从 RAG 到 Self-RAG —— LLM 的知识增强
作者:紫气东来 (上海交大 工学硕士)
一、 RAG 及其必要性
1.1 初识 RAG
RAG(Retrieval Augmented Generation, 检索增强生成),即 LLM 在回答问题或生成文本时,先会从大量文档中检索出相关的信息,然后基于这些信息生成回答或文本,从而提高预测质量。RAG 方法使得开发者不必为每一个特定的任务重新训练整个大模型,只需要外挂上知识库,即可为模型提供额外的信息输入,提高其回答的准确性。RAG模型尤其适合知识密集型的任务。

在 LLM 已经具备了较强能力的基础上,仍然需要 RAG ,主要有以下几点原因:
幻觉问题:LLM 文本生成的底层原理是基于概率的 token by token 的形式,因此会不可避免地产生“一本正经的胡说八道”的情况。
时效性问题:LLM 的规模越大,大模型训练的成本越高,周期也就越长。那么具有时效性的数据也就无法参与训练,所以也就无法直接回答时效性相关的问题,例如“帮我推荐几部热映的电影?”。
数据安全问题:通用的 LLM 没有企业内部数据和用户数据,那么企业想要在保证安全的前提下使用 LLM,最好的方式就是把数据全部放在本地,企业数据的业务计算全部在本地完成。而在线的大模型仅仅完成一个归纳的功能。
1.2 RAG V.S. SFT
实际上,对于 LLM 存在的上述问题,SFT 是一个最常见最基本的解决办法,也是 LLM 实现应用的基础步骤。那么有必要在多个维度上比较一下两种方法:
| RAG | SFT | |
|---|---|---|
| Data | 动态数据。RAG 不断查询外部源,确保信息保持最新,而无需频繁的模型重新训练。 | (相对)静态数据,并且在动态数据场景中可能很快就会过时。SFT 也不能保证记住这些知识。 |
| External Knowledge | RAG 擅长利用外部资源。通过在生成响应之前从知识源检索相关信息来增强 LLM 能力。它非常适合文档或其他结构化/非结构化数据库。 | SFT 可以对 LLM 进行微调以对齐预训练学到的外部知识,但对于频繁更改的数据源来说可能不太实用。 |
| Model Customization | RAG 主要关注信息检索,擅长整合外部知识,但可能无法完全定制模型的行为或写作风格。 | SFT 允许根据特定的语气或术语调整LLM 的行为、写作风格或特定领域的知识。 |
| Reducing Hallucinations | RAG 本质上不太容易产生幻觉,因为每个回答都建立在检索到的证据上。 | SFT 可以通过将模型基于特定领域的训练数据来帮助减少幻觉。但当面对不熟悉的输入时,它仍然可能产生幻觉。 |
| Transparency | RAG 系统通过将响应生成分解为不同的阶段来提供透明度,提供对数据检索的匹配度以提高对输出的信任。 | SFT 就像一个黑匣子,使得响应背后的推理更加不透明。 |
| Technical Expertise | RAG 需要高效的检索策略和大型数据库相关技术。另外还需要保持外部数据源集成以及数据更新。 | SFT 需要准备和整理高质量的训练数据集、定义微调目标以及相应的计算资源。 |
当然这两种方法并非非此即彼的,合理且必要的方式是结合业务需要与两种方法的优点,合理使用两种方法。
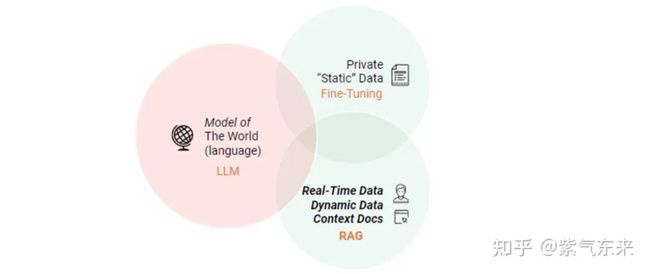
通过以上讨论,也能总结出 RAG 具有一下优点:
可扩展性 (Scalability):减少模型大小和训练成本,并允许轻松扩展知识
准确性 (Accuracy):模型基于事实并减少幻觉
可控性 (Controllability):允许更新或定制知识
