Apache Doris入门10问
基于 Apache Doris 在读写流程、副本一致性机制、 存储机制、高可用机制等方面的常见疑问点进行梳理,并以问答形式进行解答。在开始之前,我们先对本文相关的名词进行解释:
-
FE:Frontend,即 Doris 的前端节点。主要负责接收和返回客户端请求、元数据以及集群管理、查询计划生成等工作。
-
BE:Backend,即 Doris 的后端节点。主要负责数据存储与管理、查询计划执行等工作。
-
BDBJE:Oracle Berkeley DB Java Edition, 在 Doris 中,使用 BDBJE 完成元数据操作日志的持久化、FE 高可用等功能。
-
Tablet:Tablet 是一张表实际的物理存储单元,一张表按照分区和分桶后在 BE 构成分布式存储层中以 Tablet 为单位进行存储,每个 Tablet 包括元信息及若干个连续的 RowSet。
-
RowSet:RowSet 是 Tablet 中一次数据变更的数据集合,数据变更包括了数据导入、删除、更新等。RowSet 按版本信息进行记录。每次变更会生成一个版本。
-
Version:由 Start、End 两个属性构成,维护数据变更的记录信息。通常用来表示 RowSet 的版本范围,在一次新导入后生成一个 Start、End 相等的 RowSet,在 Compaction 后生成一个带范围的 RowSet 版本。
-
Segment:表示 RowSet 中的数据分段,多个 Segment 构成一个 RowSet。
-
Compaction:连续版本的 RowSet 合并的过程成称为 Compaction,合并过程中会对数据进行压缩操作。
-
Key 列、Value 列:在 Doris 中,数据以表(Table)的形式进行逻辑上的描述。一张表包括行(Row)和列(Column),Row 即用户的一行数据,Column 用于描述一行数据中不同的字段。Column 可以分为两大类:Key 和 Value。从业务角度看,Key 和 Value 可以分别对应维度列和指标列。Doris 的 Key 列是建表语句中指定的列,建表语句中的关键字 unique key 或 aggregate key 或 duplicate key 后面的列就是 Key 列,除了 Key 列剩下的就是 Value 列。
-
数据模型:Doris 的数据模型主要分为 3 类:Aggregate、Unique、Duplicate。
-
Base 表:在 Doris 中,我们将用户通过建表语句创建出来的表称为 Base 表(Base Table),Base 表中保存着按用户建表语句指定方式存储的基础数据。
-
