Logstash应用介绍
1.Logstash介绍
1.1 前世今生
Logstash 项目诞生于 2009 年 8 月 2 日。其作者是世界著名的运维工程师乔丹西塞(JordanSissel),乔丹西塞当时是著名虚拟主机托管商 DreamHost 的员工。
Logstash 动手很早,对比一下,scribed 诞生于 2008 年,flume 诞生于 2010 年,Graylog2 诞生于 2010 年,Fluentd 诞生于 2011 年。
2013 年,Logstash 被 Elasticsearch 公司收购,ELK stack 正式成为官方用语(虽然还没正式命名)。
elasticsearch 项目开始于 2010 年,其实比 logstash 还晚;
目前我们看到的 angularjs 版本 kibana 其实原名叫 elasticsearch-dashboard,kibana 原先是 RoR 框架的另一个项目,但作者是同一个人,换句话说,kibana 比 logstash 还早就进了 elasticsearch 名下。
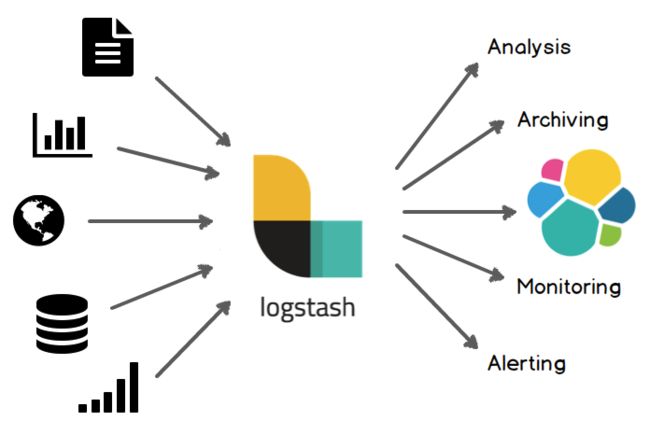
Logstash 是一款基于插件的数据收集和处理引擎。Logstash 配有大量的插件,以便人们能够轻松进行配置以在多种不同的架构中收集、处理并转发数据。
处理过程可分为一个或多个管道。在每个管道中,会有一个或多个输入插件接收或收集数据,然后这些数据会加入内部队列。默认情况下,这些数据很少并且会存储于内存中,但是为了提高可靠性和弹性,也可进行配置以扩大规模并长期存储在磁盘上。
1.2 集成组件归纳
| 类型 | 支持的插件种类 | 常用重点 |
|---|---|---|
| 数据源插件 | azure_event_hubs,beats,cloudwatch,couchdb_changes,dead_letter_queue,elastic_agent,elastic_serverless_forwarder,elasticsearch,exec,file,ganglia,gelf,generator,github,google_cloud_storage,google_pubsub,graphite,heartbeat,http,http_poller,imap,irc,java_generator,java_stdin,jdbc,jms,jmx,kafka,kinesis,logstash,log4j,lumberjack,meetup,pipe,puppet_facter,rabbitmq,redis,relp,rss,s3,s3-sns-sqs,salesforce,snmp,snmptrap,sqlite,sqs,stdin,stomp,syslog,tcp,twitter,udp,unix,varnishlog,websocket,wmi,xmpp | es,file,jdbc,kafka,s3,beats |
| 数据过滤插件 | age,aggregate,alter,bytes,cidr,cipher,clone,csv,date,de_dot,dissect,dns,drop,elapsed,elastic_integration,elasticsearch,environment,extractnumbers,fingerprint,geoip,grok,http,i18n,java_uuid,jdbc_static,jdbc_streaming,json,json_encode,kv,memcached,metricize,metrics,mutate,prune,range,ruby,sleep,split,syslog_pri,threats_classifier,throttle,tld,translate,truncate,urldecode,useragent,uuid,wurfl_device_detection,xml | |
| 数据输出插件 | boundary,circonus,cloudwatch,csv,datadog,datadog_metrics,dynatrace,elastic_app_search,elastic_workplace_search,elasticsearch,email,exec,file,ganglia,gelf,google_bigquery,google_cloud_storage,google_pubsub,graphite,graphtastic,http,influxdb,irc,java_stdout,juggernaut,kafka,librato,logstash,loggly,lumberjack,metriccatcher,mongodb,nagios,nagios_nsca,opentsdb,pagerduty,pipe,rabbitmq,redis,redmine,riak,riemann,s3,sink,sns,solr_http,sqs,statsd,stdout,stomp,syslog,tcp,timber,udp,webhdfs,websocket,xmpp,zabbix | hdfs,es,s3,kafka, |