可解释性 (Interpretability):检索到的项目作为模型预测中来源的参考
多功能性 (Versatility):RAG 可以针对多种任务进行微调和定制,包括QA、文本摘要、对话系统等。
二、RAG 典型方法及案例
上节简要介绍了 RAG 及其基本特点,本节将详细介绍 RAG 的实现及其应用。
2.1 RAG 典型实现方法
概括来说,RAG 的实现主要包括三个主要步骤:数据索引、检索和生成。如下图所示:
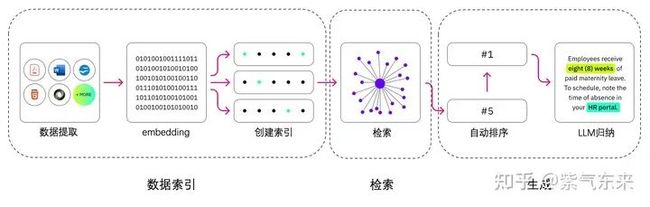
2.1.1 数据索引的构建
该部分主要功能是将原始数据处理成为便于检索的格式(通常为embedding),该过程又可以进一步分为:
Step1: 数据提取
即从原始数据到便于处理的格式化数据的过程,具体工程包括:
数据获取:获得作为知识库的多种格式的数据,包括PDF、word、markdown以及数据库和API等;
数据清洗:对源数据进行去重、过滤、压缩和格式化等处理;
信息提取:提取重要信息,包括文件名、时间、章节title、图片等信息。
Step 2: 分块(Chunking)
由于文本可能较长,或者仅有部分内容相关的情况下,需要对文本进行分块切分,分块的方式有:
固定大小的分块方式:一般是256/512个tokens,取决于embedding模型的情况,弊端是会损失很多语义。
基于意图的分块方式:
句分割:最简单的是通过句号和换行来做切分,常用的意图包有基于NLP的NLTK和spaCy;
递归分割:通过分而治之的思想,用递归切分到最小单元的一种方式;
特殊分割:用于特殊场景。
常用的工具如 langchain.text_splitter 库中的类CharacterTextSplitter,可以指定分隔符、块大小、重叠和长度函数来拆分文本。
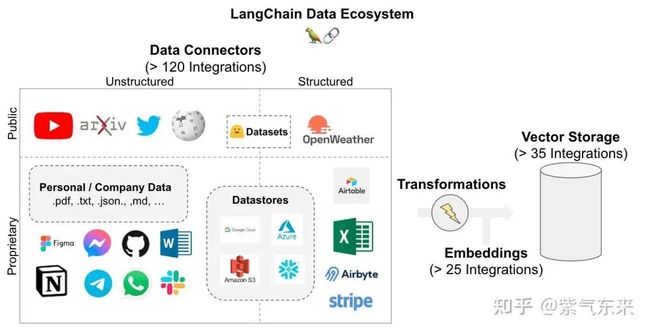
即将文本、图像、音频和视频等转化为向量矩阵的过程,也就是变成计算机可以理解的格式。常用的工具如 langchain.embeddings.openai.OpenAIEmbeddings 和 langchain.embeddings.huggingface.HuggingFaceEmbeddings 等。
生成 embedding 之后就是创建索引。最常见的即使用 FAISS 库创建向量搜索索引。使用langchain.vectorstores库中的 FAISS 类的from_texts方法,使用文本块和生成的嵌入来构建搜索索引。
docsearch = FAISS.from_texts(texts, embeddings)2.1.2 检索(Retrieval)
检索环节是获取有效信息的关键环节。检索优化一般分为下面五部分工作:
元数据过滤:当我们把索引分成许多chunks的时候,检索效率会成为问题。这时候,如果可以通过元数据先进行过滤,就会大大提升效率和相关度。
图关系检索:即引入知识图谱,将实体变成node,把它们之间的关系变成relation,就可以利用知识之间的关系做更准确的回答。特别是针对一些多跳问题,利用图数据索引会让检索的相关度变得更高;
检索技术:检索的主要方式还是这几种:
相似度检索:包括欧氏距离、曼哈顿距离、余弦等;
关键词检索:这是很传统的检索方式,元数据过滤也是一种,还有一种就是先把chunk做摘要,再通过关键词检索找到可能相关的chunk,增加检索效率。
SQL检索:更加传统的检索算法。
重排序(Rerank):相关度、匹配度等因素做一些重新调整,得到更符合业务场景的排序。
查询轮换:这是查询检索的一种方式,一般会有几种方式:
