深度学习 Day25——J4 ResNet与DenseNet结合探索(DPN)
- 本文为365天深度学习训练营 中的学习记录博客
- 原作者:K同学啊 | 接辅导、项目定制
- 文章来源:K同学的学习圈子
文章目录
- 前言
- 1 我的环境
- 2 pytorch实现DPN算法
-
- 2.1 前期准备
-
- 2.1.1 引入库
- 2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
- 2.1.3 导入数据
- 2.1.4 可视化数据
- 2.1.4 图像数据变换
- 2.1.4 划分数据集
- 2.1.4 加载数据
- 2.1.4 查看数据
- 2.2 搭建DPN模型
- 2.3 训练模型
-
- 2.3.1 设置超参数
- 2.3.2 编写训练函数
- 2.3.3 编写测试函数
- 2.3.4 正式训练
- 2.4 结果可视化
- 2.4 指定图片进行预测
- 2.6 模型评估
- 4 知识点详解
-
- 4.1 DPN讲解
-
- 4.1.2 DPN模型架构
- 总结
前言
关键字: pytorch实现DenseNet算法,tensorflow实现DenseNet算法,DenseNet算法详解
1 我的环境
- 电脑系统:Windows 11
- 语言环境:python 3.8.6
- 编译器:pycharm2020.2.3
- 深度学习环境:
torch == 1.9.1+cu111
torchvision == 0.10.1+cu111
TensorFlow 2.10.1 - 显卡:NVIDIA GeForce RTX 4070
2 pytorch实现DPN算法
2.1 前期准备
2.1.1 引入库
import torch
import torch.nn as nn
import time
import copy
from torchvision import transforms, datasets
from pathlib import Path
from PIL import Image
import torchsummary as summary
import torch.nn.functional as F
from collections import OrderedDict
import re
import torch.utils.model_zoo as model_zoo
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
import warnings
warnings.filterwarnings('ignore') # 忽略一些warning内容,无需打印
2.1.2 设置GPU(如果设备上支持GPU就使用GPU,否则使用CPU)
"""前期准备-设置GPU"""
# 如果设备上支持GPU就使用GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print("Using {} device".format(device))
输出
Using cuda device
2.1.3 导入数据
'''前期工作-导入数据'''
data_dir = r"D:\DeepLearning\data\bird\bird_photos"
data_dir = Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[-1] for path in data_paths]
print(classeNames)
输出
['Bananaquit', 'Black Skimmer', 'Black Throated Bushtiti', 'Cockatoo']
2.1.4 可视化数据
'''前期工作-可视化数据'''
subfolder = Path(data_dir) / "Cockatoo"
image_files = list(p.resolve() for p in subfolder.glob('*') if p.suffix in [".jpg", ".png", ".jpeg"])
plt.figure(figsize=(10, 6))
for i in range(len(image_files[:12])):
image_file = image_files[i]
ax = plt.subplot(3, 4, i + 1)
img = Image.open(str(image_file))
plt.imshow(img)
plt.axis("off")
# 显示图片
plt.tight_layout()
plt.show()

2.1.4 图像数据变换
'''前期工作-图像数据变换'''
total_datadir = data_dir
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir, transform=train_transforms)
print(total_data)
print(total_data.class_to_idx)
输出
Dataset ImageFolder
Number of datapoints: 565
Root location: D:\DeepLearning\data\bird\bird_photos
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
{'Bananaquit': 0, 'Black Skimmer': 1, 'Black Throated Bushtiti': 2, 'Cockatoo': 3}
2.1.4 划分数据集
'''前期工作-划分数据集'''
train_size = int(0.8 * len(total_data)) # train_size表示训练集大小,通过将总体数据长度的80%转换为整数得到;
test_size = len(total_data) - train_size # test_size表示测试集大小,是总体数据长度减去训练集大小。
# 使用torch.utils.data.random_split()方法进行数据集划分。该方法将总体数据total_data按照指定的大小比例([train_size, test_size])随机划分为训练集和测试集,
# 并将划分结果分别赋值给train_dataset和test_dataset两个变量。
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
print("train_dataset={}\ntest_dataset={}".format(train_dataset, test_dataset))
print("train_size={}\ntest_size={}".format(train_size, test_size))
输出
train_dataset=
test_dataset=
train_size=452
test_size=113
2.1.4 加载数据
'''前期工作-加载数据'''
batch_size = 4
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
2.1.4 查看数据
'''前期工作-查看数据'''
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
输出
Shape of X [N, C, H, W]: torch.Size([4, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
2.2 搭建DPN模型
class Block(nn.Module):
"""
param : in_channel--输入通道数
mid_channel -- 中间经历的通道数
out_channel -- ResNet部分使用的通道数(sum操作,这部分输出仍然是out_channel个通道)
dense_channel -- DenseNet部分使用的通道数(concat操作,这部分输出是2*dense_channel个通道)
groups -- conv2中的分组卷积参数
is_shortcut -- ResNet前是否进行shortcut操作
"""
def __init__(self, in_channel, mid_channel, out_channel, dense_channel, stride, groups, is_shortcut=False):
super(Block, self).__init__()
self.is_shortcut = is_shortcut