2.安装
官网下载地址:https://www.elastic.co/cn/downloads/logstash
Logstash是一个即装即用的组件,使用非常方便,安装完成后修改conf文件运行即可
举例:
vim logstash-simple.conf
input { stdin { } }
output {
stdout { codec => rubydebug }
}
bin/logstash -f logstash-simple.conf
{
"message" => "Hello World",
"@version" => "1",
"@timestamp" => "2021-01-11T10:30:59.937Z",
"host" => "local",
}
3.语法介绍
3.1 语法
Logstash 设计了自己的 DSL —— 有点像 Puppet 的 DSL,或许因为都是用 Ruby 语言写的吧 —— 包括有区域,注释,数据类型(布尔值,字符串,数值,数组,哈希),条件判断,字段引用等。
3.2 区段(section)
Logstash 用 {} 来定义区域。区域内可以包括插件区域定义,你可以在一个区域内定义多个插件。插件区域内则可以定义键值对设置。示例如下:
input {
stdin {}
syslog {}
}
3.3 数据类型
Logstash 支持少量的数据值类型:
bool
debug => true
string
host => "hostname"
number
port => 514
array
match => ["datetime", "UNIX", "ISO8601"]
hash
options => {
key1 => "value1",
key2 => "value2"
}
注意:如果你用的版本低于 1.2.0,哈希的语法跟数组是一样的,像下面这样写:
match => [ "field1", "pattern1", "field2", "pattern2" ]
3.4 字段引用(field reference)
字段是 Logstash::Event 对象的属性。我们之前提过事件就像一个哈希一样,所以你可以想象字段就像一个键值对。
我们叫它字段,因为 Elasticsearch 里是这么叫的。
如果你想在 Logstash 配置中使用字段的值,只需要把字段的名字写在中括号 [] 里就行了,这就叫字段引用。
对于 嵌套字段(也就是多维哈希表,或者叫哈希的哈希),每层的字段名都写在 [] 里就可以了。比如,你可以从 geoip 里这样获取 longitude 值(是的,这是个笨办法,实际上有单独的字段专门存这个数据的):
[geoip][location][0]
logstash 的数组也支持倒序下标,即 [geoip][location][-1] 可以获取数组最后一个元素的值。
Logstash 还支持变量内插,在字符串里使用字段引用的方法是这样:
"the longitude is %{[geoip][location][0]}">
3.5 条件判断(condition)
Logstash从 1.3.0 版开始支持条件判断和表达式。
表达式支持下面这些操作符:
- equality, etc: ==, !=, <, >, <=, >=
- regexp: =~, !~
- inclusion: in, not in
- boolean: and, or, nand, xor
- unary: !()
通常来说,你都会在表达式里用到字段引用。比如:
if "_grokparsefailure" not in [tags] {
} else if [status] !~ /^2\d\d/ and [url] == "/noc.gif" {
} else {
}
3.6 命令行参数
Logstash 提供了一个 shell 脚本叫 logstash 方便快速运行。它支持一下参数:
- -e
意即执行。我们在 “Hello World” 的时候已经用过这个参数了。事实上你可以不写任何具体配置,直接运行 bin/logstash -e ‘’ 达到相同效果。这个参数的默认值是下面这样:
input {
stdin { }
}
output {
stdout { }
}
–config 或 -f
意即文件。真实运用中,我们会写很长的配置,甚至可能超过 shell 所能支持的 1024 个字符长度。所以我们必把配置固化到文件里,然后通过 bin/logstash -f agent.conf 这样的形式来运行。
此外,logstash 还提供一个方便我们规划和书写配置的小功能。你可以直接用 bin/logstash -f /etc/logstash.d/ 来运行。logstash 会自动读取 /etc/logstash.d/ 目录下所有的文本文件,然后在自己内存里拼接成一个完整的大配置文件,再去执行。
-
–configtest 或 -t
意即测试。用来测试 Logstash 读取到的配置文件语法是否能正常解析。Logstash 配置语法是用 grammar.treetop 定义的。尤其是使用了上一条提到的读取目录方式的读者,尤其要提前测试。 -
–log 或 -l