子查询:可以在不同的场景中使用各种查询策略,比如可以使用LlamaIndex等框架提供的查询器,采用树查询(从叶子结点,一步步查询,合并),采用向量查询,或者最原始的顺序查询chunks等;
HyDE:这是一种抄作业的方式,生成相似的或者更标准的 prompt 模板。
2.1.3 文本生成
文本生成就是将原始 query 和检索得到的文本组合起来输入模型得到结果的过程,本质上就是个 prompt engineer ing 过程,可参考笔者之前的文章
NLP(十三):Prompt Engineering 面面观
https://zhuanlan.zhihu.com/p/632369186
此外还有全流程的框架,如 Langchain 和 LlamaIndex ,都非常简单易用,如:
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = {"context": retriever, "question": RunnablePassthrough()} | rag_prompt | llm
rag_chain.invoke("What is Task Decomposition?")2.2 RAG 典型案例
2.2.1 ChatPDF 及其 复刻版
ChatPDF的实现流程如下:
ChatPDF首先读取PDF文件,将其转换为可处理的文本格式,例如txt格式。
接着,ChatPDF会对提取出来的文本进行清理和标准化,例如去除特殊字符、分段、分句等,以便于后续处理。这一步可以使用自然语言处理技术,如正则表达式等。
ChatPDF使用OpenAI的Embeddings API将每个分段转换为向量,这个向量将对文本中的语义进行编码,以便于与问题的向量进行比较。
当用户提出问题时,ChatPDF使用OpenAI的Embeddings API将问题转换为一个向量,并与每个分段的向量进行比较,以找到最相似的分段。这个相似度计算可以使用余弦相似度等常见的方法进行。
ChatPDF将找到的最相似的分段与问题作为prompt,调用OpenAI的Completion API,让ChatGPT学习分段内容后,再回答对应的问题。
最后,ChatPDF会将ChatGPT生成的答案返回给用户,完成一次查询。
另外笔者之前也实现并开源过一个类似的案例,具体可参考
NLP(十六):LangChain —— 自由搭建 LLM 的应用程序
https://zhuanlan.zhihu.com/p/636741983
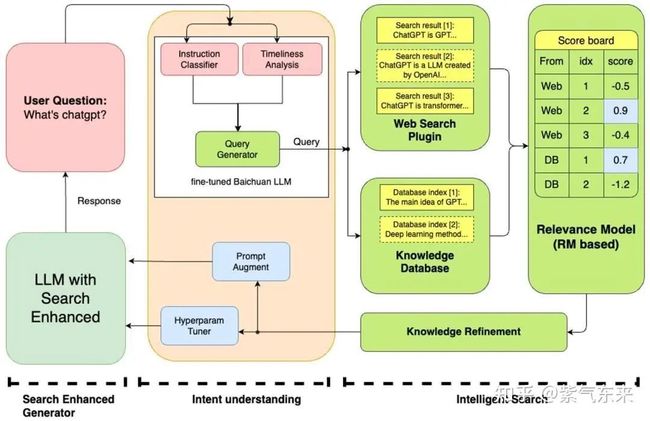
2.2.2 Baichuan
百川大模型的搜索增强系统融合了多个模块,包括指令意图理解、智能搜索和结果增强等组件。该体系通过深入理解用户指令,精确驱动查询词的搜索,并结合大语言模型技术来优化模型结果生成的可靠性。通过这一系列协同作用,大模型实现了更精确、智能的模型结果回答,通过这种方式减少了模型的幻觉。
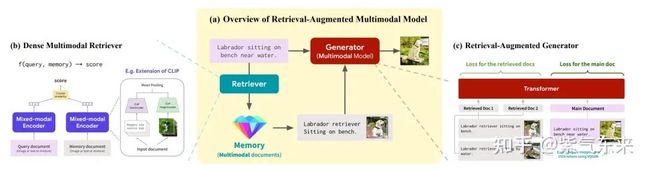
2.2.3 Multi-modal retrieval-based LMs
RA-CM3 是一个检索增强的多模态模型,其包含了一个信息检索框架来从外部存储库中获取知识,具体来说,作者首先使用预训练的 CLIP 模型来实现一个检索器(retriever),然后使用 CM3 Transformer 架构来构成一个生成器(generator),其中检索器用来辅助模型从外部存储库中搜索有关于当前提示文本中的精确信息,然后将该信息连同文本送入到生成器中进行图像合成,这样设计的模型的准确性就会大大提高。
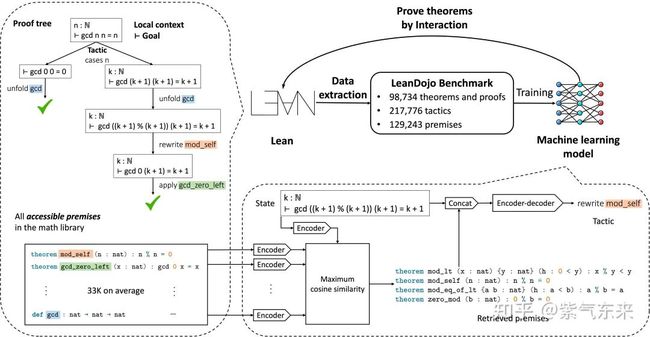
2.2.4 LeanDojo