self.out_channel = out_channel
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, mid_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(mid_channel),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(mid_channel, mid_channel, kernel_size=3, stride=stride, padding=1, groups=groups, bias=False),
nn.BatchNorm2d(mid_channel),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(mid_channel, out_channel + dense_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel + dense_channel)
)
if self.is_shortcut:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channel, out_channel + dense_channel, kernel_size=3, padding=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channel + dense_channel)
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
a = x
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
if self.is_shortcut:
a = self.shortcut(a)
# a[:, :self.out_channel, :, :]+x[:, :self.out_channel, :, :]是使用ResNet的方法,即采用sum的方式将特征图进行求和,通道数不变,都是out_channel个通道
# a[:, self.out_channel:, :, :], x[:, self.out_channel:, :, :]]是使用DenseNet的方法,即采用concat的方式将特征图在channel维度上直接进行叠加,通道数加倍,即2*dense_channel
# 注意最终是将out_channel个通道的特征(ResNet方式)与2*dense_channel个通道特征(DenseNet方式)进行叠加,因此最终通道数为out_channel+2*dense_channel
x = torch.cat([a[:, :self.out_channel, :, :] + x[:, :self.out_channel, :, :], a[:, self.out_channel:, :, :],
x[:, self.out_channel:, :, :]], dim=1)
x = self.relu(x)
return x
class DPN(nn.Module):
def __init__(self, cfg):
super(DPN, self).__init__()
self.group = cfg['group']
self.in_channel = cfg['in_channel']
mid_channels = cfg['mid_channels']
out_channels = cfg['out_channels']
dense_channels = cfg['dense_channels']
num = cfg['num']
self.conv1 = nn.Sequential(
nn.Conv2d(3, self.in_channel, 7, stride=2, padding=3, bias=False, padding_mode='zeros'),
nn.BatchNorm2d(self.in_channel),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
)
self.conv2 = self._make_layers(mid_channels[0], out_channels[0], dense_channels[0], num[0], stride=1)
self.conv3 = self._make_layers(mid_channels[1], out_channels[1], dense_channels[1], num[1], stride=2)
self.conv4 = self._make_layers(mid_channels[2], out_channels[2], dense_channels[2], num[2], stride=2)
self.conv5 = self._make_layers(mid_channels[3], out_channels[3], dense_channels[3], num[3], stride=2)
self.pool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(cfg['out_channels'][3] + (num[3] + 1) * cfg['dense_channels'][3], cfg['classes']) # fc层需要计算
def _make_layers(self, mid_channel, out_channel, dense_channel, num, stride):
layers = []
# is_shortcut=True表示进行shortcut操作,则将浅层的特征进行一次卷积后与进行第三次卷积的特征图相加(ResNet方式)和concat(DeseNet方式)操作
# 第一次使用Block可以满足浅层特征的利用,后续重复的Block则不需要线层特征,因此后续的Block的is_shortcut=False(默认值)
layers.append(Block(self.in_channel, mid_channel, out_channel, dense_channel, stride=stride, groups=self.group,
is_shortcut=True))
self.in_channel = out_channel + dense_channel * 2
for i in range(1, num):
layers.append(Block(self.in_channel, mid_channel, out_channel, dense_channel, stride=1, groups=self.group))
# 由于Block包含DenseNet在叠加特征图,所以第一次是2倍dense_channel,后面每次都会多出1倍dense_channel
self.in_channel += dense_channel
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.pool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
def DPN92(n_class=4):
cfg = {
"group": 32,
"in_channel": 64,
"mid_channels": (96, 192, 384, 768),
"out_channels": (256, 512, 1024, 2048),
"dense_channels": (16, 32, 24, 128),
"num": (3, 4, 20, 3),
"classes": (n_class)
}
return DPN(cfg)
def DPN98(n_class=4):
cfg = {
"group": 40,
"in_channel": 96,
"mid_channels": (160, 320, 640, 1280),
"out_channels": (256, 512, 1024, 2048),
"dense_channels": (16, 32, 32, 128),
"num": (3, 6, 20, 3),
"classes": (n_class)
}
return DPN(cfg)
"""搭建DPN92模型"""
model = DPN92().to(device)