意即日志。Logstash 默认输出日志到标准错误。生产环境下你可以通过 bin/logstash -l logs/logstash.log 命令来统一存储日志。 -
–filterworkers 或 -w
意即工作线程。Logstash 会运行多个线程。你可以用 bin/logstash -w 5 这样的方式强制 Logstash 为过滤插件运行 5 个线程。
注意:Logstash目前还不支持输入插件的多线程。而输出插件的多线程需要在配置内部设置,这个命令行参数只是用来设置过滤插件的!
提示:Logstash 目前不支持对过滤器线程的监测管理。如果 filterworker 挂掉,Logstash 会处于一个无 filter 的僵死状态。这种情况在使用 filter/ruby 自己写代码时非常需要注意,很容易碰上 NoMethodError: undefined method ‘*’ for nil:NilClass 错误。需要妥善处理,提前判断。
-
–pluginpath 或 -P
可以写自己的插件,然后用 bin/logstash --pluginpath /path/to/own/plugins 加载它们。 -
–verbose
输出一定的调试日志。
4.使用举例
#1.数据源
input {
stdin {
}
jdbc {
# mysql 数据库链接,shop为数据库名
jdbc_connection_string => "jdbc:mysql:/xxx:3306/rebuild?characterEncoding=UTF-8&useSSL=false"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "root"
# 驱动
jdbc_driver_library => "E:/2setsoft/1dev/logstash-7.8.0/mysqletc/mysql-connector-java-5.1.7-bin.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
parameters => {"number" => "200"}
# 执行的sql 文件路径+名称
#statement_filepath => "E:/2setsoft/1dev/logstash-7.8.0/mysqletc/user.sql"
statement => "SELECT * FROM `hhyp_article` WHERE delete_time = 0"
# 是否将字段名转换为小写,默认true(如果有数据序列化、反序列化需求,建议改为false);
lowercase_column_names => false
# Value can be any of: fatal,error,warn,info,debug,默认info;
sql_log_level => warn
# 是否记录上次执行结果,true表示会将上次执行结果的tracking_column字段的值保存到last_run_metadata_path指定的文件中;
record_last_run => true
# 需要记录查询结果某字段的值时,此字段为true,否则默认tracking_column为timestamp的值;
use_column_value => true
# 需要记录的字段,用于增量同步,需是数据库字段
tracking_column => "ModifyTime"
# Value can be any of: numeric,timestamp,Default value is "numeric"
tracking_column_type => timestamp
# record_last_run上次数据存放位置;
last_run_metadata_path => "E:/2setsoft/1dev/logstash-7.8.0/mysqletc/last_id.txt"
# 是否清除last_run_metadata_path的记录,需要增量同步时此字段必须为false;
clean_run => false
# 设置监听间隔 各字段含义(由左至右)分、时、天、月、年,全部为*默认含义为每分钟都更新
schedule => "* * * * *"
# 索引类型
type => "article"
}
}
#2.数据处理
filter {
json {
source => "message"
remove_field => ["message"]
}
}
#3.数据输出
output {
if[type] == "article" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "hhyp_article"
document_id => "%{id}"
}
}
if[type] == "article_cate" {
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "hhyp_article_cate"
document_id => "%{id}"
}
}
stdout {
codec => json_lines
}
}