ROLLUP 表:在 Base 表之上,用户可以创建任意多个 ROLLUP 表。这些 ROLLUP 的数据是基于 Base 表产生的,并且在物理上是独立存储的。ROLLUP 表的基本作用,在于在 Base 表的基础上,获得更粗粒度的聚合数据,类似于物化视图。
Q1:Doris 分区跟分桶有什么区别?
Doris 支持两层数据划分:
-
第一层是 Partition(分区),支持 Range 和 List 的划分方式(类似于 MySQL 的分区表的概念)。若干个 Partition 组成一个 Table,Partition 可以视为是逻辑上最小的管理单元。数据的导入与删除,仅能针对一个 Partition 进行。
-
第二层是 Bucket(Tablet 也称为分桶),支持 Hash 和 Random 的划分方式。每个 Tablet 包含若干数据行,各个 Tablet 之间的数据没有交集,并且在物理上是独立存储的。Tablet 是数据移动、复制等操作的最小物理存储单元。
也可以仅使用一层分区,建表时如果不写分区的语句即可,此时 Doris 会生成一个默认的分区,对用户是透明的。
示意如下:
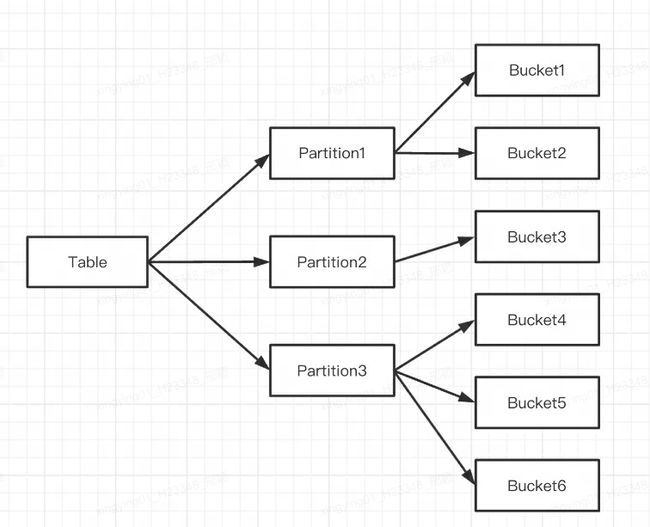
多个 Tablet 在逻辑上归属于不同的分区(Partition),一个 Tablet 只属于一个 Partition,而一个 Partition 包含若干个 Tablet。因为 Tablet 在物理上是独立存储的,所以可以视为 Partition 在物理上也是独立。
从逻辑上来讲,分区和分桶最大的区别就是分桶随机分割数据库,分区是非随机分割数据库。
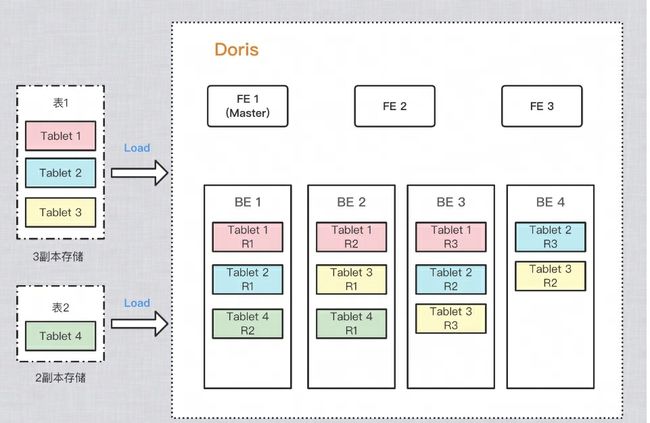
怎么保证数据多副本的?
为了提高保存数据的可靠性和计算时的性能,Doris 对每个表复制多份进行存储。数据的每份复制就叫做一个副本。Doris 按 Tablet 为基本单元对数据进行副本存储,默认一个分片有 3 个副本。建表时可在 PROPERTIES 中设置副本的数量:
PROPERTIES
(
"replication_num" = "3"
);
下图示例,有两个表分别导入 Doris,表 1 导入后按 3 副本存储,表 2 导入后按 2 副本存储。数据分布如下:
Q2:为什么需要分桶?
为了分桶裁剪,并且避免数据倾斜,同时也为了分散读 IO,提升查询性能,可以将 Tablet 的不同副本分散在不同机器上,查询时可以充分发挥不同机器的 IO 性能。
Q3:物理文件的存储结构及格式是怎样的?
Doris 的每次导入可视为一个事务,会生成一个 RowSet 。而 RowSet 又包括多个 Segment,即 Tablet-->Rowset-->Segment 。那 BE 是如何存储这些文件的呢?