print(summary.summary(model, (3, 224, 224))) # 查看模型的参数量以及相关指标
输出
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 55, 55] 0
Conv2d-5 [-1, 96, 55, 55] 6,144
BatchNorm2d-6 [-1, 96, 55, 55] 192
ReLU-7 [-1, 96, 55, 55] 0
Conv2d-8 [-1, 96, 55, 55] 2,592
BatchNorm2d-9 [-1, 96, 55, 55] 192
ReLU-10 [-1, 96, 55, 55] 0
Conv2d-11 [-1, 272, 55, 55] 26,112
BatchNorm2d-12 [-1, 272, 55, 55] 544
Conv2d-13 [-1, 272, 55, 55] 156,672
BatchNorm2d-14 [-1, 272, 55, 55] 544
ReLU-15 [-1, 288, 55, 55] 0
Block-16 [-1, 288, 55, 55] 0
Conv2d-17 [-1, 96, 55, 55] 27,648
BatchNorm2d-18 [-1, 96, 55, 55] 192
ReLU-19 [-1, 96, 55, 55] 0
Conv2d-20 [-1, 96, 55, 55] 2,592
BatchNorm2d-21 [-1, 96, 55, 55] 192
ReLU-22 [-1, 96, 55, 55] 0
Conv2d-23 [-1, 272, 55, 55] 26,112
BatchNorm2d-24 [-1, 272, 55, 55] 544
ReLU-25 [-1, 304, 55, 55] 0
Block-26 [-1, 304, 55, 55] 0
Conv2d-27 [-1, 96, 55, 55] 29,184
BatchNorm2d-28 [-1, 96, 55, 55] 192
ReLU-29 [-1, 96, 55, 55] 0
Conv2d-30 [-1, 96, 55, 55] 2,592
BatchNorm2d-31 [-1, 96, 55, 55] 192
ReLU-32 [-1, 96, 55, 55] 0
Conv2d-33 [-1, 272, 55, 55] 26,112
BatchNorm2d-34 [-1, 272, 55, 55] 544
ReLU-35 [-1, 320, 55, 55] 0
Block-36 [-1, 320, 55, 55] 0
Conv2d-37 [-1, 192, 55, 55] 61,440
BatchNorm2d-38 [-1, 192, 55, 55] 384
ReLU-39 [-1, 192, 55, 55] 0
Conv2d-40 [-1, 192, 28, 28] 10,368
BatchNorm2d-41 [-1, 192, 28, 28] 384
ReLU-42 [-1, 192, 28, 28] 0
Conv2d-43 [-1, 544, 28, 28] 104,448
BatchNorm2d-44 [-1, 544, 28, 28] 1,088
Conv2d-45 [-1, 544, 28, 28] 1,566,720
BatchNorm2d-46 [-1, 544, 28, 28] 1,088
ReLU-47 [-1, 576, 28, 28] 0
Block-48 [-1, 576, 28, 28] 0
Conv2d-49 [-1, 192, 28, 28] 110,592
BatchNorm2d-50 [-1, 192, 28, 28] 384
ReLU-51 [-1, 192, 28, 28] 0
Conv2d-52 [-1, 192, 28, 28] 10,368
BatchNorm2d-53 [-1, 192, 28, 28] 384
ReLU-54 [-1, 192, 28, 28] 0
Conv2d-55 [-1, 544, 28, 28] 104,448
BatchNorm2d-56 [-1, 544, 28, 28] 1,088
ReLU-57 [-1, 608, 28, 28] 0
Block-58 [-1, 608, 28, 28] 0
Conv2d-59 [-1, 192, 28, 28] 116,736
BatchNorm2d-60 [-1, 192, 28, 28] 384
ReLU-61 [-1, 192, 28, 28] 0
Conv2d-62 [-1, 192, 28, 28] 10,368
BatchNorm2d-63 [-1, 192, 28, 28] 384
ReLU-64 [-1, 192, 28, 28] 0
Conv2d-65 [-1, 544, 28, 28] 104,448
BatchNorm2d-66 [-1, 544, 28, 28] 1,088
ReLU-67 [-1, 640, 28, 28] 0
Block-68 [-1, 640, 28, 28] 0
Conv2d-69 [-1, 192, 28, 28] 122,880
BatchNorm2d-70 [-1, 192, 28, 28] 384
ReLU-71 [-1, 192, 28, 28] 0
Conv2d-72 [-1, 192, 28, 28] 10,368
BatchNorm2d-73 [-1, 192, 28, 28] 384
ReLU-74 [-1, 192, 28, 28] 0
Conv2d-75 [-1, 544, 28, 28] 104,448
BatchNorm2d-76 [-1, 544, 28, 28] 1,088
ReLU-77 [-1, 672, 28, 28] 0
Block-78 [-1, 672, 28, 28] 0
Conv2d-79 [-1, 384, 28, 28] 258,048
BatchNorm2d-80 [-1, 384, 28, 28] 768
ReLU-81 [-1, 384, 28, 28] 0
Conv2d-82 [-1, 384, 14, 14] 41,472
BatchNorm2d-83 [-1, 384, 14, 14] 768
ReLU-84 [-1, 384, 14, 14] 0
Conv2d-85 [-1, 1048, 14, 14] 402,432
BatchNorm2d-86 [-1, 1048, 14, 14] 2,096
Conv2d-87 [-1, 1048, 14, 14] 6,338,304
BatchNorm2d-88 [-1, 1048, 14, 14] 2,096
ReLU-89 [-1, 1072, 14, 14] 0
Block-90 [-1, 1072, 14, 14] 0
Conv2d-91 [-1, 384, 14, 14] 411,648
BatchNorm2d-92 [-1, 384, 14, 14] 768
ReLU-93 [-1, 384, 14, 14] 0
Conv2d-94 [-1, 384, 14, 14] 41,472
BatchNorm2d-95 [-1, 384, 14, 14] 768
ReLU-96 [-1, 384, 14, 14] 0
Conv2d-97 [-1, 1048, 14, 14] 402,432
BatchNorm2d-98 [-1, 1048, 14, 14] 2,096
ReLU-99 [-1, 1096, 14, 14] 0
Block-100 [-1, 1096, 14, 14] 0
Conv2d-101 [-1, 384, 14, 14] 420,864
BatchNorm2d-102 [-1, 384, 14, 14] 768
ReLU-103 [-1, 384, 14, 14] 0
Conv2d-104 [-1, 384, 14, 14] 41,472
BatchNorm2d-105 [-1, 384, 14, 14] 768
ReLU-106 [-1, 384, 14, 14] 0
Conv2d-107 [-1, 1048, 14, 14] 402,432
BatchNorm2d-108 [-1, 1048, 14, 14] 2,096
ReLU-109 [-1, 1120, 14, 14] 0
Block-110 [-1, 1120, 14, 14] 0
Conv2d-111 [-1, 384, 14, 14] 430,080
BatchNorm2d-112 [-1, 384, 14, 14] 768
ReLU-113 [-1, 384, 14, 14] 0
Conv2d-114 [-1, 384, 14, 14] 41,472