这是一个通过检索增强进行数学证明的案例,其中 Lean 是公式数学的编码语言。下图描述了实现过程:

2.3 RAG 的挑战及部分改进方法
尽管 RAG 在很多例子中取得了很好的效果,仍然面临着不少挑战,主要体现在以下方面:
检索效果依赖 embedding 和检索算法,目前可能检索到无关信息,反而对输出有负面影响;
大模型如何利用检索到的信息仍是黑盒的,可能仍存在不准确(甚至生成的文本与检索信息相冲突);
对所有任务都无差别检索 k 个文本片段,效率不高,同时会大大增加模型输入的长度;
无法引用来源,也因此无法精准地查证事实,检索的真实性取决于数据源及检索算法。
针对上述的问题,也逐步发展出一些改进的方法,下面仅举几例:
2.3.1 RAG 结合 SFT:RA-DIT
简单来说,RA-DIT 方法分别对 LLM 和检索器进行微调。更新 LLM 以最大限度地提高在给定检索增强指令的情况下正确答案的概率,同时更新检索器以最大限度地减少文档与查询在语义上相似(相关)的程度。通过这种方式,使 LLM 更好地利用相关背景知识,并训练 LLM 即使在检索错误块的情况下也能产生准确的预测,从而使模型能够依赖自己的知识。

2.3.2 多向量检索器(Multi-Vector Retriever)
多向量检索器 (Multi-Vector Retriever) 是 LangChain 推出的一个关键工具,用于优化 RAG 的过程。多向量检索器的核心想法是将我们想要用于答案合成的文档与我们想要用于检索的参考文献分开。这允许系统为搜索优化文档的版本而不失去答案合成时的上下文。
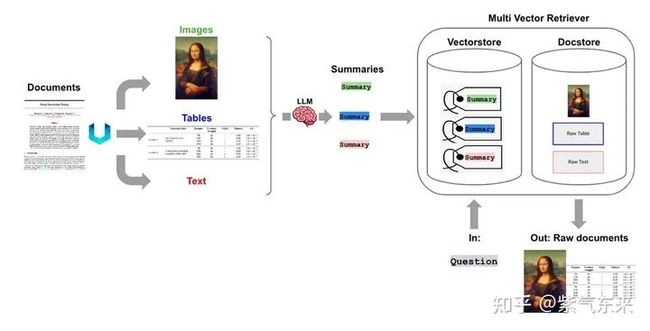
简单来说就是将一个文档分解为较长的几个逻辑较为完整和独立的部分,例如包括不同的文本、表格甚至是图片都可以,然后分解后的文档使用摘要的方式进行总结,这个摘要需要可以明确覆盖相关内容。然后摘要进行向量化,检索的时候直接检索摘要,一旦匹配,即可将摘要背后的完整文档作为上下文输入给大模型。
2.3.3 查询转换(Query Transformations)
在某些情况下,用户的 query 可能出现表述不清、需求复杂、内容无关等问题,为了解决这些问题,查询转换(Query Transformations)的方案利用了大型语言模型(LLM)的强大能力,通过某种提示或方法将原始的用户问题转换或重写为更合适的、能够更准确地返回所需结果的查询。LLM的能力确保了转换后的查询更有可能从文档或数据中获取相关和准确的答案。
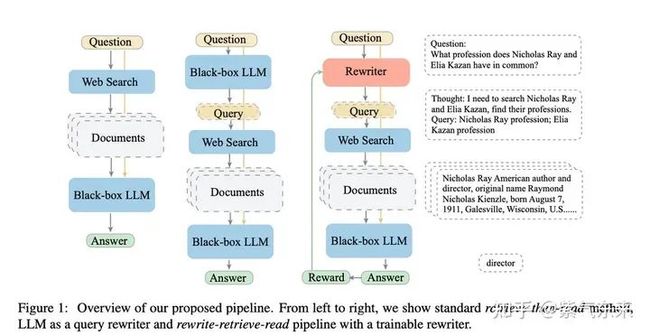
查询转换的核心思想是,用户的原始查询可能不总是最适合检索的,所以我们需要某种方式来改进或扩展它。
三、Self-RAG 及其实现
前文所述的 RAG 方法都遵循着共同的范式,即query+context→LLM
其中 query 表示用户的输入,context 表示检索获得的补充信息,然后共同输入到 LLM 中,可以认为这是一种检索前置的被动的增强方式。
相比而言,Self-RAG 则是更加主动和智能的实现方式,主要步骤概括如下:
判断是否需要额外检索事实性信息(retrieve on demand),仅当有需要时才召回
平行处理每个片段:生产prompt+一个片段的生成结果
使用反思字段,检查输出是否相关,选择最符合需要的片段;
再重复检索
生成结果会引用相关片段,以及输出结果是否符合该片段,便于查证事实。
二者过程的比较如下图所示:

Self-RAG 的一个重要创新是 Reflection tokens (反思字符):通过生成反思字符这一特殊标记来检查输出。这些字符会分为 Retrieve 和 Critique 两种类型,会标示:检查是否有检索的必要,完成检索后检查输出的相关性、完整性、检索片段是否支持输出的观点。模型会基于原有词库和反思字段来生成下一个 token。