Doris 的存储结构
Doris 通过 storage_root_path 进行存储路径配置,Segment 文件存放在 tablet_id 目录下按 SchemaHash 管理。Segment 文件可以有多个,一般按照大小进行分割,默认为 256MB。存储目录以及 Segment 文件命名规则为:
${storage_root_path}/data/${shard}/${tablet_id}/${schema_hash}/${rowset_id}_${segment_id}.dat
进入 storage_root_path 目录,可以看到如下存储结构:
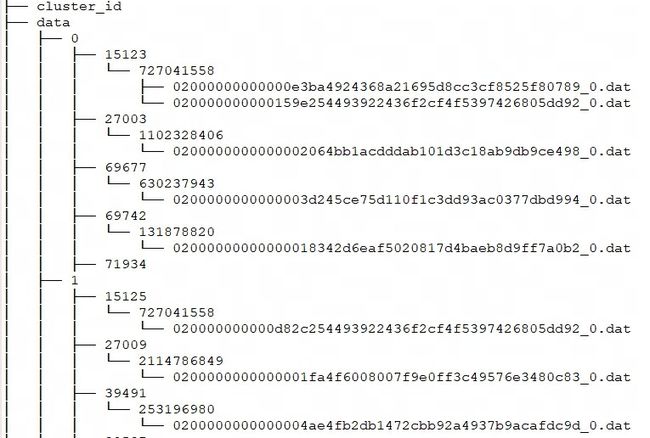
-
${shard}:即上图中的 0、1。是存储目录下 BE 自动创建的,是随机的。会随着数据的增多而增多。 -
${tablet_id}:即上图中的 15123、27003 等,即上面提到的 Bucket 的 ID。 -
${schema_hash}:即上图中的 727041558、1102328406 等。因为一个表的结构可能会被变更,所以对每个 Schema 的版本生成一个SchemaHash,来标识该版本下的数据。 -
${segment_id}.dat:其中前面的为rowset_id,即上图中的 02000000000000e3ba4924368a21695d8cc3cf8525f80789;${segment_id}为当前 RowSet 的segment_id,从 0 开始递增。
Segment 文件的存储格式
Segment 整体的文件格式分为数据区域,索引区域和 Footer 三个部分,如下图所示:

-
Data Region: 用于存储各个列的数据信息,这里的数据是按需分 Page 加载的,其中 Page 中包含了列的数据,每个 Page 为 64k。
-
Index Region:Doris 中将各个列的 Index 数据统一存储在 Index Region,这里的数据会按照列粒度进行加载,所以跟列的数据信息分开存储。
-
Footer 信息:包含文件的元数据信息、内容的 Checksum 等。
Q4:Doris 的不同表模型在 DML 方面有什么限制?
-
Update:Update 语句目前仅支持 UNIQUE KEY 模型,并且只支持更新 Value 列。
-
Delete:1)如果是使用聚合类的表模型(AGGREGATE、UNIQUE),Delete 操作只能指定 Key 列上的条件;2)该操作会同时删除和此 Base Index 相关的 Rollup Index 的数据。
-
Insert:所有数据模型均可 Insert。
Insert 怎么实现?数据插入后如何被查询到?
-
AGGREGATE 模型:Insert 阶段将增量的数据按照 Append 的方式写到 RowSet,查询阶段采用 Merge on Read 的方式进行进行合并。也就是说数据在导入时先写入一个新的 RowSet,写入后并不会执行去重,只有在发起查询时才会做多路并发排序,在进行多路归并排序时,会将重复的 Key 排在一起,并进行聚合操作。其中高版本 Key 的会覆盖低版本的 Key,最终只返回给用户版本最高的那一条记录。
-
DUPLICATE 模型:该模型写入与上述类似,读取阶段不会有任何聚合操作。
-
UNIQUE 模型:在 1.2 版本之前,该模型本质上是聚合模型的一个特例,行为与 AGGREGATE 模型一致。由于聚合模型的实现方式是读时合并(Merge on Read),因此在一些聚合查询上性能不佳。Doris 在 1.2 版本后引入了 Unique 模型新的实现方式,写时合并(Merge on Write),通过在写入时将被覆盖和被更新的数据进行标记删除,在查询的时候,所有被标记删除的数据都会在文件级别被过滤掉,读取出来的数据就都是最新的数据,消除掉了读时合并中的数据聚合过程,并且能够在很多情况下支持多种谓词的下推。