BatchNorm2d-115 [-1, 384, 14, 14] 768
ReLU-116 [-1, 384, 14, 14] 0
Conv2d-117 [-1, 1048, 14, 14] 402,432
BatchNorm2d-118 [-1, 1048, 14, 14] 2,096
ReLU-119 [-1, 1144, 14, 14] 0
Block-120 [-1, 1144, 14, 14] 0
Conv2d-121 [-1, 384, 14, 14] 439,296
BatchNorm2d-122 [-1, 384, 14, 14] 768
ReLU-123 [-1, 384, 14, 14] 0
Conv2d-124 [-1, 384, 14, 14] 41,472
BatchNorm2d-125 [-1, 384, 14, 14] 768
ReLU-126 [-1, 384, 14, 14] 0
Conv2d-127 [-1, 1048, 14, 14] 402,432
BatchNorm2d-128 [-1, 1048, 14, 14] 2,096
ReLU-129 [-1, 1168, 14, 14] 0
Block-130 [-1, 1168, 14, 14] 0
Conv2d-131 [-1, 384, 14, 14] 448,512
BatchNorm2d-132 [-1, 384, 14, 14] 768
ReLU-133 [-1, 384, 14, 14] 0
Conv2d-134 [-1, 384, 14, 14] 41,472
BatchNorm2d-135 [-1, 384, 14, 14] 768
ReLU-136 [-1, 384, 14, 14] 0
Conv2d-137 [-1, 1048, 14, 14] 402,432
BatchNorm2d-138 [-1, 1048, 14, 14] 2,096
ReLU-139 [-1, 1192, 14, 14] 0
Block-140 [-1, 1192, 14, 14] 0
Conv2d-141 [-1, 384, 14, 14] 457,728
BatchNorm2d-142 [-1, 384, 14, 14] 768
ReLU-143 [-1, 384, 14, 14] 0
Conv2d-144 [-1, 384, 14, 14] 41,472
BatchNorm2d-145 [-1, 384, 14, 14] 768
ReLU-146 [-1, 384, 14, 14] 0
Conv2d-147 [-1, 1048, 14, 14] 402,432
BatchNorm2d-148 [-1, 1048, 14, 14] 2,096
ReLU-149 [-1, 1216, 14, 14] 0
Block-150 [-1, 1216, 14, 14] 0
Conv2d-151 [-1, 384, 14, 14] 466,944
BatchNorm2d-152 [-1, 384, 14, 14] 768
ReLU-153 [-1, 384, 14, 14] 0
Conv2d-154 [-1, 384, 14, 14] 41,472
BatchNorm2d-155 [-1, 384, 14, 14] 768
ReLU-156 [-1, 384, 14, 14] 0
Conv2d-157 [-1, 1048, 14, 14] 402,432
BatchNorm2d-158 [-1, 1048, 14, 14] 2,096
ReLU-159 [-1, 1240, 14, 14] 0
Block-160 [-1, 1240, 14, 14] 0
Conv2d-161 [-1, 384, 14, 14] 476,160
BatchNorm2d-162 [-1, 384, 14, 14] 768
ReLU-163 [-1, 384, 14, 14] 0
Conv2d-164 [-1, 384, 14, 14] 41,472
BatchNorm2d-165 [-1, 384, 14, 14] 768
ReLU-166 [-1, 384, 14, 14] 0
Conv2d-167 [-1, 1048, 14, 14] 402,432
BatchNorm2d-168 [-1, 1048, 14, 14] 2,096
ReLU-169 [-1, 1264, 14, 14] 0
Block-170 [-1, 1264, 14, 14] 0
Conv2d-171 [-1, 384, 14, 14] 485,376
BatchNorm2d-172 [-1, 384, 14, 14] 768
ReLU-173 [-1, 384, 14, 14] 0
Conv2d-174 [-1, 384, 14, 14] 41,472
BatchNorm2d-175 [-1, 384, 14, 14] 768
ReLU-176 [-1, 384, 14, 14] 0
Conv2d-177 [-1, 1048, 14, 14] 402,432
BatchNorm2d-178 [-1, 1048, 14, 14] 2,096
ReLU-179 [-1, 1288, 14, 14] 0
Block-180 [-1, 1288, 14, 14] 0
Conv2d-181 [-1, 384, 14, 14] 494,592
BatchNorm2d-182 [-1, 384, 14, 14] 768
ReLU-183 [-1, 384, 14, 14] 0
Conv2d-184 [-1, 384, 14, 14] 41,472
BatchNorm2d-185 [-1, 384, 14, 14] 768
ReLU-186 [-1, 384, 14, 14] 0
Conv2d-187 [-1, 1048, 14, 14] 402,432
BatchNorm2d-188 [-1, 1048, 14, 14] 2,096
ReLU-189 [-1, 1312, 14, 14] 0
Block-190 [-1, 1312, 14, 14] 0
Conv2d-191 [-1, 384, 14, 14] 503,808
BatchNorm2d-192 [-1, 384, 14, 14] 768
ReLU-193 [-1, 384, 14, 14] 0
Conv2d-194 [-1, 384, 14, 14] 41,472
BatchNorm2d-195 [-1, 384, 14, 14] 768
ReLU-196 [-1, 384, 14, 14] 0
Conv2d-197 [-1, 1048, 14, 14] 402,432
BatchNorm2d-198 [-1, 1048, 14, 14] 2,096
ReLU-199 [-1, 1336, 14, 14] 0
Block-200 [-1, 1336, 14, 14] 0
Conv2d-201 [-1, 384, 14, 14] 513,024
BatchNorm2d-202 [-1, 384, 14, 14] 768
ReLU-203 [-1, 384, 14, 14] 0
Conv2d-204 [-1, 384, 14, 14] 41,472
BatchNorm2d-205 [-1, 384, 14, 14] 768
ReLU-206 [-1, 384, 14, 14] 0
Conv2d-207 [-1, 1048, 14, 14] 402,432
BatchNorm2d-208 [-1, 1048, 14, 14] 2,096
ReLU-209 [-1, 1360, 14, 14] 0
Block-210 [-1, 1360, 14, 14] 0
Conv2d-211 [-1, 384, 14, 14] 522,240
BatchNorm2d-212 [-1, 384, 14, 14] 768
ReLU-213 [-1, 384, 14, 14] 0
Conv2d-214 [-1, 384, 14, 14] 41,472
BatchNorm2d-215 [-1, 384, 14, 14] 768
ReLU-216 [-1, 384, 14, 14] 0
Conv2d-217 [-1, 1048, 14, 14] 402,432
BatchNorm2d-218 [-1, 1048, 14, 14] 2,096
ReLU-219 [-1, 1384, 14, 14] 0
Block-220 [-1, 1384, 14, 14] 0
Conv2d-221 [-1, 384, 14, 14] 531,456
BatchNorm2d-222 [-1, 384, 14, 14] 768