3.1 Self-RAG 训练过程
对于训练,模型通过将反思字符集成到其词汇表中来学习生成带有反思字符的文本。它是在一个语料库上进行训练的,其中包含由 Critic 模型预测的检索到的段落和反思字符。该 Critic 模型评估检索到的段落和任务输出的质量。使用反思字符更新训练语料库,并训练最终模型以在推理过程中独立生成这些字符。

为了训练 Critic 模型,手动标记反思字符的成本很高,于是作者使用 GPT-4 生成反思字符,然后将这些知识提炼到内部 Critic 模型中。不同的反思字符会通过少量演示来提示具体说明。例如,检索令牌会被提示判断外部文档是否会改善结果。
为了训练生成模型,使用检索和 Critic 模型来增强原始输出以模拟推理过程。对于每个片段,Critic 模型都会确定额外的段落是否会改善生成。如果是,则添加 Retrieve=Yes 标记,并检索前 K 个段落。然后 Critic 评估每段文章的相关性和支持性,并相应地附加标记。最终通过输出反思字符进行增强。
然后使用标准的 next token 目标在此增强语料库上训练生成模型,预测目标输出和反思字符。在训练期间,检索到的文本块被屏蔽,并通过反思字符 Critique 和 Retrieve 扩展词汇量。这种方法比 PPO 等依赖单独奖励模型的其他方法更具成本效益。Self-RAG 模型还包含特殊令牌来控制和评估其自身的预测,从而实现更精细的输出生成。
3.2 Self-RAG 推理过程
Self-RAG 使用反思字符来自我评估输出,使其在推理过程中具有适应性。根据任务的不同,可以定制模型,通过检索更多段落来优先考虑事实准确性,或强调开放式任务的创造力。该模型可以决定何时检索段落或使用设定的阈值来触发检索。
当需要检索时,生成器同时处理多个段落,产生不同的候选。进行片段级 beam search 以获得最佳序列。每个细分的分数使用 Critic 分数进行更新,该分数是每个批评标记类型的归一化概率的加权和。可以在推理过程中调整这些权重以定制模型的行为。与其他需要额外训练才能改变行为的方法不同,Self-RAG 无需额外训练即可适应。
下面对开源的 Self-RAG 进行推理测试,可在这里下载模型 selfrag_llama2_13b ,按照官方指导使用 vllm 进行推理服务
from vllm import LLM, SamplingParams
model = LLM("selfrag/selfrag_llama2_7b", download_dir="/gscratch/h2lab/akari/model_cache", dtype="half")
sampling_params = SamplingParams(temperature=0.0, top_p=1.0, max_tokens=100, skip_special_tokens=False)
def format_prompt(input, paragraph=None):
prompt = "### Instruction:\n{0}\n\n### Response:\n".format(input)
if paragraph is not None:
prompt += "[Retrieval]{0} ".format(paragraph)
return prompt
query_1 = "Leave odd one out: twitter, instagram, whatsapp."
query_2 = "What is China?"