简单来讲,Merge on Write 的处理流程是:
-
对于每一条 Key,查找它在 Base 数据中的位置(RowSetid + Segmentid + 行号)【内存中维护了 Segment 级别的主键区间树,加速查询】
-
如果 Key 存在,则将该行数据标记删除。标记删除的信息记录在 Delete Bitmap 中,其中每个 Segment 都有一个对应的 Delete Bitmap。
-
将更新的数据写入新的 RowSet 中,完成事务,让新数据可见,即能够被用户查询到。
-
查询时,读取 Delete Bitmap,将被标记删除的行过滤掉,只返回有效的数据【对于命中的所有 Segment,按照版本从高到低进行查询】
下面介绍一下写入流程和读取流程的实现。
写入流程:写入数据时会先创建每个 Segment 的主键索引,再更新 Delete Bitmap。

读取流程:Bitmap 的读取流程如下图所示,从图片中我们可知:
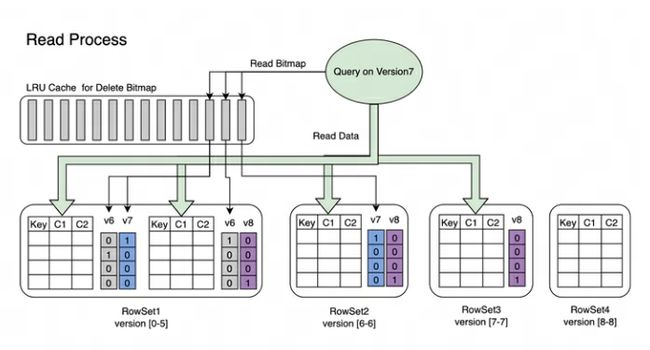
-
一个请求了版本 7 的 Query,只会看到版本 7 对应的数据
-
读取 RowSet5 的数据时,会将 V6 和 V7 对它的修改产生的 Bitmap 合并在一起,得到 Version7 对应的完整 DeleteBitmap,用来过滤数据
-
在上图的示例中,版本 8 的导入覆盖了 RowSet1 的 Segment2 一条数据,但请求版本 7 的 Query 仍然能读到该条数据
Update 怎么实现的?
UNIQUE 模型 Update 过程本质上是 Select+Insert。
-
Update 利用查询引擎自身的 Where 过滤逻辑,从待更新表中筛选出需要被更新的行,基于此维护 Delete Bitmap 以及生成新插入的数据。
-
接着再执行 Insert 逻辑,具体流程跟上述的 UNIQUE 模型写入逻辑类似。
Q5:Doris 的 Delete 是怎么实现的?也是会生成一个 RowSet?如何删除对应的数据?
-
Doris 的 Delete 也是会生成一个 RowSet,DELETE 模式下没有对数据进行实际删除操作,而是对数据删除条件进行了记录。存储在 Meta 信息中。当执行 Base Compaction 时删除条件会一起被合入到 Base 版本中。
-
Doris 在 UNIQUE KEY 模型下也支持了 LOAD_DELETE ,实现了通过批量导入要删除的 key 对数据进行删除,能够支持大量数据删除能力。整体思路是在数据记录中加入删除状态标识,在 Compaction 流程中会对删除的 Key 进行压缩。Compaction 主要负责将多个 RowSet 版本进行合并。
Q6:Doris 有哪些索引?
目前 Doris 主要支持两类索引:
-
内建的智能索引,包括前缀索引和 ZoneMap 索引。
-
用户手动创建的二级索引,包括倒排索引、 Bloomfilter 索引、 Ngram Bloomfilter 索引 和 Bitmap 索引。
其中 ZoneMap 索引是在列存格式上,对每一列自动维护的索引信息,包括 Min/Max,Null 值个数等等。这种索引对用户透明。
索引是什么级别?
-
现在 Doris 里所有索引都是 BE 级别 Local 的,例如:倒排索引、 Bloomfilter 索引、 Ngram Bloomfilter 索引 和 Bitmap 索引、前缀索引和 ZoneMap 索引等
-
Doris 没有 Global Index。广义理解上,分区间 + 分桶键 这些也能算是 Global 的,但是比较粗粒度。
索引的存储格式是怎样的?