ReLU-223 [-1, 384, 14, 14] 0
Conv2d-224 [-1, 384, 14, 14] 41,472
BatchNorm2d-225 [-1, 384, 14, 14] 768
ReLU-226 [-1, 384, 14, 14] 0
Conv2d-227 [-1, 1048, 14, 14] 402,432
BatchNorm2d-228 [-1, 1048, 14, 14] 2,096
ReLU-229 [-1, 1408, 14, 14] 0
Block-230 [-1, 1408, 14, 14] 0
Conv2d-231 [-1, 384, 14, 14] 540,672
BatchNorm2d-232 [-1, 384, 14, 14] 768
ReLU-233 [-1, 384, 14, 14] 0
Conv2d-234 [-1, 384, 14, 14] 41,472
BatchNorm2d-235 [-1, 384, 14, 14] 768
ReLU-236 [-1, 384, 14, 14] 0
Conv2d-237 [-1, 1048, 14, 14] 402,432
BatchNorm2d-238 [-1, 1048, 14, 14] 2,096
ReLU-239 [-1, 1432, 14, 14] 0
Block-240 [-1, 1432, 14, 14] 0
Conv2d-241 [-1, 384, 14, 14] 549,888
BatchNorm2d-242 [-1, 384, 14, 14] 768
ReLU-243 [-1, 384, 14, 14] 0
Conv2d-244 [-1, 384, 14, 14] 41,472
BatchNorm2d-245 [-1, 384, 14, 14] 768
ReLU-246 [-1, 384, 14, 14] 0
Conv2d-247 [-1, 1048, 14, 14] 402,432
BatchNorm2d-248 [-1, 1048, 14, 14] 2,096
ReLU-249 [-1, 1456, 14, 14] 0
Block-250 [-1, 1456, 14, 14] 0
Conv2d-251 [-1, 384, 14, 14] 559,104
BatchNorm2d-252 [-1, 384, 14, 14] 768
ReLU-253 [-1, 384, 14, 14] 0
Conv2d-254 [-1, 384, 14, 14] 41,472
BatchNorm2d-255 [-1, 384, 14, 14] 768
ReLU-256 [-1, 384, 14, 14] 0
Conv2d-257 [-1, 1048, 14, 14] 402,432
BatchNorm2d-258 [-1, 1048, 14, 14] 2,096
ReLU-259 [-1, 1480, 14, 14] 0
Block-260 [-1, 1480, 14, 14] 0
Conv2d-261 [-1, 384, 14, 14] 568,320
BatchNorm2d-262 [-1, 384, 14, 14] 768
ReLU-263 [-1, 384, 14, 14] 0
Conv2d-264 [-1, 384, 14, 14] 41,472
BatchNorm2d-265 [-1, 384, 14, 14] 768
ReLU-266 [-1, 384, 14, 14] 0
Conv2d-267 [-1, 1048, 14, 14] 402,432
BatchNorm2d-268 [-1, 1048, 14, 14] 2,096
ReLU-269 [-1, 1504, 14, 14] 0
Block-270 [-1, 1504, 14, 14] 0
Conv2d-271 [-1, 384, 14, 14] 577,536
BatchNorm2d-272 [-1, 384, 14, 14] 768
ReLU-273 [-1, 384, 14, 14] 0
Conv2d-274 [-1, 384, 14, 14] 41,472
BatchNorm2d-275 [-1, 384, 14, 14] 768
ReLU-276 [-1, 384, 14, 14] 0
Conv2d-277 [-1, 1048, 14, 14] 402,432
BatchNorm2d-278 [-1, 1048, 14, 14] 2,096
ReLU-279 [-1, 1528, 14, 14] 0
Block-280 [-1, 1528, 14, 14] 0
Conv2d-281 [-1, 768, 14, 14] 1,173,504
BatchNorm2d-282 [-1, 768, 14, 14] 1,536
ReLU-283 [-1, 768, 14, 14] 0
Conv2d-284 [-1, 768, 7, 7] 165,888
BatchNorm2d-285 [-1, 768, 7, 7] 1,536
ReLU-286 [-1, 768, 7, 7] 0
Conv2d-287 [-1, 2176, 7, 7] 1,671,168
BatchNorm2d-288 [-1, 2176, 7, 7] 4,352
Conv2d-289 [-1, 2176, 7, 7] 29,924,352
BatchNorm2d-290 [-1, 2176, 7, 7] 4,352
ReLU-291 [-1, 2304, 7, 7] 0
Block-292 [-1, 2304, 7, 7] 0
Conv2d-293 [-1, 768, 7, 7] 1,769,472
BatchNorm2d-294 [-1, 768, 7, 7] 1,536
ReLU-295 [-1, 768, 7, 7] 0
Conv2d-296 [-1, 768, 7, 7] 165,888
BatchNorm2d-297 [-1, 768, 7, 7] 1,536
ReLU-298 [-1, 768, 7, 7] 0
Conv2d-299 [-1, 2176, 7, 7] 1,671,168
BatchNorm2d-300 [-1, 2176, 7, 7] 4,352
ReLU-301 [-1, 2432, 7, 7] 0
Block-302 [-1, 2432, 7, 7] 0
Conv2d-303 [-1, 768, 7, 7] 1,867,776
BatchNorm2d-304 [-1, 768, 7, 7] 1,536
ReLU-305 [-1, 768, 7, 7] 0
Conv2d-306 [-1, 768, 7, 7] 165,888
BatchNorm2d-307 [-1, 768, 7, 7] 1,536
ReLU-308 [-1, 768, 7, 7] 0
Conv2d-309 [-1, 2176, 7, 7] 1,671,168
BatchNorm2d-310 [-1, 2176, 7, 7] 4,352
ReLU-311 [-1, 2560, 7, 7] 0
Block-312 [-1, 2560, 7, 7] 0
AdaptiveAvgPool2d-313 [-1, 2560, 1, 1] 0
Linear-314 [-1, 4] 10,244
================================================================
Total params: 67,994,324
Trainable params: 67,994,324
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 489.24
Params size (MB): 259.38
Estimated Total Size (MB): 749.20
----------------------------------------------------------------
2.3 训练模型
2.3.1 设置超参数
"""训练模型--设置超参数"""
loss_fn = nn.CrossEntropyLoss() # 创建损失函数,计算实际输出和真实相差多少,交叉熵损失函数,事实上,它就是做图片分类任务时常用的损失函数
learn_rate = 1e-4 # 学习率
optimizer1 = torch.optim.SGD(model.parameters(), lr=learn_rate)# 作用是定义优化器,用来训练时候优化模型参数;其中,SGD表示随机梯度下降,用于控制实际输出y与真实y之间的相差有多大
optimizer2 = torch.optim.Adam(model.parameters(), lr=learn_rate)