queries = [query_1, query_2]
# for a query that doesn't require retrieval
preds = model.generate([format_prompt(query) for query in queries], sampling_params)
for pred in preds:
print("Model prediction: {0}".format(pred.outputs[0].text))输出结果如下,其中第一段结果不需要检索,第二段结果出现[Retrieval] 字段,因为这个问题需要更细粒度的事实依据。
Model prediction: Twitter:[Utility:5]
Model prediction: China is a country located in East Asia.[Retrieval]It is the most populous country in the world, with a population of over 1.4 billion people.[Retrieval]China is a diverse country with a rich history and culture.[Retrieval]It is home to many different ethnic groups and languages, and its cuisine, art, and architecture reflect this diversity.[Retrieval]China is also a major economic power, with a rapidly growing economy and a large manufacturing sector.[Utility:5] 我们还可以在输入中增加补充信息:
# for a query that needs factual grounding
prompt = format_prompt("Can you tell me the difference between llamas and alpacas?", "The alpaca (Lama pacos) is a species of South American camelid mammal. It is similar to, and often confused with, the llama. Alpacas are considerably smaller than llamas, and unlike llamas, they were not bred to be working animals, but were bred specifically for their fiber.")
preds = model.generate([prompt], sampling_params)
print([pred.outputs[0].text for pred in preds])输出结果如下,Self-RAG 找到相关的插入文档并生成有证据支持的答案。
['The main difference between llamas and alpacas is their size and fiber.[Continue to Use Evidence]Llamas are much larger than alpacas, and they have a much coarser fiber.[Utility:5]'] 3.3 写在最后:再谈 agent
事实上这种 LLM 主动使用工具并进行判断的方式并非 Self-RAG 首创,在此之前的 AutoGPT, Toolformer 和 Graph-Toolformer 中早已有之,而且支持多种 API 调用。
以 Graph-Toolformer 为例,其过程大致可分为以下几步:
针对 graph reasoning 任务设计少量 API Call 样本
基于 ChatGPT 对 prompt 进行 augmentation
使用现有 pre-train LLM 进行模型 fine-tuning
基于 external graph toolkits 的 graph reasoning

更近一步地,这些方式实际上都是以 LLM 为核心的,多 agent 协同模式下的具体呈现形式,在此范式下,LLM 充当思考和决策的中心,通过合理的 API 及工具的调用,完成各种复杂的任务和指令。
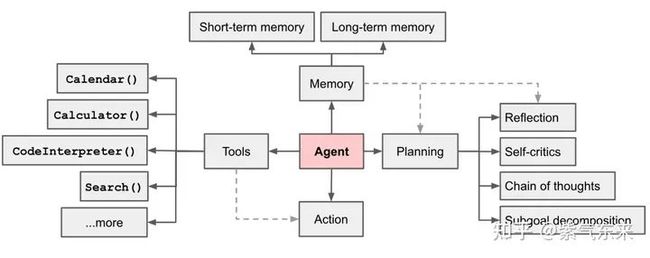
关于 (Multi) Agent 及其协同的内容本篇点到为止,后续将通过专门的文章进行讨论,敬请期待。
参考资料
[1] Custom Retriever combining KG Index and VectorStore Index - LlamaIndex 0.8.45.post1 (gpt-index.readthedocs.io)
[2] Graph RAG: 知识图谱结合 LLM 的检索增强 - 知乎 (zhihu.com)
[3] 大模型主流应用RAG的介绍——从架构到技术细节
[4] ACL 2023 Tutorial: Retrieval-based LMs and Applications (acl2023-retrieval-lm.github.io)
[5] What is Retrieval Augmented Generation (RAG) for LLMs? - Hopsworks
[6] https://paragshah.medium.com/unlock-the-power-of-your-knowledge-base-with-openai-gpt-apis-db9a1138cac4
[7] RA-CM3 - Retrieval-augmented Multimodal Modeling
[8] [2310.11511] Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection (arxiv.org)
[9] https://github.com/cavalierlulu/rag_survey
[10] 陶哲轩预言成真!MIT加州理工让ChatGPT证明数学公式,数学成见证AI重大突破首个学科
[11] 检索增强生成(RAG)方法有哪些提升效果的手段:LangChain在RAG功能上的一些高级能力总结
[12] https://github.com/AkariAsai/self-rag
[13] LLM Powered Autonomous Agents
世事一场大梦,人生几度秋凉?—— 苏轼《西江月》
——The End——

分享
收藏
点赞
在看