Doris 中将各个列的 Index 数据统一存储在 Segment 文件的 Index Region,这里的数据会按照列粒度进行加载,所以跟列的数据信息分开存储。这里以 Short Key Index 前缀索引为例进行介绍。
Short Key Index 前缀索引,是在 Key(AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY)排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。这里 Short Key Index 索引也采用了稀疏索引结构,在数据写入过程中,每隔一定行数,会生成一个索引项。这个行数为索引粒度默认为 1024 行,可配置。该过程如下图所示:
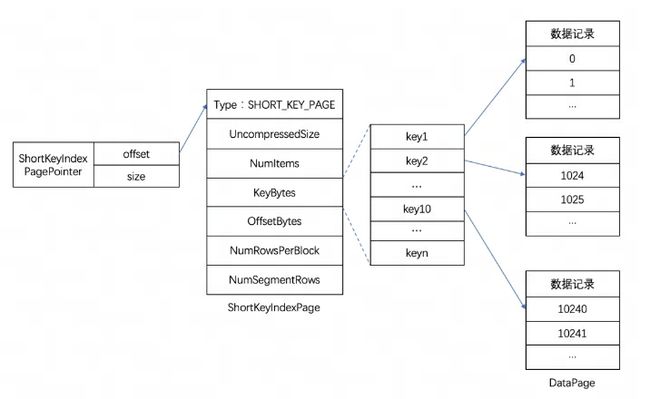
其中,KeyBytes 中存放了索引项数据,OffsetBytes 存放了索引项在 KeyBytes 中的偏移。
Short Key Index 采用了前 36 个字节,作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。 Short Key Index 采用了前 36 个字节,作为这行数据的前缀索引。当遇到 VARCHAR 类型时,前缀索引会直接截断。
读的过程如何命中索引?
在查询一个 Segment 中的数据时,根据执行的查询条件,会对首先根据字段加索引的情况对数据进行过滤。然后在进行读取数据,整体的查询流程如下:
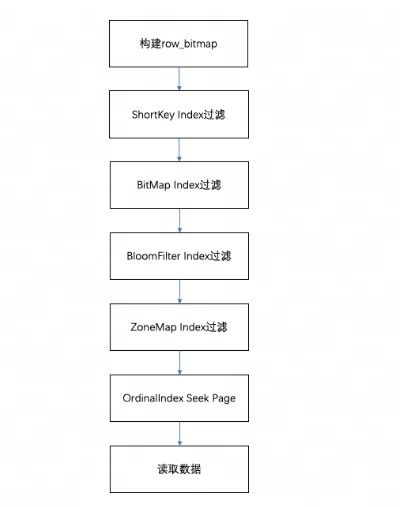
-
首先,会按照 Segment 的行数构建一个
row_bitmap,表示记录哪些数据需要进行读取。没有使用任何索引的情况下,需要读取所有数据。 -
当查询条件中按前缀索引规则使用到了 Key 时,会先进行 ShortKey Index 的过滤,可以在 ShortKey Index 中匹配到的 Oordinal 行号范围,合入到
row_bitmap中。 -
当查询条件中列字段存在 BitMap Index 索引时,会按照 BitMap 索引直接查出符合条件的 Ordinal 行号,与 row_bitmap 求交过滤。这里的过滤是精确的,之后去掉该查询条件,这个字段就不会再进行后面索引的过滤。
-
当查询条件中列字段存在 BloomFilter 索引并且条件为等值(eq,in,is)时,会按 BloomFilter 索引过滤,这里会走完所有索引,过滤每一个 Page 的 BloomFilter,找出查询条件能命中的所有 Page。将索引信息中的 Ordinal 行号范围与
row_bitmap求交过滤。 -
当查询条件中列字段存在 ZoneMap 索引时,会按 ZoneMap 索引过滤,这里同样会走完所有索引,找出查询条件能与 ZoneMap 有交集的所有 Page。将索引信息中的 Ordinal 行号范围与
row_bitmap求交过滤。 -
生成好
row_bitmap之后,批量通过每个 Column 的 OrdinalIndex 找到到具体的 Data Page。 -
批量读取每一列的 Column Data Page 的数据。在读取时,对于有 Null 值的 Page,根据 Null 值位图判断当前行是否是 Null,如果为 Null 进行直接填充即可。
Q7:Doris 如何进行 Compaction 的?