lr_opt = optimizer2
model_opt = optimizer2
# 调用官方动态学习率接口时使用2
lambda1 = lambda epoch : 0.92 ** (epoch // 4)
# optimizer = torch.optim.SGD(model.parameters(), lr=learn_rate)
scheduler = torch.optim.lr_scheduler.LambdaLR(lr_opt, lr_lambda=lambda1) #选定调整方法
2.3.2 编写训练函数
"""训练模型--编写训练函数"""
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 加载数据加载器,得到里面的 X(图片数据)和 y(真实标签)
X, y = X.to(device), y.to(device) # 用于将数据存到显卡
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # 清空过往梯度
loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新网络参数
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
2.3.3 编写测试函数
"""训练模型--编写测试函数"""
# 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad(): # 测试时模型参数不用更新,所以 no_grad,整个模型参数正向推就ok,不反向更新参数
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()#统计预测正确的个数
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
2.3.4 正式训练
"""训练模型--正式训练"""
epochs = 40
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_test_acc=0
for epoch in range(epochs):
milliseconds_t1 = int(time.time() * 1000)
# 更新学习率(使用自定义学习率时使用)
# adjust_learning_rate(lr_opt, epoch, learn_rate)
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, model_opt)
scheduler.step() # 更新学习率(调用官方动态学习率接口时使用)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
# 获取当前的学习率
lr = lr_opt.state_dict()['param_groups'][0]['lr']
milliseconds_t2 = int(time.time() * 1000)
template = ('Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E}')
if best_test_acc < epoch_test_acc:
best_test_acc = epoch_test_acc
#备份最好的模型
best_model = copy.deepcopy(model)
template = (
'Epoch:{:2d}, duration:{}ms, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}, Lr:{:.2E},Update the best model')
print(
template.format(epoch + 1, milliseconds_t2-milliseconds_t1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))
# 保存最佳模型到文件中
PATH = './best_model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
print('Done')
Epoch: 1, duration:14512ms, Train_acc:45.1%, Train_loss:1.304, Test_acc:68.1%,Test_loss:1.117, Lr:1.00E-04,Update the best model
Epoch: 2, duration:13979ms, Train_acc:63.7%, Train_loss:0.917, Test_acc:59.3%,Test_loss:1.028, Lr:1.00E-04
Epoch: 3, duration:14432ms, Train_acc:67.5%, Train_loss:0.818, Test_acc:69.9%,Test_loss:0.917, Lr:1.00E-04,Update the best model
Epoch: 4, duration:14277ms, Train_acc:73.0%, Train_loss:0.714, Test_acc:69.9%,Test_loss:0.747, Lr:1.00E-04
Epoch: 5, duration:13996ms, Train_acc:75.9%, Train_loss:0.623, Test_acc:79.6%,Test_loss:0.699, Lr:1.00E-04,Update the best model
Epoch: 6, duration:14143ms, Train_acc:79.2%, Train_loss:0.559, Test_acc:83.2%,Test_loss:0.626, Lr:1.00E-04,Update the best model
Epoch: 7, duration:14288ms, Train_acc:82.7%, Train_loss:0.439, Test_acc:84.1%,Test_loss:0.570, Lr:1.00E-04,Update the best model
Epoch: 8, duration:14050ms, Train_acc:83.0%, Train_loss:0.452, Test_acc:85.8%,Test_loss:0.529, Lr:1.00E-04,Update the best model
Epoch: 9, duration:14923ms, Train_acc:86.9%, Train_loss:0.349, Test_acc:90.3%,Test_loss:0.326, Lr:1.00E-04,Update the best model
Epoch:10, duration:14192ms, Train_acc:89.4%, Train_loss:0.281, Test_acc:75.2%,Test_loss:0.863, Lr:1.00E-04
Epoch:11, duration:14168ms, Train_acc:92.5%, Train_loss:0.228, Test_acc:90.3%,Test_loss:0.517, Lr:1.00E-04
Epoch:12, duration:14068ms, Train_acc:92.5%, Train_loss:0.252, Test_acc:90.3%,Test_loss:0.389, Lr:1.00E-04
Epoch:13, duration:14273ms, Train_acc:93.6%, Train_loss:0.186, Test_acc:87.6%,Test_loss:0.463, Lr:1.00E-04
Epoch:14, duration:14090ms, Train_acc:92.7%, Train_loss:0.241, Test_acc:91.2%,Test_loss:0.375, Lr:1.00E-04,Update the best model
Epoch:15, duration:14125ms, Train_acc:94.9%, Train_loss:0.164, Test_acc:89.4%,Test_loss:0.391, Lr:1.00E-04
Epoch:16, duration:14159ms, Train_acc:96.9%, Train_loss:0.112, Test_acc:85.8%,Test_loss:0.417, Lr:1.00E-04
