一样
- filter()和 where():用于对数据进行过滤操作, 一般在spark SQL中主要使用where
- groupBy():用于执行分组操作
- orderBy():用于执行排序操作
DSL主要支持以下几种传递的方式: str | Column对象 | 列表
str格式: '字段'
Column对象:
DataFrame含有的字段 df['字段']
执行过程新产生: F.col('字段')
列表:
['字段1','字段2'...]
[df['字段1'],df['字段2']]




为了能够支持在编写Spark SQL的DSL时候,在DSL中使用SQL函数,专门提供一个SQL的函数库。直接加载使用即可
导入这个函数库: import pyspark.sql.functions as F
通过F调用对应的函数即可。SparkSQL中所支持的函数,都可以通过以下地址查询到:
https://spark.apache.org/docs/3.1.2/api/sql/index.html