Doris 通过 Compaction 将增量聚合 RowSet 文件提升性能,RowSet 的版本信息中设计了有两个字段 Start、End 来表示 Rowset 合并后的版本范围。未合并的 Cumulative RowSet 的版本 Start 和 End 相等。Compaction 时相邻的 RowSet 会进行合并,生成一个新的 RowSet,版本信息的 Start、End 也会进行合并,变成一个更大范围的版本。另一方面,Compaction 流程大大减少 RowSet 文件数量,提升查询效率。
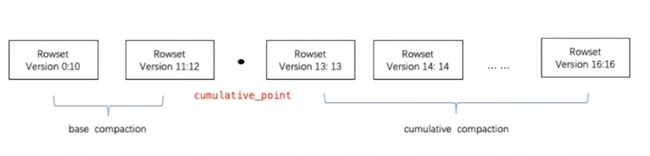
如上图所示,Compaction 任务分为两种,Base Compaction 和 Cumulative Compaction。cumulative_point 是分割两种策略关键。
可以这样理解:
-
cumulative_point右边是从未合并过的增量 RowSet,其每个 RowSet 的 Start 与 End 版本相等; -
cumulative_point左边是合并过的 RowSet,Start 版本与 End 版本不等。 -
Base Compaction 和 Cumulative Compaction 任务流程基本一致,差异仅在选取要合并的 InputRowSet 逻辑有所不同。
Compaction 是按照什么 Key 来的?
-
在一个 Segment 中,数据始终按照 Key(AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY)排序顺序进行存储,即 Key 的排序决定了数据存储的物理结构,确定了列数据的物理结构顺序。
-
所以 Doris Compaction 过程是基于 AGGREGATE KEY、UNIQ KEY 和 DUPLICATE KEY 来进行的。
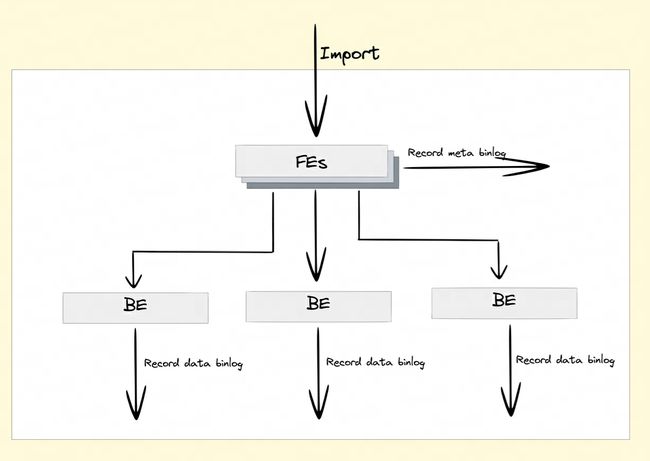
Q8:Doris 怎么实现跨集群数据复制功能?
为了实现跨集群数据复制功能,Doris 引入了 Binlog 机制。通过 Binlog 机制自动记录数据修改记录和操作,以实现数据的可追溯性,同时还可以基于 Binlog 回放机制来实现数据的重放和恢复。
Binlog 怎么记录的?
在开启 Binlog 属性后,FE 和 BE 会将 DDL/DML 操作的修改记录持久化成 Meta Binlog 和 Data Binlog。
-
Meta Binlog:Doris 对 EditLog 的实现进行了增强,以确保日志的有序性。通过构建一个递增序列的 LogID,对每个操作进行准确记录,并按顺序持久化。这种有序的持久化机制有助于保证数据的一致性。
-
Data Binlog:在 FE 发起 Publish Transaction 的时候,BE 会执行对应的 Publish 操作,BE 会将这次 Transaction 涉及 RowSet 的元数据信息写入以
rowset_meta为前缀的 KV 中,并持久化到 Meta 存储中,提交后会把导入的 Segment Files 链接到 Binlog 文件夹下。
Binlog 生成:
BInlog 数据回放:

Q9:Doris 的表是多副本的,写入阶段怎么保证多副本的,是否有主从概念?需要 Majority 后再返回写入成功吗?