Epoch:17, duration:15162ms, Train_acc:96.9%, Train_loss:0.089, Test_acc:89.4%,Test_loss:0.373, Lr:1.00E-04
Epoch:18, duration:14245ms, Train_acc:96.7%, Train_loss:0.159, Test_acc:86.7%,Test_loss:0.335, Lr:1.00E-04
Epoch:19, duration:14100ms, Train_acc:95.6%, Train_loss:0.143, Test_acc:92.9%,Test_loss:0.332, Lr:1.00E-04,Update the best model
Epoch:20, duration:14143ms, Train_acc:98.5%, Train_loss:0.067, Test_acc:88.5%,Test_loss:0.402, Lr:1.00E-04
Epoch:21, duration:14288ms, Train_acc:95.8%, Train_loss:0.101, Test_acc:88.5%,Test_loss:0.316, Lr:1.00E-04
Epoch:22, duration:14163ms, Train_acc:94.5%, Train_loss:0.178, Test_acc:82.3%,Test_loss:0.679, Lr:1.00E-04
Epoch:23, duration:14092ms, Train_acc:96.7%, Train_loss:0.112, Test_acc:88.5%,Test_loss:0.370, Lr:1.00E-04
Epoch:24, duration:14134ms, Train_acc:98.9%, Train_loss:0.042, Test_acc:92.9%,Test_loss:0.308, Lr:1.00E-04
Epoch:25, duration:14092ms, Train_acc:97.6%, Train_loss:0.070, Test_acc:71.7%,Test_loss:0.747, Lr:1.00E-04
Epoch:26, duration:14197ms, Train_acc:98.7%, Train_loss:0.064, Test_acc:90.3%,Test_loss:0.272, Lr:1.00E-04
Epoch:27, duration:14238ms, Train_acc:99.6%, Train_loss:0.041, Test_acc:91.2%,Test_loss:0.232, Lr:1.00E-04
Epoch:28, duration:14378ms, Train_acc:99.1%, Train_loss:0.044, Test_acc:87.6%,Test_loss:0.351, Lr:1.00E-04
Epoch:29, duration:14075ms, Train_acc:96.0%, Train_loss:0.102, Test_acc:85.0%,Test_loss:0.430, Lr:1.00E-04
Epoch:30, duration:15464ms, Train_acc:95.8%, Train_loss:0.166, Test_acc:83.2%,Test_loss:0.579, Lr:1.00E-04
Epoch:31, duration:14089ms, Train_acc:96.9%, Train_loss:0.095, Test_acc:79.6%,Test_loss:0.646, Lr:1.00E-04
Epoch:32, duration:14133ms, Train_acc:95.4%, Train_loss:0.133, Test_acc:91.2%,Test_loss:0.271, Lr:1.00E-04
Epoch:33, duration:14259ms, Train_acc:94.7%, Train_loss:0.146, Test_acc:83.2%,Test_loss:0.434, Lr:1.00E-04
Epoch:34, duration:14067ms, Train_acc:98.2%, Train_loss:0.071, Test_acc:89.4%,Test_loss:0.415, Lr:1.00E-04
Epoch:35, duration:14010ms, Train_acc:98.9%, Train_loss:0.054, Test_acc:88.5%,Test_loss:0.368, Lr:1.00E-04
Epoch:36, duration:14065ms, Train_acc:98.7%, Train_loss:0.043, Test_acc:84.1%,Test_loss:0.512, Lr:1.00E-04
Epoch:37, duration:14092ms, Train_acc:99.6%, Train_loss:0.027, Test_acc:88.5%,Test_loss:0.452, Lr:1.00E-04
Epoch:38, duration:14137ms, Train_acc:99.8%, Train_loss:0.021, Test_acc:91.2%,Test_loss:0.373, Lr:1.00E-04
Epoch:39, duration:14252ms, Train_acc:100.0%, Train_loss:0.009, Test_acc:92.0%,Test_loss:0.327, Lr:1.00E-04
Epoch:40, duration:14561ms, Train_acc:100.0%, Train_loss:0.008, Test_acc:90.3%,Test_loss:0.327, Lr:1.00E-04
2.4 结果可视化
"""训练模型--结果可视化"""
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

2.4 指定图片进行预测
def predict_one_image(image_path, model, transform, classes):
test_img = Image.open(image_path).convert('RGB')
plt.imshow(test_img) # 展示预测的图片
plt.show()
test_img = transform(test_img)
img = test_img.to(device).unsqueeze(0)
model.eval()
output = model(img)
_, pred = torch.max(output, 1)
pred_class = classes[pred]
print(f'预测结果是:{pred_class}')
# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))
"""指定图片进行预测"""
classes = list(total_data.class_to_idx)
# 预测训练集中的某张照片
predict_one_image(image_path=str(Path(data_dir) / "Cockatoo/001.jpg"),
model=model,
transform=train_transforms,
classes=classes)

输出
预测结果是:Cockatoo
2.6 模型评估
"""模型评估"""
best_model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
# 查看是否与我们记录的最高准确率一致
print(epoch_test_acc, epoch_test_loss)
输出
0.9292035398230089 0.33127474204881985
4 知识点详解
4.1 DPN讲解
论文:Dual Path Networks
论文链接:https://arxiv.org/abs/1707.01629
代码:https://github.com/cypw/DPNs
MXNet框架下可训练模型的DPN代码:https://github.com/miraclewkf/DPN
算法详解:
介绍的duall path networks(DPN)是颜水成老师新作,2017年4月在arxiv上放出,对于图像分类的效果有一定提升。我们知道ResNet,ResNeXt,DenseNet等网络在图像分类领域的效果显而易见,而DPN可以说是融合了ResNeXt和DenseNet的核心思想,这里为什么不说是融合了ResNet和DenseNet,因为作者也用了group操作,而ResNeXt和ResNet的主要区别就在于group操作。
我们知道ResNet,ResNeXt,DenseNet等网络在图像分类领域的效果显而易见,而DPN可以说是融合了ResNeXt和DenseNet的核心思想,这里为什么不说是融合了ResNet和DenseNet,因为作者也用了group操作,而ResNeXt和ResNet的主要区别就在于group操作。
优势
1、关于模型复杂度,作者的原文是这么说的:The DPN-92 costs about 15% fewer parameters than ResNeXt-101 (32 4d), while the DPN-98 costs about 26% fewer parameters than ResNeXt-101 (64 4d).
2、关于计算复杂度,作者的原文是这么说的:DPN-92 consumes about 19% less FLOPs than ResNeXt-101(32 4d), and the DPN-98 consumes about 25% less FLOPs than ResNeXt-101(64 4d).
先放上网络结构Table1,有一个直观的印象。其实DPN和ResNeXt(ResNet)的结构很相似。最开始一个7*7的卷积层和max pooling层,然后是4个stage,每个stage包含几个sub-stage(后面会介绍),再接着是一个global average pooling和全连接层,最后是softmax层。重点在于stage里面的内容,也是DPN算法的核心。
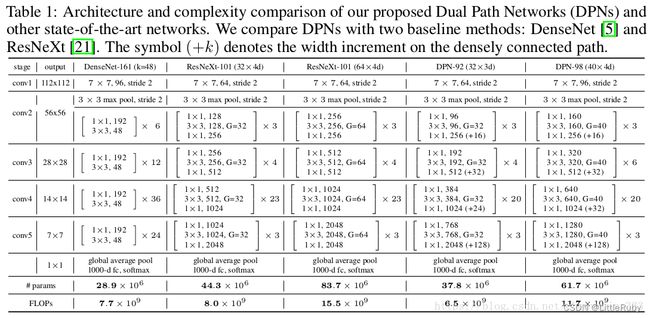
因为DPN算法简单讲就是将ResNeXt和DenseNet融合成一个网络,因此在介绍DPN的每个stage里面的结构之前,先简单过一下ResNet(ResNeXt和ResNet的子结构在宏观上是一样的)和DenseNet的核心内容。下图中的(a)是ResNet的某个stage中的一部分。(a)的左边竖着的大矩形框表示输入输出内容,对一个输入x,分两条线走,一条线还是x本身,另一条线是x经过11卷积,33卷积,11卷积(这三个卷积层的组合又称作bottleneck),然后把这两条线的输出做一个element-wise addition,也就是对应值相加,就是(a)中的加号,得到的结果又变成下一个同样模块的输入,几个这样的模块组合在一起就成了一个stage(比如Table1中的conv3)。(b)表示DenseNet的核心内容。(c)的左边竖着的多边形框表示输入输出内容,对输入x,只走一条线,那就是经过几层卷积后和x做一个通道的合并(cancat),得到的结果又成了下一个小模块的输入,这样每一个小模块的输入都在不断累加,举个例子:第二个小模块的输入包含第一个小模块的输出和第一个小模块的输入,以此类推。
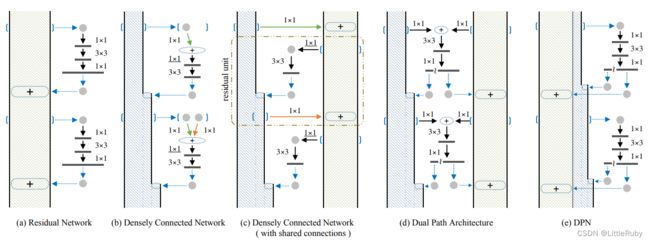
DPN是怎么做呢?简单讲就是将Residual Network 和 Densely Connected Network融合在一起。下图中的(d)和(e)是一个意思,所以就按(e)来讲吧。(e)中竖着的矩形框和多边形框的含义和前面一样。具体在代码中,对于一个输入x(分两种情况:一种是如果x是整个网络第一个卷积层的输出或者某个stage的输出,会对x做一个卷积,然后做slice,也就是将输出按照channel分成两部分:data_o1和data_o2,可以理解为(e)中竖着的矩形框和多边形框;另一种是在stage内部的某个sub-stage的输出,输出本身就包含两部分:data_o1和data_o2),走两条线,一条线是保持data_o1和data_o2本身,和ResNet类似;另一条线是对x做11卷积,33卷积,11卷积,然后再做slice得到两部分c1和c2,最后c1和data_o1做相加(element-wise addition)得到sum,类似ResNet中的操作;c2和data_o2做通道合并(concat)得到dense(这样下一层就可以得到这一层的输出和这一层的输入),也就是最后返回两个值:sum和dense。以上这个过程就是DPN中 一个stage中的一个sub-stage。有两个细节,一个是33的卷积采用的是group操作,类似ResNeXt,另一个是在每个sub-stage的首尾都会对dense部分做一个通道的加宽操作。
由上图可知,ResNet复用了前面层的特征,而每一层的特征会原封不动的传到下一层,而在每一层通过卷积等操作后又会提取到不同的特征,因此特征的冗余度较低。但DenseNet的每个11卷积参数不同,前面提到的层不是被后面的层直接使用,而是被重新加工后生成了新的特征,因此这种结构很有可能会造成后面的层提取到的特征是前面的网络已经提取过的特征,故而DenseNet是一个冗余度较高的网络。DPN以ResNet为主要框架,保证特征的低冗余度,并添加了一个非常小的DenseNet分支,用于生成新的特征。
作者在MXNet框架下实现了DPN算法,具体的symbol可以看:https://github.com/cypw/DPNs/tree/master/settings,介绍得非常详细也很容易读懂。
实验结果:
Table2是在ImageNet-1k数据集上和目前最好的几个算法的对比:ResNet,ResNeXt,DenseNet。可以看出在模型大小,GFLOP和准确率方面DPN网络都更胜一筹。不过在这个对比中好像DenseNet的表现不如DenseNet那篇论文介绍的那么喜人,可能是因为DenseNet的需要更多的训练技巧。

Figure3是关于训练速度和存储空间的对比。现在对于模型的改进,可能准确率方面的提升已经很难作为明显的创新点,因为幅度都不大,因此大部分还是在模型大小和计算复杂度上优化,同时只要准确率还能提高一点就算进步了。

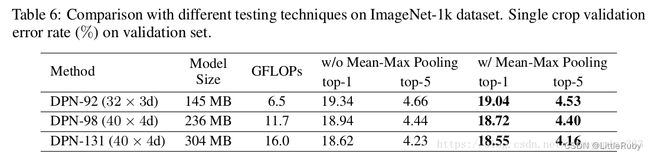
作者的最后提到一个如果在测试阶段,在网络结构后面加上mean-max pooling 层可以提高准确率,如下图:
总结
作者提出的DPN网络可以理解为在ResNeXt的基础上引入了DenseNet的核心内容,使得模型对特征的利用更加充分。原理方面并不难理解,而且在跑代码过程中也比较容易训练,同时文章中的实验也表明模型在分类和检测的数据集上都有不错的效果。
4.1.2 DPN模型架构

上图最左侧为DPN92的网络结构,对比下图的ResNet不难看出,DPN确是以ResNet为框架进行的改进。右侧是DPN主要模块的详细结构图,其中粉色模块对应ResNet中的ConvBlock模块,灰色模块对应ResNet中的IdentityBlock模块。但又由独特之处,就是在两个模块中,无论是直接shortcut还是经过一个Conc2d+BN,与ResNet的直接进行sum处理不同,这里将两条支路的特征分别进行截取,如图中红框和蓝框中所示,将其特征分别截取成①和②部分,以及③和④部分,其中①③的尺寸一致,②④的尺寸一致,然后将①和③进行sum操作后再与②④进行concat操作,这样便引入了DenseNet中的直接在channel维度上进行concat的思想。

参考链接:
详解深度学习之经典网络架构(九):DPN(Dual Path Network)
CNN(四):ResNet与DenseNet结合–DPN
总结
前面实现了ResNet和DenseNet的算法,了解了它们有各自的特点:
ResNet:通过建立前面层与后面层之间的“短路连接”(shortcut),其特征则直接进行sum操作,因此channel数不变;
DenseNet:通过建立的是前面所有层与后面层的紧密连接(dense connection),其特征在channel维度上的直接concat来实现特征重用(feature reuse),因此channel数增加;
Dual Path Architecture(DPA)以ResNet为主要框架,保证了特征的低冗余度,并在其基础上添加了一个非常小的DenseNet分支,用于生成新的特征。可以理解为在ResNeXt的基础上引入了DenseNet的核心内容,使得模型对特征的利用更加充分。
但是在实际测试跑算法过程中,DPN并没有比Resnet或Densenet效果好,采用batchsize=32时,测试集识别率还不到90%,当batchsize=4时,增加epoch,测试精度能达到90%多,但并没有到理论上的优势,该问题还需继续探究。