-
Doris BE 的 3 副本没有主从的概念,采用 Quorum 算法保证多副本写入。
-
在写入过程中,FE 会判断每一个 Tablet 成功写入数据的副本数量是否超过了 Tablet 副本总数的一半,如果每一个 Tablet 成功写入数据的副本数量都超过 Tablet 副本总数的一半(多数成功),则 Commit Transaction 成功,并将事务状态设置为 COMMITTED;COMMITTED 状态表示数据已经成功写入,但是数据还不可见,需要继续执行 Publish Version 任务,此后,事务不可被回滚。
-
FE 会有一个单独的线程对 Commit 成功的 Transaction 执行 Publish Version,FE 执行 Publish Version 时会通过 Thrift RPC 向 Transaction 相关的所有 Executor BE 节点下发 Publish Version 请求,Publish Version 任务在各个 Executor BE 节点异步执行,将数据导入生成的 RowSet 变为可见的数据版本。
为什么会有 Publish 机制:类似于 MVCC,如果没有 Publish 机制,用户可能读到还没有提交的数据。
如果表为 3 副本,只写入成功 1 个副本会怎样:这个时候事务会 ABORTED
如果表为 3 副本,只写入成功 2 副本会怎样:这个时候事务会 COMMITTED,Doris FE 会定期执行 Tablet 监控巡检,如果发现 Tablet 副本异常,会生成 Clone 任务,Clone 一个新的副本。
为什么用户执行完 Insert Into,立即执行查询,结果可能为空呢:原因是事务还没有 Publish
Q10:Doris 的 FE 怎么保证高可用的?
元数据层面,Doris 采用 Paxos 协议以及 Memory + Checkpoint + Journal 的机制来确保元数据的高性能及高可靠。
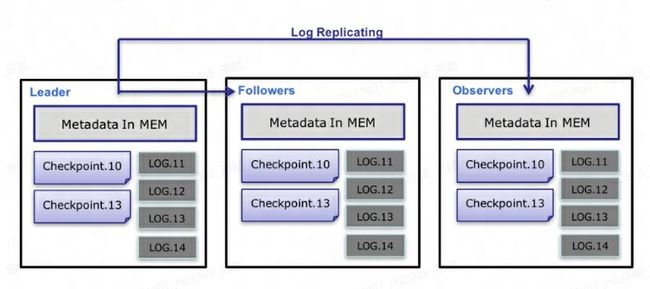
元数据的数据流具体过程如下:
-
只有 Leader FE 可以对元数据进行写操作。写操作在修改 Leader 的内存后,会序列化为一条 Log,按照
key-value的形式写入 BDBJE。其中 Key 为连续的整型,作为log id,Value 即为序列化后的操作日志。 -
日志写入 BDBJE 后,BDBJE 会根据策略(写多数 / 全写),将日志复制到其他 Non-Leader 的 FE 节点。Non-Leader FE 节点通过对日志回放,修改自身的元数据内存镜像,完成与 Leader 节点的元数据同步。
-
Leader 节点的日志条数达到阈值(默认 10w 条)并且满足 Checkpoint 线程执行周期(默认六十秒)。Checkpoint 会读取已有的 Image 文件,和其之后的日志,重新在内存中回放出一份新的元数据镜像副本。然后将该副本写入到磁盘,形成一个新的 Image。之所以是重新生成一份镜像副本,而不是将已有镜像写成 Image,主要是考虑写 Image 加读锁期间,会阻塞写操作。所以每次 Checkpoint 会占用双倍内存空间。
-
Image 文件生成后,Leader 节点会通知其他 Non-Leader 节点新的 Image 已生成。Non-Leader 主动通过 HTTP 拉取最新的 Image 文件,来更换本地的旧文件。
-
BDBJE 中的日志,在 Image 做完后,会定期删除旧的日志。
解释:
-
元数据的每次更新,都首先写入到磁盘的日志文件中,然后再写到内存中,最后定期 Checkpoint 到本地磁盘上。
-
相当于是一个纯内存的一个结构,也就是说所有的元数据都会缓存在内存之中,从而保证 FE 在宕机后能够快速恢复元数据,而且不丢失元数据。
-
Leader、Follower 和 Observer 它们三个构成一个可靠的服务,单机的节点故障的时候其实基本上三个就够了,因为 FE 节点毕竟它只存了一份元数据,它的压力不大,所以如果 FE 太多的时候它会去消耗机器资源,所以多数情况下三个就足够了,可以达到一个很高可用的元数据服务。
-
用户可以使用 MySQL 连接任意一个 FE 节点进行元数据的读写访问。如果连接的是 Non-Leader 节点,则该节点会将写操作转发给 Leader 节点。
转载自隐形 (邢颖) 网易资深数据库内核工程师